Debug dan Diagnosis Aplikasi Spark di SQL Server Kluster Big Data di Server Riwayat Spark
Berlaku untuk: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Penting
Add-on Kluster Big Data Microsoft SQL Server 2019 akan dihentikan. Dukungan untuk SQL Server 2019 Kluster Big Data akan berakhir pada 28 Februari 2025. Semua pengguna SQL Server 2019 yang ada dengan Jaminan Perangkat Lunak akan didukung sepenuhnya pada platform dan perangkat lunak akan terus dipertahankan melalui pembaruan kumulatif SQL Server hingga saat itu. Untuk informasi selengkapnya, lihat posting blog pengumuman dan Opsi big data di platform Microsoft SQL Server.
Artikel ini menyediakan panduan tentang cara menggunakan Server Riwayat Spark yang diperluas untuk men-debug dan mendiagnosis aplikasi Spark dalam Kluster Big Data SQL Server. Kemampuan debug dan diagnosis ini dibangun ke dalam Spark History Server dan didukung oleh Microsoft. Ekstensi ini mencakup tab data dan tab grafik dan tab diagnosis. Di tab data, pengguna dapat memeriksa data input dan output pekerjaan Spark. Di tab grafik, pengguna dapat memeriksa aliran data dan memutar ulang grafik pekerjaan. Di tab diagnosis, pengguna dapat merujuk ke Penyimpangan data, Penyimpangan waktu, dan analisis Penggunaan Pelaksana.
Mendapatkan akses ke Spark History Server
Pengalaman pengguna server riwayat Spark dari sumber terbuka ditingkatkan dengan informasi, yang mencakup data khusus pekerjaan dan visualisasi interaktif grafik pekerjaan dan aliran data untuk kluster big data.
Buka UI Web Server Riwayat Spark berdasarkan URL
Buka Spark History Server dengan menelusuri URL berikut, ganti <Ipaddress> dan <Port> dengan informasi spesifik kluster big data. Pada kluster yang disebarkan sebelum SQL Server 2019 CU 5, dengan pengaturan kluster big data autentikasi dasar (nama pengguna/kata sandi), Anda harus menyediakan akar pengguna ketika diminta untuk masuk ke titik akhir gateway (Knox). Lihat Menyebarkan kluster big data SQL Server. Dimulai dengan SQL Server 2019 (15.x) CU 5, saat Anda menyebarkan kluster baru dengan autentikasi dasar semua titik akhir termasuk penggunaan AZDATA_USERNAME gateway dan AZDATA_PASSWORD. Titik akhir pada kluster yang ditingkatkan ke CU 5 terus digunakan root sebagai nama pengguna untuk menyambungkan ke titik akhir gateway. Perubahan ini tidak berlaku untuk penyebaran menggunakan autentikasi Direktori Aktif. Lihat Kredensial untuk mengakses layanan melalui titik akhir gateway dalam catatan rilis.
https://<Ipaddress>:<Port>/gateway/default/sparkhistory
Antarmuka pengguna web Spark History Server terlihat seperti:
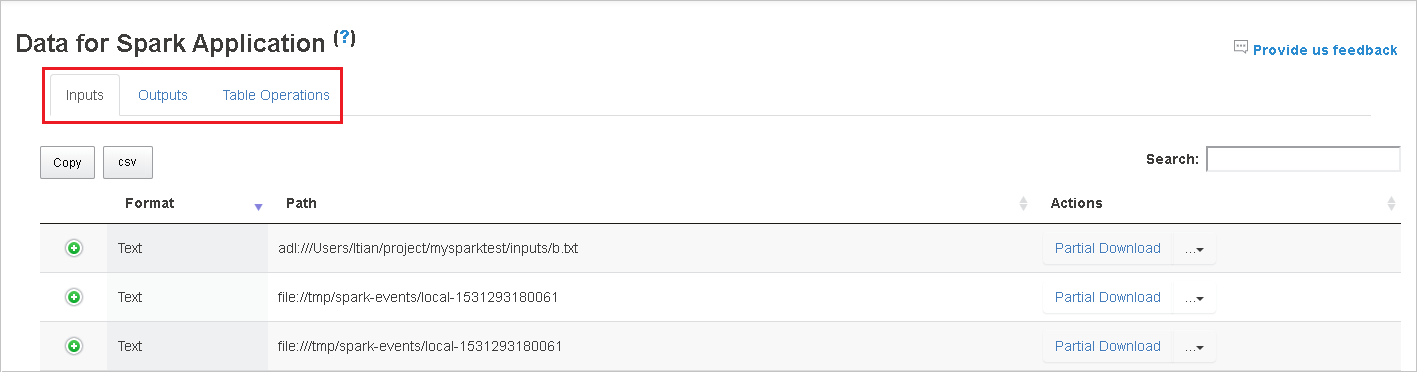
Tab Data di Server Riwayat Spark
Pilih ID pekerjaan lalu klik Data pada menu alat untuk mendapatkan tampilan data.
Periksa Input, Output, dan Operasi Tabel dengan memilih tab secara terpisah.
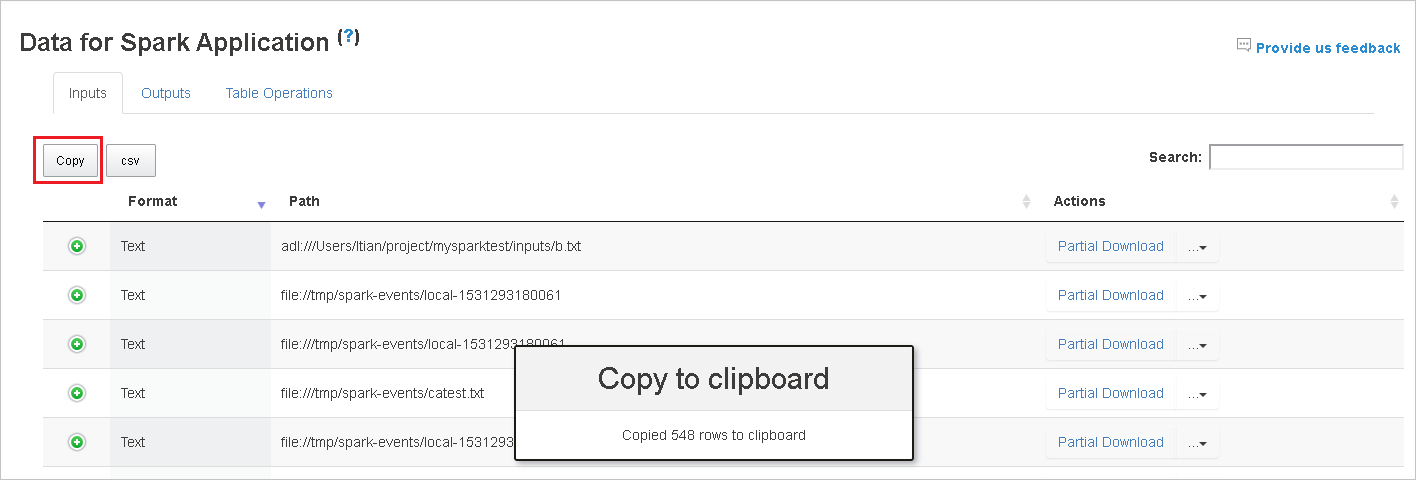
Salin semua baris dengan mengklik tombol Salin.
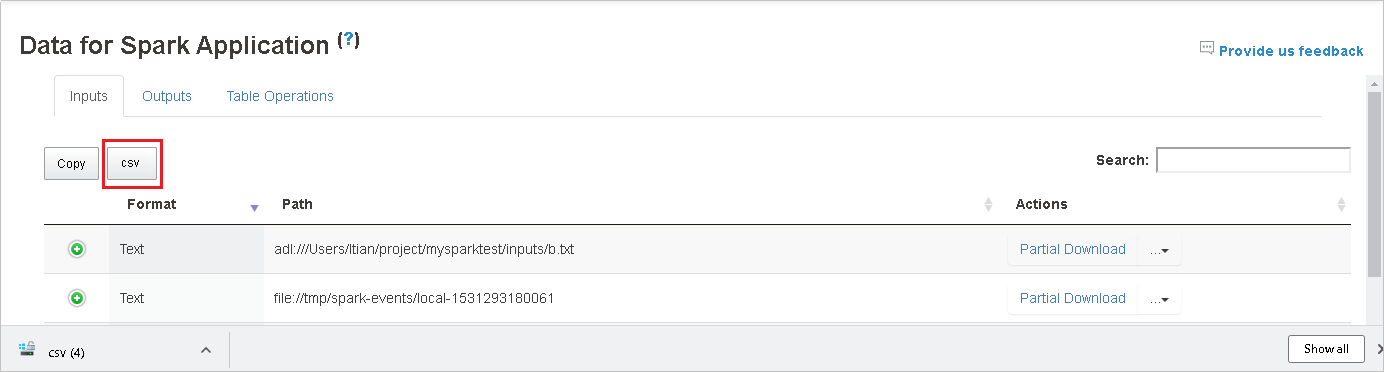
Simpan semua data sebagai file CSV dengan mengklik tombol csv.
Cari dengan memasukkan kata kunci di bidang Pencarian, hasil pencarian akan segera ditampilkan.
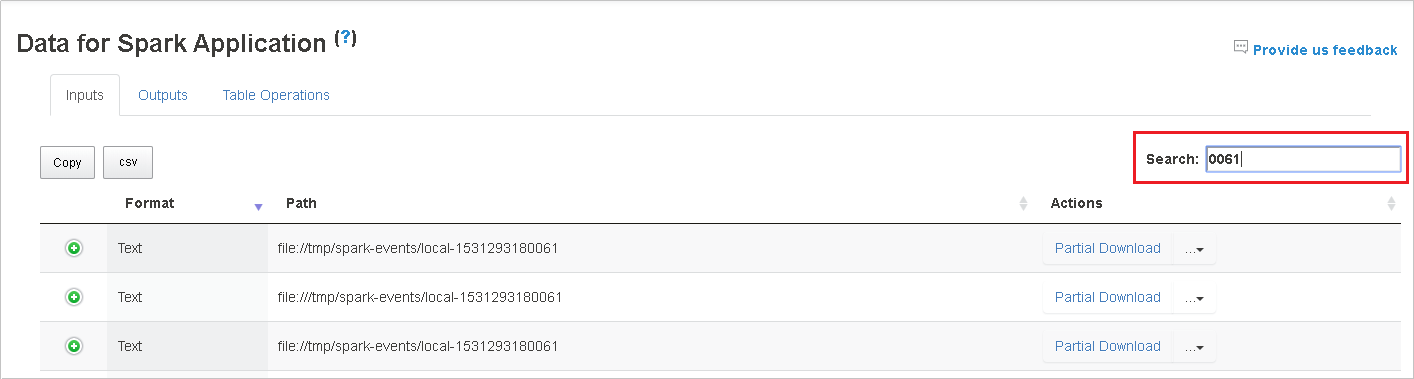
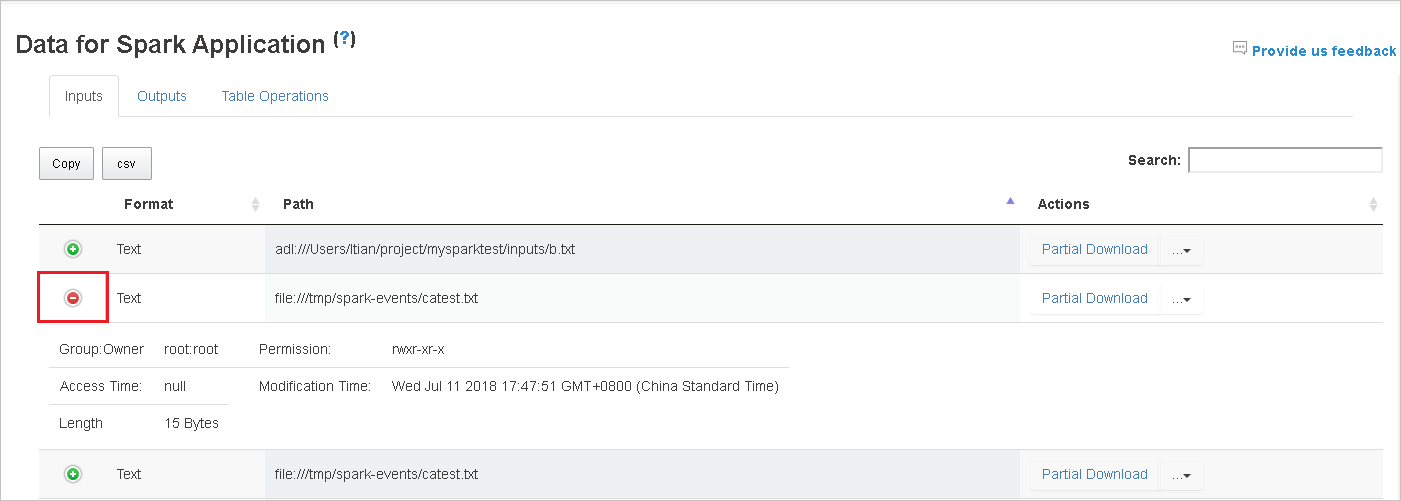
Klik header kolom untuk mengurutkan tabel, klik tanda plus untuk memperluas baris untuk memperlihatkan detail selengkapnya, atau klik tanda minus untuk menciutkan baris.
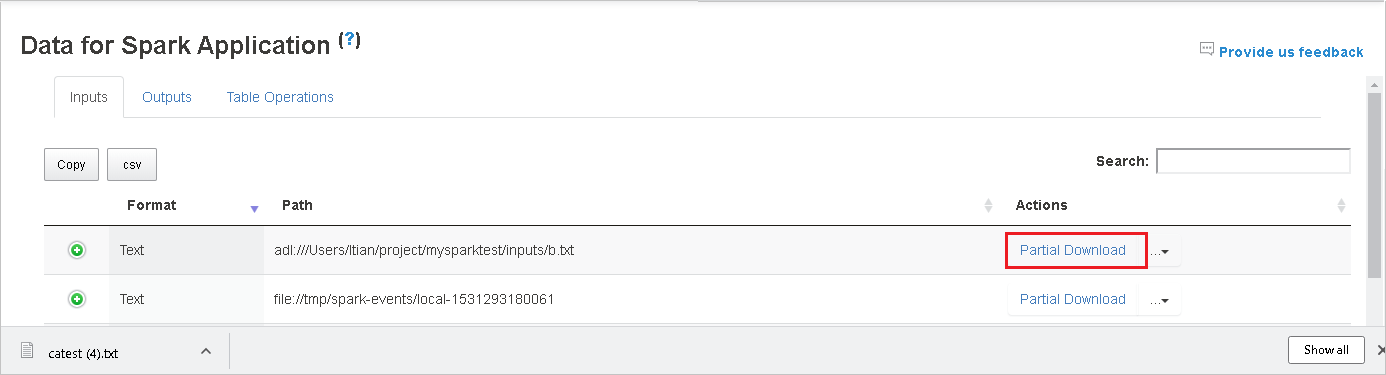
Unduh file tunggal dengan mengklik tombol Unduh Sebagian tempat itu di sebelah kanan, lalu file yang dipilih diunduh ke tempat lokal. Jika file tidak ada lagi, file akan membuka tab baru untuk menampilkan pesan kesalahan.
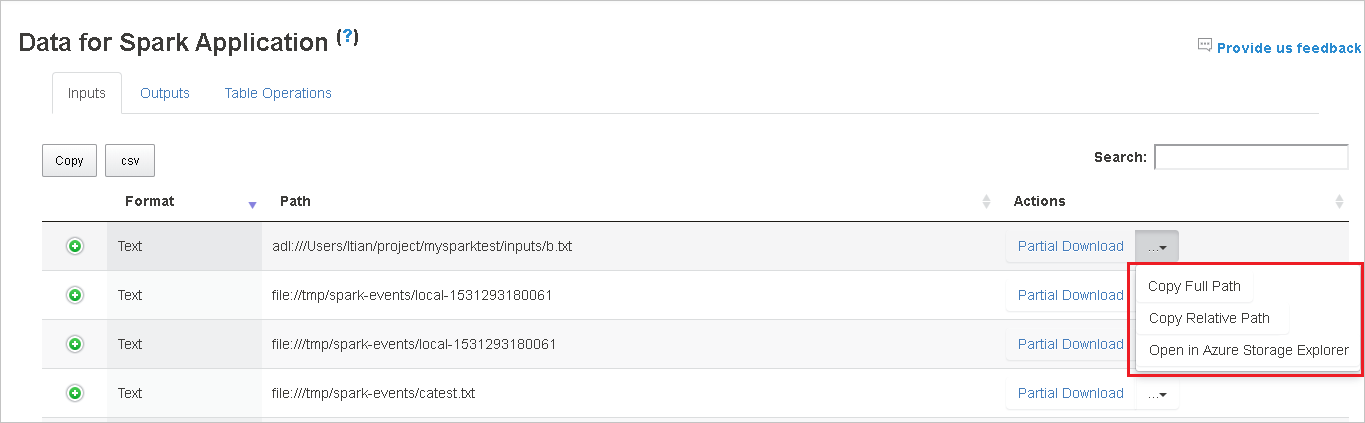
Salin jalur lengkap atau jalur relatif dengan memilih Salin Jalur Lengkap, Salin Jalur Relatif yang diperluas dari menu unduhan. Untuk file penyimpanan azure data lake, Buka di Azure Storage Explorer akan meluncurkan Azure Storage Explorer. Dan temukan ke folder yang tepat saat masuk.
Klik angka di bawah tabel untuk menavigasi halaman ketika terlalu banyak baris untuk ditampilkan dalam satu halaman.

Arahkan mouse ke tanda tanya di samping Data untuk memperlihatkan tipsalat, atau klik tanda tanya untuk mendapatkan informasi selengkapnya.
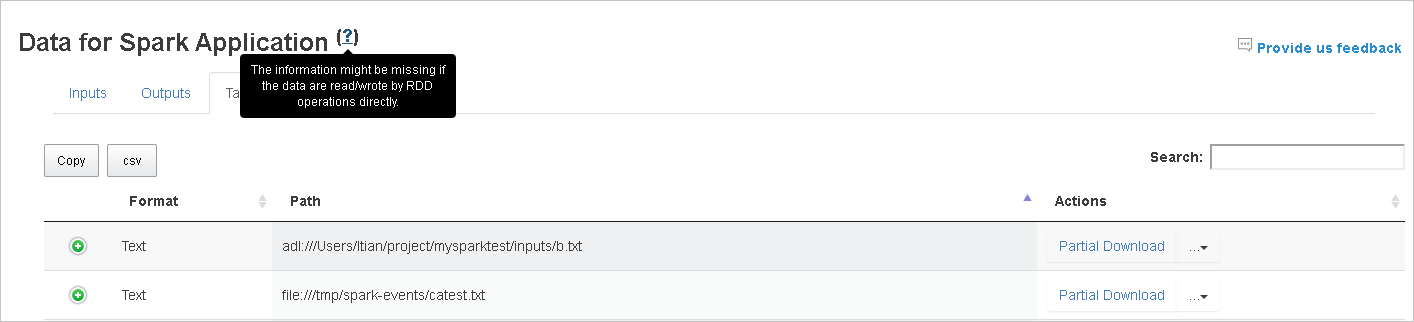
Kirim umpan balik dengan masalah dengan mengklik Berikan umpan balik kepada kami.
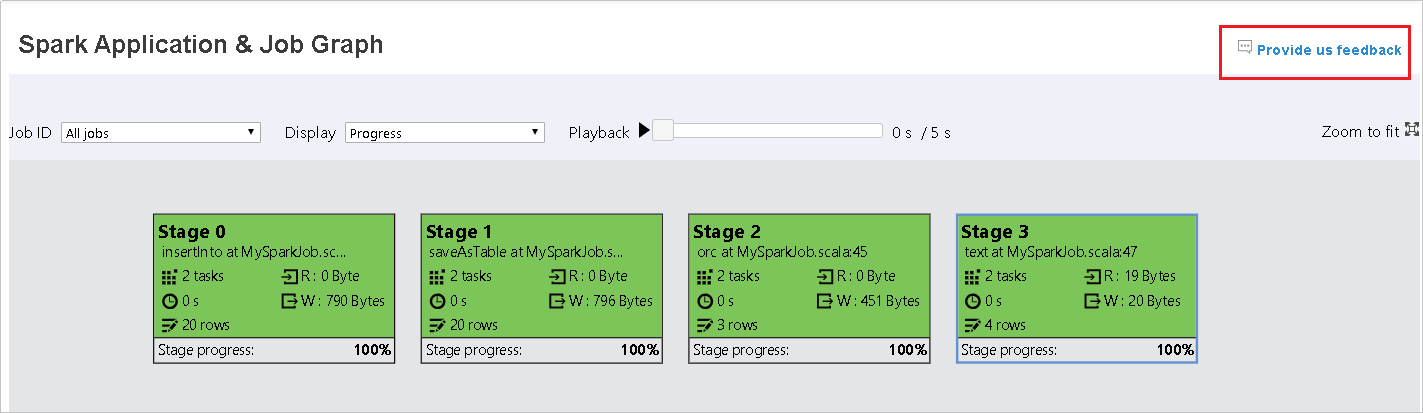
Tab Grafik di Server Riwayat Spark
Pilih ID pekerjaan lalu klik Graph pada menu alat untuk mendapatkan tampilan grafik pekerjaan.
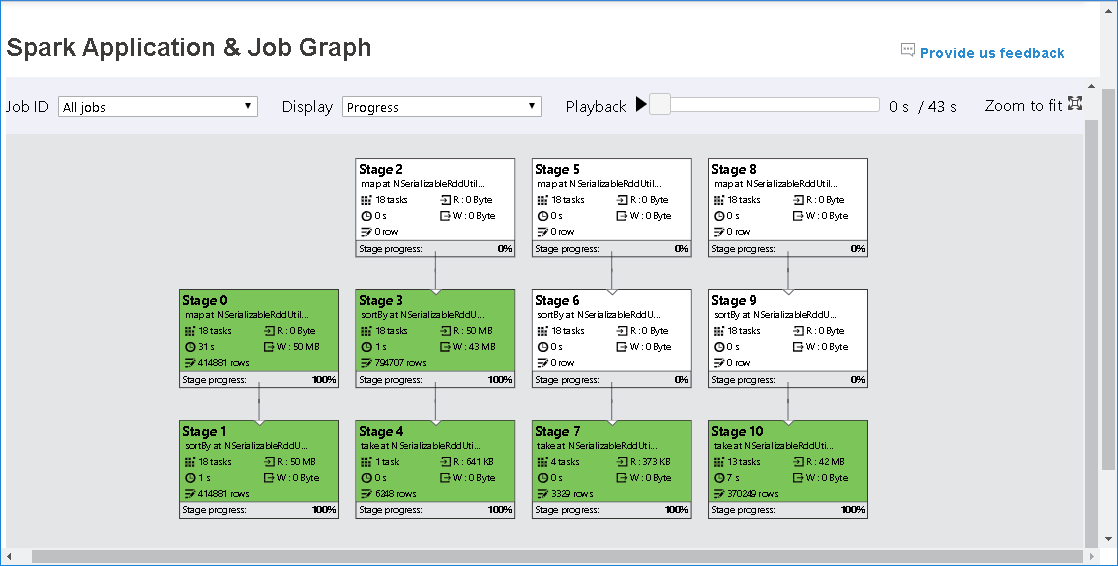
Periksa gambaran umum pekerjaan Anda oleh grafik pekerjaan yang dihasilkan.
Secara default, ini akan menampilkan semua pekerjaan, dan dapat difilter oleh ID Pekerjaan.
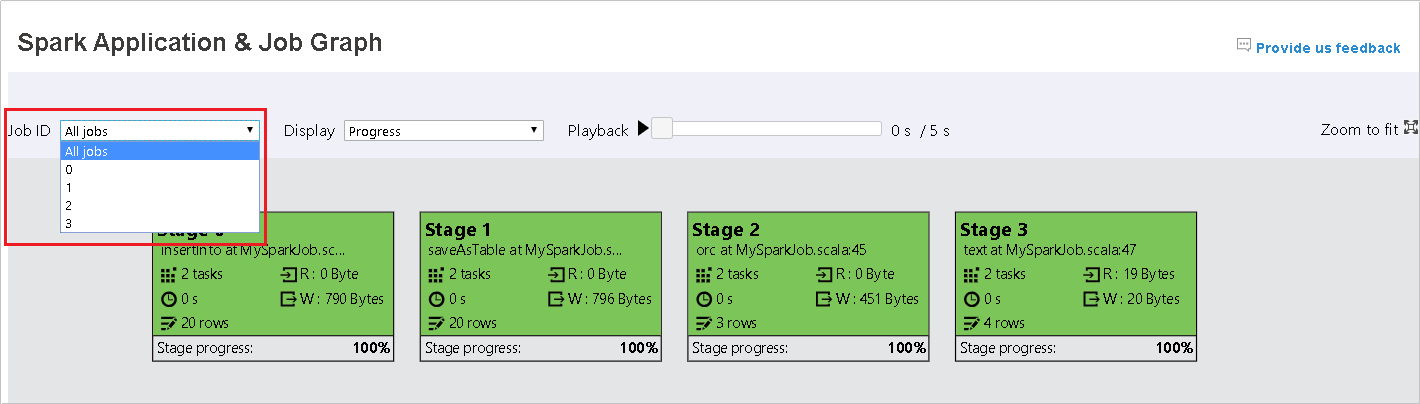
Kami meninggalkan Kemajuan sebagai nilai default. Pengguna dapat memeriksa aliran data dengan memilih Baca atau Ditulis dalam daftar dropdown Tampilan.
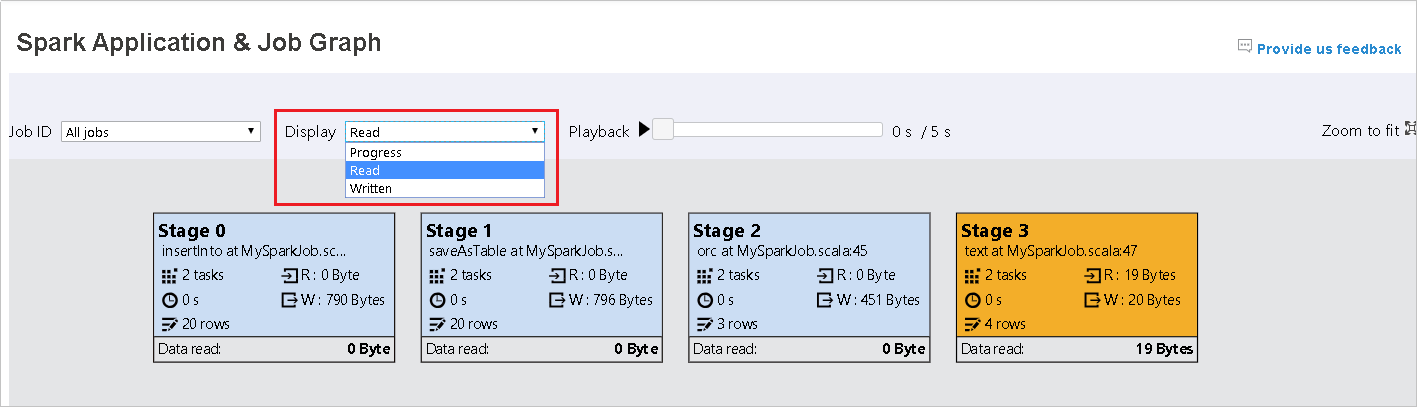
Node grafik ditampilkan dalam warna yang menunjukkan peta panas.

Putar kembali pekerjaan dengan mengklik tombol Pemutaran dan berhenti kapan saja dengan mengklik tombol berhenti. Tugas ditampilkan dalam warna untuk menampilkan status yang berbeda saat diputar kembali:
- Hijau untuk berhasil: Pekerjaan telah berhasil diselesaikan.
- Oranye untuk dicoba kembali: Instans tugas yang gagal tetapi tidak memengaruhi hasil akhir pekerjaan. Tugas ini memiliki instans duplikat atau coba lagi yang mungkin berhasil nanti.
- Biru untuk berjalan: Tugas sedang berjalan.
- Putih untuk menunggu atau dilewati: Tugas sedang menunggu untuk dijalankan, atau tahap telah dilewati.
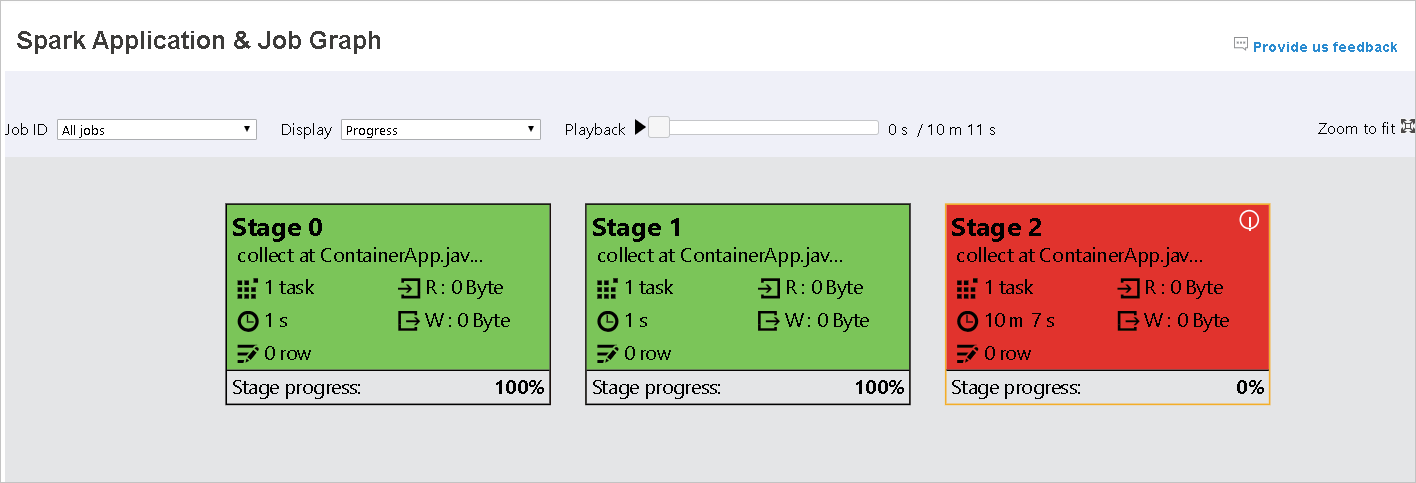
- Merah untuk gagal: Tugas gagal.

Tampilan tahap yang dilewati berwarna putih.
Catatan
Pemutaran untuk setiap pekerjaan diizinkan. Untuk pekerjaan yang tidak lengkap, pemutaran tidak didukung.
Gulir mouse untuk memperbesar/memperkecil grafik pekerjaan, atau klik Perbesar agar pas agar pas dengan layar.
Arahkan mouse ke simpul grafik untuk melihat tipsalat ketika ada tugas yang gagal, dan klik panggung untuk membuka halaman panggung.
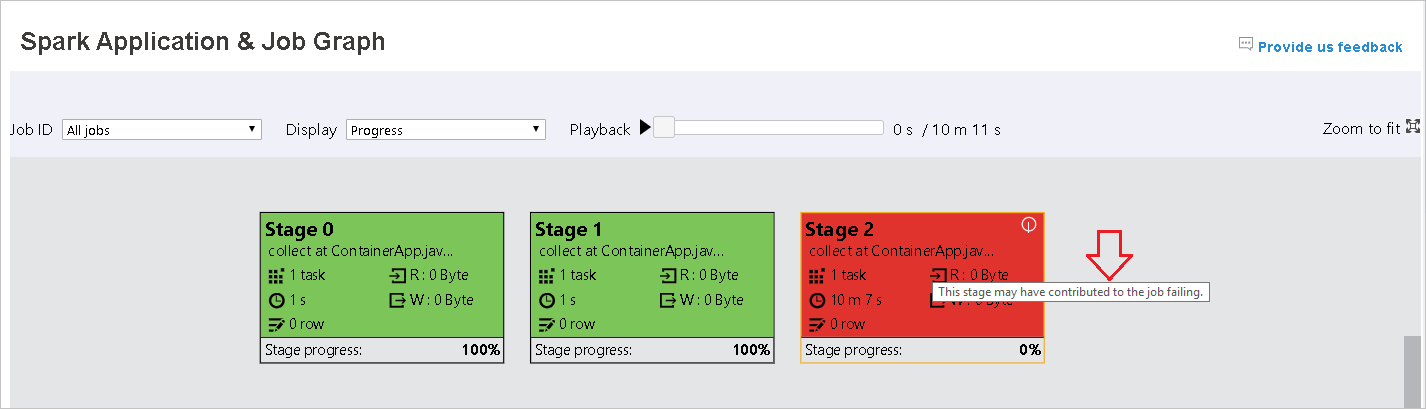
Di tab grafik pekerjaan, tahapan akan memiliki tipsalat dan ikon kecil yang ditampilkan jika memiliki tugas yang memenuhi kondisi di bawah ini:
- Penyimpangan data: ukuran baca data ukuran > rata-rata ukuran baca data dari semua tugas di dalam tahap ini * 2 dan ukuran > baca data 10 MB
- Kecondongan waktu: waktu eksekusi rata-rata waktu > eksekusi semua tugas di dalam tahap ini * 2 dan waktu > eksekusi 2 menit
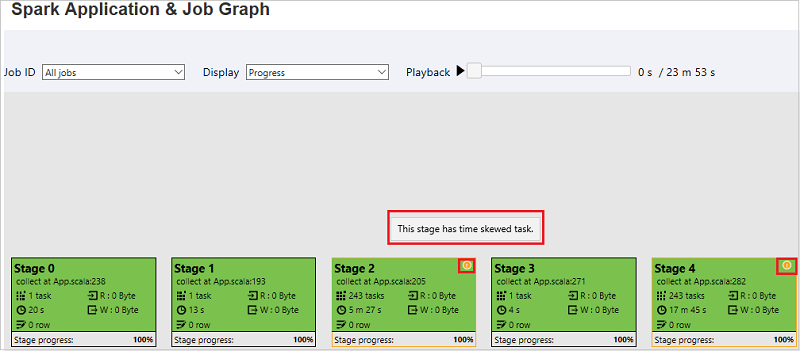
Simpul grafik pekerjaan akan menampilkan informasi berikut dari setiap tahap:
- ID.
- Nama atau deskripsi.
- Total jumlah tugas.
- Baca data: jumlah ukuran input dan ukuran baca acak.
- Penulisan data: jumlah ukuran output dan ukuran tulis acak.
- Waktu eksekusi: waktu antara waktu mulai upaya pertama dan waktu penyelesaian upaya terakhir.
- Jumlah baris: jumlah rekaman input, rekaman output, rekaman baca acak, dan rekaman tulis acak.
- Kemajuan.
Catatan
Secara default, simpul grafik pekerjaan akan menampilkan informasi dari upaya terakhir setiap tahap (kecuali untuk waktu eksekusi tahap), tetapi selama simpul grafik pemutaran akan menampilkan informasi dari setiap upaya.
Catatan
Untuk ukuran data baca dan tulis, kami menggunakan 1MB = 1000 KB = 1000 * 1000 Byte.
Kirim umpan balik dengan masalah dengan mengklik Berikan umpan balik kepada kami.
Tab Diagnosis di Server Riwayat Spark
Pilih ID pekerjaan lalu klik Diagnosis pada menu alat untuk mendapatkan tampilan Diagnosis pekerjaan. Tab diagnosis mencakup Penyimpangan Data, Penyimpangan Waktu, dan Analisis Penggunaan Eksekutor.
Periksa Penyimpangan Data, Penyimpangan Waktu, dan Analisis Penggunaan Eksekutor dengan memilih tab masing-masing.
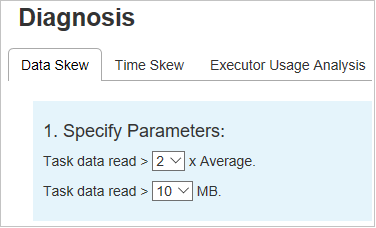
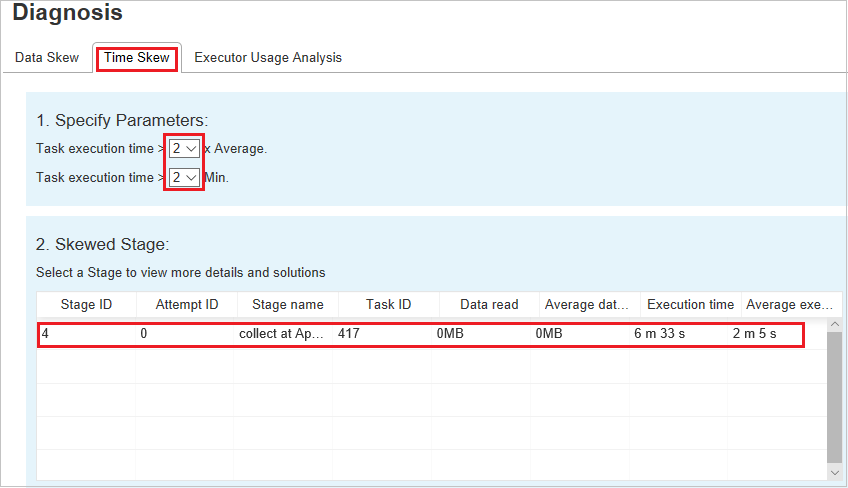
Penyimpangan Data
Klik tab Penyimpangan Data, tugas condong terkait ditampilkan berdasarkan parameter yang ditentukan.
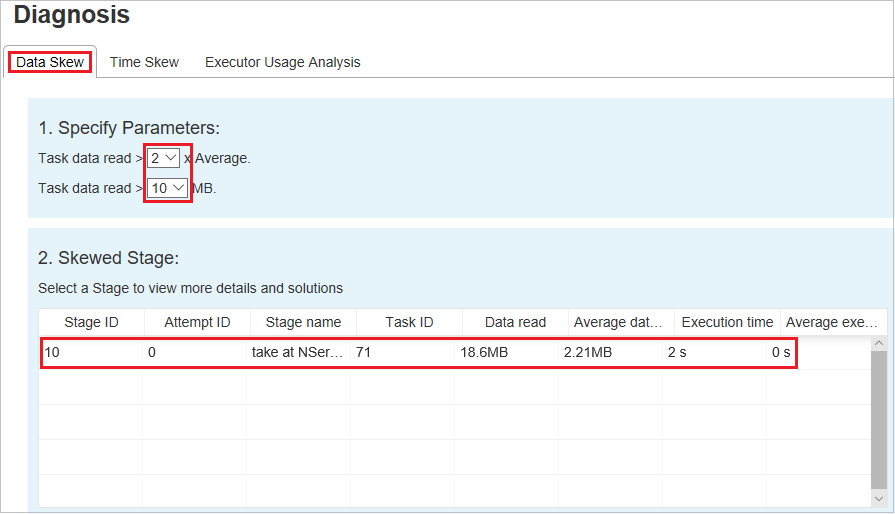
Menentukan Parameter - Bagian pertama menampilkan parameter, yang digunakan untuk mendeteksi Penyimpangan Data. Aturan bawaan adalah: Pembacaan Data Tugas lebih besar dari tiga kali dari data tugas rata-rata yang dibaca, dan data tugas yang dibaca lebih dari 10 MB. Jika Anda ingin menentukan aturan Anda sendiri untuk tugas condong, Anda dapat memilih parameter Anda, Bagian Tahap Condong, dan Karakter Condong akan di-refresh.
Tahap Menyimpang - Bagian kedua menampilkan tahap, yang memiliki tugas menyimpang yang memenuhi kriteria yang ditentukan di atas. Jika ada lebih dari satu tugas menyimpang dalam tahap, tabel tahap menyimpang hanya menampilkan tugas yang paling menyimpang (misalnya, data terbesar untuk penyimpangan data).
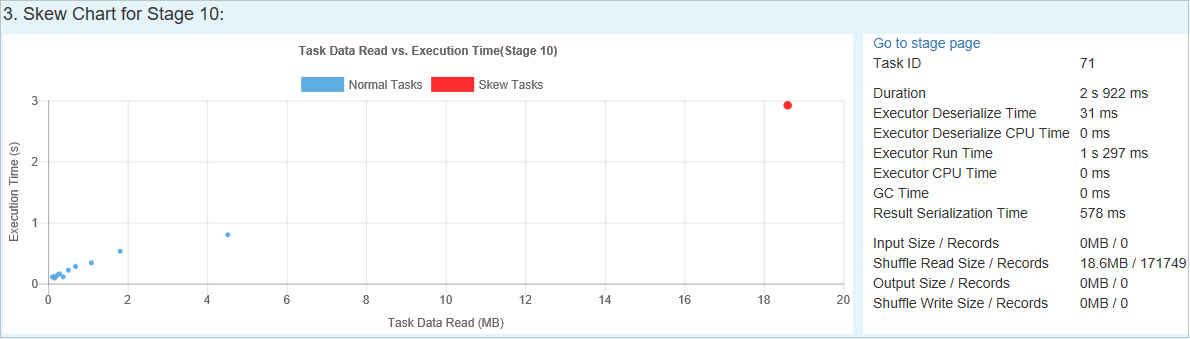
Bagan Condong - Saat baris dalam tabel tahap condong dipilih, bagan condong menampilkan lebih banyak detail distribusi tugas berdasarkan waktu baca dan eksekusi data. Tugas menyimpang ditandai dengan warna merah, dan tugas normal ditandai dengan warna biru. Untuk pertimbangan performa, bagan hanya menampilkan hingga 100 tugas sampel. Detail tugas ditampilkan di panel kanan bawah.
Penyimpangan Waktu
Tab Penyimpangan Waktu menampilkan tugas menyimpang berdasarkan waktu eksekusi tugas.
Menentukan Parameter - Bagian pertama menampilkan parameter, yang digunakan untuk mendeteksi Penyimpangan Waktu. Kriteria default untuk mendeteksi penyimpangan waktu adalah: waktu eksekusi tugas lebih besar dari tiga kali waktu eksekusi rata-rata dan waktu eksekusi tugas lebih besar dari 30 detik. Anda dapat mengubah parameter berdasarkan kebutuhan Anda. Tahap Menyimpang dan Bagan Penyimpangan menampilkan informasi tahap dan tugas yang sesuai, seperti di tab Penyimpangan Data.
Klik Penyimpangan Waktu, lalu hasil yang difilter ditampilkan di bagian Tahap condong sesuai dengan parameter yang diatur di bagian Tentukan Parameter. Klik satu item di bagian Tahap Miring, lalu bagan terkait disusur di bagian3, dan detail tugas ditampilkan di panel kanan bawah.
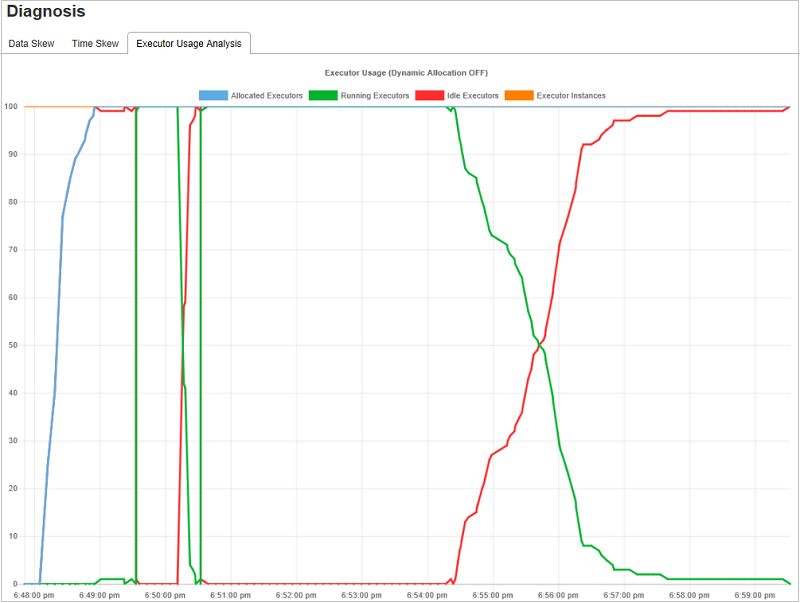
Analisis Penggunaan Eksekutor
Grafik Penggunaan Pelaksana memvisualisasikan alokasi pelaksana pekerjaan Spark yang sebenarnya dan status berjalan.
Klik Analisis Penggunaan Pelaksana, lalu kami menyusun empat kurva jenis tentang penggunaan eksekutor. Mereka termasuk Eksekutor yang Dialokasikan, Pelaksana Yang Berjalan, Pelaksana diam, dan Instans Pelaksana Maks. Mengenai pelaksana yang dialokasikan, setiap peristiwa "Eksekutor ditambahkan" atau "Pelaksana dihapus" akan meningkatkan atau mengurangi pelaksana yang dialokasikan. Anda dapat memeriksa "Garis Waktu Peristiwa" di tab "Pekerjaan" untuk perbandingan lebih lanjut.
Klik ikon warna untuk memilih atau membatalkan pilihan konten terkait di semua draf.
Log Spark / Yarn
Selain Spark History Server, Anda dapat menemukan log untuk Spark dan Yarn di sini, masing-masing:
- Log Peristiwa Spark: hdfs:///system/spark-events
- Log yarn: hdfs:///tmp/logs/root/logs-tfile
Catatan: Kedua log ini memiliki periode retensi default 7 hari. Jika Anda ingin mengubah periode retensi, lihat halaman Mengonfigurasi Apache Spark dan Apache Hadoop . Lokasi tidak dapat diubah.
Masalah umum
Server Riwayat Spark memiliki masalah umum berikut:
Saat ini, ini hanya berfungsi untuk kluster Spark 3.1 (CU13+) dan Spark 2.4 (CU12-).
Data input/output menggunakan RDD tidak akan ditampilkan di tab Data.
Langkah berikutnya
- Mulai menggunakan SQL Server Kluster Big Data
- Mengonfigurasi pengaturan Spark
- Mengonfigurasi pengaturan Spark