Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
| Mayana Pereira | Scott Christiansen |
|---|---|
| Ilmu Data CELA | Keamanan dan Kepercayaan Pelanggan |
| Microsoft | Microsoft |
Abstract — Mengidentifikasi laporan bug keamanan (SBR) adalah langkah penting dalam siklus hidup pengembangan perangkat lunak. Dalam pendekatan berbasis pembelajaran mesin yang diawasi, biasanya diasumsikan bahwa seluruh laporan bug tersedia untuk pelatihan dan bahwa label mereka bebas kebisingan. Sepengetahuan kami, ini adalah studi pertama yang menunjukkan bahwa prediksi label yang akurat dimungkinkan untuk SBR bahkan ketika hanya judul yang tersedia dan di tengah gangguan label.
Istilah Indeks — Pembelajaran Mesin, Pelabelan yang Salah, Gangguan, Laporan Bug Keamanan, Repositori Bug
I. PERKENALAN
Mengidentifikasi masalah terkait keamanan di antara bug yang dilaporkan adalah kebutuhan yang mendesak di antara tim pengembangan perangkat lunak karena masalah tersebut meminta perbaikan yang lebih dipercepat untuk memenuhi persyaratan kepatuhan dan memastikan integritas perangkat lunak dan data pelanggan.
Pembelajaran mesin dan alat kecerdasan buatan menjanjikan untuk membuat pengembangan perangkat lunak lebih cepat, gesit, dan benar. Beberapa peneliti telah menerapkan pembelajaran mesin pada masalah mengidentifikasi bug keamanan [2], [7], [8], [18]. Studi yang diterbitkan sebelumnya telah mengasumsikan bahwa seluruh laporan bug tersedia untuk melatih dan menilai model pembelajaran mesin. Ini belum tentu terjadi. Ada situasi di mana seluruh laporan bug tidak dapat disediakan. Misalnya, laporan bug mungkin berisi kata sandi, informasi identifikasi pribadi (PII) atau jenis data sensitif lainnya - kasus yang saat ini kami hadapi di Microsoft. Oleh karena itu penting untuk menetapkan seberapa baik identifikasi bug keamanan dapat dilakukan menggunakan lebih sedikit informasi, seperti ketika hanya judul laporan bug yang tersedia.
Selain itu, repositori bug sering berisi entri yang salah label [7]: laporan bug non-keamanan yang diklasifikasikan sebagai terkait keamanan dan sebaliknya. Ada beberapa alasan terjadinya kesalahan label, mulai dari kurangnya keahlian tim pengembangan dalam keamanan, hingga keburukan masalah tertentu, misalnya, ada kemungkinan bug non-keamanan dieksploitasi dengan cara tidak langsung untuk menyebabkan implikasi keamanan. Ini adalah masalah serius karena kesalahan pelabelan SBR menghasilkan para ahli keamanan harus meninjau database bug secara manual dalam upaya yang mahal dan memakan waktu. Memahami bagaimana kebisingan memengaruhi pengklasifikasi yang berbeda dan seberapa kuat (atau rapuh) teknik pembelajaran mesin yang berbeda di hadapan himpunan data yang terkontaminasi dengan berbagai jenis kebisingan adalah masalah yang harus ditangani untuk membawa klasifikasi otomatis ke praktik rekayasa perangkat lunak.
Pekerjaan awal berpendapat bahwa repositori bug secara intrinsik berisik dan bahwa kebisingan mungkin memiliki efek buruk pada pengklasifikasi pembelajaran mesin performa [7]. Namun, tidak ada studi sistematis dan kuantitatif tentang bagaimana berbagai tingkat dan jenis kebisingan memengaruhi performa algoritma pembelajaran mesin yang diawasi yang berbeda untuk masalah mengidentifikasi laporan bug keamanan (SRB).
Dalam penelitian ini, kami menunjukkan bahwa klasifikasi laporan bug dapat dilakukan bahkan ketika hanya judul yang tersedia untuk pelatihan dan penilaian. Sepengetahuan kami, ini adalah karya pertama yang melakukan ini. Selain itu, kami memberikan studi sistematis pertama tentang efek kebisingan dalam klasifikasi laporan bug. Kami membuat studi komparatif tentang ketahanan tiga teknik pembelajaran mesin (regresi logistik, Naïve Bayes dan AdaBoost) terhadap kebisingan independen kelas.
Meskipun ada beberapa model analitik yang menangkap pengaruh umum kebisingan untuk beberapa pengklasifikasi sederhana [5], [6], hasil ini tidak memberikan batas ketat pada efek kebisingan pada presisi dan hanya berlaku untuk teknik pembelajaran mesin tertentu. Analisis akurat dari efek kebisingan dalam model pembelajaran mesin biasanya dilakukan dengan menjalankan eksperimen komputasi. Analisis semacam itu telah dilakukan untuk beberapa skenario mulai dari data pengukuran perangkat lunak [4], hingga klasifikasi gambar satelit [13] dan data medis [12]. Namun hasil ini tidak dapat diterjemahkan ke masalah spesifik kami, karena dependensinya yang tinggi pada sifat himpunan data dan masalah klasifikasi yang mendasar. Sepengetahuan kami, tidak ada hasil yang diterbitkan tentang masalah efek himpunan data berisik pada klasifikasi laporan bug keamanan khususnya.
KONTRIBUSI PENELITIAN KAMI:
Kami melatih pengklasifikasi untuk identifikasi laporan bug keamanan (SBR) hanya berdasarkan judul laporan. Sepengetahuan kami, ini adalah karya pertama yang melakukannya. Pekerjaan sebelumnya menggunakan laporan bug lengkap atau meningkatkan laporan bug dengan fitur pelengkap tambahan. Mengklasifikasikan bug hanya berdasarkan petak peta sangat relevan ketika laporan bug lengkap tidak dapat disediakan karena masalah privasi. Misalnya, terkenal kasus laporan bug yang berisi kata sandi dan data sensitif lainnya.
Kami juga menyediakan studi sistematis pertama tentang toleransi kebisingan label dari berbagai model dan teknik pembelajaran mesin yang digunakan untuk klasifikasi otomatis SBR. Kami melakukan studi komparatif tentang ketahanan tiga teknik pembelajaran mesin yang berbeda (regresi logistik, naive Bayes, dan AdaBoost) terhadap kebisingan yang bergantung pada kelas dan yang tidak bergantung pada kelas.
Sisa kertas disajikan sebagai berikut: Di bagian II kami menyajikan beberapa karya sebelumnya dalam literatur. Di bagian III kami menjelaskan himpunan data dan cara data diproses sebelumnya. Metodologi dijelaskan di bagian IV dan hasil eksperimen kami yang dianalisis di bagian V. Akhirnya, kesimpulan dan karya masa depan kami disajikan dalam VI.
II. KARYA SEBELUMNYA
APLIKASI PEMBELAJARAN MESIN PADA REPOSITORI BUG.
Ada literatur yang luas dalam menerapkan penambangan teks, pemrosesan bahasa alami dan pembelajaran mesin pada repositori bug dalam upaya untuk mengotomatiskan tugas-tugas yang melelahkan seperti deteksi bug keamanan [2], [7], [8], [18], identifikasi duplikat bug [3], triase bug [1], [11], untuk beberapa aplikasi. Idealnya, pernikahan pembelajaran mesin (ML) dan pemrosesan bahasa alami berpotensi mengurangi pekerjaan manual yang diperlukan untuk mengumpulkan database bug, mempersingkat waktu yang diperlukan untuk menyelesaikan tugas-tugas ini dan dapat meningkatkan keandalan hasilnya.
Dalam [7] penulis mengusulkan model bahasa alami untuk mengotomatiskan klasifikasi SBR berdasarkan deskripsi bug. Penulis mengekstrak kosakata dari semua deskripsi bug dalam himpunan data pelatihan dan secara manual menyusunnya menjadi tiga daftar kata: kata yang relevan, kata umum (kata-kata umum yang tampaknya tidak relevan untuk klasifikasi), dan sinonim. Mereka membandingkan performa klasifikator bug keamanan yang dilatih pada data yang dievaluasi oleh insinyur keamanan dan klasifikator yang dilatih pada data yang diberi label oleh pelapor bug secara umum. Meskipun model mereka jelas lebih efektif ketika dilatih pada data yang ditinjau oleh insinyur keamanan, model yang diusulkan ini bergantung pada kosakata yang diturunkan secara manual, yang menjadikannya tergantung pada kurasi manusia. Selain itu, tidak ada analisis tentang bagaimana tingkat kebisingan yang berbeda memengaruhi model mereka, bagaimana pengklasifikasi yang berbeda merespons kebisingan, dan jika kebisingan di salah satu kelas memengaruhi performa secara berbeda.
Zou et. al [18] memanfaatkan beberapa jenis informasi yang terkandung dalam laporan bug yang melibatkan bidang non-tekstual laporan bug (fitur meta, misalnya, waktu, tingkat keparahan, dan prioritas) dan konten tekstual laporan bug (fitur tekstual, yaitu, teks dalam bidang ringkasan). Berdasarkan fitur-fitur ini, mereka membangun model untuk secara otomatis mengidentifikasi SBR melalui pemrosesan bahasa alami dan teknik pembelajaran mesin. Dalam [8] penulis melakukan analisis serupa, tetapi juga mereka membandingkan performa teknik pembelajaran mesin yang diawasi dan tidak diawasi, dan mempelajari berapa banyak data yang diperlukan untuk melatih model mereka.
Dalam [2] penulis juga mengeksplorasi teknik pembelajaran mesin yang berbeda untuk mengklasifikasikan bug sebagai SBR atau NSBR (Laporan Bug Non-Keamanan) berdasarkan deskripsi mereka. Mereka mengusulkan alur untuk pemrosesan data dan pelatihan model berdasarkan TFIDF. Mereka membandingkan alur yang diusulkan dengan model berdasarkan bag-of-words dan Naïve Bayes. Wijayasekara et al. [16] juga menggunakan teknik penambangan teks untuk menghasilkan vektor fitur dari setiap laporan bug berdasarkan kata-kata yang sering untuk mengidentifikasi Bug Dampak Tersembunyi (HIB). Yang et al. [17] mengklaim mengidentifikasi laporan bug dengan dampak tinggi (misalnya, SBR) dengan bantuan Frekuensi Istilah (TF) dan Naïve Bayes. Dalam [9] penulis mengusulkan model untuk memprediksi tingkat keparahan bug.
KEBISINGAN LABEL
Masalah menangani himpunan data dengan kebisingan label telah dipelajari secara luas. Frenay dan Verleysen mengusulkan taksonomi kebisingan label dalam [6], untuk membedakan berbagai jenis label berisik. Penulis mengusulkan tiga jenis kebisingan yang berbeda: kebisingan label yang terjadi secara independen dari kelas sebenarnya maupun nilai dari fitur instans; kebisingan label yang bergantung hanya pada label sebenarnya; dan kebisingan label di mana probabilitas kesalahan pelabelan juga bergantung pada nilai fitur. Dalam pekerjaan kami, kami mempelajari dua jenis kebisingan pertama. Dari perspektif teoritis, kebisingan label biasanya mengurangi performa model [10], kecuali dalam beberapa kasus tertentu [14]. Secara umum, metode yang kuat mengandalkan penghindaran terjadinya overfitting untuk menangani kebisingan pada label [15]. Studi efek kebisingan dalam klasifikasi telah dilakukan sebelumnya di banyak bidang seperti klasifikasi gambar satelit [13], klasifikasi kualitas perangkat lunak [4] dan klasifikasi domain medis [12]. Sepengetahuan kami, tidak ada karya yang diterbitkan yang mempelajari kuantifikasi yang tepat dari efek label berisik dalam masalah klasifikasi SBR. Dalam skenario ini, hubungan yang tepat di antara tingkat kebisingan, jenis kebisingan, dan penurunan performa belum dibuat. Selain itu, ada baiknya untuk memahami bagaimana pengklasifikasi yang berbeda berperilaku di hadapan kebisingan. Lebih umumnya, kami tidak menyadari pekerjaan apa pun yang secara sistematis mempelajari efek himpunan data yang bising pada performa algoritma pembelajaran mesin yang berbeda dalam konteks laporan bug perangkat lunak.
III. DESKRIPSI HIMPUNAN DATA
Himpunan data kami terdiri dari 1.073.149 judul bug, 552.073 di antaranya sesuai dengan SBR dan 521.076 NSBR. Data ini dikumpulkan dari berbagai tim di seluruh Microsoft pada tahun 2015, 2016, 2017 dan 2018. Semua label diperoleh oleh sistem verifikasi bug berbasis tanda tangan atau berlabel manusia. Judul bug dalam himpunan data kami adalah teks yang sangat pendek, berisi sekitar 10 kata, dengan gambaran umum masalah.
Sebuah. Pra-pemrosesan Data Kami mengurai setiap judul bug berdasarkan spasi kosongnya, menghasilkan daftar token. Kami memproses setiap daftar token sebagai berikut:
Hapus semua token yang merupakan jalur file
Pisahkan token tempat simbol berikut ada: { , (, ), -, }, {, [, ], }
Hapus kata berhenti , token yang hanya terdiri dari karakter numerik dan token yang muncul kurang dari 5 kali di seluruh korpus.
IV. METODOLOGI
Proses pelatihan model pembelajaran mesin kami terdiri dari dua langkah utama: mengodekan data menjadi vektor fitur dan melatih pengklasifikasi pembelajaran mesin yang diawasi.
Sebuah. Vektor Fitur dan Teknik Pembelajaran Mesin
Bagian pertama melibatkan pengodean data ke dalam vektor fitur menggunakan istilah algoritma frekuensiinverse frekuensi dokumen (TF-IDF), seperti yang digunakan dalam [2]. TF-IDF adalah teknik pengambilan informasi yang menimbang frekuensi istilah (TF) dan frekuensi dokumen invers (IDF). Setiap kata atau istilah memiliki skor TF dan IDF masing-masing. Algoritma TF-IDF menetapkan kepentingan untuk kata tersebut berdasarkan berapa kali muncul dalam dokumen, dan yang lebih penting, ini memeriksa seberapa relevan kata kunci di seluruh kumpulan judul dalam himpunan data. Kami melatih dan membandingkan tiga teknik klasifikasi: naïve Bayes (NB), pohon keputusan yang ditingkatkan (AdaBoost) dan regresi logistik (LR). Kami telah memilih teknik ini karena mereka telah terbukti berkinerja baik untuk tugas terkait mengidentifikasi laporan bug keamanan berdasarkan seluruh laporan dalam literatur. Hasil ini dikonfirmasi dalam analisis awal di mana ketiga pengklasifikasi ini mengungguli mesin vektor dukungan dan hutan acak. Dalam eksperimen kami, kami menggunakan pustaka scikit-learn untuk pengodean dan pelatihan model.
B. Jenis Kebisingan
Kebisingan yang dipelajari dalam penelitian ini mengacu pada kebisingan pada label kelas yang ada dalam data pelatihan. Dalam kondisi kebisingan seperti itu, akibatnya, proses pembelajaran dan model yang dihasilkan terganggu oleh contoh berlabel salah. Kami menganalisis dampak tingkat kebisingan yang berbeda yang diterapkan pada informasi kelas. Jenis kebisingan label telah dibahas sebelumnya dalam literatur menggunakan berbagai terminologi. Dalam pekerjaan kami, kami menganalisis efek dari dua kebisingan label yang berbeda pada pengklasifikasi kami: kebisingan label yang independen dari kelas, yang dicapai dengan memilih instans secara acak dan mengubah label mereka; dan kebisingan tergantung kelas, di mana kelas memiliki kemungkinan yang berbeda untuk menjadi bising.
a) kebisingan independen kelas: Kebisingan independen kelas mengacu pada kebisingan yang terjadi secara independen dari kelas sebenarnya dari instans. Dalam jenis kebisingan ini, probabilitas salah memberi label pbr sama untuk semua instans dalam himpunan data. Kami memperkenalkan kebisingan independen dari kelas dalam himpunan data kami dengan membalik setiap label secara acak dengan probabilitas pbr.
b) kebisingan yang bergantung pada kelas: Kebisingan yang bergantung pada kelas mengacu pada kebisingan yang bergantung pada kelas asli dari instans. Dalam jenis kebisingan ini, probabilitas mislabeling di kelas SBR adalah psbr dan probabilitas mislabeling di kelas NSBR adalah pnsbr. Kami memperkenalkan kebisingan dependen kelas dalam himpunan data kami dengan membalik setiap entri dalam himpunan data yang label sebenarnya adalah SBR dengan probabilitas psbr. Secara analog, kami membalik label kelas instans NSBR dengan probabilitas pnsbr.
c) kebisingan kelas tunggal : Kebisingan kelas tunggal adalah kasus khusus dari kebisingan yang bergantung pada kelas, di mana pnsbr = 0 dan psbr> 0. Perhatikan bahwa untuk kebisingan yang tidak bergantung pada kelas, kami memiliki psbr = pnsbr = pbr.
C. Pembangkitan Kebisingan
Eksperimen kami menyelidiki dampak berbagai jenis dan tingkat kebisingan dalam pelatihan pengklasifikasi SBR. Dalam eksperimen kami, kami menetapkan 25% himpunan data sebagai data pengujian, 10% sebagai validasi dan 65% sebagai data pelatihan.
Kami menambahkan kebisingan ke kumpulan data pelatihan dan validasi untuk berbagai tingkat pbr, psbr dan pnsbr . Kami tidak melakukan modifikasi apa pun pada himpunan data pengujian. Tingkat kebisingan yang berbeda yang digunakan adalah P = {0,05 × i|0 < i < 10}.
Dalam eksperimen kebisingan yang independen dari kelas, untuk pbr ∈ P kami melakukan hal berikut:
Menghasilkan kebisingan untuk himpunan data pelatihan dan validasi;
Melatih regresi logistik, model Naïve Bayes dan AdaBoost menggunakan himpunan data pelatihan (dengan kebisingan); * Menyetel model menggunakan himpunan data validasi (dengan kebisingan);
Menguji model menggunakan himpunan data pengujian (tanpa kebisingan).
Dalam eksperimen kebisingan yang bergantung pada kelas, untuk psbr ∈ P dan pnsbr ∈ P kami melakukan hal berikut untuk semua kombinasi psbr dan pnsbr:
Menghasilkan kebisingan untuk himpunan data pelatihan dan validasi;
Melatih model regresi logistik, model Naïve Bayes, dan model AdaBoost menggunakan himpunan data pelatihan (dengan kebisingan);
Mengoptimalkan model menggunakan himpunan data validasi (dengan kebisingan);
Menguji model menggunakan himpunan data pengujian (tanpa kebisingan).
V. HASIL PERCOBAAN
Di bagian ini analisis hasil eksperimen yang dilakukan sesuai dengan metodologi yang dijelaskan di bagian IV.
a) Performa model tanpa kebisingan dalam himpunan data pelatihan: Salah satu kontribusi makalah ini adalah proposal model pembelajaran mesin untuk mengidentifikasi bug keamanan hanya dengan menggunakan judul bug sebagai data untuk pengambilan keputusan. Ini memungkinkan pelatihan model pembelajaran mesin bahkan ketika tim pengembangan tidak ingin berbagi laporan bug secara penuh karena adanya data sensitif. Kami membandingkan performa tiga model pembelajaran mesin saat dilatih hanya menggunakan judul bug.
Model regresi logistik adalah pengklasifikasi berkinerja terbaik. Ini adalah pengklasifikasi dengan nilai AUC tertinggi, 0,9826, recall 0,9353 untuk nilai FPR sebesar 0,0735. Klasifikasi Naive Bayes menunjukkan performa yang sedikit lebih rendah dibandingkan dengan Klasifikasi Regresi Logistik, dengan AUC 0,9779 dan recall 0,9189 pada FPR 0,0769. Pengklasifikasi AdaBoost memiliki performa yang lebih rendah dibandingkan dengan dua pengklasifikasi yang disebutkan sebelumnya. Ini mencapai AUC 0.9143, dan recall 0.7018 untuk FPR 0.0774. Area di bawah kurva ROC (AUC) adalah metrik yang baik untuk membandingkan performa beberapa model, karena meringkas dalam satu nilai hubungan TPR vs. FPR. Dalam analisis berikutnya, kami akan membatasi analisis komparatif kami dengan nilai AUC.
Tabel 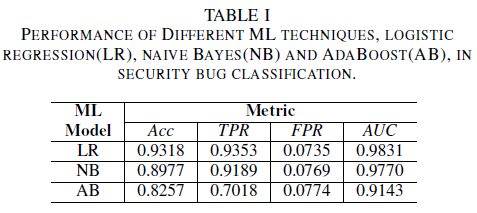
Sebuah. Kebisingan Kelas: hanya satu kelas
Seseorang dapat membayangkan skenario di mana semua bug ditetapkan ke kelas NSBR secara default, dan bug hanya akan ditetapkan ke kelas SBR jika ada pakar keamanan yang meninjau repositori bug. Skenario ini diwakili dalam pengaturan eksperimental kelas tunggal, di mana kami berasumsi bahwa pnsbr = 0 dan 0 < psbr< 0,5.
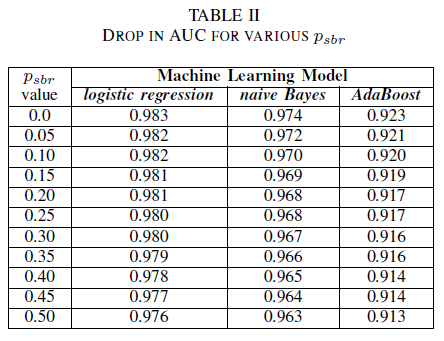
Dari tabel II, kami mengamati dampak yang sangat kecil terhadap AUC untuk ketiga pengklasifikasi. AUC-ROC dari model yang dilatih pada psbr = 0 dibandingkan dengan AUC-ROC model di mana psbr = 0.25 berbeda sebesar 0.003 untuk regresi logistik, 0.006 untuk naive Bayes, dan 0.006 untuk AdaBoost. Dalam kasus psbr = 0,50, AUC yang diukur untuk setiap model berbeda dari model yang dilatih dengan psbr = 0 sebesar 0,007 untuk regresi logistik, 0,011 untuk naïve Bayes, dan 0,010 untuk AdaBoost. pengklasifikasi regresi logistik yang dilatih dengan adanya kebisingan kelas tunggal menyajikan variasi terkecil dalam metrik AUC-nya, yaitu perilaku yang lebih kuat, jika dibandingkan dengan pengklasifikasi Naïve Bayes dan AdaBoost kami.
B. Kebisingan Kelas: tidak bergantung pada kelas
Kami membandingkan kinerja tiga pengklasifikasi kami untuk kasus di mana data pelatihan rusak oleh kebisingan yang tidak tergantung pada kelas. Kami mengukur AUC untuk setiap model yang dilatih dengan tingkat pbr yang berbeda dalam data pelatihan.
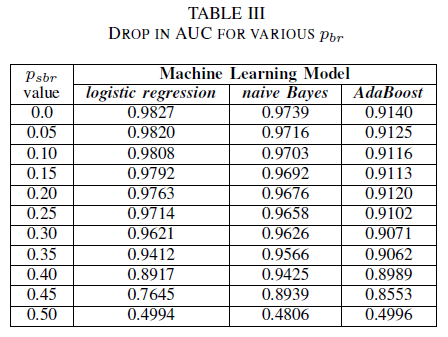
Dalam Tabel III kami mengamati penurunan AUC-ROC untuk setiap kenaikan kebisingan dalam eksperimen. AUC-ROC yang diukur dari model yang dilatih pada data tanpa kebisingan dibandingkan dengan AUC-ROC model yang dilatih dengan kebisingan yang independen dari kelas dengan pbr = 0,25 berbeda sebesar 0,011 untuk regresi logistik, 0,008 untuk naïve Bayes, dan 0,0038 untuk AdaBoost. Kami mengamati bahwa kebisingan label tidak berdampak pada AUC Bayes naif dan pengklasifikasi AdaBoost secara signifikan ketika tingkat kebisingan lebih rendah dari 40%. Di sisi lain, Pengklasifikasi regresi logistik mengalami dampak dalam ukuran AUC untuk tingkat kebisingan label di atas 30%.
Variasi AUC 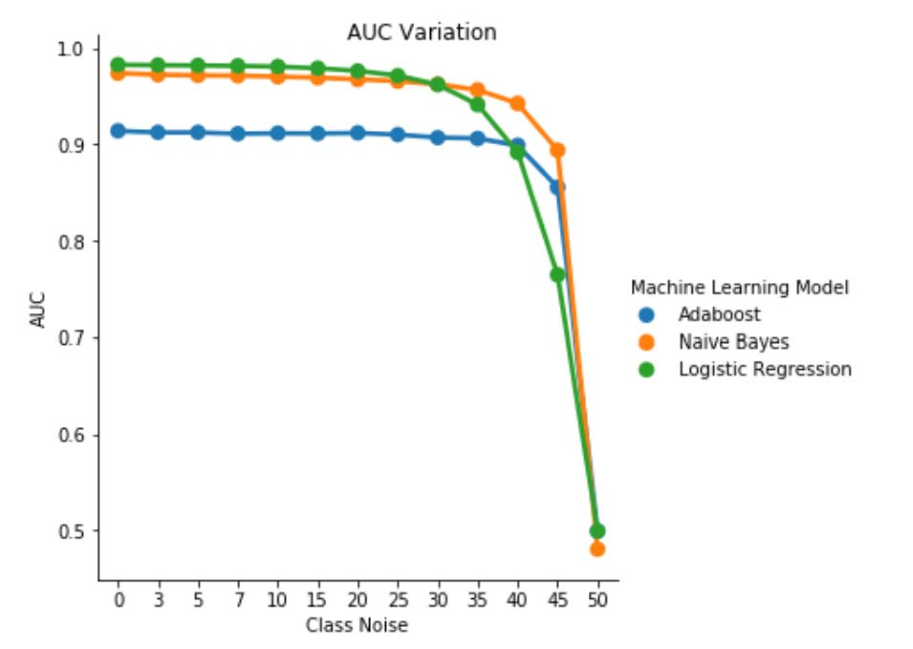
Gambar 1. Variasi AUC-ROC dalam kebisingan independen kelas. Untuk tingkat kebisingan pbr =0,5 pengklasifikasi bertindak seperti pengklasifikasi acak, yaitu AUC≈0.5. Tetapi kita dapat mengamati bahwa untuk tingkat kebisingan yang lebih rendah (pbr ≤0,30), pelajar regresi logistik menyajikan performa yang lebih baik dibandingkan dengan dua model lainnya. Namun, untuk pembelajar naive Bayes 0.35≤ pbr ≤0.45 menyajikan metrik AUCROC yang lebih baik.
C. Kebisingan Kelas: tergantung kelas
Dalam serangkaian eksperimen akhir, kami mempertimbangkan skenario di mana kelas yang berbeda berisi tingkat kebisingan yang berbeda, yaitu psbr ≠ pnsbr. Kami secara sistematis menaikkan psbr dan pnsbr secara independen sebesar 0,05 dalam data pelatihan dan mengamati perubahan perilaku tiga pengklasifikasi.
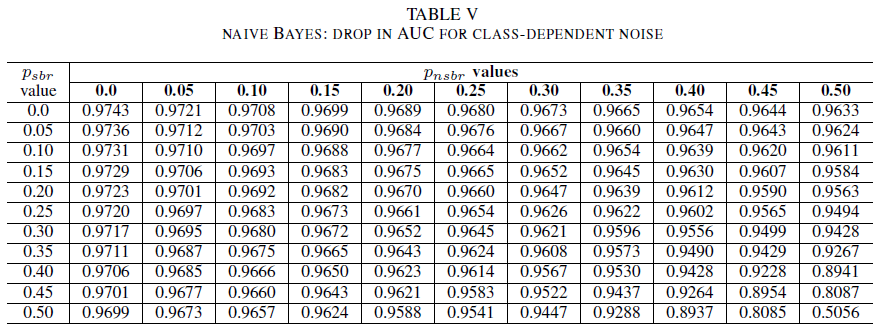
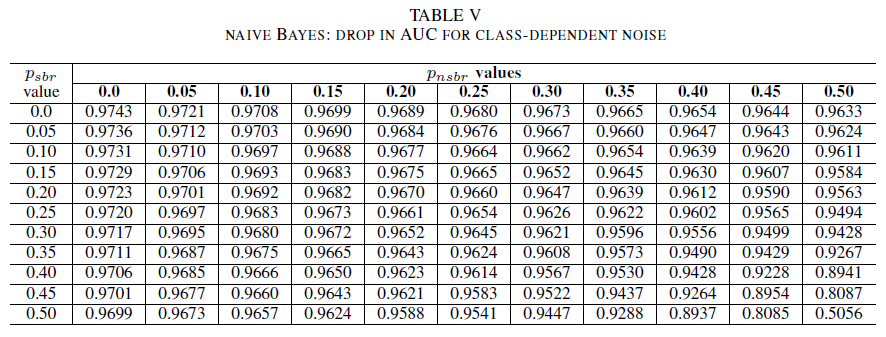
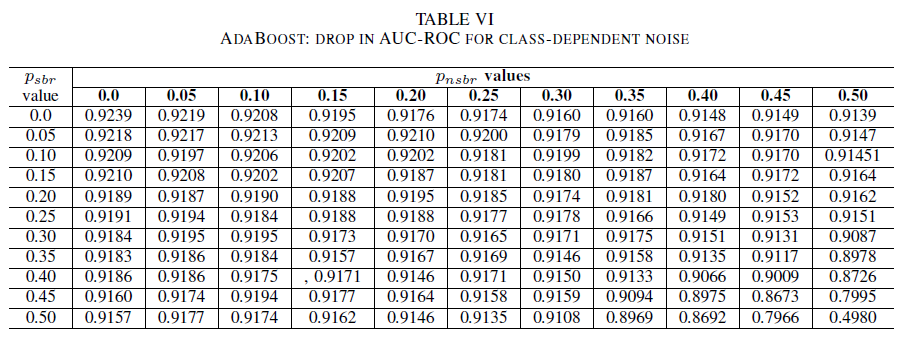
Tabel IV, V, VI menunjukkan variasi AUC seiring peningkatan kebisingan pada berbagai tingkat di setiap kelas untuk regresi logistik dalam Tabel IV, untuk Naïve Bayes dalam Tabel V, dan untuk AdaBoost dalam Tabel VI. Untuk semua pengklasifikasi, kami melihat dampak pada metrik AUC ketika kedua kelas mengandung tingkat kebisingan di atas 30%. Naïve Bayes berfungsi secara tangguh. Dampak pada AUC sangat kecil bahkan ketika 50% label di kelas positif dibalik, asalkan kelas negatif berisi 30% label berisik atau kurang. Dalam hal ini, penurunan AUC adalah 0,03. AdaBoost menyajikan perilaku paling kuat dari ketiga pengklasifikasi. Perubahan signifikan dalam AUC hanya akan terjadi untuk tingkat kebisingan yang lebih besar dari 45% di kedua kelas. Dalam hal ini, kita mulai mengamati kerusakan AUC yang lebih besar dari 0,02.
D. Pada Keberadaan Kebisingan Residu di Himpunan Data Asli
Himpunan data kami diberi label oleh sistem otomatis berbasis tanda tangan dan oleh pakar manusia. Selain itu, semua laporan bug telah ditinjau lebih lanjut dan ditutup oleh pakar manusia. Meskipun kami mengharapkan bahwa jumlah kebisingan dalam himpunan data kami minimal dan tidak signifikan secara statistik, adanya kebisingan residual tidak membatalkan kesimpulan kami. Memang, demi ilustrasi, asumsikan bahwa himpunan data asli terganggu oleh kebisingan yang independen dari kelas, sama dengan 0 < p < 1/2 yang terdistribusi secara independen dan identik (i.i.d) untuk setiap entri.
Jika kita, selain kebisingan asli, menambahkan suatu kebisingan independen kelas dengan probabilitas pbr i.i.d, kebisingan yang dihasilkan per entri akan menjadi p∗ = p(1 − pbr )+(1 − p)pbr . Untuk 0 < p,pbr< 1/2, kami memiliki bahwa kebisingan aktual per label p∗ benar-benar lebih besar dari kebisingan yang kami tambahkan secara buatan ke himpunan data pbr . Dengan demikian, performa pengklasifikasi kami akan lebih baik jika mereka dilatih dengan himpunan data yang benar-benar tidak berisik (p = 0) sejak awal. Singkatnya, adanya kebisingan residual dalam himpunan data aktual berarti bahwa ketahanan pengklasifikasi kami terhadap kebisingan lebih baik daripada hasil yang disajikan di sini. Selain itu, jika kebisingan residu dalam himpunan data kami relevan secara statistik, AUC pengklasifikasi kami akan menjadi 0,5 (tebakan acak) untuk tingkat kebisingan yang benar-benar kurang dari 0,5. Kami tidak mengamati perilaku tersebut dalam hasil kami.
VI. KESIMPULAN DAN PEKERJAAN DI MASA DEPAN
Kontribusi kami dalam makalah ini adalah dua kali lipat.
Pertama, kami telah menunjukkan kelayakan klasifikasi laporan bug keamanan hanya berdasarkan judul laporan bug. Ini sangat relevan dalam skenario di mana seluruh laporan bug tidak tersedia karena kendala privasi. Misalnya, dalam kasus kami, laporan bug berisi informasi privat seperti kata sandi dan kunci kriptografi dan tidak tersedia untuk melatih pengklasifikasi. Hasil kami menunjukkan bahwa identifikasi SBR dapat dilakukan dengan akurasi tinggi bahkan ketika hanya judul laporan yang tersedia. Model klasifikasi kami yang menggunakan kombinasi TF-IDF dan regresi logistik menghasilkan AUC sebesar 0.9831.
Kedua, kami menganalisis efek dari data pelatihan dan validasi yang diberi label tidak tepat. Kami membandingkan tiga teknik klasifikasi pembelajaran mesin terkenal (Naïve Bayes, regresi logistik, dan AdaBoost) dalam hal ketahanannya terhadap berbagai jenis kebisingan dan tingkat kebisingan. Ketiga pengklasifikasi tahan terhadap noise dari satu kelas. Kebisingan dalam data pelatihan tidak berpengaruh signifikan pada pengklasifikasi yang dihasilkan. Penurunan AUC sangat kecil (0,01) untuk tingkat kebisingan sebesar 50%. Untuk kebisingan yang ada di kedua kelas dan tidak bergantung pada kelas, model Naïve Bayes dan AdaBoost menunjukkan variasi signifikan dalam AUC hanya ketika dilatih dengan data dengan tingkat kebisingan lebih besar dari 40%.
Akhirnya, kebisingan yang bergantung pada kelas secara signifikan berdampak pada AUC hanya ketika ada lebih dari 35% kebisingan dalam kedua kelas. AdaBoost menunjukkan ketahanan yang paling kuat. Dampak terhadap AUC sangat kecil bahkan jika kelas positif memiliki 50% labelnya berisik, asalkan kelas negatif memiliki 45% label berisik atau kurang. Dalam hal ini, penurunan AUC kurang dari 0,03. Sepengetahuan kami, ini adalah studi sistematis pertama tentang efek himpunan data berisik untuk identifikasi laporan bug keamanan.
PEKERJAAN DI MASA MENDATANG
Dalam makalah ini kami telah memulai studi sistematis tentang efek kebisingan dalam performa pengklasifikasi pembelajaran mesin untuk identifikasi bug keamanan. Ada beberapa lanjutan yang menarik untuk pekerjaan ini, termasuk: memeriksa efek kumpulan data yang berisik dalam menentukan tingkat keparahan bug keamanan; memahami efek ketidakseimbangan kelas pada ketahanan model terlatih terhadap kebisingan; memahami efek kebisingan yang diperkenalkan secara sengaja untuk tujuan mengganggu dalam kumpulan data.
REFERENSI
[1] John Anvik, Lyndon Hiew, dan Gail C Murphy. Siapa yang harus memperbaiki bug ini? Dalam Prosiding konferensi internasional ke-28 tentang rekayasa perangkat lunak, halaman 361–370. ACM, 2006.
[2] Diksha Behl, Sahil Handa, dan Anuja Arora. Alat penambangan bug untuk mengidentifikasi dan menganalisis bug keamanan menggunakan naive Bayes dan tf-idf. Dalam Optimasi, Reliabilitas, dan Teknologi Informasi (ICROIT), Konferensi Internasional 2014 pada, halaman 294–299. IEEE, 2014.
[3] Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann, dan Sunghun Kim. Laporan bug duplikat dianggap berbahaya benar-benar? Dalam pemeliharaan perangkat lunak , 2008. ICSM 2008. Konferensi Internasional IEEE tentang, halaman 337–345. IEEE, 2008.
[4] Andres Folleco, Taghi M Khoshgoftaar, Jason Van Hulse, dan Lofton Bullard. Mengidentifikasi pelajar yang kuat terhadap data berkualitas rendah. Dalam Penggunaan Ulang dan Integrasi Informasi, 2008. IRI 2008. Konferensi Internasional IEEE tentang, halaman 190–195. IEEE, 2008.
[5] Benoˆıt Frenay.' Ketidakpastian dan kebisingan label dalam pembelajaran mesin. Tesis PhD, Universitas Katolik Louvain, Louvain-la-Neuve, Belgia, 2013.
[6] Benoˆıt Frenay dan Michel Verleysen. Klasifikasi dengan adanya kebisingan label: survei. transaksi IEEE pada jaringan neural dan sistem pembelajaran, 25(5):845–869, 2014.
[7] Michael Gegick, Pete Rotella, dan Tao Xie. Mengidentifikasi laporan bug keamanan melalui penambangan teks: Studi kasus industri. Dalam Mining software repositories (MSR), konferensi kerja IEEE ke-7 tahun 2010 tentang, halaman 11–20. IEEE, 2010.
[8] Katerina Goseva-Popstojanova dan Jacob Tyo. Identifikasi laporan bug terkait keamanan melalui penambangan teks menggunakan klasifikasi yang diawasi dan tidak diawasi. Dalam 2018 IEEE International Conference on Software Quality, Reliability and Security (QRS), halaman 344–355, 2018.
[9] Ahmed Lamkanfi, Serge Demeyer, Emanuel Giger, dan Bart Goethals. Memprediksi tingkat keparahan bug yang dilaporkan. Dalam Mining Software Repositories (MSR), Konferensi Kerja IEEE ke-7 2010 tentang, halaman 1–10. IEEE, 2010.
[10] Naresh Manwani dan PS Sastry. Toleransi kebisingan di bawah minimisasi risiko. transaksi IEEE padacybernetics , 43(3):1146–1151, 2013.
[11] G Murphy dan D Cubranic. Triase masalah otomatis menggunakan pengelompokan teks. Dalam Proses Konferensi Internasional Keenam Belas tentang Rekayasa Perangkat Lunak & Teknik Pengetahuan. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen, dan Oleksandr Pechenizkiy. Kebisingan kelas dan pembelajaran yang diawasi dalam domain medis: Efek ekstraksi fitur. Dalam null, halaman 708–713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre, dan Gerard Dedieu. Efek kebisingan label kelas pelatihan pada kinerja klasifikasi untuk pemetaan penutup lahan dengan citra satelit deret waktu. Penginderaan Jauh, 9(2):173, 2017.
[14] PS Sastry, GD Nagendra, dan Naresh Manwani. Tim automata pembelajaran berkelanjutan untuk pembelajaran setengah ruang yang toleran terhadap kebisingan. Transaksi IEEE pada Sistem, Manusia, dan Cybernetics, Bagian B (Cybernetics), 40(1):19–28, 2010.
[15] Choh-Man Teng. Perbandingan teknik penanganan kebisingan. Dalam FLAIRS Conference, halaman 269–273, 2001.
[16] Dumidu Wijayasekara, Milos Manic, dan Miles McQueen. Identifikasi dan klasifikasi kerentanan melalui database bug penambangan teks. Dalam Industrial Electronics Society, IECON 2014-40th Annual Conference of the IEEE, halaman 3612–3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia, dan Jianling Sun. Identifikasi otomatis laporan bug berdampak tinggi yang memanfaatkan strategi pembelajaran yang tidak seimbang. Dalam Computer Software and Applications Conference (COMPSAC), 2016 IEEE 40th Annual, volume 1, halaman 227–232. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Zhen Li, dan Hai Jin. Mengidentifikasi laporan bug keamanan secara otomatis melalui analisis fitur multitipe. Dalam Konferensi Australasian tentang Keamanan Informasi dan Privasi, halaman 619–633. Springer, 2018.