Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dokumen ini menjelaskan pendekatan tim Fabric untuk mempertahankan layanan yang andal, berkinerja, dan dapat diskalakan bagi pelanggan. Ini menjelaskan pemantauan kesehatan layanan, menangani insiden, dan melakukan perbaikan yang diperlukan. Aspek operasional penting lainnya seperti manajemen keamanan dan rilis berada di luar cakupan dokumen ini. Dokumen ini dibuat untuk berbagi pengetahuan dengan pelanggan kami, yang sering mengajukan pertanyaan mengenai praktik rekayasa keandalan situs. Niatnya adalah untuk menawarkan transparansi tentang bagaimana Fabric meminimalkan gangguan layanan melalui penyebaran yang aman, pemantauan berkelanjutan, dan respons insiden yang cepat. Teknik yang dijelaskan di sini juga menyediakan cetak biru bagi tim yang menghosting solusi berbasis layanan untuk membangun proses situs langsung dasar yang efisien dan efektif dalam skala besar.
Mengapa insiden terjadi dan cara hidup bersama mereka
Tim Fabric mengirimkan pembaruan fitur mingguan untuk layanan dan perbaikan yang ditargetkan sesuai permintaan untuk mengatasi masalah kualitas layanan. Proses rilis mencakup serangkaian gerbang kualitas yang komprehensif, termasuk tinjauan kode menyeluruh, pengujian ad-hoc, pengujian otomatis berdasarkan komponen dan skenario, peluncuran bertahap fitur, dan penyebaran aman di tingkat regional. Namun, bahkan dengan perlindungan ini, insiden situs langsung dapat dan terjadi.
Insiden situs langsung dapat dibagi menjadi beberapa kategori:
Masalah layanan dependen seperti Azure AD, Azure SQL, Penyimpanan, skala mesin virtual, Service Fabric.
Pemadaman infrastruktur seperti kegagalan perangkat keras, kegagalan pusat data.
Masalah konfigurasi lingkungan fabric seperti kapasitas yang tidak mencukup.
Regresi kode layanan Fabric
Kesalahan konfigurasi pelanggan seperti sumber daya yang tidak mencukupi dan kueri atau laporan yang salah.
Mengurangi volume insiden adalah salah satu cara untuk mengurangi beban situs langsung dan untuk meningkatkan kepuasan pelanggan. Namun, melakukannya tidak selalu mungkin mengingat bahwa beberapa kategori insiden berada di luar kontrol langsung tim. Selain itu, ketika jejak layanan meluas untuk mendukung pertumbuhan penggunaan, kemungkinan insiden terjadi karena faktor eksternal meningkat. Jumlah insiden yang tinggi dapat terjadi bahkan dalam kasus di mana layanan Fabric memiliki regresi kode layanan minimal, dan telah memenuhi atau melebihi Tujuan Tingkat Layanan (SLO) untuk keandalan keseluruhan 99,95%, yang telah menyebabkan tim Fabric mencurahkan sumber daya yang signifikan untuk mengurangi dampak insiden.
Proses insiden situs langsung
Saat menyelidiki insiden situs langsung, tim Fabric mengikuti proses operasional standar yang umum di seluruh Microsoft dan industri. Gambar berikut merangkum siklus hidup penanganan insiden situs web aktif standar.
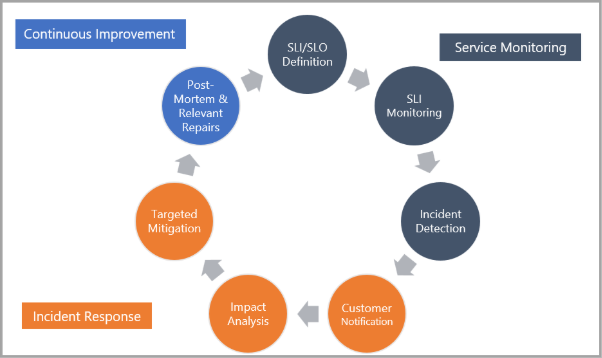
Fase 1: Pemantauan layanan Tim SRE bekerja dengan teknisi, manajer program, dan Tim Kepemimpinan Senior untuk menentukan Indikator Tingkat Layanan (SLI) dan Tujuan Tingkat Layanan (SLA) untuk skenario utama dan skenario kecil. Tujuan ini berlaku untuk metrik layanan yang berbeda, termasuk skenario dan komponen keandalan, skenario dan komponen performa (latensi), dan konsumsi sumber daya. Tim situs langsung dan tim produk kemudian membuat pemberitahuan yang memantau Indikator Tingkat Layanan (SLI) terhadap target yang disepakati. Saat pelanggaran terdeteksi, peringatan dipicu untuk penyelidikan.
Fase 2: Respons insiden - Proses disusun untuk memfasilitasi hasil berikut:
Segera kirimkan dan targetkan pemberitahuan kepada pelanggan mengenai dampak yang relevan.
Analisis komponen dan alur kerja layanan yang terpengaruh
Mitigasi dampak insiden yang ditargetkan
Fase 3: Peningkatan Berkelanjutan - Penyelesaian analisis evaluasi yang relevan dan resolusi dari setiap perbaikan yang diidentifikasi pada proses, pemantauan, konfigurasi, atau kode. Perbaikan kemudian diprioritaskan terhadap backlog rekayasa umum tim berdasarkan tingkat keparahan keseluruhan dan risiko terulang kembali.
Praktik kami untuk pemantauan layanan
Tim Fabric menekankan pendekatan yang konsisten, berbasis data, dan berpusat pada pelanggan untuk operasi situs langsung. Menentukan Indikator Tingkat Layanan (SLI) dan menerapkan pemberitahuan pemantauan situs langsung yang sesuai adalah bagian dari kriteria persetujuan untuk mengaktifkan fitur Fabric baru dalam produksi. Teknisi grup produk juga menyertakan langkah-langkah untuk penyelidikan dan mitigasi pemberitahuan ketika terjadi menggunakan Panduan Pemecahan Masalah templat (TSG). Hasil tersebut kemudian disajikan kepada tim Rekayasa Keandalan Situs (SRE).
Salah satu cara tim Fabric memungkinkan pertumbuhan layanan eksponensial adalah dengan menggunakan tim SRE. Individu ini terampil dengan arsitektur layanan, otomatisasi, serta praktik manajemen insiden, dan dilibatkan dalam insiden untuk memastikan resolusi menyeluruh. Pendekatan ini berbeda dengan model rotasi di mana pemimpin teknik dari grup produk mengambil peran manajer insiden hanya selama beberapa minggu per tahun. Tim SRE memastikan bahwa sekelompok individu yang konsisten bertanggung jawab untuk mendorong peningkatan situs langsung dan memastikan bahwa pembelajaran dari insiden sebelumnya dimasukkan ke dalam eskalasi di masa depan. Tim SRE juga membantu latihan skala besar yang menguji kemampuan Business Continuity and Disaster Recovery (BCDR) layanan.
Anggota tim SRE menggunakan keahlian unik mereka dan pengalaman yang luas dalam pengelolaan situs langsung, serta bermitra dengan tim fitur untuk meningkatkan SLI dan peringatan yang disediakan oleh tim produk dengan berbagai cara. Beberapa cara mereka meningkatkan SLI (Sistem Layanan Informasi) meliputi:
Anomaly Alerts - SREs mengembangkan monitor yang mempertimbangkan penggunaan umum dan pola operasional dalam lingkungan produksi tertentu dan memberikan peringatan ketika terjadi penyimpangan signifikan. Contoh : Latensi refresh himpunan data meningkat sebesar 50% relatif terhadap periode penggunaan serupa.
Pemberitahuan Pelanggan/Environment-Specific - SREs mengembangkan monitor yang mendeteksi kapan pelanggan tertentu, kapasitas yang disediakan, atau kluster yang disebarkan menyimpang dari perilaku yang diharapkan. contoh : Satu kapasitas yang dimiliki oleh pelanggan gagal memuat himpunan data untuk mengkueri.
Fine-Grained Pemberitahuan - SREs mempertimbangkan subset populasi yang mungkin mengalami masalah secara independen dari populasi yang lebih luas. Untuk kasus seperti itu, peringatan tertentu dibuat untuk memastikan bahwa peringatan benar-benar akan aktif jika skenario yang kurang umum gagal meskipun volumenya lebih rendah. Contoh: Merefresh himpunan data yang menggunakan konektor GitHub mengalami kegagalan
Peringatan Keandalan yang Dirasakan - SRE juga merancang peringatan yang mendeteksi kasus ketika pengguna gagal karena segala jenis kesalahan. Ini dapat mencakup kegagalan dari kesalahan pengguna dan menunjukkan kebutuhan untuk meningkatkan dokumentasi atau pengalaman pengguna yang dimodifikasi. Pemberitahuan ini juga dapat memberi tahu teknisi tentang kesalahan sistem tak terduga yang mungkin salah diklasifikasikan sebagai kesalahan pengguna. Contoh : Refresh himpunan data gagal karena kredensial yang salah
Peran penting lain dari tim SRE adalah mengotomatiskan tindakan TSG sejauh mungkin melalui Azure Automation. Dalam kasus di mana otomatisasi lengkap tidak dimungkinkan, tim SRE mendefinisikan tindakan untuk memperkaya pemberitahuan dengan informasi diagnostik yang berguna dan khusus insiden untuk mempercepat penyelidikan berikutnya. Pengayaan tersebut dipasangkan dengan panduan preskriptif dalam TSG yang sesuai sehingga teknisi situs langsung dapat mengambil tindakan tertentu untuk mengurangi insiden atau dengan cepat meningkatkan ke UKM untuk penyelidikan tambahan.
Sebagai hasil langsung dari upaya ini, lebih dari 82% insiden dimitigasi tanpa interaksi manusia. Insiden yang tersisa memiliki data pengayaan yang cukup dan dokumentasi pendukung untuk ditangani tanpa keterlibatan UKM dalam 99,7% kasus.
SREs Situs Langsung juga menjaga kualitas peringatan dengan beberapa cara, termasuk yang berikut ini:
Memastikan bahwa TSG mencakup analisis dampak dan kebijakan eskalasi
Memastikan bahwa pemberitahuan dijalankan untuk jendela waktu sekecil absolut yang mungkin untuk deteksi yang lebih cepat
Memastikan bahwa pemberitahuan menggunakan ambang keandalan alih-alih batas absolut untuk menskalakan kluster dengan ukuran yang berbeda
Praktik kami dalam respons insiden
Ketika insiden situs aktif otomatis dibuat untuk layanan Fabric, salah satu prioritas pertama adalah memberi tahu pelanggan tentang potensi dampak. Azure memiliki target waktu untuk mengirim pemberitahuan selama 15 menit, yang sulit dicapai ketika pemberitahuan diposting secara manual oleh manajer insiden setelah bergabung dalam panggilan konferensi. Komunikasi dalam kasus tersebut berisiko terlambat atau tidak akurat karena analisis manual yang diperlukan. Azure Monitoring menawarkan solusi pemantauan dan pemberitahuan terpusat yang berdasarkan metrik tertentu dalam jendela waktu ini, dapat mendeteksi kemungkinan dampaknya. Namun, Fabric adalah penawaran SaaS dengan skenario kompleks dan interaksi pengguna yang tidak dapat dengan mudah dimodelkan dan dilacak menggunakan sistem peringatan tersebut. Sebagai respons, tim Fabric mengembangkan layanan pemberitahuan Time To Notify Zero (TTN0).
Filosofi situs aktif Fabric menekankan penyelesaian insiden otomatis untuk meningkatkan skalabilitas dan keberlanjutan tim SRE secara keseluruhan. Penekanan pada otomatisasi memungkinkan mitigasi dalam skala besar dan berpotensi menghindari pembatalan yang mahal atau perbaikan yang dipercepat berisiko pada sistem produksi. Ketika penyelidikan manual diperlukan, Fabric mengadopsi pendekatan berjenjang dengan penyelidikan awal yang dilakukan oleh tim SRE khusus. Anggota tim SRE berpengalaman dalam mengelola insiden situs yang sedang berjalan, memfasilitasi komunikasi lintas tim, dan mengendalikan upaya mitigasi. Dalam kasus di mana anggota tim SRE yang bertindak memerlukan lebih banyak konteks tentang skenario/komponen yang terpengaruh, mereka mungkin melibatkan Subject Matter Expert (SME) dari area tersebut untuk panduan. Akhirnya, tim UKM melakukan simulasi kegagalan komponen sistem untuk memahami dan mengurangi masalah sebelum insiden situs langsung aktif.
Setelah komponen atau skenario layanan yang terpengaruh ditentukan, tim Fabric memiliki beberapa teknik untuk mengurangi dampak dengan cepat. Beberapa di antaranya adalah:
Mengaktifkan infrastruktur penyebaran berdampingan - Fabric mendukung menjalankan beban kerja versi yang berbeda di kluster yang sama, memungkinkan tim menjalankan versi baru (atau sebelumnya) dari beban kerja tertentu untuk pelanggan tertentu tanpa memicu penyebaran skala penuh (atau putar kembali). Pendekatan ini dapat mengurangi waktu mitigasi menjadi 15 menit dan menurunkan risiko penyebaran keseluruhan.
Eksekusi proses Business Continuity/Disaster Recovery (BCDR) - Memungkinkan tim untuk memindahkan beban kerja utama ke lingkungan alternatif dalam tiga menit jika masalah serius ditemukan dalam versi layanan baru. BCDR juga dapat digunakan ketika faktor lingkungan atau layanan dependen mencegah kluster/wilayah utama beroperasi secara normal.
Memanfaatkan ketahanan layanan dependen - Fabric secara proaktif mengevaluasi dan berinvestasi dalam upaya ketahanan dan redundansi untuk semua layanan dependen (seperti SQL, Redis Cache, Key Vault). Ketahanan mencakup pemantauan komponen yang memadai untuk mendeteksi regresi hulu dan hilir serta redundansi lokal, zonal, dan regional (jika berlaku). Berinvestasi dalam kemampuan ini memastikan bahwa alat tersedia untuk memicu operasi pemulihan secara otomatis atau manual guna mengurangi dampak dari ketergantungan yang terpengaruh.
** Saatnya Memberi Pemberitahuan untuk Nol
Time To Notify Zero, juga dikenal sebagai TTN0, adalah layanan pemberitahuan insiden otomatis sepenuhnya yang menggunakan infrastruktur pemberitahuan internal kami untuk mengidentifikasi skenario dan pelanggan tertentu yang terpengaruh oleh insiden yang baru dibuat. Ini juga terintegrasi dengan agen pemantauan eksternal di luar Azure untuk mendeteksi masalah konektivitas yang mungkin tidak terdeteksi. TTN0 memungkinkan pelanggan untuk menerima email ketika TTN0 mendeteksi gangguan atau degradasi layanan. Dengan TTN0, tim Fabric dapat mengirim pemberitahuan yang andal dan ditargetkan dalam waktu 10 menit dari waktu mulai dampak (yaitu 33% lebih cepat daripada target Azure). Karena solusi sepenuhnya otomatis, ada risiko minimal dari kesalahan manusia atau keterlambatan.
Praktik kami untuk peningkatan berkelanjutan
Tim Fabric meninjau semua insiden yang berdampak pada pelanggan selama tinjauan layanan mingguan dengan representasi dari semua grup teknik yang berkontribusi pada layanan Fabric. Ulasan ini menyebarluaskan pembelajaran utama dari insiden kepada para pemimpin di seluruh organisasi dan memberikan kesempatan untuk menyesuaikan proses kami untuk menutup celah dan mengatasi inefisiensi.
Sebelum peninjauan, tim SRE menyiapkan konten pasca-mortem dan mengidentifikasi elemen perbaikan awal untuk tim situs aktif dan tim pengembangan produk. Item mungkin menyertakan perbaikan kode, telemetri yang ditingkatkan, atau pemberitahuan atau TSG yang telah diperbarui. Fabric SREs terbiasa dengan banyak bidang ini dan sering kali secara proaktif membuat penyesuaian secara real time saat menangani insiden aktif. Melakukannya membantu memastikan bahwa perubahan dimasukkan ke dalam sistem tepat waktu untuk mendeteksi terjadinya kembali masalah serupa. Dalam kasus di mana insiden adalah hasil dari eskalasi pelanggan, tim SRE menyesuaikan pemberitahuan otomatis dan SLI yang ada untuk mencerminkan ekspektasi pelanggan. Untuk sejumlah kecil insiden yang memerlukan eskalasi ke Subject Matter Expert (SME) dari skenario/komponen yang terkena dampak, tim Fabric SRE akan meninjau cara di mana insiden yang sama (atau insiden serupa) dapat ditangani tanpa eskalasi di masa depan. Analisis terperinci oleh tim SRE membantu tim pengembangan produk untuk merancang produk yang lebih tangguh, dapat diskalakan, dan mendukung.
Di luar peninjauan postmortem tertentu, tim SRE juga menghasilkan laporan tentang data insiden agregat untuk mengidentifikasi peluang peningkatan layanan seperti otomatisasi mitigasi insiden atau perbaikan produk di masa mendatang. Pelaporan menggabungkan data dari beberapa sumber, termasuk tim dukungan pelanggan, pemberitahuan otomatis, dan telemetri layanan. Tampilan terkonsolidasi memberikan visibilitas ke dalam masalah yang paling berdampak negatif pada layanan dan kesehatan tim, dan tim SRE kemudian memprioritaskan potensi peningkatan berdasarkan manfaat keseluruhan terhadap keandalan layanan. Misalnya, jika pemberitahuan tertentu terlalu sering diaktifkan atau menghasilkan dampak yang tidak proporsional pada keandalan layanan, tim SRE dapat bermitra dengan tim pengembangan produk untuk berinvestasi dalam peningkatan kualitas yang relevan. Menyelesaikan item kerja ini mendorong peningkatan metrik layanan dan situs langsung dan secara langsung berkontribusi pada hasil kunci tujuan organisasi (OKR). Dalam kasus di mana SLI telah terpenuhi secara konsisten untuk jangka waktu yang lama, tim SRE dapat menyarankan peningkatan ke SLO layanan untuk memberikan pengalaman yang lebih baik bagi pelanggan kami.
Mengukur keberhasilan melalui hasil kunci objektif (OKR)
Tim Fabric memiliki serangkaian Objective Key Results (OKR) komprehensif yang digunakan untuk memastikan kesehatan layanan dan kepuasan pelanggan secara keseluruhan. OKR dapat dibagi menjadi dua kategori:
OKR Service Health - OKR ini secara langsung atau tidak langsung mengukur kesehatan skenario atau komponen dalam layanan dan sering dilacak dengan memantau atau memperingatkan. contoh : Kapasitas tunggal milik pelanggan gagal memuat himpunan data untuk melakukan kueri.
OKR Live Site Health - OKR ini, baik secara langsung maupun tidak langsung, mengukur efisiensi dan efektivitas operasi site live dalam mengatasi insiden dan pemadaman layanan. Contoh : Saatnya memberitahu (TTN) pelanggan tentang insiden yang berdampak.
Waktu yang diperlukan tim Fabric untuk bereaksi terhadap insiden seperti yang diukur oleh TTN, TTA, dan TTM secara signifikan melebihi target. Otomatisasi pemberitahuan berkorelasi langsung dengan kemampuan tim untuk mempertahankan pertumbuhan layanan eksponensial, sambil terus memenuhi atau melebihi waktu respons target untuk pemberitahuan, pemberitahuan, dan mitigasi insiden.
OKR di atas secara aktif dilacak oleh tim situs langsung Fabric, dan Tim Kepemimpinan Senior, untuk memastikan bahwa tim terus memenuhi atau melebihi garis besar yang diperlukan untuk mendukung pertumbuhan layanan yang substansial, untuk mempertahankan beban kerja situs langsung yang berkelanjutan, dan untuk memastikan kepuasan pelanggan yang tinggi.