Timbunan (tabel tanpa indeks berkluster)
Berlaku untuk:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Timbunan adalah tabel tanpa indeks berkluster. Satu atau beberapa indeks nonclustered dapat dibuat pada tabel yang disimpan sebagai timbunan. Data disimpan dalam tumpukan tanpa menentukan pesanan. Biasanya data awalnya disimpan dalam urutan di mana baris disisipkan. Namun, Mesin Database dapat memindahkan data di dalam timbunan untuk menyimpan baris secara efisien. Dalam hasil kueri, urutan data tidak dapat diprediksi. Untuk menjamin urutan baris yang dikembalikan dari timbunan ORDER BY , gunakan klausa . Untuk menentukan urutan logis permanen untuk menyimpan baris, buat indeks berkluster pada tabel, sehingga tabel bukan timbunan.
Catatan
Terkadang ada alasan yang baik untuk meninggalkan tabel sebagai timbunan alih-alih membuat indeks berkluster, tetapi menggunakan timbunan secara efektif adalah keterampilan tingkat lanjut. Sebagian besar tabel harus memiliki indeks berkluster yang dipilih dengan hati-hati kecuali ada alasan yang baik untuk meninggalkan tabel sebagai tumpuk.
Kapan menggunakan timbunan
Tumpukan sangat ideal untuk tabel yang sering dipotong dan dimuat ulang. Mesin database mengoptimalkan ruang dalam timbunan dengan mengisi ruang paling awal yang tersedia.
Pertimbangkan hal berikut:
- Menemukan ruang kosong dalam timbunan bisa mahal, terutama jika telah ada banyak penghapusan atau pembaruan.
- Indeks berkluster menawarkan performa stabil untuk tabel yang tidak sering dipotong.
Untuk tabel yang dipotong atau dibuat ulang secara teratur, seperti tabel sementara atau penahapan, menggunakan tumpukan sering kali lebih efisien.
Pilihan antara menggunakan timbunan dan indeks berkluster dapat secara signifikan memengaruhi performa dan efisiensi database Anda.
Saat tabel disimpan sebagai tumpukan, baris individual diidentifikasi dengan referensi ke pengidentifikasi baris 8 byte (RID) yang terdiri dari nomor file, nomor halaman data, dan slot di halaman (FileID:PageID:SlotID). ID baris adalah struktur kecil dan efisien.
Tumpukan dapat digunakan sebagai tabel penahapan untuk operasi penyisipan besar yang tidak diurutkan. Karena data disisipkan tanpa memberlakukan urutan yang ketat, operasi penyisipan biasanya lebih cepat daripada sisipan yang setara ke dalam indeks berkluster. Jika data timbunan akan dibaca dan diproses ke tujuan akhir, mungkin berguna untuk membuat indeks berkluster sempit yang mencakup predikat pencarian yang digunakan oleh kueri.
Catatan
Data diambil dari tumpukan dalam urutan halaman data, tetapi belum tentu urutan di mana data disisipkan.
Terkadang profesional data juga menggunakan tumpukan ketika data selalu diakses melalui indeks non-kluster, dan RID lebih kecil dari kunci indeks berkluster.
Jika tabel adalah tumpukan dan tidak memiliki indeks non-kluster, maka seluruh tabel harus dibaca (pemindaian tabel) untuk menemukan baris apa pun. SQL Server tidak dapat mencari RID langsung pada heap. Perilaku ini dapat diterima ketika tabel kecil.
Kapan tidak menggunakan timbunan
Jangan gunakan tumpukan saat data sering dikembalikan dalam urutan yang diurutkan. Indeks terkluster pada kolom pengurutan dapat menghindari operasi pengurutan.
Jangan gunakan tumpukan saat data sering dikelompokkan bersama- sama. Data harus diurutkan sebelum dikelompokkan, dan indeks berkluster pada kolom pengurutan dapat menghindari operasi pengurutan.
Jangan gunakan tumpukan saat rentang data sering dikueri dari tabel. Indeks berkluster pada kolom rentang menghindari pengurutan seluruh timbunan.
Jangan gunakan tumpukan ketika tidak ada indeks non-kluster dan tabel besar. Satu-satunya aplikasi untuk desain ini adalah mengembalikan seluruh konten tabel tanpa urutan yang ditentukan. Dalam timbunan, Mesin Database membaca semua baris untuk menemukan baris apa pun.
Jangan gunakan tumpukan jika data sering diperbarui. Jika Anda memperbarui rekaman dan pembaruan menggunakan lebih banyak ruang di halaman data daripada yang digunakan saat ini, rekaman harus dipindahkan ke halaman data yang memiliki ruang kosong yang cukup. Ini membuat rekaman yang diteruskan yang menunjuk ke lokasi baru data, dan penerusan pointer harus ditulis di halaman yang menyimpan data tersebut sebelumnya, untuk menunjukkan lokasi fisik baru. Ini memperkenalkan fragmentasi dalam tumpukan. Ketika Mesin Database memindai tumpukan, database mengikuti penunjuk ini. Tindakan ini membatasi performa read-ahead, dan dapat menimbulkan I/O tambahan yang mengurangi performa pemindaian.
Mengelola timbunan
Untuk membuat timbunan, buat tabel tanpa indeks berkluster. Jika tabel sudah memiliki indeks berkluster, letakkan indeks berkluster untuk mengembalikan tabel ke timbunan.
Untuk menghapus timbunan, buat indeks berkluster pada timbunan.
Untuk membangun kembali tumpukan untuk mengklaim kembali ruang yang terbuang:
- Buat indeks berkluster pada timbunan, lalu hilangkan indeks berkluster tersebut.
ALTER TABLE ... REBUILDGunakan perintah untuk membangun kembali tumpukan.
Peringatan
Membuat atau menghilangkan indeks berkluster memerlukan penulisan ulang seluruh tabel. Jika tabel memiliki indeks non-kluster, semua indeks non-kluster semuanya harus dibuat ulang setiap kali indeks berkluster diubah. Oleh karena itu, mengubah dari tumpukan ke struktur indeks berkluster atau kembali dapat memakan banyak waktu dan memerlukan ruang disk untuk menyusun ulang data dalam tempdb.
Identifikasi timbunan
Kueri berikut mengembalikan daftar timbunan dari database saat ini. Daftar ini meliputi:
- Nama tabel
- Nama skema
- Jumlah baris
- Ukuran tabel dalam KB
- Ukuran indeks dalam KB
- Spasi yang tidak digunakan
- Kolom untuk mengidentifikasi timbunan
SELECT t.name AS 'Your TableName',
s.name AS 'Your SchemaName',
p.rows AS 'Number of Rows in Your Table',
SUM(a.total_pages) * 8 AS 'Total Space of Your Table (KB)',
SUM(a.used_pages) * 8 AS 'Used Space of Your Table (KB)',
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS 'Unused Space of Your Table (KB)',
CASE
WHEN i.index_id = 0
THEN 'Yes'
ELSE 'No'
END AS 'Is Your Table a Heap?'
FROM sys.tables t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id
INNER JOIN sys.partitions p
ON i.object_id = p.object_id
AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a
ON p.partition_id = a.container_id
LEFT JOIN sys.schemas s
ON t.schema_id = s.schema_id
WHERE i.index_id <= 1 -- 0 for Heap, 1 for Clustered Index
GROUP BY t.name,
s.name,
i.index_id,
p.rows
ORDER BY 'Your TableName';
Struktur timbunan
Timbunan adalah tabel tanpa indeks berkluster. Tumpukan memiliki satu baris dalam sys.partitions, dengan index_id = 0 untuk setiap partisi yang digunakan oleh tumpukan. Secara default, tumpukan memiliki satu partisi. Ketika tumpukan memiliki beberapa partisi, setiap partisi memiliki struktur tumpukan yang berisi data untuk partisi tertentu tersebut. Misalnya, jika tumpukan memiliki empat partisi, ada empat struktur tumpukan; satu di setiap partisi.
Bergantung pada jenis data dalam tumpukan, setiap struktur timbunan akan memiliki satu atau beberapa unit alokasi untuk menyimpan dan mengelola data untuk partisi tertentu. Minimal, setiap timbunan akan memiliki satu IN_ROW_DATA unit alokasi per partisi. Timbunan juga akan memiliki satu LOB_DATA unit alokasi per partisi, jika berisi kolom objek besar (LOB). Ini juga akan memiliki satu ROW_OVERFLOW_DATA unit alokasi per partisi, jika berisi kolom panjang variabel yang melebihi batas ukuran baris 8.060 byte.
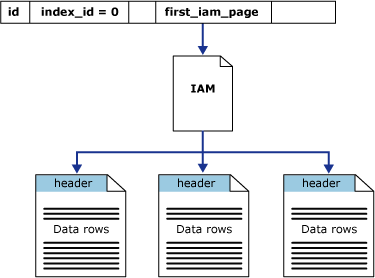
Kolom first_iam_page dalam sys.system_internals_allocation_units tampilan sistem menunjuk ke halaman IAM pertama dalam rantai halaman IAM yang mengelola ruang yang dialokasikan ke timbunan dalam partisi tertentu. SQL Server menggunakan halaman IAM untuk berpindah melalui timbunan. Halaman data dan baris di dalamnya tidak dalam urutan tertentu dan tidak ditautkan. Satu-satunya koneksi logis antara halaman data adalah informasi yang direkam di halaman IAM.
Penting
Tampilan sys.system_internals_allocation_units sistem hanya dicadangkan untuk penggunaan internal SQL Server. Kompatibilitas di masa mendatang tidak dijamin.
Pemindaian tabel atau pembacaan serial tumpukan dapat dilakukan dengan memindai halaman IAM untuk menemukan sejauh mana halaman yang disimpan untuk tumpukan. Karena IAM mewakili tingkat dalam urutan yang sama dengan yang ada dalam file data, ini berarti bahwa timbunan serial memindai kemajuan secara berurutan melalui setiap file. Menggunakan halaman IAM untuk mengatur urutan pemindaian juga berarti bahwa baris dari tumpukan biasanya tidak dikembalikan dalam urutan di mana baris tersebut dimasukkan.
Ilustrasi berikut menunjukkan bagaimana Mesin Database SQL Server menggunakan halaman IAM untuk mengambil baris data dalam satu tumpukan partisi.
Konten Terkait
BUAT INDEKS (Transact-SQL)
DROP INDEX (Transact-SQL)
Indeks Terkluster dan Non-Kluster Dijelaskan