Mengintegrasikan OneLake dengan Azure Databricks
Skenario ini menunjukkan cara menyambungkan ke OneLake melalui Azure Databricks. Setelah menyelesaikan tutorial ini, Anda akan dapat membaca dan menulis ke Microsoft Fabric lakehouse dari ruang kerja Azure Databricks Anda.
Prasyarat
Sebelum tersambung, Anda harus memiliki:
- Ruang kerja Fabric dan lakehouse.
- Ruang kerja Azure Databricks premium. Hanya ruang kerja Azure Databricks premium yang mendukung passthrough kredensial Microsoft Entra, yang Anda butuhkan untuk skenario ini.
Menyiapkan ruang kerja Databricks Anda
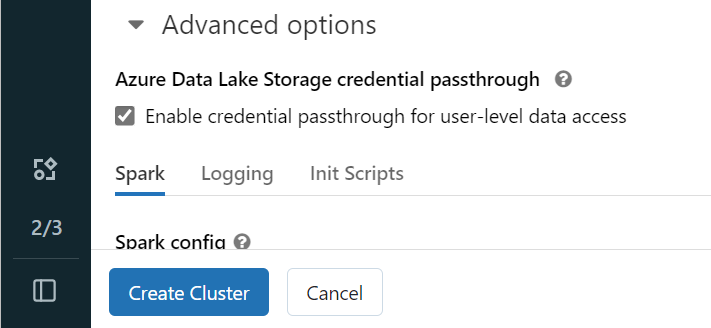
Buka ruang kerja Azure Databricks Anda dan pilih Buat>Kluster.
Untuk mengautentikasi ke OneLake dengan identitas Microsoft Entra, Anda harus mengaktifkan passthrough kredensial Azure Data Lake Storage (ADLS) pada kluster Anda di Opsi Tingkat Lanjut.
Catatan
Anda juga dapat menghubungkan Databricks ke OneLake menggunakan perwakilan layanan. Untuk informasi selengkapnya tentang mengautentikasi Azure Databricks menggunakan perwakilan layanan, lihat Mengelola perwakilan layanan.
Buat kluster dengan parameter pilihan Anda. Untuk informasi selengkapnya tentang membuat kluster Databricks, lihat Mengonfigurasi kluster - Azure Databricks.
Buka buku catatan dan sambungkan ke kluster yang baru dibuat.
Menulis buku catatan Anda
Navigasikan ke fabric lakehouse Anda dan salin jalur Azure Blob Filesystem (ABFS) ke lakehouse Anda. Anda bisa menemukannya di panel Properti .
Catatan
Azure Databricks hanya mendukung driver Azure Blob Filesystem (ABFS) saat membaca dan menulis ke ADLS Gen2 dan OneLake:
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/.Simpan jalur ke lakehouse Anda di buku catatan Databricks Anda. Lakehouse ini adalah tempat Anda menulis data yang diproses nanti:
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'Muat data dari himpunan data publik Databricks ke dalam dataframe. Anda juga dapat membaca file dari tempat lain di Fabric atau memilih file dari akun ADLS Gen2 lain yang sudah Anda miliki.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")Memfilter, mengubah, atau menyiapkan data Anda. Untuk skenario ini, Anda dapat memangkas himpunan data untuk pemuatan yang lebih cepat, bergabung dengan himpunan data lain, atau memfilter ke hasil tertentu.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)Tulis dataframe yang difilter ke fabric lakehouse Anda menggunakan jalur OneLake Anda.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)Uji bahwa data Anda berhasil ditulis dengan membaca file yang baru dimuat.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
Selamat. Anda sekarang dapat membaca dan menulis data di Fabric menggunakan Azure Databricks.