Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() SQL Server
SQL Server
Dalam grup ketersediaan Always On, mode ketersediaan adalah properti replika yang menentukan apakah replika ketersediaan tertentu dapat berjalan dalam mode synchronous-commit. Untuk setiap replika ketersediaan, mode ketersediaan harus dikonfigurasi untuk mode komit sinkron, mode komit asinkron, atau mode hanya konfigurasi.
Jika replika utama dikonfigurasi untuk mode penerapan asinkron, replika sekunder tidak menunggu untuk menulis catatan log transaksi masuk ke disk (untuk mengeraskan log).
Jika replika sekunder tertentu dikonfigurasi untuk mode penerapan asinkron, replika utama tidak menunggu replika sekunder tersebut mengeraskan log. Jika replika utama dan replika sekunder tertentu keduanya dikonfigurasi untuk mode penerapan sinkron, replika utama menunggu replika sekunder untuk mengonfirmasi bahwa replika tersebut telah mengeraskan log (kecuali replika sekunder gagal melakukan ping replika utama dalam periode waktu habis sesi utama).
Catatan
Jika replika sekunder komit sinkron melebihi periode batas waktu sesi dari replika utama (defaultnya adalah 10 detik), replika utama menandai untuk sementara status sinkronisasi setiap database pada replika sekunder ini sebagai NOT SYNCHRONIZING dan status replika sebagai NOT_HEALTHY. Ketika replika sekunder terhubung kembali dengan replika utama, replika tersebut melanjutkan mode penerapan sinkron.
Mode ketersediaan yang didukung
Grup ketersediaan AlwaysOn mendukung tiga mode ketersediaan:
- Mode penerapan asinkron
- Mode penerapan sinkron
- Mode konfigurasi saja
Mode commit asinkron adalah solusi pemulihan bencana yang berfungsi dengan baik ketika replika ketersediaan didistribusikan melalui jarak yang cukup jauh. Jika setiap replika sekunder berjalan di bawah mode komitmen asinkron, replika utama tidak menunggu replika sekunder apa pun untuk mengokohkan log. Sebaliknya, segera setelah menulis catatan log ke file log lokal, replika utama mengirimkan konfirmasi transaksi ke klien. Replika utama beroperasi dengan latensi transaksi minimum dibandingkan dengan replika sekunder yang dikonfigurasi untuk mode komitmen asinkron.
Jika primer saat ini dikonfigurasi untuk mode ketersediaan penerapan asinkron, ia melakukan transaksi secara asinkron untuk semua replika sekunder terlepas dari pengaturan mode ketersediaan individual mereka.
Untuk informasi selengkapnya, lihat Asynchronous-Commit Mode Ketersediaan, nanti di artikel ini.
Mode commit sinkron menekankan ketersediaan tinggi dibandingkan dengan performa, dengan biaya peningkatan latensi transaksi. Dalam mode komit sinkron, transaksi menunggu sampai mengirimkan konfirmasi transaksi ke klien hingga replika sekunder menyimpan log ke disk. Ketika sinkronisasi data dimulai pada database sekunder, replika sekunder mulai menerapkan rekaman log masuk dari database utama yang sesuai. Segera setelah setiap rekaman log diperkuat, database sekunder memasuki status SYNCHRONIZED. Setelah itu, setiap transaksi baru diperkuat oleh replika sekunder sebelum rekaman log ditulis ke file log lokal. Ketika semua database sekunder dari replika sekunder tertentu telah disinkronkan, mode komit sinkron mendukung failover manual dan, secara opsional, failover otomatis.
Untuk informasi selengkapnya, lihat Synchronous-Commit Mode Ketersediaan, nanti di artikel ini.
Mode konfigurasi saja berlaku untuk grup ketersediaan yang tidak terdapat pada Kluster Failover Windows Server. Replika hanya dalam mode konfigurasi tidak berisi data pengguna. Dalam mode konfigurasi saja, database replika master menyimpan metadata konfigurasi grup ketersediaan. Untuk informasi selengkapnya, lihat Ketersediaan tinggi dan perlindungan data untuk konfigurasi grup ketersediaan.
Ilustrasi berikut menunjukkan sebuah grup ketersediaan dengan lima replika. Replika utama dan satu replika sekunder dikonfigurasi untuk mode komit sinkron dengan failover secara otomatis. Replika sekunder lainnya dikonfigurasi untuk mode penerapan sinkron dengan hanya failover manual yang direncanakan, dan dua replika sekunder dikonfigurasi untuk mode penerapan asinkron, yang hanya mendukung failover manual paksa (biasanya disebut failover paksa).
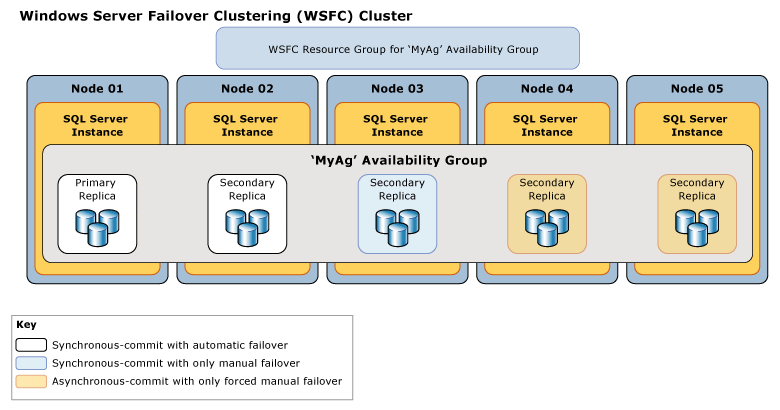
Perilaku sinkronisasi dan failover antara dua replika ketersediaan bergantung pada mode ketersediaan kedua replika. Misalnya, agar penerapan sinkron terjadi, replika utama dan replika sekunder harus dikonfigurasi untuk penerapan sinkron. Demikian juga untuk failover otomatis, kedua replika perlu dikonfigurasi untuk failover otomatis. Oleh karena itu, perilaku untuk skenario penyebaran yang diilustrasikan sebelumnya dapat diringkas dalam tabel berikut, yang mengeksplorasi perilaku dengan setiap replika utama potensial:
| Replika utama saat ini | Target failover otomatis | Perilaku mode penerapan sinkron dengan | Perilaku mode komit asinkron dengan | Dimungkinkan adanya failover otomatis |
|---|---|---|---|---|
| 01 | 02 | 02 dan 03 | 04 | Ya |
| 02 | 01 | 01 dan 03 | 04 | Ya |
| 03 | 01 dan 02 | 04 | Tidak | |
| 04 | 01, 02, dan 03 | Tidak |
Biasanya, Node 04 sebagai replika komitmen asinkron, dipasang di lokasi pemulihan bencana. Fakta bahwa Node 01, 02, dan 03 tetap berada pada mode komit asinkron setelah dialihkan ke Node 04 membantu mencegah potensi penurunan performa pada grup ketersediaan Anda karena latensi jaringan yang tinggi antara kedua situs.
Mode ketersediaan penerapan asinkron
Di bawah mode komitmen asinkron, replika sekunder tidak pernah menjadi sinkron dengan replika utama. Meskipun database sekunder tertentu mungkin mengejar database utama yang sesuai, database sekunder apa pun dapat tertinggal kapan saja. Mode penerapan asinkron dapat berguna dalam skenario pemulihan bencana di mana replika utama dan replika sekunder dipisahkan oleh jarak yang signifikan dan di mana Anda tidak ingin kesalahan kecil memengaruhi replika utama atau dalam situasi di mana performa lebih penting daripada perlindungan data yang disinkronkan. Selain itu, karena replika utama tidak menunggu pengakuan dari replika sekunder, masalah pada replika sekunder tidak pernah berdampak pada replika utama.
Replika sekunder dengan komitmen asinkron berusaha untuk terus mengikuti catatan log yang diterima dari replika utama. Tetapi database sekunder commit asinkron selalu tidak tersinkronkan dan agak tertinggal di belakang database utama yang sesuai. Biasanya kesenjangan antara database sekunder penerapan asinkron dan database utama yang sesuai kecil. Tetapi kesenjangan dapat menjadi substansial jika server yang menghosting replika sekunder kelebihan beban atau jaringan lambat.
Satu-satunya bentuk failover yang didukung oleh mode penerapan asinkron adalah failover paksa (dengan kemungkinan kehilangan data). Memaksa failover adalah upaya terakhir yang hanya ditujukan untuk situasi di mana replika utama saat ini akan tetap tidak tersedia untuk jangka waktu yang lama dan ketersediaan langsung database utama lebih penting daripada risiko kemungkinan kehilangan data. Target failover harus berupa replika yang perannya berada dalam status SECONDARY atau RESOLVING . Target failover beralih ke peran utama, dan salinan databasenya menjadi database utama. Semua database sekunder yang tersisa, bersama dengan database utama sebelumnya, begitu mereka tersedia, ditangguhkan hingga Anda mengaktifkannya secara manual satu per satu. Dalam mode komit asinkron, semua log transaksi yang belum dikirim oleh replika utama asli ke replika sekunder sebelumnya akan hilang. Ini berarti bahwa beberapa atau semua database utama baru mungkin tidak memiliki transaksi yang baru saja dilakukan. Untuk informasi selengkapnya tentang cara kerja failover paksa dan praktik terbaik untuk menggunakannya, lihat Mode Failover dan Failover (Grup Ketersediaan AlwaysOn).
Mode ketersediaan komit sinkron
Di bawah mode ketersediaan komit sinkron (sinkronisasi-komit), setelah tergabung ke dalam grup ketersediaan, database sekunder menyelaraskan dengan database utama yang bersangkutan dan memasuki status SYNCHRONIZED. Database sekunder tetap SYNCHRONIZED ada selama sinkronisasi data berlanjut. Ini menjamin bahwa setiap transaksi yang dilakukan pada database utama tertentu dilakukan pada database sekunder yang sesuai. Ketika setiap database sekunder pada replika sekunder tertentu disinkronkan, status sinkronisasi-kesehatan replika sekunder secara keseluruhan adalah HEALTHY.
Di bagian ini:
- Faktor-faktor yang mengganggu sinkronisasi data
- Cara kerja sinkronisasi pada replika sekunder
- Mode penerapan sinkron hanya dengan failover manual
- Mode komit sinkron dengan failover otomatis
Faktor-faktor yang mengganggu sinkronisasi data
Setelah semua databasenya disinkronkan, replika sekunder memasuki status HEALTHY . Replika sekunder yang disinkronkan tetap sehat kecuali salah satu hal berikut ini terjadi:
Penundaan atau kesalahan jaringan atau komputer menyebabkan sesi antara replika sekunder dan replika utama kehabisan waktu.
Catatan
Untuk informasi tentang properti durasi sesi replika ketersediaan, lihat Apa itu grup ketersediaan Always On?
Anda menunda database sekunder pada replika sekunder. Replika sekunder berhenti disinkronkan, dan status kesehatan sinkronisasinya ditandai sebagai NOT_HEALTHY. Replika sekunder tidak dapat menjadi sehat lagi sampai database sekunder yang ditangguhkan dilanjutkan dan disinkronkan ulang atau dihapus dari grup ketersediaan.
Anda menambahkan database utama ke grup ketersediaan. Replika sekunder yang sebelumnya disinkronkan memasuki status kesehatan sinkronisasi
NOT_HEALTHY. Status ini menunjukkan bahwa setidaknya satu database berada dalam statusNOT SYNCHRONIZINGsinkronisasi. Replika sekunder tertentu tidak dapatHEALTHYlagi sampai database sekunder yang sesuai telah disiapkan pada replika, telah bergabung ke grup ketersediaan, dan telah disinkronkan dengan database utama baru.Anda mengubah salah satu dari replika utama atau replika sekunder menjadi mode ketersediaan penerapan komit asinkron. Setelah berubah ke mode komit asinkron, replika sekunder akan tetap dalam status sinkronisasi kesehatan selama sinkronisasi data berlanjut. Namun, jika hanya replika utama yang diubah ke mode komitmen asinkron, replika sekunder komitmen sinkron akan memasuki
PARTIALLY_HEALTHYstatus sinkronisasi-kesehatan. Status ini menunjukkan bahwa setidaknya satu database berada dalamSYNCHRONIZINGstatus sinkronisasi, tetapi tidak ada database yang berada dalam statusNOT SYNCHRONIZING.Anda mengubah replika sekunder ke mode ketersediaan commit sinkron. Hal ini menyebabkan replika sekunder ditandai sebagai dalam
PARTIALLY_HEALTHYstatus synchronization-health hingga semua databasenya berada dalamSYNCHRONIZEDstatus sinkronisasi.
Petunjuk / Saran
Untuk melihat kesehatan sinkronisasi dari grup ketersediaan, replika ketersediaan, atau database ketersediaan, lakukan kueri pada kolom synchronization_health atau synchronization_health_desc dari sys.dm_hadr_availability_group_states, sys.dm_hadr_availability_replica_states, atau sys.dm_hadr_database_replica_states.
Cara kerja sinkronisasi pada replika sekunder
Dalam mode komitmen sinkron, setelah replika sekunder bergabung dengan grup ketersediaan dan menjalin sesi dengan replika utama:
- Replika sekunder menulis catatan log yang masuk ke disk (mengamankan log).
- Replika sekunder mengirimkan pesan konfirmasi ke replika utama.
Setelah log yang diperkeras pada database sekunder telah mencapai akhir log pada database utama, status database sekunder diatur ke SYNCHRONIZED.
Waktu yang diperlukan untuk sinkronisasi tergantung pada seberapa jauh database sekunder berada di belakang database utama pada awal sesi. Delta ini diukur dengan jumlah rekaman log yang awalnya diterima dari replika utama, beban kerja pada database utama, dan kecepatan host instans replika sekunder.
Proses transaksi
Dalam mode komit sinkron, transaksi di-komitkan ke kedua replika dalam urutan ini:
Replika utama menerima transaksi dari klien.
Replika utama menulis catatan ke log transaksi dan secara bersamaan mengirim catatan log ke replika sekunder.
Setelah catatan log ditulis ke log transaksi database utama, transaksi hanya dapat dibatalkan jika ada failover ke sekunder yang tidak menerima log.
Replika utama menunggu konfirmasi dari replika sekunder synchronous-commit.
Replika sekunder mengeraskan log dan mengembalikan pengakuan ke replika utama.
Replika utama menyelesaikan pemrosesan penerapan dan mengirim pesan konfirmasi ke klien.
Batas waktu komit sinkron
Jika waktu replika sekunder penerapan sinkron habis tanpa mengonfirmasi bahwa replika tersebut telah mengeraskan log, tindakan berikut terjadi di grup ketersediaan:
- Replika utama menandai replika sekunder tersebut sebagai gagal.
- Status replika sekunder berubah menjadi
DISCONNECTED. - Primer berhenti menunggu konfirmasi.
- Grup ketersediaan menandai status sinkronisasi sebagai
NOT SYNCHRONIZINGdan status replika sebagaiNOT_HEALTHY.
Perilaku ini memastikan bahwa replika sekunder komit sinkron yang gagal tidak mencegah pengerasan log pada replika utama.
Ketika replika sekunder kembali online:
- Status replika sekunder berubah menjadi
CONNECTED. - Replika sekunder memproses antrean pengiriman log replika utama.
- Status sinkronisasi beralih ke
SYNCHRONIZING, dan kesehatan replika kePARTIALLY_HEALTHY.
Setelah antrean pengiriman log diproses, status sinkronisasi menjadi SYNCHRONIZED, dan kesehatan replika menjadi HEALTHY.
Mode komit sinkron melindungi data Anda dengan mengharuskan data disinkronkan antara dua tempat, dengan konsekuensi sedikit meningkatkan latensi transaksi.
Mode penerapan sinkron hanya dengan failover manual
Ketika replika ini tersambung dan database disinkronkan, pindah alih manual tersedia. Jika replika sekunder turun, replika utama tidak terpengaruh. Replika utama berjalan dalam keadaan terbuka jika tidak ada SYNCHRONIZED replika lain (yaitu, tanpa mengirim data ke replika sekunder mana pun). Jika replika utama hilang, replika sekunder memasuki RESOLVING status , tetapi pemilik database dapat memaksa failover ke replika sekunder (dengan kemungkinan kehilangan data). Untuk informasi selengkapnya, lihat Mode Failover dan Failover (Grup Ketersediaan AlwaysOn).
Mode komit sinkron dengan failover otomatis
Failover otomatis memberikan keandalan tinggi dengan memastikan bahwa database dapat segera diakses kembali setelah terjadi gangguan pada replika utama. Untuk mengonfigurasi grup ketersediaan untuk failover otomatis, Anda perlu mengatur replika utama saat ini dan setidaknya satu replika sekunder ke mode penerapan sinkron dengan failover otomatis. SQL Server 2019 (15.x) meningkatkan jumlah maksimum replika sinkron menjadi 5, naik dari 3 di SQL Server 2017 (14.x). Anda dapat mengonfigurasi grup lima replika ini untuk memiliki failover otomatis dalam grup. Ada satu replika utama, ditambah empat replika sekunder sinkron.
Selain itu, agar failover otomatis dimungkinkan pada waktu tertentu, replika sekunder ini harus disinkronkan dengan replika utama (yaitu, database sekunder semuanya disinkronkan), dan kluster Windows Server Failover Clustering (WSFC) harus memiliki kuorum. Jika replika utama menjadi tidak tersedia dalam kondisi ini, failover otomatis terjadi. Replika sekunder beralih ke peran utama, dan menawarkan databasenya sebagai database utama. Untuk informasi selengkapnya, lihat bagian "Failover Otomatis" dari artikel Failover dan Mode Failover (Grup Ketersediaan Always On).
Catatan
Untuk informasi tentang kuorum WSFC dan grup ketersediaan AlwaysOn, lihat Untuk informasi selengkapnya, lihat Mode Kuorum WSFC dan Konfigurasi Pemungutan Suara (SQL Server).
Latensi data pada replika sekunder
Menerapkan akses baca-saja ke replika sekunder berguna jika beban kerja baca-saja Anda dapat mentolerir beberapa latensi data. Dalam situasi di mana latensi data tidak dapat diterima, pertimbangkan untuk menjalankan beban kerja baca-saja terhadap replika utama.
Replika utama mengirim catatan log perubahan pada database utama ke replika sekunder. Pada setiap database sekunder, thread khusus pengulangan menerapkan catatan log. Pada database sekunder akses baca, perubahan data tertentu tidak muncul dalam hasil kueri hingga catatan log yang berisi perubahan telah diterapkan ke database sekunder dan transaksi telah dilakukan pada database utama.
Ini berarti bahwa ada beberapa latensi, biasanya hanya hitungan detik, antara replika primer dan sekunder. Namun, dalam kasus yang tidak biasa, misalnya jika masalah jaringan mengurangi throughput, latensi dapat menjadi signifikan. Latensi meningkat ketika hambatan I/O terjadi dan ketika pergerakan data ditangguhkan. Untuk memantau pergerakan data yang ditangguhkan, Anda dapat menggunakan dasbor Grup Ketersediaan AlwaysOn (SQL Server Management Studio) atau tampilan manajemen dinamis sys.dm_hadr_database_replica_states.
Untuk mengurangi latensi di SQL Server 2025 (17.x) dan versi yang lebih baru, Anda dapat mengurangi waktu (dalam milidetik) yang diperlukan replika utama untuk melakukan transaksi ke replika sekunder. Untuk informasi selengkapnya, lihat Konfigurasi server: waktu komit grup ketersediaan (ms).
Untuk mengubah mode ketersediaan dan mode failover
- Mengubah mode ketersediaan replika dalam grup ketersediaan AlwaysOn
- Mengubah mode failover untuk replika dalam grup ketersediaan Always On
Untuk menyesuaikan suara kuorum
- Lihat Pengaturan BobotNode Kuorum Kluster
- Mengonfigurasi Pengaturan NodeWeight Kuorum Kluster
- Memaksa Kluster WSFC untuk Menginisiasi Tanpa Kuorum
Untuk melakukan failover manual
- Melakukan failover manual yang direncanakan dari grup ketersediaan AlwaysOn (SQL Server)
- Melakukan Failover Manual Paksa dari Grup Ketersediaan Always On (SQL Server)
- Menggunakan Panduan Grup Ketersediaan Failover (SQL Server Management Studio)
Untuk melihat grup ketersediaan, replika ketersediaan, dan status database
- sys.dm_hadr_availability_group_states
- sys.dm_hadr_availability_replica_states
- sys.dm_hadr_database_replica_states
Konten terkait
- Panduan Solusi AlwaysOn Microsoft SQL Server untuk Ketersediaan Tinggi dan Pemulihan Bencana
- Blog SQL Server Always On Team: Blog resmi SQL Server Always On Team
- Apa itu grup ketersediaan AlwaysOn?
- Mode Failover dan Failover (Grup Ketersediaan AlwaysOn)
- Pengklusteran Failover Windows Server dengan SQL Server