Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Agregasi di Power BI dapat meningkatkan performa kueri melalui model semantik DirectQuery besar. Dengan menggunakan agregasi, Anda menyimpan data di tingkat agregat dalam memori. Anda bisa mengonfigurasi agregasi secara manual di Power BI dalam model data, seperti yang dijelaskan dalam artikel ini. Untuk langganan Premium, Anda dapat mengaktifkan fitur Agregasi otomatis di Pengaturan model untuk membuatnya secara otomatis.
Membuat tabel agregasi
Bergantung pada jenis sumber data, Anda bisa membuat tabel agregasi di sumber data sebagai tabel, tampilan, atau kueri asli. Untuk performa terbesar, buat tabel agregasi sebagai tabel impor yang dibuat di Power Query. Gunakan dialog Kelola agregasi di Power BI Desktop untuk menentukan agregasi untuk kolom agregasi dengan ringkasan, tabel detail, dan properti kolom detail.
Sumber data dimensi, seperti gudang data dan mart data, dapat menggunakan agregasi berbasis hubungan. Sumber data besar berbasis Hadoop sering kali mendasarkan agregasi pada kolom GroupBy. Artikel ini menjelaskan perbedaan pemodelan data Power BI umum untuk setiap jenis sumber data.
Mengelola agregasi
Di panel Data dari tampilan Power BI Desktop apa pun, klik kanan tabel agregasi, lalu pilih Kelola agregasi.
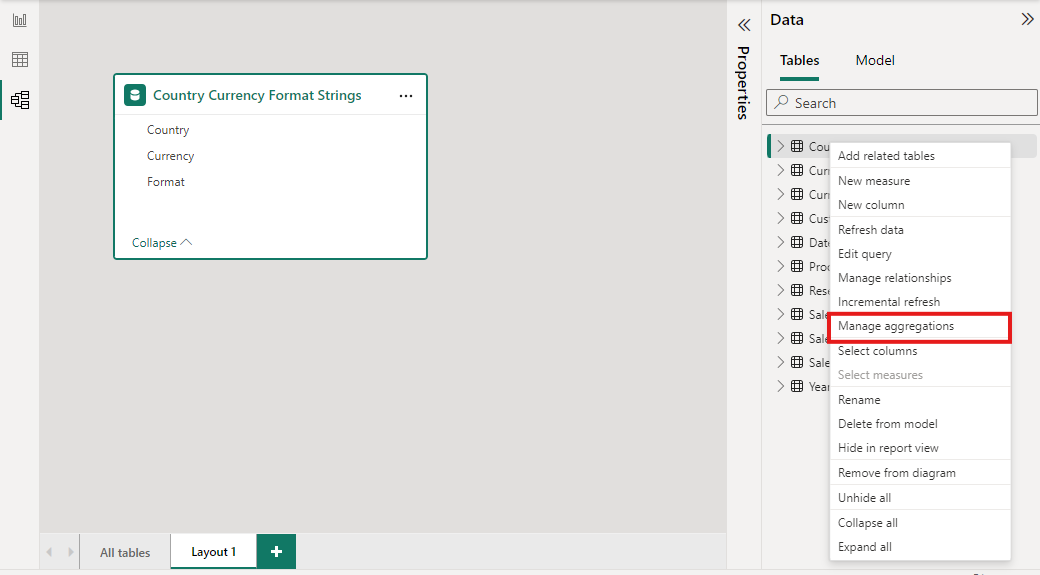
Dialog Kelola agregasi memperlihatkan baris untuk setiap kolom dalam tabel, di mana Anda bisa menentukan perilaku agregasi. Dalam contoh berikut, kueri ke tabel detail Penjualan dialihkan secara internal ke tabel agregasi Sales Agg.
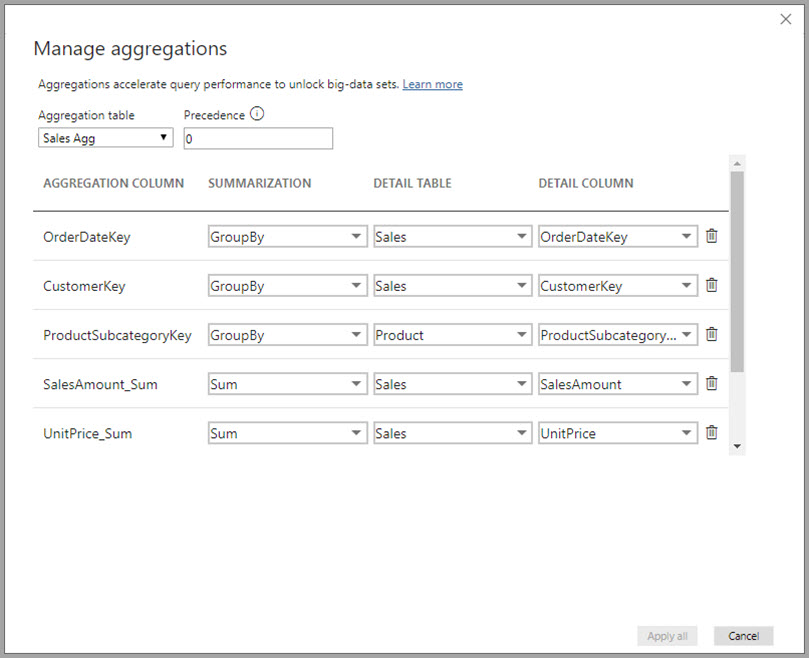
Dalam contoh agregasi berbasis hubungan ini, entri GroupBy bersifat opsional. Kecuali untuk DISTINCTCOUNT, mereka tidak memengaruhi perilaku agregasi dan terutama untuk keterbacaan. Tanpa entri GroupBy, agregasi tetap diproses, berdasarkan hubungan. Perilaku ini berbeda dari contoh big data nanti di artikel ini, di mana entri GroupBy diperlukan.
Validasi
Dialog Kelola agregasi memberlakukan validasi:
- Kolom Detail harus memiliki tipe data yang sama dengan Kolom Agregasi, kecuali untuk fungsi Ringkasan pada baris tabel Count dan Count. Hitung dan Hitung baris tabel hanya tersedia untuk kolom agregasi bilangan bulat, dan tidak memerlukan tipe data yang cocok.
- Agregasi berantai yang mencakup tiga tabel atau lebih tidak diizinkan. Misalnya, agregasi pada Tabel A tidak dapat merujuk ke Tabel B yang memiliki agregasi yang mengacu pada Tabel C.
- Agregasi duplikat, di mana dua entri menggunakan fungsi Ringkasan yang sama dan merujuk ke Tabel Detail dan Kolom Detail yang sama, tidak diizinkan.
- Tabel Detail harus menggunakan mode penyimpanan DirectQuery, bukan Impor.
- Pengelompokan menurut kolom kunci asing yang digunakan oleh hubungan yang tidak aktif, dan mengandalkan fungsi USERELATIONSHIP untuk temuan agregasi, tidak didukung. Sebagai alternatif, Anda dapat menggunakan fungsi TREATAS alih-alih USERELATIONSHIP. Saat menggunakan TREATAS, pastikan tidak ada hubungan aktif antara tabel. Agregat masih dapat terpengaruh saat menggunakan TREATAS dengan konfigurasi ini.
- Agregasi berdasarkan kolom GroupBy dapat menggunakan hubungan antara tabel agregasi tetapi hubungan penulisan antar tabel agregasi tidak didukung di Power BI Desktop. Jika perlu, Anda dapat membuat hubungan antara tabel agregasi dengan menggunakan alat pihak ketiga atau solusi pembuatan skrip melalui titik akhir XML untuk Analisis (XMLA).
Sebagian besar validasi diberlakukan dengan menonaktifkan nilai dalam menu tarik-turun dan menampilkan teks penjelasan di tooltip.
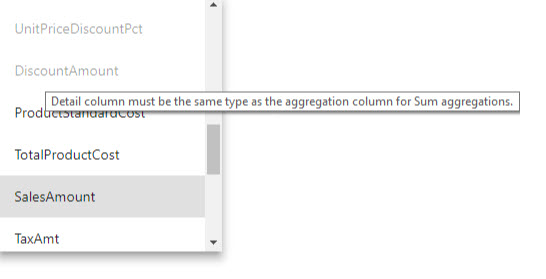
Tabel agregasi disembunyikan
Pengguna dengan akses baca-saja ke model tidak dapat mengkueri tabel agregasi. Akses baca-saja menghindari masalah keamanan ketika digunakan dengan keamanan tingkat baris (RLS). Konsumen dan kueri merujuk ke tabel detail, bukan tabel agregasi, dan tidak perlu tahu tentang tabel agregasi.
Untuk alasan ini, tabel agregasi disembunyikan dari tampilan Laporan . Jika tabel belum disembunyikan, dialog Kelola agregasi mengaturnya ke tersembunyi saat Anda memilih Terapkan semua.
Mode penyimpanan
Fitur agregasi berfungsi dengan mode penyimpanan tingkat tabel. Tabel Power BI dapat menggunakan mode penyimpanan DirectQuery, Impor, atau Dual. DirectQuery mengirim kueri langsung ke backend, sementara import mencache data dalam memori dan mengirim kueri ke data yang sudah di-cache. Semua sumber data Impor Power BI dan DirectQuery non-multidimensional berfungsi dengan agregasi.
Untuk mengatur mode penyimpanan tabel agregat ke Impor untuk mempercepat kueri, pilih tabel agregat dalam tampilan Model Desktop Power BI. Di panel Properti , perluas Tingkat Lanjut, turun bawah pilihan di bawah Mode penyimpanan, dan pilih Impor. Setelah mengatur mode penyimpanan ke Impor, Anda tidak dapat mengubahnya lagi.
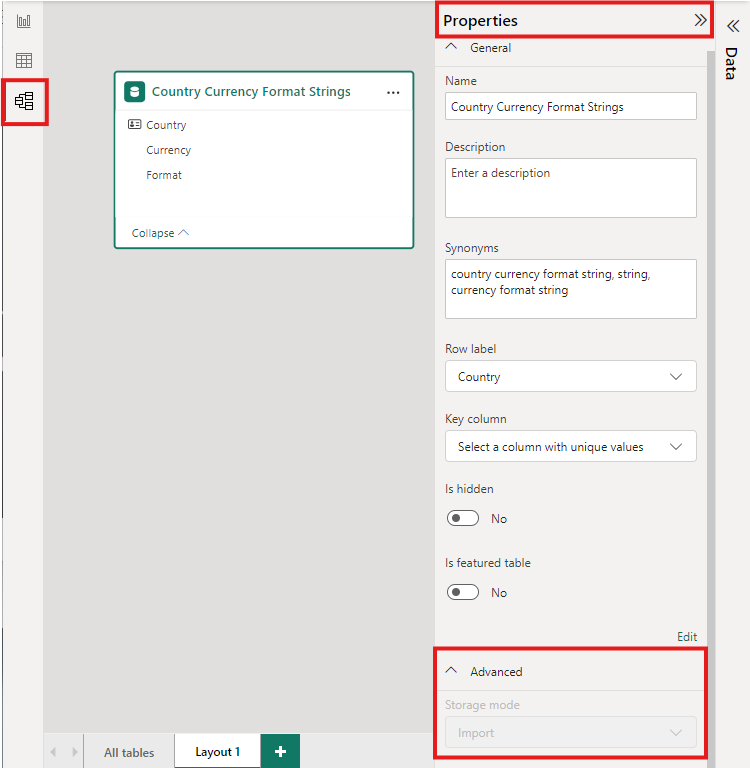
Untuk informasi selengkapnya tentang mode penyimpanan tabel, lihat Mengelola mode penyimpanan di Power BI Desktop.
RLS untuk agregasi
Untuk bekerja dengan benar untuk agregasi, ekspresi RLS harus memfilter tabel agregasi dan tabel detail.
Dalam contoh berikut, ekspresi RLS pada tabel Geografi berfungsi untuk agregasi, karena Geografi berada di sisi pemfilteran hubungan ke tabel Penjualan dan tabel Sales Agg . Kueri yang menggunakan tabel agregasi dan kueri yang tidak menggunakannya keduanya berhasil menerapkan RLS.
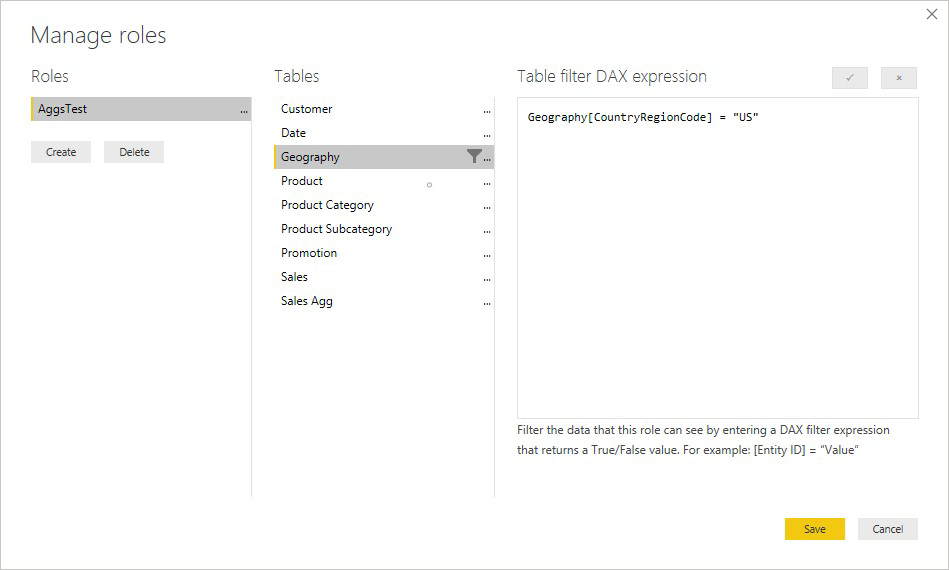
Ekspresi RLS pada tabel Produk hanya memfilter tabel Penjualan detail, bukan tabel Agg Penjualan agregat. Karena tabel agregasi adalah representasi lain dari data dalam tabel detail, tidak aman untuk menjawab kueri dari tabel agregasi jika filter RLS tidak dapat diterapkan. Hanya memfilter tabel detail tidak disarankan, karena kueri pengguna dari peran ini tidak mendapat manfaat dari hasil agregasi.
Ekspresi RLS yang memfilter hanya tabel agregasi Penjualan Agg dan bukan tabel detail Penjualan tidak diizinkan.
Untuk agregasi berdasarkan kolom GroupBy, ekspresi RLS yang diterapkan ke tabel detail dapat memfilter tabel agregasi, karena semua kolom GroupBy dalam tabel agregasi dicakup oleh tabel detail. Di sisi lain, filter RLS pada tabel agregasi tidak dapat memfilter tabel detail, sehingga tidak diizinkan.
Agregasi berdasarkan hubungan
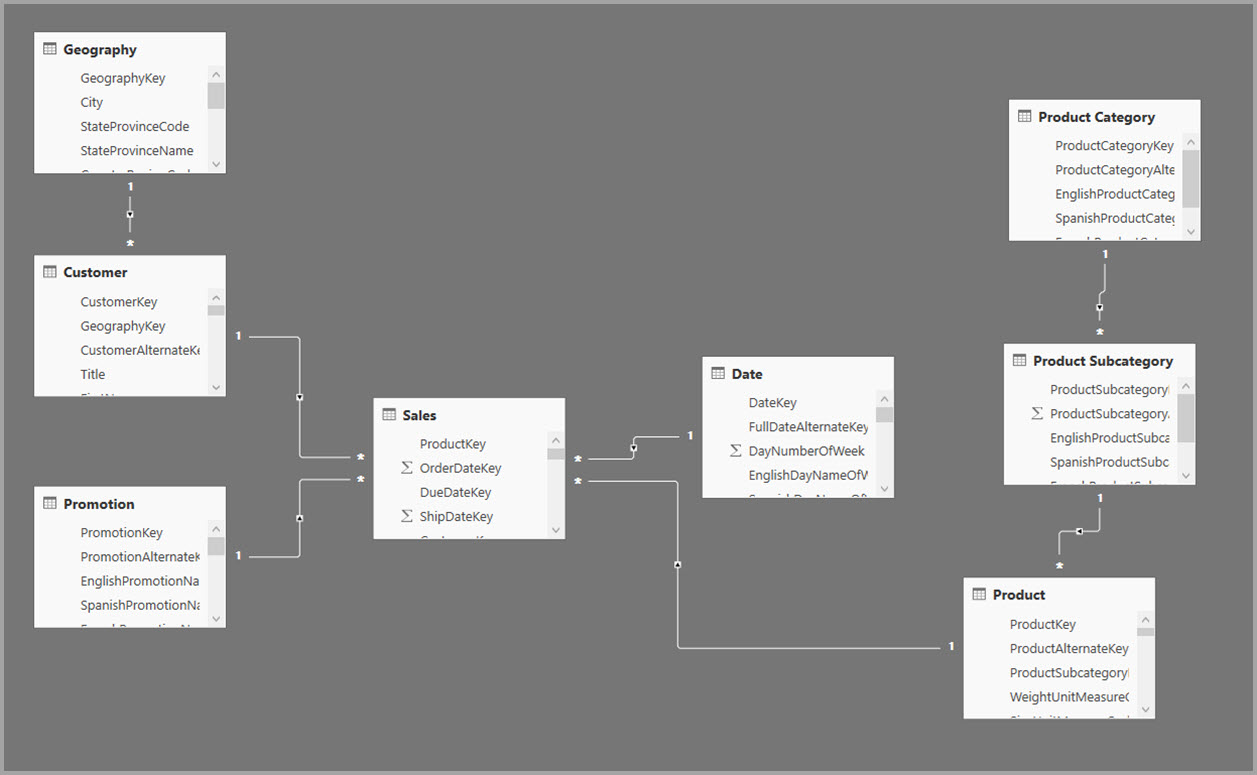
Model dimensi biasanya menggunakan agregasi berdasarkan hubungan. Model Power BI dari gudang data dan data mart menyerupai skema bintang dan snowflake, dengan hubungan antara tabel dimensi dan tabel fakta.
Dalam contoh berikut, model mendapatkan data dari satu sumber data. Tabel menggunakan mode penyimpanan DirectQuery. Tabel Fakta penjualan berisi miliaran baris. Mengatur mode penyimpanan Penjualan ke Impor untuk penyimpanan sementara akan mengkonsumsi memori dan sumber daya tambahan yang cukup besar.
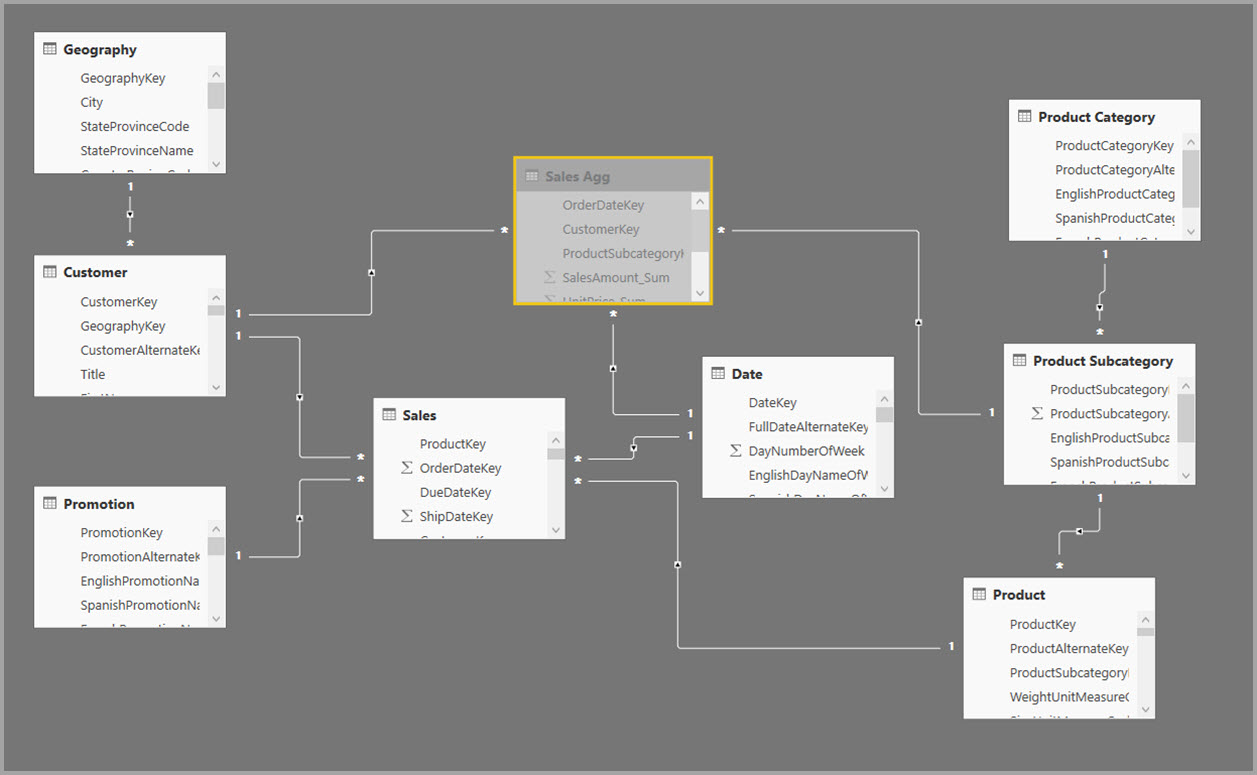
Sebagai gantinya, buat tabel agregasi Sales Agg. Dalam tabel Sales Agg, jumlah baris sama dengan jumlah total SalesAmount yang dikelompokkan berdasarkan CustomerKey, DateKey, dan ProductSubcategoryKey. Tabel Sales Agg berada pada granularitas yang lebih tinggi daripada Penjualan, jadi alih-alih miliaran, tabel tersebut mungkin berisi jutaan baris, yang lebih mudah dikelola.
Jika tabel dimensi berikut digunakan paling umum untuk kueri dengan nilai bisnis tinggi, tabel tersebut dapat memfilter Sales Agg, menggunakan hubungan satu-ke-banyak atau banyak-ke-satu .
- Geografi
- Pelanggan
- Tanggal
- Subkategori Produk
- Kategori Produk
Gambar berikut menunjukkan model ini.
Tabel berikut ini memperlihatkan agregasi untuk tabel Sales Agg .
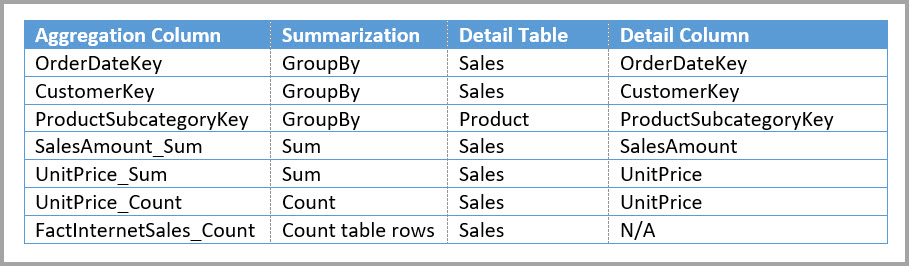
Nota
Tabel Sales Agg , seperti tabel apa pun, memiliki fleksibilitas dimuat dengan berbagai cara. Anda dapat melakukan agregasi dalam database sumber dengan menggunakan proses ETL atau ELT, atau dengan menggunakan ekspresi M untuk tabel. Tabel agregat dapat menggunakan Mode Penyimpanan Impor, dengan atau tanpa Penyegaran Bertahap untuk model semantik. Atau, ini dapat menggunakan DirectQuery dan dioptimalkan untuk kueri cepat dengan menggunakan indeks penyimpan kolom. Fleksibilitas ini memungkinkan arsitektur seimbang yang dapat menyebarkan beban kueri untuk menghindari penyempitan.
Mengubah mode penyimpanan tabel agregat Agg Penjualan menjadi mengimpor membuka kotak dialog yang menyatakan bahwa tabel dimensi terkait dapat diubah ke mode penyimpanan ganda.
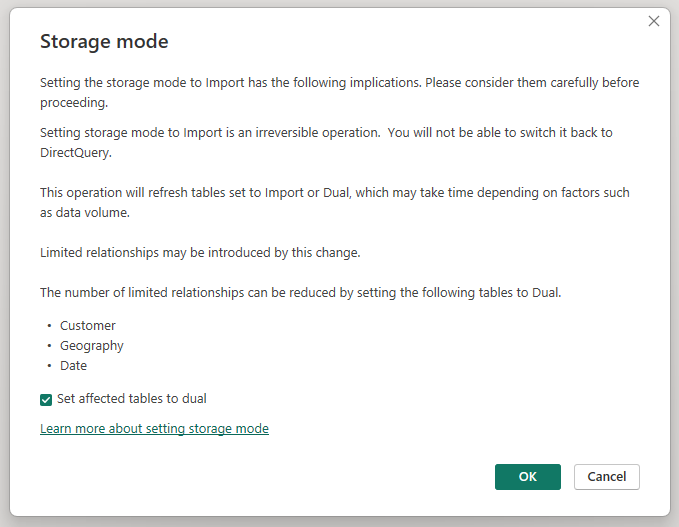
Mengatur tabel dimensi terkait ke Dual memungkinkan mereka bertindak sebagai Impor atau DirectQuery, tergantung pada subkueri. Dalam contoh:
- Kueri yang menggabungkan metrik dari tabel Sales Agg mode Impor, dan mengelompokkan menurut atribut dari tabel Ganda terkait, mengembalikan hasil dari cache dalam memori.
- Kueri yang menggabungkan metrik dari tabel Penjualan DirectQuery, dan mengelompokkan menurut atribut dari tabel Ganda terkait, mengembalikan hasil dalam mode DirectQuery. Logika kueri, termasuk operasi GroupBy, diteruskan ke database sumber.
Untuk informasi selengkapnya tentang Mode penyimpanan ganda, lihat Mengelola mode penyimpanan di Power BI Desktop.
Hubungan reguler vs. terbatas
Hit agregasi berdasarkan hubungan memerlukan hubungan yang teratur.
Hubungan reguler mencakup kombinasi mode penyimpanan berikut, di mana kedua tabel berasal dari satu sumber:
| Tabel di banyak sisi | Tabel di bagian 1 |
|---|---|
| Ganda | Ganda |
| Mengimpor | Impor atau Rangkap |
| DirectQuery | DirectQuery atau Dual |
Satu-satunya kasus di mana hubungan lintas sumber bersifat reguler adalah jika kedua tabel diatur ke Impor. Hubungan banyak-ke-banyak selalu dibatasi.
Untuk agregasi lintas sumber yang tidak bergantung pada hubungan, lihat Agregasi berdasarkan kolom GroupBy.
Contoh kueri agregasi berbasis hubungan
Kueri berikut menggunakan agregasi karena kolom dalam tabel Tanggal berada pada granularitas yang dapat menggunakan agregasi. Kolom SalesAmount menggunakan agregasi Jumlah .

Kueri berikut ini tidak menggunakan agregasi. Meskipun meminta total SalesAmount, kueri melakukan operasi GroupBy pada kolom dalam tabel Produk, yang granularitasnya tidak memungkinkan penggunaan agregasi. Jika Anda mengamati hubungan dalam model, subkategori produk dapat memiliki beberapa baris Produk. Kueri tidak dapat menentukan produk mana yang akan diagregasi. Dalam hal ini, kueri kembali ke DirectQuery dan mengirimkan kueri SQL ke sumber data.

Agregasi bukan hanya untuk perhitungan sederhana yang melakukan penjumlahan biasa. Perhitungan kompleks juga dapat menguntungkan. Secara konseptual, perhitungan kompleks dipecah menjadi subkueri untuk setiap SUM, MIN, MAX, dan COUNT. Setiap subkueri dievaluasi untuk menentukan apakah subkueri dapat menggunakan agregasi. Logika ini tidak berlaku dalam semua kasus karena pengoptimalan rencana kueri, tetapi secara umum harus berlaku. Contoh berikut menggunakan agregasi:

Fungsi COUNTROWS dapat memperoleh manfaat dari agregasi. Kueri berikut menggunakan agregasi karena ada agregasi Baris tabel Hitung yang ditentukan untuk tabel Penjualan .

Fungsi AVERAGE dapat memperoleh manfaat dari agregasi. Kueri berikut menggunakan agregasi karena AVERAGE secara internal diubah menjadi SUM yang dibagi dengan COUNT. Karena kolom UnitPrice memiliki agregasi yang ditentukan untuk SUM dan COUNT, agregasi digunakan.

Dalam beberapa kasus, fungsi DISTINCTCOUNT dapat memperoleh manfaat dari agregasi. Kueri berikut menggunakan agregasi karena ada entri GroupBy untuk CustomerKey, yang mempertahankan perbedaan CustomerKey dalam tabel agregasi. Teknik ini mungkin masih mencapai ambang performa di mana lebih dari 2 hingga 5 juta nilai yang berbeda dapat memengaruhi performa kueri. Namun, ini dapat berguna dalam skenario di mana ada miliaran baris dalam tabel detail, tetapi 2 hingga 5 juta nilai berbeda dalam kolom. Dalam hal ini, DISTINCTCOUNT dapat berkinerja lebih cepat daripada memindai tabel dengan miliaran baris, bahkan jika di-cache ke dalam memori.

Fungsi intelijensi waktu pada Data Analysis Expressions (DAX) menyadari agregasi. Kueri berikut menggunakan agregasi karena fungsi DATESYTD menghasilkan tabel nilai CalendarDay , dan tabel agregasi berada pada granularitas yang dicakup untuk kolom berdasarkan grup dalam tabel Tanggal . Ini adalah contoh filter dengan nilai tabel untuk fungsi CALCULATE, yang dapat digunakan dengan agregasi.

Agregasi berdasarkan kolom GroupBy
Model big data berbasis Hadoop memiliki karakteristik yang berbeda dari model dimensi. Untuk menghindari gabungan antara tabel besar, model big data sering tidak menggunakan hubungan, tetapi mendenormalisasi atribut dimensi ke tabel fakta. Anda dapat membuka kunci model big data tersebut untuk analisis interaktif dengan menggunakan agregasi berdasarkan kolom GroupBy.
Tabel berikut berisi kolom numerik Gerakan untuk diagregasi. Semua kolom lainnya adalah atribut untuk dikelompokkan menurut. Tabel berisi data IoT dan sejumlah besar baris. Mode penyimpanannya adalah DirectQuery. Kueri pada sumber data yang mengagregasi di seluruh model lambat akibat volume yang sangat besar.
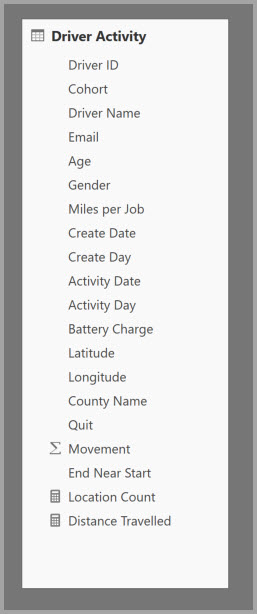
Untuk mengaktifkan analisis interaktif pada model ini, tambahkan tabel agregasi yang dikelompokkan menurut sebagian besar atribut, tetapi kecualikan atribut kardinalitas tinggi seperti bujur dan lintang. Pendekatan ini secara dramatis mengurangi jumlah baris dan cukup kecil untuk masuk dengan nyaman ke dalam cache dalam memori.
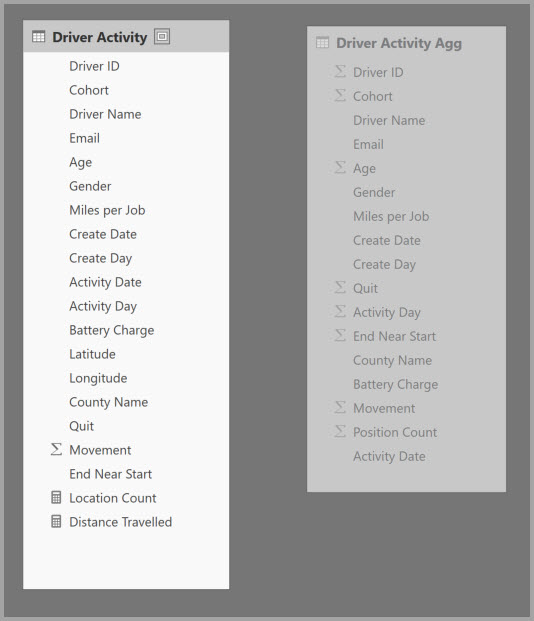
Tentukan pemetaan agregasi untuk tabel Aktivitas Driver Agg dalam dialog Kelola agregasi.
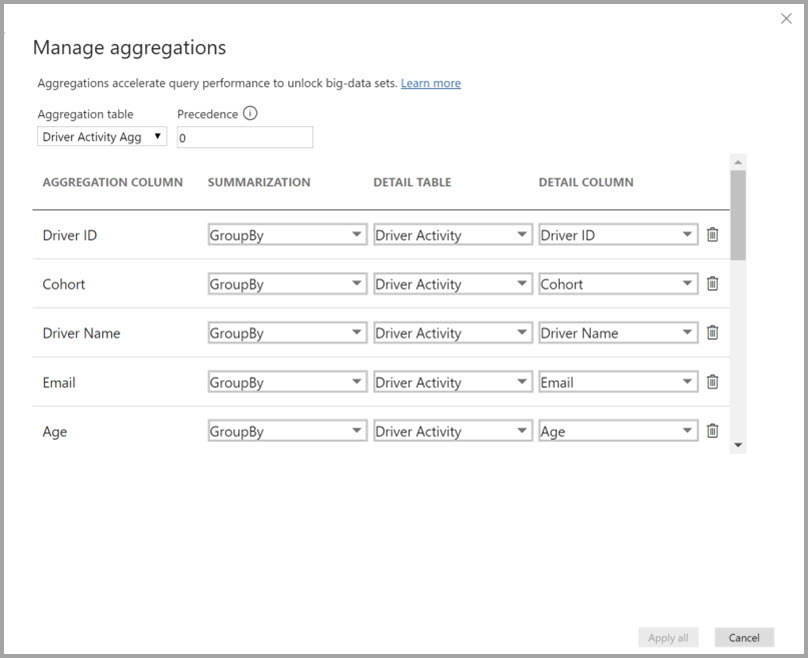
Dalam agregasi berdasarkan kolom GroupBy, entri GroupBy tidak opsional. Tanpa mereka, agregasi tidak terpukul. Perilaku ini berbeda dari menggunakan agregasi berdasarkan hubungan, di mana entri GroupBy bersifat opsional.
Tabel di bawah ini menunjukkan agregasi untuk tabel Aktivitas Pengemudi Agg.
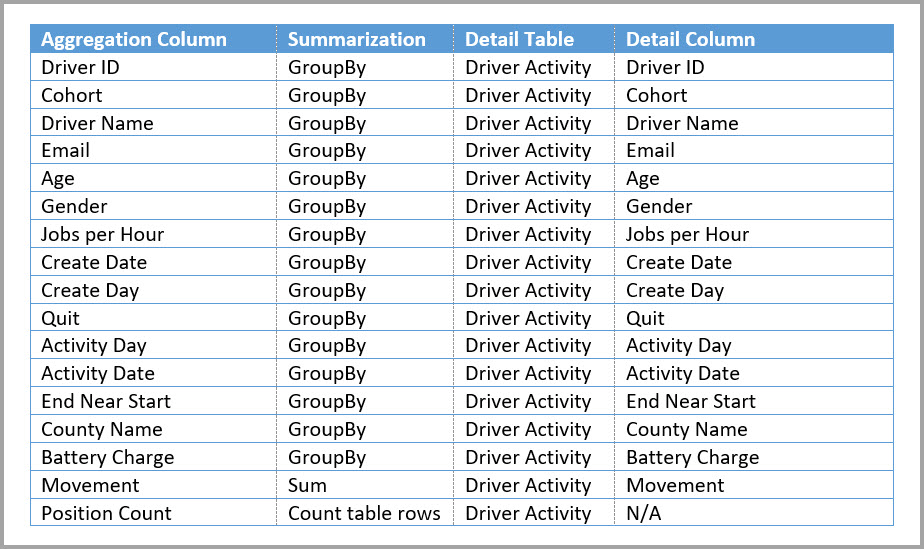
Atur mode penyimpanan tabel agregat Agg Aktivitas Driver ke Impor.
Contoh kueri agregasi GroupBy
Kueri berikut menggunakan agregasi karena kolom Tanggal Aktivitas dicakup oleh tabel agregasi. Fungsi COUNTROWS menggunakan agregasi baris yang dihitung dalam tabel.

Terutama untuk model yang berisi atribut filter pada tabel faktanya, lebih baik menggunakan agregasi Menghitung baris tabel. Power BI dapat mengirimkan kueri ke model menggunakan COUNTROWS jika tidak diminta secara eksplisit oleh pengguna. Misalnya, dialog filter memperlihatkan jumlah baris untuk setiap nilai.
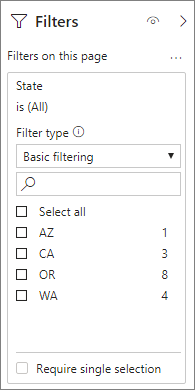
Teknik penggabungan agregasi
Anda dapat menggabungkan hubungan dan teknik kolom GroupBy untuk agregasi. Agregasi berdasarkan hubungan dapat mengharuskan tabel dimensi yang didenormalisasi dibagi menjadi beberapa tabel. Jika persyaratan ini mahal atau tidak praktis untuk tabel dimensi tertentu, Anda dapat mereplikasi atribut yang diperlukan dalam tabel agregasi untuk dimensi tersebut, dan menggunakan hubungan untuk orang lain.
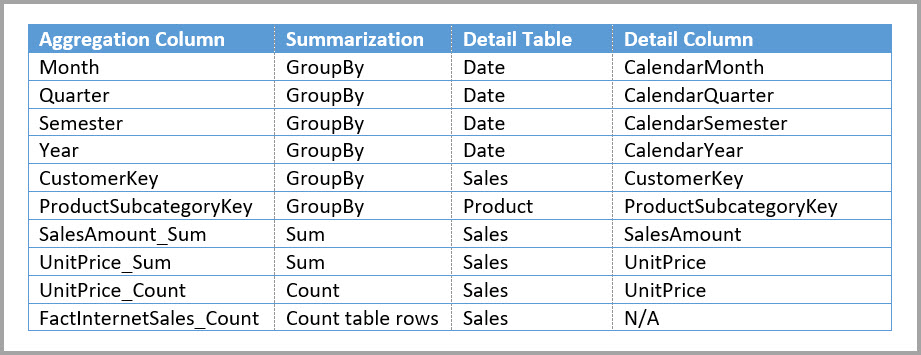
Misalnya, model berikut mereplikasi Bulan, Kuartal, Semester, dan Tahun dalam tabel Sales Agg . Tidak ada hubungan antara Sales Agg dan tabel Tanggal , tetapi ada hubungan dengan Pelanggan dan Subkategorer Produk. Mode penyimpanan Sales Agg adalah Impor.
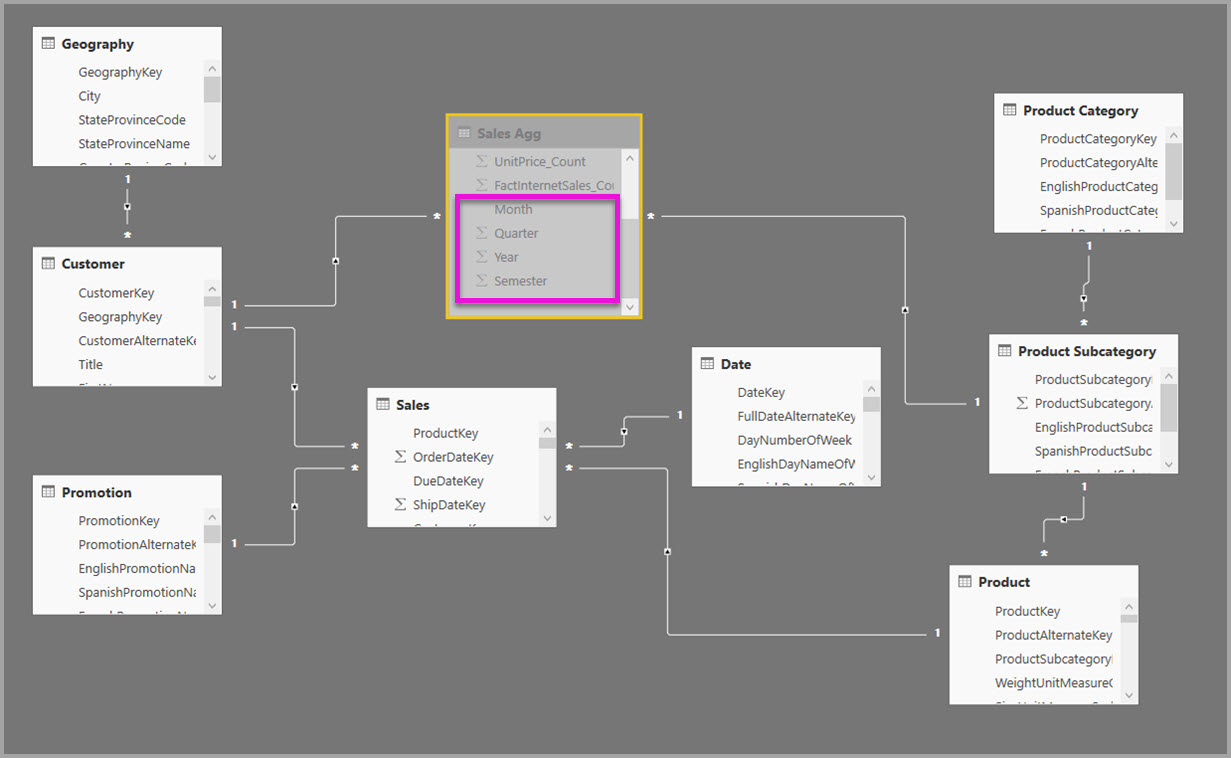
Tabel berikut menunjukkan entri yang diatur dalam dialog Kelola agregasi untuk tabel Sales Agg. Entri GroupBy di mana Tanggal adalah tabel detail wajib, untuk menggunakan agregasi untuk kueri yang dikelompokkan menurut atribut Tanggal . Seperti dalam contoh sebelumnya, entri GroupBy untuk CustomerKey dan ProductSubcategoryKey tidak memengaruhi penggunaan agregasi, kecuali DISTINCTCOUNT, karena adanya hubungan.
Contoh kueri agregasi gabungan
Kueri berikut menggunakan agregasi, karena tabel agregasi mencakup CalendarMonth, dan Anda bisa mengakses CategoryName melalui hubungan satu-ke-banyak. Kueri menggunakan agregasi SUM untuk SalesAmount.

Kueri berikut ini tidak menggunakan agregasi, karena tabel agregasi tidak mencakup CalendarDay.

Kueri inteligensi waktu berikut tidak menggunakan agregasi, karena fungsi DATESYTD menghasilkan tabel nilai CalendarDay , dan tabel agregasi tidak mencakup CalendarDay.

Urutan agregasi
Prioritas agregasi memungkinkan satu subkueri untuk mempertimbangkan beberapa tabel agregasi.
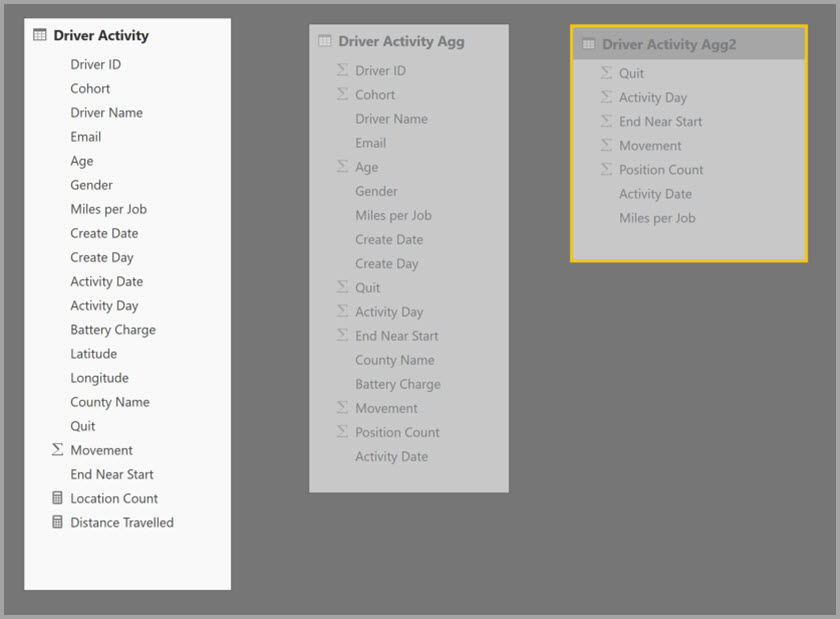
Contoh berikut adalah model komposit yang berisi beberapa sumber:
- Tabel DirectQuery Aktivitas Driver berisi lebih dari satu triliun baris data IoT yang bersumber dari sistem data besar. Ini melayani kueri drillthrough untuk melihat data IoT individual dalam konteks penyaringan yang dikendalikan.
- Tabel Driver Activity Agg adalah tabel agregasi perantara dalam mode DirectQuery. Ini berisi lebih dari satu miliar baris di Azure Synapse Analytics (sebelumnya Gudang Data SQL) dan dioptimalkan di sumber menggunakan indeks penyimpan kolom.
- Tabel Impor Driver Activity Agg2 memiliki tingkat granularitas yang tinggi, karena atribut pengelompokan sedikit dan memiliki kardinalitas rendah. Jumlah baris bisa serendah ribuan, sehingga dapat dengan mudah masuk ke dalam cache dalam memori. Kebetulan, atribut-atribut ini digunakan oleh dashboard eksekutif yang memiliki profil tinggi, sehingga kueri yang merujuk padanya harus secepat mungkin.
Nota
Tabel agregasi DirectQuery yang menggunakan sumber data yang berbeda dari tabel detail hanya didukung jika tabel agregasi berasal dari sumber SQL Server, Azure SQL, atau Azure Synapse Analytics (sebelumnya Gudang Data SQL).
Jejak memori model ini relatif kecil, tetapi membuka kunci model besar. Ini mewakili arsitektur seimbang karena menyebarkan beban kueri di seluruh komponen arsitektur, menggunakannya berdasarkan kekuatannya.
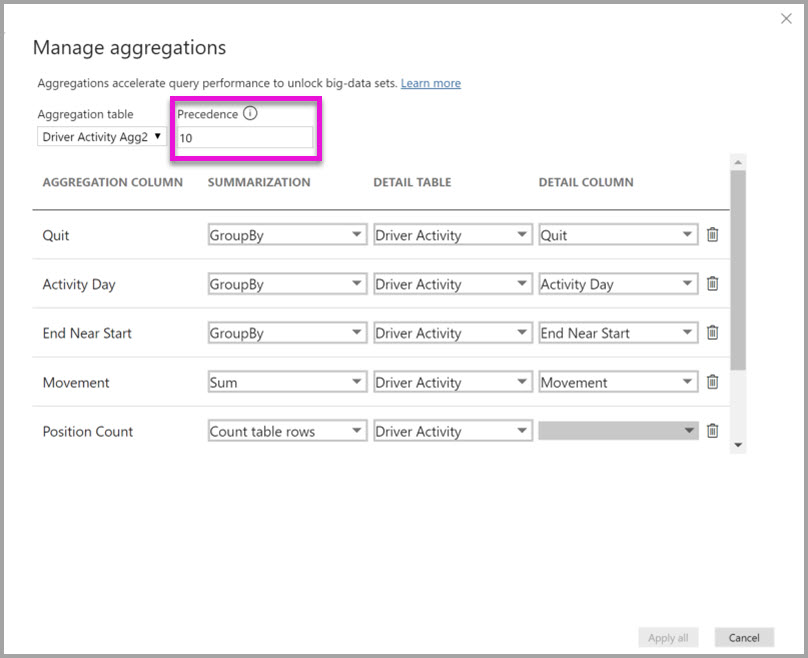
Dialog Agregasi terkelola untuk Agg2 Aktivitas Driver mengatur bidang Prioritas ke 10, yang lebih tinggi dari untuk Agg Aktivitas Driver. Pengaturan prioritas yang lebih tinggi berarti kueri yang menggunakan agregasi mempertimbangkan Driver Activity Agg2 terlebih dahulu. Subkueri yang tidak berada pada granularitas yang dapat dijawab oleh Agg2 Aktivitas Driver dapat mempertimbangkan Aktivitas Driver Agg sebagai gantinya. Kueri detail yang tidak dapat dijawab oleh tabel agregasi dapat diarahkan ke Aktivitas Driver.
Tabel yang ditentukan dalam kolom Tabel Detail adalah Aktivitas Driver, bukan Agg Aktivitas Driver, karena agregasi berantai tidak diizinkan.
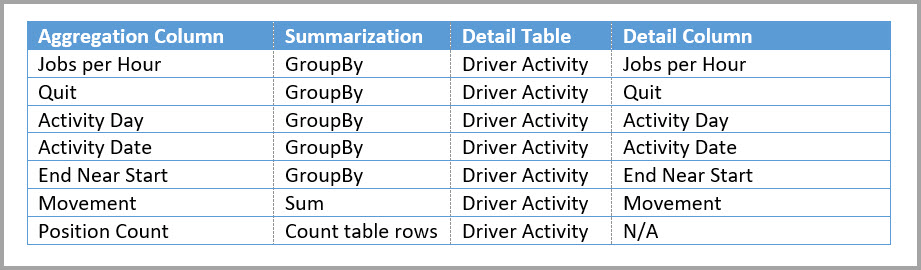
Tabel berikut ini memperlihatkan agregasi untuk tabel Aktivitas Pengemudi Agg2.
Mendeteksi apakah kueri mencapai atau gagal pada agregasi
SQL Profiler dapat mendeteksi apakah kueri berasal dari mesin penyimpanan cache dalam memori, atau jika DirectQuery mendorongnya ke sumber data. Anda dapat menggunakan proses yang sama untuk mendeteksi apakah agregasi sedang digunakan. Untuk informasi selengkapnya, lihat Kueri yang mengenai atau melewatkan cache.
SQL Profiler juga menyediakan peristiwa Query Processing\Aggregate Table Rewrite Query yang diperluas.
Cuplikan JSON berikut menunjukkan contoh output peristiwa saat agregasi digunakan.
- matchingResult menunjukkan bahwa subkueri menggunakan agregasi.
- dataRequest memperlihatkan kolom GroupBy dan kolom agregat yang digunakan subkueri.
- Pemetaan memperlihatkan kolom dalam tabel agregasi yang dipetakan.

Menjaga cache tetap sinkron
Agregasi yang menggabungkan mode penyimpanan DirectQuery, Import, dan Dual dapat mengembalikan data yang berbeda kecuali cache dalam memori tetap sinkron dengan data sumber. Misalnya, eksekusi kueri tidak mencoba menutupi masalah data dengan memfilter hasil DirectQuery agar sesuai dengan nilai cache. Anda mungkin perlu menangani masalah ini di sumbernya. Pengoptimalan performa tidak boleh membahayakan kemampuan Anda untuk memenuhi persyaratan bisnis. Anda perlu memahami aliran data dan desain yang sesuai.
Pertimbangan dan batasan
Agregasi tidak mendukung Parameter Kueri M Dinamis.
Mulai Agustus 2022, karena perubahan fungsionalitas, Power BI mengabaikan tabel agregasi mode impor yang memiliki sumber data diaktifkan dengan single sign-on (SSO) karena potensi risiko keamanan. Untuk memastikan performa kueri yang optimal dengan agregasi, nonaktifkan SSO untuk sumber data ini.
Komunitas
Power BI memiliki komunitas semarak di mana MVP, pro BI, dan rekan berbagi keahlian dalam grup diskusi, video, blog, dan banyak lagi. Saat mempelajari tentang agregasi, pastikan untuk memeriksa sumber daya ini: