hll() (fungsi agregasi)
Berlaku untuk: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Fungsi ini hll() adalah cara untuk memperkirakan jumlah nilai unik dalam sekumpulan nilai. Ini dilakukan dengan menghitung hasil perantara untuk agregasi dalam operator ringkasan untuk sekelompok data menggunakan dcount fungsi .
Baca tentang algoritma yang mendasari (HyperLogLog) dan akurasi estimasi.
Catatan
Fungsi ini digunakan bersama dengan ringkasan operator.
Tip
- Gunakan fungsi hll_merge untuk menggabungkan hasil beberapa
hll()fungsi. - Gunakan fungsi dcount_hll untuk menghitung jumlah nilai yang berbeda dari
hll()output fungsi atauhll_merge.
Penting
Hasil hll(), hll_if(), dan hll_merge() dapat disimpan dan kemudian diambil. Misalnya, Anda mungkin ingin membuat ringkasan pengguna unik harian, yang kemudian dapat digunakan untuk menghitung jumlah mingguan. Namun, representasi biner yang tepat dari hasil ini dapat berubah dari waktu ke waktu. Tidak ada jaminan bahwa fungsi-fungsi ini akan menghasilkan hasil yang identik untuk input yang identik, dan oleh karena itu kami tidak menyarankan untuk mengandalkannya.
Sintaks
hll(expr [, akurasi])
Pelajari selengkapnya tentang konvensi sintaksis.
Parameter
| Nama | Tipe | Wajib | Deskripsi |
|---|---|---|---|
| expr | string |
✔️ | Ekspresi yang digunakan untuk perhitungan agregasi. |
| ketepatan | int |
Nilai yang mengontrol keseimbangan antara kecepatan dan akurasi. Jika tidak ditentukan, nilai defaultnya adalah 1. Untuk nilai yang didukung, lihat Akurasi estimasi. |
Mengembalikan
Mengembalikan hasil perantara dari jumlah kedaluwarsa yang berbeda di seluruh grup.
Contoh
Dalam contoh berikut, hll() fungsi digunakan untuk memperkirakan jumlah nilai DamageProperty unik kolom dalam setiap bin waktu 10 menit kolom StartTime .
StormEvents
| summarize hll(DamageProperty) by bin(StartTime,10m)
Tabel hasil yang ditampilkan hanya menyertakan 10 baris pertama.
| StartTime | hll_DamageProperty |
|---|---|
| 2007-01-01T00:20:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T01:00:00Z | [[1024,14],["7755241107725382121","-5665157283053373866","3803688792395291579","-1003235211361077779"],[]] |
| 2007-01-01T02:00:00Z | [[1024,14],["-1003235211361077779","-5665157283053373866","7755241107725382121"],[]] |
| 2007-01-01T02:20:00Z | [[1024,14],["7755241107725382121"],[]] |
| 2007-01-01T03:30:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T03:40:00Z | [[1024,14],["-5665157283053373866"],[]] |
| 2007-01-01T04:30:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T05:30:00Z | [[1024,14],["3803688792395291579"],[]] |
| 2007-01-01T06:30:00Z | [[1024,14],["1589522558235929902"],[]] |
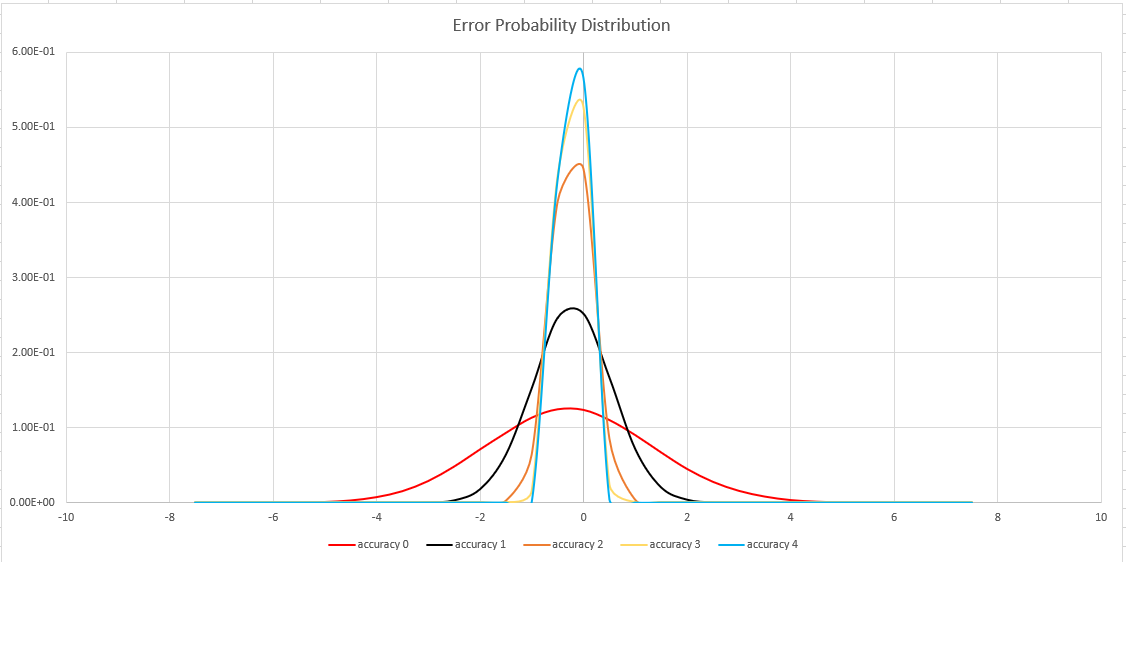
Akurasi estimasi
Fungsi ini menggunakan varian dari algoritma HyperLogLog (HLL), yang melakukan estimasi stokastik dari kardinalitas yang ditetapkan. Algoritma ini menyediakan "kenop" yang dapat digunakan untuk menyeimbangkan akurasi dan waktu eksekusi per ukuran memori:
| Akurasi | Kesalahan (%) | Jumlah entri |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0,8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0.28 | 217 |
| 4 | 0,2 | 218 |
Catatan
Kolom "jumlah entri" adalah jumlah penghitung 1 byte dalam implementasi HLL.
Algoritma ini mencakup beberapa ketentuan untuk melakukan penghitungan sempurna (zero error), jika kardinalitas set berukuran cukup kecil:
- Ketika tingkat akurasi adalah
1, 1000 nilai dikembalikan - Ketika tingkat akurasi adalah
2, 8000 nilai dikembalikan
Batas kesalahan bersifat probabilistik, bukan batas teoritis. Nilainya adalah simpangan baku dari distribusi kesalahan (sigma), dan 99,7% estimasi akan memiliki kesalahan relatif di bawah 3 x sigma.
Gambar berikut menunjukkan fungsi distribusi peluang dari kesalahan estimasi relatif, dalam persentase, untuk semua pengaturan akurasi yang didukung: