Tutorial: Membangun model pengklusteran di R dengan pembelajaran mesin SQL
Berlaku untuk: ![]() SQL Server 2016 (13.x) dan Azure SQL Managed Instance yang lebih baru
SQL Server 2016 (13.x) dan Azure SQL Managed Instance yang lebih baru ![]()
Di bagian tiga dari seri tutorial empat bagian ini, Anda akan membangun model K-Means di R untuk melakukan pengklusteran. Di bagian berikutnya dari seri ini, Anda akan menyebarkan model ini dalam database dengan SQL Server Pembelajaran Mesin Services atau di Kluster Big Data.
Di bagian tiga dari seri tutorial empat bagian ini, Anda akan membangun model K-Means di R untuk melakukan pengklusteran. Di bagian berikutnya dari seri ini, Anda akan menyebarkan model ini dalam database dengan SQL Server Pembelajaran Mesin Services.
Di bagian tiga dari seri tutorial empat bagian ini, Anda akan membangun model K-Means di R untuk melakukan pengklusteran. Di bagian berikutnya dari seri ini, Anda akan menyebarkan model ini dalam database dengan SQL Server R Services.
Di bagian tiga dari seri tutorial empat bagian ini, Anda akan membangun model K-Means di R untuk melakukan pengklusteran. Di bagian berikutnya dari seri ini, Anda akan menyebarkan model ini dalam database dengan Azure SQL Managed Instance Pembelajaran Mesin Services.
Dalam artikel ini, Anda akan mempelajari cara:
- Menentukan jumlah kluster untuk algoritma K-Means
- Melakukan pengklusteran
- Menganalisis hasilnya
Di bagian satu, Anda menginstal prasyarat dan memulihkan database sampel.
Di bagian dua, Anda mempelajari cara menyiapkan data dari database untuk melakukan pengklusteran.
Di bagian empat, Anda akan mempelajari cara membuat prosedur tersimpan dalam database yang dapat melakukan pengklusteran di R berdasarkan data baru.
Prasyarat
- Bagian ketiga dari seri tutorial ini mengasumsikan Anda telah memenuhi prasyarat bagian satu dan menyelesaikan langkah-langkah di bagian dua.
Menentukan jumlah kluster
Untuk mengelompokkan data pelanggan, Anda akan menggunakan algoritma pengklusteran K-Means , salah satu cara pengelompokan data yang paling sederhana dan paling terkenal. Anda dapat membaca lebih lanjut tentang K-Means dalam Panduan lengkap untuk algoritma pengklusteran K-means.
Algoritma menerima dua input: Data itu sendiri, dan angka "k" yang telah ditentukan sebelumnya yang mewakili jumlah kluster yang akan dihasilkan. Outputnya adalah kluster k dengan data input yang dipartisi di antara kluster.
Untuk menentukan jumlah kluster untuk algoritma yang akan digunakan, gunakan plot dari dalam grup jumlah kuadrat, berdasarkan jumlah kluster yang diekstrak. Jumlah kluster yang sesuai untuk digunakan ada di tikungan atau "siku" plot.
# Determine number of clusters by using a plot of the within groups sum of squares,
# by number of clusters extracted.
wss <- (nrow(customer_data) - 1) * sum(apply(customer_data, 2, var))
for (i in 2:20)
wss[i] <- sum(kmeans(customer_data, centers = i)$withinss)
plot(1:20, wss, type = "b", xlab = "Number of Clusters", ylab = "Within groups sum of squares")
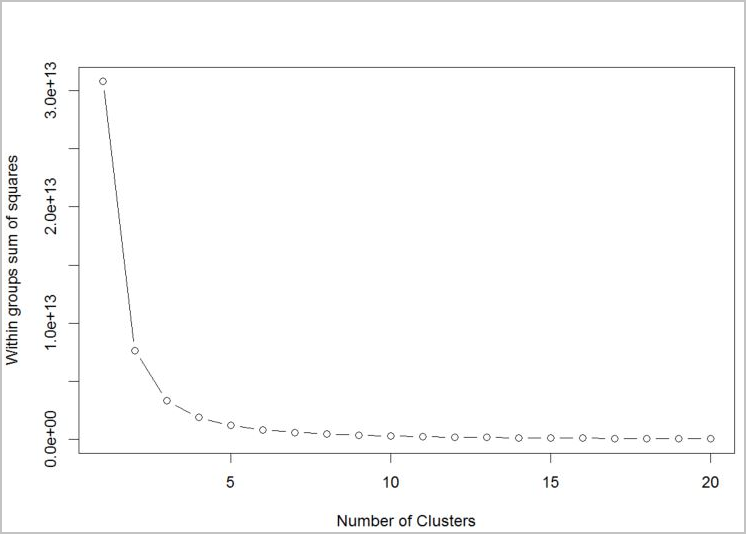
Berdasarkan grafik, sepertinya k = 4 akan menjadi nilai yang baik untuk dicoba. Nilai k tersebut akan mengelompokkan pelanggan ke dalam empat kluster.
Melakukan pengklusteran
Dalam skrip R berikut, Anda akan menggunakan kmean fungsi untuk melakukan pengklusteran .
# Output table to hold the customer group mappings.
# Generate clusters using Kmeans and output key / cluster to a table
# called return_cluster
## create clustering model
clust <- kmeans(customer_data[,2:5],4)
## create clustering ouput for table
customer_cluster <- data.frame(cluster=clust$cluster,customer=customer_data$customer,orderRatio=customer_data$orderRatio,
itemsRatio=customer_data$itemsRatio,monetaryRatio=customer_data$monetaryRatio,frequency=customer_data$frequency)
## write cluster output to DB table
sqlSave(ch, customer_cluster, tablename = "return_cluster")
# Read the customer returns cluster table from the database
customer_cluster_check <- sqlFetch(ch, "return_cluster")
head(customer_cluster_check)
Menganalisis hasilnya
Sekarang setelah Anda melakukan pengklusteran menggunakan K-Means, langkah selanjutnya adalah menganalisis hasilnya dan melihat apakah Anda dapat menemukan informasi yang dapat ditindaklanjuti.
#Look at the clustering details to analyze results
clust[-1]
$centers
orderRatio itemsRatio monetaryRatio frequency
1 0.621835791 0.1701519 0.35510836 1.009025
2 0.074074074 0.0000000 0.05886575 2.363248
3 0.004807692 0.0000000 0.04618708 5.050481
4 0.000000000 0.0000000 0.00000000 0.000000
$totss
[1] 40191.83
$withinss
[1] 19867.791 215.714 660.784 0.000
$tot.withinss
[1] 20744.29
$betweenss
[1] 19447.54
$size
[1] 4543 702 416 31675
$iter
[1] 3
$ifault
[1] 0
Empat sarana kluster diberikan menggunakan variabel yang ditentukan di bagian dua:
- orderRatio = mengembalikan rasio pesanan (jumlah total pesanan sebagian atau dikembalikan sepenuhnya versus jumlah total pesanan)
- itemsRatio = mengembalikan rasio item (jumlah total item yang dikembalikan versus jumlah item yang dibeli)
- moneterRatio = rasio jumlah pengembalian (jumlah total item moneter yang dikembalikan versus jumlah yang dibeli)
- frekuensi = frekuensi pengembalian
Penggalian data menggunakan K-Means sering memerlukan analisis lebih lanjut tentang hasilnya, dan langkah-langkah lebih lanjut untuk lebih memahami setiap kluster, tetapi dapat memberikan beberapa prospek yang baik. Berikut adalah beberapa cara untuk menginterpretasikan hasil ini:
- Kluster 1 (kluster terbesar) tampaknya merupakan sekelompok pelanggan yang tidak aktif (semua nilai nol).
- Kluster 3 tampaknya merupakan grup yang menonjol dalam hal perilaku pengembalian.
Membersihkan sumber daya
Jika Anda tidak akan melanjutkan tutorial ini, hapus database tpcxbb_1gb.
Langkah berikutnya
Di bagian tiga seri tutorial ini, Anda mempelajari cara:
- Menentukan jumlah kluster untuk algoritma K-Means
- Melakukan pengklusteran
- Menganalisis hasilnya
Untuk menyebarkan model pembelajaran mesin yang telah Anda buat, ikuti bagian empat dari seri tutorial ini: