Mendiagnosis dan mengatasi ketidakcocokan kait di SQL Server
Panduan ini menjelaskan cara mengidentifikasi dan mengatasi masalah ketidakcocokan kait yang diamati saat menjalankan aplikasi SQL Server pada sistem konkurensi tinggi dengan beban kerja tertentu.
Karena jumlah inti CPU di server terus meningkat, peningkatan konkurensi terkait dapat memperkenalkan titik ketidakcocokan pada struktur data yang harus diakses dengan cara serial dalam mesin database. Hal ini terutama berlaku untuk beban kerja pemrosesan transaksi throughput tinggi/konkurensi tinggi (OLTP). Ada sejumlah alat, teknik, dan cara untuk mendekati tantangan ini serta praktik yang dapat diikuti dalam merancang aplikasi yang dapat membantu menghindarinya sama sekali. Artikel ini akan membahas jenis ketidakcocokan tertentu pada struktur data yang menggunakan spinlock untuk menserialisasikan akses ke struktur data ini.
Catatan
Konten ini ditulis oleh tim Microsoft SQL Server Customer Advisory Team (SQLCAT) berdasarkan proses mereka untuk mengidentifikasi dan menyelesaikan masalah yang terkait dengan ketidakcocokan kait halaman di aplikasi SQL Server pada sistem konkurensi tinggi. Rekomendasi dan praktik terbaik yang didokumentasikan di sini didasarkan pada pengalaman dunia nyata selama pengembangan dan penyebaran sistem OLTP dunia nyata.
Apa itu ketidakcocokan kait SQL Server?
Latch adalah primitif sinkronisasi ringan yang digunakan oleh mesin SQL Server untuk menjamin konsistensi struktur dalam memori termasuk; indeks, halaman data, dan struktur internal, seperti halaman non-leaf di B-Tree. SQL Server menggunakan latch buffer untuk melindungi halaman di latch kumpulan buffer dan I/O untuk melindungi halaman yang belum dimuat ke dalam kumpulan buffer. Setiap kali data ditulis atau dibaca dari halaman di kumpulan buffer SQL Server, utas pekerja harus terlebih dahulu memperoleh kait buffer untuk halaman tersebut. Ada berbagai jenis kait buffer yang tersedia untuk mengakses halaman di kumpulan buffer termasuk kait eksklusif (PAGELATCH_EX) dan kait bersama (PAGELATCH_SH). Ketika SQL Server mencoba mengakses halaman yang belum ada di kumpulan buffer, I/O asinkron diposting untuk memuat halaman ke dalam kumpulan buffer. Jika SQL Server perlu menunggu subsistem I/O meresponsnya akan menunggu latch I/O eksklusif (PAGEIOLATCH_EX) atau bersama (PAGEIOLATCH_SH) tergantung pada jenis permintaan; ini dilakukan untuk mencegah utas pekerja lain memuat halaman yang sama ke kumpulan buffer dengan kait yang tidak kompatibel. Kait juga digunakan untuk melindungi akses ke struktur memori internal selain halaman kumpulan buffer; ini dikenal sebagai kait Non-Buffer.
Ketidakcocokan pada kait halaman adalah skenario paling umum yang ditemui pada sistem multi-CPU, sehingga sebagian besar artikel ini akan berfokus pada ini.
Ketidakcocokan kait terjadi ketika beberapa utas secara bersamaan mencoba memperoleh kait yang tidak kompatibel ke struktur dalam memori yang sama. Karena kait adalah mekanisme kontrol internal; mesin SQL secara otomatis menentukan kapan harus menggunakannya. Karena perilaku kait bersifat deterministik, keputusan aplikasi termasuk desain skema dapat memengaruhi perilaku ini. Artikel ini bertujuan untuk memberikan informasi berikut:
- Informasi latar belakang tentang bagaimana kait digunakan oleh SQL Server.
- Alat yang digunakan untuk menyelidiki ketidakcocokan kait.
- Cara menentukan apakah jumlah pertikaian yang diamati bermasalah.
Kami akan membahas beberapa skenario umum dan cara terbaik untuk menanganinya untuk meringankan ketidakcocokan.
Bagaimana SQL Server menggunakan kait?
Halaman di SQL Server adalah 8 KB dan dapat menyimpan beberapa baris. Untuk meningkatkan konkurensi dan performa, kait buffer hanya ditahan selama durasi operasi fisik di halaman, tidak seperti kunci, yang ditahan selama durasi transaksi logis.
Kait bersifat internal untuk mesin SQL dan digunakan untuk memberikan konsistensi memori, sedangkan kunci digunakan oleh SQL Server untuk memberikan konsistensi transaksional logis. Tabel berikut membandingkan kait dengan kunci:
| Struktur | Tujuan | Dikontrol oleh | Biaya performa | Diekspos oleh |
|---|---|---|---|---|
| Kait | Menjamin konsistensi struktur dalam memori. | Hanya mesin SQL Server. | Biaya performa rendah. Untuk memungkinkan konkurensi maksimum dan memberikan performa maksimum, kait hanya ditahan selama durasi operasi fisik pada struktur dalam memori, tidak seperti kunci, yang ditahan selama durasi transaksi logis. | sys.dm_os_wait_stats (Transact-SQL) - Menyediakan informasi tentang jenis tunggu PAGELATCH, PAGEIOLATCH, dan LATCH (LATCH_EX, LATCH_SH digunakan untuk mengelompokkan semua tunggu kait non-buffer). sys.dm_os_latch_stats (Transact-SQL) – Menyediakan informasi terperinci tentang penantian kait non-buffer. sys.dm_db_index_operational_stats (Transact-SQL) - DMV ini menyediakan penantian agregat untuk setiap indeks, yang berguna untuk memecahkan masalah performa terkait kait. |
| Kunci | Menjamin konsistensi transaksi. | Dapat dikontrol oleh pengguna. | Biaya performa relatif tinggi terhadap kait karena kunci harus ditahan selama transaksi. | sys.dm_tran_locks (T-SQL). sys.dm_exec_sessions (T-SQL). |
Mode dan kompatibilitas kait SQL Server
Beberapa ketidakcocokan kait diharapkan sebagai bagian normal dari pengoperasian mesin SQL Server. Tidak dapat dihindari bahwa beberapa permintaan kait bersamaan dari berbagai kompatibilitas akan terjadi pada sistem konkurensi tinggi. SQL Server memberlakukan kompatibilitas kait dengan mengharuskan permintaan kait yang tidak kompatibel untuk menunggu dalam antrean hingga permintaan kait yang terutang selesai.
Kait diperoleh dalam salah satu dari lima mode berbeda, yang terkait dengan tingkat akses. Mode kait SQL Server dapat diringkas sebagai berikut:
KP -- Simpan kait, memastikan bahwa struktur yang direferensikan tidak dapat dihancurkan. Digunakan saat utas ingin melihat struktur buffer. Karena kait KP kompatibel dengan semua kait kecuali untuk kait penghancurkan (DT), kait KP dianggap "ringan", yang berarti bahwa dampak pada performa saat menggunakannya minimal. Karena kait KP tidak kompatibel dengan kait DT, itu akan mencegah utas lain menghancurkan struktur yang dirujuk. Misalnya, kait KP akan mencegah struktur yang dirujuknya dihancurkan oleh proses lazywriter. Untuk informasi selengkapnya tentang bagaimana proses lazywriter digunakan dengan manajemen halaman buffer SQL Server, lihat Menulis Halaman.
SH -- Kait bersama, diperlukan untuk membaca struktur yang dirujuk (misalnya membaca halaman data). Beberapa utas dapat secara bersamaan mengakses sumber daya untuk dibaca di bawah kait bersama.
UP -- Perbarui kait, kompatibel dengan SH (Kait bersama) dan KP, tetapi tidak ada yang lain dan oleh karena itu tidak akan mengizinkan kait EX untuk menulis ke struktur yang dirujuk.
EX -- Kait eksklusif, memblokir utas lain agar tidak menulis ke atau membaca dari struktur yang dirujuk. Salah satu contoh penggunaannya adalah memodifikasi konten halaman untuk perlindungan halaman yang robek.
DT -- Hancurkan kait, harus diperoleh sebelum menghancurkan isi struktur yang dirujuk. Misalnya, kait DT harus diperoleh oleh proses lazywriter untuk membebaskan halaman bersih sebelum menambahkannya ke daftar buffer gratis yang tersedia untuk digunakan oleh utas lain.
Mode kait memiliki tingkat kompatibilitas yang berbeda, misalnya, kait bersama (SH) kompatibel dengan kait pembaruan (UP) atau keep (KP) tetapi tidak kompatibel dengan kait hancur (DT). Beberapa kait dapat diperoleh secara bersamaan pada struktur yang sama selama kait kompatibel. Ketika utas mencoba memperoleh kait yang disimpan dalam mode yang tidak kompatibel, utas ditempatkan ke dalam antrean untuk menunggu sinyal yang menunjukkan bahwa sumber daya tersedia. Spinlock jenis SOS_Task digunakan untuk melindungi antrean tunggu dengan memberlakukan akses berseri ke antrean. Spinlock ini harus diperoleh untuk menambahkan item ke antrean. Spinlock SOS_Task juga menandakan utas dalam antrean ketika kait yang tidak kompatibel dilepaskan, memungkinkan alur tunggu untuk memperoleh kait yang kompatibel dan terus bekerja. Antrean tunggu diproses berdasarkan masuk pertama, pertama keluar (FIFO) saat permintaan kait dirilis. Kait mengikuti sistem FIFO ini untuk memastikan keadilan dan untuk mencegah kelaparan utas.
Kompatibilitas mode kait tercantum dalam tabel berikut (Y menunjukkan kompatibilitas dan N menunjukkan ketidakcocokan):
| Mode kait | KP | SH | UP | KELUARAN | DT |
|---|---|---|---|---|---|
| KP | Y | Y | Y | Y | N |
| SH | Y | Y | Y | N | N |
| UP | Y | Y | N | N | N |
| KELUARAN | Y | N | N | N | N |
| DT | N | N | N | N | N |
SuperLatche dan sublache SQL Server
Dengan meningkatnya kehadiran beberapa sistem soket / multi-core berbasis NUMA, SQL Server 2005 memperkenalkan SuperLatches, juga dikenal sebagai sublache, yang hanya efektif pada sistem dengan prosesor logis 32 atau lebih. Superlatche meningkatkan efisiensi mesin SQL untuk pola penggunaan tertentu dalam beban kerja OLTP yang sangat bersamaan; misalnya, ketika halaman tertentu memiliki pola akses bersama baca-saja (SH) yang berat, tetapi jarang ditulis. Contoh halaman dengan pola akses seperti itu adalah halaman akar pohon B (yaitu indeks) ; mesin SQL mengharuskan kait bersama ditahan di halaman akar ketika pemisahan halaman terjadi pada tingkat apa pun di pohon B. Dalam beban kerja OLTP insert-heavy dan high-concurrency, jumlah pemisahan halaman akan meningkat secara luas sejalan dengan throughput, yang dapat menurunkan performa. SuperLatches dapat memungkinkan peningkatan performa untuk mengakses halaman bersama di mana beberapa utas pekerja yang berjalan bersamaan memerlukan kait SH. Untuk mencapai hal ini, Mesin SQL Server akan secara dinamis mempromosikan kait di halaman tersebut ke SuperLatch. SuperLatch mempartisi satu kait ke dalam array struktur sublatch, satu sublatch per partisi per inti CPU, di mana kait utama menjadi pengalih proksi dan sinkronisasi status global tidak diperlukan untuk kait baca-saja. Dengan demikian, pekerja, yang selalu ditetapkan ke CPU tertentu, hanya perlu memperoleh sublatch bersama (SH) yang ditetapkan ke penjadwal lokal.
Catatan
Dokumentasi SQL Server menggunakan istilah pohon B umumnya dalam referensi ke indeks. Dalam indeks rowstore, SQL Server mengimplementasikan pohon B+. Ini tidak berlaku untuk indeks penyimpan kolom atau penyimpanan data dalam memori. Untuk informasi selengkapnya, lihat panduan arsitektur dan desain indeks SQL Server dan Azure SQL.
Akuisisi kait yang kompatibel, seperti Superlatch bersama menggunakan lebih sedikit sumber daya dan menskalakan akses ke halaman panas lebih baik daripada kait bersama yang tidak dipartisi karena menghapus persyaratan sinkronisasi status global secara signifikan meningkatkan performa dengan hanya mengakses memori NUMA lokal. Sebaliknya, memperoleh SuperLatch eksklusif (EX) lebih mahal daripada memperoleh kait reguler EX karena SQL harus memberi sinyal di semua sublache. Ketika SuperLatch diamati untuk menggunakan pola akses EX berat, Mesin SQL dapat menurunkannya setelah halaman dibuang dari kumpulan buffer. Diagram berikut menggambarkan kait normal dan SuperLatch yang dipartisi:
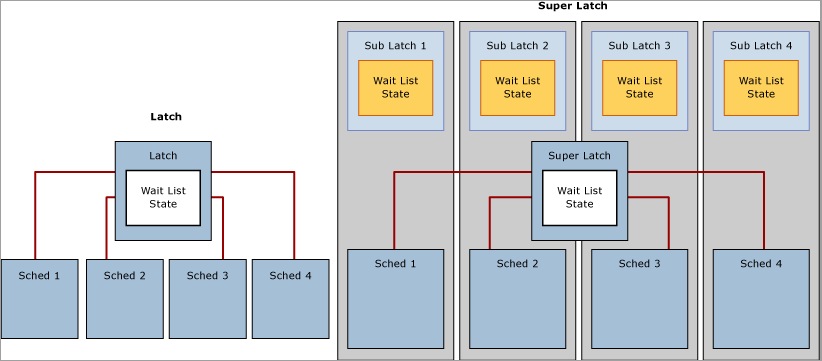
Gunakan objek SQL Server:Latches dan penghitung terkait di Monitor Performa untuk mengumpulkan informasi tentang SuperLatches, termasuk jumlah SuperLatches, promosi SuperLatch per detik, dan demosi SuperLatch per detik. Untuk informasi selengkapnya tentang objek SQL Server:Latches dan penghitung terkait, lihat SQL Server, Latches Object.
Jenis waktu tunggu latch
Informasi tunggu kumulatif dilacak oleh SQL Server dan dapat diakses menggunakan Tampilan Manajemen Dinamis (DMW) sys.dm_os_wait_stats. SQL Server menggunakan tiga jenis tunggu kait seperti yang didefinisikan oleh yang sesuai wait_type dalam sys.dm_os_wait_stats DMV:
Kait buffer (BUF): digunakan untuk menjamin konsistensi halaman indeks dan data untuk objek pengguna. Mereka juga digunakan untuk melindungi akses ke halaman data yang SQL Server gunakan untuk objek sistem. Misalnya, halaman yang mengelola alokasi dilindungi oleh latch buffer. Ini termasuk halaman Ruang Bebas Halaman (PFS), Peta Alokasi Global (GAM), Peta Alokasi Global Bersama (SGAM) dan Peta Alokasi Indeks (IAM). Kait buffer dilaporkan dengan
sys.dm_os_wait_statswait_typePAGELATCH_ *.Kait non-buffer (Non-BUF): digunakan untuk menjamin konsistensi struktur dalam memori selain halaman kumpulan buffer. Setiap tunggu kait non-buffer akan dilaporkan sebagai
wait_typeLATCH_*.Kait IO: subset kait buffer yang menjamin konsistensi struktur yang sama yang dilindungi oleh kait buffer ketika struktur ini memerlukan pemuatan ke dalam kumpulan buffer dengan operasi I/O. Kait IO mencegah utas lain memuat halaman yang sama ke dalam kumpulan buffer dengan kait yang tidak kompatibel. Terkait dengan
wait_typePAGEIOLATCH_*.Catatan
Jika Anda melihat penantian PAGEIOLATCH yang signifikan, itu berarti bahwa SQL Server menunggu pada subsistem I/O. Meskipun sejumlah penantian PAGEIOLATCH diharapkan dan perilaku normal, jika waktu tunggu PAGEIOLATCH rata-rata secara konsisten di atas 10 milidetik (ms), Anda harus menyelidiki mengapa subsistem I/O berada di bawah tekanan.
Jika saat memeriksa sys.dm_os_wait_stats DMV, Anda menemukan kait non-buffer, sys.dm_os_latch_stats harus diperiksa untuk mendapatkan perincian detail informasi tunggu kumulatif untuk kait non-buffer. Semua tunggu kait buffer diklasifikasikan di bawah kelas kait BUFFER, sisanya digunakan untuk mengklasifikasikan kait non-buffer.
Gejala dan penyebab ketidakcocokan kait SQL Server
Pada sistem konkurensi tinggi yang sibuk, normal untuk melihat ketidakcocokan aktif pada struktur yang sering diakses dan dilindungi oleh kait dan mekanisme kontrol lainnya di SQL Server. Ini dianggap bermasalah ketika ketidakcocokan dan waktu tunggu yang terkait dengan memperoleh kait untuk halaman cukup untuk mengurangi pemanfaatan sumber daya (CPU), yang menghambat throughput.
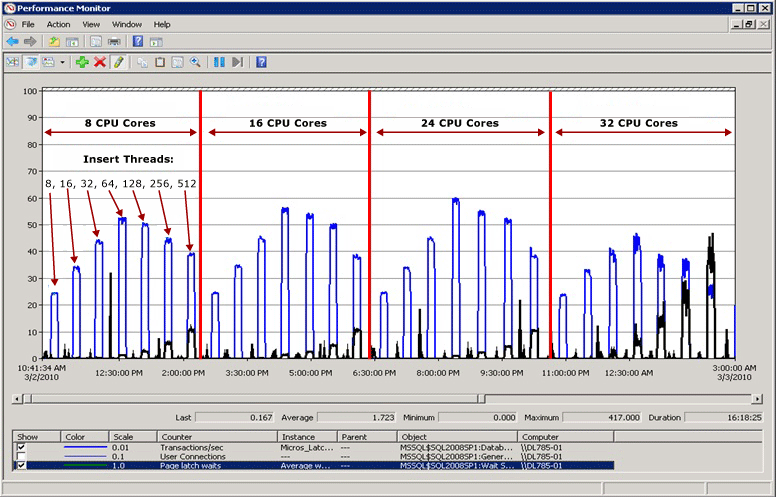
Contoh ketidakcocokan kait
Dalam diagram berikut, garis biru mewakili throughput di SQL Server, sebagaimana diukur oleh Transaksi per detik; garis hitam mewakili waktu tunggu kait halaman rata-rata. Dalam hal ini, setiap transaksi melakukan INSERT ke dalam indeks berkluster dengan nilai terkemuka yang meningkat secara berurutan, seperti saat mengisi kolom IDENTITY jenis data bigint. Ketika jumlah CPU meningkat menjadi 32, terbukti bahwa throughput keseluruhan telah menurun dan waktu tunggu kait halaman telah meningkat menjadi sekitar 48 milidetik sebagaimana dibuktikan oleh garis hitam. Hubungan terbalik antara throughput dan waktu tunggu kait halaman ini adalah skenario umum yang mudah didiagnosis.
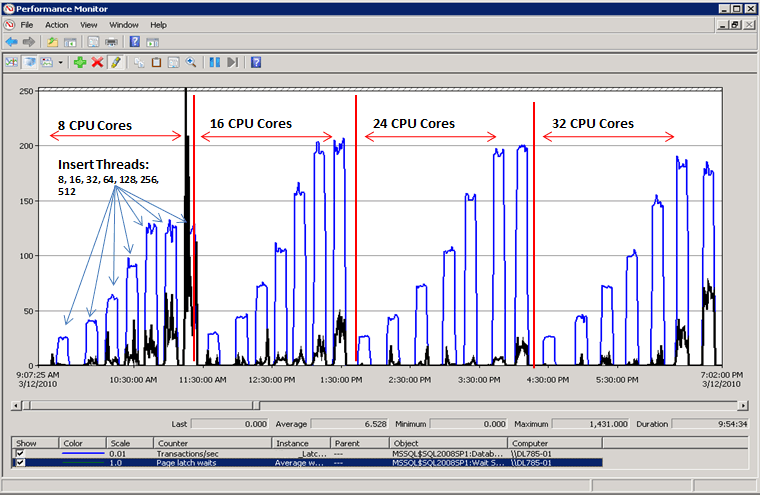
Performa saat ketidakcocokan kait diselesaikan
Seperti yang diilustrasikan oleh diagram berikut, SQL Server tidak lagi memiliki leher botol pada tunggu kait halaman dan throughput ditingkatkan sebesar 300% sebagaimana diukur oleh transaksi per detik. Ini dicapai dengan Menggunakan Partisi Hash dengan teknik Kolom Komputasi yang dijelaskan nanti dalam artikel ini. Peningkatan performa ini diarahkan pada sistem dengan jumlah inti yang tinggi dan tingkat konkurensi yang tinggi.
Faktor-faktor yang memengaruhi ketidakcocokan kait
Ketidakcocokan kait yang menghambat performa di lingkungan OLTP biasanya disebabkan oleh konkurensi tinggi yang terkait dengan satu atau beberapa faktor berikut:
| Faktor | Detail |
|---|---|
| Jumlah CPU logis yang tinggi yang digunakan oleh SQL Server | Ketidakcocokan kait dapat terjadi pada sistem multi-inti apa pun. Dalam SQLCAT mengalami ketidakcocokan kait yang berlebihan, yang berdampak pada performa aplikasi di luar tingkat yang dapat diterima, paling sering diamati pada sistem dengan 16+ inti CPU dan dapat meningkat karena inti tambahan tersedia. |
| Desain skema dan pola akses | Kedalaman pohon B, desain indeks berkluster dan tidak berkluster, ukuran dan kepadatan baris per halaman, dan pola akses (aktivitas baca/tulis/hapus) adalah faktor yang dapat berkontribusi pada ketidakcocokan kait halaman yang berlebihan. |
| Tingkat konkurensi tinggi pada tingkat aplikasi | Ketidakcocokan kait halaman yang berlebihan biasanya terjadi bersamaan dengan tingkat permintaan bersamaan yang tinggi dari tingkat aplikasi. Ada praktik pemrograman tertentu yang juga dapat memperkenalkan sejumlah besar permintaan untuk halaman tertentu. |
| Tata letak file logis yang digunakan oleh database SQL Server | Tata letak file logis dapat memengaruhi tingkat ketidakcocokan kait halaman yang disebabkan oleh struktur alokasi seperti halaman Ruang Bebas Halaman (PFS), Peta Alokasi Global (GAM), Peta Alokasi Global Bersama (SGAM) dan Peta Alokasi Indeks (IAM). Untuk informasi selengkapnya, lihat Pemantauan dan Pemecahan Masalah TempDB: Penyempitan Alokasi. |
| Performa subsistem I/O | Penantian PAGEIOLATCH yang signifikan menunjukkan SQL Server sedang menunggu pada subsistem I/O. |
Mendiagnosis ketidakcocokan kait SQL Server
Bagian ini menyediakan informasi untuk mendiagnosis ketidakcocokan kait SQL Server untuk menentukan apakah itu bermasalah dengan lingkungan Anda.
Alat dan metode untuk mendiagnosis pertikaian kait
Alat utama yang digunakan untuk mendiagnosis pertikaian kait adalah:
Monitor Performa untuk memantau pemanfaatan CPU dan waktu tunggu dalam SQL Server dan menetapkan apakah ada hubungan antara pemanfaatan CPU dan waktu tunggu kait.
DMV SQL Server, yang dapat digunakan untuk menentukan jenis kait tertentu yang menyebabkan masalah dan sumber daya yang terpengaruh.
Dalam beberapa kasus, cadangan memori proses SQL Server harus diperoleh dan dianalisis dengan alat penelusuran kesalahan Windows.
Catatan
Tingkat pemecahan masalah tingkat lanjut ini biasanya hanya diperlukan jika memecahkan masalah ketidakcocokan kait non-buffer. Anda mungkin ingin melibatkan Layanan Dukungan Produk Microsoft untuk jenis pemecahan masalah tingkat lanjut ini.
Proses teknis untuk mendiagnosis ketidakcocokan kait dapat diringkas dalam langkah-langkah berikut:
Tentukan bahwa ada pertikaian yang mungkin terkait dengan kait.
Gunakan tampilan DMV yang disediakan dalam Lampiran: Skrip SQL Server Latch Contention untuk menentukan jenis kait dan sumber daya yang terpengaruh.
Meringankan pertikaian menggunakan salah satu teknik yang dijelaskan dalam Menangani Ketidakcocokan Kait untuk Pola Tabel yang Berbeda.
Indikator ketidakcocokan kait
Seperti yang dinyatakan sebelumnya, ketidakcocokan kait hanya bermasalah ketika ketidakcocokan dan waktu tunggu yang terkait dengan memperoleh kait halaman mencegah throughput meningkat ketika sumber daya CPU tersedia. Menentukan jumlah ketidakcocokan yang dapat diterima memerlukan pendekatan holistik yang mempertimbangkan persyaratan performa dan throughput bersama dengan sumber daya I/O dan CPU yang tersedia. Bagian ini akan memandu Anda menentukan dampak ketidakcocokan kait pada beban kerja sebagai berikut:
Mengukur waktu tunggu keseluruhan selama pengujian perwakilan.
Peringkat mereka secara berurutan.
Tentukan proporsi yang terkait dengan kait.
Informasi tunggu kumulatif tersedia dari sys.dm_os_wait_stats DMV. Jenis ketidakcocokan kait yang paling umum adalah pertikaian kait buffer, diamati sebagai peningkatan waktu tunggu untuk kait dengan wait_typePAGELATCH_*. Kait non-buffer dikelompokkan di bawah jenis tunggu LATCH* . Seperti yang diilustrasikan diagram berikut, Anda harus terlebih dahulu melihat penantian sistem menggunakan sys.dm_os_wait_stats DMV untuk menentukan persentase waktu tunggu keseluruhan yang disebabkan oleh kait buffer atau non-buffer. Jika Anda menemukan kait non-buffer, sys.dm_os_latch_stats DMV juga harus diperiksa.
Diagram berikut menjelaskan hubungan antara informasi yang dikembalikan oleh sys.dm_os_wait_stats DMV dan sys.dm_os_latch_stats .

Untuk informasi selengkapnya tentang sys.dm_os_wait_stats DMV, lihat sys.dm_os_wait_stats (Transact-SQL) di bantuan SQL Server.
Untuk informasi selengkapnya tentang sys.dm_os_latch_stats DMV, lihat sys.dm_os_latch_stats (Transact-SQL) di bantuan SQL Server.
Langkah-langkah waktu tunggu kait berikut adalah indikator bahwa ketidakcocokan kait yang berlebihan memengaruhi performa aplikasi:
Rata-rata waktu tunggu kait halaman secara konsisten meningkat dengan throughput: Jika rata-rata waktu tunggu kait halaman secara konsisten meningkat dengan throughput dan jika waktu tunggu kait buffer rata-rata juga meningkat di atas waktu respons disk yang diharapkan, Anda harus memeriksa tugas tunggu saat ini menggunakan
sys.dm_os_waiting_tasksDMV. Rata-rata dapat menyesatkan jika dianalisis dalam isolasi sehingga penting untuk melihat sistem hidup ketika mungkin untuk memahami karakteristik beban kerja. Secara khusus, periksa apakah ada penantian tinggi pada permintaan PAGELATCH_EX dan/atau PAGELATCH_SH di halaman mana pun. Ikuti langkah-langkah ini untuk mendiagnosis peningkatan waktu tunggu kait halaman rata-rata dengan throughput:- Gunakan contoh skrip Kueri sys.dm_os_waiting_tasks Diurutkan menurut ID Sesi atau Hitung Tunggu Selama Periode Waktu untuk melihat tugas tunggu saat ini dan mengukur waktu tunggu kait rata-rata.
- Gunakan contoh skrip Deskriptor Buffer Kueri untuk Menentukan Objek Yang Menyebabkan Ketidakcocokan Kait untuk menentukan indeks dan tabel yang mendasar tempat pertikaian terjadi.
- Mengukur waktu tunggu kait halaman rata-rata dengan penghitung Monitor Performa MSSQL%InstanceName%\Wait Statistics\Page Latch Waits\Average Wait Time atau dengan menjalankan
sys.dm_os_wait_statsDMV.
Catatan
Untuk menghitung waktu tunggu rata-rata untuk jenis tunggu tertentu (dikembalikan oleh
sys.dm_os_wait_statssebagai wt_:type), bagi total waktu tunggu (dikembalikan sebagaiwait_time_ms) dengan jumlah tugas tunggu (dikembalikan sebagaiwaiting_tasks_count).Persentase total waktu tunggu yang dihabiskan untuk jenis tunggu kait selama beban puncak: Jika waktu tunggu kait rata-rata sebagai persentase waktu tunggu keseluruhan meningkat sejalan dengan beban aplikasi, maka ketidakcocokan kait dapat memengaruhi performa dan harus diselidiki.
Mengukur tunggu kait halaman dan latch non-halaman menunggu dengan penghitung kinerja Objek SQLServer:Wait Statistics. Kemudian bandingkan nilai untuk penghitung kinerja ini dengan penghitung kinerja yang terkait dengan CPU, I/O, memori, dan throughput jaringan. Misalnya, transaksi/detik dan permintaan batch/detik adalah dua langkah pemanfaatan sumber daya yang baik.
Catatan
Waktu tunggu relatif untuk setiap jenis tunggu tidak disertakan dalam
sys.dm_os_wait_statsDMV karena DMW ini mengukur waktu tunggu sejak terakhir kali instans SQL Server dimulai atau statistik tunggu kumulatif diatur ulang menggunakan DBCC SQLPERF. Untuk menghitung waktu tunggu relatif untuk setiap jenis tunggu, ambil rekam jepretsys.dm_os_wait_statssebelum beban puncak, setelah beban puncak, lalu hitung perbedaannya. Contoh skrip Menghitung Tunggu Selama Periode Waktu dapat digunakan untuk tujuan ini.Untuk lingkungan non-produksi saja, hapus
sys.dm_os_wait_statsDMV dengan perintah berikut:dbcc SQLPERF ('sys.dm_os_wait_stats', 'CLEAR')Perintah serupa dapat dijalankan untuk menghapus
sys.dm_os_latch_statsDMV:dbcc SQLPERF ('sys.dm_os_latch_stats', 'CLEAR')Throughput tidak meningkat, dan dalam beberapa kasus menurun, karena beban aplikasi meningkat dan jumlah CPU yang tersedia untuk SQL Server meningkat: Ini diilustrasikan dalam Contoh Ketidakcocokan Kait.
Pemanfaatan CPU tidak meningkat saat beban kerja aplikasi meningkat: Jika pemanfaatan CPU pada sistem tidak meningkat karena konkurensi yang didorong oleh throughput aplikasi meningkat, ini adalah indikator bahwa SQL Server menunggu sesuatu dan gejala ketidakcocokan kait.
Menganalisis akar penyebabnya. Bahkan jika setiap kondisi sebelumnya benar, masih mungkin bahwa akar penyebab masalah performa terletak di tempat lain. Bahkan, dalam sebagian besar kasus pemanfaatan CPU suboptimal disebabkan oleh jenis penantian lain seperti pemblokiran pada kunci, tunggu terkait I/O atau masalah terkait jaringan. Sebagai aturan praktis, selalu yang terbaik untuk menyelesaikan tunggu sumber daya yang mewakili proporsi terbesar dari waktu tunggu keseluruhan sebelum melanjutkan dengan analisis yang lebih mendalam.
Menganalisis kait buffer tunggu saat ini
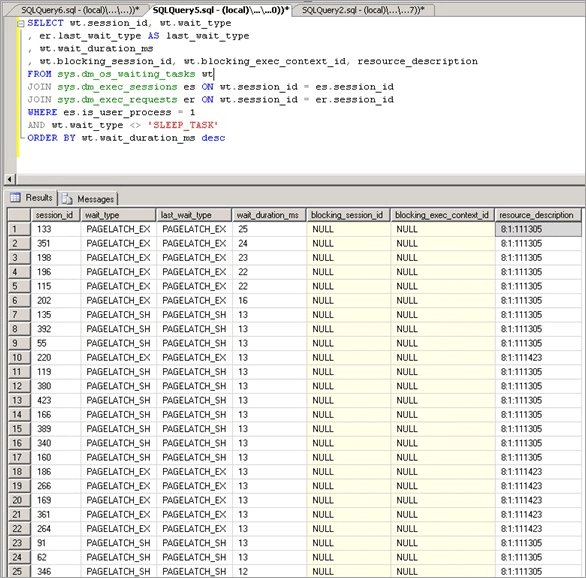
Pertikaian kait buffer bermanifestasi sebagai peningkatan waktu tunggu untuk kait dengan wait_typePAGELATCH_* atau PAGEIOLATCH_* seperti yang ditampilkan di sys.dm_os_wait_stats DMV. Untuk melihat sistem secara real time, jalankan kueri berikut pada sistem untuk bergabung dengan sys.dm_os_wait_statsDMV , sys.dm_exec_sessions dan sys.dm_exec_requests . Hasilnya dapat digunakan untuk menentukan jenis tunggu saat ini untuk sesi yang dijalankan pada server.
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc
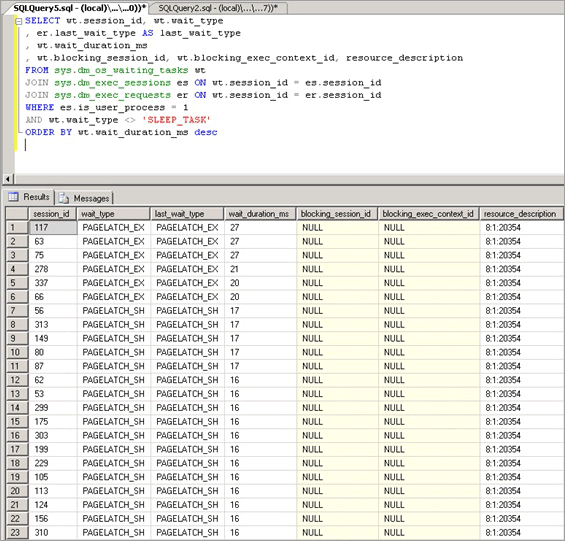
Statistik yang diekspos oleh kueri ini dijelaskan sebagai berikut:
| Statistik | Deskripsi |
|---|---|
| Session_id | ID sesi yang terkait dengan tugas. |
| Wait_type | Jenis tunggu yang telah direkam SQL Server di mesin, yang mencegah permintaan saat ini dijalankan. |
| Last_wait_type | Jika permintaan ini sebelumnya telah diblokir, kolom ini mengembalikan jenis tunggu terakhir. Tidak dapat diubah ke null. |
| Wait_duration_ms | Total waktu tunggu dalam milidetik yang dihabiskan untuk menunggu jenis tunggu ini karena instans SQL Server dimulai atau karena statistik tunggu kumulatif diatur ulang. |
| Blocking_session_id | ID sesi yang memblokir permintaan. |
| Blocking_exec_context_id | ID konteks eksekusi yang terkait dengan tugas. |
| Resource_description | Kolom resource_description mencantumkan halaman yang tepat sedang ditunggu dalam format: <database_id>:<file_id>:<page_id> |
Kueri berikut akan mengembalikan informasi untuk semua kait non-buffer:
select * from sys.dm_os_latch_stats where latch_class <> 'BUFFER' order by wait_time_ms desc;
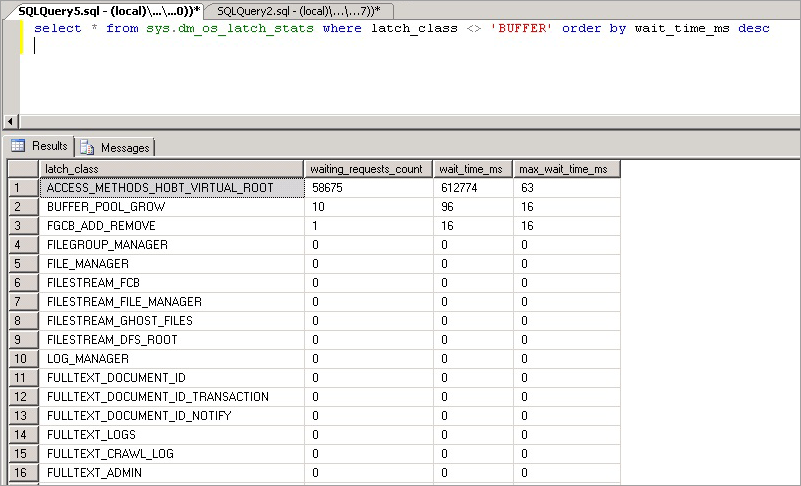
Statistik yang diekspos oleh kueri ini dijelaskan sebagai berikut:
| Statistik | Deskripsi |
|---|---|
| latch_class | Jenis kait yang telah direkam SQL Server di mesin, yang mencegah permintaan saat ini dijalankan. |
| waiting_requests_count | Jumlah tunggu pada kait di kelas ini sejak SQL Server dimulai ulang. Penghitung ini ditingkatkan pada awal penantian kait. |
| wait_time_ms | Total waktu tunggu dalam milidetik yang dihabiskan untuk menunggu jenis kait ini. |
| max_wait_time_ms | Waktu maksimum dalam milidetik setiap permintaan yang dihabiskan untuk menunggu jenis kait ini. |
Catatan
Nilai yang dikembalikan oleh DMV ini bersifat kumulatif sejak terakhir kali mesin database dimulai ulang atau DMV direset. sqlserver_start_time Gunakan kolom di sys.dm_os_sys_info untuk menemukan waktu mulai mesin database terakhir. Pada sistem yang telah berjalan lama ini berarti beberapa statistik seperti max_wait_time_ms jarang berguna. Perintah berikut dapat digunakan untuk mengatur ulang statistik tunggu untuk DMV ini:
DBCC SQLPERF ('sys.dm_os_latch_stats', CLEAR);
Skenario ketidakcocokan kait SQL Server
Skenario berikut telah diamati untuk menyebabkan ketidakcocokan kait yang berlebihan.
Halaman terakhir/halaman berikutnya menyisipkan pertikaian
Praktik OLTP umum adalah membuat indeks berkluster pada kolom identitas atau tanggal. Ini membantu mempertahankan organisasi fisik indeks yang baik, yang dapat sangat menguntungkan performa baca dan tulis ke indeks. Namun, desain skema ini secara tidak sengaja dapat menyebabkan ketidakcocokan kait. Masalah ini paling umum terlihat dengan tabel besar, dengan baris kecil; dan menyisipkan ke dalam indeks yang berisi kolom kunci utama yang meningkat secara berurutan seperti bilangan bulat naik atau kunci tanggalwaktu. Dalam skenario ini, aplikasi jarang melakukan pembaruan atau penghapusan, pengecualiannya adalah untuk operasi pengarsipan.
Dalam contoh berikut, utas satu dan utas dua keduanya ingin melakukan penyisipan rekaman yang akan disimpan di halaman 299. Dari perspektif penguncian logis, tidak ada masalah karena kunci tingkat baris akan digunakan dan kunci eksklusif pada kedua rekaman pada halaman yang sama dapat ditahan pada saat yang sama. Namun untuk memastikan integritas memori fisik hanya satu utas pada satu waktu yang dapat memperoleh kait eksklusif sehingga akses ke halaman diserialisasikan untuk mencegah pembaruan yang hilang dalam memori. Dalam hal ini, utas 1 memperoleh kait eksklusif; dan utas 2 menunggu, yang mendaftarkan PAGELATCH_EX menunggu sumber daya ini dalam statistik tunggu. Ini ditampilkan melalui wait_type nilai dalam sys.dm_os_waiting_tasks DMV.
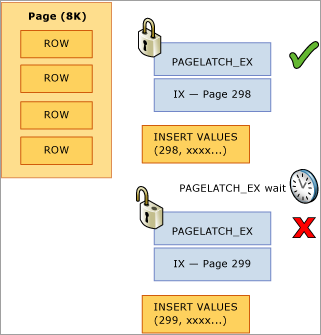
Pertikaian ini biasanya disebut sebagai pertikaian "Sisipan Halaman Terakhir" karena terjadi di tepi paling kanan pohon B seperti yang ditampilkan dalam diagram berikut:
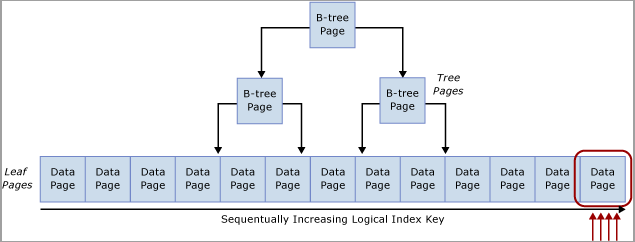
Jenis ketidakcocokan kait ini dapat dijelaskan sebagai berikut. Ketika baris baru dimasukkan ke dalam indeks, SQL Server akan menggunakan algoritma berikut untuk menjalankan modifikasi:
Melintasi pohon B untuk menemukan halaman yang benar untuk menyimpan rekaman baru.
Kaitkan halaman dengan PAGELATCH_EX, mencegah orang lain memodifikasinya, dan memperoleh kait bersama (PAGELATCH_SH) di semua halaman non-daun.
Catatan
Dalam beberapa kasus, Mesin SQL memerlukan kait EX untuk diperoleh pada halaman pohon B non-daun juga. Misalnya, ketika pemisahan halaman terjadi halaman apa pun yang akan terkena dampak langsung perlu dikaitkan secara eksklusif (PAGELATCH_EX).
Rekam entri log bahwa baris telah dimodifikasi.
Tambahkan baris ke halaman dan tandai halaman sebagai kotor.
Lepaskan semua halaman.
Jika indeks tabel didasarkan pada kunci yang meningkat secara berurutan, setiap sisipan baru akan masuk ke halaman yang sama di akhir pohon B, hingga halaman tersebut penuh. Dalam skenario konkurensi tinggi, ini dapat menyebabkan ketidakcocokan di tepi paling kanan pohon B dan dapat terjadi pada indeks berkluster dan non-kluster. Tabel yang dipengaruhi oleh jenis ketidakcocokan ini terutama menerima INSERT, dan halaman untuk indeks bermasalah biasanya relatif padat (misalnya, ukuran baris ~165 byte (termasuk overhead baris) sama dengan ~49 baris per halaman). Dalam contoh insert-heavy ini, diharapkan bahwa PAGELATCH_EX/PAGELATCH_SH menunggu akan terjadi, dan ini adalah pengamatan umum. Untuk memeriksa tunggu Latch Halaman vs. Latch Halaman Pohon menunggu, gunakan sys.dm_db_index_operational_stats DMV.
Tabel berikut ini meringkas faktor utama yang diamati dengan jenis ketidakcocokan kait ini:
| Faktor | Pengamatan umum |
|---|---|
| CPU logis yang digunakan oleh SQL Server | Jenis ketidakcocokan kait ini terjadi terutama pada 16+ sistem inti CPU dan paling umum pada 32+ sistem inti CPU. |
| Desain skema dan pola akses | Menggunakan nilai identitas yang meningkat secara berurutan sebagai kolom terkemuka dalam indeks pada tabel untuk data transaksional. Indeks memiliki kunci primer yang meningkat dengan tingkat sisipan yang tinggi. Indeks memiliki setidaknya satu nilai kolom yang meningkat secara berurutan. Biasanya ukuran baris kecil dengan banyak baris per halaman. |
| Jenis tunggu diamati | Banyak utas yang bersaing untuk sumber daya yang sama dengan penantian kait eksklusif (EX) atau bersama (SH) yang terkait dengan resource_description yang sama di sys.dm_os_waiting_tasks DMV seperti yang dikembalikan oleh Kueri sys.dm_os_waiting_tasks Diurutkan berdasarkan Durasi Tunggu. |
| Faktor desain yang perlu dipertimbangkan | Pertimbangkan untuk mengubah urutan kolom indeks seperti yang dijelaskan dalam strategi mitigasi indeks non-berurutan jika Anda dapat menjamin bahwa sisipan akan didistribusikan di seluruh pohon B secara seragam sepanjang waktu. Jika strategi mitigasi partisi Hash digunakan, strategi ini akan menghapus kemampuan untuk menggunakan partisi untuk tujuan lain seperti pengarsipan jendela geser. Penggunaan strategi mitigasi partisi Hash dapat menyebabkan masalah penghapusan partisi untuk kueri SELECT yang digunakan oleh aplikasi. |
Kaitkan ketidakcocokan pada tabel kecil dengan indeks non-kluster dan sisipan acak (tabel antrean)
Skenario ini biasanya terlihat ketika tabel SQL digunakan sebagai antrean sementara (misalnya, dalam sistem olahpesan asinkron).
Dalam skenario ini, ketidakcocokan kait eksklusif skenario (EX) dan bersama (SH) dapat terjadi dalam kondisi berikut:
- Sisipkan, pilih, perbarui, atau hapus operasi terjadi di bawah konkurensi tinggi.
- Ukuran baris relatif kecil (mengarah ke halaman padat).
- Jumlah baris dalam tabel relatif kecil; mengarah ke pohon B dangkal, didefinisikan dengan memiliki kedalaman indeks dua atau tiga.
Catatan
Bahkan pohon B dengan kedalaman yang lebih besar daripada ini dapat mengalami ketidakcocokan dengan jenis pola akses ini, jika frekuensi bahasa manipulasi data (DML) dan konkurensi sistem cukup tinggi. Tingkat ketidakcocokan kait dapat diucapkan saat konkurensi meningkat ketika 16 inti CPU atau lebih tersedia untuk sistem.
Ketidakcocokan kait dapat terjadi bahkan jika akses acak di seluruh pohon B seperti ketika kolom non-berurutan adalah kunci utama dalam indeks berkluster. Cuplikan layar berikut berasal dari sistem yang mengalami jenis ketidakcocokan kait ini. Dalam contoh ini, pertikaian disebabkan oleh kepadatan halaman yang disebabkan oleh ukuran baris kecil dan pohon B yang relatif dangkal. Saat konkurensi meningkat, ketidakcocokan kait pada halaman terjadi meskipun sisipan acak di seluruh pohon B karena GUID adalah kolom utama dalam indeks.
Dalam cuplikan layar berikut, penantian terjadi pada halaman data buffer dan halaman ruang kosong halaman (PFS). Untuk informasi selengkapnya tentang ketidakcocokan halaman PFS, lihat posting blog pihak ketiga berikut di SQLSkills: Tolok ukur: Beberapa file data di SSD. Bahkan ketika jumlah file data ditingkatkan, ketidakcocokan kait umum pada halaman data buffer.
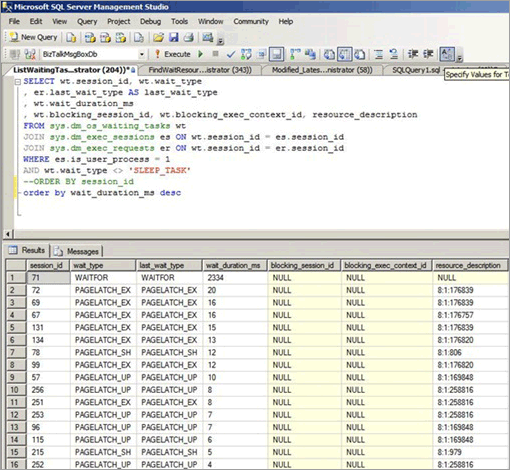
Tabel berikut ini meringkas faktor utama yang diamati dengan jenis ketidakcocokan kait ini:
| Faktor | Pengamatan umum |
|---|---|
| CPU logis yang digunakan oleh SQL Server | Ketidakcocokan kait terjadi terutama pada komputer dengan 16+ inti CPU. |
| Desain Skema dan Pola Akses | Tingkat tinggi pola akses insert/select/update/delete terhadap tabel kecil. Pohon B dangkal (kedalaman indeks dua atau tiga). Ukuran baris kecil (banyak rekaman per halaman). |
| Tingkat konkurensi | Ketidakcocokan kait hanya akan terjadi di bawah tingkat permintaan bersamaan yang tinggi dari tingkat aplikasi. |
| Jenis tunggu diamati | Amati menunggu pada buffer (PAGELATCH_EX dan PAGELATCH_SH) dan kait non-buffer ACCESS_METHODS_HOBT_VIRTUAL_ROOT karena pemisahan akar. Juga PAGELATCH_UP menunggu di halaman PFS. Untuk informasi selengkapnya tentang tunggu kait non-buffer, lihat sys.dm_os_latch_stats (Transact-SQL) di bantuan SQL Server. |
Kombinasi B-Tree dangkal dan sisipan acak di seluruh indeks rentan menyebabkan pemisahan halaman di pohon B. Untuk melakukan pemisahan halaman, SQL Server harus memperoleh kait bersama (SH) di semua tingkat, lalu memperoleh kait eksklusif (EX) pada halaman di pohon B yang terlibat dalam pemisahan halaman. Juga ketika konkurensi tinggi dan data terus dimasukkan dan dihapus, pemisahan akar pohon B dapat terjadi. Dalam hal ini, sisipan lain mungkin harus menunggu kait non-buffer yang diperoleh di pohon B. Ini akan dimanifestasikan sebagai sejumlah besar tunggu pada jenis kait ACCESS_METHODS_HOBT_VIRTUAL_ROOT yang diamati dalam sys.dm_os_latch_stats DMV.
Skrip berikut dapat dimodifikasi untuk menentukan kedalaman pohon B untuk indeks pada tabel yang terpengaruh.
select o.name as [table],
i.name as [index],
indexProperty(object_id(o.name), i.name, 'indexDepth')
+ indexProperty(object_id(o.name), i.name, 'isClustered') as depth, --clustered index depth reported doesn't count leaf level
i.[rows] as [rows],
i.origFillFactor as [fillFactor],
case (indexProperty(object_id(o.name), i.name, 'isClustered'))
when 1 then 'clustered'
when 0 then 'nonclustered'
else 'statistic'
end as type
from sysIndexes i
join sysObjects o on o.id = i.id
where o.type = 'u'
and indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes
and indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics
order by o.name;
Kaitkan ketidakcocokan pada halaman ruang kosong halaman (PFS)
PFS adalah singkatan dari Ruang Kosong Halaman, SQL Server mengalokasikan satu halaman PFS untuk setiap 8088 halaman (dimulai dengan PageID = 1) di setiap file database. Setiap byte di halaman PFS merekam informasi termasuk berapa banyak ruang kosong di halaman, jika dialokasikan atau tidak dan apakah halaman menyimpan catatan hantu. Halaman PFS berisi informasi tentang halaman yang tersedia untuk alokasi saat halaman baru diperlukan oleh operasi sisipkan atau perbarui. Halaman PFS harus diperbarui dalam sejumlah skenario, termasuk ketika alokasi atau de-alokasi terjadi. Karena penggunaan kait pembaruan (UP) diperlukan untuk melindungi halaman PFS, ketidakcocokan kait pada halaman PFS dapat terjadi jika Anda memiliki file data yang relatif sedikit dalam grup file dan sejumlah besar inti CPU. Cara sederhana untuk mengatasi hal ini adalah dengan meningkatkan jumlah file per grup file.
Peringatan
Meningkatkan jumlah file per grup file dapat berdampak buruk pada performa beban tertentu, seperti beban dengan banyak operasi pengurutan besar yang meluapkan memori ke disk.
Jika banyak PAGELATCH_UP menunggu diamati untuk halaman PFS atau SGAM di tempdb, selesaikan langkah-langkah ini untuk menghilangkan hambatan ini:
Tambahkan file data ke tempdb sehingga jumlah file data tempdb sama dengan jumlah inti prosesor di server Anda.
Aktifkan Bendera Pelacakan SQL Server 1118.
Untuk informasi selengkapnya tentang penyempitan alokasi yang disebabkan oleh ketidakcocokan pada halaman sistem, lihat posting blog Apa itu hambatan alokasi?.
Fungsi bernilai tabel dan ketidakcocokan kait pada tempdb
Ada faktor lain di luar pertikaian alokasi yang dapat menyebabkan ketidakcocokan kait pada tempdb, seperti penggunaan TVF berat dalam kueri.
Menangani ketidakcocokan kait untuk pola tabel yang berbeda
Bagian berikut menjelaskan teknik yang dapat digunakan untuk mengatasi atau mengatasi masalah performa yang terkait dengan ketidakcocokan kait yang berlebihan.
Menggunakan kunci indeks terkemuka yang tidak berurutan
Salah satu metode untuk menangani pertikaian kait adalah mengganti kunci indeks berurutan dengan kunci non-berurutan untuk mendistribusikan sisipan secara merata di seluruh rentang indeks.
Biasanya ini dilakukan dengan memiliki kolom terkemuka dalam indeks yang akan mendistribusikan beban kerja secara proporsional. Ada beberapa opsi di sini:
Opsi: Gunakan kolom dalam tabel untuk mendistribusikan nilai di seluruh rentang kunci indeks
Evaluasi beban kerja Anda untuk nilai alami yang dapat digunakan untuk mendistribusikan sisipan di seluruh rentang kunci. Misalnya, pertimbangkan skenario perbankan ATM di mana ATM_ID mungkin merupakan kandidat yang baik untuk mendistribusikan sisipan ke dalam tabel transaksi untuk penarikan karena satu nasabah hanya dapat menggunakan satu ATM pada satu waktu. Demikian pula dalam sistem titik penjualan, mungkin Checkout_ID atau ID Toko akan menjadi nilai alami yang dapat digunakan untuk mendistribusikan sisipan di seluruh rentang kunci. Teknik ini mengharuskan pembuatan kunci indeks komposit dengan kolom kunci terkemuka adalah nilai kolom yang diidentifikasi atau beberapa hash dari nilai tersebut dikombinasikan dengan satu atau beberapa kolom tambahan untuk memberikan keunikan. Dalam kebanyakan kasus, hash nilai akan bekerja paling baik karena terlalu banyak nilai yang berbeda akan mengakibatkan organisasi fisik yang buruk. Misalnya, dalam sistem titik penjualan, hash dapat dibuat dari ID Toko yang merupakan beberapa modulo, yang selaras dengan jumlah inti CPU. Teknik ini akan mengakibatkan jumlah rentang yang relatif kecil dalam tabel namun akan cukup untuk mendistribusikan sisipan sembari untuk menghindari ketidakcocokan kait. Gambar berikut mengilustrasikan teknik ini.
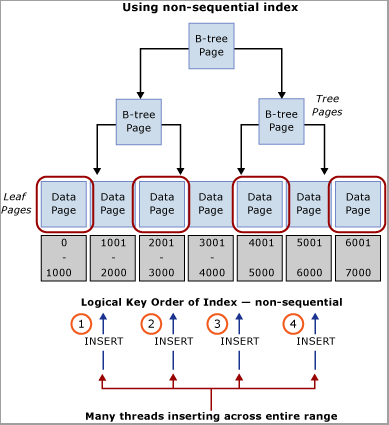
Penting
Pola ini bertentangan dengan praktik terbaik pengindeksan tradisional. Meskipun teknik ini akan membantu memastikan distribusi sisipan yang seragam di seluruh pohon B, teknik ini juga dapat mengharuskan perubahan skema pada tingkat aplikasi. Selain itu, pola ini dapat berdampak negatif pada performa kueri yang memerlukan pemindaian rentang yang menggunakan indeks berkluster. Beberapa analisis pola beban kerja akan diperlukan untuk menentukan apakah pendekatan desain ini akan berfungsi dengan baik. Pola ini harus diimplementasikan jika Anda dapat mengorbankan beberapa performa pemindaian berurutan untuk mendapatkan throughput sisipan dan skala.
Pola ini diterapkan selama keterlibatan lab performa dan mengatasi ketidakcocokan kait pada sistem dengan 32 inti CPU fisik. Tabel digunakan untuk menyimpan saldo penutupan pada akhir transaksi; setiap transaksi bisnis melakukan satu sisipan ke dalam tabel.
Definisi tabel asli
Saat menggunakan definisi tabel asli, ketidakcocokan kait yang berlebihan diamati terjadi pada indeks berkluster pk_table1:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (TransactionID, UserID);
go
Catatan
Nama objek dalam definisi tabel telah diubah dari nilai aslinya.
Definisi indeks yang diurutkan ulang
Menyusun ulang kolom kunci indeks dengan UserID sebagai kolom utama di kunci utama menyediakan distribusi sisipan yang hampir acak di seluruh halaman. Distribusi yang dihasilkan tidak 100% acak karena tidak semua pengguna online pada saat yang sama, tetapi distribusinya cukup acak untuk meringankan ketidakcocokan kait yang berlebihan. Salah satu peringatan penyusunan ulang definisi indeks adalah bahwa setiap kueri pemilihan terhadap tabel ini harus dimodifikasi untuk menggunakan UserID dan TransactionID sebagai predikat kesetaraan.
Penting
Pastikan Anda menguji secara menyeluruh setiap perubahan di lingkungan pengujian sebelum berjalan di lingkungan produksi.
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (UserID, TransactionID);
go
Menggunakan nilai hash sebagai kolom utama di kunci primer
Definisi tabel berikut dapat digunakan untuk menghasilkan modulo yang selaras dengan jumlah CPU, HashValue dihasilkan menggunakan nilai yang meningkat secara berurutan TransactionID untuk memastikan distribusi seragam di seluruh B-Tree:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
-- Consider using bulk loading techniques to speed it up
ALTER TABLE table1
ADD [HashValue] AS (CONVERT([tinyint], abs([TransactionID])%(32))) PERSISTED NOT NULL
alter table table1
add constraint pk_table1
primary key clustered (HashValue, TransactionID, UserID);
go
Opsi: Gunakan GUID sebagai kolom kunci utama indeks
Jika tidak ada pemisah alami, maka kolom GUID dapat digunakan sebagai kolom kunci utama indeks untuk memastikan distribusi sisipan yang seragam. Saat menggunakan GUID sebagai kolom terkemuka dalam pendekatan kunci indeks memungkinkan penggunaan partisi untuk fitur lain, teknik ini juga dapat memperkenalkan potensi kelemahan dari lebih banyak pemisahan halaman, organisasi fisik yang buruk, dan kepadatan halaman rendah.
Catatan
Penggunaan GUID sebagai kolom kunci utama indeks adalah subjek yang sangat diperdebatkan. Diskusi mendalam tentang pro dan kontra dari metode ini berada di luar cakupan artikel ini.
Menggunakan partisi hash dengan kolom komputasi
Pemartisian tabel dalam SQL Server dapat digunakan untuk mengurangi ketidakcocokan kait yang berlebihan. Membuat skema partisi hash dengan kolom komputasi pada tabel yang dipartisi adalah pendekatan umum yang dapat dicapai dengan langkah-langkah berikut:
Buat grup file baru atau gunakan grup file yang ada untuk menahan partisi.
Jika menggunakan grup file baru, sama-sama menyeimbangkan file individual melalui LUN, berhati-hatilah untuk menggunakan tata letak yang optimal. Jika pola akses melibatkan tingkat sisipan yang tinggi, pastikan untuk membuat jumlah file yang sama karena ada inti CPU fisik di komputer SQL Server.
Gunakan perintah CREATE PARTITION FUNCTION untuk mempartisi tabel ke dalam partisi X, di mana X adalah jumlah inti CPU fisik pada komputer SQL Server. (setidaknya hingga 32 partisi)
Catatan
Penyelarasan 1:1 dari jumlah partisi ke jumlah inti CPU tidak selalu diperlukan. Dalam banyak kasus, ini bisa menjadi beberapa nilai yang kurang dari jumlah inti CPU. Memiliki lebih banyak partisi dapat menghasilkan lebih banyak overhead untuk kueri yang harus mencari semua partisi dan dalam kasus ini lebih sedikit partisi yang akan membantu. Dalam pengujian SQLCAT pada sistem CPU logis 64 dan 128 dengan beban kerja pelanggan nyata 32 partisi telah cukup untuk menyelesaikan ketidakcocokan kait yang berlebihan dan mencapai target skala. Pada akhirnya jumlah partisi yang ideal harus ditentukan melalui pengujian.
Gunakan perintah CREATE PARTITION SCHEME:
- Ikat fungsi partisi ke grup file.
- Tambahkan kolom hash jenis tinyint atau smallint ke tabel.
- Hitung distribusi hash yang baik. Misalnya, gunakan hashbyte dengan modulo atau binary_checksum.
Contoh skrip berikut dapat disesuaikan untuk tujuan implementasi Anda:
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
Skrip ini dapat digunakan untuk hash partisi tabel yang mengalami masalah yang disebabkan oleh halaman terakhir/halaman berikutnya menyisipkan pertikaian. Teknik ini memindahkan ketidakcocokan dari halaman terakhir dengan mempartisi tabel dan mendistribusikan sisipan di seluruh partisi tabel dengan operasi modulus nilai hash.
Apa yang dilakukan partisi hash dengan kolom komputasi
Seperti yang diilustrasikan oleh diagram berikut, teknik ini memindahkan pertikaian dari halaman terakhir dengan membangun kembali indeks pada fungsi hash dan membuat jumlah partisi yang sama karena ada inti CPU fisik di komputer SQL Server. Sisipan masih masuk ke akhir rentang logis (nilai yang meningkat secara berurutan) tetapi operasi modulus nilai hash memastikan bahwa sisipan dibagi di berbagai pohon B, yang meringankan hambatan. Ini diilustrasikan dalam diagram berikut:
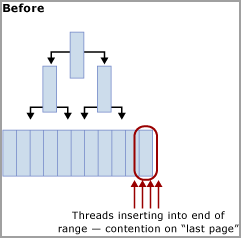
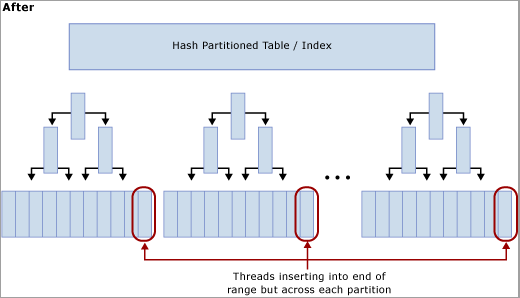
Trade-off saat menggunakan partisi hash
Meskipun pemartisian hash dapat menghilangkan ketidakcocokan pada sisipan, ada beberapa trade-off yang perlu dipertimbangkan saat memutuskan apakah akan menggunakan teknik ini atau tidak:
Pilih kueri akan dalam banyak kasus perlu dimodifikasi untuk menyertakan partisi hash dalam predikat dan mengarah ke rencana kueri yang tidak menyediakan eliminasi partisi ketika kueri ini dikeluarkan. Cuplikan layar berikut menunjukkan rencana buruk tanpa eliminasi partisi setelah partisi hash diterapkan.
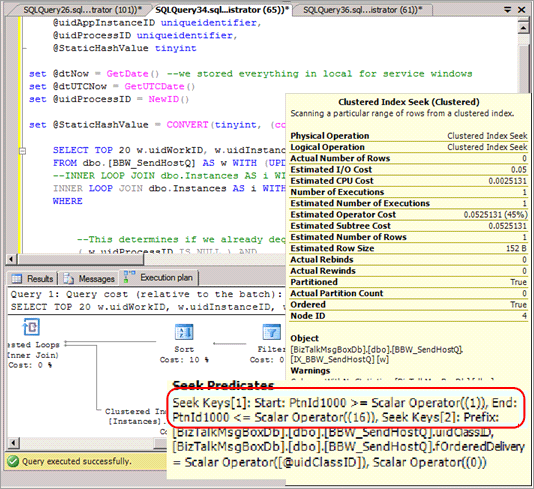
Ini menghilangkan kemungkinan eliminasi partisi pada kueri lain tertentu, seperti laporan berbasis rentang.
Saat menggabungkan tabel yang dipartisi hash ke tabel lain, untuk mencapai penghapusan partisi, tabel kedua perlu dipartisi hash pada kunci yang sama dan kunci hash harus menjadi bagian dari kriteria gabungan.
Pemartisian hash mencegah penggunaan partisi untuk fitur manajemen lain seperti pengarsipan jendela geser dan fungsionalitas pengalihan partisi.
Pemartisian hash adalah strategi efektif untuk mengurangi ketidakcocokan kait yang berlebihan karena meningkatkan throughput sistem secara keseluruhan dengan mengurangi ketidakcocokan pada sisipan. Karena ada beberapa trade-off yang terlibat, itu mungkin bukan solusi optimal untuk beberapa pola akses.
Ringkasan teknik yang digunakan untuk mengatasi ketidakcocokan kait
Dua bagian berikut memberikan ringkasan teknik yang dapat digunakan untuk mengatasi ketidakcocokan kait yang berlebihan:
Kunci/indeks non-berurutan
Keuntungan:
- Memungkinkan penggunaan fitur partisi lainnya, seperti pengarsipan data menggunakan skema jendela geser dan fungsionalitas pengalihan partisi.
Kerugian:
- Kemungkinan tantangan saat memilih kunci/indeks untuk memastikan distribusi sisipan yang seragam 'cukup dekat' sepanjang waktu.
- GUID sebagai kolom terkemuka dapat digunakan untuk menjamin distribusi seragam dengan peringatan yang dapat mengakibatkan operasi pemisahan halaman yang berlebihan.
- Sisipan acak di seluruh B-Tree dapat mengakibatkan terlalu banyak operasi pemisahan halaman dan menyebabkan ketidakcocokan kait pada halaman non-daun.
Pemartisian hash dengan kolom komputasi
Keuntungan:
- Transparan untuk penyisipan.
Kerugian:
- Pemartisian tidak dapat digunakan untuk fitur manajemen yang dimaksudkan seperti pengarsipan data menggunakan opsi pengalihan partisi.
- Dapat menyebabkan masalah penghapusan partisi untuk kueri termasuk pemilihan/pembaruan berbasis individual dan rentang, dan kueri yang melakukan gabungan.
- Menambahkan kolom komputasi yang dipertahankan adalah operasi offline.
Tip
Untuk teknik tambahan, lihat posting blog PAGELATCH_EX menunggu dan sisipan berat.
Panduan: Mendiagnosis ketidakcocokan kait
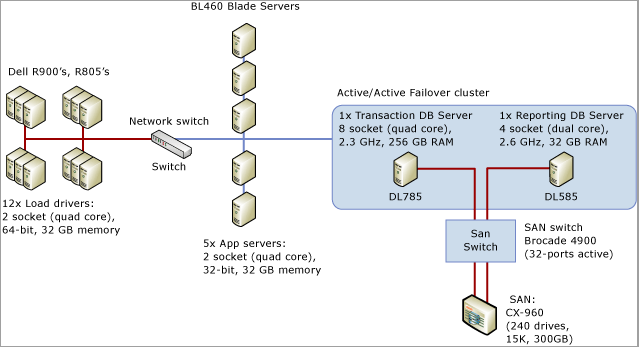
Panduan berikut menunjukkan alat dan teknik yang dijelaskan dalam Mendiagnosis SQL Server Latch Contention dan Menangani Pertikaian Kait untuk Pola Tabel yang Berbeda untuk menyelesaikan masalah dalam skenario dunia nyata. Skenario ini menjelaskan keterlibatan pelanggan untuk melakukan pengujian beban sistem titik penjualan yang mensimulasikan sekitar 8.000 toko yang melakukan transaksi terhadap aplikasi SQL Server yang berjalan pada soket 8, sistem inti fisik 32 dengan memori 256 GB.
Diagram berikut merinci perangkat keras yang digunakan untuk menguji titik sistem penjualan:
Gejala: Kait panas
Dalam hal ini, kami mengamati penantian tinggi untuk PAGELATCH_EX di mana kami biasanya mendefinisikan tinggi sebagai rata-rata lebih dari 1 ms. Dalam hal ini, kami secara konsisten mengamati menunggu melebihi 20 mdtk.
Setelah kami menentukan bahwa ketidakcocokan kait bermasalah, kami kemudian menetapkan untuk menentukan apa yang menyebabkan ketidakcocokan kait.
Mengisolasi objek yang menyebabkan ketidakcocokan kait
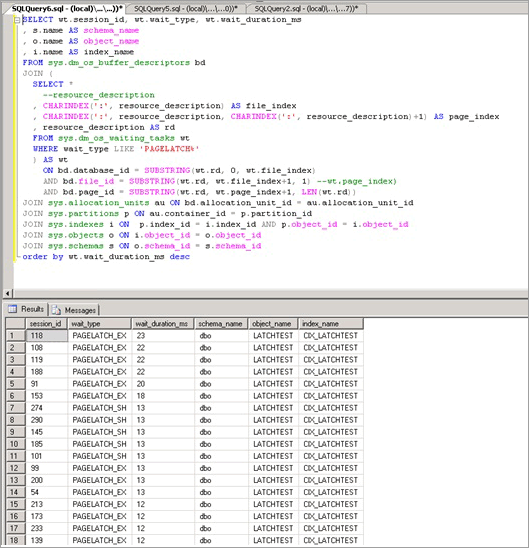
Skrip berikut menggunakan kolom resource_description untuk mengisolasi indeks mana yang menyebabkan ketidakcocokan PAGELATCH_EX:
Catatan
Kolom resource_description yang dikembalikan oleh skrip ini menyediakan deskripsi sumber daya dalam format <DatabaseID,FileID,PageID> di mana nama database yang terkait dengan DatabaseID dapat ditentukan dengan meneruskan nilai DatabaseID ke fungsi DB_NAME ().
SELECT wt.session_id, wt.wait_type, wt.wait_duration_ms
, s.name AS schema_name
, o.name AS object_name
, i.name AS index_name
FROM sys.dm_os_buffer_descriptors bd
JOIN (
SELECT *
--resource_description
, CHARINDEX(':', resource_description) AS file_index
, CHARINDEX(':', resource_description, CHARINDEX(':', resource_description)+1) AS page_index
, resource_description AS rd
FROM sys.dm_os_waiting_tasks wt
WHERE wait_type LIKE 'PAGELATCH%'
) AS wt
ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index)
AND bd.file_id = SUBSTRING(wt.rd, wt.file_index+1, 1) --wt.page_index)
AND bd.page_id = SUBSTRING(wt.rd, wt.page_index+1, LEN(wt.rd))
JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id
order by wt.wait_duration_ms desc;
Seperti yang ditunjukkan di sini, ketidakcocokan ada pada tabel LATCHTEST dan nama indeks CIX_LATCHTEST. Nama catatan telah diubah untuk menganonimkan beban kerja.
Untuk skrip yang lebih canggih yang melakukan polling berulang kali dan menggunakan tabel sementara untuk menentukan total waktu tunggu selama periode yang dapat dikonfigurasi, lihat Deskriptor Buffer Kueri untuk Menentukan Objek Yang Menyebabkan Ketidakcocokan Kait di Lampiran.
Teknik alternatif untuk mengisolasi objek yang menyebabkan ketidakcocokan kait
Terkadang tidak praktis untuk mengkueri sys.dm_os_buffer_descriptors. Karena memori dalam sistem, dan tersedia untuk kumpulan buffer meningkat begitu juga waktu yang diperlukan untuk menjalankan DMV ini. Pada sistem 256 GB, mungkin perlu waktu hingga 10 menit atau lebih agar DMV ini berjalan. Teknik alternatif tersedia dan secara luas diuraikan sebagai berikut dan diilustrasikan dengan beban kerja yang berbeda, yang kami jalankan di lab:
Kueri tugas tunggu saat ini, menggunakan Kueri skrip Lampiran sys.dm_os_waiting_tasks Diurutkan berdasarkan Durasi Tunggu.
Identifikasi halaman kunci tempat konvoi diamati, yang terjadi ketika beberapa utas bersaing di halaman yang sama. Dalam contoh ini, utas yang melakukan penyisipan bersaing pada halaman berikutnya di pohon B dan akan menunggu sampai mereka dapat memperoleh kait EX. Ini ditunjukkan oleh resource_description dalam kueri pertama, dalam kasus kami 8:1:111305.
Aktifkan bendera pelacakan 3604, yang memaparkan informasi lebih lanjut tentang halaman melalui HALAMAN DBCC dengan sintaks berikut, ganti nilai yang Anda peroleh melalui resource_description untuk nilai dalam tanda kurung:
--enable trace flag 3604 to enable console output dbcc traceon (3604); --examine the details of the page dbcc page (8,1, 111305, -1);Periksa output DBCC. Harus ada Metadata ObjectID terkait, dalam kasus kami '78623323'.
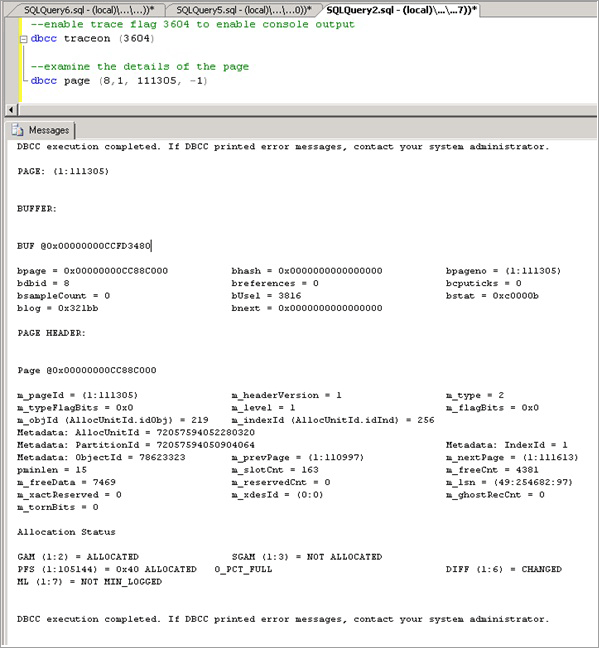
Kita sekarang dapat menjalankan perintah berikut untuk menentukan nama objek yang menyebabkan pertikaian, yang seperti yang diharapkan adalah LATCHTEST.
Catatan
Pastikan Anda berada dalam konteks database yang benar jika tidak, kueri akan mengembalikan NULL.
--get object name select OBJECT_NAME (78623323);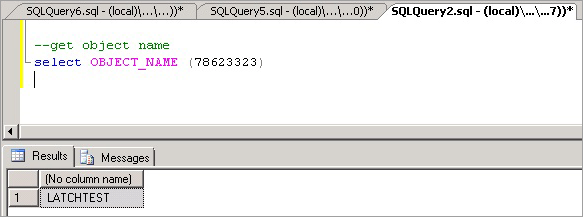
Ringkasan dan hasil
Menggunakan teknik di atas kami dapat mengonfirmasi bahwa pertikaian terjadi pada indeks berkluster dengan nilai kunci yang meningkat secara berurutan pada tabel yang sejauh ini menerima jumlah sisipan tertinggi. Jenis pertikaian ini tidak jarang terjadi untuk indeks dengan nilai kunci yang meningkat secara berurutan seperti tanggalwaktu, identitas, atau transactionID yang dihasilkan aplikasi.
Untuk mengatasi masalah ini, kami menggunakan partisi hash dengan kolom komputasi dan mengamati peningkatan performa 690%. Tabel berikut ini meringkas performa aplikasi sebelum dan sesudah menerapkan partisi hash dengan kolom komputasi. Pemanfaatan CPU meningkat secara luas sejalan dengan throughput seperti yang diharapkan setelah hambatan pertikaian kait dihapus:
| Pengukuran | Sebelum partisi hash | Setelah pemartisian hash |
|---|---|---|
| Transaksi Bisnis/Detik | 36 | 249 |
| Rata-rata Waktu Tunggu Kait Halaman | 36 milidetik | 0,6 milidetik |
| Latch Waits/Sec | 9,562 | 2,873 |
| Waktu Prosesor SQL | 24% | 78% |
| Permintaan Batch SQL/detik | 12,368 | 47,045 |
Seperti yang dapat dilihat dari tabel di atas, mengidentifikasi dan menyelesaikan masalah performa yang disebabkan oleh ketidakcocokan kait halaman yang berlebihan dapat berdampak positif pada performa aplikasi secara keseluruhan.
Lampiran: Teknik alternatif
Salah satu strategi yang mungkin untuk menghindari ketidakcocokan latch halaman yang berlebihan adalah dengan baris pad dengan kolom CHAR untuk memastikan bahwa setiap baris akan menggunakan halaman lengkap. Strategi ini adalah opsi ketika ukuran data keseluruhan kecil dan Anda perlu mengatasi ketidakcocokan kait halaman EX yang disebabkan oleh kombinasi faktor-faktor berikut:
- Ukuran baris kecil
- Pohon B dangkal
- Pola akses dengan tingkat penyisipan acak yang tinggi, pilih, perbarui, dan hapus operasi
- Tabel kecil, seperti tabel antrean sementara
Dengan mengayuh baris untuk menempati halaman lengkap, Anda memerlukan SQL untuk mengalokasikan halaman tambahan, membuat lebih banyak halaman tersedia untuk penyisipan dan mengurangi ketidakcocokan kait halaman EX.
Baris Padding untuk memastikan setiap baris menempati halaman penuh
Skrip yang mirip dengan yang berikut ini dapat digunakan untuk pad baris untuk menempati seluruh halaman:
ALTER TABLE mytable ADD Padding CHAR(5000) NOT NULL DEFAULT ('X');
Catatan
Gunakan karakter terkecil yang memaksa satu baris per halaman untuk mengurangi persyaratan CPU tambahan untuk nilai padding dan ruang tambahan yang diperlukan untuk mencatat baris. Setiap byte dihitung dalam sistem performa tinggi.
Teknik ini dijelaskan untuk kelengkapan; dalam praktiknya SQLCAT hanya menggunakan ini pada tabel kecil dengan 10.000 baris dalam satu keterlibatan performa. Teknik ini memiliki aplikasi terbatas karena meningkatkan tekanan memori pada SQL Server untuk tabel besar dan dapat mengakibatkan ketidakcocokan kait buffer pada halaman non-daun. Tekanan memori tambahan dapat menjadi faktor pembatas yang signifikan untuk penerapan teknik ini. Dengan jumlah memori yang tersedia di server modern, proporsi besar set kerja untuk beban kerja OLTP biasanya disimpan dalam memori. Ketika himpunan data meningkat menjadi ukuran yang tidak lagi cocok dalam memori, penurunan performa yang signifikan akan terjadi. Oleh karena itu, teknik ini adalah sesuatu yang hanya berlaku untuk tabel kecil. Teknik ini tidak digunakan oleh SQLCAT untuk skenario seperti halaman terakhir/halaman berikutnya menyisipkan pertikaian untuk tabel besar.
Penting
Menggunakan strategi ini dapat menyebabkan sejumlah besar tunggu pada jenis kait ACCESS_METHODS_HOBT_VIRTUAL_ROOT karena strategi ini dapat menyebabkan sejumlah besar pemisahan halaman yang terjadi di tingkat non-daun pohon B. Jika ini terjadi, SQL Server harus memperoleh kait bersama (SH) di semua tingkat diikuti oleh kait eksklusif (EX) pada halaman di pohon B tempat pemisahan halaman dimungkinkan. sys.dm_os_latch_stats Periksa DMV untuk jumlah tunggu yang tinggi pada jenis kait ACCESS_METHODS_HOBT_VIRTUAL_ROOT setelah baris padding.
Lampiran: Skrip pertikaian kait SQL Server
Bagian ini berisi skrip yang dapat digunakan untuk membantu mendiagnosis dan memecahkan masalah ketidakcocokan kait.
Kueri sys.dm_os_waiting_tasks diurutkan menurut ID sesi
Contoh skrip berikut akan mengkueri sys.dm_os_waiting_tasks dan mengembalikan penantian kait yang diurutkan berdasarkan ID sesi:
-- WAITING TASKS ordered by session_id
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY session_id;
Kueri sys.dm_os_waiting_tasks diurutkan berdasarkan durasi tunggu
Contoh skrip berikut akan mengkueri sys.dm_os_waiting_tasks dan mengembalikan penantian kait yang diurutkan berdasarkan durasi tunggu:
-- WAITING TASKS ordered by wait_duration_ms
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc;
Menghitung waktu tunggu selama periode waktu tertentu
Skrip berikut menghitung dan mengembalikan penantian kait selama periode waktu tertentu.
/* Snapshot the current wait stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
use tempdb
go
declare @current_snap_time datetime;
declare @previous_snap_time datetime;
set @current_snap_time = GETDATE();
if not exists(select name from tempdb.sys.sysobjects where name like '#_wait_stats%')
create table #_wait_stats
(
wait_type varchar(128)
,waiting_tasks_count bigint
,wait_time_ms bigint
,avg_wait_time_ms int
,max_wait_time_ms bigint
,signal_wait_time_ms bigint
,avg_signal_wait_time int
,snap_time datetime
);
insert into #_wait_stats (
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,snap_time
)
select
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,getdate()
from sys.dm_os_wait_stats;
--get the previous collection point
select top 1 @previous_snap_time = snap_time from #_wait_stats
where snap_time < (select max(snap_time) from #_wait_stats)
order by snap_time desc;
--get delta in the wait stats
select top 10
s.wait_type
, (e.waiting_tasks_count - s.waiting_tasks_count) as [waiting_tasks_count]
, (e.wait_time_ms - s.wait_time_ms) as [wait_time_ms]
, (e.wait_time_ms - s.wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_wait_time_ms]
, (e.max_wait_time_ms) as [max_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms) as [signal_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_signal_time_ms]
, s.snap_time as [start_time]
, e.snap_time as [end_time]
, DATEDIFF(ss, s.snap_time, e.snap_time) as [seconds_in_sample]
from #_wait_stats e
inner join (
select * from #_wait_stats
where snap_time = @previous_snap_time
) s on (s.wait_type = e.wait_type)
where
e.snap_time = @current_snap_time
and s.snap_time = @previous_snap_time
and e.wait_time_ms > 0
and (e.waiting_tasks_count - s.waiting_tasks_count) > 0
and e.wait_type NOT IN ('LAZYWRITER_SLEEP', 'SQLTRACE_BUFFER_FLUSH'
, 'SOS_SCHEDULER_YIELD','DBMIRRORING_CMD', 'BROKER_TASK_STOP'
, 'CLR_AUTO_EVENT', 'BROKER_RECEIVE_WAITFOR', 'WAITFOR'
, 'SLEEP_TASK', 'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT'
, 'FT_IFTS_SCHEDULER_IDLE_WAIT', 'BROKER_TO_FLUSH', 'XE_DISPATCHER_WAIT'
, 'SQLTRACE_INCREMENTAL_FLUSH_SLEEP')
order by (e.wait_time_ms - s.wait_time_ms) desc ;
--clean up table
delete from #_wait_stats
where snap_time = @previous_snap_time;
Deskriptor buffer kueri untuk menentukan objek yang menyebabkan ketidakcocokan kait
Skrip berikut meminta deskriptor buffer untuk menentukan objek mana yang terkait dengan waktu tunggu kait terpanjang.
IF EXISTS (SELECT * FROM tempdb.sys.objects WHERE [name] like '#WaitResources%') DROP TABLE #WaitResources;
CREATE TABLE #WaitResources (session_id INT, wait_type NVARCHAR(1000), wait_duration_ms INT,
resource_description sysname NULL, db_name NVARCHAR(1000), schema_name NVARCHAR(1000),
object_name NVARCHAR(1000), index_name NVARCHAR(1000));
GO
declare @WaitDelay varchar(16), @Counter INT, @MaxCount INT, @Counter2 INT
SELECT @Counter = 0, @MaxCount = 600, @WaitDelay = '00:00:00.100'-- 600x.1=60 seconds
SET NOCOUNT ON;
WHILE @Counter < @MaxCount
BEGIN
INSERT INTO #WaitResources(session_id, wait_type, wait_duration_ms, resource_description)--, db_name, schema_name, object_name, index_name)
SELECT wt.session_id,
wt.wait_type,
wt.wait_duration_ms,
wt.resource_description
FROM sys.dm_os_waiting_tasks wt
WHERE wt.wait_type LIKE 'PAGELATCH%' AND wt.session_id <> @@SPID
--select * from sys.dm_os_buffer_descriptors
SET @Counter = @Counter + 1;
WAITFOR DELAY @WaitDelay;
END;
--select * from #WaitResources;
update #WaitResources
set db_name = DB_NAME(bd.database_id),
schema_name = s.name,
object_name = o.name,
index_name = i.name
FROM #WaitResources wt
JOIN sys.dm_os_buffer_descriptors bd
ON bd.database_id = SUBSTRING(wt.resource_description, 0, CHARINDEX(':', wt.resource_description))
AND bd.file_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description) + 1, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) - CHARINDEX(':', wt.resource_description) - 1)
AND bd.page_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) + 1, LEN(wt.resource_description) + 1)
--AND wt.file_index > 0 AND wt.page_index > 0
JOIN sys.allocation_units au ON bd.allocation_unit_id = AU.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id;
select * from #WaitResources order by wait_duration_ms desc;
GO
/*
--Other views of the same information
SELECT wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY wait_type, db_name, schema_name, object_name, index_name;
SELECT session_id, wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY session_id, wait_type, db_name, schema_name, object_name, index_name;
*/
--SELECT * FROM #WaitResources
--DROP TABLE #WaitResources;
Skrip pemartisian hash
Penggunaan skrip ini dijelaskan dalam Menggunakan Partisi Hash dengan Kolom Komputasi dan harus disesuaikan untuk tujuan implementasi Anda.
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
Langkah berikutnya
Untuk informasi selengkapnya tentang alat pemantauan performa, lihat Pemantauan Performa dan Alat Penyetelan.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk