Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Mirroring in Fabric menawarkan cara sederhana untuk menghindari proses ETL (Extract, Transform, Load) yang kompleks dan mengintegrasikan data gudang Google BigQuery Anda yang ada dengan sisa data Anda di Fabric. Anda dapat terus mereplikasi data Google BigQuery langsung ke OneLake Fabric. Setelah di Fabric, Anda dapat memanfaatkan kemampuan yang kuat untuk kecerdasan bisnis, AI, rekayasa data, ilmu data, dan berbagi data.
Untuk tutorial tentang mengonfigurasi database Google BigQuery Anda untuk Mirroring di Fabric, lihat Tutorial: Mengonfigurasi database cermin Microsoft Fabric dari Google BigQuery.
Penting
Pencerminan untuk Google BigQuery sekarang dalam pratinjau. Beban kerja produksi tidak didukung selama masa pratinjau.
Mengapa menggunakan pencerminan di Fabric?
Penggunaan Microsoft Fabric menghilangkan kompleksitas menggabungkan alat dari berbagai penyedia. Tidak perlu memigrasikan data Anda. Sambungkan ke data Google BigQuery Anda nyaris real-time untuk menggunakan berbagai alat analitik Fabric. Fabric juga bekerja dengan mulus dengan produk Microsoft, Google BigQuery, dan berbagai teknologi yang mendukung format tabel Delta Lake sumber terbuka.
Pengalaman analitik apa yang tertanam?
Pencerminan membuat database cermin dan titik akhir analitik SQL di ruang kerja Fabric Anda. Database yang dicerminkan mengelola replikasi data ke OneLake dan konversi ke Parquet, memungkinkan skenario hilir seperti rekayasa data, ilmu data, dan banyak lagi.
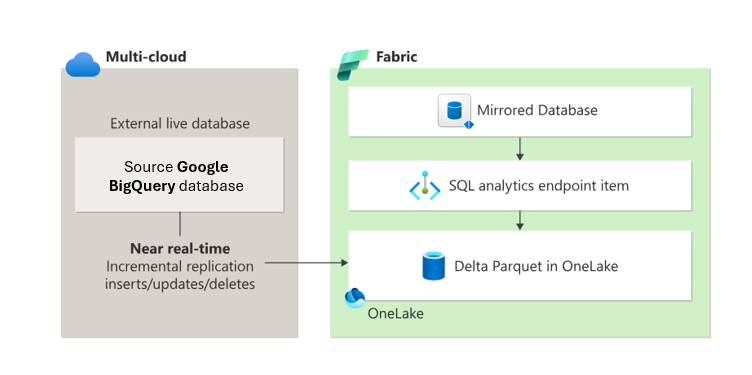
Titik akhir analitik SQL memberikan pengalaman analitik baca-saja di atas tabel Delta yang dibuat selama pencerminan. Anda dapat menelusuri tabel yang dicerminkan, membuat kueri dan tampilan tanpa kode, membuat tampilan SQL dan prosedur tersimpan, serta membuat kueri pada data di berbagai gudang data dan lakehouse dalam ruang kerja yang sama.
Untuk informasi selengkapnya tentang kemampuan analitik dan alat yang kompatibel, lihat Mencerminkan objek.
Pertimbangan keamanan
Ada persyaratan izin pengguna khusus untuk mengaktifkan Fabric Mirroring.
Fabric juga menyediakan fitur perlindungan data untuk mengelola akses dalam Microsoft Fabric. Untuk informasi selengkapnya, lihat dokumentasi fitur perlindungan data kami.
Pertimbangan biaya Mirrored BigQuery
Komputasi Fabric yang digunakan untuk mereplikasi data Anda ke Fabric OneLake gratis. Biaya penyimpanan Mirroring bebas hingga batas berdasarkan kapasitas. Komputasi untuk mengkueri data menggunakan SQL, Power BI, atau Spark dikenakan tarif reguler.
Fabric tidak membebankan biaya masuk data jaringan ke OneLake untuk Mirroring.
Ada biaya komputasi Google BigQuery dan kueri cloud saat data dicerminkan: BigQuery Change Data Capture (CDC) memanfaatkan komputasi BigQuery untuk modifikasi baris, Storage Write API untuk penyerapan data, dan penyimpanan BigQuery untuk penyimpanan data yang semuanya menimbulkan biaya.
Untuk informasi selengkapnya tentang biaya untuk mencerminkan Google BigQuery, lihat penjelasan harga.