Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pengenalan karakter optik (OCR) memungkinkan Anda menemukan dan mengekstrak teks dari gambar atau layar.
Meskipun sebagian besar skenario mengharuskan Anda menangani teks dalam bahasa tertentu, ada beberapa kasus di mana sumbernya multibahasa.
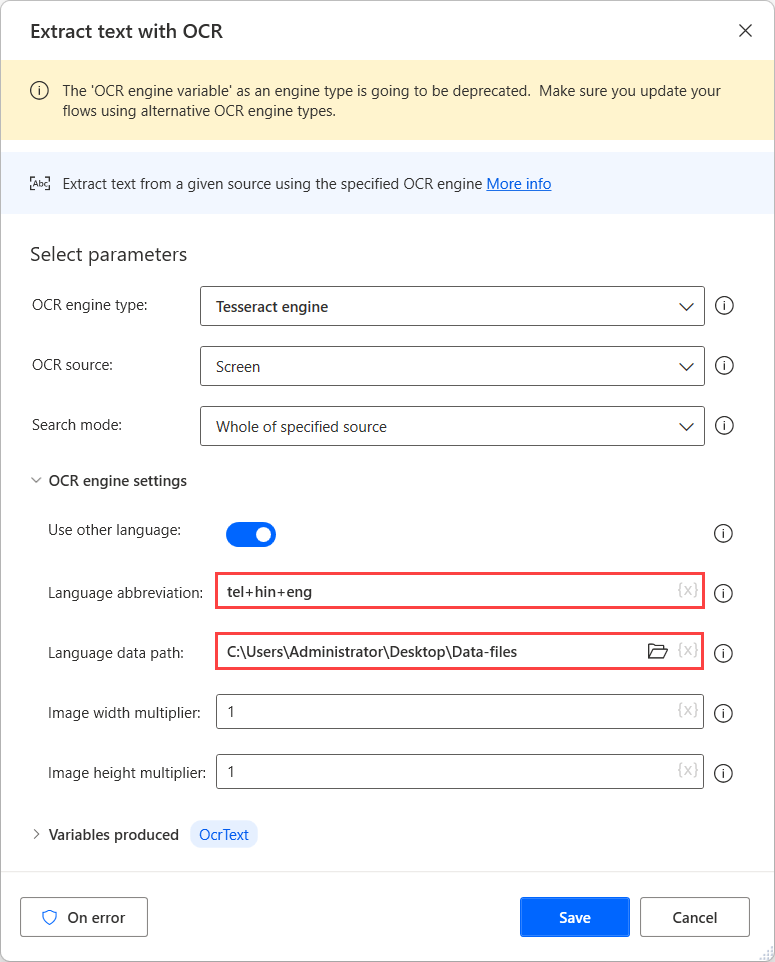
Untuk melakukan OCR pada sumber-sumber ini, gunakan mesin Tesseract dalam tindakan OCR masing-masing dan aktifkan opsi Gunakan bahasa lain di pengaturan mesin.
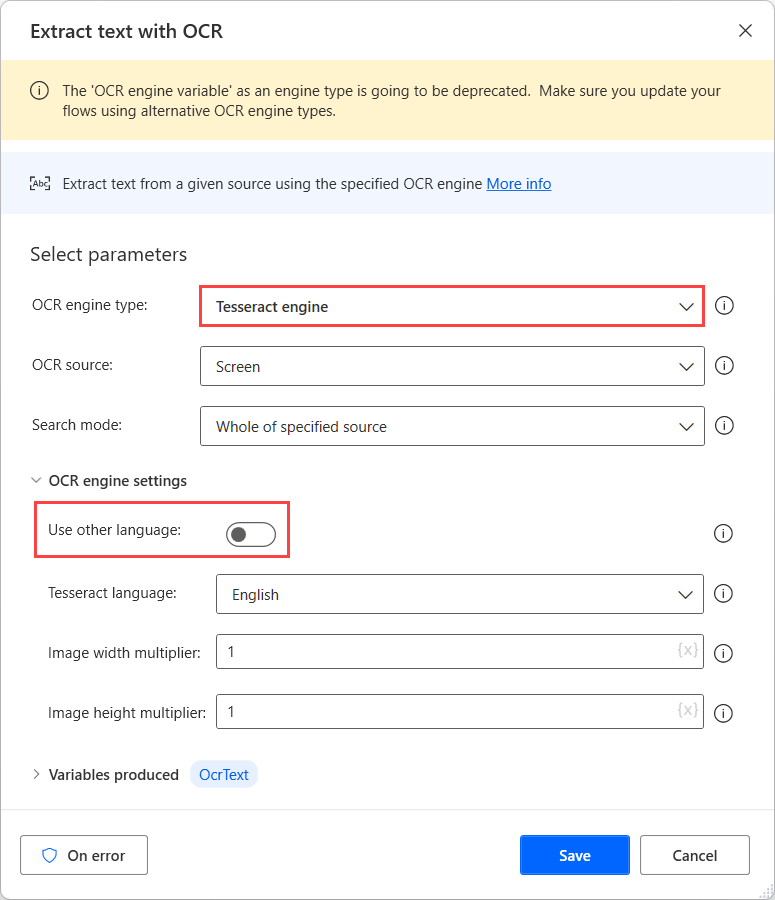
Saat opsi Gunakan bahasa lain diaktifkan, tindakan menampilkan dua pengaturan tambahan: singkatan Bahasa dan bidang jalur data Bahasa.
Bidang singkatan Bahasa menunjukkan ke mesin bahasa mana yang harus dicari selama OCR. Bidang Jalur data bahasa berisi file data bahasa (.traineddata) yang digunakan untuk melatih mesin OCR.
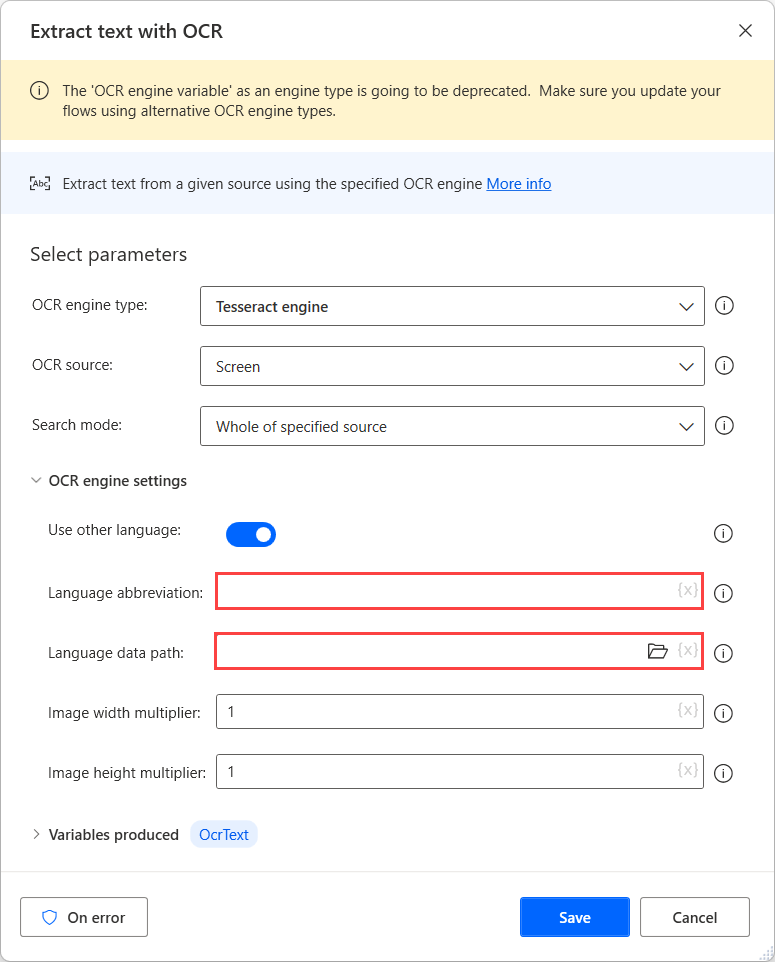
Setelah mengunduh file data untuk bahasa yang diperlukan, pindahkan ke folder umum untuk membuatnya tersedia di bawah jalur yang sama.
Selanjutnya, pilih folder yang dibuat di bidang Jalur data bahasa, dan isi kode bahasa yang sesuai di bidang Singkatan bahasa. Untuk memisahkan kode bahasa, gunakan karakter plus (+).
Catatan
Anda dapat menemukan semua kode bahasa yang tersedia di sumber file data bahasa. Dalam contoh berikut, kode yang digunakan mewakili Telugu, Hindi, dan Inggris.