Menyebarkan Kluster Big Data SQL Server dengan ketersediaan tinggi
Berlaku untuk:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Penting
Add-on Kluster Big Data Microsoft SQL Server 2019 akan dihentikan. Dukungan untuk SQL Server 2019 Kluster Big Data akan berakhir pada 28 Februari 2025. Semua pengguna SQL Server 2019 yang ada dengan Jaminan Perangkat Lunak akan didukung sepenuhnya pada platform dan perangkat lunak akan terus dipertahankan melalui pembaruan kumulatif SQL Server hingga saat itu. Untuk informasi selengkapnya, lihat posting blog pengumuman dan Opsi big data di platform Microsoft SQL Server.
Karena Kluster Big Data SQL Server ada di Kubernetes sebagai aplikasi kontainer, dan menggunakan fitur seperti set stateful dan penyimpanan persisten, infrastruktur ini memiliki pemantauan kesehatan bawaan, deteksi kegagalan, dan mekanisme failover yang dimanfaatkan komponen kluster untuk menjaga kesehatan layanan. Untuk meningkatkan keandalan, Anda juga dapat mengonfigurasi instans master SQL Server dan/atau node nama HDFS dan layanan bersama Spark untuk disebarkan dengan replika tambahan dalam konfigurasi ketersediaan tinggi. Pemantauan, deteksi kegagalan, dan failover otomatis dikelola oleh layanan manajemen kluster big data, yaitu layanan kontrol. Layanan ini disediakan tanpa intervensi pengguna - semua dari penyiapan grup ketersediaan, mengonfigurasi titik akhir pencerminan database, hingga menambahkan database ke grup ketersediaan atau kegagalan dan meningkatkan koordinasi.
Gambar berikut menunjukkan bagaimana grup ketersediaan disebarkan di Kluster Big Data SQL Server:
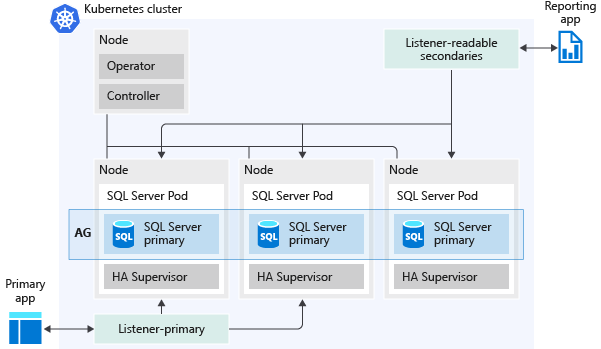
Berikut adalah beberapa kemampuan yang diaktifkan grup ketersediaan:
Jika pengaturan ketersediaan tinggi ditentukan dalam file konfigurasi penyebaran, satu grup ketersediaan bernama
containedagdibuat. Secara default,containedagmemiliki tiga replika, termasuk primer. Semua operasi CRUD untuk grup ketersediaan dikelola secara internal, termasuk membuat grup ketersediaan atau menggabungkan replika ke grup ketersediaan yang dibuat. Grup ketersediaan tambahan tidak dapat dibuat di instans master SQL Server dalam kluster big data.Semua database secara otomatis ditambahkan ke grup ketersediaan, termasuk semua database pengguna dan sistem seperti
masterdanmsdb. Kapabilitas ini menyediakan tampilan sistem tunggal di seluruh replika grup ketersediaan. Database model tambahan -model_replicatedmasterdanmodel_msdb- digunakan untuk menyemai bagian database sistem yang direplikasi. Selain database ini, Anda akan melihatcontainedag_masterdatabase dancontainedag_msdbjika Anda terhubung langsung ke instans. Databasecontainedagmewakilimasterdanmsdbdalam grup ketersediaan.Penting
Database yang dibuat pada instans sebagai hasil dari alur kerja, seperti melampirkan database, tidak secara otomatis ditambahkan ke grup ketersediaan. Administrator Kluster Big Data SQL Server harus melakukan ini secara manual. Untuk mempelajari cara mengaktifkan titik akhir sementara ke database master instans SQL Server, lihat Koneksi ke instans SQL Server. Sebelum rilis CU2 SQL Server 2019, database yang dibuat sebagai hasil dari pernyataan pemulihan memiliki perilaku yang sama, dan database harus ditambahkan secara manual ke grup ketersediaan yang terkandung.
Database konfigurasi PolyBase tidak disertakan dalam grup ketersediaan karena menyertakan metadata tingkat instans khusus untuk setiap replika.
Titik akhir eksternal secara otomatis disediakan untuk tersambung ke database dalam grup ketersediaan. Titik akhir
master-svc-externalini memainkan peran pendengar grup ketersediaan.Titik akhir eksternal kedua disediakan untuk koneksi baca-saja ke replika sekunder untuk meluaskan skala beban kerja baca.
Sebarkan
Untuk menyebarkan master SQL Server dalam grup ketersediaan:
hadrMengaktifkan fitur- Tentukan jumlah replika untuk AG (minimum adalah 3)
- Mengonfigurasi detail titik akhir eksternal kedua yang dibuat untuk koneksi ke replika sekunder baca-saja
Anda dapat menggunakan profil konfigurasi bawaan aks-dev-test-ha atau kubeadm-prod untuk mulai menyesuaikan kluster big data Anda. Profil ini mencakup pengaturan yang diperlukan untuk sumber daya yang dapat Anda konfigurasikan ketersediaan tinggi tambahan. Misalnya, di bawah ini adalah bagian dalam bdc.json file konfigurasi yang relevan untuk mengaktifkan grup ketersediaan untuk instans master SQL Server.
{
...
"spec": {
"type": "Master",
"replicas": 3,
"endpoints": [
{
"name": "Master",
"serviceType": "LoadBalancer",
"port": 31433
},
{
"name": "MasterSecondary",
"serviceType": "LoadBalancer",
"port": 31436
}
],
"settings": {
"sql": {
"hadr.enabled": "true"
}
}
}
...
}
Langkah-langkah berikut menelusuri contoh tentang cara memulai dari aks-dev-test-ha profil dan menyesuaikan konfigurasi penyebaran kluster big data Anda. Untuk penyebaran pada kubeadm kluster, langkah serupa akan berlaku, tetapi pastikan Anda menggunakan NodePort untuk serviceType di bagian tersebut endpoints .
Mengkloning profil yang Ditargetkan
azdata bdc config init --source aks-dev-test-ha --target custom-aks-haSecara opsional, lakukan pengeditan ke profil kustom seperlunya.
Mulai penyebaran kluster menggunakan profil konfigurasi kluster yang dibuat di atas
azdata bdc create --config-profile custom-aks-ha --accept-eula yes
Koneksi ke database SQL Server dalam grup ketersediaan
Bergantung pada jenis beban kerja yang ingin Anda jalankan terhadap master SQL Server, Anda dapat menyambungkan ke utama untuk beban kerja baca-tulis atau ke database di replika sekunder untuk jenis beban kerja baca-saja. Berikut adalah kerangka untuk setiap jenis koneksi:
Koneksi ke database pada replika utama
Untuk koneksi ke replika utama, gunakan sql-server-master titik akhir. Titik akhir ini juga merupakan pendengar untuk AG. Saat menggunakan titik akhir ini, semua koneksi berada dalam konteks database dalam grup ketersediaan. Misalnya, koneksi default yang menggunakan titik akhir ini akan mengakibatkan koneksi ke master database dalam grup ketersediaan, bukan database instans master SQL Server. Jalankan perintah ini untuk menemukan titik akhir:
azdata bdc endpoint list -e sql-server-master -o table
Description Endpoint Name Protocol
------------------------------------ ------------------- ----------------- ----------
SQL Server Master Instance Front-End 11.11.111.111,11111 sql-server-master tds
Catatan
Peristiwa failover dapat terjadi selama eksekusi kueri terdistribusi yang mengakses data dari sumber data jarak jauh seperti HDFS atau kumpulan data. Sebagai praktik terbaik, aplikasi harus dirancang untuk memiliki logika coba lagi koneksi jika terjadi pemutusan yang disebabkan oleh failover.
Koneksi ke database pada replika sekunder
Untuk koneksi baca-saja ke database di replika sekunder, gunakan sql-server-master-readonly titik akhir. Titik akhir ini bertindak seperti load balancer di semua replika sekunder. Saat menggunakan titik akhir ini, semua koneksi berada dalam konteks database dalam grup ketersediaan. Misalnya, koneksi default yang menggunakan titik akhir ini akan mengakibatkan koneksi ke master database dalam grup ketersediaan, bukan database instans master SQL Server.
azdata bdc endpoint list -e sql-server-master-readonly -o table
Description Endpoint Name Protocol
--------------------------------------------- ------------------ -------------------------- ----------
SQL Server Master Readable Secondary Replicas 11.11.111.11,11111 sql-server-master-readonly tds
Koneksi ke instans SQL Server
Untuk operasi tertentu seperti mengatur konfigurasi tingkat server atau menambahkan database secara manual ke grup ketersediaan, Anda harus tersambung ke instans SQL Server. Sebelum SQL Server 2019 CU2, operasi seperti sp_configure, RESTORE DATABASE atau grup ketersediaan DDL akan memerlukan jenis koneksi ini. Secara default, kluster big data tidak menyertakan titik akhir yang memungkinkan koneksi instans dan Anda harus mengekspos titik akhir ini secara manual.
Penting
Titik akhir yang diekspos untuk koneksi instans SQL Server hanya mendukung autentikasi SQL, bahkan di kluster tempat Direktori Aktif diaktifkan. Secara default, selama penyebaran kluster big data, sa login dinonaktifkan dan login baru sysadmin disediakan berdasarkan nilai yang disediakan pada waktu penyebaran untuk AZDATA_USERNAME variabel lingkungan dan AZDATA_PASSWORD .
Penting
DDL grup ketersediaan yang terkandung dikelola sendiri secara eksklusif di BDC. Setiap (pengguna eksternal) mencoba menghilangkan avaialbilitas yang terkandung atau titik akhir pencerminan database tidak didukung dan dapat mengakibatkan status BDC yang tidak dapat dipulihkan.
Berikut adalah contoh yang memperlihatkan cara mengekspos titik akhir ini lalu menambahkan database yang dibuat dengan alur kerja pemulihan ke grup ketersediaan. Instruksi serupa untuk menyiapkan koneksi ke instans master SQL Server berlaku saat Anda ingin mengubah konfigurasi server dengan sp_configure.
Catatan
Dimulai dengan SQL Server 2019 CU2, database yang dibuat sebagai hasil dari alur kerja pemulihan ditambahkan secara otomatis ke grup ketersediaan yang terkandung.
Tentukan pod yang menghosting replika utama dengan menyambungkan ke
sql-server-mastertitik akhir dan jalankan:SELECT @@SERVERNAMEMengekspos titik akhir eksternal dengan membuat layanan Kubernetes baru
Untuk kluster, jalankan
kubeadmperintah di bawah ini. GantipodNamedengan nama server yang dikembalikan pada langkah sebelumnya,serviceNamedengan nama pilihan untuk layanan Kubernetes yang dibuat dannamespaceName* dengan nama kluster big data Anda.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortUntuk eksekusi kluster aks, jalankan perintah yang sama, kecuali bahwa jenis layanan yang dibuat akan menjadi
LoadBalancer. Contohnya:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerBerikut adalah contoh perintah ini yang dijalankan terhadap aks, di mana pod yang menghosting primer adalah
master-0:kubectl -n mssql-cluster expose pod master-0 --port=1533 --name=master-sql-0 --type=LoadBalancerDapatkan IP dari layanan Kube yang dibuat:
kubectl get services -n <namespaceName>
Penting
Sebagai praktik terbaik, Anda harus melakukan pembersihan dengan menghapus layanan Kube yang dibuat di atas dengan menjalankan perintah ini:
kubectl delete svc master-sql-0 -n mssql-cluster
Menambahkan database ke grup ketersediaan.
Agar database ditambahkan ke AG, database harus berjalan dalam model pemulihan penuh dan cadangan log harus diambil. Gunakan IP dari layanan Kubernetes yang dibuat di atas dan sambungkan ke instans SQL Server lalu jalankan pernyataan T-SQL seperti yang ditunjukkan di bawah ini.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>Contoh berikut menambahkan database bernama
salesyang dipulihkan pada instans:ALTER DATABASE sales SET RECOVERY FULL; BACKUP DATABASE sales TO DISK='/var/opt/mssql/data/sales.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE sales
Pembatasan yang diketahui
Ini adalah masalah dan batasan yang diketahui dengan grup ketersediaan yang terkandung untuk master SQL Server di kluster big data:
- Konfigurasi ketersediaan tinggi harus dibuat ketika kluster big data disebarkan. Anda tidak dapat mengaktifkan konfigurasi ketersediaan tinggi dengan grup ketersediaan pasca penyebaran. Saat ini, hanya konfigurasi yang diaktifkan adalah untuk replika penerapan sinkron.
Peringatan
Memperbarui mode sinkronisasi ke penerapan asinkron untuk salah satu replika dalam penerapan kuorum, akan menghasilkan konfigurasi yang tidak valid untuk ketersediaan tinggi. Berjalan dalam konfigurasi ini melibatkan risiko kehilangan data karena jika terjadi peristiwa kegagalan yang memengaruhi replika utama, tidak ada failover otomatis yang dipicu dan pengguna harus menerima risiko kehilangan data saat mengeluarkan failover manual.
- Agar berhasil memulihkan database yang diaktifkan TDE dari cadangan yang dibuat di server lain, Anda harus memastikan bahwa sertifikat yang diperlukan dipulihkan pada master instans SQL Server serta master AG yang terkandung. Lihat di sini untuk contoh tentang cara mencadangkan dan memulihkan sertifikat.
- Operasi tertentu seperti menjalankan pengaturan konfigurasi server dengan
sp_configurememerlukan koneksi ke database instansmasterSQL Server, bukan grupmasterketersediaan . Anda tidak dapat menggunakan titik akhir utama yang sesuai. Ikuti instruksi untuk mengekspos titik akhir dan menyambungkan ke instans SQL Server dan jalankansp_configure. Anda hanya dapat menggunakan autentikasi SQL saat mengekspos titik akhir secara manual untuk menyambungkan ke database instansmasterSQL Server. - Meskipun database msdb yang terkandung disertakan dalam grup ketersediaan dan pekerjaan SQL Agent direplikasi di seluruh, pekerjaan hanya berjalan per jadwal pada replika utama.
- Fitur replikasi tidak didukung untuk grup ketersediaan yang terkandung. Instans SQL Server bagian dari AG yang terkandung tidak dapat berfungsi sebagai distributor atau penerbit, baik di tingkat instans atau tingkat AG yang terkandung.
- Menambahkan grup file saat membuat database tidak didukung. Sebagai solusinya, Anda dapat terlebih dahulu membuat database lalu mengeluarkan pernyataan ALTER DATABASE untuk menambahkan grup file apa pun.
- Sebelum SQL Server 2019 CU2, database yang dibuat sebagai hasil dari alur kerja selain
CREATE DATABASEdanRESTORE DATABASEsepertiCREATE DATABASE FROM SNAPSHOTtidak ditambahkan secara otomatis ke grup ketersediaan. Koneksi ke instans dan tambahkan database ke grup ketersediaan secara manual. - Service Broker dan Database Mail saat ini tidak didukung pada Kluster Big Data disebarkan dengan ketersediaan tinggi.
Langkah berikutnya
- Untuk informasi selengkapnya tentang menggunakan file konfigurasi dalam penyebaran kluster big data, lihat Cara menyebarkan SQL Server Kluster Big Data di Kubernetes.
- Untuk informasi selengkapnya tentang fitur Grup Ketersediaan untuk SQL Server, lihat Gambaran Umum Grup Ketersediaan AlwaysOn (SQL Server).
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk