Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk: ✅Microsoft Fabric✅Azure Data Explorer
Fungsi series_mv_if_anomalies_fl() ini adalah fungsi yang ditentukan pengguna (UDF) yang mendeteksi anomali multivariat dalam seri dengan menerapkan model forest isolasi dari scikit-learn. Fungsi menerima serangkaian seri sebagai array dinamis numerik, nama kolom fitur, dan persentase anomali yang diharapkan dari seluruh seri. Fungsi ini membangun ansambel pohon isolasi untuk setiap seri dan menandai titik yang dengan cepat diisolasi sebagai anomali.
Prasyarat
- Plugin Python harus diaktifkan pada kluster. Ini diperlukan untuk Python sebaris yang digunakan dalam fungsi.
- Plugin Python harus diaktifkan pada database. Ini diperlukan untuk Python sebaris yang digunakan dalam fungsi.
Sintaks
T | invoke series_mv_if_anomalies_fl(features_cols anomaly_col [ , score_col [, anomalies_pct [, num_trees , samples_pct ], )
Pelajari selengkapnya tentang konvensi sintaksis.
Parameter
| Nama | Tipe | Wajib | Deskripsi |
|---|---|---|---|
| features_cols | dynamic |
✔️ | Array yang berisi nama kolom yang digunakan untuk model deteksi anomali multivariat. |
| anomaly_col | string |
✔️ | Nama kolom untuk menyimpan anomali yang terdeteksi. |
| score_col | string |
Nama kolom untuk menyimpan skor anomali. | |
| anomalies_pct | real |
Angka riil dalam rentang [0-50] yang menentukan persentase anomali yang diharapkan dalam data. Nilai default: 4%. | |
| num_trees | int |
Jumlah pohon isolasi yang akan dibangun untuk setiap rangkaian waktu. Nilai default: 100. | |
| samples_pct | real |
Angka riil dalam rentang [0-100] yang menentukan persentase sampel yang digunakan untuk membangun setiap pohon. Nilai default: 100%, yaitu gunakan seri lengkap. |
Definisi fungsi
Anda dapat menentukan fungsi dengan menyematkan kodenya sebagai fungsi yang ditentukan kueri, atau membuatnya sebagai fungsi tersimpan dalam database Anda, sebagai berikut:
Tentukan fungsi menggunakan pernyataan let berikut. Tidak ada izin yang diperlukan.
Penting
Pernyataan let tidak dapat berjalan sendiri. Ini harus diikuti oleh pernyataan ekspresi tabular. Untuk menjalankan contoh series_mv_if_anomalies_fl()kerja , lihat Contoh.
// Define function
let series_mv_if_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0, num_trees:int=100, samples_pct:real=100.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct, 'num_trees', num_trees, 'samples_pct', samples_pct);
let code = ```if 1:
from sklearn.ensemble import IsolationForest
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
num_trees = kargs['num_trees']
samples_pct = kargs['samples_pct']
dff = df[features_cols]
iforest = IsolationForest(contamination=anomalies_pct/100.0, random_state=0, n_estimators=num_trees, max_samples=samples_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
iforest.fit(dffe)
df.loc[i, anomaly_col] = (iforest.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = iforest.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Write your query to use the function here.
Contoh
Contoh berikut menggunakan operator pemanggilan untuk menjalankan fungsi.
Untuk menggunakan fungsi yang ditentukan kueri, panggil setelah definisi fungsi yang disematkan.
// Define function
let series_mv_if_anomalies_fl=(tbl:(*), features_cols:dynamic, anomaly_col:string, score_col:string='', anomalies_pct:real=4.0, num_trees:int=100, samples_pct:real=100.0)
{
let kwargs = bag_pack('features_cols', features_cols, 'anomaly_col', anomaly_col, 'score_col', score_col, 'anomalies_pct', anomalies_pct, 'num_trees', num_trees, 'samples_pct', samples_pct);
let code = ```if 1:
from sklearn.ensemble import IsolationForest
features_cols = kargs['features_cols']
anomaly_col = kargs['anomaly_col']
score_col = kargs['score_col']
anomalies_pct = kargs['anomalies_pct']
num_trees = kargs['num_trees']
samples_pct = kargs['samples_pct']
dff = df[features_cols]
iforest = IsolationForest(contamination=anomalies_pct/100.0, random_state=0, n_estimators=num_trees, max_samples=samples_pct/100.0)
for i in range(len(dff)):
dffi = dff.iloc[[i], :]
dffe = dffi.explode(features_cols)
iforest.fit(dffe)
df.loc[i, anomaly_col] = (iforest.predict(dffe) < 0).astype(int).tolist()
if score_col != '':
df.loc[i, score_col] = iforest.decision_function(dffe).tolist()
result = df
```;
tbl
| evaluate hint.distribution=per_node python(typeof(*), code, kwargs)
};
// Usage
normal_2d_with_anomalies
| extend anomalies=dynamic(null), scores=dynamic(null)
| invoke series_mv_if_anomalies_fl(pack_array('x', 'y'), 'anomalies', 'scores', anomalies_pct=8, num_trees=1000)
| extend anomalies=series_multiply(40, anomalies)
| render timechart
Hasil
Tabel normal_2d_with_anomalies berisi satu set 3 rangkaian waktu. Setiap rangkaian waktu memiliki distribusi normal dua dimensi dengan anomali harian yang ditambahkan masing-masing pada tengah malam, pukul 08.00, dan 16.00. Anda dapat membuat himpunan data sampel ini menggunakan contoh kueri.
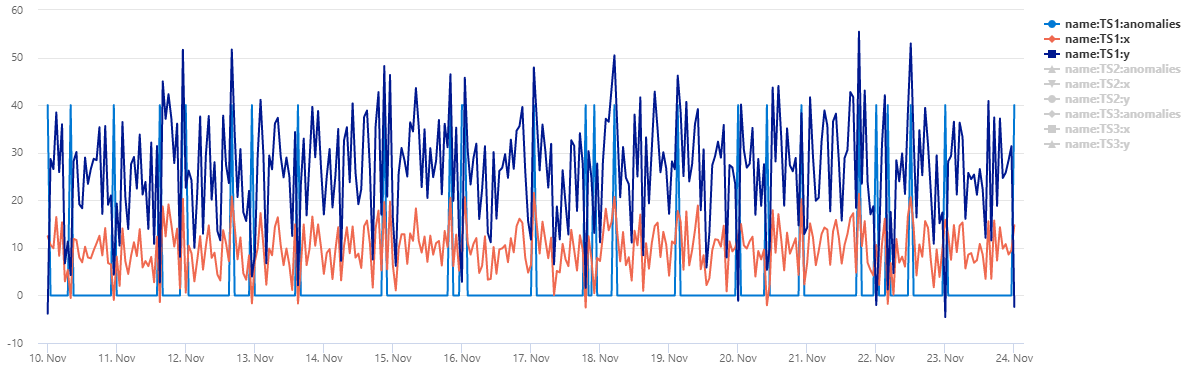
Untuk melihat data sebagai bagan sebar, ganti kode penggunaan dengan yang berikut ini:
normal_2d_with_anomalies
| extend anomalies=dynamic(null)
| invoke series_mv_if_anomalies_fl(pack_array('x', 'y'), 'anomalies')
| where name == 'TS1'
| project x, y, anomalies
| mv-expand x to typeof(real), y to typeof(real), anomalies to typeof(string)
| render scatterchart with(series=anomalies)
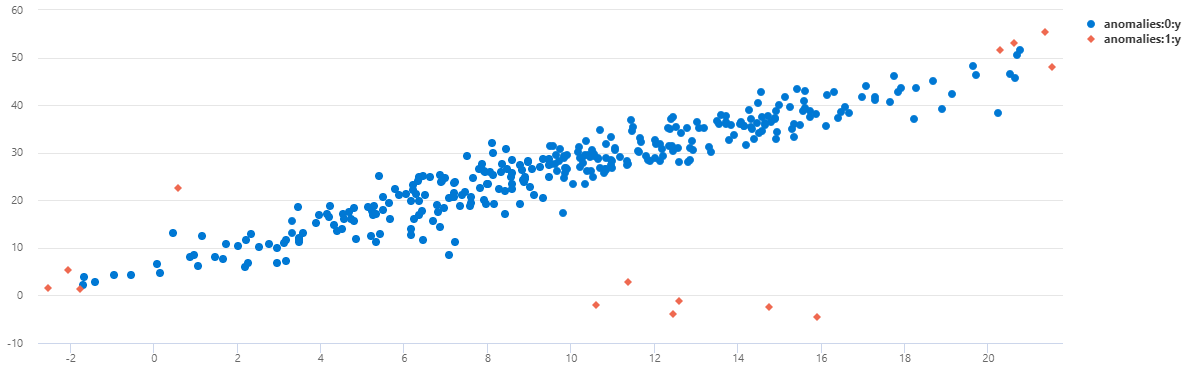
Anda dapat melihat bahwa pada TS2 sebagian besar anomali yang terjadi pada pukul 08.00 terdeteksi menggunakan model multivariat ini.