Mulai menggunakan indeks penyimpan kolom untuk analitik operasional real time
Berlaku untuk:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
SQL Server 2016 (13.x) memperkenalkan analitik operasional real time, kemampuan untuk menjalankan beban kerja analitik dan OLTP pada tabel database yang sama secara bersamaan. Selain menjalankan analitik secara real time, Anda juga dapat menghilangkan kebutuhan akan ETL dan gudang data.
Penjelasan analitik operasional real time
Secara tradisional, bisnis telah memiliki sistem terpisah untuk beban kerja operasional (yaitu, OLTP) dan analitik. Untuk pekerjaan sistem tersebut, Ekstrak, Transformasi, dan Muat (ETL) secara teratur memindahkan data dari penyimpanan operasional ke penyimpanan analitik. Data analitik biasanya disimpan di gudang data atau data mart yang didedikasikan untuk menjalankan kueri analitik. Meskipun solusi ini telah menjadi standar, solusi ini memiliki tiga tantangan utama ini:
Kompleksitas. Menerapkan ETL dapat memerlukan pengkodian yang cukup besar terutama untuk memuat hanya baris yang dimodifikasi. Ini bisa kompleks untuk mengidentifikasi baris mana yang telah dimodifikasi.
Biaya. Menerapkan ETL memerlukan biaya pembelian lisensi perangkat keras dan perangkat lunak tambahan.
Latensi Data. Menerapkan ETL menambahkan penundaan waktu untuk menjalankan analitik. Misalnya, jika pekerjaan ETL berjalan di akhir setiap hari kerja, kueri analitik akan berjalan pada data yang setidaknya berusia sehari. Bagi banyak bisnis penundaan ini tidak dapat diterima karena bisnis tergantung pada analisis data secara real time. Misalnya, deteksi penipuan memerlukan analitik real time pada data operasional.
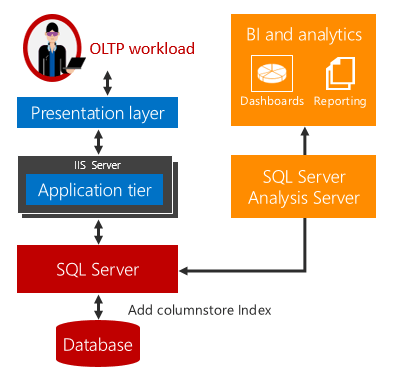
Analitik operasional real time menawarkan solusi untuk tantangan ini.
Tidak ada penundaan waktu ketika analitik dan beban kerja OLTP berjalan pada tabel yang mendasari yang sama. Untuk skenario yang dapat menggunakan analitik real time, biaya dan kompleksitas sangat berkurang dengan menghilangkan kebutuhan akan ETL dan kebutuhan untuk membeli dan memelihara gudang data terpisah.
Catatan
Analitik operasional real time menargetkan skenario sumber data tunggal seperti aplikasi perencanaan sumber daya perusahaan (ERP) tempat Anda dapat menjalankan beban kerja operasional dan analitik. Ini tidak menggantikan kebutuhan akan gudang data terpisah saat Anda perlu mengintegrasikan data dari beberapa sumber sebelum menjalankan beban kerja analitik atau ketika Anda memerlukan performa analitik ekstrem menggunakan data pra-agregat seperti kubus.
Analitik real time menggunakan indeks penyimpan kolom yang dapat diperbarui pada tabel rowstore. Indeks penyimpan kolom mempertahankan salinan data, sehingga beban kerja OLTP dan analitik berjalan terhadap salinan data terpisah. Ini meminimalkan dampak performa kedua beban kerja yang berjalan secara bersamaan. SQL Server secara otomatis mempertahankan perubahan indeks sehingga perubahan OLTP selalu diperbarui untuk analitik. Dengan desain ini, dimungkinkan dan praktis untuk menjalankan analitik secara real time pada data terbaru. Ini berfungsi untuk tabel berbasis disk dan memori yang dioptimalkan.
Contoh Memulai
Untuk mulai menggunakan analitik real-time:
Identifikasi tabel dalam skema operasional Anda yang berisi data yang diperlukan untuk analitik.
Untuk setiap tabel, hilangkan semua indeks pohon B yang terutama dirancang untuk mempercepat analitik yang ada pada beban kerja OLTP Anda. Ganti dengan indeks penyimpan kolom tunggal. Ini dapat meningkatkan performa keseluruhan beban kerja OLTP Anda karena akan ada lebih sedikit indeks yang perlu dipertahankan.
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;Indeks penyimpan kolom pada tabel dalam memori memungkinkan analitik operasional dengan mengintegrasikan teknologi OLTP dalam memori dan columnstore dalam memori untuk memberikan performa tinggi untuk beban kerja OLTP dan analitik. Indeks penyimpan kolom pada tabel dalam memori harus menyertakan semua kolom.
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON ); GO
Anda sekarang siap untuk menjalankan analitik operasional real-time tanpa membuat perubahan apa pun pada aplikasi Anda. Kueri analitik akan berjalan terhadap indeks penyimpan kolom dan operasi OLTP akan terus berjalan terhadap indeks pohon B OLTP Anda. Beban kerja OLTP akan terus berkinerja, tetapi akan menimbulkan beberapa overhead tambahan untuk mempertahankan indeks penyimpan kolom. Lihat pengoptimalan performa di bagian berikutnya.
Catatan
Dokumentasi menggunakan istilah pohon B umumnya dalam referensi ke indeks. Dalam indeks rowstore, Mesin Database mengimplementasikan pohon B+. Ini tidak berlaku untuk indeks penyimpan kolom atau indeks pada tabel yang dioptimalkan memori. Untuk informasi selengkapnya, lihat panduan arsitektur dan desain indeks SQL Server dan Azure SQL.
Posting blog
Baca posting blog berikut untuk mempelajari selengkapnya tentang analitik operasional real time. Mungkin lebih mudah untuk memahami bagian tips performa jika Anda melihat posting blog terlebih dahulu.
Menggunakan indeks penyimpan kolom non-klusster untuk analitik operasional real time
Contoh sederhana menggunakan indeks penyimpan kolom yang tidak terkluster
Cara SQL Server mempertahankan indeks penyimpan kolom non-klusster pada beban kerja transaksional
Analitik operasional real time dengan tabel yang dioptimalkan memori
Indeks penyimpan kolom dan kebijakan penggabungan untuk grup baris
Video
Seri video Data Yang Diekspos ke dalam detail lebih lanjut tentang beberapa kemampuan dan pertimbangan.
- Bagian 1: Cara Azure SQL Mengaktifkan Analitik Operasional Real Time (HTAP)
- Bagian 2: Mengoptimalkan database dan aplikasi yang ada dengan analitik operasional
- Bagian 3: Cara membuat analitik operasional dengan Window Functions.
Tips performa #1: Gunakan indeks yang difilter untuk meningkatkan performa kueri
Menjalankan analitik operasional real time dapat memengaruhi performa beban kerja OLTP. Dampak ini harus minimal. Contoh A menunjukkan cara menggunakan indeks yang difilter untuk meminimalkan dampak indeks penyimpan kolom non-kluster pada beban kerja transaksional sambil tetap mengirimkan analitik secara real time.
Untuk meminimalkan overhead mempertahankan indeks penyimpan kolom non-kluster pada beban kerja operasional, Anda dapat menggunakan kondisi yang difilter untuk membuat indeks penyimpan kolom non-kluster hanya pada data yang hangat atau berubah perlahan. Misalnya, dalam aplikasi manajemen pesanan, Anda dapat membuat indeks penyimpan kolom non-kluster pada pesanan yang telah dikirim. Setelah pesanan dikirim, pesanan jarang berubah dan oleh karena itu dapat dianggap data hangat. Dengan indeks Terfilter, data dalam indeks penyimpan kolom non-kluster memerlukan lebih sedikit pembaruan sehingga menurunkan dampak pada beban kerja transaksional.
Kueri analitik secara transparan mengakses data hangat dan panas sesuai kebutuhan untuk menyediakan analitik real time. Jika bagian penting dari beban kerja operasional menyentuh data 'panas', operasi tersebut tidak akan memerlukan pemeliharaan tambahan indeks penyimpan kolom. Praktik terbaik adalah memiliki indeks berkluster rowstore pada kolom yang digunakan dalam definisi indeks yang difilter. SQL Server menggunakan indeks terkluster untuk memindai baris yang tidak memenuhi kondisi terfilter dengan cepat. Tanpa indeks berkluster ini, pemindaian tabel lengkap tabel rowstore akan diperlukan untuk menemukan baris ini, yang dapat berdampak negatif pada performa kueri analitik secara signifikan. Dengan tidak adanya indeks berkluster, Anda dapat membuat indeks pohon B berkluster yang difilter pelengkap untuk mengidentifikasi baris tersebut tetapi tidak disarankan karena mengakses berbagai baris melalui indeks pohon B non-kluster mahal.
Catatan
Indeks penyimpan kolom non-kluster yang difilter hanya didukung pada tabel berbasis disk. Ini tidak didukung pada tabel yang dioptimalkan memori
Contoh A: Mengakses data panas dari indeks pohon B, data hangat dari indeks penyimpan kolom
Contoh ini menggunakan kondisi yang difilter (accountkey > 0) untuk menetapkan baris mana yang akan berada di indeks penyimpan kolom. Tujuannya adalah untuk merancang kondisi yang difilter dan kueri berikutnya untuk mengakses data "panas" yang sering berubah dari indeks pohon B+, dan untuk mengakses data "hangat" yang lebih stabil dari indeks penyimpan kolom.

Catatan
Pengoptimal Kueri akan mempertimbangkan, tetapi tidak selalu memilih, indeks penyimpan kolom untuk rencana kueri. Saat pengoptimal kueri memilih indeks penyimpan kolom yang difilter, pengoptimal kueri secara transparan menggabungkan baris baik dari indeks penyimpan kolom maupun baris yang tidak memenuhi kondisi yang difilter untuk memungkinkan analitik real time. Ini berbeda dari indeks terfilter berkluster biasa yang hanya dapat digunakan dalam kueri yang membatasi diri mereka ke baris yang ada dalam indeks.
--Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
Customername nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50));
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fullfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
where orderstatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT top 5 customername, sum (PurchasePrice)
FROM orders
WHERE purchaseprice > 100.0
Group By customername;
Kueri analitik akan dijalankan dengan rencana kueri berikut. Anda dapat melihat bahwa baris yang tidak memenuhi kondisi yang difilter diakses melalui indeks pohon B berkluster.

Untuk informasi selengkapnya, lihat Blog: Indeks penyimpan kolom nonclustered yang difilter.
Tips performa #2: Offload analitik ke sekunder yang dapat dibaca AlwaysOn
Meskipun Anda dapat meminimalkan pemeliharaan indeks penyimpan kolom dengan menggunakan indeks penyimpan kolom yang difilter, kueri analitik masih dapat memerlukan sumber daya komputasi yang signifikan (CPU, I/O, memori) yang memengaruhi performa beban kerja operasional. Untuk sebagian besar beban kerja penting misi, rekomendasi kami adalah menggunakan konfigurasi AlwaysOn. Dalam konfigurasi ini, Anda dapat menghilangkan dampak menjalankan analitik dengan membongkarnya ke sekunder yang dapat dibaca.
Tips Performa #3: Mengurangi fragmentasi Indeks dengan menyimpan data panas di grup baris delta
Tabel dengan indeks penyimpan kolom mungkin terfragmentasi secara signifikan (yaitu, baris yang dihapus) jika beban kerja memperbarui/menghapus baris yang telah dikompresi. Indeks penyimpan kolom terfragmentasi menyebabkan pemanfaatan memori/penyimpanan yang tidak efisien. Selain penggunaan sumber daya yang tidak efisien, ini juga berdampak negatif pada performa kueri analitik karena I/O tambahan dan kebutuhan untuk memfilter baris yang dihapus dari kumpulan hasil.
Baris yang dihapus tidak dihapus secara fisik sampai Anda menjalankan defragmentasi indeks dengan REORGANIZE perintah atau membangun kembali indeks penyimpan kolom pada seluruh tabel atau partisi yang terpengaruh. Baik indeks REORGANIZE maupun REBUILD operasi mahal mengambil sumber daya yang sebaliknya dapat digunakan untuk beban kerja. Selain itu, jika baris dikompresi terlalu awal, baris mungkin perlu dikompresi ulang beberapa kali karena pembaruan yang mengarah ke overhead kompresi yang terbuang.
Anda dapat meminimalkan fragmentasi indeks menggunakan COMPRESSION_DELAY opsi.
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY. The columnstore index will keep the rows in closed delta rowgroup for 100 minutes
-- after it has been marked closed
CREATE NONCLUSTERED COLUMNSTORE index t_colstor_cci on t_colstor (accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION= COLUMNSTORE, COMPRESSION_DELAY = 100);
Untuk informasi selengkapnya, lihat Blog: Penundaan pemadatan.
Berikut adalah praktik terbaik yang direkomendasikan:
Beban kerja Sisipkan/Kueri: Jika beban kerja Anda terutama menyisipkan data dan mengkuerinya, COMPRESSION_DELAY default 0 adalah opsi yang direkomendasikan. Baris yang baru disisipkan akan dikompresi setelah 1 juta baris dimasukkan ke dalam satu grup baris delta.
Beberapa contoh beban kerja tersebut adalah (a) analisis select-stream beban kerja DW tradisional (b) saat Anda perlu menganalisis pola pemilihan dalam aplikasi web.Beban kerja OLTP: Jika beban kerja DML berat (yaitu, campuran berat Pembaruan, Hapus dan Sisipkan), Anda mungkin melihat fragmentasi indeks penyimpan kolom dengan memeriksa DMV
sys. dm_db_column_store_row_group_physical_stats. Jika Anda melihat bahwa > 10% baris ditandai dihapus dalam grup baris yang baru saja dikompresi, Anda dapat menggunakan opsi COMPRESSION_DELAY untuk menambahkan penundaan waktu saat baris memenuhi syarat untuk pemadatan. Misalnya, jika untuk beban kerja Anda, tetap 'panas' yang baru disisipkan (yaitu, diperbarui beberapa kali) misalnya 60 menit, Anda harus memilih COMPRESSION_DELAY menjadi 60.
Kami berharap sebagian besar pelanggan tidak perlu melakukan apa pun. Nilai COMPRESSION_DELAY default opsi harus berfungsi untuk mereka.
Untuk pengguna lanjutan, sebaiknya jalankan kueri berikut dan kumpulkan % baris yang dihapus selama tujuh hari terakhir.
SELECT row_group_id,cast(deleted_rows as float)/cast(total_rows as float)*100 as [% fragmented], created_time
FROM sys. dm_db_column_store_row_group_physical_stats
WHERE object_id = object_id('FactOnlineSales2')
AND state_desc='COMPRESSED'
AND deleted_rows>0
AND created_time > GETDATE() - 7
ORDER BY created_time DESC;
Jika jumlah baris yang dihapus dalam grup > baris terkompresi 20%, dataran tinggi di grup baris yang lebih lama dengan < variasi 5% (disebut sebagai grup baris dingin) set COMPRESSION_DELAY = (youngest_rowgroup_created_time - current_time). Pendekatan ini bekerja paling baik dengan beban kerja yang stabil dan relatif homogen.