Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Kluster Big Data Microsoft SQL Server 2019 dihentikan. Dukungan untuk Kluster Big Data SQL Server 2019 berakhir per 28 Februari 2025. Untuk informasi selengkapnya, lihat posting blog pengumuman dan Opsi big data di platform Microsoft SQL Server.
Tutorial ini menunjukkan cara memuat dan menjalankan notebook di Azure Data Studio pada kluster big data SQL Server 2019. Ini memungkinkan ilmuwan data dan insinyur data untuk menjalankan kode Python, R, atau Scala terhadap kluster.
Tip
Jika mau, Anda dapat mengunduh dan menjalankan skrip untuk perintah dalam tutorial ini. Untuk petunjuknya, lihat sampel Spark di GitHub.
Prerequisites
-
Alat big data
- kubectl
- Azure Data Studio
- Ekstensi SQL Server 2019
- Memuat data sampel ke dalam kluster big data Anda
Mengunduh file buku catatan sampel
Gunakan instruksi berikut untuk memuat contoh file notebook spark-sql.ipynb ke Azure Data Studio.
Buka prompt perintah bash (Linux) atau Windows PowerShell.
Navigasikan ke direktori tempat Anda ingin mengunduh file buku catatan sampel.
Jalankan perintah curl berikut untuk mengunduh file notebook dari GitHub:
curl https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/data-loading/transform-csv-files.ipynb -o transform-csv-files.ipynb
Buka buku catatan
Langkah-langkah berikut menunjukkan cara membuka file buku catatan di Azure Data Studio:
Di Azure Data Studio, sambungkan ke instans master kluster big data Anda. Untuk informasi selengkapnya, lihat Menyambungkan ke kluster big data.
Klik dua kali pada koneksi gateway HDFS/Spark di jendela Server . Lalu pilih Buka Buku Catatan.
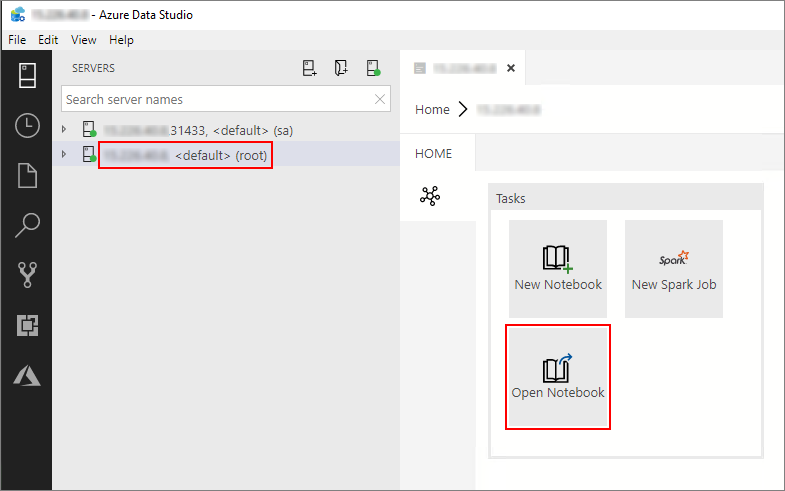
Tunggu Kernel dan konteks target (Terhubung ke) diisi. Atur Kernel ke PySpark3, dan tautkan ke alamat IP endpoint kluster big data Anda.
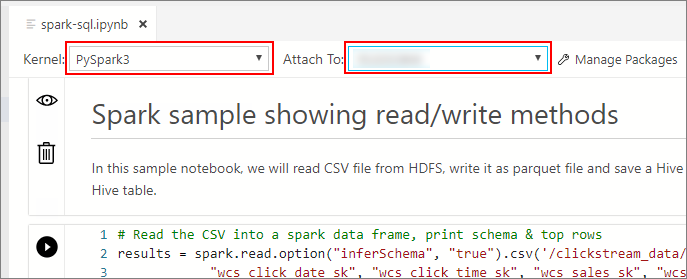
Important
Di Azure Data Studio, semua jenis buku catatan Spark (Scala Spark, PySpark, dan SparkR) secara konvensional menentukan beberapa variabel terkait sesi Spark penting setelah eksekusi sel pertama. Variabel tersebut adalah: spark, , scdan sqlContext. Saat menyalin logika dari notebook untuk pengiriman batch (ke dalam file Python yang akan dijalankan misalnya azdata bdc spark batch create ), pastikan Anda menentukan variabel yang sesuai.
Jalankan sel buku catatan
Anda bisa menjalankan setiap sel buku catatan dengan menekan tombol putar di sebelah kiri sel. Hasilnya diperlihatkan dalam buku catatan setelah sel selesai berjalan.

Jalankan setiap sel dalam contoh buku catatan secara berturut-turut. Untuk informasi selengkapnya tentang menggunakan buku catatan dengan Kluster Big Data SQL Server, lihat sumber daya berikut ini:
Next steps
Pelajari selengkapnya tentang buku catatan: