Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() SQL Server 2016 (13.x) dan versi yang lebih baru
SQL Server 2016 (13.x) dan versi yang lebih baru
Artikel ini memberikan gambaran umum tentang solusi kelangsungan bisnis untuk ketersediaan tinggi dan pemulihan bencana di SQL Server, di Windows dan Linux.
Setiap orang yang menerapkan SQL Server perlu memastikan bahwa semua instans SQL Server yang kritis untuk misi dan database di dalamnya tersedia ketika pengguna bisnis dan pengguna akhir membutuhkannya, baik ketersediaan tersebut selama jam kerja biasa atau 24 jam. Tujuannya adalah untuk menjaga bisnis tetap aktif dan berjalan dengan gangguan minimal atau tanpa gangguan. Konsep ini juga dikenal sebagai kelangsungan bisnis.
SQL Server 2017 (14.x) dan versi yang lebih baru memperkenalkan fitur dan penyempurnaan untuk ketersediaan. Penambahan terbesar adalah dukungan untuk SQL Server pada distribusi Linux. Untuk daftar lengkap fitur baru di SQL Server, lihat artikel berikut ini:
| Versi | Sistem operasi |
|---|---|
| Apa yang baru di SQL Server 2025 (17.x) | Windows | Linux |
| Apa yang baru di SQL Server 2022 (16.x) | Windows | Linux |
| Apa yang baru di SQL Server 2019 (15.x) | Windows | Linux |
| Apa yang baru di SQL Server 2017 (14.x) | Windows | Linux |
Artikel ini berfokus pada skenario ketersediaan di SQL Server 2017 (14.x) dan versi yang lebih baru, serta fitur ketersediaan baru dan yang ditingkatkan. Skenario ini termasuk yang hibrid yang dapat mencakup penyebaran SQL Server di Windows Server dan Linux, dan yang dapat meningkatkan jumlah salinan database yang dapat dibaca.
Meskipun artikel ini tidak mencakup opsi ketersediaan di luar SQL Server (seperti virtualisasi), semuanya yang dibahas di sini berlaku untuk penginstalan SQL Server di dalam komputer virtual tamu baik di cloud publik atau dihosting oleh server hypervisor lokal.
Skenario SQL Server yang menggunakan fitur ketersediaan
Anda dapat menggunakan grup ketersediaan AlwaysOn, instans kluster failover, dan pengiriman log dengan cara yang berbeda, dan bukan hanya untuk ketersediaan. Ada empat cara utama Anda dapat menggunakan fitur ketersediaan:
- Ketersediaan tinggi
- Pemulihan dari bencana
- Migrasi dan peningkatan
- Menskalakan salinan yang dapat dibaca dari satu atau beberapa database
Bagian berikut menjelaskan fitur yang relevan untuk setiap skenario. Salah satu fitur yang tidak tercakup adalah replikasi SQL Server. Meskipun replikasi SQL Server tidak secara resmi ditetapkan sebagai fitur ketersediaan di bawah payung AlwaysOn, replikasi ini sering digunakan untuk membuat data redundan dalam skenario tertentu. Replikasi penggabungan tidak didukung untuk SQL Server di Linux. Untuk informasi selengkapnya, lihat Replikasi SQL Server di Linux.
Penting
Fitur ketersediaan SQL Server tidak menggantikan persyaratan untuk memiliki strategi pencadangan dan pemulihan yang kuat dan teruji dengan baik. Strategi pencadangan dan pemulihan adalah blok penyusun paling mendasar dari solusi ketersediaan apa pun.
Ketersediaan tinggi
Penting untuk memastikan bahwa instans atau database SQL Server tersedia jika terjadi masalah yang lokal ke pusat data atau wilayah tunggal di cloud. Bagian ini menjelaskan bagaimana fitur ketersediaan SQL Server dapat membantu. Semua fitur yang dijelaskan tersedia baik di Windows Server maupun di Linux.
Grup ketersediaan
Grup ketersediaan (AG) memberikan perlindungan tingkat database dengan mengirim setiap transaksi database ke instans lain, atau replika, yang berisi salinan database tersebut dalam status khusus. Anda dapat menyebarkan AG pada edisi Standar atau Perusahaan. Instans yang berpartisipasi dalam AG dapat berupa instans kluster mandiri atau failover (FCI, yang dijelaskan di bagian berikutnya). Karena transaksi dikirim ke replika saat terjadi, AG direkomendasikan di mana ada persyaratan untuk titik pemulihan yang lebih pendek dan waktu pemulihan yang lebih cepat. Pergerakan data antar replika dapat sinkron atau asinkron, dengan edisi Enterprise memungkinkan hingga tiga replika (termasuk yang utama) sebagai sinkron. AG memiliki satu salinan database baca/tulis sepenuhnya yang ada di replika utama, sementara semua replika sekunder tidak dapat menerima transaksi langsung dari pengguna akhir atau aplikasi.
Catatan
Always On adalah istilah payung untuk fitur ketersediaan di SQL Server dan mencakup AG dan FCI. Always On bukan nama fitur AG.
Sebelum SQL Server 2022 (16.x), AG hanya menyediakan tingkat database, dan bukan perlindungan tingkat instans. Apa pun yang tidak diambil dalam log transaksi atau dikonfigurasi dalam database harus disinkronkan secara manual untuk setiap replika sekunder. Beberapa contoh objek yang harus disinkronkan secara manual adalah login di tingkat instans, server tertaut, dan pekerjaan SQL Server Agent.
Di SQL Server 2022 (16.x) dan versi yang lebih baru, Anda dapat mengelola objek metadata termasuk pengguna, login, izin, dan pekerjaan SQL Server Agent di tingkat AG selain tingkat instans. Untuk informasi selengkapnya, lihat Apa itu grup ketersediaan mandiri?
AG juga memiliki komponen lain yang disebut listener, yang memungkinkan aplikasi dan pengguna akhir untuk terhubung tanpa perlu mengetahui instans SQL Server mana yang menghosting replika utama. Setiap AG memiliki pendengarnya sendiri. Meskipun implementasi listener sedikit berbeda di Windows Server versus Linux, keduanya menyediakan fungsionalitas dan kegunaan yang sama. Diagram berikut menunjukkan AG berbasis Windows Server yang menggunakan Kluster Failover Windows Server (WSFC). Kluster yang mendasar di lapisan OS diperlukan untuk ketersediaan baik di Linux atau Windows Server. Contoh menunjukkan konfigurasi sederhana dengan dua server, atau simpul, dengan WSFC sebagai kluster dasar.
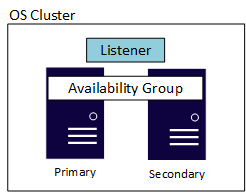
Edisi Standar dan Enterprise memiliki batas maksimum yang berbeda terkait replika. AG dalam edisi Standar, yang dikenal sebagai grup ketersediaan dasar, mendukung dua replika (satu primer dan satu sekunder) hanya dengan satu database di AG. Edisi perusahaan tidak hanya memungkinkan beberapa database dikonfigurasi dalam satu AG, tetapi juga dapat memiliki hingga sembilan total replika (satu primer, delapan sekunder). Edisi perusahaan juga memberikan manfaat opsional lainnya seperti replika sekunder yang dapat dibaca, kemampuan untuk membuat cadangan dari replika sekunder, dan banyak lagi.
Catatan
Pencerminan database, yang tidak digunakan lagi di SQL Server 2012 (11.x), tidak tersedia di versi Linux SQL Server, juga tidak ditambahkan. Pelanggan yang masih menggunakan pencerminan database harus berencana untuk bermigrasi ke AG, yang merupakan pengganti pencerminan database.
Dalam konteks ketersediaan, AG dapat menyediakan failover otomatis atau manual. Failover otomatis dapat terjadi jika pergerakan data sinkron dikonfigurasi dan database pada replika primer dan sekunder dalam keadaan disinkronkan. Selama pendengar digunakan dan aplikasi menggunakan versi .NET Framework yang didukung (3,5 dengan Paket Layanan 1, atau versi 4.6.2 dan yang lebih baru), failover harus ditangani dengan minimal hingga tidak berpengaruh pada pengguna akhir jika pendengar digunakan. Mengalihkan ke replika sekunder untuk menjadikannya replika utama baru dapat dikonfigurasi agar otomatis atau manual, dan umumnya diukur dalam hitungan detik.
Daftar berikut menyoroti beberapa perbedaan dengan AG di Windows Server versus Linux:
Karena cara kerja kluster yang mendasar di Linux dan Windows Server, semua failover AG (manual atau otomatis) dilakukan melalui kluster di Linux. Pada penyebaran AG berbasis Windows Server, failover manual harus dilakukan melalui SQL Server. Failover otomatis ditangani oleh kluster yang mendasar di Windows Server dan Linux.
Untuk SQL Server di Linux, Anda harus mengonfigurasi AG dengan minimal tiga replika, karena cara kerja pengklusteran yang mendasar.
Di Linux, nama umum yang digunakan oleh setiap pendengar didefinisikan dalam DNS dan bukan di kluster seperti di Windows Server.
SQL Server 2017 (14.x) memperkenalkan fitur dan penyempurnaan berikut pada AG:
- Jenis kluster
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT- Dukungan Koordinator Transaksi Distributor Microsoft (DTC) yang ditingkatkan untuk konfigurasi berbasis Windows Server
- Skenario penambahan kapasitas untuk database baca-saja (dijelaskan nanti dalam artikel ini)
Jenis kluster grup ketersediaan
Bentuk ketersediaan bawaan dari pengklusteran di Windows Server diaktifkan melalui fitur bernama Pengelompokan Pengalihan. Ini memungkinkan Anda membangun WSFC yang dapat digunakan dengan AG atau FCI. SQL Server mengirimkan DLL sumber daya sadar kluster yang menyediakan integrasi untuk AG dan FCI.
SQL Server di Linux mendukung beberapa teknologi pengklusteran. Microsoft mendukung komponen SQL Server, sementara mitra kami mendukung teknologi pengklusteran yang relevan. Misalnya, bersama dengan Pacemaker, SQL Server di Linux mendukung HPE Serviceguard dan DH2i DxEnterprise sebagai solusi kluster.
Kluster failover berbasis Windows dan solusi kluster Linux lebih mirip dari yang berbeda. Keduanya menyediakan cara untuk mengambil server individual dan menggabungkannya dalam konfigurasi untuk menyediakan ketersediaan, dan memiliki konsep hal-hal seperti sumber daya, batasan (bahkan jika diimplementasikan secara berbeda), failover, dan sebagainya.
Misalnya, untuk mendukung Pacemaker dalam konfigurasi AG dan FCI, termasuk failover otomatis, Microsoft menyediakan paket mssql-server-ha, yang mirip dengan, tetapi tidak persis sama dengan DLL sumber daya di WSFC, untuk Pacemaker. Salah satu perbedaan antara WSFC dan Pacemaker adalah bahwa tidak ada sumber daya nama jaringan di Pacemaker, yang merupakan komponen yang membantu mengabstraksi nama pendengar (atau nama FCI) pada WSFC. Gunakan DNS untuk resolusi nama di Linux.
Karena perbedaan dalam stack kluster, AG di SQL Server 2017 (14.x) dan versi yang lebih baru perlu menangani beberapa metadata yang ditangani secara bawaan oleh WSFC. Misalnya, ada tiga jenis kluster untuk grup ketersediaan, yang disimpan di sys.availability_groups, cluster_type, dan cluster_type_desc kolom:
- WSFC
- Eksternal
- Tidak
Semua AG yang memerlukan ketersediaan tinggi harus menggunakan kluster yang mendasar, yang dalam kasus SQL Server 2017 (14.x) dan versi yang lebih baru berarti WSFC atau agen pengklusteran Linux. Untuk AG berbasis Windows Server yang menggunakan WSFC yang mendasar, jenis kluster default adalah WSFC dan Anda tidak perlu mengaturnya. Untuk AG berbasis Linux, Anda harus mengatur jenis kluster ke Eksternal saat membuat AG. Integrasi dengan solusi kluster eksternal di Linux dikonfigurasi setelah AG dibuat, sedangkan pada WSFC, itu dilakukan pada waktu pembuatan.
Jenis kluster Tidak Ada dapat digunakan dengan Windows Server dan Linux AG. Mengatur jenis kluster ke Tidak Ada berarti bahwa AG tidak memerlukan kluster yang mendasar. Ini berarti SQL Server 2017 (14.x) adalah versi pertama SQL Server yang mendukung AG tanpa kluster, tetapi komprominya adalah bahwa konfigurasi ini tidak didukung sebagai solusi ketersediaan tinggi.
Penting
Di SQL Server 2017 (14.x) dan versi yang lebih baru, Anda tidak dapat mengubah jenis kluster untuk AG setelah dibuat. Pembatasan ini berarti bahwa AG tidak dapat dialihkan dari opsi Tidak Ada ke Eksternal atau WSFC, dan sebaliknya.
Jika Anda hanya ingin menambahkan salinan tambahan dari database yang bersifat baca-saja, atau jika Anda menginginkan manfaat yang disediakan AG untuk migrasi dan peningkatan tanpa harus berurusan dengan kompleksitas kluster yang mendasari atau bahkan replikasi, pertimbangkan untuk menyiapkan AG dengan jenis kluster Tanpa. Untuk informasi selengkapnya, lihat bagian Migrasi dan upgrade dan read-scale.
Cuplikan layar berikut menunjukkan dukungan untuk berbagai jenis jenis kluster di SQL Server Management Studio (SSMS). Anda harus menjalankan versi 17.1 atau yang lebih baru. Cuplikan layar berikut berasal dari versi 17.2:

PERSYARATAN_SECONDARIES_TERKONSINKRONISASI_UNTUK_KOMIT
SQL Server 2016 (13.x) meningkatkan dukungan untuk jumlah replika sinkron dari dua menjadi tiga di edisi Enterprise. Namun, jika satu replika sekunder disinkronkan tetapi replika lain mengalami masalah, tidak ada cara untuk mengatur perilaku untuk memberi instruksi kepada primer, apakah harus menunggu replika yang bermasalah atau mengizinkannya untuk melanjutkan. Dalam skenario ini, replika utama masih dapat menerima lalu lintas tulis meskipun replika sekunder tidak dalam keadaan disinkronkan, yang mengakibatkan kehilangan data pada replika sekunder.
Di SQL Server 2017 (14.x) dan versi yang lebih baru, Anda dapat mengontrol perilaku apa yang terjadi ketika ada replika sinkron dengan REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT. Opsi ini berfungsi sebagai berikut:
- Ada tiga nilai yang mungkin:
0, ,1dan2. - Nilainya adalah jumlah replika sekunder yang harus disinkronkan, yang memiliki implikasi untuk kehilangan data, ketersediaan AG, dan failover.
- Untuk WSFC dan jenis kluster Tidak Ada, nilai defaultnya adalah
0, dan Anda dapat mengaturnya secara manual ke1atau2. - Untuk jenis kluster Eksternal, mekanisme kluster mengatur nilai ini secara default, dan Anda dapat mengambil alihnya secara manual. Untuk tiga replika sinkron, nilai defaultnya adalah
1.
Di Linux, Anda mengonfigurasi nilai untuk REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT pada sumber daya AG di kluster. Di Windows, Anda mengaturnya melalui Transact-SQL.
Nilai yang lebih tinggi daripada 0 memastikan perlindungan data yang lebih tinggi, karena jika jumlah replika sekunder yang diperlukan tidak tersedia, replika utama tidak tersedia hingga kondisi tersebut teratasi.
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT juga memengaruhi perilaku failover karena failover otomatis tidak dapat terjadi jika jumlah replika sekunder yang tepat tidak dalam status yang tepat. Di Linux, nilai 0 tidak memungkinkan failover otomatis, jadi saat menggunakan sinkronisasi dengan failover otomatis di Linux, Anda harus mengatur nilai yang lebih tinggi dari 0 agar dapat mencapai failover otomatis.
0 pada Windows Server adalah perilaku di SQL Server 2016 (13.x) dan versi yang lebih lama.
Dukungan Koordinator Transaksi Terdistribusi Microsoft yang Ditingkatkan
Sebelum SQL Server 2016 (13.x), satu-satunya cara untuk mendapatkan ketersediaan di SQL Server untuk aplikasi yang memerlukan transaksi terdistribusi, yang menggunakan DTC di bawah sampul, adalah dengan menyebarkan FCI. Transaksi terdistribusi dapat dilakukan dengan salah satu dari dua cara:
- Transaksi yang mencakup lebih dari satu database dalam instans SQL Server yang sama.
- Transaksi yang mencakup lebih dari satu instans SQL Server atau mungkin melibatkan sumber data non-SQL Server.
SQL Server 2016 (13.x) memperkenalkan dukungan parsial untuk DTC dengan AG yang mencakup skenario terakhir. SQL Server 2017 (14.x) menyelesaikan cerita dengan mendukung kedua skenario dengan DTC.
Di SQL Server 2017 (14.x) dan versi yang lebih baru, Anda dapat menambahkan dukungan DTC ke AG setelah dibuat. Di SQL Server 2016 (13.x), Anda hanya dapat mengaktifkan dukungan DTC saat membuat AG.
Instans kluster failover
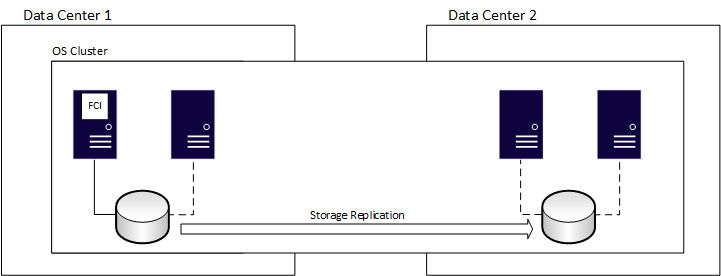
Instans kluster failover (FCI) menyediakan ketersediaan untuk seluruh penginstalan SQL Server, yang dikenal sebagai instans. Dengan FCI, jika server yang mendasar mengalami masalah, semua yang ada di dalam instans dipindahkan ke server lain, termasuk database, pekerjaan SQL Server Agent, server tertaut, dan banyak lagi. Semua FCI memerlukan beberapa penyimpanan bersama, bahkan jika itu ditentukan oleh jaringan. Satu simpul dapat menjalankan dan memiliki sumber daya FCI pada waktu tertentu. Dalam diagram berikut, simpul pertama kluster memiliki FCI. Ini juga memiliki dan mengelola sumber daya penyimpanan bersama yang terkait dengannya, yang ditunjukkan dengan garis solid ke penyimpanan.

Setelah failover, kepemilikan berubah, seperti yang diperlihatkan dalam diagram berikut:

FCI memiliki nol kehilangan data, tetapi penyimpanan bersama yang mendasar adalah satu-satunya titik kegagalan karena hanya ada satu salinan data. Untuk memiliki salinan database yang berlebihan, gabungkan FCI dengan metode ketersediaan lain, seperti AG atau pengiriman log. Metode lain harus menggunakan penyimpanan yang terpisah secara fisik dari FCI. Ketika FCI gagal beralih ke node lain, FCI berhenti pada satu node dan mulai pada node lain. Proses ini mirip dengan mematikan server dan menyalakannya.
FCI melewati proses pemulihan normal. Ini menggulirkan transaksi apa pun yang perlu digulirkan ke depan, dan mengembalikan transaksi yang tidak lengkap. Oleh karena itu, database konsisten dari titik data hingga waktu kegagalan atau failover manual, sehingga tidak ada kehilangan data. Database hanya tersedia setelah pemulihan selesai. Waktu pemulihan tergantung pada banyak faktor dan umumnya lebih lama dibandingkan dengan failover pada AG. Kompromi adalah bahwa ketika Anda melakukan failover AG, mungkin ada tugas tambahan yang diperlukan untuk membuat database dapat digunakan, seperti mengaktifkan job SQL Server Agent.
Catatan
Pemulihan database yang dipercepat (ADR) dapat mengurangi waktu pemulihan. Untuk informasi selengkapnya, lihat Pemulihan database yang dipercepat.
Seperti AG, FCI mengabstraksi node mana dari cluster dasar yang menghostingnya. FCI selalu mempertahankan nama yang sama. Aplikasi dan pengguna akhir tidak pernah terhubung ke simpul. Sebaliknya, mereka menggunakan nama unik yang sudah ditetapkan untuk FCI. FCI dapat berpartisipasi dalam AG sebagai salah satu instans yang menghosting replika baik primer maupun sekunder.
Daftar berikut menyoroti beberapa perbedaan dengan FCI di Windows Server versus Linux:
- Di Windows Server, FCI adalah bagian dari proses penginstalan. Anda mengonfigurasi FCI di Linux setelah menginstal SQL Server.
- Linux hanya mendukung satu penginstalan SQL Server per host, sehingga semua FCI adalah instans default. Windows Server mendukung hingga 25 FCI per WSFC.
- Nama umum yang digunakan oleh FCI di Linux didefinisikan dalam DNS, dan harus sama dengan sumber daya yang dibuat untuk FCI.
Pengiriman log
Jika tujuan titik pemulihan dan waktu pemulihan lebih fleksibel, atau database tidak terlalu penting untuk misi, pengiriman log adalah fitur ketersediaan lain yang terbukti di SQL Server. Berdasarkan cadangan bawaan SQL Server, proses pengiriman log secara otomatis menghasilkan pencadangan log transaksi, menyalinnya ke satu atau beberapa instans yang dikenal sebagai cadangan siaga hangat, dan secara otomatis menerapkan pencadangan log transaksi ke cadangan tersebut. Pengiriman Log menggunakan pekerjaan agen SQL Server untuk mengotomatiskan proses pencadangan, penyalinan, dan penerapan pencadangan log transaksi.

Keuntungan terbesar menggunakan pengiriman log adalah bahwa itu memperhitungkan kesalahan manusia, karena Anda dapat menunda implementasi log transaksi. Misalnya, jika seseorang mengeluarkan UPDATE tanpa klausul WHERE, sistem siaga mungkin tidak memiliki perubahan tersebut, sehingga Anda dapat beralih ke sistem tersebut sambil memperbaiki sistem utama. Meskipun pengiriman log mudah dikonfigurasi, beralih dari server utama ke cadangan hangat, yang disebut sebagai perubahan peran, selalu dilakukan secara manual. Anda memulai perubahan peran melalui Transact-SQL, dan seperti pada Availability Group (AG), Anda harus secara manual menyinkronkan semua objek yang tidak tercatat dalam log transaksi. Anda perlu mengonfigurasi pengiriman log per database, sedangkan satu AG dapat berisi beberapa database.
Tidak seperti AG atau FCI, pengiriman log tidak memiliki abstraksi untuk perubahan peran yang harus bisa ditangani oleh aplikasi. Teknik seperti alias DNS (CNAME) dapat digunakan, tetapi ada pro dan kontra, seperti waktu yang diperlukan AGAR DNS di-refresh setelah pengalihan.
Pemulihan dari bencana
Ketika lokasi ketersediaan utama Anda mengalami peristiwa bencana seperti gempa atau banjir, bisnis harus siap untuk memiliki sistemnya online di tempat lain. Bagian ini mencakup bagaimana fitur ketersediaan SQL Server dapat membantu kelangsungan bisnis.
Grup ketersediaan
Salah satu manfaat AG adalah Anda mengonfigurasi ketersediaan tinggi dan pemulihan bencana menggunakan satu fitur. Tanpa persyaratan untuk memastikan bahwa penyimpanan bersama juga sangat tersedia, jauh lebih mudah untuk memiliki replika yang lokal dalam satu pusat data untuk ketersediaan tinggi, dan yang terpencil di pusat data lain untuk pemulihan bencana masing-masing dengan penyimpanan terpisah. Memiliki salinan tambahan dari database adalah kompromi untuk memastikan redundansi. Contoh AG yang mencakup beberapa pusat data diperlihatkan dalam diagram berikut. Satu replika utama bertanggung jawab untuk menjaga semua replika sekunder tetap sinkron.

Di luar AG dengan jenis kluster Tidak Ada, AG mengharuskan semua replika adalah bagian dari kluster yang mendasar yang sama baik itu WSFC atau solusi kluster eksternal. Dalam diagram sebelumnya, WSFC direntangkan untuk bekerja di dua pusat data yang berbeda, yang menambah kompleksitas terlepas dari platform (Windows Server atau Linux). Memperluas kluster di berbagai lokasi menambah kompleksitas.
Diperkenalkan di SQL Server 2016 (13.x), grup ketersediaan terdistribusi memungkinkan Availability Group (AG) untuk menghubungkan AG antara kluster yang berbeda. AG terdistribusi memisahkan persyaratan untuk membuat semua simpul berpartisipasi dalam kluster yang sama, yang membuat konfigurasi pemulihan bencana jauh lebih mudah. Untuk informasi selengkapnya tentang AG terdistribusi, lihat Grup ketersediaan terdistribusi.

Instans kluster failover
Anda dapat menggunakan FCI untuk pemulihan bencana. Seperti halnya AG normal, Anda harus memperluas mekanisme kluster yang mendasar ke semua lokasi, yang menambah kompleksitas. Untuk FCI, Anda juga perlu mempertimbangkan penyimpanan bersama. Situs utama dan sekunder memerlukan akses ke disk yang sama. Untuk memastikan bahwa penyimpanan yang digunakan oleh FCI ada di kedua situs, gunakan metode eksternal seperti fungsionalitas yang disediakan oleh vendor penyimpanan di lapisan perangkat keras. Atau, gunakan Replika Penyimpanan di Windows Server.
Pengiriman log
Pengiriman log adalah salah satu metode tertua untuk menyediakan pemulihan bencana untuk database SQL Server. Pengiriman log sering digunakan dengan AG dan FCI untuk memberikan pemulihan bencana yang hemat biaya dan lebih sederhana di mana opsi lain mungkin menantang karena lingkungan, keterampilan administratif, atau anggaran. Mirip dengan pendekatan ketersediaan tinggi untuk pengiriman log, banyak lingkungan menunda pemuatan log transaksi untuk mengantisipasi kesalahan manusia.
Migrasi dan peningkatan
Saat organisasi menyebarkan instans baru atau meningkatkan instans lama, organisasi tidak dapat mentolerir pemadaman yang lama. Bagian ini membahas bagaimana fitur ketersediaan SQL Server dapat digunakan untuk meminimalkan waktu henti dalam perubahan arsitektur yang direncanakan, sakelar server, perubahan platform (seperti Windows Server ke Linux atau sebaliknya), atau selama patching.
Catatan
Anda juga dapat menggunakan metode lain, seperti pencadangan dan pemulihan, untuk migrasi dan peningkatan. Artikel ini tidak membahas metode tersebut.
Grup ketersediaan
Anda dapat meningkatkan instans yang ada yang berisi satu atau beberapa grup ketersediaan (AG) di tempat, ke versi SQL Server yang lebih baru. Meskipun peningkatan ini membutuhkan beberapa waktu henti, hal ini dapat diminimalkan dengan perencanaan yang tepat.
Jika Anda ingin bermigrasi ke server baru tanpa mengubah konfigurasi (termasuk sistem operasi atau versi SQL Server), tambahkan server tersebut sebagai simpul ke kluster dasar yang ada, lalu tambahkan ke AG. Setelah salinan atau salinan-salinan berada dalam status yang tepat, lakukan failover secara manual ke server baru. Kemudian, hapus server lama dari AG dan nonaktifkan.
AG terdistribusi juga merupakan metode lain untuk bermigrasi ke konfigurasi baru atau meningkatkan SQL Server. Karena AG terdistribusi mendukung AG yang mendasar yang berbeda pada arsitektur yang berbeda, Anda dapat mengubah dari SQL Server 2019 (15.x) yang berjalan pada Windows Server 2019 ke SQL Server 2025 (17.x) yang berjalan di Windows Server 2025.

Terakhir, AG dengan jenis kluster None berguna untuk migrasi atau peningkatan. Anda tidak dapat mencampur dan mencocokkan jenis kluster dalam konfigurasi AG biasa, sehingga semua replika harus menjadi jenis Tidak Ada. AG terdistribusi dapat digunakan untuk menjangkau AG yang dikonfigurasi dengan jenis kluster yang berbeda. Metode ini juga didukung di berbagai platform OS.
Semua varian AG untuk migrasi dan peningkatan memungkinkan sinkronisasi data, bagian pekerjaan yang paling memakan waktu, tersebar dari waktu ke waktu. Ketika tiba saatnya untuk memulai peralihan ke konfigurasi baru, cutover merupakan periode pemadaman singkat, bukan satu periode waktu henti yang panjang di mana semua pekerjaan, termasuk sinkronisasi data, harus diselesaikan.
AG dapat memberikan waktu henti minimal selama patching sistem operasi (OS) yang mendasarinya dengan melakukan failover secara manual dari replika primer ke replika sekunder saat patching sedang berlangsung. Dari perspektif sistem operasi, melakukan ini lebih umum di Windows Server, karena melayani OS yang mendasarinya dapat memerlukan mulai ulang. Patching Linux terkadang membutuhkan hidupkan ulang, tetapi kurang umum.
Cara lain untuk meminimalkan waktu henti adalah dengan memperbarui patch instans SQL Server yang berpartisipasi dalam grup ketersediaan, tergantung pada seberapa kompleks arsitektur grup ketersediaannya. Anda patch replika sekunder terlebih dahulu. Setelah jumlah replika yang tepat dipatch, alihkan secara manual replika utama ke node lain untuk mendapatkan peningkatan. Tingkatkan replika sekunder yang tersisa pada tahap tersebut.
Instans kluster failover
FCI sendiri tidak dapat membantu migrasi atau peningkatan tradisional. Anda harus mengonfigurasi AG atau pengiriman log untuk database di FCI dan memperhitungkan semua objek lainnya. Namun, FCI di bawah Windows Server masih merupakan opsi populer ketika Anda perlu menambal Windows Server yang mendasar. Ketika Anda memulai failover manual, pemadaman singkat menggantikan periode ketika instans tidak tersedia selama Windows Server sedang diperbaiki.
Anda dapat meningkatkan FCI ke versi SQL Server yang lebih baru. Untuk informasi selengkapnya, lihat Meningkatkan instans kluster failover.
Pengiriman log
Pengiriman log masih merupakan opsi populer untuk memigrasikan dan meningkatkan database. Mirip dengan AG, tetapi kali ini menggunakan log transaksi sebagai metode sinkronisasi, penyebaran data dapat dimulai dengan baik sebelum pengalihan server. Pada saat pengalihan, setelah semua lalu lintas dihentikan di sumbernya, log transaksi akhir perlu diambil, disalin, dan diterapkan ke konfigurasi baru. Pada saat itu, database dapat dibawa secara online.
Pengiriman log sering kali lebih toleran terhadap jaringan yang lebih lambat, dan sementara peralihan mungkin sedikit lebih lama daripada yang dilakukan menggunakan AG atau AG terdistribusi, biasanya diukur dalam hitungan menit, bukan jam, hari, atau minggu.
Mirip dengan AG, pengiriman log dapat menyediakan cara untuk beralih ke server lain selama jendela pemeliharaan.
Metode dan ketersediaan penyebaran SQL Server lainnya
Ada dua metode penyebaran lainnya untuk SQL Server di Linux: kontainer dan menggunakan Azure (atau penyedia cloud publik lainnya). Kebutuhan umum akan ketersediaan ada terlepas dari bagaimana SQL Server disebarkan. Kedua metode ini memiliki beberapa pertimbangan khusus ketika membuat SQL Server sangat tersedia.
Kontainer SQL Server dan opsi HA/DR
Penyebaran kontainer SQL Server adalah cara untuk menyederhanakan provisi, penskalaan, dan manajemen siklus hidup SQL Server di seluruh lingkungan. Kontainer adalah gambar lengkap yang siap dijalankan dari SQL Server.
Bergantung pada platform kontainer Anda, misalnya saat menggunakan orkestrator kontainer seperti Kubernetes, jika kontainer hilang, kontainer dapat disebarkan lagi dan dilampirkan ke penyimpanan bersama yang digunakan. Meskipun ini memberikan beberapa ketahanan, ada beberapa waktu henti yang terkait dengan pemulihan database, dan tidak benar-benar tersedia seperti jika menggunakan grup ketersediaan atau FCI.
Jika Anda ingin mengonfigurasi ketersediaan tinggi untuk kontainer SQL Server yang disebarkan pada platform Kubernetes atau non-Kubernetes, Anda dapat menggunakan DH2i DxEnterprise sebagai salah satu solusi pengklusteran, di atasnya Anda dapat mengonfigurasi AG dalam mode ketersediaan tinggi. Opsi ini memberi Anda tujuan titik pemulihan (RPO) dan tujuan waktu pemulihan (RTO) yang diharapkan dari solusi ketersediaan tinggi.
Penyebaran VM berbasis Linux
Linux dapat disebarkan dengan SQL Server di Linux Azure Virtual Machines. Seperti halnya penginstalan berbasis lokal, penginstalan yang didukung memerlukan penggunaan "fencing" (isolasi) pada node yang gagal, yang berada di luar agen kluster itu sendiri. Anggar node disediakan melalui agen ketersediaan anggar. Beberapa distribusi mengirimkannya sebagai bagian dari platform, sementara yang lain mengandalkan vendor perangkat keras dan perangkat lunak eksternal. Periksa dengan distribusi Linux pilihan Anda untuk melihat bentuk pagar node apa yang disediakan sehingga solusi yang didukung dapat disebarkan di cloud publik.
Panduan untuk menginstal SQL Server di Linux tersedia untuk distribusi berikut:
- Mulai cepat: Menginstal SQL Server dan membuat database di Red Hat
- Mulai cepat: Menginstal SQL Server dan membuat database di Ubuntu
- Mulai cepat: Menginstal SQL Server dan membuat database di SUSE Linux Enterprise Server
Skala pembacaan
Replika sekunder memiliki kemampuan untuk digunakan sebagai kueri baca-saja. Ada dua cara yang dapat dicapai dengan AG:
- Izinkan akses langsung ke sekunder
- Mengonfigurasi perutean baca saja, yang memerlukan penggunaan pendengar. SQL Server 2016 (13.x) memperkenalkan kemampuan untuk membagi beban koneksi baca-saja melalui pengawas menggunakan algoritma round robin, memungkinkan distribusi permintaan baca-saja di semua replika terbaca.
Catatan
Replika sekunder yang dapat dibaca hanya tersedia di edisi Enterprise. Setiap instans yang menghosting replika yang dapat dibaca memerlukan lisensi SQL Server.
Penskalaan salinan database yang dapat dibaca melalui AG pertama kali diperkenalkan dengan AG terdistribusi di SQL Server 2016 (13.x). Fitur ini menawarkan salinan database baca-saja tidak hanya secara lokal, tetapi juga secara regional dan global, dengan konfigurasi minimal. Penyiapan ini mengurangi lalu lintas dan latensi jaringan dengan menjalankan kueri secara lokal. Setiap replika utama AG dapat menyemai dua AG lainnya, bahkan jika itu bukan salinan baca/tulis sepenuhnya, dan setiap AG terdistribusi dapat mendukung hingga 27 salinan data yang dapat dibaca.

Di SQL Server 2017 (14.x) dan versi yang lebih baru, Anda dapat membuat solusi baca-saja yang hampir real time dengan AG yang dikonfigurasi dengan jenis kluster Tidak Ada. Jika tujuan Anda adalah menggunakan AG untuk replika sekunder yang dapat dibaca dan bukan ketersediaan, pendekatan ini menghapus kompleksitas penggunaan WSFC atau solusi kluster eksternal di Linux. Ini memberikan manfaat yang dapat dibaca dari AG dalam metode penyebaran yang lebih sederhana.
Catatan utama yang penting adalah bahwa, karena tidak adanya kluster dasar dengan jenis kluster 'None', pengaturan perutean baca-saja menjadi sedikit berbeda. Dari perspektif SQL Server, pendengar masih diperlukan untuk merutekan permintaan meskipun tidak ada kluster. Alih-alih mengonfigurasi listener tradisional, gunakan alamat IP atau nama replika utama. Replika utama kemudian merutekan permintaan baca-saja.
Siaga hangat pengiriman log secara teknis dapat dikonfigurasi untuk penggunaan yang dapat dibaca dengan memulihkan database WITH STANDBY. Namun, karena log transaksi memerlukan penggunaan eksklusif database untuk pemulihan, itu berarti bahwa pengguna tidak dapat mengakses database saat itu terjadi. Ini menjadikan pengiriman log sebagai solusi yang kurang ideal - terutama jika data yang mendekati waktu nyata diperlukan.
Tidak seperti replikasi transaksi di mana semua data disiarkan langsung, setiap replika sekunder dalam skenario skala baca adalah salinan tepat dari replika utama. Replika tidak dalam keadaan di mana indeks unik dapat diterapkan. Jika ada indeks yang diperlukan untuk pelaporan atau jika data perlu dimanipulasi, Anda harus membuat indeks tersebut pada database pada replika utama. Jika Anda membutuhkan fleksibilitas tersebut, replikasi adalah solusi yang lebih baik untuk data yang dapat dibaca.
Interoperabilitas distribusi lintas platform dan Linux
Dengan dukungan SQL Server di Windows Server dan Linux, bagian ini mencakup bagaimana mereka dapat bekerja sama untuk ketersediaan selain tujuan lain. Ini juga mencakup cerita untuk solusi yang menggabungkan lebih dari satu distribusi Linux.
Catatan
Tidak ada skenario di mana instans kluster failover berbasis WSFC (FCI) atau grup ketersediaan (AG) bekerja dengan FCI atau AG berbasis Linux secara langsung. Kluster Failover Windows Server (WSFC) tidak dapat diperluas oleh node Pacemaker dan begitu pula sebaliknya.
Grup ketersediaan terdistribusi
AG terdistribusi dirancang untuk meliputi konfigurasi AG, apakah kedua kluster yang mendasari AG tersebut adalah dua WSFC yang berbeda, distribusi Linux, atau satu kluster di WSFC dan yang lainnya di Linux. AG terdistribusi adalah metode utama untuk memiliki solusi lintas platform. AG terdistribusi juga merupakan solusi utama untuk migrasi seperti mengonversi dari infrastruktur SQL Server berbasis Windows Server ke infrastruktur berbasis Linux jika itulah yang ingin dilakukan perusahaan Anda. Seperti disebutkan sebelumnya, AG, dan terutama AG terdistribusi, akan meminimalkan waktu aplikasi tidak tersedia untuk digunakan. Contoh AG terdistribusi yang mencakup WSFC dan Pacemaker diperlihatkan dalam diagram berikut:

Jika Anda mengonfigurasi AG dengan jenis kluster None, AG dapat mencakup Windows Server dan Linux, dan beberapa distribusi Linux. Karena konfigurasi ini tidak benar-benar ketersediaan tinggi, jangan gunakan untuk penyebaran misi penting. Sebagai gantinya, gunakan untuk skenario skala baca atau migrasi dan peningkatan.
Pengiriman log
Pengiriman log didasarkan pada pencadangan dan pemulihan, sehingga tidak ada perbedaan dalam database, struktur file, dan elemen lain untuk SQL Server di Windows Server versus SQL Server di Linux. Anda dapat mengonfigurasi pengiriman log antara penginstalan SQL Server berbasis Windows Server dan yang Linux, dan di antara distribusi Linux. Segala sesuatu yang lain tetap sama.
Sama seperti dengan AG, pengiriman log tidak berfungsi ketika server sumber berada pada versi utama SQL Server yang lebih tinggi, terhadap target yang berada pada versi utama yang lebih rendah.
Ringkasan
Anda dapat membuat instans dan database SQL Server 2017 (14.x) dan versi yang lebih baru sangat tersedia dengan menggunakan fitur yang sama di Windows Server dan Linux. Selain skenario ketersediaan standar ketersediaan tinggi lokal dan pemulihan bencana, Anda dapat meminimalkan waktu henti yang terkait dengan peningkatan dan migrasi dengan menggunakan fitur ketersediaan di SQL Server. AG juga dapat menyediakan salinan tambahan database sebagai bagian dari arsitektur yang sama untuk menskalakan salinan yang dapat dibaca. Baik Anda menyebarkan solusi baru atau mempertimbangkan peningkatan, SQL Server memiliki ketersediaan dan keandalan yang Anda butuhkan.