Tutorial Python: Membangun model untuk mengategorikan pelanggan dengan pembelajaran mesin SQL
Berlaku untuk: ![]() SQL Server 2017 (14.x) dan Azure SQL Managed Instance yang lebih baru
SQL Server 2017 (14.x) dan Azure SQL Managed Instance yang lebih baru ![]()
Di bagian tiga dari seri tutorial empat bagian ini, Anda akan membangun model K-Means di Python untuk melakukan pengklusteran. Di bagian berikutnya dari seri ini, Anda akan menyebarkan model ini dalam database dengan SQL Server Pembelajaran Mesin Services atau di Kluster Big Data.
Di bagian tiga dari seri tutorial empat bagian ini, Anda akan membangun model K-Means di Python untuk melakukan pengklusteran. Di bagian berikutnya dari seri ini, Anda akan menyebarkan model ini dalam database dengan SQL Server Pembelajaran Mesin Services.
Di bagian tiga dari seri tutorial empat bagian ini, Anda akan membangun model K-Means di Python untuk melakukan pengklusteran. Di bagian berikutnya dari seri ini, Anda akan menyebarkan model ini dalam database dengan Azure SQL Managed Instance Pembelajaran Mesin Services.
Dalam artikel ini, Anda akan mempelajari cara:
- Menentukan jumlah kluster untuk algoritma K-Means
- Melakukan pengklusteran
- Menganalisis hasilnya
Di bagian satu, Anda menginstal prasyarat dan memulihkan database sampel.
Di bagian dua, Anda mempelajari cara menyiapkan data dari database untuk melakukan pengklusteran.
Di bagian empat, Anda akan mempelajari cara membuat prosedur tersimpan dalam database yang dapat melakukan pengklusteran di Python berdasarkan data baru.
Prasyarat
- Bagian ketiga dari tutorial ini mengasumsikan Anda telah memenuhi prasyarat bagian satu, dan menyelesaikan langkah-langkah di bagian dua.
Menentukan jumlah kluster
Untuk mengelompokkan data pelanggan, Anda akan menggunakan algoritma pengklusteran K-Means , salah satu cara pengelompokan data yang paling sederhana dan paling terkenal. Anda dapat membaca lebih lanjut tentang K-Means dalam Panduan lengkap untuk algoritma pengklusteran K-means.
Algoritma menerima dua input: Data itu sendiri, dan angka "k" yang telah ditentukan sebelumnya yang mewakili jumlah kluster yang akan dihasilkan. Outputnya adalah kluster k dengan data input yang dipartisi di antara kluster.
Tujuan dari K-means adalah untuk mengelompokkan item ke dalam kluster k sehingga semua item dalam kluster yang sama mirip satu sama lain, dan berbeda dari item di kluster lain, sebisa mungkin.
Untuk menentukan jumlah kluster untuk algoritma yang akan digunakan, gunakan plot dari dalam grup jumlah kuadrat, berdasarkan jumlah kluster yang diekstrak. Jumlah kluster yang sesuai untuk digunakan ada di tikungan atau "siku" plot.
################################################################################################
## Determine number of clusters using the Elbow method
################################################################################################
cdata = customer_data
K = range(1, 20)
KM = (sk_cluster.KMeans(n_clusters=k).fit(cdata) for k in K)
centroids = (k.cluster_centers_ for k in KM)
D_k = (sci_distance.cdist(cdata, cent, 'euclidean') for cent in centroids)
dist = (np.min(D, axis=1) for D in D_k)
avgWithinSS = [sum(d) / cdata.shape[0] for d in dist]
plt.plot(K, avgWithinSS, 'b*-')
plt.grid(True)
plt.xlabel('Number of clusters')
plt.ylabel('Average within-cluster sum of squares')
plt.title('Elbow for KMeans clustering')
plt.show()
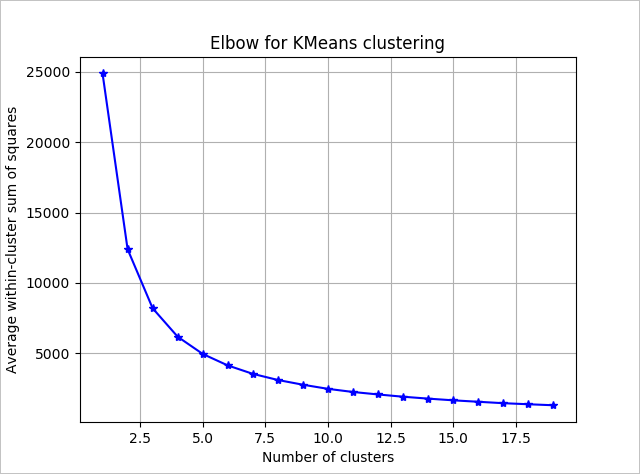
Berdasarkan grafik, sepertinya k = 4 akan menjadi nilai yang baik untuk dicoba. Nilai k tersebut akan mengelompokkan pelanggan ke dalam empat kluster.
Melakukan pengklusteran
Dalam skrip Python berikut, Anda akan menggunakan fungsi KMeans dari paket sklearn.
################################################################################################
## Perform clustering using Kmeans
################################################################################################
# It looks like k=4 is a good number to use based on the elbow graph.
n_clusters = 4
means_cluster = sk_cluster.KMeans(n_clusters=n_clusters, random_state=111)
columns = ["orderRatio", "itemsRatio", "monetaryRatio", "frequency"]
est = means_cluster.fit(customer_data[columns])
clusters = est.labels_
customer_data['cluster'] = clusters
# Print some data about the clusters:
# For each cluster, count the members.
for c in range(n_clusters):
cluster_members=customer_data[customer_data['cluster'] == c][:]
print('Cluster{}(n={}):'.format(c, len(cluster_members)))
print('-'* 17)
print(customer_data.groupby(['cluster']).mean())
Menganalisis hasilnya
Sekarang setelah Anda melakukan pengklusteran menggunakan K-Means, langkah selanjutnya adalah menganalisis hasilnya dan melihat apakah Anda dapat menemukan informasi yang dapat ditindaklanjuti.
Lihat nilai rata-rata pengklusteran dan ukuran kluster yang dicetak dari skrip sebelumnya.
Cluster0(n=31675):
-------------------
Cluster1(n=4989):
-------------------
Cluster2(n=1):
-------------------
Cluster3(n=671):
-------------------
customer orderRatio itemsRatio monetaryRatio frequency
cluster
0 50854.809882 0.000000 0.000000 0.000000 0.000000
1 51332.535779 0.721604 0.453365 0.307721 1.097815
2 57044.000000 1.000000 2.000000 108.719154 1.000000
3 48516.023845 0.136277 0.078346 0.044497 4.271237
Empat sarana kluster diberikan menggunakan variabel yang ditentukan di bagian satu:
- orderRatio = mengembalikan rasio pesanan (jumlah total pesanan sebagian atau dikembalikan sepenuhnya versus jumlah total pesanan)
- itemsRatio = mengembalikan rasio item (jumlah total item yang dikembalikan versus jumlah item yang dibeli)
- moneterRatio = rasio jumlah pengembalian (jumlah total item moneter yang dikembalikan versus jumlah yang dibeli)
- frekuensi = frekuensi pengembalian
Penggalian data menggunakan K-Means sering memerlukan analisis lebih lanjut tentang hasilnya, dan langkah-langkah lebih lanjut untuk lebih memahami setiap kluster, tetapi dapat memberikan beberapa prospek yang baik. Berikut adalah beberapa cara untuk menginterpretasikan hasil ini:
- Kluster 0 tampaknya merupakan sekelompok pelanggan yang tidak aktif (semua nilai nol).
- Kluster 3 tampaknya merupakan grup yang menonjol dalam hal perilaku pengembalian.
Kluster 0 adalah sekumpulan pelanggan yang jelas tidak aktif. Mungkin Anda dapat menargetkan upaya pemasaran terhadap grup ini untuk memicu minat untuk pembelian. Pada langkah berikutnya, Anda akan mengkueri database untuk alamat email pelanggan di kluster 0, sehingga Anda dapat mengirim email pemasaran kepada mereka.
Membersihkan sumber daya
Jika Anda tidak akan melanjutkan tutorial ini, hapus database tpcxbb_1gb.
Langkah berikutnya
Di bagian tiga seri tutorial ini, Anda menyelesaikan langkah-langkah berikut:
- Menentukan jumlah kluster untuk algoritma K-Means
- Melakukan pengklusteran
- Menganalisis hasilnya
Untuk menyebarkan model pembelajaran mesin yang telah Anda buat, ikuti bagian empat dari seri tutorial ini:
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk