Membaca Halaman
Berlaku untuk:![]() SQL Server
SQL Server
I/O dari instans Mesin Database SQL Server mencakup bacaan logis dan fisik. Pembacaan logis terjadi setiap kali Mesin Database meminta halaman dari cache buffer. Jika halaman saat ini tidak berada di cache buffer, baca fisik terlebih dahulu menyalin halaman dari disk ke dalam cache.
Permintaan baca yang dihasilkan oleh instans Mesin Database dikontrol oleh mesin relasional dan dioptimalkan oleh mesin penyimpanan. Mesin relasional menentukan metode akses yang paling efektif (seperti pemindaian tabel, pemindaian indeks, atau bacaan bertanda kunci); metode akses dan komponen manajer buffer mesin penyimpanan menentukan pola umum bacaan untuk dilakukan, dan mengoptimalkan bacaan yang diperlukan untuk mengimplementasikan metode akses. Utas yang mengeksekusi batch menjadwalkan pembacaan.
Baca-Depan
Mesin Database mendukung mekanisme pengoptimalan performa yang disebut read-ahead. Read-ahead mengantisipasi data dan halaman indeks yang diperlukan untuk memenuhi rencana eksekusi kueri dan membawa halaman ke dalam cache buffer sebelum benar-benar digunakan oleh kueri. Ini memungkinkan komputasi dan I/O untuk tumpang tindih, mengambil keuntungan penuh dari CPU dan disk.
Mekanisme read-ahead memungkinkan Mesin Database untuk membaca hingga 64 halaman yang berdekatan (512KB) dari satu file. Bacaan dilakukan sebagai pembacaan sebar tunggal yang dibaca ke jumlah buffer (mungkin tidak berdampingan) yang sesuai di cache buffer. Jika salah satu halaman dalam rentang sudah ada di cache buffer, halaman yang sesuai dari baca akan dibuang ketika baca selesai. Rentang halaman mungkin juga "dipangkas" dari kedua ujungnya jika halaman yang sesuai sudah ada di cache.
Ada dua jenis read-ahead: satu untuk halaman data dan satu untuk halaman indeks.
Membaca Halaman Data
Pemindaian tabel yang digunakan untuk membaca halaman data sangat efisien di Mesin Database. Halaman peta alokasi indeks (IAM) dalam database SQL Server mencantumkan tingkat yang digunakan oleh tabel atau indeks. Mesin penyimpanan dapat membaca IAM untuk membuat daftar alamat disk yang diurutkan yang harus dibaca. Ini memungkinkan mesin penyimpanan untuk mengoptimalkan I/Os-nya sebagai bacaan berurutan besar yang dilakukan secara berurutan, berdasarkan lokasinya pada disk. Untuk informasi selengkapnya tentang halaman IAM, lihat Mengelola Ruang yang Digunakan oleh Objek.
Membaca Halaman Indeks
Mesin penyimpanan membaca halaman indeks secara serial dalam urutan kunci. Misalnya, ilustrasi ini menunjukkan representasi yang disederhanakan dari sekumpulan halaman daun yang berisi sekumpulan kunci dan simpul indeks perantara yang memetakan halaman daun. Untuk informasi selengkapnya tentang struktur halaman dalam indeks, lihat Struktur Indeks Berkluster.
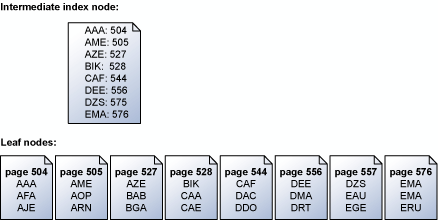
Mesin penyimpanan menggunakan informasi di halaman indeks perantara di atas tingkat daun untuk menjadwalkan read-ahead serial untuk halaman yang berisi kunci. Jika permintaan dibuat untuk semua kunci dari ABC ke DEF, mesin penyimpanan terlebih dahulu membaca halaman indeks di atas halaman daun. Namun, itu tidak hanya membaca setiap halaman data secara berurutan dari halaman 504 ke halaman 556 (halaman terakhir dengan kunci dalam rentang yang ditentukan). Sebagai gantinya, mesin penyimpanan memindai halaman indeks menengah dan membangun daftar halaman daun yang harus dibaca. Mesin penyimpanan kemudian menjadwalkan semua bacaan dalam urutan kunci. Mesin penyimpanan juga mengakui bahwa halaman 504/505 dan 527/528 berdekatan dan melakukan satu bacaan sebar untuk mengambil halaman yang berdekatan dalam satu operasi. Ketika ada banyak halaman yang akan diambil dalam operasi serial, mesin penyimpanan menjadwalkan blok baca pada satu waktu. Ketika subset bacaan ini selesai, mesin penyimpanan menjadwalkan jumlah pembacaan baru yang sama sampai semua bacaan yang diperlukan telah dijadwalkan.
Mesin penyimpanan menggunakan prefetching untuk mempercepat pencarian tabel dasar dari indeks nonclustered. Baris daun dari indeks non-kluster berisi penunjuk ke baris data yang berisi setiap nilai kunci tertentu. Saat mesin penyimpanan membaca halaman daun indeks non-kluster, mesin penyimpanan juga mulai menjadwalkan pembacaan asinkron untuk baris data yang penunjuknya telah diambil. Ini memungkinkan mesin penyimpanan untuk mengambil baris data dari tabel yang mendasar sebelum menyelesaikan pemindaian indeks nonclustered. Prefetching digunakan terlepas dari apakah tabel memiliki indeks berkluster. SQL Server Enterprise menggunakan lebih banyak prefetching daripada edisi SQL Server lainnya, memungkinkan lebih banyak halaman untuk dibaca di depan. Tingkat prefetching tidak dapat dikonfigurasi dalam edisi apa pun. Untuk informasi selengkapnya tentang indeks nonclustered, lihat Struktur Indeks Nonclustered.
Pemindaian Tingkat Lanjut
Di SQL Server Enterprise, fitur pemindaian tingkat lanjut memungkinkan beberapa tugas untuk berbagi pemindaian tabel penuh. Jika rencana eksekusi pernyataan Transact-SQL memerlukan pemindaian halaman data dalam tabel dan Mesin Database mendeteksi bahwa tabel sudah dipindai untuk rencana eksekusi lain, Mesin Database menggabungkan pemindaian kedua ke yang pertama, di lokasi pemindaian kedua saat ini. Mesin Database membaca setiap halaman satu kali dan meneruskan baris dari setiap halaman ke kedua rencana eksekusi. Ini berlanjut hingga akhir tabel tercapai.
Pada titik itu, rencana eksekusi pertama memiliki hasil lengkap pemindaian, tetapi rencana eksekusi kedua masih harus mengambil halaman data yang dibaca sebelum bergabung dengan pemindaian yang sedang berlangsung. Pemindaian untuk rencana eksekusi kedua kemudian membungkus kembali ke halaman data pertama tabel dan memindai maju ke tempatnya bergabung dengan pemindaian pertama. Sejumlah pemindaian dapat digabungkan seperti ini. Mesin Database akan terus mengulang halaman data hingga menyelesaikan semua pemindaian. Mekanisme ini juga disebut "pemindaian merry-go-round" dan menunjukkan mengapa urutan hasil yang dikembalikan dari pernyataan SELECT tidak dapat dijamin tanpa klausul ORDER BY.
Misalnya, asumsikan bahwa Anda memiliki tabel dengan 500.000 halaman. UserA menjalankan pernyataan Transact-SQL yang memerlukan pemindaian tabel. Ketika pemindaian tersebut telah memproses 100.000 halaman, UserB menjalankan pernyataan Transact-SQL lain yang memindai tabel yang sama. Mesin Database menjadwalkan satu set permintaan baca untuk halaman setelah 100.001, dan meneruskan baris dari setiap halaman kembali ke kedua pemindaian. Ketika pemindaian mencapai halaman ke-200.000, UserC menjalankan pernyataan Transact-SQL lain yang memindai tabel yang sama. Dimulai dengan halaman 200.001, Mesin Database meneruskan baris dari setiap halaman yang dibacanya kembali ke ketiga pemindaian. Setelah membaca baris ke-500.000, pemindaian untuk UserA selesai, dan pemindaian untuk PenggunaB dan UserC membungkus kembali dan mulai membaca halaman yang dimulai dengan halaman 1. Ketika Mesin Database sampai ke halaman 100.000, pemindaian untuk UserB selesai. Pemindaian untuk UserC kemudian terus berjalan sendiri sampai membaca halaman 200.000. Pada titik ini, semua pemindaian telah selesai.
Tanpa pemindaian lanjutan, setiap pengguna harus bersaing untuk ruang buffer dan menyebabkan ketidakcocokan lengan disk. Halaman yang sama kemudian akan dibaca sekali untuk setiap pengguna, alih-alih membaca satu kali dan dibagikan oleh beberapa pengguna, memperlambat performa dan sumber daya pajak.
Lihat Juga
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk