Panduan arsitektur pemrosesan kueri
Berlaku untuk:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Mesin Database SQL Server memproses kueri pada berbagai arsitektur penyimpanan data seperti tabel lokal, tabel yang dipartisi, dan tabel yang didistribusikan di beberapa server. Bagian berikut mencakup cara SQL Server memproses kueri dan mengoptimalkan penggunaan kembali kueri melalui penembolokan rencana eksekusi.
Mode eksekusi
Mesin Database SQL Server dapat memproses pernyataan Transact-SQL menggunakan dua mode pemrosesan yang berbeda:
- Eksekusi mode baris
- Eksekusi mode batch
Eksekusi mode baris
Eksekusi mode baris adalah metode pemrosesan kueri yang digunakan dengan tabel RDBMS tradisional, di mana data disimpan dalam format baris. Saat kueri dijalankan dan mengakses data dalam tabel penyimpanan baris, operator pohon eksekusi dan operator anak membaca setiap baris yang diperlukan, di semua kolom yang ditentukan dalam skema tabel. Dari setiap baris yang dibaca, SQL Server kemudian mengambil kolom yang diperlukan untuk kumpulan hasil, seperti yang dirujuk oleh pernyataan SELECT, predikat JOIN, atau predikat filter.
Catatan
Eksekusi mode baris sangat efisien untuk skenario OLTP, tetapi bisa kurang efisien saat memindai data dalam jumlah besar, misalnya dalam skenario Pergudangan Data.
Eksekusi mode batch
Eksekusi mode batch adalah metode pemrosesan kueri yang digunakan untuk memproses beberapa baris bersama-sama (karenanya istilah batch). Setiap kolom dalam batch disimpan sebagai vektor di area memori terpisah, sehingga pemrosesan mode batch berbasis vektor. Pemrosesan mode batch juga menggunakan algoritma yang dioptimalkan untuk CPU multi-core dan peningkatan throughput memori yang ditemukan pada perangkat keras modern.
Ketika pertama kali diperkenalkan, eksekusi mode batch terintegrasi erat dengan, dan dioptimalkan di sekitar, format penyimpanan penyimpan kolom. Namun, dimulai dengan SQL Server 2019 (15.x) dan di Azure SQL Database, eksekusi mode batch tidak lagi memerlukan indeks penyimpan kolom. Untuk informasi selengkapnya, lihat Mode batch di rowstore.
Pemrosesan mode batch beroperasi pada data terkompresi jika memungkinkan, dan menghilangkan operator pertukaran yang digunakan oleh eksekusi mode baris. Hasilnya adalah paralelisme yang lebih baik dan performa yang lebih cepat.
Saat kueri dijalankan dalam mode batch, dan mengakses data dalam indeks penyimpan kolom, operator pohon eksekusi dan operator anak membaca beberapa baris bersama-sama dalam segmen kolom. SQL Server hanya membaca kolom yang diperlukan untuk hasilnya, seperti yang dirujuk oleh pernyataan SELECT, predikat JOIN, atau predikat filter. Untuk informasi selengkapnya tentang indeks penyimpan kolom, lihat Arsitektur Indeks Penyimpan Kolom.
Catatan
Eksekusi mode batch adalah skenario Pergudangan Data yang sangat efisien, di mana sejumlah besar data dibaca dan dikumpulkan.
Pemrosesan pernyataan SQL
Memproses satu pernyataan Transact-SQL adalah cara paling dasar SQL Server menjalankan pernyataan Transact-SQL. Langkah-langkah yang digunakan untuk memproses satu SELECT pernyataan yang hanya mereferensikan tabel dasar lokal (tanpa tampilan atau tabel jarak jauh) yang mengilustrasikan proses dasar.
Prioritas operator logis
Ketika lebih dari satu operator logis digunakan dalam pernyataan, NOT dievaluasi terlebih dahulu, lalu AND, dan akhirnya OR. Aritmatika, dan bitwise, operator ditangani sebelum operator logis. Untuk informasi selengkapnya, lihat Prioritas Operator.
Dalam contoh berikut, kondisi warna berkaitan dengan model produk 21, dan bukan untuk model produk 20, karena AND lebih diutamakan daripada OR.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
Anda bisa mengubah arti kueri dengan menambahkan tanda kurung untuk memaksa evaluasi yang OR pertama. Kueri berikut hanya menemukan produk di bawah model 20 dan 21 yang berwarna merah.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
Menggunakan tanda kurung, bahkan ketika tidak diperlukan, dapat meningkatkan keterbacaan kueri, dan mengurangi kemungkinan membuat kesalahan halus karena prioritas operator. Tidak ada penalti performa yang signifikan dalam menggunakan tanda kurung. Contoh berikut lebih mudah dibaca daripada contoh aslinya, meskipun secara sintis sama.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
Mengoptimalkan pernyataan SELECT
Pernyataan SELECT tidak prosedural; pernyataan tidak menyatakan langkah-langkah tepat yang harus digunakan server database untuk mengambil data yang diminta. Ini berarti bahwa server database harus menganalisis pernyataan untuk menentukan cara paling efisien untuk mengekstrak data yang diminta. Ini disebut sebagai mengoptimalkan SELECT pernyataan. Komponen yang melakukan ini, disebut Pengoptimal Kueri. Input ke Pengoptimal Kueri terdiri dari kueri, skema database (definisi tabel dan indeks), dan statistik database. Output Pengoptimal Kueri adalah rencana eksekusi kueri, terkadang disebut sebagai rencana kueri, atau rencana eksekusi. Konten rencana eksekusi dijelaskan secara lebih rinci nanti dalam artikel ini.
Input dan output Pengoptimal Kueri selama pengoptimalan satu SELECT pernyataan diilustrasikan dalam diagram berikut:
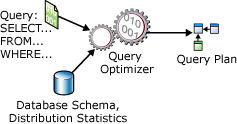
Pernyataan SELECT hanya mendefinisikan yang berikut:
- Format kumpulan hasil. Ini sebagian besar ditentukan dalam daftar pilih. Namun, klausul lain seperti
ORDER BYdanGROUP BYjuga memengaruhi bentuk akhir dari tataan hasil. - Tabel yang berisi data sumber. Ini ditentukan dalam
FROMklausa. - Bagaimana tabel terkait secara logis untuk tujuan
SELECTpernyataan. Ini didefinisikan dalam spesifikasi gabungan, yang mungkin muncul dalamWHEREklausa atau dalamONklausul berikutFROM. - Kondisi yang harus dipenuhi baris dalam tabel sumber untuk memenuhi syarat untuk pernyataan tersebut
SELECT. Ini ditentukan dalamWHEREklausa danHAVING.
Rencana eksekusi kueri adalah definisi dari yang berikut ini:
Urutan di mana tabel sumber diakses.
Biasanya, ada banyak urutan di mana server database dapat mengakses tabel dasar untuk membangun tataan hasil. Misalnya, jika pernyataan mereferensikanSELECTtiga tabel, server database dapat terlebih dahulu mengaksesTableA, gunakan data dariTableAuntuk mengekstrak baris yang cocok dariTableB, lalu menggunakan data dariTableBuntuk mengekstrak data dariTableC. Urutan lain di mana server database dapat mengakses tabel adalah:
TableC, ,TableBTableA, atau
TableB, ,TableATableC, atau
TableB, ,TableCTableA, atau
TableC, ,TableATableBMetode yang digunakan untuk mengekstrak data dari setiap tabel.
Umumnya, ada berbagai metode untuk mengakses data di setiap tabel. Jika hanya beberapa baris dengan nilai kunci tertentu yang diperlukan, server database dapat menggunakan indeks. Jika semua baris dalam tabel diperlukan, server database dapat mengabaikan indeks dan melakukan pemindaian tabel. Jika semua baris dalam tabel diperlukan tetapi ada indeks yang kolom kuncinya berada diORDER BY, melakukan pemindaian indeks alih-alih pemindaian tabel mungkin menyimpan semacam kumpulan hasil yang terpisah. Jika tabel sangat kecil, pemindaian tabel mungkin merupakan metode yang paling efisien untuk hampir semua akses ke tabel.Metode yang digunakan untuk menghitung perhitungan, dan cara memfilter, mengagregasi, dan mengurutkan data dari setiap tabel.
Saat data diakses dari tabel, ada berbagai metode untuk melakukan penghitungan atas data seperti menghitung nilai skalar, dan untuk menggabungkan dan mengurutkan data seperti yang ditentukan dalam teks kueri, misalnya saat menggunakanGROUP BYklausa atauORDER BY, dan cara memfilter data, misalnya saat menggunakanWHEREklausa atauHAVING.
Proses memilih satu rencana eksekusi dari kemungkinan banyak kemungkinan rencana disebut sebagai pengoptimalan. Pengoptimal Kueri adalah salah satu komponen terpenting dari Mesin Database. Meskipun beberapa overhead digunakan oleh Pengoptimal Kueri untuk menganalisis kueri dan memilih paket, overhead ini biasanya disimpan beberapa kali lipat saat Pengoptimal Kueri memilih rencana eksekusi yang efisien. Misalnya, dua perusahaan konstruksi dapat diberikan cetak biru yang identik untuk sebuah rumah. Jika satu perusahaan menghabiskan beberapa hari di awal untuk merencanakan bagaimana mereka akan membangun rumah, dan perusahaan lain mulai membangun tanpa perencanaan, perusahaan yang membutuhkan waktu untuk merencanakan proyek mereka mungkin akan selesai terlebih dahulu.
Pengoptimal Kueri SQL Server adalah pengoptimal berbasis biaya. Setiap kemungkinan rencana eksekusi memiliki biaya terkait dalam hal jumlah sumber daya komputasi yang digunakan. Pengoptimal Kueri harus menganalisis rencana yang mungkin dan memilih paket dengan perkiraan biaya terendah. Beberapa pernyataan kompleks SELECT memiliki ribuan kemungkinan rencana eksekusi. Dalam kasus ini, Pengoptimal Kueri tidak menganalisis semua kemungkinan kombinasi. Sebaliknya, ia menggunakan algoritma kompleks untuk menemukan rencana eksekusi yang memiliki biaya yang cukup dekat dengan biaya minimum yang mungkin.
Pengoptimal Kueri SQL Server tidak hanya memilih rencana eksekusi dengan biaya sumber daya terendah; ini memilih paket yang mengembalikan hasil kepada pengguna dengan biaya yang wajar dalam sumber daya dan yang mengembalikan hasil tercepat. Misalnya, memproses kueri secara paralel biasanya menggunakan lebih banyak sumber daya daripada memprosesnya secara serial, tetapi menyelesaikan kueri lebih cepat. Pengoptimal Kueri SQL Server akan menggunakan rencana eksekusi paralel untuk mengembalikan hasil jika beban di server tidak akan terpengaruh secara merugikan.
Pengoptimal Kueri SQL Server bergantung pada statistik distribusi ketika memperkirakan biaya sumber daya dari metode yang berbeda untuk mengekstrak informasi dari tabel atau indeks. Statistik distribusi disimpan untuk kolom dan indeks, dan menyimpan informasi tentang kepadatan 1 data yang mendasar. Ini digunakan untuk menunjukkan selektivitas nilai dalam indeks atau kolom tertentu. Misalnya, dalam tabel yang mewakili mobil, banyak mobil memiliki produsen yang sama, tetapi setiap mobil memiliki nomor identifikasi kendaraan (VIN) yang unik. Indeks pada VIN lebih selektif daripada indeks pada produsen, karena VIN memiliki kepadatan yang lebih rendah daripada produsen. Jika statistik indeks tidak terkini, Pengoptimal Kueri mungkin tidak membuat pilihan terbaik untuk status tabel saat ini. Untuk informasi selengkapnya tentang kepadatan, lihat Statistik.
1 Kepadatan mendefinisikan distribusi nilai unik yang ada dalam data, atau jumlah rata-rata nilai duplikat untuk kolom tertentu. Saat kepadatan menurun, selektivitas nilai meningkat.
Pengoptimal Kueri SQL Server penting karena memungkinkan server database untuk menyesuaikan secara dinamis dengan perubahan kondisi dalam database tanpa memerlukan input dari administrator programmer atau database. Ini memungkinkan programmer untuk fokus pada menggambarkan hasil akhir kueri. Mereka dapat mempercayai bahwa Pengoptimal Kueri SQL Server akan membangun rencana eksekusi yang efisien untuk status database setiap kali pernyataan dijalankan.
Catatan
SQL Server Management Studio memiliki tiga opsi untuk menampilkan rencana eksekusi:
- Perkiraan Rencana Eksekusi, yang merupakan rencana yang dikompilasi, seperti yang dihasilkan oleh Pengoptimal Kueri.
- Rencana Eksekusi Aktual, yang sama dengan rencana yang dikompilasi ditambah konteks eksekusinya. Ini termasuk informasi runtime yang tersedia setelah eksekusi selesai, seperti peringatan eksekusi, atau dalam versi Mesin Database yang lebih baru, waktu yang berlalu dan CPU yang digunakan selama eksekusi.
- Statistik Kueri Langsung, yang sama dengan rencana yang dikompilasi ditambah konteks eksekusinya. Ini termasuk informasi runtime selama kemajuan eksekusi, dan diperbarui setiap detik. Informasi runtime termasuk misalnya jumlah baris aktual yang mengalir melalui operator.
Memproses pernyataan SELECT
Langkah-langkah dasar yang digunakan SQL Server untuk memproses satu pernyataan SELECT meliputi yang berikut ini:
- Pengurai memindai
SELECTpernyataan dan memecahnya menjadi unit logis seperti kata kunci, ekspresi, operator, dan pengidentifikasi. - Pohon kueri, kadang-kadang disebut sebagai pohon urutan, dibangun yang menjelaskan langkah-langkah logis yang diperlukan untuk mengubah data sumber menjadi format yang diperlukan oleh kumpulan hasil.
- Pengoptimal Kueri menganalisis berbagai cara tabel sumber dapat diakses. Kemudian memilih serangkaian langkah yang mengembalikan hasil tercepat saat menggunakan lebih sedikit sumber daya. Pohon kueri diperbarui untuk merekam rangkaian langkah yang tepat ini. Versi akhir yang dioptimalkan dari pohon kueri disebut rencana eksekusi.
- Mesin relasional mulai menjalankan rencana eksekusi. Karena langkah-langkah yang memerlukan data dari tabel dasar diproses, mesin relasional meminta agar mesin penyimpanan meneruskan data dari set baris yang diminta dari mesin relasional.
- Mesin relasional memproses data yang dikembalikan dari mesin penyimpanan ke dalam format yang ditentukan untuk tataan hasil dan mengembalikan hasil yang diatur ke klien.
Lipatan konstanta dan evaluasi ekspresi
SQL Server mengevaluasi beberapa ekspresi konstanta lebih awal untuk meningkatkan performa kueri. Ini disebut sebagai pelipatan konstanta. Konstanta adalah literal Transact-SQL, seperti 3, , '2005-12-31''ABC', 1.0e3, atau 0x12345678.
Ekspresi yang dapat dilipat
SQL Server menggunakan pelipatan konstanta dengan jenis ekspresi berikut:
- Ekspresi aritmatika, seperti
1 + 1dan5 / 3 * 2, yang hanya berisi konstanta. - Ekspresi logis, seperti
1 = 1dan1 > 2 AND 3 > 4, yang hanya berisi konstanta. - Fungsi bawaan yang dianggap dapat dilipat oleh SQL Server, termasuk
CASTdanCONVERT. Umumnya, fungsi intrinsik dapat dilipat jika fungsi inputnya saja dan bukan informasi kontekstual lainnya, seperti opsi SET, pengaturan bahasa, opsi database, dan kunci enkripsi. Fungsi nondeterministik tidak dapat dilipat. Fungsi bawaan deterministik dapat dilipat, dengan beberapa pengecualian. - Metode deterministik dari jenis yang ditentukan pengguna CLR dan fungsi yang ditentukan pengguna CLR bernilai skalar deterministik (dimulai dengan SQL Server 2012 (11.x)). Untuk informasi selengkapnya, lihat Lipatan Konstan untuk Fungsi dan Metode yang Ditentukan Pengguna CLR.
Catatan
Pengecualian dibuat untuk jenis objek besar. Jika jenis output dari proses lipatan adalah jenis objek besar (teks,ntext, gambar, nvarchar(max), varchar(max), varbinary(max), atau XML), maka SQL Server tidak melipat ekspresi.
Ekspresi yang tidak dapat dilipat
Semua jenis ekspresi lainnya tidak dapat dilipat. Secara khusus, jenis ekspresi berikut tidak dapat dilipat:
- Ekspresi nonkonstant seperti ekspresi yang hasilnya bergantung pada nilai kolom.
- Ekspresi yang hasilnya bergantung pada variabel atau parameter lokal, seperti @x.
- Fungsi nondeterministik.
- Fungsi Transact-SQL yangditentukan pengguna 1.
- Ekspresi yang hasilnya bergantung pada pengaturan bahasa.
- Ekspresi yang hasilnya bergantung pada opsi SET.
- Ekspresi yang hasilnya bergantung pada opsi konfigurasi server.
1 Sebelum SQL Server 2012 (11.x), fungsi yang ditentukan pengguna CLR bernilai skalar deterministik dan metode jenis yang ditentukan pengguna CLR tidak dapat dilipat.
Contoh ekspresi konstanta yang dapat dilipat dan tidak dapat dilipat
Pertimbangkan kueri berikut:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
PARAMETERIZATION Jika opsi database tidak diatur ke FORCED untuk kueri ini, maka ekspresi 117.00 + 1000.00 dievaluasi dan digantikan oleh hasilnya, 1117.00, sebelum kueri dikompilasi. Manfaat dari pelipatan konstanta ini meliputi yang berikut:
- Ekspresi tidak harus dievaluasi berulang kali pada waktu proses.
- Nilai ekspresi setelah dievaluasi digunakan oleh Pengoptimal Kueri untuk memperkirakan ukuran kumpulan hasil dari bagian kueri
TotalDue > 117.00 + 1000.00.
Di sisi lain, jika dbo.f adalah fungsi skalar yang ditentukan pengguna, ekspresi dbo.f(100) tidak dilipat, karena SQL Server tidak melipat ekspresi yang melibatkan fungsi yang ditentukan pengguna, bahkan jika mereka deterministik. Untuk informasi selengkapnya tentang parameterisasi, lihat Parameterisasi Paksa nanti di artikel ini.
Evaluasi ekspresi
Selain itu, beberapa ekspresi yang tidak konstanta dilipat tetapi argumennya diketahui pada waktu kompilasi, apakah argumen adalah parameter atau konstanta, dievaluasi oleh estimator ukuran (kardinalitas) yang merupakan bagian dari pengoptimal selama pengoptimalan.
Secara khusus, fungsi bawaan dan operator khusus berikut dievaluasi pada waktu kompilasi jika semua input mereka diketahui: UPPER, , LOWER, DATEPART( YY only )RTRIM, , GETDATE, CAST, dan CONVERT. Operator berikut juga dievaluasi pada waktu kompilasi jika semua input mereka diketahui:
- Operator aritmatika: +, -, *, /, unary -
- Operator Logis:
AND,OR,NOT - Operator perbandingan: <, , >= <, >=, <>,
LIKE,IS NULL,IS NOT NULL
Tidak ada fungsi atau operator lain yang dievaluasi oleh Pengoptimal Kueri selama estimasi kardinalitas.
Contoh evaluasi ekspresi waktu kompilasi
Pertimbangkan prosedur tersimpan ini:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Selama pengoptimalan SELECT pernyataan dalam prosedur, Pengoptimal Kueri mencoba mengevaluasi kardinalitas yang diharapkan dari hasil yang ditetapkan untuk kondisi OrderDate > @d+1. Ekspresi @d+1 tidak dilipat secara konstan, karena @d merupakan parameter. Namun, pada waktu pengoptimalan, nilai parameter diketahui. Ini memungkinkan Pengoptimal Kueri memperkirakan ukuran kumpulan hasil secara akurat, yang membantunya memilih rencana kueri yang baik.
Sekarang pertimbangkan contoh yang mirip dengan yang sebelumnya, kecuali bahwa variabel @d2 lokal diganti @d+1 dalam kueri dan ekspresi dievaluasi dalam pernyataan SET alih-alih dalam kueri.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
SELECT Ketika pernyataan di dioptimalkan MyProc2 di SQL Server, nilai @d2 tidak diketahui. Oleh karena itu, Pengoptimal Kueri menggunakan perkiraan default untuk pemilihan OrderDate > @d2, (dalam hal ini 30 persen).
Memproses pernyataan lain
Langkah-langkah dasar yang SELECT dijelaskan untuk memproses pernyataan berlaku untuk pernyataan Transact-SQL lainnya seperti INSERT, , UPDATEdan DELETE. UPDATE dan DELETE pernyataan keduanya harus menargetkan kumpulan baris yang akan dimodifikasi atau dihapus. Proses mengidentifikasi baris ini adalah proses yang sama yang digunakan untuk mengidentifikasi baris sumber yang berkontribusi pada kumpulan SELECT hasil pernyataan. Pernyataan UPDATE dan INSERT mungkin berisi pernyataan tersemat SELECT yang menyediakan nilai data yang akan diperbarui atau disisipkan.
Bahkan pernyataan Data Definition Language (DDL), seperti CREATE PROCEDURE atau ALTER TABLE, pada akhirnya diselesaikan ke serangkaian operasi relasional pada tabel katalog sistem dan terkadang (seperti ALTER TABLE ADD COLUMN) terhadap tabel data.
Worktables
Mesin Relasional mungkin perlu membangun worktable untuk melakukan operasi logis yang ditentukan dalam pernyataan Transact-SQL. Worktables adalah tabel internal yang digunakan untuk menyimpan hasil perantara. Worktables dihasilkan untuk kueri , , ORDER BYatau UNION tertentuGROUP BY. Misalnya, jika ORDER BY klausul mereferensikan kolom yang tidak dicakup oleh indeks apa pun, Mesin Relasional mungkin perlu menghasilkan worktable untuk mengurutkan hasil yang diatur ke dalam urutan yang diminta. Worktable juga terkadang digunakan sebagai penampung yang menahan sementara hasil menjalankan bagian dari rencana kueri. Worktables dibangun dan dihilangkan tempdb secara otomatis ketika tidak lagi diperlukan.
Lihat resolusi
Prosesor kueri SQL Server memperlakukan tampilan terindeks dan nonindeks secara berbeda:
- Baris tampilan terindeks disimpan dalam database dalam format yang sama dengan tabel. Jika Pengoptimal Kueri memutuskan untuk menggunakan tampilan terindeks dalam rencana kueri, tampilan terindeks diperlakukan dengan cara yang sama seperti tabel dasar.
- Hanya definisi tampilan yang tidak terindeks yang disimpan, bukan baris tampilan. Pengoptimal Kueri menggabungkan logika dari definisi tampilan ke dalam rencana eksekusi yang dibuatnya untuk pernyataan Transact-SQL yang mereferensikan tampilan yang tidak diindeks.
Logika yang digunakan oleh Pengoptimal Kueri SQL Server untuk memutuskan kapan menggunakan tampilan terindeks mirip dengan logika yang digunakan untuk memutuskan kapan menggunakan indeks pada tabel. Jika data dalam tampilan terindeks mencakup semua atau sebagian pernyataan Transact-SQL, dan Pengoptimal Kueri menentukan bahwa indeks pada tampilan adalah jalur akses bernilai rendah, Pengoptimal Kueri akan memilih indeks terlepas dari apakah tampilan direferensikan berdasarkan nama dalam kueri.
Ketika pernyataan Transact-SQL mereferensikan tampilan nonindexed, pengurai dan Pengoptimal Kueri menganalisis sumber pernyataan Transact-SQL dan tampilan lalu menyelesaikannya menjadi satu rencana eksekusi. Tidak ada satu paket untuk pernyataan Transact-SQL dan paket terpisah untuk tampilan.
Misalnya, pertimbangkan tampilan berikut:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
Berdasarkan tampilan ini, kedua pernyataan Transact-SQL ini melakukan operasi yang sama pada tabel dasar dan menghasilkan hasil yang sama:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
Fitur SQL Server Management Studio Showplan menunjukkan bahwa mesin relasional membangun rencana eksekusi yang sama untuk kedua pernyataan ini SELECT .
Menggunakan petunjuk dengan tampilan
Petunjuk yang ditempatkan pada tampilan dalam kueri mungkin bertentangan dengan petunjuk lain yang ditemukan saat tampilan diperluas untuk mengakses tabel dasarnya. Ketika ini terjadi, kueri mengembalikan kesalahan. Misalnya, pertimbangkan tampilan berikut yang berisi petunjuk tabel dalam definisinya:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Sekarang misalkan Anda memasukkan kueri ini:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
Kueri gagal, karena petunjuk SERIALIZABLE yang diterapkan pada tampilan Person.AddrState dalam kueri disebarluaskan ke tabel Person.Address dan Person.StateProvince dalam tampilan saat diperluas. Namun, memperluas tampilan juga mengungkapkan NOLOCK petunjuk tentang Person.Address. SERIALIZABLE Karena konflik petunjuk dan NOLOCK , kueri yang dihasilkan salah.
PAGLOCKPetunjuk tabel , , ROWLOCKNOLOCK, TABLOCKatau TABLOCKX bertentangan satu sama lain, seperti halnya HOLDLOCKpetunjuk tabel , , READCOMMITTEDNOLOCK, REPEATABLEREAD. SERIALIZABLE
Petunjuk dapat menyebar melalui tingkat tampilan berlapis. Misalnya, kueri menerapkan HOLDLOCK petunjuk pada tampilan v1. Ketika v1 diperluas, kami menemukan bahwa tampilan v2 adalah bagian dari definisinya. v2Definisi mencakup NOLOCK petunjuk pada salah satu tabel dasarnya. Tetapi tabel ini juga mewarisi HOLDLOCK petunjuk dari kueri pada tampilan v1. NOLOCK Karena konflik petunjuk dan HOLDLOCK , kueri gagal.
FORCE ORDER Saat petunjuk digunakan dalam kueri yang berisi tampilan, urutan gabungan tabel dalam tampilan ditentukan oleh posisi tampilan dalam konstruksi yang diurutkan. Misalnya, kueri berikut memilih dari tiga tabel dan tampilan:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
Dan View1 didefinisikan seperti yang ditunjukkan dalam hal berikut:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
Urutan gabungan dalam rencana kueri adalah Table1, , Table2, TableATableB, Table3.
Mengatasi indeks pada tampilan
Seperti halnya indeks apa pun, SQL Server memilih untuk menggunakan tampilan terindeks dalam rencana kuerinya hanya jika Pengoptimal Kueri menentukan bermanfaat untuk melakukannya.
Tampilan terindeks dapat dibuat dalam edisi SQL Server apa pun. Dalam beberapa edisi beberapa versi SQL Server yang lebih lama, Pengoptimal Kueri secara otomatis mempertimbangkan tampilan terindeks. Dalam beberapa edisi beberapa versi SQL Server yang lebih lama, untuk menggunakan tampilan terindeks, NOEXPAND petunjuk tabel harus digunakan. Sebelum SQL Server 2016 (13.x) Paket Layanan 1, penggunaan otomatis tampilan terindeks oleh pengoptimal kueri hanya didukung dalam edisi SQL Server tertentu. Karena, semua edisi mendukung penggunaan otomatis tampilan terindeks. Azure SQL Database dan Azure SQL Managed Instance juga mendukung penggunaan otomatis tampilan terindeks tanpa menentukan NOEXPAND petunjuk.
Pengoptimal Kueri SQL Server menggunakan tampilan terindeks saat kondisi berikut terpenuhi:
- Opsi sesi ini diatur ke
ON:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- Opsi
NUMERIC_ROUNDABORTsesi diatur ke NONAKTIF. - Pengoptimal Kueri menemukan kecocokan antara kolom indeks tampilan dan elemen dalam kueri, seperti berikut ini:
- Predikat kondisi pencarian dalam klausa WHERE
- Gabungkan operasi
- Fungsi agregat
GROUP BYKlausul- Referensi tabel
- Perkiraan biaya untuk menggunakan indeks memiliki biaya terendah dari mekanisme akses apa pun yang dipertimbangkan oleh Pengoptimal Kueri.
- Setiap tabel yang direferensikan dalam kueri (baik secara langsung, atau dengan memperluas tampilan untuk mengakses tabel yang mendasar) yang sesuai dengan referensi tabel dalam tampilan terindeks harus memiliki kumpulan petunjuk yang sama yang diterapkan di dalam kueri.
Catatan
Petunjuk READCOMMITTED dan READCOMMITTEDLOCK selalu dianggap sebagai petunjuk yang berbeda dalam konteks ini, terlepas dari tingkat isolasi transaksi saat ini.
Selain persyaratan untuk SET opsi dan petunjuk tabel, ini adalah aturan yang sama dengan yang digunakan Pengoptimal Kueri untuk menentukan apakah indeks tabel mencakup kueri. Tidak ada lagi yang harus ditentukan dalam kueri untuk tampilan terindeks yang akan digunakan.
Kueri tidak harus secara eksplisit mereferensikan tampilan terindeks dalam FROM klausa untuk Pengoptimal Kueri untuk menggunakan tampilan terindeks. Jika kueri berisi referensi ke kolom dalam tabel dasar yang juga ada dalam tampilan terindeks, dan Pengoptimal Kueri memperkirakan bahwa menggunakan tampilan terindeks menyediakan mekanisme akses biaya terendah, Pengoptimal Kueri memilih tampilan terindeks, mirip dengan cara memilih indeks tabel dasar saat tidak direferensikan secara langsung dalam kueri. Pengoptimal Kueri bisa memilih tampilan saat berisi kolom yang tidak dirujuk oleh kueri, selama tampilan menawarkan opsi biaya terendah untuk mencakup satu atau beberapa kolom yang ditentukan dalam kueri.
Pengoptimal Kueri memperlakukan tampilan terindeks yang direferensikan dalam FROM klausa sebagai tampilan standar. Pengoptimal Kueri memperluas definisi tampilan ke dalam kueri di awal proses pengoptimalan. Kemudian, pencocokan tampilan terindeks dilakukan. Tampilan terindeks dapat digunakan dalam rencana eksekusi akhir yang dipilih oleh Pengoptimal Kueri, atau sebagai gantinya, paket mungkin mewujudkan data yang diperlukan dari tampilan dengan mengakses tabel dasar yang direferensikan oleh tampilan. Pengoptimal Kueri memilih alternatif dengan biaya terendah.
Menggunakan petunjuk dengan tampilan terindeks
Anda bisa mencegah indeks tampilan digunakan untuk kueri dengan menggunakan EXPAND VIEWS petunjuk kueri, atau Anda bisa menggunakan NOEXPAND petunjuk tabel untuk memaksa penggunaan indeks untuk tampilan terindeks yang ditentukan dalam FROM klausul kueri. Namun, Anda harus membiarkan Pengoptimal Kueri secara dinamis menentukan metode akses terbaik untuk digunakan untuk setiap kueri. Batasi penggunaan EXPAND Anda dan NOEXPAND untuk kasus tertentu di mana pengujian telah menunjukkan bahwa pengujian tersebut meningkatkan performa secara signifikan.
Opsi
EXPAND VIEWSmenentukan bahwa Pengoptimal Kueri tidak menggunakan indeks tampilan apa pun untuk seluruh kueri.Ketika
NOEXPANDditentukan untuk tampilan, Pengoptimal Kueri mempertimbangkan untuk menggunakan indeks apa pun yang ditentukan pada tampilan.NOEXPANDditentukan dengan klausul opsional memaksa PengoptimalINDEX()Kueri untuk menggunakan indeks yang ditentukan.NOEXPANDhanya dapat ditentukan untuk tampilan terindeks dan tidak dapat ditentukan untuk tampilan yang tidak diindeks. Sebelum SQL Server 2016 (13.x) Paket Layanan 1, penggunaan otomatis tampilan terindeks oleh pengoptimal kueri hanya didukung dalam edisi SQL Server tertentu. Karena, semua edisi mendukung penggunaan otomatis tampilan terindeks. Azure SQL Database dan Azure SQL Managed Instance juga mendukung penggunaan otomatis tampilan terindeks tanpa menentukanNOEXPANDpetunjuk.
Ketika tidak NOEXPAND atau EXPAND VIEWS ditentukan dalam kueri yang berisi tampilan, tampilan diperluas untuk mengakses tabel yang mendasar. Jika kueri yang membentuk tampilan berisi petunjuk tabel apa pun, petunjuk ini disebarkan ke tabel yang mendasar. (Proses ini dijelaskan secara lebih rinci dalam Lihat Resolusi.) Selama kumpulan petunjuk yang ada pada tabel tampilan yang mendasar identik satu sama lain, kueri memenuhi syarat untuk dicocokkan dengan tampilan terindeks. Sebagian besar waktu, petunjuk ini akan cocok satu sama lain, karena mereka diwariskan langsung dari tampilan. Namun, jika kueri mereferensikan tabel alih-alih tampilan, dan petunjuk yang diterapkan langsung pada tabel ini tidak identik, kueri seperti itu tidak memenuhi syarat untuk pencocokan dengan tampilan terindeks. INDEXJika petunjuk , , ROWLOCKPAGLOCK, TABLOCKXUPDLOCK, , atau XLOCK berlaku untuk tabel yang direferensikan dalam kueri setelah ekspansi tampilan, kueri tidak memenuhi syarat untuk pencocokan tampilan terindeks.
Jika petunjuk tabel dalam bentuk INDEX (index_val[ ,...n] ) referensi tampilan dalam kueri dan Anda tidak juga menentukan NOEXPAND petunjuk, petunjuk indeks diabaikan. Untuk menentukan penggunaan indeks tertentu, gunakan NOEXPAND.
Umumnya, ketika Pengoptimal Kueri cocok dengan tampilan terindeks ke kueri, petunjuk apa pun yang ditentukan pada tabel atau tampilan dalam kueri diterapkan langsung ke tampilan terindeks. Jika Pengoptimal Kueri memilih untuk tidak menggunakan tampilan terindeks, petunjuk apa pun disebarluaskan langsung ke tabel yang direferensikan dalam tampilan. Untuk informasi selengkapnya, lihat Lihat Resolusi. Penyebaran ini tidak berlaku untuk menggabungkan petunjuk. Mereka hanya diterapkan di posisi aslinya dalam kueri. Petunjuk gabungan tidak dipertimbangkan oleh Pengoptimal Kueri saat mencocokkan kueri dengan tampilan terindeks. Jika paket kueri menggunakan tampilan terindeks yang cocok dengan bagian kueri yang berisi petunjuk gabungan, petunjuk gabungan tidak digunakan dalam paket.
Petunjuk tidak diperbolehkan dalam definisi tampilan terindeks. Dalam mode kompatibilitas 80 dan yang lebih tinggi, SQL Server mengabaikan petunjuk di dalam definisi tampilan terindeks saat mempertahankannya, atau saat menjalankan kueri yang menggunakan tampilan terindeks. Meskipun menggunakan petunjuk dalam definisi tampilan terindeks tidak akan menghasilkan kesalahan sintaks dalam mode kompatibilitas 80, petunjuk tersebut diabaikan.
Untuk informasi selengkapnya, lihat Petunjuk Tabel (Transact-SQL).
Mengatasi tampilan terpartisi terdistribusi
Prosesor kueri SQL Server mengoptimalkan performa tampilan yang dipartisi terdistribusi. Aspek terpenting dari performa tampilan terpartisi terdistribusi adalah meminimalkan jumlah data yang ditransfer antar server anggota.
SQL Server membangun rencana dinamis cerdas yang memanfaatkan kueri terdistribusi secara efisien untuk mengakses data dari tabel anggota jarak jauh:
- Prosesor Kueri terlebih dahulu menggunakan OLE DB untuk mengambil definisi batasan pemeriksaan dari setiap tabel anggota. Ini memungkinkan prosesor kueri untuk memetakan distribusi nilai kunci di seluruh tabel anggota.
- Prosesor Kueri membandingkan rentang kunci yang ditentukan dalam klausa pernyataan
WHERETransact-SQL dengan peta yang memperlihatkan bagaimana baris didistribusikan dalam tabel anggota. Prosesor kueri kemudian membuat rencana eksekusi kueri yang menggunakan kueri terdistribusi untuk mengambil hanya baris jarak jauh yang diperlukan untuk menyelesaikan pernyataan Transact-SQL. Rencana eksekusi juga dibangun sedih sehingga akses apa pun ke tabel anggota jarak jauh, baik untuk data atau metadata, tertunda hingga informasi diperlukan.
Misalnya, pertimbangkan sistem di mana Customers tabel dipartisi di seluruh Server1 (CustomerID dari 1 hingga 3299999), Server2 (CustomerID dari 3300000 sampai 6599999), dan Server3 (CustomerID dari 6600000 sampai 9999999).
Pertimbangkan rencana eksekusi yang dibuat untuk kueri ini yang dijalankan di Server1:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
Rencana eksekusi untuk kueri ini mengekstrak baris dengan CustomerID nilai kunci dari 3200000 hingga 3299999 dari tabel anggota lokal, dan mengeluarkan kueri terdistribusi untuk mengambil baris dengan nilai kunci dari 33000000 hingga 3400000 dari Server2.
Prosesor Kueri SQL Server juga dapat membangun logika dinamis ke dalam rencana eksekusi kueri untuk pernyataan Transact-SQL di mana nilai kunci tidak diketahui kapan paket harus dibuat. Misalnya, pertimbangkan prosedur tersimpan ini:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server tidak dapat memprediksi nilai kunci apa yang akan disediakan oleh @CustomerIDParameter parameter setiap kali prosedur dijalankan. Karena nilai kunci tidak dapat diprediksi, prosesor kueri juga tidak dapat memprediksi tabel anggota mana yang harus diakses. Untuk menangani kasus ini, SQL Server membangun rencana eksekusi yang memiliki logika kondisional, yang disebut sebagai filter dinamis, untuk mengontrol tabel anggota mana yang diakses, berdasarkan nilai parameter input. Dengan asumsi prosedur tersimpan GetCustomer dijalankan di Server1, logika rencana eksekusi dapat diwakili seperti yang ditunjukkan dalam hal berikut:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
SQL Server terkadang membangun jenis rencana eksekusi dinamis ini bahkan untuk kueri yang tidak diparameterkan. Pengoptimal Kueri dapat membuat parameter kueri sehingga rencana eksekusi dapat digunakan kembali. Jika Pengoptimal Kueri membuat parameter kueri yang mereferensikan tampilan yang dipartisi, Pengoptimal Kueri tidak dapat lagi mengasumsikan baris yang diperlukan akan berasal dari tabel dasar tertentu. Kemudian harus menggunakan filter dinamis dalam rencana eksekusi.
Prosedur tersimpan dan eksekusi pemicu
SQL Server hanya menyimpan sumber untuk prosedur dan pemicu yang disimpan. Ketika prosedur atau pemicu tersimpan pertama kali dijalankan, sumber dikompilasi ke dalam rencana eksekusi. Jika prosedur atau pemicu tersimpan lagi dijalankan sebelum rencana eksekusi berusia dari memori, mesin relasional mendeteksi rencana yang ada dan menggunakannya kembali. Jika rencana telah kehabisan usia memori, rencana baru dibuat. Proses ini mirip dengan proses yang diikuti SQL Server untuk semua pernyataan Transact-SQL. Keuntungan performa utama yang dimiliki prosedur dan pemicu yang disimpan di SQL Server dibandingkan dengan batch Transact-SQL dinamis adalah bahwa pernyataan Transact-SQL mereka selalu sama. Oleh karena itu, mesin relasional dengan mudah mencocokkannya dengan rencana eksekusi yang ada. Prosedur tersimpan dan rencana pemicu mudah digunakan kembali.
Rencana eksekusi untuk prosedur dan pemicu tersimpan dijalankan secara terpisah dari rencana eksekusi untuk batch yang memanggil prosedur tersimpan atau menembakkan pemicu. Ini memungkinkan penggunaan kembali yang lebih besar dari prosedur tersimpan dan memicu rencana eksekusi.
Penembolokan dan penggunaan kembali rencana eksekusi
SQL Server memiliki kumpulan memori yang digunakan untuk menyimpan rencana eksekusi dan buffer data. Persentase kumpulan yang dialokasikan untuk rencana eksekusi atau buffer data berfluktuasi secara dinamis, tergantung pada status sistem. Bagian dari kumpulan memori yang digunakan untuk menyimpan rencana eksekusi disebut sebagai cache rencana.
Cache paket memiliki dua penyimpanan untuk semua paket yang dikompilasi:
- Penyimpanan cache Rencana Objek (OBJCP) yang digunakan untuk rencana yang terkait dengan objek yang disimpan (prosedur tersimpan, fungsi, dan pemicu).
- Penyimpanan cache Paket SQL (SQLCP) yang digunakan untuk paket yang terkait dengan kueri yang diparameterisasi otomatis, dinamis, atau disiapkan.
Kueri di bawah ini menyediakan informasi tentang penggunaan memori untuk dua penyimpanan cache ini:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Catatan
Cache paket memiliki dua penyimpanan tambahan yang tidak digunakan untuk menyimpan paket:
- Penyimpanan cache Pohon Terikat (PHDR) yang digunakan untuk struktur data yang digunakan selama kompilasi paket untuk tampilan, batasan, dan default. Struktur ini dikenal sebagai Pohon Terikat atau Pohon Algebrizer.
- Penyimpanan cache Prosedur Tersimpan Diperluas (XPROC) yang digunakan untuk prosedur sistem yang telah ditentukan sebelumnya, seperti
sp_executeSqlatauxp_cmdshell, yang didefinisikan menggunakan DLL, tidak menggunakan pernyataan Transact-SQL. Struktur yang di-cache hanya berisi nama fungsi dan nama DLL tempat prosedur diimplementasikan.
Rencana eksekusi SQL Server memiliki komponen utama berikut:
Paket yang Dikompilasi (atau Rencana Kueri)
Rencana kueri yang dihasilkan oleh proses kompilasi sebagian besar merupakan struktur data baca-saja yang digunakan oleh sejumlah pengguna. Ini menyimpan informasi tentang:Operator fisik yang menerapkan operasi yang dijelaskan oleh operator logis.
Urutan operator ini, yang menentukan urutan data diakses, difilter, dan dikumpulkan.
Jumlah perkiraan baris yang mengalir melalui operator.
Catatan
Dalam versi Mesin Database yang lebih baru, informasi tentang objek statistik yang digunakan untuk Estimasi Kardinalitas juga disimpan.
Objek dukungan apa yang harus dibuat, seperti worktable atau workfiles di
tempdb. Tidak ada konteks pengguna atau informasi runtime yang disimpan dalam rencana kueri. Tidak pernah ada lebih dari satu atau dua salinan rencana kueri dalam memori: satu salinan untuk semua eksekusi serial dan satu lagi untuk semua eksekusi paralel. Salinan paralel mencakup semua eksekusi paralel, terlepas dari tingkat paralelisme mereka.
Konteks Eksekusi
Setiap pengguna yang saat ini menjalankan kueri memiliki struktur data yang menyimpan data khusus untuk eksekusi mereka, seperti nilai parameter. Struktur data ini disebut sebagai konteks eksekusi. Struktur data konteks eksekusi digunakan kembali, tetapi kontennya tidak. Jika pengguna lain menjalankan kueri yang sama, struktur data diinisialisasi ulang dengan konteks untuk pengguna baru.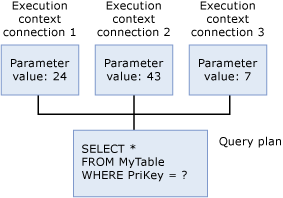
Ketika pernyataan Transact-SQL dijalankan di SQL Server, Mesin Database terlebih dahulu melihat cache rencana untuk memverifikasi bahwa rencana eksekusi yang ada untuk pernyataan Transact-SQL yang sama ada. Pernyataan Transact-SQL memenuhi syarat sebagai yang ada jika secara harfiah cocok dengan pernyataan Transact-SQL yang dieksekusi sebelumnya dengan rencana cache, karakter per karakter. SQL Server menggunakan kembali paket yang ada yang ditemukannya, menyimpan overhead dari kompilasi ulang pernyataan Transact-SQL. Jika tidak ada rencana eksekusi, SQL Server menghasilkan rencana eksekusi baru untuk kueri.
Catatan
Rencana eksekusi untuk beberapa pernyataan Transact-SQL tidak bertahan dalam cache rencana, seperti pernyataan operasi massal yang berjalan di rowstore atau pernyataan yang berisi literal string yang berukuran lebih besar dari 8 KB. Paket ini hanya ada saat kueri sedang dijalankan.
SQL Server memiliki algoritma yang efisien untuk menemukan rencana eksekusi yang ada untuk pernyataan Transact-SQL tertentu. Di sebagian besar sistem, sumber daya minimal yang digunakan oleh pemindaian ini kurang dari sumber daya yang disimpan dengan dapat menggunakan kembali rencana yang ada alih-alih mengkompilasi setiap pernyataan Transact-SQL.
Algoritma untuk mencocokkan pernyataan Transact-SQL baru dengan rencana eksekusi yang ada dan tidak digunakan dalam cache rencana mengharuskan semua referensi objek sepenuhnya memenuhi syarat. Misalnya, asumsikan bahwa Person adalah skema default untuk pengguna yang menjalankan pernyataan di bawah ini SELECT . Meskipun dalam contoh ini tidak diperlukan bahwa Person tabel sepenuhnya memenuhi syarat untuk dijalankan, itu berarti bahwa pernyataan kedua tidak cocok dengan paket yang ada, tetapi yang ketiga cocok:
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
Mengubah salah satu opsi SET berikut untuk eksekusi tertentu akan memengaruhi kemampuan untuk menggunakan kembali rencana, karena Mesin Database melakukan pelipatan konstan dan opsi ini memengaruhi hasil ekspresi tersebut:
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
BAHASA
CONCAT_NULL_YIELDS_NULL
DATEFORMAT
ANSI_WARNINGS
QUOTED_IDENTIFIER
ANSI_NULLS
NO_BROWSETABLE
ANSI_DEFAULTS
Cache beberapa paket untuk kueri yang sama
Kueri dan rencana eksekusi dapat diidentifikasi secara unik di Mesin Database, seperti sidik jari:
- Hash rencana kueri adalah nilai hash biner yang dihitung pada rencana eksekusi untuk kueri tertentu, dan digunakan untuk mengidentifikasi rencana eksekusi serupa secara unik.
- Hash kueri adalah nilai hash biner yang dihitung pada teks Transact-SQL kueri, dan digunakan untuk mengidentifikasi kueri secara unik.
Paket yang dikompilasi dapat diambil dari cache paket menggunakan Handel Rencana, yang merupakan pengidentifikasi sementara yang tetap konstan hanya saat paket tetap berada di cache. Handel rencana adalah nilai hash yang berasal dari rencana yang dikompilasi dari seluruh batch. Handel rencana untuk rencana yang dikompilasi tetap sama meskipun satu atau beberapa pernyataan dalam batch dikompilasi ulang.
Catatan
Jika paket dikompilasi untuk batch alih-alih satu pernyataan, rencana untuk pernyataan individu dalam batch dapat diambil menggunakan handel rencana dan offset pernyataan.
sys.dm_exec_requests DMV berisi statement_start_offset kolom dan statement_end_offset untuk setiap rekaman, yang merujuk ke pernyataan yang sedang dijalankan dari batch yang sedang dijalankan atau objek yang dipertahankan. Untuk informasi lebih lanjut, lihat sys.dm_exec_requests (Transact-SQL).
sys.dm_exec_query_stats DMV juga berisi kolom ini untuk setiap rekaman, yang merujuk ke posisi pernyataan dalam objek batch atau persisten. Untuk informasi selengkapnya, lihat sys.dm_exec_query_stats (Transact-SQL).
Teks Transact-SQL aktual dari batch disimpan dalam ruang memori terpisah dari cache paket, yang disebut cache SQL Manager (SQLMGR). Teks Transact-SQL untuk paket yang dikompilasi dapat diambil dari cache manajer sql menggunakan SQL Handle, yang merupakan pengidentifikasi sementara yang tetap konstan hanya sementara setidaknya satu paket yang mereferensikannya tetap berada di cache paket. Handel sql adalah nilai hash yang berasal dari seluruh teks batch dan dijamin unik untuk setiap batch.
Catatan
Seperti paket yang dikompilasi, teks Transact-SQL disimpan per batch, termasuk komentar. Handel sql berisi hash MD5 dari seluruh teks batch dan dijamin unik untuk setiap batch.
Kueri di bawah ini menyediakan informasi tentang penggunaan memori untuk cache manajer sql:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
Ada hubungan 1:N antara handel sql dan handel rencana. Kondisi seperti itu terjadi ketika kunci cache untuk rencana yang dikompilasi berbeda. Ini mungkin terjadi karena perubahan opsi SET antara dua eksekusi batch yang sama.
Pertimbangkan prosedur tersimpan berikut:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Verifikasi apa yang dapat ditemukan di cache paket menggunakan kueri di bawah ini:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Berikut set hasilnya.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Sekarang jalankan prosedur tersimpan dengan parameter yang berbeda, tetapi tidak ada perubahan lain pada konteks eksekusi:
EXEC usp_SalesByCustomer 8
GO
Verifikasi lagi apa yang dapat ditemukan di cache paket. Berikut set hasilnya.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
usecounts Perhatikan telah meningkat menjadi 2, yang berarti rencana cache yang sama digunakan kembali apa adanya, karena struktur data konteks eksekusi digunakan kembali. Sekarang ubah SET ANSI_DEFAULTS opsi dan jalankan prosedur tersimpan menggunakan parameter yang sama.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Verifikasi lagi apa yang dapat ditemukan di cache paket. Berikut set hasilnya.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Perhatikan bahwa sekarang ada dua entri dalam sys.dm_exec_cached_plans output DMV:
- Kolom
usecountsmemperlihatkan nilai1dalam rekaman pertama, yaitu paket yang dijalankan sekali denganSET ANSI_DEFAULTS OFF. - Kolom
usecountsmenunjukkan nilai2dalam rekaman kedua, yaitu rencana yang dijalankan denganSET ANSI_DEFAULTS ON, karena dijalankan dua kali. - Yang berbeda
memory_object_addressmengacu pada entri rencana eksekusi yang berbeda dalam cache rencana. Namun,sql_handlenilainya sama untuk kedua entri karena merujuk ke batch yang sama.- Eksekusi dengan
ANSI_DEFAULTSdiatur ke NONAKTIF memiliki yang baruplan_handle, dan tersedia untuk digunakan kembali untuk panggilan yang memiliki sekumpulan opsi SET yang sama. Handel rencana baru diperlukan karena konteks eksekusi diinisialisasi ulang karena opsi SET yang diubah. Tetapi itu tidak memicu kompilasi ulang: kedua entri merujuk ke rencana dan kueri yang sama, sebagaimana dibuktikan oleh nilai danquery_hashyang samaquery_plan_hash.
- Eksekusi dengan
Apa artinya ini secara efektif adalah bahwa kita memiliki dua entri paket dalam cache yang sesuai dengan batch yang sama, dan ini menggarisbawaikan pentingnya memastikan bahwa cache paket yang memengaruhi opsi SET sama, ketika kueri yang sama dijalankan berulang kali, untuk mengoptimalkan penggunaan kembali rencana dan mempertahankan ukuran cache rencana ke minimum yang diperlukan.
Tip
Perangkap umum adalah bahwa klien yang berbeda dapat memiliki nilai default yang berbeda untuk opsi SET. Misalnya, koneksi yang dibuat melalui SQL Server Management Studio secara otomatis diatur QUOTED_IDENTIFIER ke AKTIF, sementara SQLCMD diatur QUOTED_IDENTIFIER ke NONAKTIF. Menjalankan kueri yang sama dari kedua klien ini akan menghasilkan beberapa paket (seperti yang dijelaskan dalam contoh di atas).
Menghapus rencana eksekusi dari cache paket
Rencana eksekusi tetap berada di cache rencana selama ada cukup memori untuk menyimpannya. Ketika tekanan memori ada, Mesin Database SQL Server menggunakan pendekatan berbasis biaya untuk menentukan rencana eksekusi mana yang akan dihapus dari cache paket. Untuk membuat keputusan berbasis biaya, Mesin Database SQL Server meningkatkan dan mengurangi variabel biaya saat ini untuk setiap rencana eksekusi sesuai dengan faktor-faktor berikut.
Saat proses pengguna menyisipkan rencana eksekusi ke dalam cache, proses pengguna mengatur biaya saat ini sama dengan biaya kompilasi kueri asli; untuk rencana eksekusi ad hoc, proses pengguna menetapkan biaya saat ini ke nol. Setelah itu, setiap kali proses pengguna mereferensikan rencana eksekusi, proses tersebut mengatur ulang biaya saat ini ke biaya kompilasi asli; untuk rencana eksekusi ad hoc, proses pengguna meningkatkan biaya saat ini. Untuk semua paket, nilai maksimum untuk biaya saat ini adalah biaya kompilasi asli.
Ketika tekanan memori ada, Mesin Database SQL Server merespons dengan menghapus rencana eksekusi dari cache rencana. Untuk menentukan rencana mana yang akan dihapus, Mesin Database SQL Server berulang kali memeriksa status setiap rencana eksekusi dan menghapus rencana ketika biayanya saat ini adalah nol. Rencana eksekusi dengan biaya saat ini nol tidak dihapus secara otomatis ketika tekanan memori ada; ini dihapus hanya ketika Mesin Database SQL Server memeriksa paket dan biaya saat ini adalah nol. Saat memeriksa rencana eksekusi, Mesin Database SQL Server mendorong biaya saat ini menuju nol dengan mengurangi biaya saat ini jika kueri saat ini tidak menggunakan paket.
Mesin Database SQL Server berulang kali memeriksa rencana eksekusi sampai cukup telah dihapus untuk memenuhi persyaratan memori. Meskipun tekanan memori ada, rencana eksekusi mungkin memiliki biayanya meningkat dan menurun lebih dari sekali. Ketika tekanan memori tidak ada lagi, Mesin Database SQL Server berhenti mengurangi biaya rencana eksekusi yang tidak digunakan saat ini dan semua rencana eksekusi tetap berada di cache rencana, bahkan jika biayanya nol.
Mesin Database SQL Server menggunakan monitor sumber daya dan utas pekerja pengguna untuk membebaskan memori dari cache rencana sebagai respons terhadap tekanan memori. Monitor sumber daya dan utas pekerja pengguna dapat memeriksa rencana yang dijalankan secara bersamaan untuk mengurangi biaya saat ini untuk setiap rencana eksekusi yang tidak digunakan. Monitor sumber daya menghapus rencana eksekusi dari cache rencana ketika tekanan memori global ada. Ini membebaskan memori untuk menerapkan kebijakan untuk memori sistem, memori proses, memori kumpulan sumber daya, dan ukuran maksimum untuk semua cache.
Ukuran maksimum untuk semua cache adalah fungsi dari ukuran kumpulan buffer dan tidak dapat melebihi memori server maksimum. Untuk informasi selengkapnya tentang mengonfigurasi memori server maksimum, lihat max server memory pengaturan di sp_configure.
Utas pekerja pengguna menghapus rencana eksekusi dari cache rencana ketika ada tekanan memori cache tunggal. Mereka memberlakukan kebijakan untuk ukuran cache tunggal maksimum dan entri cache tunggal maksimum.
Contoh berikut mengilustrasikan rencana eksekusi mana yang dihapus dari cache paket:
- Rencana eksekusi sering dirujuk sehingga biayanya tidak pernah ke nol. Paket tetap berada dalam cache paket dan tidak dihapus kecuali ada tekanan memori dan biaya saat ini adalah nol.
- Rencana eksekusi ad hoc dimasukkan dan tidak direferensikan lagi sebelum tekanan memori ada. Karena paket ad hoc diinisialisasi dengan biaya nol saat ini, ketika Mesin Database SQL Server memeriksa rencana eksekusi, itu akan melihat biaya saat ini nol dan menghapus paket dari cache paket. Rencana eksekusi ad hoc tetap berada di cache paket dengan biaya saat ini nol ketika tekanan memori tidak ada.
Untuk menghapus satu paket atau semua paket secara manual dari cache, gunakan DBCC FREEPROCCACHE. DBCC FREESYSTEMCACHE juga dapat digunakan untuk menghapus cache apa pun, termasuk cache paket. Dimulai dengan SQL Server 2016 (13.x), ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE untuk menghapus cache prosedur (rencana) untuk database dalam cakupan.
Perubahan dalam beberapa pengaturan konfigurasi melalui sp_configure dan konfigurasi ulang juga akan menyebabkan rencana dihapus dari cache paket. Anda dapat menemukan daftar pengaturan konfigurasi ini di bagian Keterangan dari artikel DBCC FREEPROCCACHE . Perubahan konfigurasi seperti ini akan mencatat pesan informasi berikut dalam log kesalahan:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Rencana eksekusi kompilasi ulang
Perubahan tertentu dalam database dapat menyebabkan rencana eksekusi menjadi tidak efisien atau tidak valid, berdasarkan status baru database. SQL Server mendeteksi perubahan yang membatalkan rencana eksekusi dan menandai paket sebagai tidak valid. Paket baru kemudian harus dikompresi ulang untuk koneksi berikutnya yang menjalankan kueri. Kondisi yang membatalkan paket meliputi yang berikut ini:
- Perubahan yang dibuat pada tabel atau tampilan yang dirujuk oleh kueri (
ALTER TABLEdanALTER VIEW). - Perubahan yang dilakukan pada satu prosedur, yang akan menghilangkan semua rencana untuk prosedur tersebut dari cache (
ALTER PROCEDURE). - Perubahan pada indeks apa pun yang digunakan oleh rencana eksekusi.
- Pembaruan statistik yang digunakan oleh rencana eksekusi, dihasilkan secara eksplisit dari pernyataan, seperti
UPDATE STATISTICS, atau dihasilkan secara otomatis. - Menghilangkan indeks yang digunakan oleh rencana eksekusi.
- Panggilan eksplisit ke
sp_recompile. - Sejumlah besar perubahan pada kunci (dihasilkan oleh
INSERTatauDELETEpernyataan dari pengguna lain yang mengubah tabel yang dirujuk oleh kueri). - Untuk tabel dengan pemicu, jika jumlah baris dalam tabel yang disisipkan atau dihapus tumbuh secara signifikan.
- Menjalankan prosedur tersimpan
WITH RECOMPILEmenggunakan opsi .
Sebagian besar kompilasi ulang diperlukan baik untuk kebenaran pernyataan atau untuk mendapatkan rencana eksekusi kueri yang berpotensi lebih cepat.
Dalam versi SQL Server sebelum 2005, setiap kali pernyataan dalam batch menyebabkan kompilasi ulang, seluruh batch, apakah dikirimkan melalui prosedur tersimpan, pemicu, batch ad hoc, atau pernyataan yang disiapkan, dikompilasi ulang. Dimulai dengan SQL Server 2005 (9.x), hanya pernyataan di dalam batch yang memicu kompilasi ulang yang dikompilasi ulang. Selain itu, ada jenis kompilasi ulang tambahan di SQL Server 2005 (9.x) dan yang lebih baru karena kumpulan fitur yang diperluas.
Performa manfaat kompilasi ulang tingkat pernyataan karena, dalam kebanyakan kasus, sejumlah kecil pernyataan menyebabkan kompilasi ulang dan penalti terkait, dalam hal waktu dan kunci CPU. Oleh karena itu, penalti ini dihindari untuk pernyataan lain dalam batch yang tidak harus dikompresi ulang.
Peristiwa sql_statement_recompile yang diperluas (XEvent) melaporkan kompilasi ulang tingkat pernyataan. XEvent ini terjadi ketika kompilasi ulang tingkat pernyataan diperlukan oleh segala jenis batch. Ini termasuk prosedur tersimpan, pemicu, batch ad hoc, dan kueri. Batch dapat dikirimkan melalui beberapa antarmuka, termasuk sp_executesql, SQL dinamis, Metode persiapan atau metode Execute.
Kolom recompile_cause sql_statement_recompile XEvent berisi kode bilangan bulat yang menunjukkan alasan kompilasi ulang. Tabel berikut berisi kemungkinan alasan:
Skema berubah
Statistik berubah
Kompilasi yang ditangguhkan
Opsi SET diubah
Tabel sementara diubah
Set baris jarak jauh diubah
FOR BROWSE izin diubah
Lingkungan pemberitahuan kueri berubah
Tampilan yang dipartisi berubah
Opsi kursor berubah
OPTION (RECOMPILE) Diminta
Paket berparameter dihapus
Rencana yang memengaruhi versi database berubah
Kebijakan memaksa paket Penyimpanan Kueri diubah
Paket Penyimpanan Kueri memaksa gagal
Penyimpanan Kueri tidak memiliki paket
Catatan
Dalam versi SQL Server di mana XEvents tidak tersedia, maka peristiwa pelacakan SQL Server Profiler SP:Recompile dapat digunakan untuk tujuan yang sama untuk melaporkan kompilasi ulang tingkat pernyataan.
Peristiwa SQL:StmtRecompile pelacakan juga melaporkan kompilasi ulang tingkat pernyataan, dan peristiwa pelacakan ini juga dapat digunakan untuk melacak dan men-debug kompilasi ulang.
SP:Recompile Sedangkan hanya menghasilkan untuk prosedur dan pemicu tersimpan, SQL:StmtRecompile dihasilkan untuk prosedur tersimpan, pemicu, batch ad hoc, batch yang dijalankan dengan menggunakan sp_executesql, kueri yang disiapkan, dan SQL dinamis.
Kolom EventSubClass dan SP:Recompile SQL:StmtRecompile berisi kode bilangan bulat yang menunjukkan alasan kompilasi ulang. Kode dijelaskan di sini.
Catatan
AUTO_UPDATE_STATISTICS Ketika opsi database diatur ke ON, kueri dikombinasikan ulang ketika mereka menargetkan tabel atau tampilan terindeks yang statistiknya telah diperbarui atau yang kardinalitasnya telah berubah secara signifikan sejak eksekusi terakhir.
Perilaku ini berlaku untuk tabel standar yang ditentukan pengguna, tabel sementara, dan tabel yang disisipkan dan dihapus yang dibuat oleh pemicu DML. Jika performa kueri dipengaruhi oleh kompilasi ulang yang berlebihan, pertimbangkan untuk mengubah pengaturan ini menjadi OFF. AUTO_UPDATE_STATISTICS Ketika opsi database diatur ke OFF, tidak ada kompilasi ulang yang terjadi berdasarkan statistik atau perubahan kardinalitas, dengan pengecualian tabel yang disisipkan dan dihapus yang dibuat oleh pemicu DMLINSTEAD OF. Karena tabel ini dibuat dalam tempdb, kompilasi ulang kueri yang mengaksesnya tergantung pada pengaturan AUTO_UPDATE_STATISTICS di tempdb.
Di SQL Server sebelum 2005, kueri terus dikompilasi ulang berdasarkan perubahan kardinalitas pada pemicu DML yang dimasukkan dan dihapus tabel, bahkan ketika pengaturan ini adalah OFF.
Parameter dan penggunaan kembali rencana eksekusi
Penggunaan parameter, termasuk penanda parameter di aplikasi ADO, OLE DB, dan ODBC, dapat meningkatkan penggunaan kembali rencana eksekusi.
Peringatan
Menggunakan parameter atau penanda parameter untuk menyimpan nilai yang di ketik oleh pengguna akhir lebih aman daripada menggabungkan nilai ke dalam string yang kemudian dijalankan dengan menggunakan metode API akses data, EXECUTE pernyataan, atau prosedur tersimpan sp_executesql .
Satu-satunya perbedaan antara dua SELECT pernyataan berikut adalah nilai yang dibandingkan dalam WHERE klausa:
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Satu-satunya perbedaan antara rencana eksekusi untuk kueri ini adalah nilai yang disimpan untuk perbandingan ProductSubcategoryID terhadap kolom. Meskipun tujuannya adalah agar SQL Server selalu mengenali bahwa pernyataan pada dasarnya menghasilkan rencana yang sama dan menggunakan kembali rencana, SQL Server terkadang tidak mendeteksi ini dalam pernyataan Transact-SQL yang kompleks.
Memisahkan konstanta dari pernyataan Transact-SQL dengan menggunakan parameter membantu mesin relasional mengenali rencana duplikat. Anda dapat menggunakan parameter dengan cara berikut:
Dalam Transact-SQL , gunakan
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmMetode ini direkomendasikan untuk skrip Transact-SQL, prosedur tersimpan, atau pemicu yang menghasilkan pernyataan SQL secara dinamis.
ADO, OLE DB, dan ODBC menggunakan penanda parameter. Penanda parameter adalah tanda tanya (?) yang menggantikan konstanta dalam pernyataan SQL dan terikat ke variabel program. Misalnya, Anda akan melakukan hal berikut dalam aplikasi ODBC:
Gunakan
SQLBindParameteruntuk mengikat variabel bilangan bulat ke penanda parameter pertama dalam pernyataan SQL.Masukkan nilai bilangan bulat dalam variabel.
Jalankan pernyataan, menentukan penanda parameter (?):
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
Penyedia SQL Server Native Client OLE DB dan driver ODBC SQL Server Native Client yang disertakan dengan penggunaan
sp_executesqlSQL Server untuk mengirim pernyataan ke SQL Server saat penanda parameter digunakan dalam aplikasi.Untuk merancang prosedur tersimpan, yang menggunakan parameter menurut desain.
Jika Anda tidak secara eksplisit membuat parameter ke dalam desain aplikasi, Anda juga dapat mengandalkan Pengoptimal Kueri SQL Server untuk secara otomatis membuat parameter kueri tertentu dengan menggunakan perilaku default parameterisasi sederhana. Atau, Anda dapat memaksa Pengoptimal Kueri untuk mempertimbangkan parameterisasi semua kueri dalam database dengan mengatur PARAMETERIZATION opsi ALTER DATABASE pernyataan ke FORCED.
Ketika parameterisasi paksa diaktifkan, parameterisasi sederhana masih dapat terjadi. Misalnya, kueri berikut tidak dapat diparameterkan sesuai dengan aturan parameterisasi paksa:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
Namun, dapat diparameterkan sesuai dengan aturan parameterisasi sederhana. Ketika parameterisasi paksa dicoba tetapi gagal, parameterisasi sederhana masih dicoba.
Parameterisasi sederhana
Di SQL Server, menggunakan parameter atau penanda parameter dalam pernyataan Transact-SQL meningkatkan kemampuan mesin relasional untuk mencocokkan pernyataan Transact-SQL baru dengan rencana eksekusi yang sudah ada dan dikompilasi sebelumnya.
Peringatan
Menggunakan parameter atau penanda parameter untuk menyimpan nilai yang di ketik oleh pengguna akhir lebih aman daripada menggabungkan nilai ke dalam string yang kemudian dijalankan menggunakan metode API akses data, EXECUTE pernyataan, atau prosedur tersimpan sp_executesql .
Jika pernyataan Transact-SQL dijalankan tanpa parameter, SQL Server membuat parameter pernyataan secara internal untuk meningkatkan kemungkinan mencocokkannya dengan rencana eksekusi yang ada. Proses ini disebut parameterisasi sederhana. Dalam versi SQL Server sebelum 2005, proses ini disebut sebagai parameterisasi otomatis.
Pertimbangkan pernyataan ini:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
Nilai 1 di akhir pernyataan dapat ditentukan sebagai parameter. Mesin relasional membangun rencana eksekusi untuk batch ini seolah-olah parameter telah ditentukan sebagai pengganti nilai 1. Karena parameterisasi sederhana ini, SQL Server mengakui bahwa dua pernyataan berikut pada dasarnya menghasilkan rencana eksekusi yang sama dan menggunakan kembali rencana pertama untuk pernyataan kedua:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Saat memproses pernyataan Transact-SQL yang kompleks, mesin relasional dapat mengalami kesulitan menentukan ekspresi mana yang dapat diparameterkan. Untuk meningkatkan kemampuan mesin relasional untuk mencocokkan pernyataan Transact-SQL yang kompleks dengan rencana eksekusi yang ada dan tidak digunakan, tentukan parameter secara eksplisit menggunakan sp_executesql penanda parameter atau .
Catatan
+Ketika operator aritmatika , -, *, /atau % digunakan untuk melakukan konversi implisit atau eksplisit dari nilai konstanta int, smallint, tinyint, atau bigint ke jenis data float, real, desimal, atau numerik, SQL Server menerapkan aturan khusus untuk menghitung jenis dan presisi hasil ekspresi. Namun, aturan ini berbeda, tergantung pada apakah kueri diparameterkan atau tidak. Oleh karena itu, ekspresi serupa dalam kueri dapat, dalam beberapa kasus, menghasilkan hasil yang berbeda.
Di bawah perilaku default parameterisasi sederhana, SQL Server membuat parameter pada kelas kueri yang relatif kecil. Namun, Anda dapat menentukan bahwa semua kueri dalam database diparameterkan, tunduk pada batasan tertentu, dengan mengatur PARAMETERIZATION opsi ALTER DATABASE perintah ke FORCED. Melakukannya dapat meningkatkan performa database yang mengalami volume kueri bersamaan yang tinggi dengan mengurangi frekuensi kompilasi kueri.
Atau, Anda dapat menentukan bahwa satu kueri, dan kueri lain yang setara secara sintetis tetapi hanya berbeda dalam nilai parameternya, diparameterkan.
Tip
Saat menggunakan solusi Pemetaan Hubungan Objek (ORM) seperti Kerangka Kerja Entitas (EF), kueri aplikasi seperti pohon kueri LINQ manual atau kueri SQL mentah tertentu mungkin tidak diparameterkan, yang memengaruhi penggunaan kembali rencana dan kemampuan untuk melacak kueri di Penyimpanan Kueri. Untuk informasi selengkapnya, lihat Penembolokan dan parameterisasi Kueri EF dan Kueri SQL Mentah EF.
Parameterisasi paksa
Anda dapat mengambil alih perilaku parameterisasi sederhana default SQL Server dengan menentukan bahwa semua SELECTpernyataan , , INSERTUPDATE, dan DELETE dalam database diparameterkan, tunduk pada batasan tertentu. Parameterisasi paksa diaktifkan dengan mengatur PARAMETERIZATION opsi ke FORCED ALTER DATABASE dalam pernyataan. Parameterisasi paksa dapat meningkatkan performa database tertentu dengan mengurangi frekuensi kompilasi kueri dan kompilasi ulang. Database yang mungkin mendapat manfaat dari parameterisasi paksa umumnya adalah database yang mengalami volume kueri bersamaan yang tinggi dari sumber seperti aplikasi point-of-sale.
PARAMETERIZATION Ketika opsi diatur ke FORCED, nilai harfiah apa pun yang muncul dalam SELECTpernyataan , , UPDATEINSERT, atau DELETE , yang dikirimkan dalam bentuk apa pun, dikonversi ke parameter selama kompilasi kueri. Pengecualiannya adalah literal yang muncul dalam konstruksi kueri berikut:
INSERT...EXECUTEPernyataan.- Pernyataan di dalam isi prosedur tersimpan, pemicu, atau fungsi yang ditentukan pengguna. SQL Server sudah menggunakan kembali rencana kueri untuk rutinitas ini.
- Pernyataan yang disiapkan yang telah diparameterkan pada aplikasi sisi klien.
- Pernyataan yang berisi panggilan metode XQuery, di mana metode muncul dalam konteks di mana argumennya biasanya akan diparameterkan, seperti
WHEREklausa. Jika metode muncul dalam konteks di mana argumennya tidak akan diparameterkan, sisa pernyataan diparameterkan. - Pernyataan di dalam kursor Transact-SQL. (
SELECTpernyataan di dalam kursor API diparameterkan.) - Konstruksi kueri yang tidak digunakan lagi.
- Pernyataan apa pun yang dijalankan dalam konteks
ANSI_PADDINGatauANSI_NULLSdiatur keOFF. - Pernyataan yang berisi lebih dari 2.097 literal yang memenuhi syarat untuk parameterisasi.
- Pernyataan yang mereferensikan variabel, seperti
WHERE T.col2 >= @bb. - Pernyataan yang berisi
RECOMPILEpetunjuk kueri. - Pernyataan yang berisi
COMPUTEklausa. - Pernyataan yang berisi
WHERE CURRENT OFklausa.
Selain itu, klausa kueri berikut tidak diparameterkan. Dalam kasus ini, hanya klausul yang tidak diparameterkan. Klausa lain dalam kueri yang sama dapat memenuhi syarat untuk parameterisasi paksa.
- <Select_list> pernyataan apa pun
SELECT. Ini termasukSELECTdaftar subkueri danSELECTdaftar di dalamINSERTpernyataan. - Pernyataan subkueri
SELECTyang muncul di dalam pernyataanIF. - Klausa
TOPkueri , ,HAVINGGROUP BYTABLESAMPLE,ORDER BY,OUTPUT...INTO, atau .FOR XML - Argumen, baik langsung atau sebagai subekspresi, ke
OPENROWSET, ,OPENQUERYOPENDATASOURCE,OPENXML, atau operator apa punFULLTEXT. - Pola dan argumen escape_character klausul
LIKE. - Argumen
CONVERTgaya klausa. - Konstanta bilangan bulat di dalam
IDENTITYklausul. - Konstanta yang ditentukan dengan menggunakan sintaks ekstensi ODBC.
- Ekspresi yang dapat dilipat konstan yang merupakan argumen dari
+operator , ,*-,/, dan%. Saat mempertimbangkan kelayakan untuk parameterisasi paksa, SQL Server menganggap ekspresi dapat dilipat secara konstan ketika salah satu kondisi berikut ini benar:- Tidak ada kolom, variabel, atau subkueri yang muncul dalam ekspresi.
- Ekspresi berisi klausa
CASE.
- Argumen untuk mengkueri klausa petunjuk. Ini termasuk argumen number_of_rows petunjuk kueri, argumen
MAXDOPnumber_of_processors petunjuk kueri, dan argumenMAXRECURSIONangka petunjuk kueri.FAST
Parameterisasi terjadi pada tingkat pernyataan Transact-SQL individual. Dengan kata lain, pernyataan individual dalam batch diparameterkan. Setelah dikompilasi, kueri berparameter dijalankan dalam konteks batch tempat kueri awalnya dikirimkan. Jika rencana eksekusi untuk kueri di-cache, Anda dapat menentukan apakah kueri diparameterkan dengan merujuk kolom sql dari sys.syscacheobjects tampilan manajemen dinamis. Jika kueri diparameterkan, nama dan jenis data parameter datang sebelum teks batch yang dikirimkan dalam kolom ini, seperti (@1 tinyint).
Catatan
Nama parameter semena-mena. Pengguna atau aplikasi tidak boleh mengandalkan urutan penamaan tertentu. Selain itu, berikut ini dapat berubah antara versi peningkatan SQL Server dan Paket Layanan: Nama parameter, pilihan literal yang diparameterkan, dan penspasian dalam teks berparameter.
Jenis data parameter
Saat SQL Server membuat parameter literal, parameter dikonversi ke jenis data berikut:
- Literal bilangan bulat yang ukurannya akan sesuai dengan jenis data int yang diparameterkan ke int. Literal bilangan bulat yang lebih besar yang merupakan bagian dari predikat yang melibatkan operator perbandingan apa pun (termasuk
<,=!=>>=!>!<<=<>ALL,SOMEANY,BETWEEN, , danIN) berparameter ke numerik(38,0). Literal yang lebih besar yang bukan bagian dari predikat yang melibatkan operator perbandingan berparameter ke numerik yang presisinya hanya cukup besar untuk mendukung ukurannya dan yang skalanya adalah 0. - Literal numerik titik tetap yang merupakan bagian dari predikat yang melibatkan operator perbandingan berparameter dengan numerik yang presisinya adalah 38 dan yang skalanya hanya cukup besar untuk mendukung ukurannya. Literal numerik titik tetap yang bukan bagian dari predikat yang melibatkan operator perbandingan berparameter dengan numerik yang presisi dan skalanya hanya cukup besar untuk mendukung ukurannya.
- Harfiah numerik titik mengambang berparameter ke float(53).
- Untai (karakter) non-Unicode berparameter ke varchar(8000) jika harfiah pas dalam 8.000 karakter, dan untuk varchar(maks) jika lebih besar dari 8.000 karakter.
- Literal string Unicode berparameter ke nvarchar(4000) jika harfiah pas dalam 4.000 karakter Unicode, dan untuk nvarchar(maks) jika literal lebih besar dari 4.000 karakter.
- Literal biner berparameter ke varbinary(8000) jika harfiah cocok dalam 8.000 byte. Jika lebih besar dari 8.000 byte, itu dikonversi ke varbinary(maks).
- Jenis uang harfiah diparameterkan menjadi uang.
Panduan untuk menggunakan parameterisasi paksa
Pertimbangkan hal berikut saat Anda mengatur PARAMETERIZATION opsi ke FORCED:
- Parameterisasi paksa, berlaku, mengubah konstanta harfiah dalam kueri ke parameter saat mengkompilasi kueri. Oleh karena itu, Pengoptimal Kueri dapat memilih rencana suboptimal untuk kueri. Secara khusus, Pengoptimal Kueri cenderung tidak cocok dengan kueri dengan tampilan terindeks atau indeks pada kolom komputasi. Ini mungkin juga memilih rencana suboptimal untuk kueri yang diposisikan pada tabel yang dipartisi dan tampilan yang dipartisi terdistribusi. Parameterisasi paksa tidak boleh digunakan untuk lingkungan yang sangat bergantung pada tampilan dan indeks terindeks pada kolom komputasi. Umumnya,
PARAMETERIZATION FORCEDopsi hanya boleh digunakan oleh administrator database berpengalaman setelah menentukan bahwa melakukan ini tidak berdampak buruk pada performa. - Kueri terdistribusi yang mereferensikan lebih dari satu database memenuhi syarat untuk parameterisasi paksa selama
PARAMETERIZATIONopsi diatur keFORCEDdalam database yang konteks kuerinya berjalan. PARAMETERIZATIONMengatur opsi untukFORCEDmenghapus semua rencana kueri dari cache paket database, kecuali yang saat ini mengkompilasi, mengkompilasi ulang, atau menjalankan. Rencana untuk kueri yang mengkompilasi atau berjalan selama perubahan pengaturan diparameterkan saat kueri dijalankan berikutnya.PARAMETERIZATIONMengatur opsi adalah operasi online yang tidak memerlukan kunci eksklusif tingkat database.- Pengaturan
PARAMETERIZATIONopsi saat ini dipertahankan saat memasang ulang atau memulihkan database.
Anda dapat mengambil alih perilaku parameterisasi paksa dengan menentukan bahwa parameterisasi sederhana dicoba pada satu kueri, dan yang lain yang setara secara sintetis tetapi hanya berbeda dalam nilai parameternya. Sebaliknya, Anda dapat menentukan bahwa parameterisasi paksa hanya dicoba pada sekumpulan kueri yang setara secara sintetis, bahkan jika parameterisasi paksa dinonaktifkan dalam database. Panduan paket digunakan untuk tujuan ini.
Catatan
PARAMETERIZATION Ketika opsi diatur ke FORCED, pelaporan pesan kesalahan dapat berbeda dari ketika PARAMETERIZATION opsi diatur ke SIMPLE: beberapa pesan kesalahan mungkin dilaporkan di bawah parameterisasi paksa, di mana lebih sedikit pesan akan dilaporkan di bawah parameterisasi sederhana, dan nomor baris di mana kesalahan terjadi dapat dilaporkan dengan salah.
Menyiapkan pernyataan SQL
Mesin relasional SQL Server memperkenalkan dukungan penuh untuk menyiapkan pernyataan Transact-SQL sebelum dijalankan. Jika aplikasi harus menjalankan pernyataan Transact-SQL beberapa kali, aplikasi dapat menggunakan API database untuk melakukan hal berikut:
- Siapkan pernyataan sekali. Ini mengkompilasi pernyataan Transact-SQL ke dalam rencana eksekusi.
- Jalankan rencana eksekusi yang telah dikommpilasikan setiap kali harus menjalankan pernyataan. Ini mencegah harus mengkombinasi ulang pernyataan Transact-SQL pada setiap eksekusi setelah pertama kalinya. Menyiapkan dan menjalankan pernyataan dikontrol oleh fungsi dan metode API. Ini bukan bagian dari bahasa Transact-SQL. Model persiapan/eksekusi menjalankan pernyataan Transact-SQL didukung oleh Penyedia OLE DB Klien Asli SQL Server dan driver ODBC Klien Asli SQL Server. Pada permintaan persiapan, penyedia atau driver mengirimkan pernyataan ke SQL Server dengan permintaan untuk menyiapkan pernyataan. SQL Server mengkompilasi rencana eksekusi dan mengembalikan handel untuk rencana tersebut ke penyedia atau driver. Pada permintaan eksekusi, penyedia atau driver mengirimkan permintaan kepada server untuk menjalankan rencana yang terkait dengan handel.
Pernyataan yang disiapkan tidak dapat digunakan untuk membuat objek sementara di SQL Server. Pernyataan yang disiapkan tidak dapat mereferensikan prosedur tersimpan sistem yang membuat objek sementara, seperti tabel sementara. Prosedur ini harus dijalankan secara langsung.
Kelebihan penggunaan model persiapan/eksekusi dapat menurunkan performa. Jika pernyataan dijalankan hanya sekali, eksekusi langsung hanya memerlukan satu jaringan pulang pergi ke server. Menyiapkan dan menjalankan pernyataan Transact-SQL yang dijalankan hanya satu kali memerlukan pulang-pergi jaringan tambahan; satu perjalanan untuk menyiapkan pernyataan dan satu perjalanan untuk mengeksekusinya.
Menyiapkan pernyataan lebih efektif jika penanda parameter digunakan. Misalnya, asumsikan bahwa aplikasi kadang-kadang diminta untuk mengambil informasi produk dari AdventureWorks database sampel. Ada dua cara aplikasi dapat melakukan ini.
Dengan menggunakan cara pertama, aplikasi dapat menjalankan kueri terpisah untuk setiap produk yang diminta:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
Dengan menggunakan cara kedua, aplikasi melakukan hal berikut:
Menyiapkan pernyataan yang berisi penanda parameter (?):
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Mengikat variabel program ke penanda parameter.
Setiap kali informasi produk diperlukan, mengisi variabel terikat dengan nilai kunci dan menjalankan pernyataan.
Cara kedua lebih efisien ketika pernyataan dijalankan lebih dari tiga kali.
Di SQL Server, model persiapan/eksekusi tidak memiliki keunggulan performa yang signifikan daripada eksekusi langsung, karena cara SQL Server menggunakan kembali rencana eksekusi. SQL Server memiliki algoritma yang efisien untuk mencocokkan pernyataan Transact-SQL saat ini dengan rencana eksekusi yang dihasilkan untuk eksekusi sebelumnya dari pernyataan Transact-SQL yang sama. Jika aplikasi menjalankan pernyataan Transact-SQL dengan penanda parameter beberapa kali, SQL Server akan menggunakan kembali rencana eksekusi dari eksekusi pertama untuk eksekusi kedua dan berikutnya (kecuali rencana usia dari cache rencana). Model persiapan/eksekusi masih memiliki manfaat berikut:
- Menemukan rencana eksekusi dengan handel identifikasi lebih efisien daripada algoritma yang digunakan untuk mencocokkan pernyataan Transact-SQL dengan rencana eksekusi yang ada.
- Aplikasi dapat mengontrol kapan rencana eksekusi dibuat dan ketika digunakan kembali.
- Model persiapan/eksekusi portabel ke database lain, termasuk versi SQL Server yang lebih lama.
Sensitivitas parameter
Sensitivitas parameter, juga dikenal sebagai "parameter sniffing", mengacu pada proses di mana SQL Server "mengendus" nilai parameter saat ini selama kompilasi atau kompilasi ulang, dan meneruskannya ke Pengoptimal Kueri sehingga dapat digunakan untuk menghasilkan rencana eksekusi kueri yang berpotensi lebih efisien.
Nilai parameter di-sniff selama kompilasi atau kompilasi ulang untuk jenis batch berikut:
- Prosedur tersimpan
- Kueri dikirimkan melalui
sp_executesql - Kueri yang disiapkan
Untuk informasi selengkapnya tentang pemecahan masalah sniffing parameter buruk, lihat:
- Menyelidiki dan mengatasi masalah sensitif parameter
- Parameter dan Penggunaan Kembali Rencana Eksekusi
- Pengoptimalan Rencana Sensitif Parameter
- Memecahkan masalah kueri dengan masalah rencana eksekusi kueri sensitif parameter di Azure SQL Database
- Memecahkan masalah kueri dengan masalah rencana eksekusi kueri sensitif parameter di Azure SQL Managed Instance
Catatan
Untuk kueri yang RECOMPILE menggunakan petunjuk, nilai parameter dan nilai variabel lokal saat ini di-sniffed. Nilai yang di-sniff (parameter dan variabel lokal) adalah nilai yang ada di tempat dalam batch tepat sebelum pernyataan dengan RECOMPILE petunjuk. Secara khusus, untuk parameter, nilai yang disertakan dengan panggilan pemanggilan batch tidak di-sniff.
Pemrosesan kueri paralel
SQL Server menyediakan kueri paralel untuk mengoptimalkan eksekusi kueri dan operasi indeks untuk komputer yang memiliki lebih dari satu microprocessor (CPU). Karena SQL Server dapat melakukan operasi kueri atau indeks secara paralel dengan menggunakan beberapa utas pekerja sistem operasi, operasi dapat diselesaikan dengan cepat dan efisien.
Selama pengoptimalan kueri, SQL Server mencari kueri atau operasi indeks yang mungkin mendapat manfaat dari eksekusi paralel. Untuk kueri ini, SQL Server menyisipkan operator pertukaran ke dalam rencana eksekusi kueri untuk menyiapkan kueri untuk eksekusi paralel. Operator pertukaran adalah operator dalam rencana eksekusi kueri yang menyediakan manajemen proses, redistribusi data, dan kontrol alur. Operator pertukaran mencakup Distribute Streamsoperator logis , Repartition Streams, dan Gather Streams sebagai subjenis, satu atau beberapa di antaranya dapat muncul dalam output Showplan dari rencana kueri untuk kueri paralel.
Penting
Konstruksi tertentu menghambat kemampuan SQL Server untuk menggunakan paralelisme pada seluruh rencana eksekusi, atau bagian atau rencana eksekusi.
Konstruksi yang menghambat paralelisme meliputi:
UDF skalar
Untuk informasi selengkapnya tentang fungsi skalar yang ditentukan pengguna, lihat Membuat Fungsi yang ditentukan pengguna. Dimulai dengan SQL Server 2019 (15.x), Mesin Database SQL Server memiliki kemampuan untuk menginline fungsi-fungsi ini, dan membuka kunci penggunaan paralelisme selama pemrosesan kueri. Untuk informasi selengkapnya tentang inlining UDF skalar, lihat Pemrosesan kueri cerdas dalam database SQL.Kueri Jarak Jauh
Untuk informasi selengkapnya tentang Kueri Jarak Jauh, lihat Referensi Operator Logis dan Fisik Showplan.Kursor dinamis
Untuk informasi selengkapnya tentang kursor, lihat MENDEKLARASIKAN KURSOR.Kueri rekursif
Untuk informasi selengkapnya tentang rekursi, lihat Panduan untuk Menentukan dan Menggunakan Ekspresi dan Rekursi Tabel Umum Rekursif di T-SQL.Fungsi bernilai tabel multi-pernyataan (MSTVF)
Untuk informasi selengkapnya tentang MSTVF, lihat Membuat Fungsi yang Ditentukan Pengguna (Mesin Database).Kata kunci TERATAS
Untuk informasi selengkapnya, lihat TOP (Transact-SQL).
Rencana eksekusi kueri dapat berisi atribut NonParallelPlanReason dalam elemen QueryPlan , yang menjelaskan mengapa paralelisme tidak digunakan. Nilai untuk atribut ini meliputi:
| Nilai NonParallelPlanReason | Deskripsi |
|---|---|
| MaxDOPSetToOne | Tingkat paralelisme maksimum diatur ke 1. |
| EstimasiDOPIsOne | Estimasi tingkat paralelisme adalah 1. |
| NoParallelWithRemoteQuery | Paralelisme tidak didukung untuk kueri jarak jauh. |
| NoParallelDynamicCursor | Paket paralel tidak didukung untuk kursor dinamis. |
| NoParallelFastForwardCursor | Paket paralel tidak didukung untuk kursor maju cepat. |
| NoParallelCursorFetchByBookmark | Paket paralel tidak didukung untuk kursor yang diambil oleh bookmark. |
| NoParallelCreateIndexInNonEnterpriseEdition | Pembuatan indeks paralel tidak didukung untuk edisi non-Enterprise. |
| NoParallelPlansInDesktopOrExpressEdition | Paket paralel tidak didukung untuk edisi Desktop dan Ekspres. |
| NonParallelizableIntrinsicFunction | Kueri mereferensikan fungsi intrinsik yang tidak dapat diparalelkan. |
| CLRUserDefinedFunctionRequiresDataAccess | Paralelisme tidak didukung untuk CLR UDF yang memerlukan akses data. |
| TSQLUserDefinedFunctionsNotParallelizable | Kueri mereferensikan Fungsi yang Ditentukan Pengguna T-SQL yang tidak dapat diparalelkan. |
| TableVariableTransactionsDoNotSupportParallelNestedTransaction | Transaksi variabel tabel tidak mendukung transaksi berlapis paralel. |
| DMLQueryReturnsOutputToClient | Kueri DML mengembalikan output ke klien dan tidak dapat diparalelkan. |
| MixedSerialAndParallelOnlineIndexBuildNotSupported | Campuran paket serial dan paralel yang tidak didukung untuk satu build indeks online. |
| CouldNotGenerateValidParallelPlan | Memverifikasi rencana paralel gagal, gagal kembali ke serial. |
| NoParallelForMemoryOptimizedTables | Paralelisme tidak didukung untuk tabel OLTP Dalam Memori yang direferensikan. |
| NoParallelForDmlOnMemoryOptimizedTable | Paralelisme tidak didukung untuk DML pada tabel OLTP Dalam Memori. |
| NoParallelForNativelyCompiledModule | Paralelisme tidak didukung untuk modul yang dikompilasi secara asli yang direferensikan. |
| NoRangesResumableBuat | Pembuatan rentang gagal untuk operasi pembuatan yang dapat dilanjutkan. |
Setelah operator pertukaran disisipkan, hasilnya adalah rencana eksekusi kueri paralel. Rencana eksekusi kueri paralel dapat menggunakan lebih dari satu utas pekerja. Rencana eksekusi serial, yang digunakan oleh kueri non-paralel (serial), hanya menggunakan satu utas pekerja untuk eksekusinya. Jumlah aktual utas pekerja yang digunakan oleh kueri paralel ditentukan pada inisialisasi eksekusi rencana kueri dan ditentukan oleh kompleksitas rencana dan tingkat paralelisme.
Tingkat paralelisme (DOP) menentukan jumlah maksimum CPU yang digunakan; bukan berarti jumlah utas pekerja yang sedang digunakan. Batas DOP diatur per tugas. Ini bukan batas per permintaan atau per kueri. Ini berarti bahwa selama eksekusi kueri paralel, satu permintaan dapat menelurkan beberapa tugas yang ditetapkan ke penjadwal. Lebih banyak prosesor daripada yang ditentukan oleh MAXDOP dapat digunakan secara bersamaan pada titik eksekusi kueri tertentu, ketika tugas yang berbeda dijalankan secara bersamaan. Untuk informasi selengkapnya, lihat Panduan Arsitektur Utas dan Tugas.
Pengoptimal Kueri SQL Server tidak menggunakan rencana eksekusi paralel untuk kueri jika salah satu kondisi berikut ini benar:
- Rencana eksekusi serial sepele, atau tidak melebihi ambang biaya untuk pengaturan paralelisme.
- Rencana eksekusi serial memiliki total estimasi biaya subtree yang lebih rendah daripada rencana eksekusi paralel yang dieksplorasi oleh pengoptimal.
- Kueri berisi operator skalar atau relasional yang tidak dapat dijalankan secara paralel. Operator tertentu dapat menyebabkan bagian rencana kueri berjalan dalam mode serial, atau seluruh rencana berjalan dalam mode serial.
Catatan
Perkiraan total biaya subtree dari paket paralel dapat lebih rendah dari ambang biaya untuk pengaturan paralelisme. Ini menunjukkan bahwa perkiraan total biaya subtree dari rencana serial melebihinya, dan rencana kueri dengan total estimasi biaya subtree yang lebih rendah dipilih.
Tingkat paralelisme (DOP)
SQL Server secara otomatis mendeteksi tingkat paralelisme terbaik untuk setiap instans eksekusi kueri paralel atau operasi bahasa definisi data indeks (DDL). Ini dilakukan berdasarkan kriteria berikut:
Apakah SQL Server berjalan di komputer yang memiliki lebih dari satu microprocessor atau CPU, seperti komputer multiproscessing simetris (SMP). Hanya komputer yang memiliki lebih dari satu CPU yang dapat menggunakan kueri paralel.
Apakah utas pekerja yang memadai tersedia. Setiap kueri atau operasi indeks memerlukan sejumlah utas pekerja untuk dijalankan. Menjalankan rencana paralel membutuhkan lebih banyak utas pekerja daripada rencana serial, dan jumlah utas pekerja yang diperlukan meningkat dengan tingkat paralelisme. Ketika persyaratan utas pekerja dari rencana paralel untuk tingkat paralelisme tertentu tidak dapat dipenuhi, Mesin Database SQL Server mengurangi tingkat paralelisme secara otomatis atau sepenuhnya meninggalkan rencana paralel dalam konteks beban kerja yang ditentukan. Kemudian menjalankan rencana serial (satu utas pekerja).
Jenis operasi kueri atau indeks yang dijalankan. Operasi indeks yang membuat atau membangun kembali indeks, atau menghilangkan indeks berkluster dan kueri yang menggunakan siklus CPU sangat merupakan kandidat terbaik untuk rencana paralel. Misalnya, gabungan tabel besar, agregasi besar, dan pengurutan kumpulan hasil besar adalah kandidat yang baik. Kueri sederhana, sering ditemukan dalam aplikasi pemrosesan transaksi, temukan koordinasi tambahan yang diperlukan untuk menjalankan kueri secara paralel melebihi potensi peningkatan performa. Untuk membedakan antara kueri yang mendapat manfaat dari paralelisme dan yang tidak menguntungkan, Mesin Database SQL Server membandingkan perkiraan biaya eksekusi operasi kueri atau indeks dengan ambang biaya untuk nilai paralelisme . Pengguna dapat mengubah nilai default 5 menggunakan sp_configure jika pengujian yang tepat menemukan bahwa nilai yang berbeda lebih cocok untuk beban kerja yang sedang berjalan.
Apakah ada jumlah baris yang cukup untuk diproses. Jika Pengoptimal Kueri menentukan bahwa jumlah baris terlalu rendah, pengoptimal kueri tidak memperkenalkan operator pertukaran untuk mendistribusikan baris. Dengan demikian, operator dijalankan secara serial. Menjalankan operator dalam rencana serial menghindari skenario ketika biaya startup, distribusi, dan koordinasi melebihi keuntungan yang dicapai oleh eksekusi operator paralel.
Apakah statistik distribusi saat ini tersedia. Jika tingkat paralelisme tertinggi tidak dimungkinkan, derajat yang lebih rendah dipertimbangkan sebelum rencana paralel ditinggalkan. Misalnya, saat Anda membuat indeks berkluster pada tampilan, statistik distribusi tidak dapat dievaluasi, karena indeks berkluster belum ada. Dalam hal ini, Mesin Database SQL Server tidak dapat memberikan tingkat paralelisme tertinggi untuk operasi indeks. Namun, beberapa operator, seperti pengurutan dan pemindaian, masih dapat memperoleh manfaat dari eksekusi paralel.
Catatan
Operasi indeks paralel hanya tersedia di edisi SQL Server Enterprise, Developer, dan Evaluation.
Pada waktu eksekusi, Mesin Database SQL Server menentukan apakah beban kerja sistem saat ini dan informasi konfigurasi yang dijelaskan sebelumnya memungkinkan eksekusi paralel. Jika eksekusi paralel dijaga, Mesin Database SQL Server menentukan jumlah utas pekerja yang optimal dan menyebarkan eksekusi rencana paralel di seluruh utas pekerja tersebut. Saat operasi kueri atau indeks mulai dijalankan pada beberapa utas pekerja untuk eksekusi paralel, jumlah utas pekerja yang sama digunakan hingga operasi selesai. Mesin Database SQL Server memeriksa kembali jumlah keputusan utas pekerja yang optimal setiap kali rencana eksekusi diambil dari cache rencana. Misalnya, satu eksekusi kueri dapat mengakibatkan penggunaan rencana serial, eksekusi kueri yang sama nanti dapat mengakibatkan rencana paralel menggunakan tiga utas pekerja, dan eksekusi ketiga dapat menghasilkan rencana paralel menggunakan empat utas pekerja.
Operator pembaruan dan penghapusan dalam rencana eksekusi kueri paralel dijalankan secara serial, tetapi WHERE klausul UPDATE pernyataan atau DELETE mungkin dijalankan secara paralel. Perubahan data aktual kemudian diterapkan secara serial ke database.
Hingga SQL Server 2012 (11.x), operator sisipan juga dijalankan secara serial. Namun, bagian SELECT dari pernyataan INSERT mungkin dijalankan secara paralel. Perubahan data aktual kemudian diterapkan secara serial ke database.
Dimulai dengan SQL Server 2014 (12.x) dan kompatibilitas database tingkat 110, SELECT ... INTO pernyataan dapat dijalankan secara paralel. Bentuk operator sisipan lainnya berfungsi dengan cara yang sama seperti yang dijelaskan untuk SQL Server 2012 (11.x).
Dimulai dengan SQL Server 2016 (13.x) dan kompatibilitas database tingkat 130, INSERT ... SELECT pernyataan dapat dijalankan secara paralel saat memasukkan ke timbunan atau indeks penyimpan kolom terkluster (CCI), dan menggunakan petunjuk TABLOCK. Penyisipan ke dalam tabel sementara lokal (diidentifikasi oleh awalan #) dan tabel sementara global (diidentifikasi oleh awalan ##) juga diaktifkan untuk paralelisme menggunakan petunjuk TABLOCK. Untuk informasi selengkapnya, lihat INSERT (Transact-SQL).
Kursor statis dan berbasis keyset dapat diisi oleh rencana eksekusi paralel. Namun, perilaku kursor dinamis hanya dapat disediakan oleh eksekusi serial. Pengoptimal Kueri selalu menghasilkan rencana eksekusi serial untuk kueri yang merupakan bagian dari kursor dinamis.
Mengambil alih tingkat paralelisme
Tingkat paralelisme mengatur jumlah prosesor yang akan digunakan dalam eksekusi rencana paralel. Konfigurasi ini dapat diatur pada berbagai tingkatan:
Tingkat server, menggunakan opsi konfigurasi server tingkat paralelisme maksimum (MAXDOP).
Berlaku untuk: SQL ServerCatatan
SQL Server 2019 (15.x) memperkenalkan rekomendasi otomatis untuk mengatur opsi konfigurasi server MAXDOP selama proses penginstalan. Antarmuka pengguna penyiapan memungkinkan Anda menerima pengaturan yang direkomendasikan atau memasukkan nilai Anda sendiri. Untuk informasi selengkapnya, lihat Halaman Konfigurasi Mesin Database - MaxDOP.
Tingkat beban kerja, menggunakan opsi konfigurasi grup beban kerja Resource Governor MAX_DOP.
Berlaku untuk: SQL ServerTingkat database, menggunakan konfigurasi cakupan database MAXDOP.
Berlaku untuk: SQL Server dan Azure SQL DatabaseTingkat pernyataan kueri atau indeks, menggunakan petunjuk kueri MAXDOP atau opsi indeks MAXDOP. Misalnya, Anda dapat menggunakan opsi MAXDOP untuk mengontrol, dengan meningkatkan atau mengurangi, jumlah prosesor yang didedikasikan untuk operasi indeks online. Dengan cara ini, Anda dapat menyeimbangkan sumber daya yang digunakan oleh operasi indeks dengan pengguna bersamaan.
Berlaku untuk: SQL Server dan Azure SQL Database
Mengatur tingkat maksimum opsi paralelisme ke 0 (default) memungkinkan SQL Server menggunakan semua prosesor yang tersedia hingga maksimum 64 prosesor dalam eksekusi rencana paralel. Meskipun SQL Server menetapkan target runtime 64 prosesor logis ketika opsi MAXDOP diatur ke 0, nilai yang berbeda dapat diatur secara manual jika diperlukan. Mengatur MAXDOP ke 0 untuk kueri dan indeks memungkinkan SQL Server menggunakan semua prosesor yang tersedia hingga maksimum 64 prosesor untuk kueri atau indeks yang diberikan dalam eksekusi rencana paralel. MAXDOP bukan nilai yang diberlakukan untuk semua kueri paralel, melainkan target tentatif untuk semua kueri yang memenuhi syarat untuk paralelisme. Ini berarti bahwa jika tidak cukup utas pekerja yang tersedia saat runtime, kueri mungkin dijalankan dengan tingkat paralelisme yang lebih rendah daripada opsi konfigurasi server MAXDOP.
Tip
Untuk informasi selengkapnya, lihat Rekomendasi MAXDOP untuk panduan tentang mengonfigurasi MAXDOP di tingkat server, database, kueri, atau petunjuk.
Contoh kueri paralel
Kueri berikut menghitung jumlah pesanan yang ditempatkan dalam kuartal tertentu, mulai tanggal 1 April 2000, dan di mana setidaknya satu item baris pesanan diterima oleh pelanggan lebih lambat dari tanggal yang diterapkan. Kueri ini mencantumkan jumlah pesanan tersebut yang dikelompokkan menurut setiap prioritas pesanan dan diurutkan dalam urutan prioritas naik.
Contoh ini menggunakan nama tabel dan kolom teoritis.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Asumsikan indeks berikut ditentukan pada lineitem tabel dan orders :
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Berikut adalah salah satu kemungkinan rencana paralel yang dihasilkan untuk kueri yang sebelumnya diperlihatkan:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
Ilustrasi di bawah ini menunjukkan rencana kueri yang dijalankan dengan tingkat paralelisme sama dengan 4 dan melibatkan gabungan dua tabel.
Rencana paralel berisi tiga operator paralelisme. Operator Pencarian o_datkey_ptr Indeks indeks dan operator Pemindaian l_order_dates_idx Indeks indeks dilakukan secara paralel. Ini menghasilkan beberapa aliran eksklusif. Ini dapat ditentukan dari operator Paralelisme terdekat di atas operator Pemindaian Indeks dan Pencarian Indeks. Keduanya mempartisi ulang jenis pertukaran. Artinya, mereka hanya mereshuffling data di antara aliran dan menghasilkan jumlah aliran yang sama pada output mereka seperti yang mereka miliki pada input mereka. Jumlah aliran ini sama dengan tingkat paralelisme.
Operator paralelisme di atas l_order_dates_idx operator Pemindaian Indeks mempartisi ulang aliran inputnya menggunakan nilai L_ORDERKEY sebagai kunci. Dengan cara ini, nilai L_ORDERKEY yang sama berakhir di aliran output yang sama. Pada saat yang sama, aliran output mempertahankan urutan pada L_ORDERKEY kolom untuk memenuhi persyaratan input operator Gabungkan.
Operator paralelisme di atas operator Pencarian Indeks mempartisi ulang aliran inputnya menggunakan nilai O_ORDERKEY. Karena inputnya tidak diurutkan pada O_ORDERKEY nilai kolom dan ini adalah kolom gabungan di Merge Join operator, operator Urutkan antara operator paralelisme dan Gabungkan Gabungan memastikan bahwa input diurutkan untuk Merge Join operator pada kolom gabungan. Operator Sort , seperti operator Gabungkan, dilakukan secara paralel.
Operator paralelisme paling atas mengumpulkan hasil dari beberapa aliran ke dalam satu aliran. Agregasi parsial yang dilakukan oleh operator Agregat Aliran di bawah operator paralelisme kemudian diakumulasikan ke dalam satu SUM nilai untuk setiap nilai O_ORDERPRIORITY yang berbeda dari di operator Agregat Aliran di atas operator paralelisme. Karena rencana ini memiliki dua segmen pertukaran, dengan tingkat paralelisme sama dengan 4, rencana ini menggunakan delapan utas pekerja.
Untuk informasi selengkapnya tentang operator yang digunakan dalam contoh ini, lihat Referensi Operator Logis dan Fisik Showplan.
Operasi indeks paralel
Rencana kueri yang dibuat untuk operasi indeks yang membuat atau membangun kembali indeks, atau menghilangkan indeks berkluster, memungkinkan operasi utas paralel multi-pekerja pada komputer yang memiliki beberapa mikroprosesor.
Catatan
Operasi indeks paralel hanya tersedia di Enterprise Edition, dimulai dengan SQL Server 2008 (10.0.x).
SQL Server menggunakan algoritma yang sama untuk menentukan tingkat paralelisme (jumlah total utas pekerja terpisah untuk dijalankan) untuk operasi indeks seperti yang dilakukan untuk kueri lain. Tingkat paralelisme maksimum untuk operasi indeks tunduk pada tingkat maksimum opsi konfigurasi server paralelisme . Anda dapat mengambil alih tingkat maksimum nilai paralelisme untuk operasi indeks individual dengan mengatur opsi indeks MAXDOP dalam pernyataan CREATE INDEX, ALTER INDEX, DROP INDEX, dan ALTER TABLE.
Ketika Mesin Database SQL Server membangun rencana eksekusi indeks, jumlah operasi paralel diatur ke nilai terendah dari antara yang berikut ini:
- Jumlah mikroprosedor, atau CPU di komputer.
- Angka yang ditentukan dalam tingkat maksimum opsi konfigurasi server paralelisme.
- Jumlah CPU yang belum melebihi ambang batas pekerjaan yang dilakukan untuk utas pekerja SQL Server.
Misalnya, pada komputer yang memiliki delapan CPU, tetapi di mana tingkat paralelisme maksimum diatur ke 6, tidak lebih dari enam utas pekerja paralel dihasilkan untuk operasi indeks. Jika lima CPU di komputer melebihi ambang batas pekerjaan SQL Server saat rencana eksekusi indeks dibangun, rencana eksekusi hanya menentukan tiga utas pekerja paralel.
Fase utama operasi indeks paralel meliputi yang berikut ini:
- Utas pekerja koordinator dengan cepat dan acak memindai tabel untuk memperkirakan distribusi kunci indeks. Utas pekerja koordinator menetapkan batas kunci yang akan membuat sejumlah rentang kunci yang sama dengan tingkat operasi paralel, di mana setiap rentang kunci diperkirakan mencakup jumlah baris yang sama. Misalnya, jika ada empat juta baris dalam tabel dan tingkat paralelisme adalah 4, utas pekerja koordinasi akan menentukan nilai kunci yang memisahkan empat set baris dengan 1 juta baris di setiap set. Jika rentang kunci yang cukup tidak dapat dibuat untuk menggunakan semua CPU, tingkat paralelisme dikurangi.
- Utas pekerja koordinator mengirimkan sejumlah utas pekerja yang sama dengan tingkat operasi paralel dan menunggu utas pekerja ini menyelesaikan pekerjaan mereka. Setiap utas pekerja memindai tabel dasar menggunakan filter yang hanya mengambil baris dengan nilai kunci dalam rentang yang ditetapkan ke utas pekerja. Setiap utas pekerja membangun struktur indeks untuk baris dalam rentang kuncinya. Dalam kasus indeks yang dipartisi, setiap utas pekerja membangun sejumlah partisi tertentu. Partisi tidak dibagikan di antara utas pekerja.
- Setelah semua utas pekerja paralel selesai, utas pekerja koordinasi menghubungkan subunit indeks ke dalam satu indeks. Fase ini hanya berlaku untuk operasi indeks offline.
Individu CREATE TABLE atau ALTER TABLE pernyataan dapat memiliki beberapa batasan yang mengharuskan indeks dibuat. Beberapa operasi pembuatan indeks ini dilakukan secara seri, meskipun setiap operasi pembuatan indeks individu mungkin merupakan operasi paralel pada komputer yang memiliki beberapa CPU.
Arsitektur kueri terdistribusi
Microsoft SQL Server mendukung dua metode untuk mereferensikan sumber data OLE DB heterogen dalam pernyataan Transact-SQL:
Nama server tertaut
Prosedur tersimpansp_addlinkedserversistem dansp_addlinkedsrvlogindigunakan untuk memberikan nama server ke sumber data OLE DB. Objek di server tertaut ini dapat direferensikan dalam pernyataan Transact-SQL menggunakan nama empat bagian. Misalnya, jika namaDeptSQLSrvrserver tertaut didefinisikan terhadap instans SQL Server lain, pernyataan berikut mereferensikan tabel di server tersebut:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;Nama server yang ditautkan juga dapat ditentukan dalam
OPENQUERYpernyataan untuk membuka set baris dari sumber data OLE DB. Kumpulan baris ini kemudian dapat dirujuk seperti tabel dalam pernyataan Transact-SQL.Nama konektor ad hoc
Untuk referensi yang jarang ke sumber data,OPENROWSETfungsi atauOPENDATASOURCEditentukan dengan informasi yang diperlukan untuk menyambungkan ke server tertaut. Kumpulan baris kemudian dapat dirujuk dengan cara yang sama seperti tabel dirujuk dalam pernyataan Transact-SQL:SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server menggunakan OLE DB untuk berkomunikasi antara mesin relasional dan mesin penyimpanan. Mesin relasional memecah setiap pernyataan Transact-SQL menjadi serangkaian operasi pada set baris OLE DB sederhana yang dibuka oleh mesin penyimpanan dari tabel dasar. Ini berarti mesin relasional juga dapat membuka set baris OLE DB sederhana pada sumber data OLE DB apa pun.
Mesin relasional menggunakan antarmuka pemrograman aplikasi (API) OLE DB untuk membuka set baris di server tertaut, mengambil baris, dan mengelola transaksi.
Untuk setiap sumber data OLE DB yang diakses sebagai server tertaut, penyedia OLE DB harus ada di server yang menjalankan SQL Server. Kumpulan operasi Transact-SQL yang dapat digunakan terhadap sumber data OLE DB tertentu bergantung pada kemampuan penyedia OLE DB.
Untuk setiap instans SQL Server, anggota sysadmin peran server tetap dapat mengaktifkan atau menonaktifkan penggunaan nama konektor ad hoc untuk penyedia OLE DB menggunakan properti SQL Server DisallowAdhocAccess . Saat akses ad hoc diaktifkan, setiap pengguna yang masuk ke instans tersebut dapat menjalankan pernyataan Transact-SQL yang berisi nama konektor ad hoc, merujuk sumber data apa pun di jaringan yang dapat diakses menggunakan penyedia OLE DB tersebut. Untuk mengontrol akses ke sumber data, anggota sysadmin peran dapat menonaktifkan akses ad hoc untuk penyedia OLE DB tersebut, sehingga membatasi pengguna hanya untuk sumber data yang direferensikan oleh nama server tertaut yang ditentukan oleh administrator. Secara default, akses ad hoc diaktifkan untuk penyedia SQL Server OLE DB, dan dinonaktifkan untuk semua penyedia OLE DB lainnya.
Kueri terdistribusi dapat memungkinkan pengguna mengakses sumber data lain (misalnya, file, sumber data non-relasional seperti Direktori Aktif, dan sebagainya) menggunakan konteks keamanan akun Microsoft Windows tempat layanan SQL Server berjalan. SQL Server meniru login dengan tepat untuk login Windows; namun, itu tidak mungkin untuk login SQL Server. Ini berpotensi memungkinkan pengguna kueri terdistribusi mengakses sumber data lain yang tidak memiliki izin, tetapi akun tempat layanan SQL Server berjalan memang memiliki izin. Gunakan sp_addlinkedsrvlogin untuk menentukan login tertentu yang berwenang untuk mengakses server tertaut yang sesuai. Kontrol ini tidak tersedia untuk nama ad hoc, jadi berhati-hatilah dalam mengaktifkan penyedia OLE DB untuk akses ad hoc.
Jika memungkinkan, SQL Server mendorong operasi relasional seperti gabungan, pembatasan, proyeksi, pengurutan, dan operasi kelompokkan menurut ke sumber data OLE DB. SQL Server tidak default untuk memindai tabel dasar ke SQL Server dan melakukan operasi relasional itu sendiri. SQL Server meminta penyedia OLE DB untuk menentukan tingkat tata bahasa SQL yang didukungnya, dan, berdasarkan informasi tersebut, mendorong operasi relasional sebanyak mungkin kepada penyedia.
SQL Server menentukan mekanisme bagi penyedia OLE DB untuk mengembalikan statistik yang menunjukkan bagaimana nilai kunci didistribusikan dalam sumber data OLE DB. Ini memungkinkan Pengoptimal Kueri SQL Server menganalisis pola data dalam sumber data dengan lebih baik terhadap persyaratan setiap pernyataan Transact-SQL, meningkatkan kemampuan Pengoptimal Kueri untuk menghasilkan rencana eksekusi yang optimal.
Penyempurnaan pemrosesan kueri pada tabel dan indeks yang dipartisi
SQL Server 2008 (10.0.x) meningkatkan performa pemrosesan kueri pada tabel yang dipartisi untuk banyak rencana paralel, mengubah cara rencana paralel dan serial diwakili, dan meningkatkan informasi partisi yang disediakan dalam rencana eksekusi waktu kompilasi dan run-time. Artikel ini menjelaskan peningkatan ini, memberikan panduan tentang cara menginterpretasikan rencana eksekusi kueri tabel dan indeks yang dipartisi, dan menyediakan praktik terbaik untuk meningkatkan performa kueri pada objek yang dipartisi.
Catatan
Hingga SQL Server 2014 (12.x), tabel dan indeks yang dipartisi hanya didukung di edisi SQL Server Enterprise, Developer, dan Evaluation. Dimulai dengan SQL Server 2016 (13.x) SP1, tabel dan indeks yang dipartisi juga didukung dalam edisi Standar SQL Server.
Operasi pencarian sadar partisi baru
Di SQL Server, representasi internal tabel yang dipartisi diubah sehingga tabel muncul ke prosesor kueri menjadi indeks multikolom dengan PartitionID sebagai kolom utama. PartitionID adalah kolom komputasi tersembunyi yang digunakan secara internal untuk mewakili ID partisi yang berisi baris tertentu. Misalnya, asumsikan tabel T, didefinisikan sebagai T(a, b, c), dipartisi pada kolom a, dan memiliki indeks berkluster pada kolom b. Di SQL Server, tabel yang dipartisi ini diperlakukan secara internal sebagai tabel nonpartisi dengan skema T(PartitionID, a, b, c) dan indeks berkluster pada kunci (PartitionID, b)komposit . Ini memungkinkan Pengoptimal Kueri untuk melakukan operasi pencarian berdasarkan PartitionID tabel atau indeks yang dipartisi apa pun.
Penghapusan partisi sekarang dilakukan dalam operasi pencarian ini.
Selain itu, Pengoptimal Kueri diperluas sehingga operasi pencarian atau pemindaian dengan satu kondisi dapat dilakukan pada PartitionID (sebagai kolom utama logis) dan mungkin kolom kunci indeks lainnya, lalu pencarian tingkat kedua, dengan kondisi yang berbeda, dapat dilakukan pada satu atau beberapa kolom tambahan, untuk setiap nilai berbeda yang memenuhi kualifikasi untuk operasi pencarian tingkat pertama. Artinya, operasi ini, yang disebut pemindaian lewati, memungkinkan Pengoptimal Kueri untuk melakukan operasi pencarian atau pemindaian berdasarkan satu kondisi untuk menentukan partisi yang akan diakses dan indeks tingkat kedua mencari operasi dalam operator tersebut untuk mengembalikan baris dari partisi ini yang memenuhi kondisi yang berbeda. Misalnya, pertimbangkan kueri berikut.
SELECT * FROM T WHERE a < 10 and b = 2;
Untuk contoh ini, asumsikan bahwa tabel T, didefinisikan sebagai T(a, b, c), dipartisi pada kolom a, dan memiliki indeks berkluster pada kolom b. Batas partisi untuk tabel T ditentukan oleh fungsi partisi berikut:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
Untuk menyelesaikan kueri, prosesor kueri melakukan operasi pencarian tingkat pertama untuk menemukan setiap partisi yang berisi baris yang memenuhi kondisi T.a < 10. Ini mengidentifikasi partisi yang akan diakses. Dalam setiap partisi yang diidentifikasi, prosesor kemudian melakukan pencarian tingkat kedua ke dalam indeks berkluster pada kolom b untuk menemukan baris yang memenuhi kondisi T.b = 2 dan T.a < 10.
Ilustrasi berikut adalah representasi logis dari operasi lewati pemindaian. Ini memperlihatkan tabel T dengan data dalam kolom a dan b. Partisi diberi nomor 1 hingga 4 dengan batas partisi yang ditunjukkan oleh garis vertikal putus-putus. Operasi pencarian tingkat pertama ke partisi (tidak ditampilkan dalam ilustrasi) telah menentukan bahwa partisi 1, 2, dan 3 memenuhi kondisi pencarian yang tersirat oleh partisi yang ditentukan untuk tabel dan predikat pada kolom a. Artinya, T.a < 10. Jalur yang dilalui oleh bagian pencarian tingkat kedua dari operasi lewati pemindaian diilustrasikan oleh garis melengkung. Pada dasarnya, operasi lewati pemindaian mencari ke masing-masing partisi ini untuk baris yang memenuhi kondisi b = 2. Total biaya operasi lewati pemindaian sama dengan tiga pencarian indeks terpisah.
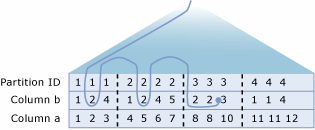
Menampilkan informasi partisi dalam rencana eksekusi kueri
Rencana eksekusi kueri pada tabel dan indeks yang dipartisi dapat diperiksa dengan menggunakan pernyataan SET SHOWPLAN_XML Transact-SQL SET atau SET STATISTICS XML, atau dengan menggunakan output rencana eksekusi grafis di SQL Server Management Studio. Misalnya, Anda dapat menampilkan rencana eksekusi waktu kompilasi dengan memilih Tampilkan Perkiraan Rencana Eksekusi pada toolbar Editor Kueri dan rencana run-time dengan memilih Sertakan Rencana Eksekusi Aktual.
Dengan menggunakan alat-alat ini, Anda dapat memastikan informasi berikut:
- Operasi seperti
scans, ,seeksinserts,updates,merges, dandeletesyang mengakses tabel atau indeks yang dipartisi. - Partisi yang diakses oleh kueri. Misalnya, jumlah total partisi yang diakses dan rentang partisi berdekatan yang diakses tersedia dalam rencana eksekusi run-time.
- Ketika operasi lewati pemindaian digunakan dalam operasi pencarian atau pemindaian untuk mengambil data dari satu atau beberapa partisi.
Penyempurnaan informasi partisi
SQL Server menyediakan informasi partisi yang ditingkatkan untuk rencana eksekusi waktu kompilasi dan run-time. Rencana eksekusi sekarang memberikan informasi berikut:
- Atribut opsional
Partitionedyang menunjukkan bahwa operator, sepertiseek, ,scan,insertupdate,merge, ataudelete, dilakukan pada tabel yang dipartisi. - Elemen baru
SeekPredicateNewdenganSeekKeyssubelemen yang menyertakanPartitionIDsebagai kolom kunci indeks terkemuka dan kondisi filter yang menentukan rentang yang dicari padaPartitionID. Kehadiran duaSeekKeyssubelemen menunjukkan bahwa operasiPartitionIDlewati pemindaian digunakan. - Informasi ringkasan yang menyediakan jumlah total partisi yang diakses. Informasi ini hanya tersedia dalam paket run-time.
Untuk menunjukkan bagaimana informasi ini ditampilkan dalam output rencana eksekusi grafis dan output XML Showplan, pertimbangkan kueri berikut pada tabel fact_salesyang dipartisi . Kueri ini memperbarui data dalam dua partisi.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
Ilustrasi berikut menunjukkan properti Clustered Index Seek operator dalam rencana eksekusi runtime untuk kueri ini. Untuk melihat definisi fact_sales tabel dan definisi partisi, lihat "Contoh" di artikel ini.

Atribut yang dipartisi
Saat operator seperti Pencarian Indeks dijalankan pada tabel atau indeks yang dipartisi, Partitioned atribut muncul dalam paket waktu kompilasi dan run-time, dan diatur ke True (1). Atribut tidak ditampilkan saat diatur ke False (0).
Atribut Partitioned dapat muncul di operator fisik dan logis berikut:
- Pemindaian Tabel
- Pemindaian Indeks
- Pencarian Indeks
- Sisipkan
- Update
- Delete
- Penggabungan
Seperti yang ditunjukkan pada ilustrasi sebelumnya, atribut ini ditampilkan di properti operator tempat ia didefinisikan. Dalam output Xml Showplan, atribut ini muncul seperti Partitioned="1" pada simpul RelOp operator tempat ia didefinisikan.
Predikat pencarian baru
Dalam output Xml Showplan, SeekPredicateNew elemen muncul di operator tempatnya ditentukan. Ini dapat berisi hingga dua kemunculan SeekKeys subelemen. Item pertama SeekKeys menentukan operasi pencarian tingkat pertama pada tingkat ID partisi indeks logis. Artinya, pencarian ini menentukan partisi yang harus diakses untuk memenuhi kondisi kueri. Item kedua SeekKeys menentukan bagian pencarian tingkat kedua dari operasi lewati pemindaian yang terjadi dalam setiap partisi yang diidentifikasi dalam pencarian tingkat pertama.
Informasi ringkasan partisi
Dalam rencana eksekusi run-time, informasi ringkasan partisi menyediakan hitungan partisi yang diakses dan identitas partisi aktual yang diakses. Anda dapat menggunakan informasi ini untuk memverifikasi bahwa partisi yang benar diakses dalam kueri dan bahwa semua partisi lain dihilangkan dari pertimbangan.
Informasi berikut disediakan: Actual Partition Count, dan Partitions Accessed.
Actual Partition Count adalah jumlah total partisi yang diakses oleh kueri.
Partitions Accessed, dalam output XML Showplan, adalah informasi ringkasan partisi yang muncul di elemen baru RuntimePartitionSummary dalam RelOp simpul operator tempatnya ditentukan. Contoh berikut menunjukkan konten RuntimePartitionSummary elemen, menunjukkan bahwa dua total partisi diakses (partisi 2 dan 3).
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Menampilkan informasi partisi dengan menggunakan metode Showplan lainnya
Metode Showplan SHOWPLAN_ALL, SHOWPLAN_TEXT, dan STATISTICS PROFILE tidak melaporkan informasi partisi yang dijelaskan dalam artikel ini, dengan pengecualian berikut. Sebagai bagian SEEK dari predikat, partisi yang akan diakses diidentifikasi oleh predikat rentang pada kolom komputasi yang mewakili ID partisi. Contoh berikut menunjukkan SEEK predikat untuk Clustered Index Seek operator. Partisi 2 dan 3 diakses, dan operator pencarian memfilter pada baris yang memenuhi kondisi date_id BETWEEN 20080802 AND 20080902.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Menginterpretasikan rencana eksekusi untuk tumpukan yang dipartisi
Tumpukan yang dipartisi diperlakukan sebagai indeks logis pada ID partisi. Penghapusan partisi pada tumpukan yang dipartisi diwakili dalam rencana eksekusi sebagai Table Scan operator dengan SEEK predikat pada ID partisi. Contoh berikut menunjukkan informasi Showplan yang disediakan:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Menginterpretasikan rencana eksekusi untuk gabungan yang dikolokasi
Kolokasi gabungan dapat terjadi ketika dua tabel dipartisi menggunakan fungsi partisi yang sama atau setara dan kolom partisi dari kedua sisi gabungan ditentukan dalam kondisi gabungan kueri. Pengoptimal Kueri dapat menghasilkan rencana di mana partisi setiap tabel yang memiliki ID partisi yang sama digabungkan secara terpisah. Gabungan yang dikolokasi dapat lebih cepat daripada gabungan yang tidak dikolokasi karena dapat membutuhkan lebih sedikit memori dan waktu pemrosesan. Pengoptimal Kueri memilih paket yang tidak dikolokasi atau paket yang dikolokasi berdasarkan perkiraan biaya.
Dalam paket yang dikolokasi, Nested Loops gabungan membaca satu atau beberapa tabel gabungan atau partisi indeks dari sisi dalam. Angka dalam Constant Scan operator mewakili nomor partisi.
Ketika rencana paralel untuk gabungan yang dikolokasi dihasilkan untuk tabel atau indeks yang dipartisi, operator Paralelisme muncul antara Constant Scan operator gabungan dan Nested Loops . Dalam hal ini, beberapa utas pekerja di sisi luar gabungan setiap bacaan dan bekerja pada partisi yang berbeda.
Ilustrasi berikut menunjukkan rencana kueri paralel untuk gabungan yang dikolokasi.
Strategi eksekusi kueri paralel untuk objek yang dipartisi
Prosesor kueri menggunakan strategi eksekusi paralel untuk kueri yang memilih dari objek yang dipartisi. Sebagai bagian dari strategi eksekusi, prosesor kueri menentukan partisi tabel yang diperlukan untuk kueri, dan proporsi utas pekerja untuk dialokasikan ke setiap partisi. Dalam kebanyakan kasus, prosesor kueri mengalokasikan jumlah utas pekerja yang sama atau hampir sama dengan setiap partisi, lalu menjalankan kueri secara paralel di seluruh partisi. Paragraf berikut menjelaskan alokasi utas pekerja secara lebih rinci.
Jika jumlah utas pekerja kurang dari jumlah partisi, prosesor kueri menetapkan setiap utas pekerja ke partisi yang berbeda, awalnya meninggalkan satu atau beberapa partisi tanpa utas pekerja yang ditetapkan. Ketika utas pekerja selesai dieksekusi pada partisi, prosesor kueri menetapkannya ke partisi berikutnya sampai setiap partisi telah diberi satu utas pekerja. Ini adalah satu-satunya kasus di mana prosesor kueri merealokasi utas pekerja ke partisi lain.
Memperlihatkan utas pekerja yang ditetapkan ulang setelah selesai. Jika jumlah utas pekerja sama dengan jumlah partisi, prosesor kueri menetapkan satu utas pekerja ke setiap partisi. Ketika utas pekerja selesai, utas tersebut tidak dialokasikan ke partisi lain.

Jika jumlah utas pekerja lebih besar dari jumlah partisi, prosesor kueri mengalokasikan jumlah utas pekerja yang sama untuk setiap partisi. Jika jumlah utas pekerja bukan kelipatan jumlah partisi yang tepat, prosesor kueri mengalokasikan satu utas pekerja tambahan ke beberapa partisi untuk menggunakan semua utas pekerja yang tersedia. Jika hanya ada satu partisi, semua utas pekerja akan ditetapkan ke partisi tersebut. Dalam diagram di bawah ini, ada empat partisi dan 14 utas pekerja. Setiap partisi memiliki 3 utas pekerja yang ditetapkan, dan dua partisi memiliki utas pekerja tambahan, untuk total 14 penetapan utas pekerja. Ketika utas pekerja selesai, utas tersebut tidak ditetapkan kembali ke partisi lain.

Meskipun contoh di atas menyarankan cara mudah untuk mengalokasikan utas pekerja, strategi aktual lebih kompleks dan menyumbang variabel lain yang terjadi selama eksekusi kueri. Misalnya, jika tabel dipartisi dan memiliki indeks berkluster pada kolom A dan kueri memiliki klausa WHERE A IN (13, 17, 25)predikat , prosesor kueri akan mengalokasikan satu atau beberapa utas pekerja untuk masing-masing dari ketiga nilai pencarian ini (A=13, A=17, dan A=25) alih-alih setiap partisi tabel. Anda hanya perlu menjalankan kueri dalam partisi yang berisi nilai-nilai ini, dan jika semua predikat pencarian ini kebetulan berada dalam partisi tabel yang sama, semua utas pekerja akan ditetapkan ke partisi tabel yang sama.
Untuk mengambil contoh lain, misalkan tabel memiliki empat partisi pada kolom A dengan titik batas (10, 20, 30), indeks pada kolom B, dan kueri memiliki klausa WHERE B IN (50, 100, 150)predikat . Karena partisi tabel didasarkan pada nilai A, nilai B dapat terjadi di salah satu partisi tabel. Dengan demikian, prosesor kueri akan mencari masing-masing dari tiga nilai B (50, 100, 150) di masing-masing dari empat partisi tabel. Prosesor kueri akan menetapkan utas pekerja secara proporsional sehingga dapat menjalankan masing-masing dari 12 pemindaian kueri ini secara paralel.
| Partisi tabel berdasarkan kolom A | Mencari kolom B di setiap partisi tabel |
|---|---|
| Partisi Tabel 1: A < 10 | B=50, B=100, B=150 |
| Partisi Tabel 2: A >= 10 DAN A < 20 | B=50, B=100, B=150 |
| Partisi Tabel 3: A >= 20 DAN A < 30 | B=50, B=100, B=150 |
| Partisi Tabel 4: A >= 30 | B=50, B=100, B=150 |
Praktik terbaik
Untuk meningkatkan performa kueri yang mengakses sejumlah besar data dari tabel dan indeks berpartisi besar, kami merekomendasikan praktik terbaik berikut:
- Stripe setiap partisi di banyak disk. Ini sangat relevan saat menggunakan disk berputar.
- Jika memungkinkan, gunakan server dengan memori utama yang cukup agar sesuai dengan partisi yang sering diakses, atau semua partisi dalam memori, untuk mengurangi biaya I/O.
- Jika data yang Anda kueri tidak pas dalam memori, kompres tabel dan indeks. Ini akan mengurangi biaya I/O.
- Gunakan server dengan prosesor cepat dan inti prosesor sebanyak yang Anda mampu, untuk memanfaatkan kemampuan pemrosesan kueri paralel.
- Pastikan server memiliki bandwidth pengontrol I/O yang memadai.
- Buat indeks berkluster pada setiap tabel besar yang dipartisi untuk memanfaatkan pengoptimalan pemindaian pohon B.
- Ikuti rekomendasi praktik terbaik di laporan resmi, Panduan Performa Pemuatan Data, saat memuat data secara massal ke dalam tabel yang dipartisi.
Contoh
Contoh berikut membuat database pengujian yang berisi satu tabel dengan tujuh partisi. Gunakan alat yang dijelaskan sebelumnya saat menjalankan kueri dalam contoh ini untuk melihat informasi partisi untuk paket waktu kompilasi dan run-time.
Catatan
Contoh ini menyisipkan lebih dari 1 juta baris ke dalam tabel. Menjalankan contoh ini dapat memakan waktu beberapa menit tergantung pada perangkat keras Anda. Sebelum menjalankan contoh ini, verifikasi bahwa Anda memiliki lebih dari 1,5 GB ruang disk yang tersedia.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
Konten terkait
- Referensi Operator Logis dan Fisik Showplan
- Gambaran umum Kejadian yang Diperluas
- Praktik terbaik untuk memantau beban kerja dengan Penyimpanan Kueri
- Estimasi Kardinalitas (SQL Server)
- Pemrosesan kueri cerdas dalam database SQL
- Prioritas Operator (Transact-SQL)
- Gambaran umum rencana eksekusi
- Pusat Performa untuk Mesin Database SQL Server dan Azure SQL Database