Mekanisme dan pedoman batas waktu sewa, kluster, dan pemeriksaan kesehatan untuk grup ketersediaan AlwaysOn
Perbedaan konfigurasi perangkat keras, perangkat lunak, dan kluster serta persyaratan aplikasi yang berbeda untuk waktu aktif dan performa memerlukan konfigurasi khusus untuk nilai batas waktu sewa, kluster, dan pemeriksaan kesehatan. Aplikasi dan beban kerja tertentu memerlukan pemantauan yang lebih agresif untuk membatasi waktu henti setelah kegagalan keras. Yang lain membutuhkan lebih banyak toleransi untuk masalah jaringan sementara dan menunggu dari penggunaan sumber daya yang tinggi dan baik-baik saja dengan failover yang lebih lambat.
Beberapa layanan pada setiap simpul berfungsi untuk mendeteksi kegagalan. Layanan kluster dapat mendeteksi kehilangan kuorum, DLL sumber daya dapat mendeteksi masalah yang muncul oleh deteksi kesehatan Always On, atau failover manual mungkin dimulai langsung pada instans utama. Layanan kluster, host sumber daya, dan instans SQL Server disinkronkan satu sama lain melalui RPC, memori bersama, dan T-SQL. Dalam sebagian besar skenario, layanan ini berhasil berkomunikasi, namun komunikasi ini tidak dapat diandalkan dengan sempurna bahkan antara layanan pada komputer yang sama. Selain itu, grup ketersediaan (AG) harus dapat menahan peristiwa luas sistem seperti kegagalan jaringan dan disk, yang dapat mencegah komunikasi atau mengganggu fungsionalitas. Dengan banyak kasus kegagalan dan tanpa komunikasi yang sepenuhnya dapat diandalkan antara layanan, AG bergantung pada berbagai mekanisme deteksi failover untuk mendeteksi dan merespons kegagalan secara independen satu sama lain sehingga status kluster selalu konsisten untuk semua simpul.
Node kluster dan deteksi sumber daya
Setiap simpul dalam kluster menjalankan satu layanan kluster, yang mengoperasikan kluster failover dan memantau semua sumber daya kluster. Host sumber daya beroperasi sebagai proses terpisah dan merupakan antarmuka antara layanan kluster dan sumber daya kluster. Host sumber daya melakukan operasi pada sumber daya kluster ketika dipanggil oleh layanan kluster. Aplikasi sadar kluster seperti SQL Server menyediakan antarmuka kustom ke monitor sumber daya melalui DLL sumber daya. DLL sumber daya menerapkan operasi online dan offline dan pemantauan kesehatan untuk sumber daya kustom. Host sumber daya adalah proses anak dari layanan kluster dan dimatikan setiap kali layanan kluster dimatikan.
Untuk SQL Server, DLL sumber daya AG menentukan kesehatan AG berdasarkan mekanisme sewa AG dan deteksi kesehatan Grup Ketersediaan AlwaysOn. DLL sumber daya AG mengekspos kesehatan sumber daya melalui IsAlive operasi. Pemantau sumber daya melakukan polling IsAlive pada interval heartbeat kluster, yang diatur oleh CrossSubnetDelay nilai di seluruh kluster dan SameSubnetDelay . Pada simpul utama, layanan kluster memulai failover setiap kali IsAlive panggilan ke DLL sumber daya mengembalikan bahwa AG tidak sehat.
Layanan kluster mengirimkan heartbeat ke simpul lain dalam kluster dan mengakui heartbeat yang diterima dari mereka. Ketika node mendeteksi kegagalan komunikasi dari serangkaian heartbeat yang tidak diakui, siaran pesan menyebabkan semua node yang dapat dijangkau untuk mendamaikan pandangan mereka tentang kesehatan node kluster. Kejadian ini, yang disebut peristiwa grup ulang, mempertahankan konsistensi status kluster di seluruh simpul. Setelah peristiwa grup ulang, jika kuorum hilang, maka semua sumber daya kluster termasuk AG dalam partisi ini diambil secara offline. Semua simpul dalam partisi ini ditransisikan ke status penyelesaian. Jika ada partisi, yang menyimpan kuorum, AG ditetapkan ke satu simpul dalam partisi dan menjadi replika utama sementara semua simpul lain menjadi replika sekunder.
Deteksi kesehatan AlwaysOn
DLL sumber daya AlwaysOn memantau status komponen SQL Server internal. sp_server_diagnostics melaporkan kesehatan komponen ini SQL Server pada interval yang dikendalikan oleh HealthCheckTimeout. sp_server_diagnostics melaporkan status kesehatan lima komponen tingkat instans: sistem, sumber daya, pemrosesan kueri, subsistem io, dan peristiwa. Ini juga melaporkan kesehatan setiap AG. Setelah setiap pembaruan, DLL sumber daya memperbarui status kesehatan sumber daya AG berdasarkan tingkat kegagalan AG. Ketika data dikembalikan oleh sp_server_diagnostics, data menunjukkan setiap komponen baik dalam status bersih, peringatan, kesalahan, atau tidak diketahui dengan beberapa data XML yang menjelaskan status komponen. Untuk deteksi kesehatan, DLL sumber daya hanya mengambil tindakan jika komponen dalam keadaan kesalahan.
Jika deteksi kesehatan gagal melaporkan pembaruan ke DLL sumber daya untuk beberapa interval, AG ditentukan tidak sehat dan akan melaporkan kegagalan pada IsAlive panggilan.
Mekanisme sewa
Tidak seperti mekanisme failover lainnya, instans SQL Server memainkan peran aktif dalam mekanisme sewa. Mekanisme sewa digunakan sebagai validasi Looks-Alive antara host sumber daya Kluster dan proses SQL Server. Mekanisme ini digunakan untuk memastikan bahwa kedua belah pihak (Layanan Kluster dan layanan SQL Server) sering berinteraksi, memeriksa keadaan satu sama lain dan akhirnya mencegah skenario split-brain. Saat membawa AG online sebagai replika utama, instans SQL Server menelurkan utas pekerja sewa khusus untuk AG. Pekerja sewa berbagi wilayah kecil memori dengan host sumber daya yang berisi peristiwa perpanjangan sewa dan pemberhentian sewa. Pekerja sewa dan host sumber daya bekerja dengan cara yang melingkar, menandakan acara perpanjangan sewa masing-masing dan kemudian tidur, menunggu pihak lain untuk menandakan acara perpanjangan sewanya sendiri atau menghentikan acara. Baik host sumber daya maupun utas sewa SQL Server mempertahankan nilai time-to-live, yang diperbarui setiap kali utas bangun setelah diberi sinyal oleh utas lainnya. Jika waktu hidup tercapai saat menunggu sinyal, sewa akan kedaluwarsa dan kemudian replika beralih ke status penyelesaian untuk AG tertentu tersebut. Jika peristiwa pemberhentian sewa diberi sinyal, maka replika beralih ke peran penyelesaian.
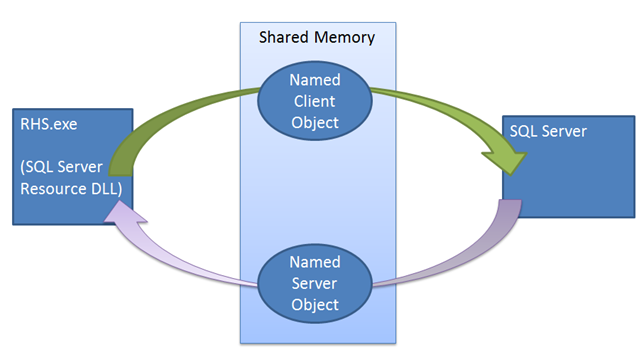
Mekanisme sewa memberlakukan sinkronisasi antara SQL Server dan Kluster Failover Windows Server. Ketika perintah failover dikeluarkan, layanan kluster melakukan Offline panggilan ke DLL sumber daya replika utama saat ini. DLL sumber daya pertama kali mencoba membuat AG offline menggunakan prosedur tersimpan. Jika prosedur tersimpan ini gagal atau waktu habis, kegagalan dilaporkan kembali ke layanan kluster, yang kemudian mengeluarkan perintah penghentian. Penghentian lagi mencoba menjalankan prosedur tersimpan yang sama, tetapi kluster kali ini tidak menunggu DLL sumber daya melaporkan keberhasilan atau kegagalan sebelum membawa AG online pada replika baru. Jika panggilan prosedur kedua ini gagal, maka host sumber daya harus mengandalkan mekanisme sewa untuk membuat instans offline. Ketika DLL sumber daya dipanggil untuk mengambil AG offline, DLL sumber daya menandakan peristiwa pemberhentian sewa, membangunkan utas pekerja sewa SQL Server untuk membuat AG offline. Bahkan jika peristiwa berhenti ini tidak diberi sinyal, sewa akan kedaluwarsa, dan replika akan beralih ke status penyelesaian.
Sewa terutama merupakan mekanisme sinkronisasi antara instans utama dan kluster, tetapi juga dapat menciptakan kondisi kegagalan di mana sebaliknya tidak perlu gagal. Misalnya, CPU tinggi, kondisi di luar memori (memori virtual rendah, halaman proses), proses SQL tidak merespons saat menghasilkan cadangan memori, sistem tidak merespons, kluster (WSFC) menjadi offline (seperti karena kehilangan kuorum) dapat mencegah perpanjangan sewa dari instans SQL dan menyebabkan hidupkan ulang atau failover.
Panduan untuk nilai batas waktu kluster
Pertimbangkan dengan cermat tradeoff dan pahami konsekuensi penggunaan pemantauan kluster SQL Server Anda yang kurang agresif. Meningkatkan nilai batas waktu kluster meningkatkan toleransi masalah jaringan sementara tetapi memperlambat reaksi terhadap kegagalan keras. Meningkatkan batas waktu untuk menangani tekanan sumber daya atau latensi geografis yang besar, juga akan meningkatkan waktu untuk pulih dari kegagalan yang keras, atau tidak dapat dipulihkan. Meskipun ini dapat diterima untuk banyak aplikasi, ini tidak ideal dalam semua kasus.
Pengaturan default dioptimalkan untuk bereaksi dengan cepat terhadap gejala kegagalan keras dan membatasi waktu henti, tetapi pengaturan ini juga dapat terlalu agresif untuk beban kerja dan konfigurasi tertentu. Tidak disarankan untuk menurunkan salah satu dari LeaseTimeout, , CrossSubnetDelay, CrossSubnetThresholdSameSubnetDelay, SameSubnetThreshold, atau HealthCheckTimeout di luar nilai defaultnya. Pengaturan yang benar untuk setiap penyebaran bervariasi dan kemungkinan membutuhkan waktu periode penyempurnaan yang lebih lama untuk ditemukan. Saat membuat perubahan pada salah satu nilai ini, buatlah secara bertahap dan dengan pertimbangan hubungan dan dependensi antara nilai-nilai ini.
Hubungan antara batas waktu kluster dan batas waktu sewa
Fungsi utama mekanisme sewa adalah untuk mengambil sumber daya SQL Server offline jika layanan kluster tidak dapat berkomunikasi dengan instans saat melakukan failover ke node lain. Ketika kluster melakukan operasi offline pada sumber daya kluster AG, layanan kluster melakukan panggilan RPC ke rhs.exe untuk membuat sumber daya offline. DLL sumber daya menggunakan prosedur tersimpan untuk memberi tahu SQL Server agar AG offline, tetapi prosedur tersimpan ini dapat gagal atau kehabisan waktu. Host sumber daya juga menghentikan utas perpanjangan sewanya sendiri selama panggilan offline. Dalam kasus terburuk, SQL Server menyebabkan sewa kedaluwarsa dalam 1/2 * LeaseTimeout dan transisi instans ke status penyelesaian. Failover dapat dimulai oleh beberapa pihak yang berbeda, tetapi sangat penting bahwa tampilan status kluster konsisten di seluruh kluster dan di seluruh instans SQL Server. Misalnya, bayangkan skenario di mana instans utama kehilangan koneksi dengan sisa kluster. Setiap simpul dalam kluster menentukan kegagalan pada waktu yang sama karena nilai batas waktu kluster, tetapi hanya simpul utama yang dapat berinteraksi dengan instans SQL Server utama untuk memaksanya menyerahkan peran utama.
Dari perspektif node utama, layanan kluster kehilangan kuorum dan layanan mulai mengakhiri dirinya sendiri. Layanan kluster mengeluarkan panggilan RPC ke host sumber daya untuk mengakhiri proses. Panggilan penghentian ini bertanggung jawab untuk mengambil AG offline pada instans SQL Server. Panggilan offline ini dilakukan melalui T-SQL, tetapi tidak dapat menjamin bahwa koneksi akan berhasil dibuat antara SQL dan DLL sumber daya.
Dari perspektif sisa kluster, saat ini tidak ada replika utama, sehingga kluster memilih dan menetapkan satu primer baru untuk node yang tersisa dalam kluster. Jika prosedur tersimpan yang dipanggil oleh DLL sumber daya, gagal atau kehabisan waktu, kluster dapat rentan terhadap skenario otak terpisah.
Batas waktu sewa mencegah skenario split brain dalam menghadapi kesalahan komunikasi. Bahkan jika semua komunikasi gagal, proses DLL sumber daya akan berakhir dan tidak dapat memperbarui sewa. Setelah sewa kedaluwarsa, AG akan offline sendiri. Instans SQL Server perlu diketahui bahwa SQL Server tidak lagi menghosting replika utama sebelum kluster menetapkan yang baru. Karena sisa kluster, yang bertanggung jawab untuk memilih replika utama baru tidak memiliki cara untuk berkoordinasi dengan replika utama saat ini, nilai batas waktu memastikan bahwa replika utama baru tidak dibuat sebelum primer saat ini mengambil dirinya offline.
Ketika kluster gagal, instans SQL Server yang menghosting replika utama sebelumnya harus beralih ke status penyelesaian sebelum replika utama baru online. Utas sewa SQL Server kapan saja memiliki sisa waktu hidup 1/2 * LeaseTimeout, karena setiap kali sewa diperbarui, waktu hidup baru diperbarui ke LeaseInterval atau 1/2 * LeaseTimeout. Jika layanan kluster atau host sumber daya terhenti atau dihentikan tanpa memberi sinyal peristiwa pemberhentian sewa, kluster akan menyatakan simpul utama mati setelah SameSubnetThreshold\ SameSubnetDelay milidetik. Dalam waktu ini, sewa harus kedaluwarsa sehingga primer dijamin offline. Karena waktu hidup maksimum untuk batas waktu sewa adalah 1/2 * LeaseTimeout, 1/2 * LeaseTimeout harus kurang dari * SameSubnetThresholdSameSubnetDelay .
SameSubnetThreshold \<= CrossSubnetThreshold dan SameSubnetDelay \<= CrossSubnetDelay harus benar dari semua kluster SQL Server.
Operasi batas waktu pemeriksaan kesehatan
Batas waktu pemeriksaan kesehatan lebih fleksibel karena tidak ada mekanisme failover lain yang bergantung padanya secara langsung. Nilai default 30 detik mengatur sp_server_diagnostics interval pada 10 detik, dengan nilai minimum selama 15 detik untuk batas waktu dan interval 5 detik. Lebih umum lagi, sp_server_diagnostics interval pembaruan selalu 1/3 * HealthCheckTimeout. Ketika DLL sumber daya tidak menerima sekumpulan data kesehatan baru pada interval, DLL terus menggunakan data kesehatan dari interval sebelumnya untuk menentukan kesehatan AG dan instans saat ini. Meningkatkan nilai batas waktu pemeriksaan kesehatan membuat tekanan CPU primer lebih toleran, yang dapat mencegah sp_server_diagnostics penyediaan data baru pada setiap interval, namun, ia bergantung pada pemeriksaan kesehatan data yang kedaluarsa untuk waktu yang lebih lama. Terlepas dari nilai batas waktu, setelah data diterima yang menunjukkan replika tidak sehat, panggilan berikutnya IsAlive akan mengembalikan bahwa instans tidak sehat dan layanan kluster akan memulai failover.
Tingkat kondisi kegagalan AG mengubah kondisi kegagalan untuk pemeriksaan kesehatan. Untuk tingkat kegagalan apa pun, jika elemen AG dilaporkan tidak sehat sp_server_diagnostics saat itu pemeriksaan kesehatan gagal. Setiap tingkat mewarisi semua kondisi kegagalan dari tingkat di bawahnya.
| Tingkat | Kondisi di mana instans dianggap mati |
|---|---|
| 1: OnServerDown | Pemeriksaan kesehatan tidak mengambil tindakan jika ada sumber daya yang gagal selain AG. Jika data AG tidak diterima dalam 5 interval, atau 5/3 * HealthCheckTimeout |
| 2: OnServerUnresponsive | Jika tidak ada data yang diterima dari sp_server_diagnostics untuk HealthCheckTimeout |
| 3: OnCriticalServerError | (Default) Jika komponen sistem melaporkan kesalahan |
| 4: OnModerateServerError | Jika komponen sumber daya melaporkan kesalahan |
| 5: OnAnyQualifiedFailureConitions | Jika komponen pemrosesan kueri melaporkan kesalahan |
Memperbarui kluster dan nilai batas waktu AlwaysOn
Nilai kluster
Ada empat nilai dalam konfigurasi WSFC yang bertanggung jawab untuk menentukan nilai batas waktu kluster:
- SameSubnetDelay
- SameSubnetThreshold
- CrossSubnetDelay
- CrossSubnetThreshold
Nilai penundaan menentukan waktu tunggu antara heartbeat dari layanan kluster, dan nilai ambang batas menetapkan jumlah heartbeat yang tidak dapat menerima pengakuan dari simpul target atau sumber daya sebelum objek dinyatakan mati oleh kluster. Jika tidak ada heartbeat yang berhasil antara simpul di subnet yang sama selama lebih dari SameSubnetDelay \* SameSubnetThreshold milidetik, maka simpul ditentukan mati. Hal yang sama berlaku untuk komunikasi lintas subnet menggunakan nilai lintas subnet.
Untuk mencantumkan semua nilai kluster saat ini, pada node apa pun di kluster target, buka terminal PowerShell yang ditingkatkan. Jalankan perintah berikut:
Get-Cluster | fl *
Untuk memperbarui salah satu nilai ini, jalankan perintah berikut di terminal PowerShell yang ditingkatkan:
(Get-Cluster).<ValueName> = <NewValue>
Saat meningkatkan produk Delay * Threshold untuk membuat batas waktu kluster lebih toleran, lebih efektif untuk terlebih dahulu meningkatkan nilai penundaan sebelum meningkatkan ambang batas. Dengan meningkatkan penundaan, waktu antara setiap detak jantung meningkat. Lebih banyak waktu antara heartbeat memberikan lebih banyak waktu bagi masalah jaringan sementara untuk menyelesaikan sendiri dan mengurangi kemacetan jaringan relatif untuk mengirim lebih banyak heartbeat dalam periode yang sama.
Batas waktu sewa
Mekanisme sewa dikendalikan oleh satu nilai khusus untuk setiap AG dalam kluster WSFC. Batas waktu sewa dapat mengakibatkan kesalahan berikut:
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
Untuk mengubah nilai batas waktu sewa, gunakan Manajer Kluster Failover dan ikuti langkah-langkah berikut:
Di tab peran, temukan peran AG target. Pilih peran AG target.
Klik kanan sumber daya AG di bagian bawah jendela dan pilih Properti.
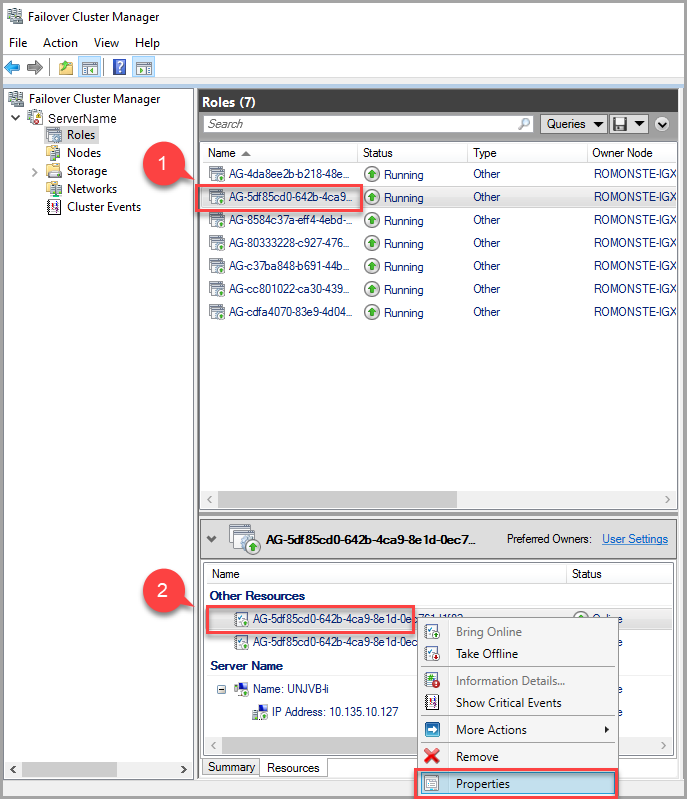
Di jendela popup, navigasikan ke tab properti untuk melihat daftar nilai khusus untuk AG ini. Pilih nilai LeaseTimeout untuk mengubahnya.
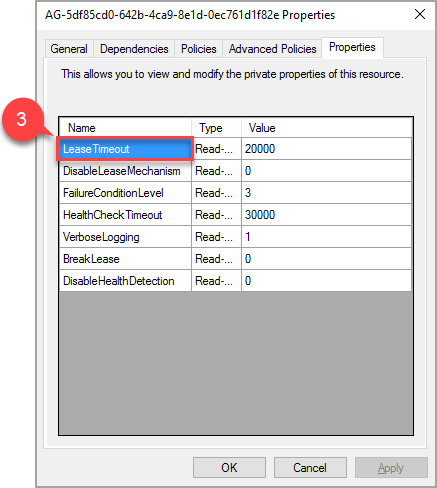
Bergantung pada konfigurasi AG mungkin ada sumber daya tambahan untuk pendengar, disk bersama, berbagi file, dll., sumber daya ini tidak memerlukan konfigurasi tambahan apa pun.
Catatan
Nilai baru properti 'LeaseTimeout' akan berlaku setelah sumber daya diambil secara offline dan dibawa online lagi.
Nilai pemeriksaan kesehatan
Dua nilai mengontrol pemeriksaan kesehatan AlwaysOn: FailureConditionLevel dan HealthCheckTimeout. FailureConditionLevel menunjukkan tingkat toleransi terhadap kondisi kegagalan tertentu yang dilaporkan oleh sp_server_diagnostics dan HealthCheckTimeout mengonfigurasi waktu dll sumber daya dapat pergi tanpa menerima pembaruan dari sp_server_diagnostics. Interval pembaruan untuk sp_server_diagnostics selalu HealthCheckTimeout / 3.
Untuk mengonfigurasi tingkat kondisi failover, gunakan FAILURE_CONDITION_LEVEL = <n> opsi CREATE pernyataan atau ALTER AVAILABILITY GROUP , di mana <n> adalah bilangan bulat antara 1 dan 5. Perintah berikut mengatur tingkat kondisi kegagalan ke 1 untuk AG 'AG1':
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
Untuk mengonfigurasi batas waktu pemeriksaan kesehatan, gunakan HEALTH_CHECK_TIMEOUT opsi CREATE pernyataan atau ALTER AVAILABILITY GROUP . Perintah berikut mengatur batas waktu pemeriksaan kesehatan menjadi 60.000 milidetik untuk AG AG1:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
Ringkasan panduan batas waktu
Menurunkan nilai batas waktu di bawah nilai defaultnya tidak disarankan.
Interval sewa (1/2 * LeaseTimeout) harus lebih pendek dari SameSubnetThreshold * SameSubnetDelay
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| Pengaturan waktu habis | Tujuan | Antara | Menggunakan | IsAlive & LooksAlive | Penyebab | Hasil |
|---|---|---|---|---|---|---|
| Batas waktu sewa Default: 20000 |
Mencegah pemisahan otak | Primer ke Kluster (HADR) |
Objek peristiwa Windows | Digunakan dalam keduanya | OS tidak merespons, memori virtual rendah, paging set kerja, menghasilkan dump, CPU yang dipatok, WSFC ke bawah (kehilangan kuorum) | Sumber daya AG offline-online, failover |
| Batas waktu sesi Default: 10000 |
Informasi masalah komunikasi antara Primer dan Sekunder | Sekunder ke Primer (HADR) |
Soket TCP (pesan yang dikirim melalui titik akhir DBM) | Digunakan dalam keduanya | Komunikasi jaringan, Masalah pada sekunder - tidak berfungsi, OS tidak merespons, ketidakcocokan sumber daya |
Sekunder - TERPUTUS |
| Batas waktu HealthCheck Default: 30000 |
Menunjukkan batas waktu saat mencoba menentukan kesehatan replika Utama | Kluster ke Primer (FCI & HADR) |
sp_server_diagnostics T-SQL | Digunakan dalam keduanya | Kondisi kegagalan terpenuhi, OS tidak merespons, memori virtual rendah, pemangkasan set kerja, menghasilkan cadangan, WSFC (kehilangan kuorum), masalah penjadwal (penjadwal terkunci mati) | Sumber daya AG Offline-online atau Failover, FCI restart/failover |