Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Oleh Andrew Marshall, Jugal Parikh, Emre Kiciman dan Ram Shankar Siva Kumar
Terima Kasih Khusus untuk Raul Rojas dan AETHER Security Engineering Workstream
November 2019
Dokumen ini adalah hasil dari Praktik Teknik AETHER untuk AI Working Group dan melengkapi praktik pemodelan ancaman SDL yang ada dengan memberikan panduan baru tentang enumerasi dan mitigasi ancaman khusus untuk ruang AI dan Pembelajaran Mesin. Ini dimaksudkan untuk digunakan sebagai referensi selama tinjauan desain keamanan berikut:
Produk/layanan yang berinteraksi dengan atau mengambil dependensi pada layanan berbasis AI/ML
Produk/layanan yang dibangun dengan AI/ML pada intinya
Mitigasi ancaman keamanan tradisional lebih penting dari sebelumnya. Persyaratan yang ditetapkan oleh Siklus Hidup Pengembangan Keamanan sangat penting untuk membangun fondasi keamanan produk yang dibangun panduan ini. Kegagalan untuk mengatasi ancaman keamanan tradisional membantu memudahkan terjadinya serangan khusus AI/ML yang tercakup dalam dokumen ini di domain perangkat lunak dan fisik, serta membuat proses kompromi menjadi sepele pada level yang lebih rendah di tumpukan perangkat lunak. Untuk pengenalan ancaman keamanan baru di ruang ini, lihat Mengamankan Masa Depan AI dan ML di Microsoft.
Keterampilan teknisi keamanan dan ilmuwan data biasanya tidak tumpang tindih. Panduan ini memberikan cara bagi kedua disiplin ilmu untuk memiliki percakapan terstruktur tentang ancaman/mitigasi baru ini tanpa mengharuskan teknisi keamanan menjadi ilmuwan data atau sebaliknya.
Dokumen ini dibagi menjadi dua bagian:
- "Pertimbangan Baru Utama dalam Pemodelan Ancaman" berfokus pada cara berpikir baru dan pertanyaan baru untuk diajukan saat pemodelan ancaman sistem AI/ML. Baik ilmuwan data maupun insinyur keamanan harus meninjau ini karena akan menjadi playbook mereka untuk diskusi pemodelan ancaman dan prioritas mitigasi.
- "Ancaman khusus AI/ML dan Mitigasinya" memberikan detail tentang serangan tertentu serta langkah-langkah mitigasi tertentu yang digunakan saat ini untuk melindungi produk dan layanan Microsoft dari ancaman ini. Bagian ini terutama ditargetkan pada ilmuwan data yang mungkin perlu menerapkan mitigasi ancaman tertentu sebagai output dari proses pemodelan ancaman/peninjauan keamanan.
Panduan ini diselenggarakan di sekitar Taksonomi Ancaman Pembelajaran Mesin Adversarial yang dibuat oleh Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen, dan Jeffrey Snover berjudul "Mode Kegagalan dalam Pembelajaran Mesin." Untuk panduan manajemen insiden tentang memilah ancaman keamanan yang dirinci dalam dokumen ini, lihat Bilah Bug SDL untuk Ancaman AI/ML. Semua ini adalah dokumen dinamis yang akan terus berkembang seiring dengan lanskap ancaman.
Pertimbangan Baru Utama dalam Pemodelan Ancaman: Mengubah cara Anda melihat Batas Kepercayaan
Asumsikan adanya kompromi/keracunan baik pada data yang digunakan untuk pelatihan Anda maupun pada penyedia data. Pelajari cara mendeteksi entri data anomali dan berbahaya serta dapat membedakan antara dan memulihkannya
Ringkasan
Penyimpanan Data Pelatihan dan sistem yang menghostingnya adalah bagian dari cakupan Pemodelan Ancaman Anda. Ancaman keamanan terbesar dalam pembelajaran mesin saat ini adalah keracunan data karena kurangnya deteksi standar dan mitigasi di ruang ini, dikombinasikan dengan ketergantungan pada himpunan data publik yang tidak tepercaya/tidak diakui sebagai sumber data pelatihan. Melacak bukti dan silsilah data Anda sangat penting untuk memastikan kepercayaannya dan menghindari siklus pelatihan "sampah masuk, sampah keluar".
Pertanyaan untuk Diajukan dalam Tinjauan Keamanan
Jika data Anda diracuni atau dirusak, bagaimana Anda tahu?
- Telemetri apa yang Anda miliki untuk mendeteksi penyimpangan dalam kualitas data pelatihan Anda?
Apakah Anda berlatih dari input yang disediakan pengguna?
-Apa jenis input validasi / sanitasi yang Anda lakukan pada konten itu?
-Apakah struktur data ini didokumentasikan mirip dengan Lembar Data untuk Himpunan Data?
Jika Anda berlatih melawan penyimpanan data online, langkah apa yang Anda ambil untuk memastikan keamanan koneksi antara model Anda dan data?
- Apakah mereka memiliki cara untuk melaporkan pelanggaran keamanan kepada konsumen umpan mereka?
-Apakah mereka bahkan mampu itu?
Seberapa sensitif data yang Anda gunakan untuk pelatihan?
-Apakah Anda membuat katalog atau mengontrol penambahan/pembaruan/penghapusan entri data?
Dapatkah model Anda menghasilkan data sensitif?
-Apakah data ini diperoleh dengan izin dari sumber?
Apakah model hanya menghasilkan hasil yang diperlukan untuk mencapai tujuannya?
Apakah model Anda mengembalikan skor keyakinan mentah atau output langsung lainnya yang dapat direkam dan diduplikasi?
Apa dampak dari data pelatihan Anda yang dipulihkan melalui penyerangan atau pembalikan model Anda?
Jika tingkat keyakinan output model Anda tiba-tiba turun, dapatkah Anda mengetahui bagaimana/mengapa, serta data yang menyebabkannya?
Apakah Anda telah mendefinisikan input yang terdefinisi dengan baik untuk model Anda? Apa yang Anda lakukan untuk memastikan input memenuhi format ini dan apa yang Anda lakukan jika tidak?
Jika output Anda salah tetapi tidak menyebabkan kesalahan dilaporkan, bagaimana Anda tahu?
Apakah Anda tahu apakah algoritma pelatihan Anda tahan terhadap input musuh pada tingkat matematika?
Bagaimana Anda memulihkan diri dari kontaminasi adversarial pada data pelatihan Anda?
-Dapatkah Anda mengkarantina konten adversarial dan melatih ulang model yang terpengaruh?
-Dapatkah Anda mengembalikan/memulihkan ke model versi sebelumnya untuk pelatihan ulang?
Apakah Anda menggunakan Reinforcement Learning pada konten publik yang tidak dikurasi?
Mulailah berpikir tentang silsilah data Anda - apakah Anda menemukan masalah, bisakah Anda melacaknya untuk pengenalannya ke dalam himpunan data? Jika tidak, apakah itu masalah?
Ketahui dari mana data pelatihan Anda berasal dan identifikasi norma statistik untuk mulai memahami seperti apa anomali
-Apa elemen data pelatihan Anda rentan terhadap pengaruh luar?
-Siapa yang dapat berkontribusi pada himpunan data yang sedang Anda gunakan untuk melatih?
-Bagaimana Anda akan menyerang sumber data pelatihan Anda untuk membahayakan pesaing?
Ancaman dan Mitigasi Terkait dalam Dokumen ini
Gangguan Adversarial (semua varian)
Keracunan Data (semua varian)
Contoh Serangan
Memaksa email jinak diklasifikasikan sebagai spam atau menyebabkan contoh berbahaya tidak terdeteksi
Input yang dirancang oleh penyerang yang mengurangi tingkat kepercayaan klasifikasi yang benar, terutama dalam skenario dengan konsekuensi tinggi
Penyerang menyuntikkan kebisingan secara acak ke dalam data sumber yang diklasifikasikan untuk mengurangi kemungkinan klasifikasi yang benar yang digunakan di masa depan, secara efektif menyamarkan model
Kontaminasi data pelatihan untuk memaksa kesalahan klasifikasi titik data tertentu, yang mengakibatkan tindakan tertentu diambil atau dihilangkan oleh sistem
Mengidentifikasi tindakan yang dapat dilakukan model atau produk/layanan Anda yang dapat menyebabkan bahaya pelanggan secara online atau di domain fisik
Ringkasan
Dibiarkan tidak terkendali, serangan pada sistem AI/ML dapat berdampak pada dunia fisik. Skenario apa pun yang dapat dipelintir untuk membahayakan pengguna secara psikologis atau fisik adalah risiko bencana bagi produk/layanan Anda. Ini meluas ke data sensitif apa pun tentang pelanggan Anda yang digunakan untuk pelatihan dan pilihan desain yang dapat membocorkan poin data privat tersebut.
Pertanyaan untuk Diajukan dalam Tinjauan Keamanan
Apakah Anda berlatih dengan contoh musuh? Dampak apa yang mereka miliki pada output model Anda di domain fisik?
Bagaimana bentuk trolling terhadap produk/layanan Anda? Bagaimana Anda dapat mendeteksi dan meresponsnya?
Apa yang diperlukan untuk membuat model Anda mengembalikan hasil yang mengelabui layanan Anda sehingga menolak akses ke pengguna yang sah?
Apa dampak model Anda yang disalin/dicuri?
Dapatkah model Anda digunakan untuk menyimpulkan keanggotaan seseorang dalam grup tertentu, atau hanya dalam data pelatihan?
Dapatkah penyerang menyebabkan kerusakan reputasi atau kesulitan PR pada produk Anda dengan membuatnya melakukan tindakan tertentu?
Bagaimana Anda menangani data yang diformat dengan benar tetapi terlalu bias, seperti dari troll?
Untuk setiap cara berinteraksi dengan atau mengkueri model Anda terekspos, bisakah metode tersebut diinterogasi untuk mengungkapkan data pelatihan atau fungsionalitas model?
Ancaman dan Mitigasi Terkait dalam Dokumen ini
Inferensi Keanggotaan
Inversi Model
Pencurian Model
Contoh Serangan
Rekonstruksi dan ekstraksi data pelatihan dengan berulang kali mengkueri model untuk hasil keyakinan maksimum
Duplikasi model itu sendiri dengan pencocokan kueri/respons yang menyeluruh
Mengkueri model dengan cara yang mengungkapkan elemen tertentu dari data privat disertakan dalam set pelatihan
Mobil tanpa pengemudi dikelabui untuk mengabaikan rambu berhenti atau lampu lalu lintas.
Bot percakapan dimanipulasi untuk mengganggu pengguna yang tidak berbahaya
Mengidentifikasi semua sumber dependensi AI/ML serta lapisan presentasi frontend dalam rantai pasokan data/model Anda
Ringkasan
Banyak serangan di AI dan Pembelajaran Mesin dimulai dengan akses sah ke API yang muncul untuk menyediakan akses kueri ke model. Karena sumber data yang melimpah dan pengalaman pengguna yang kaya terlibat di sini, akses pihak ketiga yang telah terautentikasi namun "tidak pantas" (ada area abu-abu di sini) ke model Anda merupakan risiko karena dapat berfungsi sebagai lapisan presentasi di atas layanan dari Microsoft.
Pertanyaan untuk Diajukan dalam Tinjauan Keamanan
Pelanggan/mitra mana yang diautentikasi untuk mengakses api model atau layanan Anda?
-Dapatkah mereka bertindak sebagai lapisan presentasi di atas layanan Anda?
-Dapatkah Anda mencabut akses mereka segera jika terjadi kompromi?
-Apa strategi pemulihan Anda jika terjadi penggunaan layanan atau dependensi berbahaya Anda?
Dapatkah pihakketiga membangun fasad di sekitar model Anda untuk merancangnya kembali dan membahayakan Microsoft atau pelanggannya?
Apakah pelanggan memberikan data pelatihan kepada Anda secara langsung?
-Bagaimana Anda mengamankan data itu?
-Bagaimana jika itu berbahaya dan layanan Anda adalah target?
Seperti apa bentuk positif palsu di sini? Apa dampak dari false-negative?
Dapatkah Anda melacak dan mengukur penyimpangan tingkat Positif Benar vs Positif Palsu di beberapa model?
Telemetri seperti apa yang Anda butuhkan untuk membuktikan kepercayaan output model Anda kepada pelanggan Anda?
Identifikasi semua dependensi pihakketiga dalam rantai pasokan data ML/Pelatihan Anda - bukan hanya perangkat lunak sumber terbuka, tetapi juga penyedia data
-Mengapa Anda menggunakannya dan bagaimana Anda memverifikasi kepercayaan mereka?
Apakah Anda menggunakan model bawaan dari pihakke-3 atau mengirimkan data pelatihan ke penyedia MLaaS pihakketiga ?
Inventarisasi berita mengenai serangan terhadap produk/layanan serupa. Memahami bahwa banyak ancaman AI/ML ditransfer antar jenis model, apa dampak serangan ini terhadap produk Anda sendiri?
Ancaman dan Mitigasi Terkait dalam Dokumen ini
Pemrograman Ulang Neural Net
Contoh-contoh Adversarial di domain fisik
Pemulihan Data Pelatihan oleh Penyedia Pembelajaran Mesin Berbahaya
Menyerang Rantai Pasokan ML
Model dengan Akses Pintu Belakang
Dependensi khusus ML yang telah dikompromikan
Contoh Serangan
Penyedia MLaaS berbahaya memasukkan trojan ke dalam model Anda untuk mengakali cek keamanan tertentu.
Pelanggan lawan menemukan kerentanan dalam dependensi OSS umum yang Anda gunakan, mengunggah payload data pelatihan yang dirancang untuk mengkompromikan layanan Anda
Mitra yang tidak bermoral menggunakan API pengenalan wajah dan membuat lapisan presentasi di atas layanan Anda untuk menghasilkan Deep Fakes.
Ancaman khusus AI/ML dan Mitigasinya
#1: Perturbasi Adversarial
Deskripsi
Dalam serangan modifikasi gaya perturbasi, penyerang dengan diam-diam memodifikasi kueri agar mendapatkan respons yang diinginkan dari model yang dideploy di lingkungan produksi[1]. Ini adalah pelanggaran integritas input pada model yang mengarah pada serangan bergaya fuzzing, di mana hasil akhirnya tidak selalu berupa pelanggaran akses atau peningkatan hak istimewa, tetapi justru membahayakan performa klasifikasi model. Ini juga dapat dimanifestasikan oleh troll yang menggunakan kata-kata target tertentu dengan cara yang membuat AI melarang mereka, sehingga layanan ditolak untuk pengguna yang sah dengan nama yang cocok dengan kata "dilarang".
 [24]
[24]
Varian #1a: Kesalahan klasifikasi yang ditargetkan
Dalam hal ini penyerang menghasilkan sampel yang tidak berada di kelas input pengklasifikasi target tetapi diklasifikasikan oleh model sebagai kelas input tertentu. Sampel adversarial dapat tampak seperti kebisingan acak di mata manusia, namun, penyerang memiliki pengetahuan tertentu tentang sistem pembelajaran mesin target untuk menghasilkan suara putih yang tidak acak tetapi mengeksploitasi beberapa aspek spesifik dari model target. Lawan memberikan sampel input yang bukan sampel yang sah, tetapi sistem target mengklasifikasikannya sebagai kelas yang sah.
Contoh
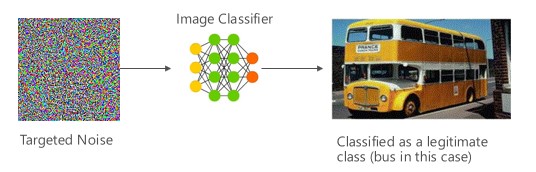 [6]
[6]
Mitigasi
Memperkuat Ketahanan Adversarial menggunakan Keyakinan Model yang Diinduksi oleh Pelatihan Adversarial [19]: Penulis mengusulkan Highly Confident Near Neighbor (HCNN), kerangka kerja yang menggabungkan informasi keyakinan dan pencarian tetangga terdekat, untuk memperkuat ketahanan adversarial dari model dasar. Ini dapat membantu membedakan antara prediksi model yang benar dan salah di lingkungan titik yang diambil sampelnya dari distribusi pelatihan yang mendasar.
Analisis Kausal berbasis atribusi [20]: Penulis mempelajari koneksi antara ketahanan terhadap perturbasi lawan dan penjelasan berbasis atribusi dari keputusan individu yang dihasilkan oleh model pembelajaran mesin. Mereka melaporkan bahwa input lawan tidak tangguh dalam ruang atribusi, yaitu menyembunyikan beberapa fitur dengan atribusi tinggi menyebabkan ketidakpastian perubahan dalam model pembelajaran mesin pada contoh lawan. Sebaliknya, input alami memiliki ketahanan di ruang atribusi.
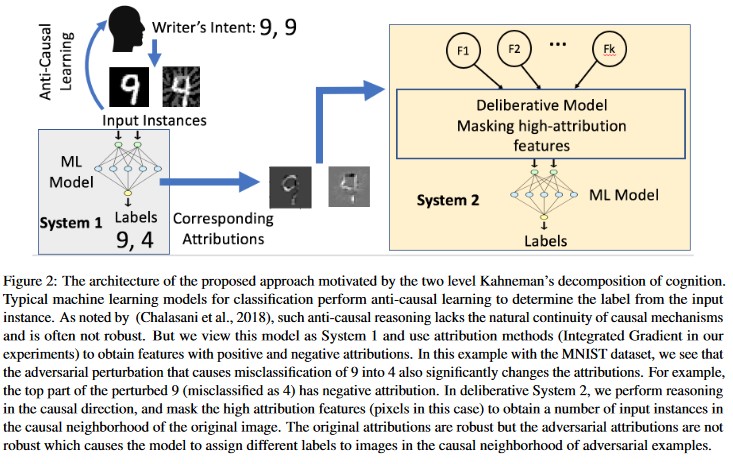 [20]
[20]
Pendekatan ini dapat membuat model pembelajaran mesin lebih tangguh terhadap serangan musuh karena membodohi sistem kognisi dua lapisan ini tidak hanya membutuhkan serangan model asli tetapi juga memastikan bahwa atribusi yang dihasilkan untuk contoh musuh mirip dengan contoh asli. Kedua sistem harus secara bersamaan diretas untuk serangan lawan yang berhasil.
Paralel Tradisional
Peningkatan Hak Istimewa dari Jarak Jauh karena penyerang sekarang memiliki kendali atas model Anda
Tingkat Keparahan
Penting
Varian #1b: Kesalahan klasifikasi Sumber/Target
Ini ditandai sebagai upaya penyerang agar model mengembalikan label yang diinginkan untuk input tertentu. Ini biasanya memaksa model menghasilkan positif palsu atau negatif palsu. Hasil akhirnya adalah pengambilalihan yang halus atas akurasi klasifikasi model, di mana penyerang dapat menginduksi bypass tertentu sesuka hati.
Meskipun serangan ini memiliki dampak yang merugikan yang signifikan terhadap akurasi klasifikasi, juga dapat memerlukan waktu lebih untuk dilakukan mengingat bahwa pihak penyerang tidak hanya harus memanipulasi data sumber sehingga tidak lagi diberi label dengan benar, tetapi juga diberi label palsu yang diinginkan. Serangan ini sering melibatkan beberapa langkah/upaya untuk memaksa kesalahan klasifikasi [3]. Jika model rentan terhadap serangan pembelajaran transfer yang memaksakan mis-klasifikasi yang terarah, mungkin tidak ada jejak lalu lintas penyerang yang dapat dikenali karena serangan pemeriksaan dapat dilakukan secara offline.
Contoh
Memaksa email jinak diklasifikasikan sebagai spam atau menyebabkan contoh berbahaya tidak terdeteksi. Ini juga dikenal sebagai serangan pengelakan atau mimikri model.
Mitigasi
Tindakan Deteksi Reaktif/Defensif
- Terapkan ambang waktu minimum antara panggilan ke API yang memberikan hasil klasifikasi. Ini memperlambat pengujian serangan multi-langkah dengan meningkatkan jumlah waktu keseluruhan yang diperlukan untuk menemukan perturbasi keberhasilan.
Tindakan Proaktif/Protektif
Fitur Denoising untuk Meningkatkan Ketahanan terhadap Serangan Adversarial [22]: Penulis mengembangkan arsitektur jaringan baru yang meningkatkan ketahanan terhadap serangan adversarial dengan melakukan denoising fitur. Secara khusus, jaringan berisi blok yang menghilangkan noise dari fitur menggunakan cara non-lokal atau filter lainnya; seluruh jaringan tersebut dilatih secara end-to-end. Ketika dikombinasikan dengan pelatihan musuh, fitur mendenoisi jaringan secara substansial meningkatkan tingkat ketahanan musuh dalam pengaturan serangan kotak putih dan kotak hitam.
Pelatihan dan Regularisasi Adversarial: Latih dengan sampel lawan yang diketahui untuk membangun ketahanan dan perlawanan terhadap input jahat. Ini juga dapat dilihat sebagai bentuk regularisasi, yang menambahkan sanksi pada norma gradien input dan membuat fungsi prediksi klasifikasi menjadi lebih halus dengan meningkatkan margin input. Ini termasuk klasifikasi yang benar dengan tingkat keyakinan yang lebih rendah.
Berinvestasi dalam mengembangkan klasifikasi monotonik dengan pemilihan fitur monotonik. Ini memastikan bahwa lawan tidak akan dapat menghindari pengklasifikasi hanya dengan menambahkan fitur dari kelas negatif [13].
Kompresi fitur [18] dapat digunakan untuk memperkuat model DNN dengan mendeteksi contoh adversarial. Ini mengurangi ruang pencarian yang tersedia untuk lawan dengan menggabungkan sampel-sampel yang berasal dari berbagai vektor fitur di ruang awal menjadi satu sampel. Dengan membandingkan prediksi model DNN pada input asli dengan yang pada input yang dipersempit, pemerasan fitur dapat membantu mendeteksi contoh adversarial. Jika contoh asli dan dipadatkan menghasilkan output yang jauh berbeda dari model, input kemungkinan bersifat menentang. Dengan mengukur ketidaksesuaian di antara prediksi dan memilih nilai ambang batas, sistem dapat menghasilkan prediksi yang benar untuk contoh yang sah dan menolak input adversarial.

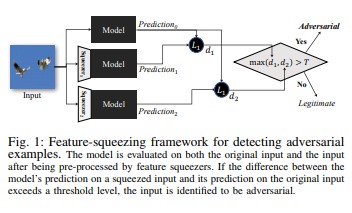 [18]
[18]Pertahanan Bersertifikat terhadap Contoh Adversarial [22]: Penulis mengusulkan metode berdasarkan relaksasi semi-pasti yang menghasilkan sertifikat yang untuk jaringan tertentu dan input pengujian, tidak ada serangan yang dapat memaksa kesalahan melebihi nilai tertentu. Kedua, karena sertifikat ini dapat dibedakan, penulis bersama-sama mengoptimalkannya dengan parameter jaringan, menyediakan regularizer adaptif yang mendorong ketahanan terhadap semua serangan.
Tindakan Respons
- Mengeluarkan pemberitahuan tentang hasil klasifikasi dengan varians tinggi antara pengklasifikasi, terutama jika dari satu pengguna atau sekelompok kecil pengguna.
Paralel Tradisional
Peningkatan Hak Istimewa dari Jarak Jauh
Tingkat Keparahan
Penting
Varian #1c: Kesalahan klasifikasi acak
Ini adalah variasi khusus di mana klasifikasi target penyerang dapat menjadi apa pun selain klasifikasi sumber yang sah. Serangan ini umumnya melibatkan injeksi kebisingan secara acak ke dalam data sumber yang diklasifikasikan untuk mengurangi kemungkinan klasifikasi yang benar yang digunakan di masa depan [3].
Contoh
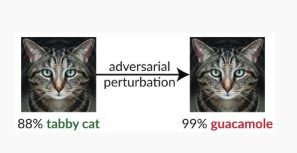
Mitigasi
Sama seperti Varian 1a.
Paralel Tradisional
Penolakan layanan yang tidak persisten
Tingkat Keparahan
Penting
Varian #1d: Pengurangan Keyakinan
Penyerang dapat membuat input untuk mengurangi tingkat keyakinan klasifikasi yang benar, terutama dalam skenario konsekuensi tinggi. Ini juga dapat berbentuk sejumlah besar positif palsu yang dimaksudkan untuk membanjiri administrator atau sistem pemantauan dengan peringatan palsu yang tidak bisa dibedakan dari peringatan yang sah [3].
Contoh

Mitigasi
- Selain tindakan yang tercakup dalam Varian #1a, pengendalian peristiwa dapat digunakan untuk mengurangi volume notifikasi dari satu sumber.
Paralel Tradisional
Penolakan layanan yang tidak persisten
Tingkat Keparahan
Penting
#2a Keracunan Data Yang Ditargetkan
Deskripsi
Tujuan dari penyerang adalah untuk mencemari model mesin yang dihasilkan dalam fase pelatihan, sehingga prediksi pada data baru akan dimodifikasi dalam fase pengujian[1]. Dalam serangan keracunan yang ditargetkan, penyerang ingin salah mengklasifikasikan contoh tertentu untuk menyebabkan tindakan tertentu diambil atau dihilangkan.
Contoh
Mengirimkan perangkat lunak AV sebagai malware untuk memaksa kesalahan klasifikasinya sebagai berbahaya dan menghilangkan penggunaan perangkat lunak AV yang ditargetkan pada sistem klien.
Mitigasi
Tentukan sensor anomali untuk melihat distribusi data setiap hari dan memperingatkan pada variasi
-Mengukur variasi data pelatihan setiap hari dan memantau data telemetri untuk pembelokan/penyimpangan.
Validasi masukan, baik sanitasi maupun pemeriksaan integritas
Keracunan menyuntikkan sampel pelatihan terluar. Dua strategi utama untuk melawan ancaman ini:
-Sanitasi Data/ validasi: hapus sampel keracunan dari data pelatihan -Bagging untuk memerangi serangan keracunan [14]
Pertahanan -Reject-on-Negative-Impact (RONI) [15]
-Robust Learning: Pilih algoritma pembelajaran yang kuat di hadapan sampel keracunan.
-Salah satu pendekatan tersebut dijelaskan dalam [21] di mana penulis mengatasi masalah keracunan data dalam dua langkah: 1) memperkenalkan metode faktorisasi matriks yang kuat untuk memulihkan subspace yang sebenarnya, dan 2) regresi komponen prinsip kuat baru untuk memangkas instans musuh berdasarkan dasar yang dipulihkan pada langkah (1). Mereka mencirikan kondisi yang diperlukan dan cukup untuk berhasil memulihkan subruang yang sebenarnya dan menyajikan batas pada kerugian prediksi yang diharapkan dibandingkan dengan kebenaran sebenarnya.
Paralel Tradisional
Host Troya di mana penyerang bertahan di jaringan. Data pelatihan dan konfigurasi terkompromi dan diproses/digunakan untuk pembuatan model.
Tingkat Keparahan
Penting
#2b Keracunan Data Yang Tidak Dapat Dibedakan
Deskripsi
Tujuannya adalah untuk merusak kualitas/integritas himpunan data yang diserang. Banyak himpunan data bersifat publik/tidak tepercaya/tidak diakui, sehingga ini menciptakan kekhawatiran tambahan sekeliling kemampuan untuk menemukan pelanggaran integritas data tersebut di tempat pertama. Pelatihan pada data yang telah dikompromikan tanpa disadari adalah fenomena sampah masuk/sampah keluar. Setelah terdeteksi, proses triase perlu menentukan tingkat pelanggaran data dan melakukan karantina/pelatihan ulang.
Contoh
Sebuah perusahaan mengambil data dari situs web terkenal dan tepercaya tentang berjangka minyak untuk melatih model mereka. Situs web penyedia data kemudian disusupi melalui serangan Injeksi SQL. Penyerang dapat meracuni himpunan data sekehendaknya, sementara model yang dilatih tidak menyadari bahwa data telah ternoda.
Mitigasi
Sama seperti varian 2a.
Paralel Tradisional
Penolakan layanan terautentikasi terhadap aset bernilai tinggi
Tingkat Keparahan
Penting
#3 Serangan Inversi Model
Deskripsi
Fitur privat yang digunakan dalam model pembelajaran mesin dapat dipulihkan [1]. Ini termasuk rekonstruksi data pelatihan privat yang tidak dapat diakses oleh penyerang. Juga dikenal sebagai serangan pendakian bukit di komunitas biometrik [16, 17] Ini dicapai dengan menemukan input yang memaksimalkan tingkat keyakinan yang dikembalikan, tunduk pada klasifikasi yang cocok dengan target [4].
Contoh
 [4]
[4]
Mitigasi
Antarmuka ke model yang dilatih dari data sensitif membutuhkan kontrol akses yang kuat.
Kueri batas tarif yang diizinkan oleh model
Terapkan gerbang antara pengguna/penelepon dan model aktual dengan melakukan validasi input pada semua kueri yang diusulkan, menolak apa pun yang tidak memenuhi definisi model dari kebenaran input dan mengembalikan hanya jumlah minimum informasi yang diperlukan untuk berguna.
Paralel Tradisional
Pengungkapan Informasi terselubung yang ditargetkan
Tingkat Keparahan
Ini secara default dianggap penting menurut bilah bug standar SDL, tetapi jika ada data sensitif atau dapat diidentifikasi secara pribadi yang diekstraksi, hal ini akan meningkat menjadi kritis.
#4 Serangan Inferensi Keanggotaan
Deskripsi
Penyerang dapat menentukan apakah rekaman data tertentu adalah bagian dari himpunan data pelatihan model atau tidak[1]. Peneliti dapat memprediksi prosedur utama pasien (misalnya: Operasi yang dilalui pasien) berdasarkan atribut (misalnya: usia, jenis kelamin, rumah sakit) [1].
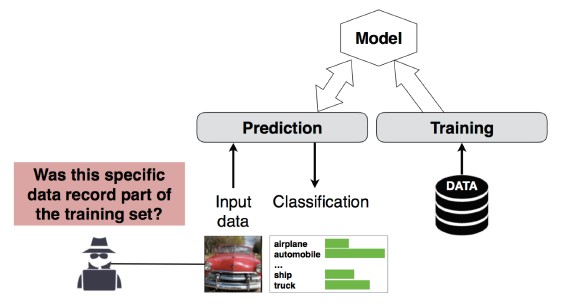 [12]
[12]
Mitigasi
Makalah penelitian yang menunjukkan kelangsungan serangan ini menunjukkan Privasi Diferensial [4, 9] akan menjadi mitigasi yang efektif. Ini masih merupakan bidang terbaru di Microsoft dan AETHER Security Engineering merekomendasikan untuk membangun keahlian dengan investasi penelitian di ruang ini. Penelitian ini perlu menghitung kemampuan Privasi Diferensial dan mengevaluasi efektivitas praktis mereka sebagai mitigasi, kemudian merancang cara agar pertahanan ini diwariskan secara transparan pada platform layanan online kami, mirip dengan cara mengkompilasi kode di Visual Studio memberi Anda perlindungan keamanan on-by-default yang transparan bagi pengembang dan pengguna.
Penggunaan dropout neuron dan penumpukan model dapat menjadi mitigasi yang efektif sampai batas tertentu. Menggunakan dropout neuron tidak hanya meningkatkan ketahanan jaring neural terhadap serangan ini, tetapi juga meningkatkan performa model [4].
Paralel Tradisional
Privasi Data. Inferensi sedang dibuat tentang penyertaan titik data dalam set pelatihan tetapi data pelatihan itu sendiri tidak diungkapkan
Tingkat Keparahan
Ini adalah masalah privasi, bukan masalah keamanan. Ini ditangani dalam panduan pemodelan ancaman karena domain tumpang tindih, tetapi respons apa pun di sini akan didorong oleh Privasi, bukan Keamanan.
#5 Mencuri Model
Deskripsi
Penyerang membuat ulang model yang mendasar dengan mengkueri model secara sah. Fungsionalitas model baru sama dengan model yang mendasar[1]. Setelah model dibuat ulang, model dapat dibalik untuk memulihkan informasi fitur atau membuat inferensi pada data pelatihan.
Pemecahan persamaan – Untuk model yang mengembalikan probabilitas kelas melalui output API, penyerang dapat membuat kueri untuk menentukan variabel yang tidak diketahui dalam model.
Path Finding – serangan yang mengeksploitasi kekhususan API untuk mengekstrak 'keputusan' yang diambil oleh pohon saat mengklasifikasikan input [7].
Serangan transferabilitas - Penyerang dapat melatih model lokal—mungkin dengan mengeluarkan kueri prediksi ke model yang ditargetkan—dan menggunakannya untuk membuat contoh musuh yang dapat ditransfer ke model target [8]. Jika model Anda diekstrak dan ditemukan rentan terhadap jenis input musuh, serangan baru terhadap model yang disebarkan produksi Anda dapat dikembangkan sepenuhnya secara offline oleh penyerang yang mengekstrak salinan model Anda.
Contoh
Dalam pengaturan di mana model ML berfungsi untuk mendeteksi perilaku musuh, seperti identifikasi spam, klasifikasi malware, dan deteksi anomali jaringan, ekstraksi model dapat memfasilitasi serangan pengindaran [7].
Mitigasi
Tindakan Proaktif/Protektif
Minimalkan atau usamkan detail yang dikembalikan dalam API prediksi sambil tetap mempertahankan kegunaannya untuk aplikasi "jujur" [7].
Tentukan kueri yang terbentuk dengan baik untuk input model Anda dan hanya mengembalikan hasil sebagai respons terhadap input lengkap dan terbentuk dengan baik yang cocok dengan format tersebut.
Mengembalikan nilai kepercayaan yang telah dibulatkan. Sebagian besar penelepon yang sah tidak memerlukan beberapa tempat desimal presisi.
Paralel Tradisional
Pengubahan data sistem tanpa autentikasi, mode baca-saja, dan pengungkapan informasi bernilai tinggi yang ditargetkan?
Tingkat Keparahan
Penting dalam model sensitif keamanan, biasa saja dalam situasi lainnya
#6 Pemrograman Ulang Neural Net
Deskripsi
Dengan kueri yang dirancang secara khusus oleh penyerang, sistem pembelajaran mesin dapat diprogram ulang ke tugas yang menyimpang dari tujuan awal pencipta [1].
Contoh
Kontrol akses yang lemah pada API pengenalan wajah memungkinkan pihak ketiga untuk mengintegrasikan ke dalam aplikasi yang dirancang untuk membahayakan pelanggan Microsoft, seperti generator deepfake.
Mitigasi
Autentikasi dua arah yang kuat antara klien dan server serta kontrol akses ke antarmuka model
Penghapusan akun yang menyinggung.
Mengidentifikasi dan menerapkan perjanjian tingkat layanan untuk API Anda. Tentukan waktu untuk memperbaiki masalah yang dapat diterima setelah dilaporkan dan pastikan masalah tidak lagi diproses ulang setelah SLA kedaluwarsa.
Paralel Tradisional
Ini adalah skenario penyalahgunaan. Anda lebih kecil kemungkinannya untuk membuka insiden keamanan tentang hal ini daripada Anda hanya menonaktifkan akun pelaku.
Tingkat Keparahan
Penting hingga Kritis
Contoh Kasus Adversarial di Domain Fisik (bits-ke-atom>)
Deskripsi
Contoh adversarial adalah input/kueri dari entitas berbahaya yang dikirim dengan satu-satunya tujuan menyesatkan sistem pembelajaran mesin [1]
Contoh
Contoh-contoh ini dapat bermanifestasi di domain fisik, seperti mobil mengemudi sendiri yang ditipu untuk menjalankan tanda berhenti karena warna cahaya tertentu (input adversarial) bersinar pada tanda berhenti, memaksa sistem pengenalan gambar untuk tidak lagi melihat tanda berhenti sebagai tanda berhenti.
Paralel Tradisional
Peningkatan Hak Akses, eksekusi kode jarak jauh
Mitigasi
Serangan ini memanifestasikan diri karena masalah di lapisan pembelajaran mesin (lapisan data & algoritma di bawah pembuatan keputusan berbasis AI) tidak dimitigasi. Seperti halnya perangkat lunak lain *atau* sistem fisik, lapisan di bawah target selalu dapat diserang melalui vektor tradisional. Karena itu, praktik keamanan tradisional lebih penting dari sebelumnya, terutama dengan lapisan kerentanan yang tidak dimitigasi (lapisan data/algo) yang digunakan antara AI dan perangkat lunak tradisional.
Tingkat Keparahan
Penting
#8 Penyedia ML berbahaya yang dapat memulihkan data pelatihan
Deskripsi
Penyedia berbahaya menyajikan algoritma yang memiliki celah belakang, di mana data pelatihan pribadi diambil. Mereka mampu merekonstruksi wajah dan teks, hanya dengan model tersebut.
Paralel Tradisional
Pengungkapan informasi yang ditargetkan
Mitigasi
Makalah penelitian yang menunjukkan kelangsungan serangan ini menunjukkan Enkripsi Homomorfik akan menjadi mitigasi yang efektif. Ini adalah area dengan sedikit investasi saat ini di Microsoft, dan AETHER Security Engineering merekomendasikan membangun keahlian dengan investasi penelitian di bidang ini. Penelitian ini perlu menghitung tenet Enkripsi Homomorfik dan mengevaluasi efektivitas praktis mereka sebagai mitigasi dalam menghadapi penyedia ML-as-a-Service yang berbahaya.
Tingkat Keparahan
Penting jika data adalah PII, Memoderasi sebaliknya
#9 Menyerang Rantai Pasokan ML
Deskripsi
Karena sumber daya besar (data + komputasi) yang diperlukan untuk melatih algoritma, praktik saat ini adalah menggunakan kembali model yang dilatih oleh perusahaan besar dan memodifikasinya sedikit untuk tugas yang ditangani (misalnya: ResNet adalah model pengenalan gambar populer dari Microsoft). Model-model ini dikurasi dalam Galeri Model (Caffe menghosting model pengenalan gambar yang populer). Dalam serangan ini, musuh menyerang model yang dihosting di Caffe, sehingga meracuni sumur untuk orang lain. [1]
Paralel Tradisional
Kompromi dependensi pihak ketiga yang tidak berkaitan dengan keamanan
Toko aplikasi tanpa sadar menghosting malware
Mitigasi
Minimalkan dependensi pihak ketiga untuk model dan data jika memungkinkan.
Masukkan dependensi ini ke dalam proses pemodelan ancaman Anda.
Manfaatkan autentikasi yang kuat, kontrol akses, dan enkripsi antara sistem pihakketiga 1st/3.
Tingkat Keparahan
Penting
#10 Mesin Pembelajaran Pintu Belakang
Deskripsi
Proses pelatihan dialihdayakan kepada pihak ke-3 berbahaya yang merusak data pelatihan dan mengirimkan model trojaned yang memaksa klasifikasi salah sasaran, seperti mengklasifikasikan virus tertentu sebagai tidak berbahaya[1]. Ini adalah risiko dalam skenario pembuatan model ML-as-a-Service.
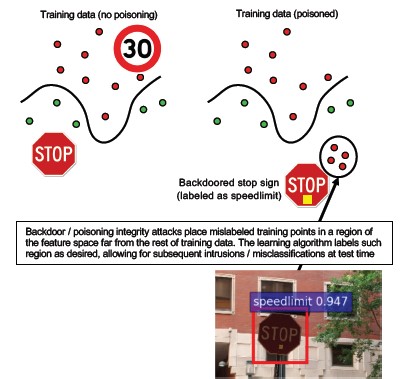 [12]
[12]
Paralel Tradisional
Kompromi keamanan dependensi pihak ketiga
Mekanisme Pembaruan Perangkat Lunak yang Disusupi
Kompromi Otoritas Sertifikat
Mitigasi
Tindakan Deteksi Reaktif/Defensif
- Kerusakan sudah dilakukan setelah ancaman ini ditemukan, sehingga model dan data pelatihan apa pun yang disediakan oleh penyedia berbahaya tidak dapat dipercaya.
Tindakan Proaktif/Protektif
Melatih semua model yang sensitif secara internal
Data pelatihan katalog atau pastikan data tersebut berasal dari pihak ketiga yang terpercaya yang memiliki praktik keamanan yang kuat
Model ancaman interaksi antara penyedia MLaaS dan sistem Anda sendiri
Tindakan Respons
- Sama seperti untuk kompromi dependensi eksternal
Tingkat Keparahan
Penting
#11 Mengeksploitasi dependensi perangkat lunak dari sistem ML
Deskripsi
Dalam serangan ini, penyerang TIDAK memanipulasi algoritma. Sebaliknya, mengeksploitasi kerentanan perangkat lunak seperti luapan buffer atau scripting lintas situs[1]. Masih lebih mudah untuk membahayakan lapisan perangkat lunak di bawah AI/ML daripada menyerang lapisan pembelajaran secara langsung, sehingga praktik mitigasi ancaman keamanan tradisional yang dirinci dalam Siklus Hidup Pengembangan Keamanan sangat penting.
Paralel Tradisional
Dependensi Sumber Terbuka Perangkat Lunak yang Terkompromi
Kerentanan server web (XSS, CSRF, kegagalan validasi input API)
Mitigasi
Bekerja sama dengan tim keamanan Anda untuk mengikuti praktik terbaik Security Development Lifecycle/Operational Security Assurance yang berlaku.
Tingkat Keparahan
Variabel; Hingga Kritis tergantung pada jenis kerentanan perangkat lunak tradisional.
Bibliografi
[1] Mode Kegagalan dalam Pembelajaran Mesin, Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen, dan Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] AETHER Security Engineering Workstream, Data Provenance/Lineage v-team
[3] Contoh Adversarial dalam Pembelajaran Mendalam: Karakterisasi dan Divergensi, Wei, et al, https://arxiv.org/pdf/1807.00051.pdf
[4] Kebocoran ML: Serangan dan Pertahanan Inferensi Keanggotaan yang Independen dari Model dan Data pada Model Pembelajaran Mesin, Salem, et al, https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha, dan T. Ristenpart, "Serangan Inversi Model yang Mengeksploitasi Informasi Keyakinan dan Penanggulangan Dasar," dalam Proses Konferensi ACM SIGSAC 2015 tentang Keamanan Komputer dan Komunikasi (CCS).
[6] Nicolas Papernot & Patrick McDaniel- Contoh Adversarial dalam Pembelajaran Mesin AIWTB 2017
[7] Mencuri Model Pembelajaran Mesin melalui API Prediksi, Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, Universitas Carolina Utara di Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] Ruang Contoh Adversarial yang Dapat Ditransfer, Florian Tramèr , Nicolas Papernot , Ian Goodfellow , Dan Boneh , dan Patrick McDaniel
[9] Memahami Inferensi Keanggotaan pada Model Pembelajaran Well-Generalized Yunhui Long1 , Vincent Bindschaedler1 , Lei Wang2 , Diyue Bu2 , Xiaofeng Wang2 , Haixu Tang2 , Carl A. Gunter1 , dan Kai Chen3,4
[10] Simon-Gabriel et al., Kerentanan jaringan neural terhadap serangan adversarial meningkat seiring dengan dimensi input, ArXiv 2018.
[11] Lyu et al., Sebuah keluarga regularisasi gradien terpadu untuk contoh adversarial, ICDM 2015
[12] Pola Liar: Sepuluh Tahun Setelah Kebangkitan Pembelajaran Mesin Adversarial - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Deteksi Malware yang Kuat Secara Adversarial Menggunakan KlasifikasiMonotonik Inigo Incer dkk.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto, dan Fabio Roli. Pengklasifikasi Bagging untuk Memerangi Serangan Keracunan dalam Tugas Klasifikasi Adversarial
[15] Peningkatan Mekanisme Pertahanan terhadap Dampak Negatif oleh Hongjiang Li dan Patrick P.K. Chan
[16] Adler. Kerentanan dalam sistem enkripsi biometrik. Konferensi Internasional ke-5. AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. Pada kerentanan sistem verifikasi wajah terhadap serangan pendakian bukit. Patt. Rec., 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Pengurangan Fitur: Mendeteksi Contoh Adversarial di Jaringan Neural Mendalam. Simposium Keamanan Jaringan dan Sistem Terdistribusi 2018. 18-21 Februari.
[19] Memperkuat Ketahanan Adversarial menggunakan Kepercayaan Model yang Diinduksi oleh Pelatihan Adversarial - Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Analisis Kausal berbasis Atribusi untuk Deteksi Contoh Adversarial, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Regresi Linier yang Kuat Terhadap Keracunan Data Pelatihan – Chang Liu dkk.
[22] Fitur Menjijikkan untuk Meningkatkan Ketahanan Adversarial, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Pertahanan Tersertifikasi terhadap Contoh yang Memusuhi - Aditi Raghunathan, Jacob Steinhardt, Percy Liang