Membangun lakehouse untuk Direct Lake
Artikel ini menjelaskan cara membuat lakehouse, membuat tabel Delta di lakehouse, lalu membuat model semantik dasar untuk lakehouse di ruang kerja Microsoft Fabric.
Sebelum mulai membuat lakehouse untuk Direct Lake, pastikan untuk membaca gambaran umum Direct Lake.
Membuat lakehouse
Di ruang kerja Microsoft Fabric Anda, pilih Baru>Opsi lainnya, lalu di Rekayasa Data, pilih petak Lakehouse.

Dalam kotak dialog New lakehouse, masukkan nama, lalu pilih Buat. Nama hanya dapat berisi karakter alfanumerik dan garis bawah.

Pastikan lakehouse baru telah dibuat dan dapat dibuka dengan sukses.

Membuat tabel Delta di lakehouse
Setelah membuat lakehouse baru, Anda kemudian harus membuat setidaknya satu tabel Delta sehingga Direct Lake dapat mengakses beberapa data. Direct Lake dapat membaca file berformat parket, tetapi untuk performa terbaik, yang terbaik adalah mengompresi data dengan menggunakan metode kompresi VORDER. VORDER mengompresi data menggunakan algoritma kompresi asli mesin Power BI. Dengan cara ini mesin dapat memuat data ke dalam memori secepat mungkin.
Ada beberapa opsi untuk memuat data ke lakehouse, termasuk alur data dan skrip. Langkah-langkah berikut menggunakan PySpark untuk menambahkan tabel Delta ke lakehouse berdasarkan Azure Open Dataset:
Di lakehouse yang baru dibuat, pilih Buka buku catatan, lalu pilih Notebook baru.

Salin dan tempel cuplikan kode berikut ke dalam sel kode pertama untuk memungkinkan SPARK mengakses model yang terbuka, lalu tekan Shift + Enter untuk menjalankan kode.
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)Verifikasi bahwa kode berhasil menghasilkan jalur blob jarak jauh.

Salin dan tempel kode berikut ke sel berikutnya, lalu tekan Shift + Enter.
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())Verifikasi kode berhasil menghasilkan skema DataFrame.

Salin dan tempel baris berikut ke sel berikutnya, lalu tekan Shift + Enter. Instruksi pertama memungkinkan metode kompresi VORDER, dan instruksi berikutnya menyimpan DataFrame sebagai tabel Delta di lakehouse.
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")Verifikasi bahwa semua pekerjaan SPARK berhasil diselesaikan. Perluas daftar pekerjaan SPARK untuk melihat detail selengkapnya.

Untuk memverifikasi bahwa tabel telah berhasil dibuat, di area kiri atas, di sebelah Tabel, pilih elipsis (...), kemudian pilih Refresh, dan setelah itu, perluas simpul Tabel.

Menggunakan metode yang sama seperti di atas atau metode lain yang didukung, tambahkan lebih banyak tabel Delta untuk data yang ingin Anda analisis.
Buat model dasar Direct Lake untuk lakehouse Anda
Di lakehouse Anda, pilih Model semantik baru, kemudian di dialog tersebut, pilih tabel yang akan disertakan.
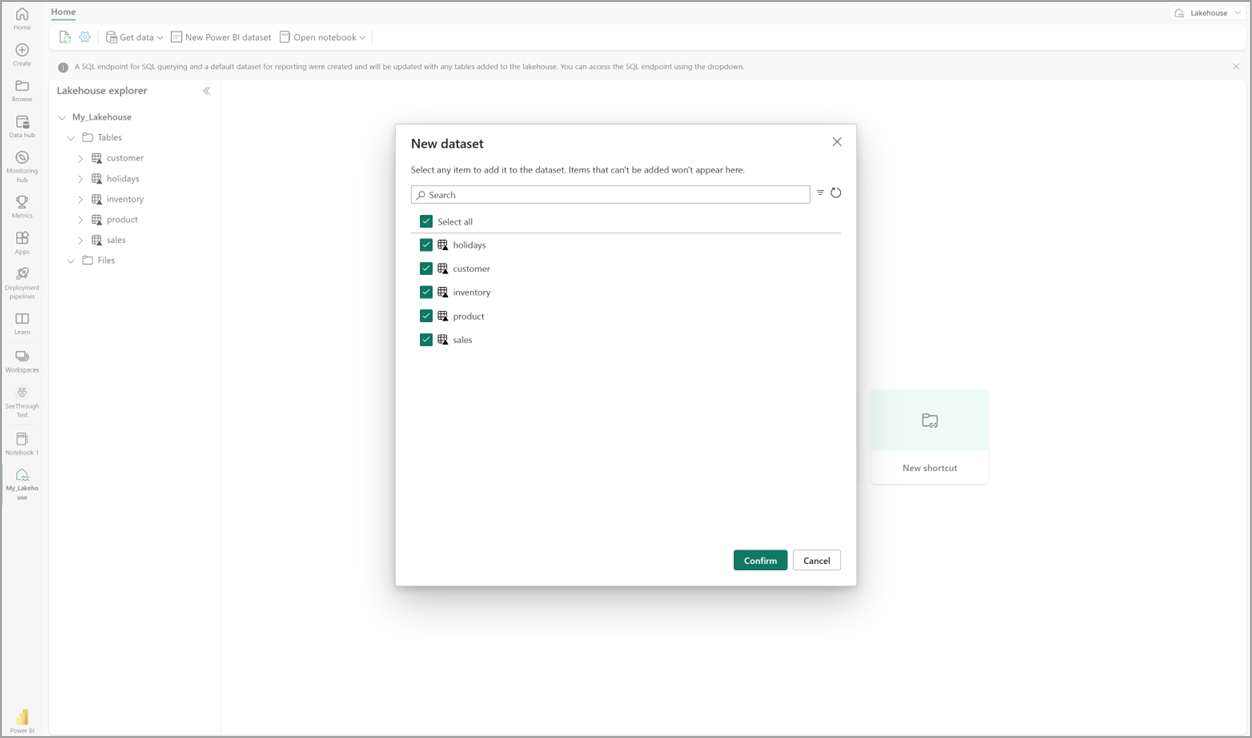
Pilih Konfirmasi untuk menghasilkan model Direct Lake. Model secara otomatis disimpan di ruang kerja sesuai dengan nama rumah danau Anda, kemudian model tersebut akan dibuka.

Pilih Buka model data untuk membuka pengalaman pemodelan Web tempat Anda dapat menambahkan hubungan tabel dan ukuran DAX.

Setelah selesai menambahkan hubungan dan ukuran DAX, Anda kemudian dapat membuat laporan, membangun model komposit, dan mengkueri model melalui titik akhir XMLA dengan cara yang sama seperti model lainnya.