Membuat, mengekspor, dan menilai model pembelajaran mesin Spark di SQL Server Kluster Big Data
Penting
Add-on Kluster Big Data Microsoft SQL Server 2019 akan dihentikan. Dukungan untuk SQL Server 2019 Kluster Big Data akan berakhir pada 28 Februari 2025. Semua pengguna SQL Server 2019 yang ada dengan Jaminan Perangkat Lunak akan didukung sepenuhnya pada platform dan perangkat lunak akan terus dipertahankan melalui pembaruan kumulatif SQL Server hingga saat itu. Untuk informasi selengkapnya, lihat posting blog pengumuman dan Opsi big data di platform Microsoft SQL Server.
Sampel berikut menunjukkan cara membangun model dengan Spark ML, mengekspor model ke MLeap, dan menilai model di SQL Server dengan Ekstensi Bahasa Java-nya. Ini dilakukan dalam konteks kluster big data SQL Server.
Diagram berikut mengilustrasikan pekerjaan yang dilakukan dalam sampel ini:
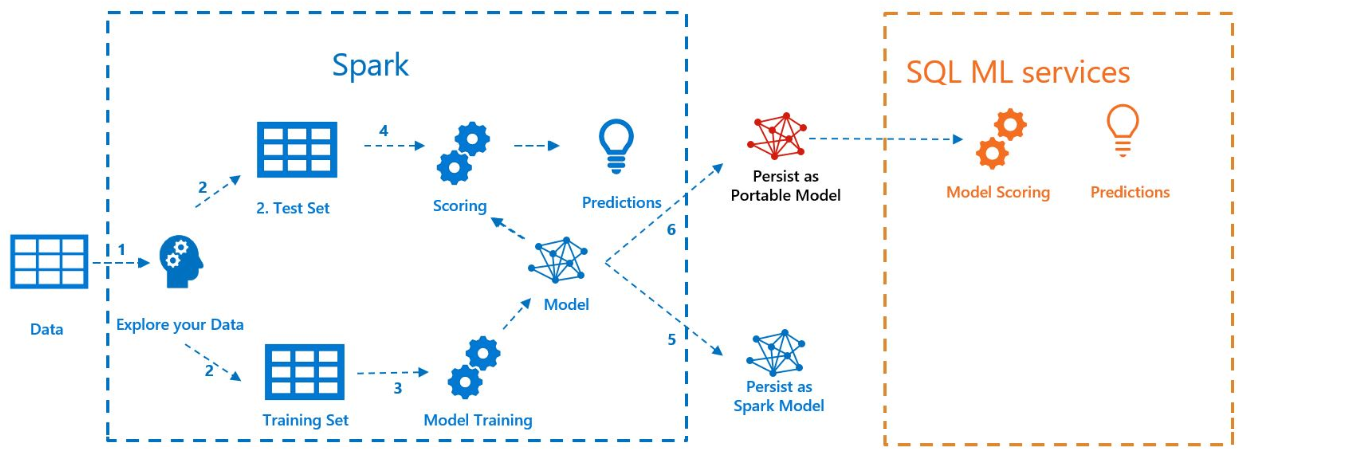
Prasyarat
Semua file untuk sampel ini terletak di https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml.
Untuk menjalankan sampel, Anda juga harus memiliki prasyarat berikut:
-
- kubectl
- curl
- Azure Data Studio
Pelatihan model dengan Spark ML
Untuk sampel ini, data sensus (AdultCensusIncome.csv) digunakan untuk membangun model alur Spark ML.
Gunakan file mleap_sql_test/setup.sh untuk mengunduh himpunan data dari internet dan meletakkannya di HDFS di kluster big data SQL Server Anda. Ini memungkinkannya diakses oleh Spark.
Kemudian unduh contoh notebook train_score_export_ml_models_with_spark.ipynb. Dari baris perintah PowerShell atau bash, jalankan perintah berikut untuk mengunduh buku catatan:
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"Buku catatan ini berisi sel dengan perintah yang diperlukan untuk bagian sampel ini.
Buka buku catatan di Azure Data Studio, dan jalankan setiap blok kode. Untuk informasi selengkapnya tentang bekerja dengan buku catatan, lihat Cara menggunakan buku catatan dengan SQL Server.
Data pertama kali dibaca ke Spark dan dibagi menjadi himpunan data pelatihan dan pengujian. Kemudian kode melatih model alur dengan data pelatihan. Terakhir, model mengekspor model ke bundel MLeap.
Tip
Anda juga dapat meninjau atau menjalankan kode Python yang terkait dengan langkah-langkah ini di luar buku catatan dalam file mleap_sql_test/mleap_pyspark.py .
Penilaian model dengan SQL Server
Sekarang setelah model alur Spark ML berada dalam format bundel MLeap serialisasi umum, Anda dapat menilai model di Java tanpa kehadiran Spark.
Sampel ini menggunakan Ekstensi Bahasa Java di SQL Server. Untuk menilai model di SQL Server, Anda harus terlebih dahulu membangun aplikasi Java yang dapat memuat model ke Java dan menilainya. Anda dapat menemukan kode sampel untuk aplikasi Java ini di folder mssql-mleap-app.
Setelah membuat sampel, Anda dapat menggunakan Transact-SQL untuk memanggil aplikasi Java dan menilai model dengan tabel database. Ini dapat dilihat di file sumber mleap_sql_test/mleap_sql_tests.py .
Langkah berikutnya
Untuk informasi selengkapnya tentang kluster big data, lihat Cara menyebarkan Kluster Big Data SQL Server di Kubernetes
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk