Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
oleh Ruslan Yakushev
Toolkit Pengoptimalan Mesin Pencari IIS menyertakan fitur Pengecualian Robot yang dapat Anda gunakan untuk mengelola konten file Robots.txt untuk situs Web Anda, dan menyertakan fitur Peta Situs dan Indeks Peta Situs yang dapat Anda gunakan untuk mengelola peta situs situs Anda. Panduan ini menjelaskan bagaimana dan mengapa menggunakan fitur-fitur ini.
Latar belakang
Perayap mesin pencari akan menghabiskan waktu dan sumber daya terbatas di situs Web Anda. Oleh karena itu, sangat penting untuk melakukan hal berikut:
- Cegah perayap mengindeks konten yang tidak penting atau yang tidak boleh muncul di halaman hasil pencarian.
- Arahkan perayap ke konten yang Anda anggap paling penting untuk pengindeksan.
Ada dua protokol yang umumnya digunakan untuk mencapai tugas-tugas ini: protokol Pengecualian Robot dan protokol Peta Situs.
Protokol Pengecualian Robot digunakan untuk memberi tahu perayap mesin pencari URL mana yang TIDAK boleh dimintanya saat merayapi situs Web. Instruksi pengecualian ditempatkan ke dalam file teks bernama Robots.txt, yang terletak di akar situs Web. Sebagian besar perayap mesin pencari biasanya mencari file ini dan mengikuti instruksi di dalamnya.
Protokol Peta Situs digunakan untuk menginformasikan perayap mesin pencari tentang URL yang tersedia untuk perayapan di situs Web Anda. Selain itu, Peta Situs digunakan untuk memberikan beberapa metadata tambahan tentang URL situs, seperti waktu modifikasi terakhir, frekuensi modifikasi, prioritas relatif, dll. Mesin pencari mungkin menggunakan metadata ini saat mengindeks situs Web Anda.
Prasyarat
1. Menyiapkan situs Web atau aplikasi
Untuk menyelesaikan panduan ini, Anda memerlukan situs Web yang dihosting IIS 7 atau lebih tinggi atau aplikasi Web yang Anda kontrol. Jika Anda tidak memilikinya, Anda dapat menginstalnya dari Galeri Aplikasi Web Microsoft. Untuk tujuan panduan ini, kami akan menggunakan aplikasi blogging populer DasBlog.
2. Menganalisis Situs Web
Setelah Anda memiliki situs Web atau aplikasi Web, Anda mungkin ingin menganalisisnya untuk memahami bagaimana mesin pencari umum akan merayapi kontennya. Untuk melakukan ini, ikuti langkah-langkah yang diuraikan dalam artikel "Menggunakan Analisis Situs untuk Merayapi Situs Web" dan "Menggunakan Laporan Analisis Situs". Ketika Anda melakukan analisis, Anda mungkin akan melihat bahwa Anda memiliki URL tertentu yang tersedia untuk dirayapi oleh mesin pencari, tetapi tidak ada manfaat nyata dalam membuatnya dirayapi atau diindeks. Misalnya, halaman login atau halaman sumber daya bahkan tidak boleh diminta oleh perayap mesin pencari. URL seperti ini harus disembunyikan dari mesin pencari dengan menambahkannya ke file Robots.txt.
Mengelola File Robots.txt
Anda dapat menggunakan fitur Pengecualian Robot dari Toolkit SEO IIS untuk menulis file Robots.txt yang memberi tahu mesin pencari bagian mana dari situs Web yang tidak boleh dirayapi atau diindeks. Langkah-langkah berikut menjelaskan cara menggunakan alat ini.
- Buka Konsol Manajemen IIS dengan mengetik INETMGR di menu Mulai.
- Navigasi ke situs Web Anda dengan menggunakan tampilan pohon di sisi kiri (misalnya, Situs Web Default).
- Klik ikon Pengoptimalan Mesin Pencari di dalam bagian Manajemen:
- Pada halaman utama SEO, klik tautan tugas "Tambahkan aturan larang baru" dalam bagian Pengecualian Robot.
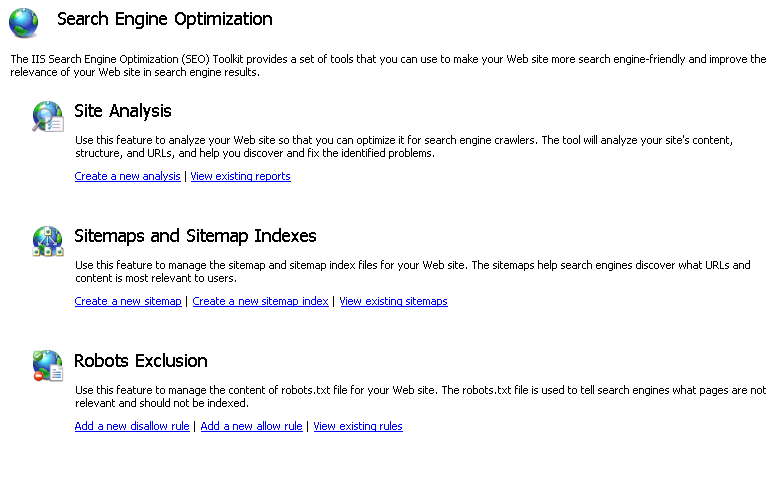
Menambahkan Melarang dan Mengizinkan Aturan
Dialog "Tambahkan Aturan Tidak Diizinkan" akan terbuka secara otomatis:
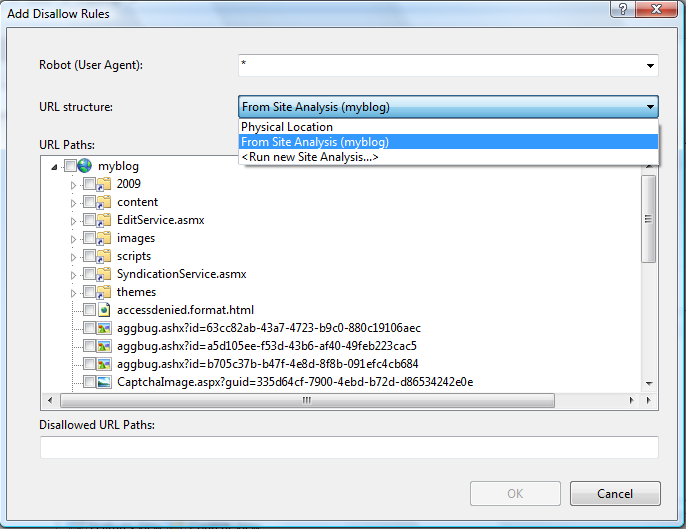
Protokol Pengecualian Robot menggunakan direktif "Izinkan" dan "Larang" untuk memberi tahu mesin pencari tentang jalur URL yang dapat dirayapi dan yang tidak dapat. Arahan ini dapat ditentukan untuk semua mesin pencari atau untuk agen pengguna tertentu yang diidentifikasi oleh header HTTP agen pengguna. Dalam dialog "Tambahkan Aturan Larang" Anda dapat menentukan perayap mesin pencari mana yang diterapkan direktif dengan memasukkan agen pengguna perayap ke bidang "Robot (Agen Pengguna)".
Tampilan pohon Jalur URL digunakan untuk memilih URL mana yang harus dilarang. Anda dapat memilih dari beberapa opsi saat memilih jalur URL dengan menggunakan daftar drop-down "Struktur URL":
- Lokasi Fisik - Anda dapat memilih jalur dari tata letak sistem file fisik situs Web Anda.
- Dari Analisis Situs (nama analisis) - Anda dapat memilih jalur dari struktur URL virtual yang ditemukan ketika situs dianalisis dengan alat Analisis Situs IIS.
- <Jalankan Analisis Situs baru...> - Anda dapat menjalankan analisis situs baru untuk mendapatkan struktur URL virtual untuk situs Web Anda, lalu memilih jalur URL dari sana.
Setelah menyelesaikan langkah-langkah yang dijelaskan di bagian prasyarat, Anda akan memiliki analisis situs yang tersedia. Pilih analisis di daftar drop-down lalu periksa URL yang perlu disembunyikan dari mesin pencari dengan menggunakan kotak centang dalam tampilan pohon "Jalur URL":
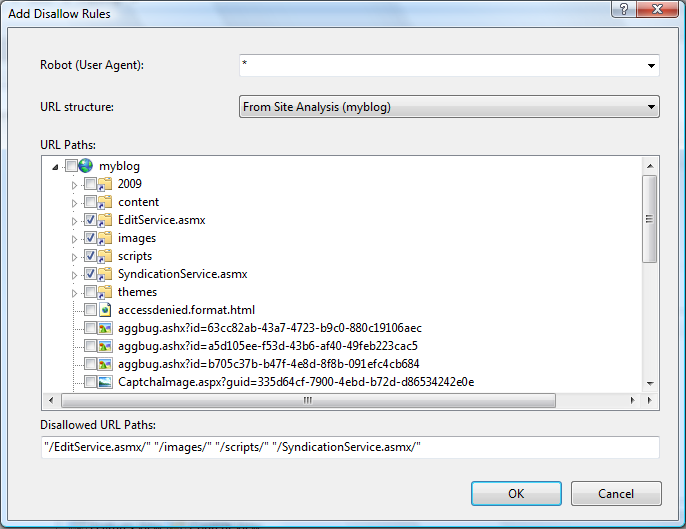
Setelah memilih semua direktori dan file yang perlu dilarang, klik OK. Anda akan melihat entri larang baru dalam tampilan fitur utama:
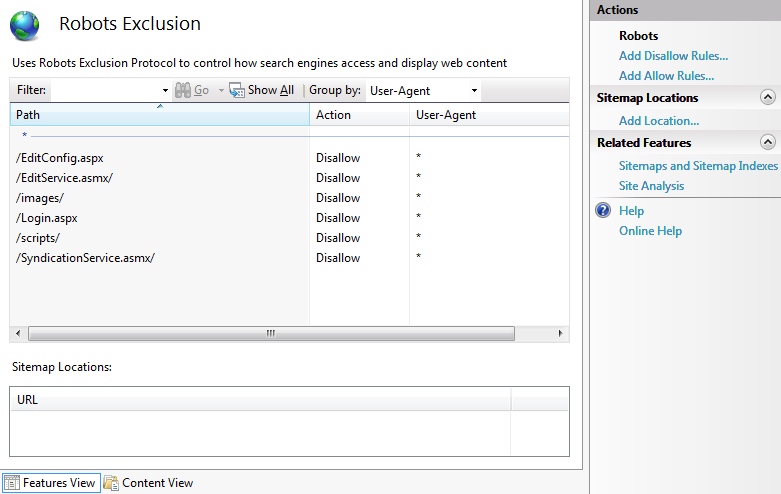
Selain itu, file Robots.txt untuk situs akan diperbarui (atau dibuat jika tidak ada). Kontennya akan terlihat mirip dengan ini:
User-agent: *
Disallow: /EditConfig.aspx
Disallow: /EditService.asmx/
Disallow: /images/
Disallow: /Login.aspx
Disallow: /scripts/
Disallow: /SyndicationService.asmx/
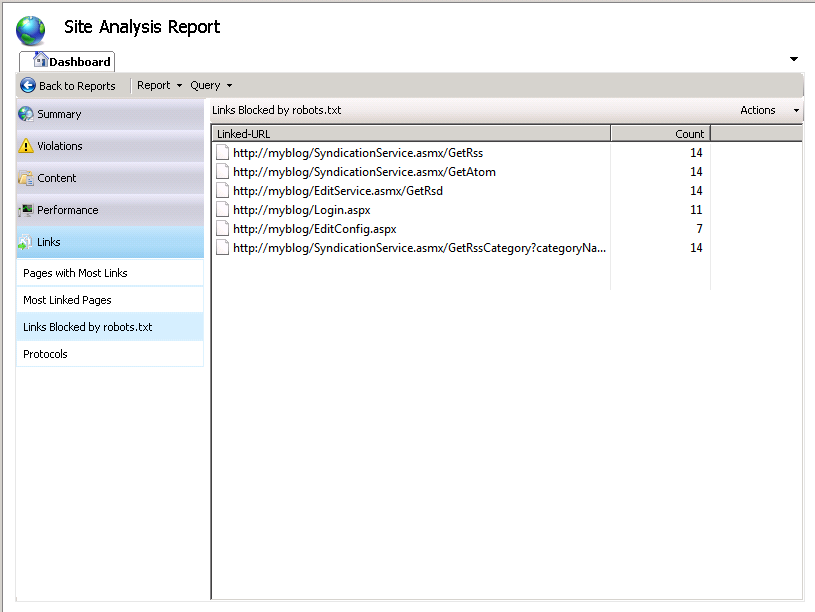
Untuk melihat cara kerja Robots.txt, kembali ke fitur Analisis Situs dan jalankan kembali analisis untuk situs tersebut. Pada halaman Ringkasan Laporan, dalam kategori Tautan , pilih Tautan Diblokir oleh Robots.txt. Laporan ini akan menampilkan semua tautan yang belum dirayapi karena tidak diizinkan oleh file Robots.txt yang baru saja Anda buat.
Mengelola File Peta Situs
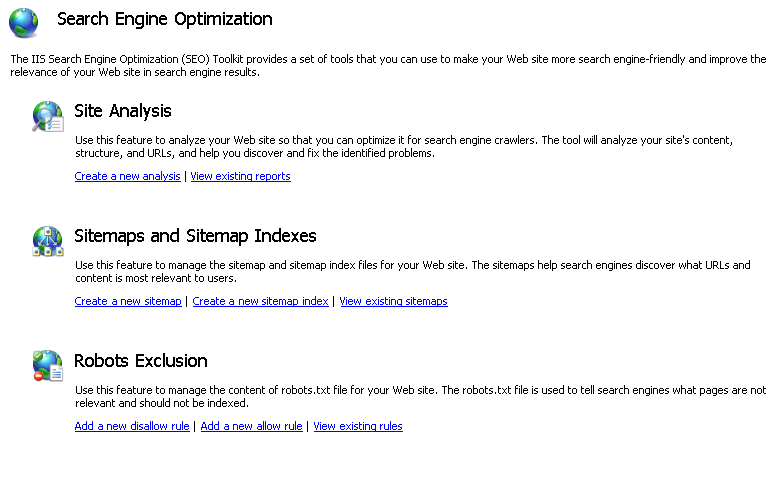
Anda dapat menggunakan fitur Peta Situs dan Indeks Peta Situs dari Toolkit SEO IIS untuk menulis peta situs di situs Web Anda untuk menginformasikan mesin pencari halaman yang harus dirayapi dan diindeks. Untuk melakukan ini, ikuti langkah-langkah berikut:
- Buka Manajer IIS dengan mengetik INETMGR di menu Mulai .
- Navigasi ke situs Web Anda dengan menggunakan tampilan pohon di sebelah kiri.
- Klik ikon Pengoptimalan Mesin Pencari di dalam bagian Manajemen:
- Pada halaman utama SEO, klik tautan tugas "Buat peta situs baru" di dalam bagian Peta Situs dan Indeks Peta Situs.
- Dialog Tambahkan Peta Situs akan terbuka secara otomatis.
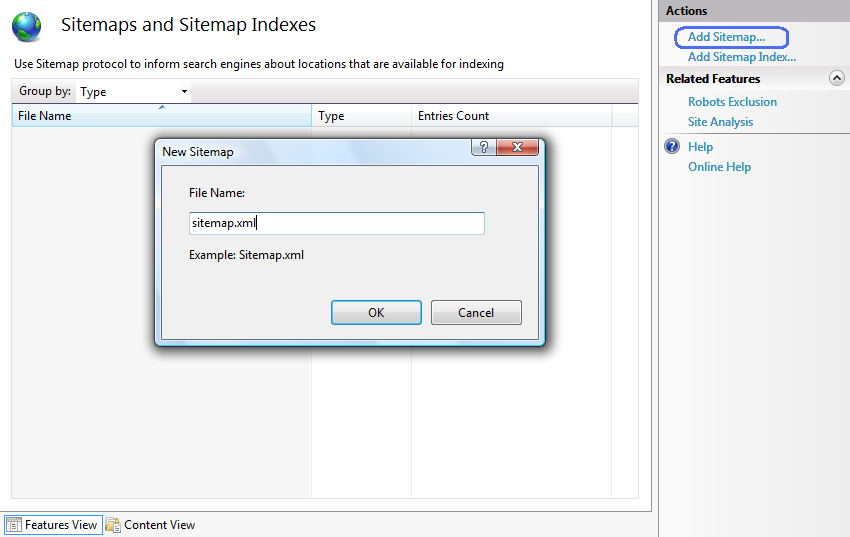
- Ketik nama untuk file peta situs Anda dan klik OK. Dialog Tambahkan URL muncul.
Menambahkan URL ke peta situs
Dialog Tambahkan URL terlihat seperti ini:
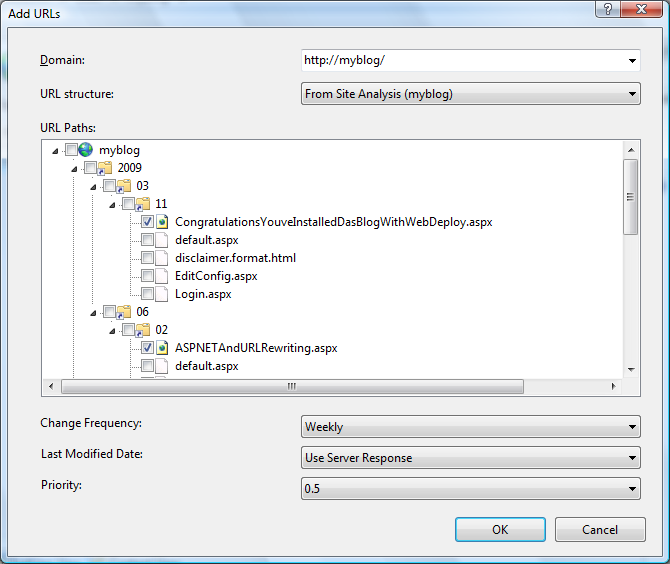
File Peta Situs pada dasarnya adalah file XML sederhana yang mencantumkan URL bersama dengan beberapa metadata, seperti frekuensi perubahan, tanggal terakhir diubah, dan prioritas relatif. Anda menggunakan dialog Tambahkan URL untuk menambahkan entri URL baru ke file xml Peta Situs. Setiap URL dalam peta situs harus dalam format URI yang sepenuhnya memenuhi syarat (yaitu harus menyertakan awalan protokol dan nama domain). Jadi, hal pertama yang harus Anda tentukan adalah domain yang akan digunakan untuk URL yang akan Anda tambahkan ke peta situs.
Tampilan pohon Jalur URL digunakan untuk memilih URL mana yang harus ditambahkan ke peta situs untuk pengindeksan. Anda dapat memilih dari beberapa opsi dengan menggunakan daftar drop-down "Struktur URL":
- Lokasi Fisik - Anda dapat memilih URL dari tata letak sistem file fisik situs Web Anda.
- Dari Analisis Situs (nama analisis) - Anda dapat memilih URL dari struktur URL virtual yang ditemukan ketika situs dianalisis dengan alat Analisis Situs.
- <Jalankan Analisis Situs baru...> - Anda dapat menjalankan analisis situs baru untuk mendapatkan struktur URL virtual untuk situs Web Anda, lalu memilih jalur URL dari sana yang ingin Anda tambahkan untuk pengindeksan.
Setelah Anda menyelesaikan langkah-langkah di bagian prasyarat, Anda akan memiliki analisis situs yang tersedia. Pilih dari daftar drop-down, lalu periksa URL yang perlu ditambahkan ke peta situs.
Jika perlu, ubah opsi Ubah Frekuensi, Tanggal Terakhir Diubah, dan Prioritas , lalu klik OK untuk menambahkan URL ke peta situs. File sitemap.xml akan diperbarui (atau dibuat jika tidak ada), dan kontennya akan terlihat seperti berikut ini:
<urlset>
<url>
<loc>http://myblog/2009/03/11/CongratulationsYouveInstalledDasBlogWithWebDeploy.aspx</loc>
<lastmod>2009-06-03T16:05:02</lastmod>
<changefreq>weekly</changefreq>
<priority>0.5</priority>
</url>
<url>
<loc>http://myblog/2009/06/02/ASPNETAndURLRewriting.aspx</loc>
<lastmod>2009-06-03T16:05:01</lastmod>
<changefreq>weekly</changefreq>
<priority>0.5</priority>
</url>
</urlset>
Menambahkan lokasi peta situs ke file Robots.txt
Sekarang setelah Anda membuat peta situs, Anda harus memberi tahu mesin pencari di mana lokasinya sehingga mereka dapat mulai menggunakannya. Cara paling sederhana untuk melakukan ini adalah dengan menambahkan URL lokasi peta situs ke file Robots.txt.
Di fitur Peta Situs dan Indeks Peta Situs, pilih peta situs yang baru saja Anda buat, lalu klik Tambahkan ke Robots.txt di panel Tindakan :
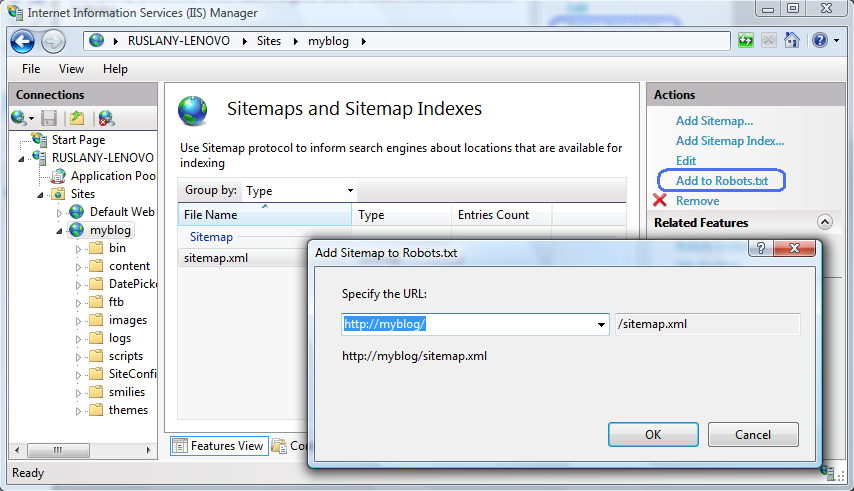
File Robots.txt Anda akan terlihat mirip dengan yang berikut ini:
User-agent: *
Disallow: /EditService.asmx/
Disallow: /images/
Disallow: /scripts/
Disallow: /SyndicationService.asmx/
Disallow: /EditConfig.aspx
Disallow: /Login.aspx
Sitemap: http://myblog/sitemap.xml
Mendaftarkan peta situs dengan mesin pencari
Selain menambahkan lokasi peta situs ke file Robots.txt, disarankan agar Anda mengirimkan URL lokasi peta situs Anda ke mesin pencari utama. Ini akan memungkinkan Anda untuk mendapatkan status dan statistik yang berguna tentang situs Web Anda dari alat webmaster mesin pencari.
- Untuk mengirimkan peta situs ke bing.com, gunakan Bing Webmasters Tools
- Untuk mengirimkan peta situs ke google.com, gunakan Google Webmasters Tools
Ringkasan
Dalam panduan ini, Anda telah mempelajari cara menggunakan fitur Pengecualian Robot dan Peta Situs dan Indeks Peta Situs dari Toolkit Pengoptimalan Mesin Pencari IIS untuk mengelola file Robots.txt dan peta situs di situs Web Anda. Toolkit Pengoptimalan Mesin Pencari IIS menyediakan serangkaian alat terintegrasi yang bekerja sama untuk membantu Anda menulis dan memvalidasi kebenaran file Robots.txt dan peta situs sebelum mesin pencari mulai menggunakannya.