Arsitektur dan panduan desain indeks SQL Server dan Azure SQL
Berlaku untuk: ![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics Analytics
Azure Synapse Analytics Analytics ![]() Platform System (PDW)
Platform System (PDW)
Indeks yang didesain dengan buruk dan kurangnya indeks adalah sumber utama penyempitan aplikasi database. Merancang indeks yang efisien sangat penting untuk mencapai performa database dan aplikasi yang baik. Panduan desain indeks ini berisi informasi tentang arsitektur indeks, dan praktik terbaik untuk membantu Anda merancang indeks yang efektif untuk memenuhi kebutuhan aplikasi Anda.
Panduan ini mengasumsikan pembaca memiliki pemahaman umum tentang jenis indeks yang tersedia. Untuk deskripsi umum jenis indeks, lihat Indeks.
Panduan ini mencakup jenis indeks berikut:
| Format penyimpanan utama | Jenis indeks |
|---|---|
| Rowstore berbasis disk | |
| Terkluster | |
| Tidak Terkluster | |
| Unik | |
| Disaring | |
| Penyimpan kolom | |
| Penyimpan kolom berkluster | |
| Penyimpan kolom berkluster | |
| Memori dioptimalkan | |
| Hash | |
| Nonclustered yang Dioptimalkan Memori |
Untuk informasi tentang indeks XML, lihat Indeks XML (SQL Server) dan indeks XML Selektif (SXI).
Untuk informasi tentang indeks spasial, lihat Gambaran Umum Indeks Spasial.
Untuk informasi tentang indeks teks lengkap, lihat Mengisi Indeks Teks Lengkap.
Dasar-dasar desain indeks
Pikirkan tentang buku biasa: di akhir buku, ada indeks yang membantu menemukan informasi dengan cepat dalam buku. Indeks adalah daftar kata kunci yang diurutkan dan di samping setiap kata kunci adalah sekumpulan nomor halaman yang menunjuk ke halaman tempat setiap kata kunci dapat ditemukan.
Indeks rowstore tidak berbeda: ini adalah daftar nilai yang diurutkan dan untuk setiap nilai ada penunjuk ke halaman data tempat nilai ini berada. Indeks itu sendiri disimpan di halaman, disebut sebagai halaman indeks. Dalam buku biasa, jika indeks mencakup beberapa halaman dan Anda harus menemukan penunjuk ke semua halaman yang berisi kata SQL misalnya, Anda harus melakukan daun sampai Anda menemukan halaman indeks yang berisi kata kunci SQL. Dari sana, Anda mengikuti pointer ke semua halaman buku. Ini dapat dioptimalkan lebih lanjut jika pada awal indeks, Anda membuat satu halaman yang berisi daftar alfabet tempat setiap huruf dapat ditemukan. Misalnya: "A hingga D - halaman 121", "E hingga G - halaman 122" dan sebagainya. Halaman tambahan ini akan menghilangkan langkah daun melalui indeks untuk menemukan tempat awal. Halaman seperti itu tidak ada dalam buku biasa, tetapi memang ada di indeks rowstore. Halaman tunggal ini disebut sebagai halaman akar indeks. Halaman akar adalah halaman awal struktur pohon yang digunakan oleh indeks. Mengikuti analogi pohon, halaman akhir yang berisi penunjuk ke data aktual disebut sebagai "halaman daun" pohon.
Indeks adalah struktur pada disk atau dalam memori yang terkait dengan tabel atau tampilan yang mempercepat pengambilan baris dari tabel atau tampilan. Indeks rowstore berisi kunci yang dibangun dari satu atau beberapa kolom dalam tabel atau tampilan. Untuk indeks rowstore, kunci ini disimpan dalam struktur pohon (pohon B+) yang memungkinkan Mesin Database menemukan baris atau baris yang terkait dengan nilai kunci dengan cepat dan efisien.
Indeks rowstore menyimpan data yang diatur secara logis sebagai tabel dengan baris dan kolom, dan disimpan secara fisik dalam format data yang bijaksana baris yang disebut rowstore 1, atau disimpan dalam format data yang bijaksana kolom yang disebut columnstore.
Pemilihan indeks yang tepat untuk database dan beban kerjanya adalah tindakan penyeimbangan yang kompleks antara kecepatan kueri dan biaya pembaruan. Indeks rowstore berbasis disk yang sempit, atau indeks dengan beberapa kolom di kunci indeks, memerlukan lebih sedikit ruang disk dan overhead pemeliharaan. Di sisi lain, indeks lebar mencakup lebih banyak kueri. Anda mungkin harus bereksperimen dengan beberapa desain yang berbeda sebelum menemukan indeks yang paling efisien. Indeks dapat ditambahkan, dimodifikasi, dan dihilangkan tanpa memengaruhi skema database atau desain aplikasi. Oleh karena itu, Anda tidak boleh ragu untuk bereksperimen dengan indeks yang berbeda.
Pengoptimal kueri di Mesin Database dengan andal memilih indeks yang paling efektif dalam banyak kasus. Strategi desain indeks keseluruhan Anda harus menyediakan berbagai indeks bagi pengoptimal kueri untuk dipilih dan mempercayainya untuk membuat keputusan yang tepat. Ini mengurangi waktu analisis dan menghasilkan performa yang baik atas berbagai situasi. Untuk melihat indeks mana yang digunakan pengoptimal kueri untuk kueri tertentu, di SQL Server Management Studio, pada menu Kueri , pilih Sertakan Rencana Eksekusi Aktual.
Jangan selalu menyamakan penggunaan indeks dengan performa yang baik, dan performa yang baik dengan penggunaan indeks yang efisien. Jika menggunakan indeks selalu membantu menghasilkan performa terbaik, pekerjaan pengoptimal kueri akan sederhana. Pada kenyataannya, pilihan indeks yang salah dapat menyebabkan performa yang kurang dari optimal. Oleh karena itu, tugas pengoptimal kueri adalah memilih indeks, atau kombinasi indeks, hanya ketika meningkatkan performa, dan untuk menghindari pengambilan terindeks saat menghambat performa.
1 Rowstore telah menjadi cara tradisional untuk menyimpan data tabel relasional. Rowstore mengacu pada tabel di mana format penyimpanan data yang mendasar adalah tumpukan, pohon B+ (indeks berkluster), atau tabel yang dioptimalkan memori. Rowstore berbasis disk mengecualikan tabel yang dioptimalkan memori.
Tugas desain indeks
Tugas-tugas berikut membentuk strategi kami yang direkomendasikan untuk merancang indeks:
Pahami karakteristik database itu sendiri.
- Misalnya, apakah database pemrosesan transaksi online (OLTP) dengan modifikasi data sering yang harus mempertahankan throughput tinggi? Tabel dan indeks yang dioptimalkan memori sangat sesuai untuk skenario ini, dengan menyediakan desain bebas kait. Untuk informasi selengkapnya, lihat Indeks pada Tabel yang Dioptimalkan Memori, atau pedoman desain indeks non-klusster yang Dioptimalkan Memori dan panduan desain indeks Hash dalam panduan ini.
- Atau apakah itu contoh database Sistem Dukungan Keputusan (DSS) atau pergudangan data (OLAP) yang harus memproses himpunan data yang sangat besar dengan cepat? Indeks penyimpan kolom sangat sesuai untuk himpunan data pergudangan data biasa. Indeks penyimpan kolom dapat mengubah pengalaman pergudangan data untuk pengguna dengan mengaktifkan performa yang lebih cepat untuk kueri pergudangan data umum seperti pemfilteran, agregasi, pengelompokan, dan kueri gabungan bintang. Untuk informasi selengkapnya, lihat Indeks penyimpan kolom: Gambaran Umum, atau Panduan desain indeks penyimpan kolom dalam panduan ini.
Pahami karakteristik kueri yang paling sering digunakan. Misalnya, mengetahui bahwa kueri yang sering digunakan bergabung dengan dua tabel atau lebih membantu Anda menentukan jenis indeks terbaik untuk digunakan.
Pahami karakteristik kolom yang digunakan dalam kueri. Misalnya, indeks sangat ideal untuk kolom yang memiliki jenis data bilangan bulat dan juga kolom unik atau non-null. Untuk kolom yang memiliki subset data yang ditentukan dengan baik, Anda dapat menggunakan indeks yang difilter di SQL Server 2008 (10.0.x) dan versi yang lebih tinggi. Untuk informasi selengkapnya, lihat Panduan desain indeks yang difilter dalam panduan ini.
Tentukan opsi indeks mana yang dapat meningkatkan performa saat indeks dibuat atau dipertahankan. Misalnya, membuat indeks berkluster pada tabel besar yang ada akan mendapat manfaat dari
ONLINEopsi indeks. Opsi iniONLINEmemungkinkan aktivitas bersamaan pada data yang mendasar untuk dilanjutkan saat indeks sedang dibuat atau dibangun kembali. Untuk informasi selengkapnya, lihat Mengatur Opsi Indeks.Tentukan lokasi penyimpanan optimal untuk indeks.
Indeks nonclustered dapat disimpan dalam grup file yang sama dengan tabel yang mendasar, atau pada grup file yang berbeda. Lokasi penyimpanan indeks dapat meningkatkan performa kueri dengan meningkatkan performa I/O disk. Misalnya, menyimpan indeks non-kluster pada grup file yang berada di disk yang berbeda dari grup file tabel dapat meningkatkan performa karena beberapa disk dapat dibaca secara bersamaan. Atau, indeks terkluster dan non-kluster dapat menggunakan skema partisi di beberapa grup file. Ketika Anda mempertimbangkan pemartisian, tentukan apakah indeks harus diselaraskan, yaitu, dipartisi pada dasarnya dengan cara yang sama seperti tabel, atau dipartisi secara independen. Pelajari selengkapnya di bagian penempatan indeks pada grup file atau skema partisi di artikel ini.
Saat Anda mengidentifikasi indeks yang hilang dengan Tampilan Manajemen Dinamis (DMV) seperti sys.dm_db_missing_index_details dan sys.dm_db_missing_index_columns, Anda mungkin ditawarkan variasi indeks yang sama pada tabel dan kolom yang sama. Periksa indeks yang ada pada tabel bersama dengan saran indeks yang hilang untuk mencegah pembuatan indeks duplikat. Pelajari selengkapnya dalam menyetel indeks non-klusifikasi dengan saran indeks yang hilang.
Panduan desain indeks umum
Administrator database berpengalaman dapat merancang serangkaian indeks yang baik, tetapi tugas ini kompleks, memakan waktu, dan rawan kesalahan bahkan untuk database dan beban kerja yang cukup kompleks. Memahami karakteristik database, kueri, dan kolom data Anda dapat membantu Anda merancang indeks yang optimal.
Pertimbangan {i>database
Saat Anda merancang indeks, pertimbangkan panduan database berikut:
Sejumlah besar indeks pada tabel memengaruhi performa INSERTpernyataan , , UPDATEDELETE, dan MERGE karena semua indeks harus disesuaikan dengan tepat saat data dalam tabel berubah. Misalnya, jika kolom digunakan dalam beberapa indeks dan Anda menjalankan UPDATE pernyataan yang memodifikasi data kolom tersebut, setiap indeks yang berisi kolom tersebut harus diperbarui serta kolom dalam tabel dasar yang mendasar (timbunan atau indeks berkluster).
Hindari pengindeksan berlebihan tabel yang sangat diperbarui dan pertahankan indeks tetap sempit, yaitu, dengan kolom seserang mungkin.
Gunakan banyak indeks untuk meningkatkan performa kueri pada tabel dengan persyaratan pembaruan rendah, tetapi data dalam volume besar. Sejumlah besar indeks dapat membantu performa kueri yang tidak mengubah data, seperti SELECT pernyataan, karena pengoptimal kueri memiliki lebih banyak indeks untuk dipilih untuk menentukan metode akses tercepat.
Mengindeks tabel kecil mungkin tidak optimal karena dapat membutuhkan waktu lebih lama bagi pengoptimal kueri untuk melintasi indeks yang mencari data daripada melakukan pemindaian tabel dasar. Oleh karena itu, indeks pada tabel kecil mungkin tidak pernah digunakan, tetapi masih harus dipertahankan saat data dalam tabel berubah.
Indeks pada tampilan dapat memberikan perolehan performa yang signifikan saat tampilan berisi agregasi, gabungan tabel, atau kombinasi agregasi dan gabungan. Tampilan tidak harus dirujuk secara eksplisit dalam kueri agar pengoptimal kueri menggunakannya.
Database pada replika utama di Azure SQL Database secara otomatis menghasilkan rekomendasi performa penasihat database untuk indeks. Anda dapat mengaktifkan penyetelan indeks otomatis secara opsional.
Penyimpanan Kueri membantu mengidentifikasi kueri dengan performa suboptimal dan menyediakan riwayat rencana eksekusi kueri yang indeks dokumennya dipilih oleh pengoptimal.
Pertimbangan kueri
Saat Anda mendesain indeks, pertimbangkan panduan kueri berikut:
Buat indeks non-kluster pada kolom yang sering digunakan dalam predikat dan kondisi gabungan dalam kueri. Ini adalah 1 kolom SARGableAnda. Namun, Anda harus menghindari penambahan kolom yang tidak perlu. Menambahkan terlalu banyak kolom indeks dapat berdampak buruk pada ruang disk dan performa pemeliharaan indeks.
Mencakup indeks dapat meningkatkan performa kueri karena semua data yang diperlukan untuk memenuhi persyaratan kueri ada dalam indeks itu sendiri. Artinya, hanya halaman indeks, dan bukan halaman data tabel atau indeks berkluster, yang diperlukan untuk mengambil data yang diminta; oleh karena itu, mengurangi I/O disk secara keseluruhan. Misalnya, kueri kolom A dan B pada tabel yang memiliki indeks komposit yang dibuat pada kolom A, B, dan C dapat mengambil data yang ditentukan dari indeks saja.
Indeks yang mencakup adalah penunjukan untuk indeks nonclustered yang menyelesaikan satu atau beberapa hasil kueri serupa secara langsung tanpa akses ke tabel dasarnya, dan tanpa menimbulkan pencarian.
Indeks tersebut memiliki semua kolom yang tidak dapat di-SARGable yang diperlukan dalam tingkat daunnya. Ini berarti bahwa kolom yang dikembalikan oleh SELECT klausul dan semua WHERE argumen dan JOIN dicakup oleh indeks.
Ada kemungkinan lebih sedikit I/O untuk menjalankan kueri, jika indeks cukup sempit jika dibandingkan dengan baris dan kolom dalam tabel itu sendiri, yang berarti itu adalah subset nyata dari total kolom.
Pertimbangkan untuk mencakup indeks saat memilih sebagian kecil tabel besar, dan di mana bagian kecil tersebut ditentukan oleh predikat tetap, seperti kolom jarang yang hanya berisi beberapa nilai non-NULL, misalnya.
Tulis kueri yang menyisipkan atau memodifikasi baris sebanyak mungkin dalam satu pernyataan, alih-alih menggunakan beberapa kueri untuk memperbarui baris yang sama. Dengan hanya menggunakan satu pernyataan, pemeliharaan indeks yang dioptimalkan dapat dieksploitasi.
Mengevaluasi jenis kueri dan bagaimana kolom digunakan dalam kueri. Misalnya, kolom yang digunakan dalam jenis kueri yang sama persis akan menjadi kandidat yang baik untuk indeks non-kluster atau berkluster.
1 Istilah SARGable dalam database relasional mengacu pada predikat S earch ARGument-able yang dapat menggunakan indeks untuk mempercepat eksekusi kueri.
Pertimbangan kolom
Saat Anda mendesain indeks, pertimbangkan panduan kolom berikut:
Pertahankan panjang kunci indeks singkat untuk indeks berkluster. Selain itu, indeks berkluster mendapat manfaat dari dibuat pada kolom unik atau non-null.
Kolom yang merupakan tipe data ntext, teks, gambar, varchar(max), nvarchar(max), dan varbinary(max) tidak dapat ditentukan sebagai kolom kunci indeks. Namun, jenis data varchar(max), nvarchar(max), varbinary(max), dan xml dapat berpartisipasi dalam indeks non-kluster sebagai kolom indeks nonkey. Untuk informasi selengkapnya, lihat bagian Indeks dengan kolom yang disertakan dalam panduan ini.
Tipe data xml hanya bisa menjadi kolom kunci dalam indeks XML. Untuk informasi selengkapnya, lihat Indeks XML (SQL Server). SQL Server 2012 SP1 memperkenalkan jenis indeks XML baru yang dikenal sebagai Indeks XML Selektif. Indeks baru ini dapat meningkatkan performa kueri atas data yang disimpan sebagai XML, memungkinkan pengindeksan beban kerja data XML besar yang lebih cepat, dan meningkatkan skalabilitas dengan mengurangi biaya penyimpanan indeks itu sendiri. Untuk informasi selengkapnya, lihat Indeks XML Selektif (SXI).
Periksa keunikan kolom. Indeks unik alih-alih indeks nonunique pada kombinasi kolom yang sama menyediakan informasi tambahan untuk pengoptimal kueri yang membuat indeks lebih berguna. Untuk informasi selengkapnya, lihat Panduan desain indeks unik dalam panduan ini.
Periksa distribusi data di kolom. Sering kali, kueri yang berjalan lama disebabkan oleh pengindeksan kolom dengan beberapa nilai unik, atau dengan melakukan gabungan pada kolom tersebut. Ini adalah masalah mendasar dengan data dan kueri, dan umumnya tidak dapat diselesaikan tanpa mengidentifikasi situasi ini. Misalnya, direktori telepon fisik yang diurutkan menurut abjad pada nama keluarga tidak mempercepat menemukan seseorang jika semua orang di kota bernama Smith atau Jones. Untuk informasi selengkapnya tentang distribusi data, lihat Statistik.
Pertimbangkan untuk menggunakan indeks terfilter pada kolom yang memiliki subset yang ditentukan dengan baik, misalnya kolom jarang, kolom dengan sebagian besar NULL nilai, kolom dengan kategori nilai, dan kolom dengan rentang nilai yang berbeda. Indeks terfilter yang dirancang dengan baik dapat meningkatkan performa kueri, mengurangi biaya pemeliharaan indeks, dan mengurangi biaya penyimpanan.
Pertimbangkan urutan kolom jika indeks berisi beberapa kolom. Kolom yang digunakan dalam WHERE klausa sama dengan (), lebih besar dari (=>), kurang dari (<), atau BETWEEN kondisi pencarian, atau berpartisipasi dalam gabungan, harus ditempatkan terlebih dahulu. Kolom tambahan harus diurutkan berdasarkan tingkat perbedaannya, yaitu, dari yang paling berbeda dengan yang paling tidak berbeda.
Misalnya, jika indeks didefinisikan sebagai LastName, FirstName, indeks berguna ketika kriteria pencarian adalah WHERE LastName = 'Smith' atau WHERE LastName = Smith AND FirstName LIKE 'J%'. Namun, pengoptimal kueri tidak akan menggunakan indeks untuk kueri yang hanya mencari di FirstName (WHERE FirstName = 'Jane').
Pertimbangkan untuk mengindeks kolom komputasi. Untuk informasi selengkapnya, lihat Indeks pada kolom komputasi.
Karakteristik indeks
Setelah Anda menentukan bahwa indeks sesuai untuk kueri, Anda bisa memilih jenis indeks yang paling sesuai dengan situasi Anda. Karakteristik indeks mencakup daftar berikut:
- Terkluster versus nonclustered
- Unik versus nonunique
- Kolom tunggal versus multikolom
- Urutan naik atau turun pada kolom dalam indeks
- Tabel penuh versus difilter untuk indeks non-kluster
- Penyimpan kolom versus rowstore
- Hash versus nonclustered untuk tabel yang dioptimalkan memori
Anda juga dapat menyesuaikan karakteristik penyimpanan awal indeks untuk mengoptimalkan performa atau pemeliharaannya dengan mengatur opsi seperti FILLFACTOR. Selain itu, Anda dapat menentukan lokasi penyimpanan indeks dengan menggunakan grup file atau skema partisi untuk mengoptimalkan performa.
Penempatan indeks pada skema grup file atau partisi
Saat Anda mengembangkan strategi desain indeks, Anda harus mempertimbangkan penempatan indeks pada grup file yang terkait dengan database. Pemilihan skema grup file atau partisi yang cermat dapat meningkatkan performa kueri.
Secara default, indeks disimpan dalam grup file yang sama dengan tabel dasar tempat indeks dibuat. Indeks berkluster nonpartisi dan tabel dasar selalu berada di grup file yang sama. Namun, Anda dapat melakukan langkah-langkah berikut:
- Buat indeks non-kluster pada grup file selain grup file tabel dasar atau indeks berkluster.
- Indeks terkluster dan non-kluster partisi untuk menjangkau beberapa grup file.
- Pindahkan tabel dari satu grup file ke grup file lainnya dengan menjatuhkan indeks berkluster dan menentukan grup file atau skema partisi baru dalam
MOVE TO klausa DROP INDEX pernyataan atau dengan menggunakan CREATE INDEX pernyataan dengan DROP_EXISTING klausa.
Dengan membuat indeks nonclustered pada grup file yang berbeda, Anda dapat mencapai perolehan performa jika grup file menggunakan drive fisik yang berbeda dengan pengontrol mereka sendiri. Informasi data dan indeks kemudian dapat dibaca secara paralel oleh beberapa kepala disk. Misalnya, jika Table_A pada grup file f1 dan Index_A grup file f2 keduanya digunakan oleh kueri yang sama, perolehan performa dapat dicapai karena kedua grup file sepenuhnya digunakan tanpa pertikaian. Namun, jika Table_A dipindai oleh kueri tetapi Index_A tidak direferensikan, hanya grup file f1 yang digunakan. Ini tidak menciptakan perolehan performa.
Karena Anda tidak dapat memprediksi jenis akses apa yang terjadi dan ketika itu terjadi, itu bisa menjadi keputusan yang lebih baik untuk menyebarkan tabel dan indeks Anda di semua grup file. Ini akan menjamin bahwa semua disk diakses karena semua data dan indeks tersebar merata di semua disk, terlepas dari cara mana data diakses. Ini juga merupakan pendekatan yang lebih sederhana untuk administrator sistem.
Partisi di beberapa grup file
Anda juga dapat mempertimbangkan partisi indeks terkluster dan terkluster berbasis disk di beberapa grup file. Indeks yang dipartisi dipartisi secara horizontal, atau menurut baris, berdasarkan fungsi partisi. Fungsi partisi menentukan bagaimana setiap baris dipetakan ke sekumpulan partisi berdasarkan nilai kolom tertentu, yang disebut kolom partisi. Skema partisi menentukan pemetaan partisi ke sekumpulan grup file.
Pemartisian indeks dapat memberikan manfaat berikut:
Menyediakan sistem yang dapat diskalakan yang membuat indeks besar lebih mudah dikelola. Sistem OLTP, misalnya, dapat menerapkan aplikasi sadar partisi yang menangani indeks besar.
Buat kueri berjalan lebih cepat dan lebih efisien. Saat kueri mengakses beberapa partisi indeks, pengoptimal kueri dapat memproses partisi individual secara bersamaan dan mengecualikan partisi yang tidak terpengaruh oleh kueri.
Untuk informasi selengkapnya, lihat Tabel dan indeks yang dipartisi.
Panduan desain urutan pengurutan indeks
Saat menentukan indeks, pertimbangkan apakah data untuk kolom kunci indeks harus disimpan dalam urutan naik atau menurun. Naik adalah default dan mempertahankan kompatibilitas dengan versi Mesin Database yang lebih lama. Sintaks pernyataan CREATE INDEX, , dan ALTER TABLE mendukung kata kunci ASC (naik) dan DESC (menurun) pada kolom individual dalam indeks CREATE TABLEdan batasan.
Menentukan urutan di mana nilai kunci disimpan dalam indeks berguna saat kueri yang merujuk tabel memiliki ORDER BY klausa yang menentukan arah yang berbeda untuk kolom kunci atau kolom dalam indeks tersebut. Dalam kasus ini, indeks dapat menghapus kebutuhan SORT operator dalam rencana kueri; oleh karena itu, ini membuat kueri lebih efisien. Misalnya, pembeli di departemen pembelian Adventure Works Cycles harus mengevaluasi kualitas produk yang mereka beli dari vendor. Pembeli paling tertarik untuk menemukan produk yang dikirim oleh vendor ini dengan tingkat penolakan yang tinggi.
Seperti yang ditunjukkan dalam kueri berikut terhadap database sampel AdventureWorks, mengambil data untuk memenuhi kriteria ini mengharuskan RejectedQty kolom dalam tabel diurutkan Purchasing.PurchaseOrderDetail dalam urutan turun (besar ke kecil) dan ProductID kolom yang akan diurutkan dalam urutan naik (kecil ke besar).
SELECT RejectedQty, ((RejectedQty/OrderQty)*100) AS RejectionRate,
ProductID, DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
GO
Rencana eksekusi berikut untuk kueri ini menunjukkan bahwa pengoptimal kueri menggunakan SORT operator untuk mengembalikan tataan hasil dalam urutan yang ditentukan oleh ORDER BY klausa.

Jika indeks rowstore berbasis disk dibuat dengan kolom kunci yang cocok dengan yang ada dalam ORDER BY klausul dalam kueri, SORT operator dapat dihilangkan dalam rencana kueri dan rencana kueri lebih efisien.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
GO
Setelah kueri dijalankan lagi, rencana eksekusi berikut menunjukkan bahwa SORT operator telah dihilangkan dan indeks noncluster yang baru dibuat digunakan.
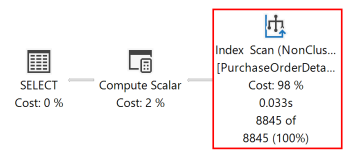
Mesin Database dapat bergerak secara sama efisien di kedua arah. Indeks yang didefinisikan sebagai (RejectedQty DESC, ProductID ASC) masih dapat digunakan untuk kueri di mana arah pengurutan kolom dalam ORDER BY klausa dibalik. Misalnya, kueri dengan ORDER BY klausa ORDER BY RejectedQty ASC, ProductID DESC dapat menggunakan indeks.
Urutan pengurutan hanya dapat ditentukan untuk kolom kunci dalam indeks. Tampilan katalog sys.index_columns dan INDEXKEY_PROPERTY fungsi melaporkan apakah kolom indeks disimpan dalam urutan naik atau menurun.
Jika Anda mengikuti contoh kode dalam database sampel AdventureWorks, Anda dapat menghapusnya IX_PurchaseOrderDetail_RejectedQty dengan Transact-SQL berikut:
DROP INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail;
GO
Metadata
Gunakan tampilan metadata ini untuk melihat atribut indeks. Informasi arsitektur lainnya disematkan dalam beberapa tampilan ini.
Untuk indeks penyimpan kolom, semua kolom disimpan dalam metadata sebagai kolom yang disertakan. Indeks penyimpan kolom tidak memiliki kolom kunci.
- sys.column_store_dictionaries
- sys.column_store_row_groups
- sys.column_store_segments
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
- sys.dm_db_index_operational_stats
- sys.dm_db_index_physical_stats
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.hash_indexes
- sys.index_columns
- sys.indexes
- sys.internal_partitions
- sys.memory_optimized_tables_internal_attributes
- sys.partitions
Panduan desain indeks berkluster
Indeks berkluster mengurutkan dan menyimpan baris data dalam tabel berdasarkan nilai kuncinya. Hanya ada satu indeks berkluster per tabel, karena baris data itu sendiri hanya dapat diurutkan dalam satu urutan. Dengan beberapa pengecualian, setiap tabel harus memiliki indeks berkluster yang ditentukan pada kolom, atau kolom, yang menawarkan hal berikut:
Dapat digunakan untuk kueri yang sering digunakan.
Memberikan tingkat keunikan yang tinggi.
Catatan
Saat Anda membuat PRIMARY KEY batasan, indeks unik pada kolom, atau kolom, secara otomatis dibuat. Secara default, indeks ini diklusterkan; namun, Anda dapat menentukan indeks nonclustered saat membuat batasan.
Dapat digunakan dalam kueri rentang.
Jika indeks berkluster tidak dibuat dengan UNIQUE properti , Mesin Database secara otomatis menambahkan kolom pengimpor unik 4-byte ke tabel. Saat diperlukan, Mesin Database secara otomatis menambahkan nilai pengidentifikasi unik ke baris untuk membuat setiap kunci unik. Kolom ini dan nilainya digunakan secara internal dan tidak dapat dilihat atau diakses oleh pengguna.
Arsitektur indeks berkluster
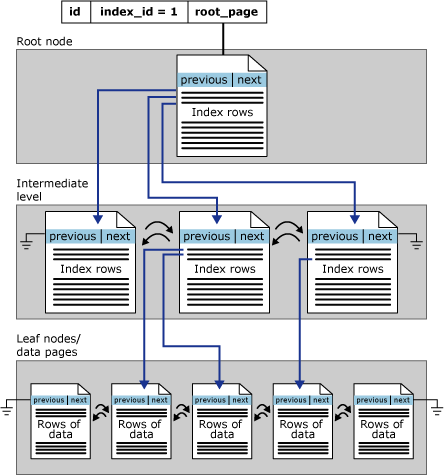
Indeks rowstore diatur sebagai pohon B+. Setiap halaman dalam pohon indeks B+ disebut simpul indeks. Simpul atas pohon B+ disebut simpul akar. Simpul bawah dalam indeks disebut simpul daun. Setiap tingkat indeks antara akar dan simpul daun secara kolektif dikenal sebagai tingkat menengah. Dalam indeks berkluster, simpul daun berisi halaman data tabel yang mendasar. Simpul tingkat akar dan menengah berisi halaman indeks yang menyimpan baris indeks. Setiap baris indeks berisi nilai kunci dan penunjuk ke halaman tingkat menengah di pohon B+, atau baris data di tingkat daun indeks. Halaman di setiap tingkat indeks ditautkan dalam daftar tertaut doubly.
Indeks berkluster memiliki satu baris dalam sys.partitions, dengan index_id = 1 untuk setiap partisi yang digunakan oleh indeks. Secara default, indeks berkluster memiliki satu partisi. Ketika indeks berkluster memiliki beberapa partisi, setiap partisi memiliki struktur pohon B+ yang berisi data untuk partisi tertentu tersebut. Misalnya, jika indeks berkluster memiliki empat partisi, ada empat struktur pohon B+; satu di setiap partisi.
Bergantung pada jenis data dalam indeks berkluster, setiap struktur indeks berkluster memiliki satu atau beberapa unit alokasi untuk menyimpan dan mengelola data untuk partisi tertentu. Minimal, setiap indeks berkluster memiliki satu IN_ROW_DATA unit alokasi per partisi. Indeks berkluster juga memiliki satu unit alokasi LOB_DATA per partisi jika berisi kolom objek besar (LOB). Ini juga memiliki satu unit alokasi ROW_OVERFLOW_DATA per partisi jika berisi kolom panjang variabel yang melebihi batas ukuran baris 8.060 byte.
Halaman dalam rantai data dan baris di dalamnya diurutkan pada nilai kunci indeks berkluster. Semua sisipan dibuat pada titik di mana nilai kunci dalam baris yang disisipkan pas dalam urutan pengurutan di antara baris yang ada.
Ilustrasi ini menunjukkan struktur indeks berkluster dalam satu partisi.
Pertimbangan kueri
Sebelum Anda membuat indeks berkluster, pahami bagaimana data Anda diakses. Pertimbangkan untuk menggunakan indeks berkluster untuk kueri yang melakukan hal berikut:
Mengembalikan rentang nilai dengan menggunakan operator seperti BETWEEN, , >, >=<, dan <=.
Setelah baris dengan nilai pertama ditemukan dengan menggunakan indeks berkluster, baris dengan nilai terindeks berikutnya dijamin berdekatan secara fisik. Misalnya, jika kueri mengambil rekaman antara rentang nomor pesanan penjualan, indeks berkluster pada kolom SalesOrderNumber dapat dengan cepat menemukan baris yang berisi nomor pesanan penjualan awal, lalu mengambil semua baris berturut-turut dalam tabel hingga nomor pesanan penjualan terakhir tercapai.
Mengembalikan tataan hasil besar.
Gunakan JOIN klausa; biasanya ini adalah kolom kunci asing.
Gunakan ORDER BY klausa atau GROUP BY .
Indeks pada kolom yang ditentukan dalam ORDER BY klausa atau GROUP BY mungkin menghapus kebutuhan Mesin Database untuk mengurutkan data, karena baris sudah diurutkan. Ini meningkatkan performa kueri.
Pertimbangan kolom
Umumnya, Anda harus menentukan kunci indeks berkluster dengan kolom seserang mungkin. Pertimbangkan kolom yang memiliki satu atau beberapa atribut berikut:
Unik atau berisi banyak nilai yang berbeda
Misalnya, ID karyawan secara unik mengidentifikasi karyawan. Indeks terkluster atau batasan KUNCI PRIMER pada EmployeeID kolom akan meningkatkan performa kueri yang mencari informasi karyawan berdasarkan nomor ID karyawan. Atau, indeks berkluster dapat dibuat pada LastName, FirstName, MiddleName karena rekaman karyawan sering dikelompokkan dan dikueri dengan cara ini, dan kombinasi kolom ini masih akan memberikan tingkat perbedaan yang tinggi.
Tip
Jika tidak ditentukan secara berbeda, saat membuat batasan KUNCI PRIMER, Mesin Database membuat indeks berkluster untuk mendukung batasan tersebut.
Meskipun uniqueidentifier dapat digunakan untuk memberlakukan keunikan sebagai PRIMARY KEY, ini bukan kunci pengklusteran yang efisien.
Jika menggunakan uniqueidentifier sebagai PRIMARY KEY, rekomendasinya adalah membuatnya sebagai indeks non-kluster, dan menggunakan kolom lain seperti IDENTITY untuk membuat indeks berkluster.
Diakses secara berurutan
Misalnya, ID produk secara unik mengidentifikasi produk dalam Production.Product tabel dalam AdventureWorks2022 database. Kueri di mana pencarian berurutan ditentukan, seperti WHERE ProductID BETWEEN 980 and 999, akan mendapat manfaat dari indeks berkluster pada ProductID. Ini karena baris akan disimpan dalam urutan diurutkan pada kolom kunci tersebut.
Didefinisikan sebagai IDENTITY.
Sering digunakan untuk mengurutkan data yang diambil dari tabel.
Sebaiknya kluster (mengurutkan secara fisik) tabel pada kolom tersebut, untuk menghemat biaya operasi pengurutan setiap kali kolom dikueri.
Indeks berkluster bukanlah pilihan yang baik untuk atribut berikut:
Kolom yang sering mengalami perubahan
Ini menyebabkan seluruh baris dipindahkan, karena Mesin Database harus menyimpan nilai data baris dalam urutan fisik. Ini adalah pertimbangan penting dalam sistem pemrosesan transaksi volume tinggi di mana data biasanya volatil.
Kunci lebar
Kunci lebar adalah komposit dari beberapa kolom atau beberapa kolom berukuran besar. Nilai kunci dari indeks berkluster digunakan oleh semua indeks non-kluster sebagai kunci pencarian. Setiap indeks non-kluster yang ditentukan pada tabel yang sama secara signifikan lebih besar, karena entri indeks non-kluster berisi kunci pengklusteran dan juga kolom kunci yang ditentukan untuk indeks non-kluster tersebut.
Pedoman desain indeks non-klusster
Indeks nonclustered rowstore berbasis disk berisi nilai kunci indeks dan pencari baris yang menunjuk ke lokasi penyimpanan data tabel. Anda dapat membuat beberapa indeks nonclustered pada tabel atau tampilan terindeks. Umumnya, indeks non-kluster harus dirancang untuk meningkatkan performa kueri yang sering digunakan yang tidak tercakup oleh indeks berkluster.
Mirip dengan cara Anda menggunakan indeks dalam buku, pengoptimal kueri mencari nilai data dengan mencari indeks nonclustered untuk menemukan lokasi nilai data dalam tabel lalu mengambil data langsung dari lokasi tersebut. Ini membuat indeks non-kluster pilihan optimal untuk kueri kecocokan yang tepat karena indeks berisi entri yang menjelaskan lokasi yang tepat dalam tabel nilai data yang sedang dicari dalam kueri. Misalnya, untuk mengkueri HumanResources.Employee tabel untuk semua karyawan yang melaporkan ke manajer tertentu, pengoptimal kueri mungkin menggunakan indeks IX_Employee_ManagerIDnonclustered ; ini memiliki ManagerID sebagai kolom kuncinya. Pengoptimal kueri dapat dengan cepat menemukan semua entri dalam indeks yang cocok dengan yang ditentukan ManagerID. Setiap entri indeks menunjuk ke halaman dan baris yang tepat dalam tabel, atau indeks berkluster, di mana data yang sesuai dapat ditemukan. Setelah pengoptimal kueri menemukan semua entri dalam indeks, pengoptimal kueri dapat langsung masuk ke halaman dan baris yang tepat untuk mengambil data.
Arsitektur indeks nonclustered
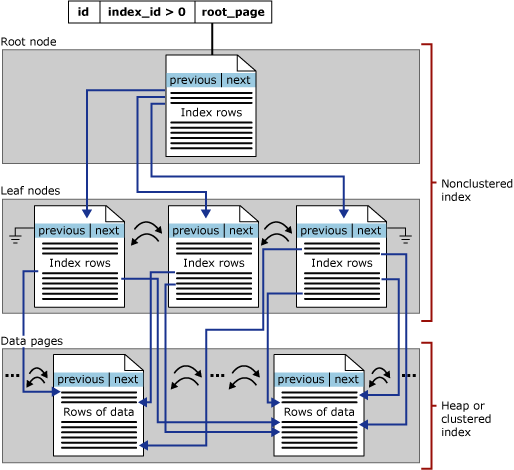
Indeks nonclustered rowstore berbasis disk memiliki struktur pohon B+ yang sama dengan indeks berkluster, kecuali untuk perbedaan signifikan berikut:
Baris data tabel yang mendasar tidak diurutkan dan disimpan secara berurutan berdasarkan kunci non-klusternya.
Tingkat daun indeks non-klusster terdiri dari halaman indeks alih-alih halaman data. Halaman indeks pada tingkat daun indeks nonclustered berisi kolom kunci dan kolom yang disertakan.
Pencari baris dalam baris indeks non-kluster adalah penunjuk ke baris atau merupakan kunci indeks berkluster untuk baris, seperti yang dijelaskan dalam hal berikut:
Jika tabel adalah tumpukan, yang berarti tidak memiliki indeks berkluster, pencari baris adalah penunjuk ke baris. Penunjuk dibangun dari pengidentifikasi file (ID), nomor halaman, dan jumlah baris di halaman. Seluruh pointer dikenal sebagai ID Baris (RID).
Jika tabel memiliki indeks berkluster, atau indeks berada pada tampilan terindeks, pencari baris adalah kunci indeks berkluster untuk baris tersebut.
Pencari baris juga memastikan keunikan untuk baris indeks nonclustered. Tabel berikut ini menjelaskan bagaimana Mesin Database menambahkan pencari baris ke indeks non-kluster:
Jenis tabel
Jenis indeks nonclustered
Pencari lokasi baris
Tumpukan
Nonunique
RID ditambahkan ke kolom kunci
Unik
RID ditambahkan ke kolom yang disertakan
Indeks berkluster unik
Nonunique
Kunci indeks berkluster ditambahkan ke kolom kunci
Unik
Kunci indeks berkluster ditambahkan ke kolom yang disertakan
Indeks berkluster yang tidak unik
Nonunique
Kunci indeks berkluster dan pengidentifikasi unik (saat ada) ditambahkan ke kolom kunci
Unik
Kunci indeks berkluster dan pengidentifikasi unik (saat ada) ditambahkan ke kolom yang disertakan
Mesin Database tidak pernah menyimpan kolom tertentu dua kali dalam indeks nonclustered. Urutan kunci indeks yang ditentukan oleh pengguna ketika mereka membuat indeks non-kluster selalu dihormati: kolom pencari baris apa pun yang perlu ditambahkan ke kunci indeks non-kluster, ditambahkan di akhir kunci, mengikuti kolom yang ditentukan dalam definisi indeks. Kolom pencari lokasi baris berbasis kunci indeks berkluster dalam indeks non-kluster dapat digunakan oleh pengoptimal kueri, terlepas dari apakah mereka secara eksplisit ditentukan dalam definisi indeks.
Contoh berikut menunjukkan bagaimana pencari baris diimplementasikan dalam indeks nonclustered:
Indeks dalam kluster
Definisi indeks yang tidak di-noncluster
Definisi indeks yang tidak terkluster dengan pencari baris
Penjelasan
Indeks berkluster unik dengan kolom kunci (A, B, C)
Indeks nonunique nonclustered dengan kolom kunci (B, A) dan kolom yang disertakan (E, G)
Kolom kunci (B, , AC) dan kolom yang disertakan (E, G)
Indeks nonclustered nonunique, sehingga pencari baris perlu ada di kunci indeks. B Kolom dan A dari pencari baris sudah ada, jadi hanya kolom c yang ditambahkan. Kolom c ditambahkan ke akhir daftar kolom kunci.
Indeks berkluster unik dengan kolom kunci (A)
Indeks nonunique nonclustered dengan kolom kunci (B, C) dan kolom yang disertakan (A)
Kolom kunci (B, C, A)
Indeks nonclustered nonunique, sehingga pencari baris ditambahkan ke kunci. Kolom A belum ditentukan sebagai kolom kunci, sehingga ditambahkan ke akhir daftar kolom kunci. Kolom A sekarang ada di kunci, jadi tidak perlu menyimpannya sebagai kolom yang disertakan.
Indeks berkluster unik dengan kolom kunci (A, B)
Indeks nonclustered unik dengan kolom kunci (C)
Kolom kunci (C) dan kolom yang disertakan (A, B)
Indeks nonclustered unik, sehingga pencari baris ditambahkan ke kolom yang disertakan.
Indeks nonclustered memiliki satu baris dalam sys.partitions dengan index_id > 1 untuk setiap partisi yang digunakan oleh indeks. Secara default, indeks nonclustered memiliki satu partisi. Ketika indeks nonclustered memiliki beberapa partisi, setiap partisi memiliki struktur pohon B+ yang berisi baris indeks untuk partisi tertentu tersebut. Misalnya, jika indeks nonclustered memiliki empat partisi, ada empat struktur pohon B+, dengan satu di setiap partisi.
Bergantung pada jenis data dalam indeks nonclustered, setiap struktur indeks nonclustered memiliki satu atau beberapa unit alokasi untuk menyimpan dan mengelola data untuk partisi tertentu. Minimal, setiap indeks non-kluster memiliki satu unit alokasi IN_ROW_DATA per partisi yang menyimpan indeks halaman pohon B+. Indeks nonclustered juga memiliki satu unit alokasi LOB_DATA per partisi jika berisi kolom objek besar (LOB). Selain itu, ia memiliki satu unit alokasi ROW_OVERFLOW_DATA per partisi jika berisi kolom panjang variabel yang melebihi batas ukuran baris 8.060 byte.
Ilustrasi berikut menunjukkan struktur indeks nonclustered dalam satu partisi.
Pertimbangan {i>database
Pertimbangkan karakteristik database saat merancang indeks non-kluster.
Database atau tabel dengan persyaratan pembaruan rendah, tetapi data dalam volume besar dapat memperoleh manfaat dari banyak indeks yang tidak terkluster untuk meningkatkan performa kueri. Pertimbangkan untuk membuat indeks yang difilter untuk subset data yang terdefinisi dengan baik untuk meningkatkan performa kueri, mengurangi biaya penyimpanan indeks, dan mengurangi biaya pemeliharaan indeks dibandingkan dengan indeks nonclustered tabel penuh.
Aplikasi dan database Sistem Dukungan Keputusan yang terutama berisi data baca-saja dapat memperoleh manfaat dari banyak indeks non-kluster. Pengoptimal kueri memiliki lebih banyak indeks untuk dipilih untuk menentukan metode akses tercepat, dan karakteristik pembaruan rendah dari database berarti pemeliharaan indeks tidak menghambat performa.
Aplikasi dan database Pemrosesan Transaksi Online (OLTP) yang berisi tabel yang sangat diperbarui harus menghindari pengindeksan berlebihan. Selain itu, indeks harus sempit, yaitu, dengan kolom seserang mungkin.
Sejumlah besar indeks pada tabel memengaruhi performa INSERTpernyataan , , UPDATEDELETE, dan MERGE karena semua indeks harus disesuaikan dengan tepat saat data dalam tabel berubah.
Pertimbangan kueri
Sebelum membuat indeks non-kluster, Anda harus memahami bagaimana data Anda diakses. Pertimbangkan untuk menggunakan indeks nonclustered untuk kueri yang memiliki atribut berikut:
Gunakan JOIN klausa atau GROUP BY .
Buat beberapa indeks non-kluster pada kolom yang terlibat dalam operasi gabungan dan pengelompokan, dan indeks berkluster pada kolom kunci asing apa pun.
Kueri yang tidak mengembalikan tataan hasil besar.
Buat indeks yang difilter untuk mencakup kueri yang mengembalikan subset baris yang ditentukan dengan baik dari tabel besar.
Tip
WHERE Biasanya klausul CREATE INDEX pernyataan cocok dengan WHERE klausul kueri yang sedang dibahas.
Berisi kolom yang sering terlibat dalam kondisi pencarian kueri, seperti WHERE klausa, yang mengembalikan kecocokan persis.
Tip
Pertimbangkan biaya versus manfaat saat menambahkan indeks baru. Mungkin lebih baik untuk mengonsolidasikan kebutuhan kueri tambahan ke dalam indeks yang sudah ada. Misalnya, pertimbangkan untuk menambahkan satu atau dua kolom tingkat daun tambahan ke indeks yang ada, jika memungkinkan cakupan beberapa kueri penting, alih-alih memiliki satu indeks yang benar-benar mencakup per setiap kueri penting.
Pertimbangan kolom
Pertimbangkan kolom yang memiliki satu atau beberapa atribut ini:
Tutupi kueri.
Perolehan performa dicapai saat indeks berisi semua kolom dalam kueri. Pengoptimal kueri dapat menemukan semua nilai kolom dalam indeks; tabel atau data indeks terkluster tidak diakses sehingga menghasilkan lebih sedikit operasi I/O disk. Gunakan indeks dengan kolom yang disertakan untuk menambahkan kolom penutup alih-alih membuat kunci indeks yang lebar.
Jika tabel memiliki indeks berkluster, kolom atau kolom yang ditentukan dalam indeks berkluster secara otomatis ditambahkan ke setiap indeks non-kluster pada tabel. Ini dapat menghasilkan kueri tercakup tanpa menentukan kolom indeks berkluster dalam definisi indeks non-kluster. Misalnya, jika tabel memiliki indeks berkluster pada kolom C, indeks nonunique nonclustered pada kolom B dan A memiliki sebagai kolom Bnilai kuncinya , , Adan C. Untuk informasi selengkapnya, kunjungi arsitektur indeks non-klusster.
Banyak nilai yang berbeda, seperti kombinasi nama keluarga dan nama depan, jika indeks berkluster digunakan untuk kolom lain.
Jika ada sangat sedikit nilai yang berbeda, seperti hanya 1 dan 0, sebagian besar kueri tidak akan menggunakan indeks karena pemindaian tabel umumnya lebih efisien. Untuk jenis data ini, pertimbangkan untuk membuat indeks yang difilter pada nilai berbeda yang hanya terjadi dalam beberapa baris. Misalnya, jika sebagian besar nilai adalah 0, pengoptimal kueri dapat menggunakan indeks yang difilter untuk baris data yang berisi 1.
Gunakan kolom yang disertakan untuk memperluas indeks non-klusster
Anda dapat memperluas fungsionalitas indeks nonclustered dengan menambahkan kolom non-kunci ke tingkat daun indeks nonclustered. Dengan menyertakan kolom non-kunci, Anda dapat membuat indeks nonclustered yang mencakup lebih banyak kueri. Ini karena kolom non-kunci memiliki manfaat berikut:
Mereka bisa menjadi jenis data yang tidak diizinkan sebagai kolom kunci indeks.
Kolom tidak dipertimbangkan oleh Mesin Database saat menghitung jumlah kolom kunci indeks atau ukuran kunci indeks.
Indeks dengan kolom non-kunci yang disertakan dapat secara signifikan meningkatkan performa kueri ketika semua kolom dalam kueri disertakan dalam indeks baik sebagai kolom kunci atau non-kunci. Perolehan performa dicapai karena pengoptimal kueri dapat menemukan semua nilai kolom dalam indeks; tabel atau data indeks terkluster tidak diakses sehingga menghasilkan lebih sedikit operasi I/O disk.
Catatan
Saat indeks berisi semua kolom yang dirujuk oleh kueri, indeks biasanya disebut sebagai mencakup kueri.
Meskipun kolom kunci disimpan di semua tingkat indeks, kolom non-kunci hanya disimpan di tingkat daun.
Menggunakan kolom yang disertakan untuk menghindari batas ukuran
Anda dapat menyertakan kolom non-kunci dalam indeks non-kluster untuk menghindari melebihi batasan ukuran indeks saat ini dari maksimum 16 kolom kunci dan ukuran kunci indeks maksimum 900 byte. Mesin Database tidak mempertimbangkan kolom non-kunci saat menghitung jumlah kolom kunci indeks atau ukuran kunci indeks.
Misalnya, asumsikan bahwa Anda ingin mengindeks kolom berikut dalam Document tabel:
Title NVARCHAR(50)
Revision NCHAR(5)
FileName NVARCHAR(400)
Karena jenis data nchar dan nvarchar memerlukan 2 byte untuk setiap karakter, indeks yang berisi ketiga kolom ini akan melebihi batasan ukuran 900 byte sebesar 10 byte (455 * 2). Dengan menggunakan INCLUDE klausa CREATE INDEX pernyataan, kunci indeks dapat didefinisikan sebagai (Title, Revision) dan FileName didefinisikan sebagai kolom non-kunci. Dengan cara ini, ukuran kunci indeks adalah 110 byte (55 * 2), dan indeks masih akan berisi semua kolom yang diperlukan. Pernyataan berikut membuat indeks seperti itu.
CREATE INDEX IX_Document_Title
ON Production.Document (Title, Revision)
INCLUDE (FileName);
GO
Jika Anda mengikuti contoh kode, Anda dapat menghilangkan indeks ini menggunakan pernyataan Transact-SQL ini:
DROP INDEX IX_Document_Title
ON Production.Document;
GO
Indeks dengan panduan kolom yang disertakan
Saat Anda merancang indeks nonclustered dengan kolom yang disertakan, pertimbangkan panduan berikut:
Kolom non-kunci didefinisikan dalam INCLUDE klausa CREATE INDEX pernyataan.
Kolom non-kunci hanya dapat ditentukan pada indeks nonclustered pada tabel atau tampilan terindeks.
Semua jenis data diizinkan kecuali teks, ntext, dan gambar.
Kolom komputasi yang deterministik dan tepat atau tidak tepat dapat disertakan kolom. Untuk informasi selengkapnya, lihat Indeks pada kolom komputasi.
Seperti halnya kolom kunci, kolom komputasi yang berasal dari tipe data gambar, ntext, dan teks dapat berupa kolom non-kunci (disertakan) selama jenis data kolom komputasi diizinkan sebagai kolom indeks non-kunci.
Nama kolom tidak dapat ditentukan dalam INCLUDE daftar dan di daftar kolom kunci.
Nama kolom tidak dapat diulang dalam INCLUDE daftar.
Panduan ukuran kolom
Setidaknya satu kolom kunci harus ditentukan. Jumlah maksimum kolom non-kunci adalah 1.023 kolom. Ini adalah jumlah maksimum kolom tabel dikurangi 1.
Kolom kunci indeks, tidak termasuk non-kunci, harus mengikuti batasan ukuran indeks yang ada maksimum 16 kolom kunci, dan ukuran kunci indeks total 900 byte.
Ukuran total semua kolom nonkey hanya dibatasi oleh ukuran kolom yang ditentukan dalam INCLUDE klausul; misalnya, kolom varchar(max) dibatasi hingga 2 GB.
Panduan modifikasi kolom
Saat Anda mengubah kolom tabel yang telah didefinisikan sebagai kolom yang disertakan, pembatasan berikut berlaku:
Kolom non-kunci tidak dapat dihilangkan dari tabel kecuali indeks dihilangkan terlebih dahulu.
Kolom non-kunci tidak dapat diubah, kecuali untuk melakukan hal berikut:
Ubah nullability kolom dari NOT NULL ke NULL.
Tingkatkan panjang kolom varchar, nvarchar, atau varbinary .
Catatan
Pembatasan modifikasi kolom ini juga berlaku untuk kolom kunci indeks.
Rekomendasi desain
Desain ulang indeks non-kluster dengan ukuran kunci indeks besar sehingga hanya kolom yang digunakan untuk pencarian dan pencarian yang merupakan kolom kunci. Buat semua kolom lain yang mencakup kolom nonkey yang disertakan kueri. Dengan cara ini, Anda memiliki semua kolom yang diperlukan untuk mencakup kueri, tetapi kunci indeks itu sendiri kecil dan efisien.
Misalnya, asumsikan bahwa Anda ingin merancang indeks untuk mencakup kueri berikut.
SELECT AddressLine1, AddressLine2, City, StateProvinceID, PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
GO
Untuk mencakup kueri, setiap kolom harus ditentukan dalam indeks. Meskipun Anda dapat menentukan semua kolom sebagai kolom kunci, ukuran kuncinya adalah 334 byte. Karena satu-satunya kolom yang digunakan sebagai kriteria pencarian adalah PostalCode kolom , memiliki panjang 30 byte, desain indeks yang lebih baik akan menentukan PostalCode sebagai kolom kunci dan menyertakan semua kolom lain sebagai kolom non-kunci.
Pernyataan berikut membuat indeks dengan kolom yang disertakan untuk mencakup kueri.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Untuk memvalidasi bahwa indeks mencakup kueri, buat indeks, lalu tampilkan perkiraan rencana eksekusi.
Jika rencana eksekusi hanya SELECT memperlihatkan operator dan operator Pencarian Indeks untuk IX_Address_PostalCode indeks, kueri dicakup oleh indeks.
Anda dapat menghilangkan indeks dengan pernyataan berikut:
DROP INDEX IX_Address_PostalCode
ON Person.Address;
GO
Pertimbangan performa
Hindari menambahkan kolom yang tidak perlu. Menambahkan terlalu banyak kolom indeks, kunci, atau non-kunci, dapat memiliki implikasi performa berikut:
Lebih sedikit baris indeks yang pas pada halaman. Ini dapat menciptakan peningkatan I/O dan mengurangi efisiensi cache.
Lebih banyak ruang disk diperlukan untuk menyimpan indeks. Secara khusus, menambahkan jenis data varchar(max), nvarchar(max), varbinary(max), atau xml karena kolom indeks nonkey dapat secara signifikan meningkatkan persyaratan ruang disk. Ini karena nilai kolom disalin ke tingkat daun indeks. Oleh karena itu, mereka berada di indeks dan tabel dasar.
Pemeliharaan indeks dapat meningkatkan waktu yang diperlukan untuk melakukan modifikasi, penyisipan, pembaruan, atau penghapusan, ke tabel atau tampilan terindeks yang mendasar.
Anda harus menentukan apakah perolehan dalam performa kueri melebihi efek terhadap performa selama modifikasi data dan dalam persyaratan ruang disk tambahan.
Panduan desain indeks unik
Indeks unik menjamin bahwa kunci indeks tidak berisi nilai duplikat dan oleh karena itu setiap baris dalam tabel dalam beberapa cara unik. Menentukan indeks unik masuk akal hanya ketika keunikan adalah karakteristik data itu sendiri. Misalnya, jika Anda ingin memastikan bahwa nilai dalam NationalIDNumber kolom dalam HumanResources.Employee tabel unik, saat kunci utama adalah EmployeeID, buat UNIQUE batasan pada NationalIDNumber kolom. Jika pengguna mencoba memasukkan nilai yang sama di kolom tersebut untuk lebih dari satu karyawan, pesan kesalahan ditampilkan dan nilai duplikat tidak dimasukkan.
Dengan indeks unik multikolom, indeks menjamin bahwa setiap kombinasi nilai dalam kunci indeks unik. Misalnya, jika indeks unik dibuat pada kombinasi LastNamekolom , , FirstNamedan MiddleName , tidak ada dua baris dalam tabel yang dapat memiliki kombinasi nilai yang sama untuk kolom ini.
Indeks berkluster dan non-kluster dapat bersifat unik. Jika data dalam kolom unik, Anda dapat membuat indeks berkluster unik dan beberapa indeks berkluster unik pada tabel yang sama.
Manfaat indeks unik meliputi yang berikut ini:
- Integritas data kolom yang ditentukan dipastikan.
- Informasi tambahan yang berguna untuk pengoptimal kueri disediakan.
PRIMARY KEY Membuat atau UNIQUE membatasi secara otomatis membuat indeks unik pada kolom yang ditentukan. Tidak ada perbedaan signifikan antara membuat UNIQUE batasan dan membuat indeks unik yang independen dari batasan. Validasi data terjadi dengan cara yang sama dan pengoptimal kueri tidak membedakan antara indeks unik yang dibuat oleh batasan atau dibuat secara manual. Namun, Anda harus membuat UNIQUE batasan atau PRIMARY KEY pada kolom saat integritas data adalah tujuannya. Dengan melakukan ini, tujuan indeks jelas.
Pertimbangan
Indeks, UNIQUE batasan, atau PRIMARY KEY batasan unik tidak dapat dibuat jika nilai kunci duplikat ada dalam data.
Jika data unik dan Anda ingin keunikan diberlakukan, membuat indeks unik alih-alih indeks nonunique pada kombinasi kolom yang sama menyediakan informasi tambahan untuk pengoptimal kueri yang dapat menghasilkan rencana eksekusi yang lebih efisien. Membuat indeks unik (sebaiknya dengan membuat UNIQUE batasan) direkomendasikan dalam kasus ini.
Indeks nonclustered unik dapat berisi kolom non-kunci yang disertakan. Untuk informasi selengkapnya, lihat Indeks dengan kolom yang disertakan.
Panduan desain indeks yang difilter
Indeks yang difilter adalah indeks non-kluster yang dioptimalkan, terutama cocok untuk mencakup kueri yang memilih dari subset data yang ditentukan dengan baik. Ini menggunakan predikat filter untuk mengindeks sebagian baris dalam tabel. Indeks terfilter yang dirancang dengan baik dapat meningkatkan performa kueri, mengurangi biaya pemeliharaan indeks, dan mengurangi biaya penyimpanan indeks dibandingkan dengan indeks tabel penuh.
Indeks yang difilter dapat memberikan keuntungan berikut daripada indeks tabel penuh:
Peningkatan performa kueri dan kualitas rencana
Indeks terfilter yang dirancang dengan baik meningkatkan performa kueri dan kualitas rencana eksekusi karena lebih kecil dari indeks nonclustered tabel penuh dan memiliki statistik yang difilter. Statistik yang difilter lebih akurat daripada statistik tabel penuh karena hanya mencakup baris dalam indeks yang difilter.
Mengurangi biaya pemeliharaan indeks
Indeks dipertahankan hanya ketika pernyataan bahasa manipulasi data (DML) memengaruhi data dalam indeks. Indeks yang difilter mengurangi biaya pemeliharaan indeks dibandingkan dengan indeks non-kluster tabel penuh karena lebih kecil dan hanya dipertahankan ketika data dalam indeks terpengaruh. Dimungkinkan untuk memiliki sejumlah besar indeks yang difilter, terutama ketika berisi data yang jarang terpengaruh. Demikian pula, jika indeks yang difilter hanya berisi data yang sering terpengaruh, ukuran indeks yang lebih kecil mengurangi biaya pembaruan statistik.
Mengurangi biaya penyimpanan indeks
Membuat indeks yang difilter dapat mengurangi penyimpanan disk untuk indeks non-kluster saat indeks tabel penuh tidak diperlukan. Anda dapat mengganti indeks non-kluster tabel penuh dengan beberapa indeks yang difilter tanpa meningkatkan persyaratan penyimpanan secara signifikan.
Indeks yang difilter berguna saat kolom berisi subset data yang ditentukan dengan baik yang direferensikan dalam SELECT pernyataan. Contohnya adalah:
- Kolom jarang yang hanya berisi beberapa nilai non.
NULL
- Kolom heterogen yang berisi kategori data.
- Kolom yang berisi rentang nilai seperti jumlah dolar, waktu, dan tanggal.
- Partisi tabel yang ditentukan oleh logika perbandingan sederhana untuk nilai kolom.
Mengurangi biaya pemeliharaan untuk indeks yang difilter paling terlihat ketika jumlah baris dalam indeks kecil dibandingkan dengan indeks tabel penuh. Jika indeks yang difilter menyertakan sebagian besar baris dalam tabel, mungkin lebih mahal untuk dipertahankan daripada indeks tabel penuh. Dalam hal ini, Anda harus menggunakan indeks tabel penuh alih-alih indeks yang difilter.
Indeks yang difilter ditentukan pada satu tabel dan hanya mendukung operator perbandingan sederhana. Jika Anda memerlukan ekspresi filter yang mereferensikan beberapa tabel atau memiliki logika kompleks, Anda harus membuat tampilan.
Pertimbangan Desain
Untuk merancang indeks yang difilter yang efektif, penting untuk memahami kueri apa yang digunakan aplikasi Anda dan bagaimana mereka berhubungan dengan subset data Anda. Beberapa contoh data yang memiliki subset yang terdefinisi dengan baik adalah kolom dengan sebagian besar NULL nilai, kolom dengan kategori nilai dan kolom heterogen dengan rentang nilai yang berbeda. Pertimbangan desain berikut memberikan berbagai skenario ketika indeks yang difilter dapat memberikan keuntungan daripada indeks tabel penuh.
Tip
Definisi indeks penyimpan kolom non-kluster mendukung penggunaan kondisi yang difilter. Untuk meminimalkan dampak performa penambahan indeks penyimpan kolom pada tabel OLTP, gunakan kondisi yang difilter untuk membuat indeks penyimpan kolom non-kluster hanya pada data dingin beban kerja operasional Anda.
Indeks yang difilter untuk subset data
Saat kolom hanya memiliki beberapa nilai yang relevan untuk kueri, Anda dapat membuat indeks yang difilter pada subset nilai. Misalnya, saat nilai dalam kolom sebagian NULL besar dan kueri hanya memilih dari nilai non,NULL Anda dapat membuat indeks yang difilter untuk baris non-dataNULL . Indeks yang dihasilkan lebih kecil dan biayanya lebih murah untuk dipertahankan daripada indeks nonkluster tabel penuh yang ditentukan pada kolom kunci yang sama.
Misalnya, database sampel AdventureWorks memiliki Production.BillOfMaterials tabel dengan 2.679 baris. Kolom EndDate hanya memiliki 199 baris yang berisi non-nilaiNULL dan 2480 baris lainnya berisi NULL. Indeks yang difilter berikut akan mencakup kueri yang mengembalikan kolom yang ditentukan dalam indeks dan yang hanya memilih baris dengan nilai bukanNULL untuk EndDate.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
GO
Indeks FIBillOfMaterialsWithEndDate yang difilter valid untuk kueri berikut. Tampilkan Perkiraan Rencana Eksekusi untuk menentukan apakah pengoptimal kueri menggunakan indeks yang difilter.
SELECT ProductAssemblyID, ComponentID, StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
GO
Untuk informasi selengkapnya tentang cara membuat indeks yang difilter dan cara menentukan ekspresi predikat indeks yang difilter, lihat Membuat indeks yang difilter.
Indeks yang difilter untuk data heterogen
Saat tabel memiliki baris data heterogen, Anda bisa membuat indeks yang difilter untuk satu atau beberapa kategori data.
Misalnya, produk yang tercantum dalam Production.Product tabel masing-masing ditetapkan ke ProductSubcategoryID, yang pada gilirannya terkait dengan kategori produk Sepeda, Komponen, Pakaian, atau Aksesori. Kategori ini bersifat heterogen karena nilai kolomnya dalam Production.Product tabel tidak berkorelasi erat. Misalnya, kolom Color, , ReorderPointListPrice, Weight, Class, dan Style memiliki karakteristik unik untuk setiap kategori produk. Misalkan ada kueri yang sering untuk aksesori, yang memiliki subkatoner antara 27 dan 36 inklusif. Anda dapat meningkatkan performa kueri untuk aksesori dengan membuat indeks yang difilter pada subkatoner aksesori seperti yang ditunjukkan dalam contoh berikut.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
Include (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
GO
Indeks FIProductAccessories yang difilter mencakup kueri berikut karena hasil kueri terkandung dalam indeks dan rencana kueri tidak menyertakan pencarian tabel dasar. Misalnya, ekspresi ProductSubcategoryID = 33 predikat kueri adalah subset dari predikat ProductSubcategoryID >= 27 indeks yang difilter dan ProductSubcategoryID <= 36, ProductSubcategoryID kolom dan ListPrice dalam predikat kueri adalah kolom kunci dalam indeks, dan nama disimpan dalam tingkat daun indeks sebagai kolom yang disertakan.
SELECT Name, ProductSubcategoryID, ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33 AND ListPrice > 25.00;
GO
Kolom kunci
Ini adalah praktik terbaik untuk menyertakan beberapa kunci atau kolom yang disertakan dalam definisi indeks yang difilter, dan untuk menggabungkan hanya kolom yang diperlukan bagi pengoptimal kueri untuk memilih indeks yang difilter untuk rencana eksekusi kueri. Pengoptimal kueri dapat memilih indeks yang difilter untuk kueri terlepas dari apakah itu terjadi atau tidak mencakup kueri. Namun, pengoptimal kueri lebih mungkin memilih indeks yang difilter jika mencakup kueri.
Dalam beberapa kasus, indeks yang difilter mencakup kueri tanpa menyertakan kolom dalam ekspresi indeks yang difilter sebagai kunci atau kolom yang disertakan dalam definisi indeks yang difilter. Panduan berikut menjelaskan kapan kolom dalam ekspresi indeks yang difilter harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter. Contoh mengacu pada indeks yang difilter, FIBillOfMaterialsWithEndDate yang dibuat sebelumnya.
Kolom dalam ekspresi indeks yang difilter tidak perlu menjadi kunci atau kolom yang disertakan dalam definisi indeks yang difilter jika ekspresi indeks yang difilter setara dengan predikat kueri dan kueri tidak mengembalikan kolom dalam ekspresi indeks yang difilter dengan hasil kueri. Misalnya, FIBillOfMaterialsWithEndDate mencakup kueri berikut karena predikat kueri setara dengan ekspresi filter, dan EndDate tidak dikembalikan dengan hasil kueri. FIBillOfMaterialsWithEndDate tidak perlu EndDate sebagai kunci atau kolom yang disertakan dalam definisi indeks yang difilter.
SELECT ComponentID, StartDate FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Kolom dalam ekspresi indeks yang difilter harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter jika predikat kueri menggunakan kolom dalam perbandingan yang tidak setara dengan ekspresi indeks yang difilter. Misalnya, FIBillOfMaterialsWithEndDate valid untuk kueri berikut karena memilih subset baris dari indeks yang difilter. Namun, kueri ini tidak mencakup kueri berikut karena EndDate digunakan dalam perbandingan EndDate > '20040101', yang tidak setara dengan ekspresi indeks yang difilter. Prosesor kueri tidak dapat menjalankan kueri ini tanpa mencari nilai EndDate. Oleh karena itu, EndDate harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter.
SELECT ComponentID, StartDate FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
Kolom dalam ekspresi indeks yang difilter harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter jika kolom berada dalam tataan hasil kueri. Misalnya, FIBillOfMaterialsWithEndDate tidak mencakup kueri berikut karena mengembalikan EndDate kolom dalam hasil kueri. Oleh karena itu, EndDate harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter.
SELECT ComponentID, StartDate, EndDate FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Kunci indeks terkluster tabel tidak perlu menjadi kunci atau kolom yang disertakan dalam definisi indeks yang difilter. Kunci indeks berkluster secara otomatis disertakan dalam semua indeks non-kluster, termasuk indeks yang difilter.
Untuk menghilangkan FIBillOfMaterialsWithEndDate indeks dan FIProductAccessories , jalankan pernyataan berikut:
DROP INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials;
GO
DROP INDEX FIProductAccessories
ON Production.Product;
GO
Operator konversi data dalam predikat filter
Jika operator perbandingan yang ditentukan dalam ekspresi indeks yang difilter dari indeks yang difilter menghasilkan konversi data implisit atau eksplisit, kesalahan terjadi jika konversi terjadi di sisi kiri operator perbandingan. Solusinya adalah menulis ekspresi indeks yang difilter dengan operator konversi data (CAST atau CONVERT) di sisi kanan operator perbandingan.
Contoh berikut membuat tabel dengan berbagai jenis data.
CREATE TABLE dbo.TestTable (
a INT,
b VARBINARY(4)
);
GO
Dalam definisi indeks yang difilter berikut, kolom b secara implisit dikonversi ke jenis data bilangan bulat untuk tujuan membandingkannya dengan konstanta 1. Ini menghasilkan pesan kesalahan 10611 karena konversi terjadi di sisi kiri operator dalam predikat yang difilter.
CREATE NONCLUSTERED INDEX TestTabIndex ON dbo.TestTable (a, b)
WHERE b = 1;
GO
Solusinya adalah mengonversi konstanta di sisi kanan menjadi tipe yang sama dengan kolom b, seperti yang terlihat dalam contoh berikut:
CREATE INDEX TestTabIndex ON dbo.TestTable (a, b)
WHERE b = CONVERT(VARBINARY(4), 1);
GO
Memindahkan konversi data dari sisi kiri ke sisi kanan operator perbandingan dapat mengubah arti konversi. Dalam contoh sebelumnya, ketika CONVERT operator ditambahkan ke sisi kanan, perbandingan berubah dari perbandingan bilangan bulat dengan perbandingan varbiner .
Hilangkan objek yang dibuat dalam contoh ini dengan menjalankan pernyataan berikut:
DROP TABLE TestTable;
GO
Arsitektur indeks penyimpan kolom
Indeks penyimpan kolom adalah teknologi untuk menyimpan, mengambil, dan mengelola data dengan menggunakan format data kolom, yang disebut penyimpan kolom. Untuk informasi selengkapnya, lihat Indeks penyimpan kolom: Gambaran Umum.
Untuk informasi versi dan untuk mengetahui apa yang baru, kunjungi Apa yang baru dalam indeks penyimpan kolom.
Mengetahui dasar-dasar ini memudahkan untuk memahami artikel penyimpan kolom lain yang menjelaskan cara menggunakannya secara efektif.
Penyimpanan data menggunakan penyimpan kolom dan kompresi rowstore
Saat membahas indeks penyimpan kolom, kami menggunakan istilah rowstore dan columnstore untuk menekankan format untuk penyimpanan data. Indeks penyimpan kolom menggunakan kedua jenis penyimpanan.
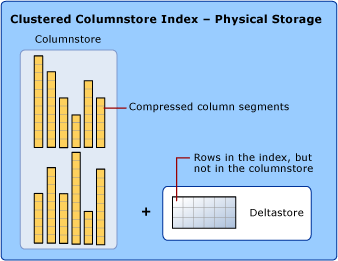
Penyimpan kolom adalah data yang secara logis diatur sebagai tabel dengan baris dan kolom, dan disimpan secara fisik dalam format data yang bijaksana kolom.
Indeks penyimpan kolom secara fisik menyimpan sebagian besar data dalam format penyimpan kolom. Dalam format penyimpan kolom, data dikompresi dan tidak dikompresi sebagai kolom. Tidak perlu membongkar nilai lain di setiap baris yang tidak diminta oleh kueri. Ini membuatnya cepat untuk memindai seluruh kolom tabel besar.
Rowstore adalah data yang secara logis diatur sebagai tabel dengan baris dan kolom, lalu disimpan secara fisik dalam format data yang bijaksana baris. Ini telah menjadi cara tradisional untuk menyimpan data tabel relasional seperti timbunan atau indeks pohon B+ berkluster.
Indeks penyimpan kolom juga secara fisik menyimpan beberapa baris dalam format rowstore yang disebut deltastore. Deltastore, juga disebut grup baris delta, adalah tempat penahanan untuk baris yang jumlahnya terlalu sedikit untuk memenuhi syarat kompresi ke penyimpanan kolom. Setiap grup baris delta diimplementasikan sebagai indeks pohon B+ berkluster.
Deltastore adalah tempat penahanan untuk baris yang jumlahnya terlalu sedikit untuk dikompresi ke dalam penyimpan kolom. Deltastore menyimpan baris dalam format rowstore.
Untuk informasi selengkapnya tentang istilah dan konsep penyimpan kolom, lihat Indeks penyimpan kolom: Gambaran Umum.
Operasi dilakukan pada grup baris dan segmen kolom
Indeks penyimpan kolom mengelompokkan baris ke dalam unit yang dapat dikelola. Masing-masing unit ini disebut grup baris. Untuk performa terbaik, jumlah baris dalam grup baris cukup besar untuk meningkatkan tingkat kompresi dan cukup kecil untuk mendapatkan manfaat dari operasi dalam memori.
Misalnya, indeks penyimpan kolom melakukan operasi ini pada grup baris:
- Memadatkan grup baris ke dalam penyimpan kolom. Pemadatan dilakukan pada setiap segmen kolom dalam grup baris.
- Menggabungkan grup baris selama
ALTER INDEX ... REORGANIZE operasi, termasuk menghapus data yang dihapus.
- Membuat grup baris baru selama
ALTER INDEX ... REBUILD operasi.
- Laporan tentang kesehatan grup baris dan fragmentasi dalam tampilan manajemen dinamis (DMV).
Deltastore terdiri dari satu atau beberapa grup baris yang disebut grup baris delta. Setiap grup baris delta adalah indeks pohon B+ berkluster yang menyimpan beban massal kecil dan menyisipkan hingga grup baris berisi 1.048.576 baris, pada saat itu proses yang disebut tuple-mover secara otomatis memadatkan grup baris tertutup ke dalam columnstore.
Untuk informasi selengkapnya tentang status grup baris, lihat sys.dm_db_column_store_row_group_physical_stats.
Tip
Memiliki terlalu banyak grup baris kecil mengurangi kualitas indeks penyimpan kolom. Operasi reorganisasi menggabungkan grup baris yang lebih kecil, mengikuti kebijakan ambang internal yang menentukan cara menghapus baris yang dihapus dan menggabungkan grup baris terkompresi. Setelah penggabungan, kualitas indeks harus ditingkatkan.
Di SQL Server 2019 (15.x) dan versi yang lebih baru, tuple-mover dibantu oleh tugas penggabungan latar belakang yang secara otomatis memadatkan grup baris delta yang lebih OPEN kecil yang telah ada selama beberapa waktu seperti yang ditentukan oleh ambang internal, atau menggabungkan COMPRESSED grup baris dari tempat sejumlah besar baris telah dihapus.
Setiap kolom memiliki beberapa nilainya di setiap grup baris. Nilai-nilai ini disebut segmen kolom. Setiap grup baris berisi satu segmen kolom untuk setiap kolom dalam tabel. Setiap kolom memiliki satu segmen kolom di setiap grup baris.
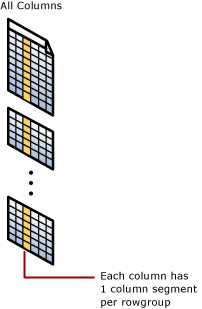
Saat indeks penyimpan kolom memadatkan grup baris, indeks tersebut memadatkan setiap segmen kolom secara terpisah. Untuk membongkar seluruh kolom, indeks penyimpan kolom hanya perlu membongkar satu segmen kolom dari setiap grup baris.
Untuk informasi selengkapnya tentang istilah dan konsep penyimpan kolom, lihat Indeks penyimpan kolom: Gambaran Umum.
Beban dan sisipan kecil masuk ke deltastore
Indeks penyimpan kolom meningkatkan pemadatan dan performa penyimpan kolom dengan memadatkan setidaknya 102.400 baris sekaligus ke dalam indeks penyimpan kolom. Untuk memadatkan baris secara massal, indeks penyimpan kolom mengakumulasi beban kecil dan sisipan di deltastore. Operasi deltastore ditangani di belakang layar. Untuk mengembalikan hasil kueri yang benar, indeks penyimpan kolom berkluster menggabungkan hasil kueri dari penyimpan kolom dan deltastore.
Baris masuk ke deltastore saat:
- Disisipkan dengan
INSERT INTO ... VALUES pernyataan.
- Di akhir beban massal, dan jumlahnya kurang dari 102.400.
- Diperbarui. Setiap pembaruan diimplementasikan sebagai penghapusan dan penyisipan.
Deltastore juga menyimpan daftar ID untuk baris yang dihapus yang telah ditandai sebagai dihapus tetapi belum dihapus secara fisik dari penyimpan kolom.
Untuk informasi selengkapnya tentang istilah dan konsep penyimpan kolom, lihat Indeks penyimpan kolom: Gambaran Umum.
Saat grup baris delta penuh, grup baris tersebut akan dikompresi ke dalam penyimpan kolom
Indeks penyimpan kolom berkluster mengumpulkan hingga 1.048.576 baris di setiap grup baris delta sebelum memadatkan grup baris ke dalam penyimpan kolom. Ini meningkatkan pemadatan indeks penyimpan kolom. Saat grup baris delta mencapai jumlah baris maksimum, grup baris tersebut beralih dari status OPEN ke CLOSED . Proses latar belakang bernama tuple-mover memeriksa grup baris tertutup. Jika proses menemukan grup baris tertutup, proses akan memadatkan grup baris dan menyimpannya ke dalam penyimpan kolom.
Ketika grup baris delta telah dikompresi, grup baris delta yang ada beralih ke status TOMBSTONE untuk dihapus nanti oleh tuple-mover ketika tidak ada referensi ke sana, dan grup baris terkompresi baru ditandai sebagai COMPRESSED.
Untuk informasi selengkapnya tentang status grup baris, lihat sys.dm_db_column_store_row_group_physical_stats.
Anda dapat memaksa grup baris delta ke dalam penyimpan kolom dengan menggunakan ALTER INDEX untuk membangun kembali atau mengatur ulang indeks. Jika ada tekanan memori selama pemadatan, indeks penyimpan kolom mungkin mengurangi jumlah baris dalam grup baris terkompresi.
Untuk informasi selengkapnya tentang istilah dan konsep penyimpan kolom, lihat Indeks penyimpan kolom: Gambaran Umum.
Setiap partisi tabel memiliki grup baris dan grup baris delta sendiri
Konsep pemartisian sama dalam indeks berkluster, timbunan, dan indeks penyimpan kolom. Pemartisian tabel membagi tabel menjadi grup baris yang lebih kecil sesuai dengan rentang nilai kolom. Ini sering digunakan untuk mengelola data. Misalnya, Anda dapat membuat partisi untuk setiap tahun data, lalu menggunakan pengalihan partisi untuk mengarsipkan data ke penyimpanan yang lebih murah. Pengalihan partisi berfungsi pada indeks penyimpan kolom dan memudahkan untuk memindahkan partisi data ke lokasi lain.
Grup baris selalu ditentukan dalam partisi tabel. Ketika indeks penyimpan kolom dipartisi, setiap partisi memiliki grup baris terkompresi dan grup baris delta sendiri.
Tip
Pertimbangkan untuk menggunakan pemartisian tabel jika ada kebutuhan untuk menghapus data dari penyimpan kolom. Beralih dan memotong partisi yang tidak diperlukan lagi adalah strategi yang efisien untuk menghapus data tanpa menghasilkan fragmentasi yang diperkenalkan dengan memiliki grup baris yang lebih kecil.
Setiap partisi dapat memiliki beberapa grup baris delta
Setiap partisi dapat memiliki lebih dari satu grup baris delta. Ketika indeks penyimpan kolom perlu menambahkan data ke grup baris delta dan grup baris delta dikunci, indeks penyimpan kolom mencoba mendapatkan kunci pada grup baris delta yang berbeda. Jika tidak ada grup baris delta yang tersedia, indeks penyimpan kolom membuat grup baris delta baru. Misalnya, tabel dengan 10 partisi dapat dengan mudah memiliki 20 grup baris delta atau lebih.
Menggabungkan indeks penyimpan kolom dan rowstore pada tabel yang sama
Indeks nonclustered berisi salinan bagian atau semua baris dan kolom dalam tabel yang mendasar. Indeks didefinisikan sebagai satu atau beberapa kolom tabel, dan memiliki kondisi opsional yang memfilter baris.
Anda dapat membuat indeks penyimpan kolom nonclustered yang dapat diperbarui pada tabel rowstore. Indeks penyimpan kolom menyimpan salinan data sehingga Anda memerlukan penyimpanan tambahan. Namun, data dalam indeks penyimpan kolom dikompresi ke ukuran yang lebih kecil dari yang diperlukan tabel rowstore. Dengan melakukan ini, Anda dapat menjalankan analitik pada indeks penyimpan kolom dan transaksi pada indeks rowstore secara bersamaan. Penyimpan kolom diperbarui saat data berubah dalam tabel rowstore, sehingga kedua indeks bekerja terhadap data yang sama.
Anda dapat memiliki satu atau beberapa indeks rowstore nonclustered pada indeks penyimpan kolom. Dengan melakukan ini, Anda dapat melakukan pencarian tabel yang efisien di penyimpan kolom yang mendasar. Opsi lain juga tersedia. Misalnya, Anda dapat menerapkan batasan kunci utama dengan menggunakan UNIQUE batasan pada tabel rowstore. Karena nilai nonunique gagal disisipkan ke dalam tabel rowstore, Mesin Database tidak dapat menyisipkan nilai ke dalam penyimpan kolom.
Pertimbangan performa
Definisi indeks penyimpan kolom non-kluster mendukung penggunaan kondisi yang difilter. Untuk meminimalkan dampak performa penambahan indeks penyimpan kolom pada tabel OLTP, gunakan kondisi yang difilter untuk membuat indeks penyimpan kolom non-kluster hanya pada data dingin beban kerja operasional Anda.
Tabel dalam memori dapat memiliki satu indeks penyimpan kolom. Anda dapat membuatnya saat tabel dibuat atau menambahkannya nanti dengan ALTER TABLE (Transact-SQL). Sebelum SQL Server 2016 (13.x), hanya tabel berbasis disk yang dapat memiliki indeks penyimpan kolom.
Untuk informasi selengkapnya, lihat Indeks penyimpan kolom - Performa kueri.
Panduan desain
- Tabel rowstore dapat memiliki satu indeks penyimpan kolom nonclustered yang dapat diperbarui. Sebelum SQL Server 2014 (12.x), indeks penyimpan kolom non-kluster bersifat baca-saja.
Untuk informasi selengkapnya, lihat Indeks penyimpan kolom - Panduan desain.
Panduan desain indeks hash
Semua tabel yang dioptimalkan memori harus memiliki setidaknya satu indeks, karena ini adalah indeks yang menghubungkan baris bersama-sama. Pada tabel yang dioptimalkan memori, setiap indeks juga dioptimalkan memori. Indeks hash adalah salah satu jenis indeks yang mungkin dalam tabel yang dioptimalkan memori. Untuk informasi selengkapnya, lihat Indeks pada Tabel yang Dioptimalkan Memori.
Berlaku untuk: SQL Server, Azure SQL Database, dan Azure SQL Managed Instance.
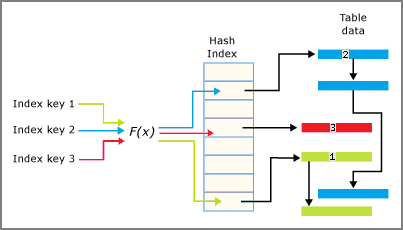
Arsitektur indeks hash
Indeks hash terdiri dari array pointer, dan setiap elemen array disebut wadah hash.
- Setiap wadah adalah 8 byte, yang digunakan untuk menyimpan alamat memori daftar tautan entri kunci.
- Setiap entri adalah nilai untuk kunci indeks, ditambah alamat baris yang sesuai dalam tabel yang dioptimalkan memori yang mendasar.
- Setiap entri menunjuk ke entri berikutnya dalam daftar tautan entri, semua ditautkan ke wadah saat ini.
Jumlah wadah harus ditentukan pada waktu definisi indeks:
- Semakin rendah rasio wadah terhadap baris tabel atau ke nilai yang berbeda, semakin lama daftar tautan wadah rata-rata.
- Daftar tautan pendek berkinerja lebih cepat daripada daftar tautan panjang.
- Jumlah maksimum wadah dalam indeks hash adalah 1.073.741.824.
Tip
Untuk menentukan hak BUCKET_COUNT untuk data Anda, lihat Mengonfigurasi jumlah wadah indeks hash.
Fungsi hash diterapkan ke kolom kunci indeks dan hasil fungsi menentukan wadah apa yang termasuk dalam kunci tersebut. Setiap wadah memiliki pointer ke baris yang nilai kunci hash-nya dipetakan ke wadah tersebut.
Fungsi hashing yang digunakan untuk indeks hash memiliki karakteristik berikut:
- Mesin Database memiliki satu fungsi hash yang digunakan untuk semua indeks hash.
- Fungsi hash adalah deterministik. Nilai kunci input yang sama selalu dipetakan ke wadah yang sama dalam indeks hash.
- Beberapa kunci indeks mungkin dipetakan ke wadah hash yang sama.
- Fungsi hash seimbang, yang berarti bahwa distribusi nilai kunci indeks melalui wadah hash biasanya mengikuti Distribusi kurva Poisson atau bel, bukan distribusi linier datar.
- Distribusi Poisson bukanlah distribusi yang merata. Nilai kunci indeks tidak didistribusikan secara merata dalam wadah hash.
- Jika dua kunci indeks dipetakan ke wadah hash yang sama, ada tabrakan hash. Sejumlah besar tabrakan hash dapat berdampak pada performa pada operasi baca. Tujuan realistis adalah untuk 30 persen wadah berisi dua nilai kunci yang berbeda.
Interplay indeks hash dan wadah dirangkum dalam gambar berikut.
Mengonfigurasi jumlah wadah indeks hash
Jumlah wadah indeks hash ditentukan pada waktu pembuatan indeks, dan dapat diubah menggunakan ALTER TABLE...ALTER INDEX REBUILD sintaks.
Dalam kebanyakan kasus, jumlah wadah idealnya adalah antara 1 dan 2 kali jumlah nilai yang berbeda dalam kunci indeks.
Anda mungkin tidak selalu dapat memprediksi berapa banyak nilai yang dapat dimiliki kunci indeks tertentu, atau akan memilikinya. Performa biasanya masih baik jika BUCKET_COUNT nilainya dalam 10 kali dari jumlah nilai kunci aktual, dan menilai secara berlebihan umumnya lebih baik daripada meremehkan.
Terlalu sedikit wadah dapat memiliki kelemahan berikut:
- Lebih banyak tabrakan hash dari nilai kunci yang berbeda.
- Setiap nilai berbeda dipaksa untuk berbagi wadah yang sama dengan nilai yang berbeda.
- Panjang rantai rata-rata per ember tumbuh.
- Semakin lama rantai wadah, semakin lambat kecepatan pencarian kesetaraan dalam indeks.
Terlalu banyak wadah dapat memiliki kelemahan berikut:
- Jumlah wadah yang terlalu tinggi dapat menghasilkan wadah yang lebih kosong.
- Wadah kosong memengaruhi performa pemindaian indeks penuh. Jika pemindaian dilakukan secara teratur, pertimbangkan untuk memilih jumlah wadah yang dekat dengan jumlah nilai kunci indeks yang berbeda.
- Wadah kosong menggunakan memori, meskipun setiap wadah hanya menggunakan 8 byte.
Catatan
Menambahkan lebih banyak wadah tidak melakukan apa pun untuk mengurangi penautan bersama entri yang berbagi nilai duplikat. Tingkat duplikasi nilai digunakan untuk memutuskan apakah hash adalah jenis indeks yang sesuai, bukan untuk menghitung jumlah wadah.
Pertimbangan performa
Performa indeks hash adalah:
- Sangat baik ketika predikat dalam
WHERE klausul menentukan nilai yang tepat untuk setiap kolom dalam kunci indeks hash. Indeks hash kembali ke pemindaian yang diberikan predikat ketidaksetaraan.
- Buruk ketika predikat dalam
WHERE klausa mencari rentang nilai dalam kunci indeks.
- Buruk ketika predikat dalam
WHERE klausul menetapkan satu nilai tertentu untuk kolom pertama dari kunci indeks hash dua kolom, tetapi tidak menentukan nilai untuk kolom kunci lainnya .
Tip
Predikat harus menyertakan semua kolom dalam kunci indeks hash. Indeks hash memerlukan kunci (untuk hash) untuk dicari ke dalam indeks.
Jika kunci indeks terdiri dari dua kolom dan WHERE klausa hanya menyediakan kolom pertama, Mesin Database tidak memiliki kunci lengkap untuk hash. Ini menghasilkan rencana kueri pemindaian indeks.
Jika indeks hash digunakan, dan jumlah kunci indeks unik adalah 100 kali (atau lebih) dari jumlah baris, pertimbangkan untuk meningkatkan ke jumlah wadah yang lebih besar untuk menghindari rantai baris besar, atau gunakan indeks yang tidak dikluster sebagai gantinya.
Pertimbangan deklarasi
Indeks hash hanya dapat ada pada tabel yang dioptimalkan memori. Ini tidak dapat ada pada tabel berbasis disk.
Indeks hash dapat dinyatakan sebagai:
UNIQUE, atau dapat default ke nonunique.NONCLUSTERED, yang merupakan default.
Contoh sintaks berikut membuat indeks hash, di luar CREATE TABLE pernyataan:
ALTER TABLE MyTable_memop
ADD INDEX ix_hash_Column2 UNIQUE
HASH (Column2) WITH (BUCKET_COUNT = 64);
Versi baris dan pengumpulan sampah
Dalam tabel yang dioptimalkan memori, saat baris dipengaruhi oleh UPDATE, tabel membuat versi baris yang diperbarui. Selama transaksi pembaruan, sesi lain mungkin dapat membaca versi baris yang lebih lama, sehingga menghindari perlambatan performa yang terkait dengan kunci baris.
Indeks hash juga dapat memiliki versi entri yang berbeda untuk mengakomodasi pembaruan.
Kemudian ketika versi lama tidak lagi diperlukan, utas pengumpulan sampah (GC) melintasi wadah dan daftar tautan mereka untuk membersihkan entri lama. Utas GC berkinerja lebih baik jika panjang rantai daftar tautan pendek. Untuk informasi selengkapnya, lihat Pengumpulan Sampah OLTP Dalam Memori.
Pedoman desain indeks nonclustered yang dioptimalkan memori
Indeks nonkluster adalah salah satu jenis indeks yang mungkin dalam tabel yang dioptimalkan memori. Untuk informasi selengkapnya, lihat Indeks pada Tabel yang Dioptimalkan Memori.
Berlaku untuk: SQL Server, Azure SQL Database, dan Azure SQL Managed Instance.
Arsitektur indeks nonclustered dalam memori
Indeks nonclustered dalam memori diimplementasikan menggunakan struktur data yang disebut pohon Bw, awalnya digambarkan dan dijelaskan oleh Microsoft Research pada tahun 2011. Pohon Bw adalah variasi kunci dan bebas kait dari pohon B. Untuk informasi selengkapnya, lihat Bw-tree: Pohon B untuk Platform Perangkat Keras Baru.
Pada tingkat tinggi, pohon Bw dapat dipahami sebagai peta halaman yang diatur oleh ID halaman (PidMap), fasilitas untuk mengalokasikan dan menggunakan kembali ID halaman (PidAlloc) dan sekumpulan halaman yang ditautkan dalam peta halaman dan satu sama lain. Ketiga subkomponen tingkat tinggi ini membentuk struktur internal dasar pohon Bw.
Strukturnya mirip dengan pohon B normal dalam arti setiap halaman memiliki sekumpulan nilai kunci yang diurutkan dan ada tingkat dalam indeks yang masing-masing menunjuk ke tingkat yang lebih rendah dan tingkat daun menunjuk ke baris data. Namun ada beberapa perbedaan.
Sama seperti indeks hash, beberapa baris data dapat ditautkan bersama-sama (versi). Penunjuk halaman di antara tingkat adalah ID halaman logis, yang merupakan offset ke dalam tabel pemetaan halaman, yang pada gilirannya memiliki alamat fisik untuk setiap halaman.
Tidak ada pembaruan halaman indeks di tempat. Halaman delta baru diperkenalkan untuk tujuan ini.
- Tidak diperlukan kait atau penguncian untuk pembaruan halaman.
- Halaman indeks bukan ukuran tetap.
Nilai kunci di setiap halaman tingkat nonleaf yang digambarkan adalah nilai tertinggi yang ditunjukkan anak tersebut, dan setiap baris juga berisi ID halaman logis halaman tersebut. Pada halaman tingkat daun, bersama dengan nilai kunci, berisi alamat fisik baris data.
Pencarian titik mirip dengan pohon B, kecuali karena halaman ditautkan hanya dalam satu arah, Mesin Database SQL Server mengikuti penunjuk halaman kanan, di mana setiap halaman nonleaf memiliki nilai tertinggi anaknya, bukan nilai terendah seperti di pohon B.
Jika halaman tingkat daun harus berubah, Mesin Database SQL Server tidak mengubah halaman itu sendiri. Sebaliknya, Mesin Database SQL Server membuat catatan delta yang menjelaskan perubahan, dan menambahkannya ke halaman sebelumnya. Kemudian juga memperbarui alamat tabel peta halaman untuk halaman sebelumnya, ke alamat catatan delta yang sekarang menjadi alamat fisik untuk halaman ini.
Ada tiga operasi berbeda yang dapat diperlukan untuk mengelola struktur pohon Bw: konsolidasi, pemisahan, dan penggabungan.
Konsolidasi Delta
Rantai panjang rekaman delta akhirnya dapat menurunkan performa pencarian karena itu bisa berarti kita melintasi rantai panjang saat mencari melalui indeks. Jika catatan delta baru ditambahkan ke rantai yang sudah memiliki 16 elemen, perubahan dalam rekaman delta dikonsolidasikan ke dalam halaman indeks yang direferensikan, dan halaman kemudian dibangun kembali, termasuk perubahan yang ditunjukkan oleh rekaman delta baru yang memicu konsolidasi. Halaman yang baru dibangun ulang memiliki ID halaman yang sama tetapi alamat memori baru.
Pisahkan halaman
Halaman indeks di pohon Bw tumbuh sesuai kebutuhan mulai dari menyimpan satu baris hingga menyimpan maksimum 8 KB. Setelah halaman indeks tumbuh menjadi 8 KB, sisipan baru dari satu baris menyebabkan halaman indeks terpisah. Untuk halaman internal, ini berarti ketika tidak ada lagi ruang untuk menambahkan nilai kunci dan penunjuk lain, dan untuk halaman daun, itu berarti bahwa baris akan terlalu besar agar pas di halaman setelah semua rekaman delta dimasukkan. Informasi statistik di header halaman untuk halaman daun melacak berapa banyak ruang yang diperlukan untuk mengonsolidasikan rekaman delta. Informasi ini disesuaikan saat setiap catatan delta baru ditambahkan.
Operasi pemisahan dilakukan dalam dua langkah atom. Dalam diagram berikut, asumsikan halaman daun memaksa pemisahan karena kunci dengan nilai 5 sedang disisipkan, dan halaman nonleaf ada yang menunjuk ke akhir halaman tingkat daun saat ini (nilai kunci 4).
Langkah 1: Alokasikan dua halaman P1 baru dan P2, dan pisahkan baris dari halaman lama P1 ke halaman baru ini, termasuk baris yang baru disisipkan. Slot baru dalam tabel pemetaan halaman digunakan untuk menyimpan alamat fisik halaman P2. Halaman-halaman ini, P1 dan P2 belum dapat diakses oleh operasi bersamaan. Selain itu, pointer logis dari P1 ke P2 diatur. Kemudian, dalam satu langkah atom memperbarui tabel pemetaan halaman untuk mengubah penunjuk dari lama P1 ke yang baru P1.
Langkah 2: Halaman nonleaf menunjuk ke P1 tetapi tidak ada penunjuk langsung dari halaman nonleaf ke P2. P2 hanya dapat dijangkau melalui P1. Untuk membuat penunjuk dari halaman nonleaf ke P2, alokasikan halaman nonleaf baru (halaman indeks internal), salin semua baris dari halaman nonleaf lama, dan tambahkan baris baru untuk menunjuk ke P2. Setelah ini selesai, dalam satu langkah atom, perbarui tabel pemetaan halaman untuk mengubah penunjuk dari halaman nonleaf lama ke halaman nonleaf baru.
Gabungkan halaman
DELETE Ketika operasi menghasilkan halaman yang memiliki kurang dari 10 persen dari ukuran halaman maksimum (saat ini 8 KB), atau dengan satu baris di dalamnya, halaman tersebut digabungkan dengan halaman yang berdekatan.
Saat baris dihapus dari halaman, catatan delta untuk penghapusan ditambahkan. Selain itu, pemeriksaan dilakukan untuk menentukan apakah halaman indeks (halaman nonleaf) memenuhi syarat untuk Penggabungan. Pemeriksaan ini memverifikasi apakah ruang yang tersisa setelah menghapus baris kurang dari 10 persen dari ukuran halaman maksimum. Jika memenuhi syarat, Penggabungan dilakukan dalam tiga langkah atom.
Dalam gambar berikut, asumsikan DELETE operasi menghapus nilai kunci 10.
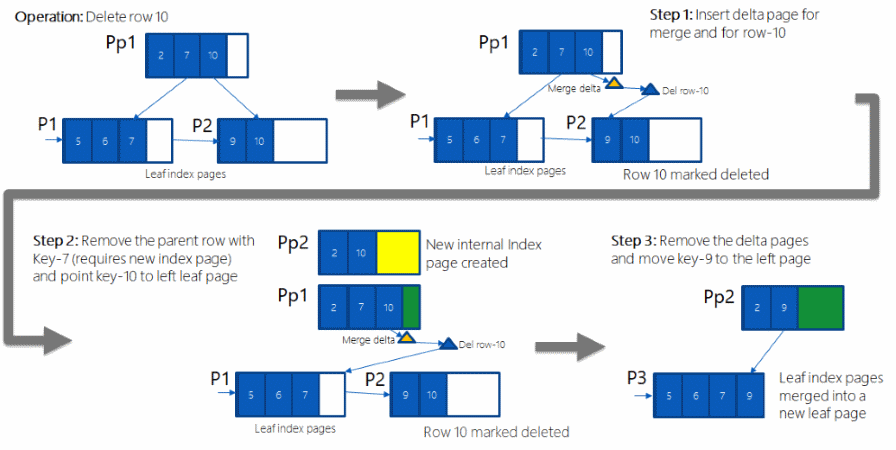
Langkah 1: Halaman delta yang mewakili nilai 10 kunci (segitiga biru) dibuat dan penunjuknya di halaman Pp1 nonleaf diatur ke halaman delta baru. Selain itu, halaman merge-delta khusus (segitiga hijau) dibuat, dan ditautkan untuk menunjuk ke halaman delta. Pada tahap ini, kedua halaman (halaman delta dan halaman merge-delta) tidak terlihat oleh transaksi bersamaan. Dalam satu langkah atomik, penunjuk ke halaman P1 tingkat daun dalam tabel pemetaan halaman diperbarui untuk menunjuk ke halaman merge-delta. Setelah langkah ini, entri untuk nilai 10 kunci di Pp1 sekarang menunjuk ke halaman merge-delta.
Langkah 2: Baris yang mewakili nilai 7 kunci di halaman Pp1 nonleaf perlu dihapus, dan entri untuk nilai 10 kunci yang diperbarui untuk menunjuk ke P1. Untuk melakukan ini, halaman Pp2 nonleaf baru dialokasikan dan semua baris dari Pp1 disalin, kecuali untuk baris yang mewakili nilai 7kunci ; maka baris untuk nilai 10 kunci diperbarui untuk menunjuk ke halaman P1. Setelah ini selesai, dalam satu langkah atom, entri tabel pemetaan halaman yang menunjuk ke Pp1 diperbarui untuk menunjuk ke Pp2. Pp1 tidak lagi dapat dijangkau.
Langkah 3: Halaman tingkat P2 daun dan P1 digabungkan dan halaman delta dihapus. Untuk melakukan ini, halaman P3 baru dialokasikan dan baris dari P2 dan P1 digabungkan, dan perubahan halaman delta disertakan dalam baru P3. Kemudian, dalam satu langkah atomik, entri tabel pemetaan halaman yang menunjuk ke halaman P1 diperbarui untuk menunjuk ke halaman P3.
Pertimbangan performa
Performa indeks nonclustered lebih baik daripada indeks hash nonclustered saat mengkueri tabel yang dioptimalkan memori dengan predikat ketidaksamaan.
Kolom dalam tabel yang dioptimalkan memori dapat menjadi bagian dari indeks hash dan indeks nonclustered.
Saat kolom kunci dalam indeks yang tidak dikluster memiliki banyak nilai duplikat, performa dapat menurun untuk pembaruan, penyisipan, dan penghapusan. Salah satu cara untuk meningkatkan performa dalam situasi ini adalah dengan menambahkan kolom yang memiliki selektivitas yang lebih baik dalam kunci indeks.
Konten terkait
- BUAT INDEKS (Transact-SQL)
- Optimalkan pemeliharaan indeks untuk meningkatkan performa kueri dan mengurangi konsumsi sumber daya
- Tabel dan indeks yang dipartisi
- Indeks pada Tabel yang Dioptimalkan Memori
- Indeks Penyimpan Kolom: Ringkasan
- Indeks pada kolom komputasi
- Menyetel indeks non-kluster dengan saran indeks yang hilang
Saat Anda merancang indeks, pertimbangkan panduan database berikut:
Sejumlah besar indeks pada tabel memengaruhi performa
INSERTpernyataan , ,UPDATEDELETE, danMERGEkarena semua indeks harus disesuaikan dengan tepat saat data dalam tabel berubah. Misalnya, jika kolom digunakan dalam beberapa indeks dan Anda menjalankanUPDATEpernyataan yang memodifikasi data kolom tersebut, setiap indeks yang berisi kolom tersebut harus diperbarui serta kolom dalam tabel dasar yang mendasar (timbunan atau indeks berkluster).Hindari pengindeksan berlebihan tabel yang sangat diperbarui dan pertahankan indeks tetap sempit, yaitu, dengan kolom seserang mungkin.
Gunakan banyak indeks untuk meningkatkan performa kueri pada tabel dengan persyaratan pembaruan rendah, tetapi data dalam volume besar. Sejumlah besar indeks dapat membantu performa kueri yang tidak mengubah data, seperti
SELECTpernyataan, karena pengoptimal kueri memiliki lebih banyak indeks untuk dipilih untuk menentukan metode akses tercepat.
Mengindeks tabel kecil mungkin tidak optimal karena dapat membutuhkan waktu lebih lama bagi pengoptimal kueri untuk melintasi indeks yang mencari data daripada melakukan pemindaian tabel dasar. Oleh karena itu, indeks pada tabel kecil mungkin tidak pernah digunakan, tetapi masih harus dipertahankan saat data dalam tabel berubah.
Indeks pada tampilan dapat memberikan perolehan performa yang signifikan saat tampilan berisi agregasi, gabungan tabel, atau kombinasi agregasi dan gabungan. Tampilan tidak harus dirujuk secara eksplisit dalam kueri agar pengoptimal kueri menggunakannya.
Database pada replika utama di Azure SQL Database secara otomatis menghasilkan rekomendasi performa penasihat database untuk indeks. Anda dapat mengaktifkan penyetelan indeks otomatis secara opsional.
Penyimpanan Kueri membantu mengidentifikasi kueri dengan performa suboptimal dan menyediakan riwayat rencana eksekusi kueri yang indeks dokumennya dipilih oleh pengoptimal.
Pertimbangan kueri
Saat Anda mendesain indeks, pertimbangkan panduan kueri berikut:
Buat indeks non-kluster pada kolom yang sering digunakan dalam predikat dan kondisi gabungan dalam kueri. Ini adalah 1 kolom SARGableAnda. Namun, Anda harus menghindari penambahan kolom yang tidak perlu. Menambahkan terlalu banyak kolom indeks dapat berdampak buruk pada ruang disk dan performa pemeliharaan indeks.
Mencakup indeks dapat meningkatkan performa kueri karena semua data yang diperlukan untuk memenuhi persyaratan kueri ada dalam indeks itu sendiri. Artinya, hanya halaman indeks, dan bukan halaman data tabel atau indeks berkluster, yang diperlukan untuk mengambil data yang diminta; oleh karena itu, mengurangi I/O disk secara keseluruhan. Misalnya, kueri kolom
AdanBpada tabel yang memiliki indeks komposit yang dibuat pada kolomA,B, danCdapat mengambil data yang ditentukan dari indeks saja.Indeks yang mencakup adalah penunjukan untuk indeks nonclustered yang menyelesaikan satu atau beberapa hasil kueri serupa secara langsung tanpa akses ke tabel dasarnya, dan tanpa menimbulkan pencarian.
Indeks tersebut memiliki semua kolom yang tidak dapat di-SARGable yang diperlukan dalam tingkat daunnya. Ini berarti bahwa kolom yang dikembalikan oleh
SELECTklausul dan semuaWHEREargumen danJOINdicakup oleh indeks.Ada kemungkinan lebih sedikit I/O untuk menjalankan kueri, jika indeks cukup sempit jika dibandingkan dengan baris dan kolom dalam tabel itu sendiri, yang berarti itu adalah subset nyata dari total kolom.
Pertimbangkan untuk mencakup indeks saat memilih sebagian kecil tabel besar, dan di mana bagian kecil tersebut ditentukan oleh predikat tetap, seperti kolom jarang yang hanya berisi beberapa nilai non-NULL, misalnya.
Tulis kueri yang menyisipkan atau memodifikasi baris sebanyak mungkin dalam satu pernyataan, alih-alih menggunakan beberapa kueri untuk memperbarui baris yang sama. Dengan hanya menggunakan satu pernyataan, pemeliharaan indeks yang dioptimalkan dapat dieksploitasi.
Mengevaluasi jenis kueri dan bagaimana kolom digunakan dalam kueri. Misalnya, kolom yang digunakan dalam jenis kueri yang sama persis akan menjadi kandidat yang baik untuk indeks non-kluster atau berkluster.
1 Istilah SARGable dalam database relasional mengacu pada predikat S earch ARGument-able yang dapat menggunakan indeks untuk mempercepat eksekusi kueri.
Pertimbangan kolom
Saat Anda mendesain indeks, pertimbangkan panduan kolom berikut:
Pertahankan panjang kunci indeks singkat untuk indeks berkluster. Selain itu, indeks berkluster mendapat manfaat dari dibuat pada kolom unik atau non-null.
Kolom yang merupakan tipe data ntext, teks, gambar, varchar(max), nvarchar(max), dan varbinary(max) tidak dapat ditentukan sebagai kolom kunci indeks. Namun, jenis data varchar(max), nvarchar(max), varbinary(max), dan xml dapat berpartisipasi dalam indeks non-kluster sebagai kolom indeks nonkey. Untuk informasi selengkapnya, lihat bagian Indeks dengan kolom yang disertakan dalam panduan ini.
Tipe data xml hanya bisa menjadi kolom kunci dalam indeks XML. Untuk informasi selengkapnya, lihat Indeks XML (SQL Server). SQL Server 2012 SP1 memperkenalkan jenis indeks XML baru yang dikenal sebagai Indeks XML Selektif. Indeks baru ini dapat meningkatkan performa kueri atas data yang disimpan sebagai XML, memungkinkan pengindeksan beban kerja data XML besar yang lebih cepat, dan meningkatkan skalabilitas dengan mengurangi biaya penyimpanan indeks itu sendiri. Untuk informasi selengkapnya, lihat Indeks XML Selektif (SXI).
Periksa keunikan kolom. Indeks unik alih-alih indeks nonunique pada kombinasi kolom yang sama menyediakan informasi tambahan untuk pengoptimal kueri yang membuat indeks lebih berguna. Untuk informasi selengkapnya, lihat Panduan desain indeks unik dalam panduan ini.
Periksa distribusi data di kolom. Sering kali, kueri yang berjalan lama disebabkan oleh pengindeksan kolom dengan beberapa nilai unik, atau dengan melakukan gabungan pada kolom tersebut. Ini adalah masalah mendasar dengan data dan kueri, dan umumnya tidak dapat diselesaikan tanpa mengidentifikasi situasi ini. Misalnya, direktori telepon fisik yang diurutkan menurut abjad pada nama keluarga tidak mempercepat menemukan seseorang jika semua orang di kota bernama Smith atau Jones. Untuk informasi selengkapnya tentang distribusi data, lihat Statistik.
Pertimbangkan untuk menggunakan indeks terfilter pada kolom yang memiliki subset yang ditentukan dengan baik, misalnya kolom jarang, kolom dengan sebagian besar
NULLnilai, kolom dengan kategori nilai, dan kolom dengan rentang nilai yang berbeda. Indeks terfilter yang dirancang dengan baik dapat meningkatkan performa kueri, mengurangi biaya pemeliharaan indeks, dan mengurangi biaya penyimpanan.Pertimbangkan urutan kolom jika indeks berisi beberapa kolom. Kolom yang digunakan dalam
WHEREklausa sama dengan (), lebih besar dari (=>), kurang dari (<), atauBETWEENkondisi pencarian, atau berpartisipasi dalam gabungan, harus ditempatkan terlebih dahulu. Kolom tambahan harus diurutkan berdasarkan tingkat perbedaannya, yaitu, dari yang paling berbeda dengan yang paling tidak berbeda.Misalnya, jika indeks didefinisikan sebagai
LastName,FirstName, indeks berguna ketika kriteria pencarian adalahWHERE LastName = 'Smith'atauWHERE LastName = Smith AND FirstName LIKE 'J%'. Namun, pengoptimal kueri tidak akan menggunakan indeks untuk kueri yang hanya mencari diFirstName (WHERE FirstName = 'Jane').Pertimbangkan untuk mengindeks kolom komputasi. Untuk informasi selengkapnya, lihat Indeks pada kolom komputasi.
Karakteristik indeks
Setelah Anda menentukan bahwa indeks sesuai untuk kueri, Anda bisa memilih jenis indeks yang paling sesuai dengan situasi Anda. Karakteristik indeks mencakup daftar berikut:
- Terkluster versus nonclustered
- Unik versus nonunique
- Kolom tunggal versus multikolom
- Urutan naik atau turun pada kolom dalam indeks
- Tabel penuh versus difilter untuk indeks non-kluster
- Penyimpan kolom versus rowstore
- Hash versus nonclustered untuk tabel yang dioptimalkan memori
Anda juga dapat menyesuaikan karakteristik penyimpanan awal indeks untuk mengoptimalkan performa atau pemeliharaannya dengan mengatur opsi seperti FILLFACTOR. Selain itu, Anda dapat menentukan lokasi penyimpanan indeks dengan menggunakan grup file atau skema partisi untuk mengoptimalkan performa.
Penempatan indeks pada skema grup file atau partisi
Saat Anda mengembangkan strategi desain indeks, Anda harus mempertimbangkan penempatan indeks pada grup file yang terkait dengan database. Pemilihan skema grup file atau partisi yang cermat dapat meningkatkan performa kueri.
Secara default, indeks disimpan dalam grup file yang sama dengan tabel dasar tempat indeks dibuat. Indeks berkluster nonpartisi dan tabel dasar selalu berada di grup file yang sama. Namun, Anda dapat melakukan langkah-langkah berikut:
- Buat indeks non-kluster pada grup file selain grup file tabel dasar atau indeks berkluster.
- Indeks terkluster dan non-kluster partisi untuk menjangkau beberapa grup file.
- Pindahkan tabel dari satu grup file ke grup file lainnya dengan menjatuhkan indeks berkluster dan menentukan grup file atau skema partisi baru dalam
MOVE TOklausaDROP INDEXpernyataan atau dengan menggunakanCREATE INDEXpernyataan denganDROP_EXISTINGklausa.
Dengan membuat indeks nonclustered pada grup file yang berbeda, Anda dapat mencapai perolehan performa jika grup file menggunakan drive fisik yang berbeda dengan pengontrol mereka sendiri. Informasi data dan indeks kemudian dapat dibaca secara paralel oleh beberapa kepala disk. Misalnya, jika Table_A pada grup file f1 dan Index_A grup file f2 keduanya digunakan oleh kueri yang sama, perolehan performa dapat dicapai karena kedua grup file sepenuhnya digunakan tanpa pertikaian. Namun, jika Table_A dipindai oleh kueri tetapi Index_A tidak direferensikan, hanya grup file f1 yang digunakan. Ini tidak menciptakan perolehan performa.
Karena Anda tidak dapat memprediksi jenis akses apa yang terjadi dan ketika itu terjadi, itu bisa menjadi keputusan yang lebih baik untuk menyebarkan tabel dan indeks Anda di semua grup file. Ini akan menjamin bahwa semua disk diakses karena semua data dan indeks tersebar merata di semua disk, terlepas dari cara mana data diakses. Ini juga merupakan pendekatan yang lebih sederhana untuk administrator sistem.
Partisi di beberapa grup file
Anda juga dapat mempertimbangkan partisi indeks terkluster dan terkluster berbasis disk di beberapa grup file. Indeks yang dipartisi dipartisi secara horizontal, atau menurut baris, berdasarkan fungsi partisi. Fungsi partisi menentukan bagaimana setiap baris dipetakan ke sekumpulan partisi berdasarkan nilai kolom tertentu, yang disebut kolom partisi. Skema partisi menentukan pemetaan partisi ke sekumpulan grup file.
Pemartisian indeks dapat memberikan manfaat berikut:
Menyediakan sistem yang dapat diskalakan yang membuat indeks besar lebih mudah dikelola. Sistem OLTP, misalnya, dapat menerapkan aplikasi sadar partisi yang menangani indeks besar.
Buat kueri berjalan lebih cepat dan lebih efisien. Saat kueri mengakses beberapa partisi indeks, pengoptimal kueri dapat memproses partisi individual secara bersamaan dan mengecualikan partisi yang tidak terpengaruh oleh kueri.
Untuk informasi selengkapnya, lihat Tabel dan indeks yang dipartisi.
Panduan desain urutan pengurutan indeks
Saat menentukan indeks, pertimbangkan apakah data untuk kolom kunci indeks harus disimpan dalam urutan naik atau menurun. Naik adalah default dan mempertahankan kompatibilitas dengan versi Mesin Database yang lebih lama. Sintaks pernyataan CREATE INDEX, , dan ALTER TABLE mendukung kata kunci ASC (naik) dan DESC (menurun) pada kolom individual dalam indeks CREATE TABLEdan batasan.
Menentukan urutan di mana nilai kunci disimpan dalam indeks berguna saat kueri yang merujuk tabel memiliki ORDER BY klausa yang menentukan arah yang berbeda untuk kolom kunci atau kolom dalam indeks tersebut. Dalam kasus ini, indeks dapat menghapus kebutuhan SORT operator dalam rencana kueri; oleh karena itu, ini membuat kueri lebih efisien. Misalnya, pembeli di departemen pembelian Adventure Works Cycles harus mengevaluasi kualitas produk yang mereka beli dari vendor. Pembeli paling tertarik untuk menemukan produk yang dikirim oleh vendor ini dengan tingkat penolakan yang tinggi.
Seperti yang ditunjukkan dalam kueri berikut terhadap database sampel AdventureWorks, mengambil data untuk memenuhi kriteria ini mengharuskan RejectedQty kolom dalam tabel diurutkan Purchasing.PurchaseOrderDetail dalam urutan turun (besar ke kecil) dan ProductID kolom yang akan diurutkan dalam urutan naik (kecil ke besar).
SELECT RejectedQty, ((RejectedQty/OrderQty)*100) AS RejectionRate,
ProductID, DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
GO
Rencana eksekusi berikut untuk kueri ini menunjukkan bahwa pengoptimal kueri menggunakan SORT operator untuk mengembalikan tataan hasil dalam urutan yang ditentukan oleh ORDER BY klausa.
Jika indeks rowstore berbasis disk dibuat dengan kolom kunci yang cocok dengan yang ada dalam ORDER BY klausul dalam kueri, SORT operator dapat dihilangkan dalam rencana kueri dan rencana kueri lebih efisien.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
GO
Setelah kueri dijalankan lagi, rencana eksekusi berikut menunjukkan bahwa SORT operator telah dihilangkan dan indeks noncluster yang baru dibuat digunakan.
Mesin Database dapat bergerak secara sama efisien di kedua arah. Indeks yang didefinisikan sebagai (RejectedQty DESC, ProductID ASC) masih dapat digunakan untuk kueri di mana arah pengurutan kolom dalam ORDER BY klausa dibalik. Misalnya, kueri dengan ORDER BY klausa ORDER BY RejectedQty ASC, ProductID DESC dapat menggunakan indeks.
Urutan pengurutan hanya dapat ditentukan untuk kolom kunci dalam indeks. Tampilan katalog sys.index_columns dan INDEXKEY_PROPERTY fungsi melaporkan apakah kolom indeks disimpan dalam urutan naik atau menurun.
Jika Anda mengikuti contoh kode dalam database sampel AdventureWorks, Anda dapat menghapusnya IX_PurchaseOrderDetail_RejectedQty dengan Transact-SQL berikut:
DROP INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail;
GO
Metadata
Gunakan tampilan metadata ini untuk melihat atribut indeks. Informasi arsitektur lainnya disematkan dalam beberapa tampilan ini.
Untuk indeks penyimpan kolom, semua kolom disimpan dalam metadata sebagai kolom yang disertakan. Indeks penyimpan kolom tidak memiliki kolom kunci.
- sys.column_store_dictionaries
- sys.column_store_row_groups
- sys.column_store_segments
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
- sys.dm_db_index_operational_stats
- sys.dm_db_index_physical_stats
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.hash_indexes
- sys.index_columns
- sys.indexes
- sys.internal_partitions
- sys.memory_optimized_tables_internal_attributes
- sys.partitions
Panduan desain indeks berkluster
Indeks berkluster mengurutkan dan menyimpan baris data dalam tabel berdasarkan nilai kuncinya. Hanya ada satu indeks berkluster per tabel, karena baris data itu sendiri hanya dapat diurutkan dalam satu urutan. Dengan beberapa pengecualian, setiap tabel harus memiliki indeks berkluster yang ditentukan pada kolom, atau kolom, yang menawarkan hal berikut:
Dapat digunakan untuk kueri yang sering digunakan.
Memberikan tingkat keunikan yang tinggi.
Catatan
Saat Anda membuat
PRIMARY KEYbatasan, indeks unik pada kolom, atau kolom, secara otomatis dibuat. Secara default, indeks ini diklusterkan; namun, Anda dapat menentukan indeks nonclustered saat membuat batasan.Dapat digunakan dalam kueri rentang.
Jika indeks berkluster tidak dibuat dengan UNIQUE properti , Mesin Database secara otomatis menambahkan kolom pengimpor unik 4-byte ke tabel. Saat diperlukan, Mesin Database secara otomatis menambahkan nilai pengidentifikasi unik ke baris untuk membuat setiap kunci unik. Kolom ini dan nilainya digunakan secara internal dan tidak dapat dilihat atau diakses oleh pengguna.
Arsitektur indeks berkluster
Indeks rowstore diatur sebagai pohon B+. Setiap halaman dalam pohon indeks B+ disebut simpul indeks. Simpul atas pohon B+ disebut simpul akar. Simpul bawah dalam indeks disebut simpul daun. Setiap tingkat indeks antara akar dan simpul daun secara kolektif dikenal sebagai tingkat menengah. Dalam indeks berkluster, simpul daun berisi halaman data tabel yang mendasar. Simpul tingkat akar dan menengah berisi halaman indeks yang menyimpan baris indeks. Setiap baris indeks berisi nilai kunci dan penunjuk ke halaman tingkat menengah di pohon B+, atau baris data di tingkat daun indeks. Halaman di setiap tingkat indeks ditautkan dalam daftar tertaut doubly.
Indeks berkluster memiliki satu baris dalam sys.partitions, dengan index_id = 1 untuk setiap partisi yang digunakan oleh indeks. Secara default, indeks berkluster memiliki satu partisi. Ketika indeks berkluster memiliki beberapa partisi, setiap partisi memiliki struktur pohon B+ yang berisi data untuk partisi tertentu tersebut. Misalnya, jika indeks berkluster memiliki empat partisi, ada empat struktur pohon B+; satu di setiap partisi.
Bergantung pada jenis data dalam indeks berkluster, setiap struktur indeks berkluster memiliki satu atau beberapa unit alokasi untuk menyimpan dan mengelola data untuk partisi tertentu. Minimal, setiap indeks berkluster memiliki satu IN_ROW_DATA unit alokasi per partisi. Indeks berkluster juga memiliki satu unit alokasi LOB_DATA per partisi jika berisi kolom objek besar (LOB). Ini juga memiliki satu unit alokasi ROW_OVERFLOW_DATA per partisi jika berisi kolom panjang variabel yang melebihi batas ukuran baris 8.060 byte.
Halaman dalam rantai data dan baris di dalamnya diurutkan pada nilai kunci indeks berkluster. Semua sisipan dibuat pada titik di mana nilai kunci dalam baris yang disisipkan pas dalam urutan pengurutan di antara baris yang ada.
Ilustrasi ini menunjukkan struktur indeks berkluster dalam satu partisi.
Pertimbangan kueri
Sebelum Anda membuat indeks berkluster, pahami bagaimana data Anda diakses. Pertimbangkan untuk menggunakan indeks berkluster untuk kueri yang melakukan hal berikut:
Mengembalikan rentang nilai dengan menggunakan operator seperti
BETWEEN, ,>,>=<, dan<=.Setelah baris dengan nilai pertama ditemukan dengan menggunakan indeks berkluster, baris dengan nilai terindeks berikutnya dijamin berdekatan secara fisik. Misalnya, jika kueri mengambil rekaman antara rentang nomor pesanan penjualan, indeks berkluster pada kolom
SalesOrderNumberdapat dengan cepat menemukan baris yang berisi nomor pesanan penjualan awal, lalu mengambil semua baris berturut-turut dalam tabel hingga nomor pesanan penjualan terakhir tercapai.Mengembalikan tataan hasil besar.
Gunakan
JOINklausa; biasanya ini adalah kolom kunci asing.Gunakan
ORDER BYklausa atauGROUP BY.Indeks pada kolom yang ditentukan dalam
ORDER BYklausa atauGROUP BYmungkin menghapus kebutuhan Mesin Database untuk mengurutkan data, karena baris sudah diurutkan. Ini meningkatkan performa kueri.
Pertimbangan kolom
Umumnya, Anda harus menentukan kunci indeks berkluster dengan kolom seserang mungkin. Pertimbangkan kolom yang memiliki satu atau beberapa atribut berikut:
Unik atau berisi banyak nilai yang berbeda
Misalnya, ID karyawan secara unik mengidentifikasi karyawan. Indeks terkluster atau batasan KUNCI PRIMER pada
EmployeeIDkolom akan meningkatkan performa kueri yang mencari informasi karyawan berdasarkan nomor ID karyawan. Atau, indeks berkluster dapat dibuat padaLastName,FirstName,MiddleNamekarena rekaman karyawan sering dikelompokkan dan dikueri dengan cara ini, dan kombinasi kolom ini masih akan memberikan tingkat perbedaan yang tinggi.Tip
Jika tidak ditentukan secara berbeda, saat membuat batasan KUNCI PRIMER, Mesin Database membuat indeks berkluster untuk mendukung batasan tersebut.
Meskipun uniqueidentifier dapat digunakan untuk memberlakukan keunikan sebagai
PRIMARY KEY, ini bukan kunci pengklusteran yang efisien.Jika menggunakan uniqueidentifier sebagai
PRIMARY KEY, rekomendasinya adalah membuatnya sebagai indeks non-kluster, dan menggunakan kolom lain sepertiIDENTITYuntuk membuat indeks berkluster.Diakses secara berurutan
Misalnya, ID produk secara unik mengidentifikasi produk dalam
Production.Producttabel dalamAdventureWorks2022database. Kueri di mana pencarian berurutan ditentukan, sepertiWHERE ProductID BETWEEN 980 and 999, akan mendapat manfaat dari indeks berkluster padaProductID. Ini karena baris akan disimpan dalam urutan diurutkan pada kolom kunci tersebut.Didefinisikan sebagai
IDENTITY.Sering digunakan untuk mengurutkan data yang diambil dari tabel.
Sebaiknya kluster (mengurutkan secara fisik) tabel pada kolom tersebut, untuk menghemat biaya operasi pengurutan setiap kali kolom dikueri.
Indeks berkluster bukanlah pilihan yang baik untuk atribut berikut:
Kolom yang sering mengalami perubahan
Ini menyebabkan seluruh baris dipindahkan, karena Mesin Database harus menyimpan nilai data baris dalam urutan fisik. Ini adalah pertimbangan penting dalam sistem pemrosesan transaksi volume tinggi di mana data biasanya volatil.
Kunci lebar
Kunci lebar adalah komposit dari beberapa kolom atau beberapa kolom berukuran besar. Nilai kunci dari indeks berkluster digunakan oleh semua indeks non-kluster sebagai kunci pencarian. Setiap indeks non-kluster yang ditentukan pada tabel yang sama secara signifikan lebih besar, karena entri indeks non-kluster berisi kunci pengklusteran dan juga kolom kunci yang ditentukan untuk indeks non-kluster tersebut.
Pedoman desain indeks non-klusster
Indeks nonclustered rowstore berbasis disk berisi nilai kunci indeks dan pencari baris yang menunjuk ke lokasi penyimpanan data tabel. Anda dapat membuat beberapa indeks nonclustered pada tabel atau tampilan terindeks. Umumnya, indeks non-kluster harus dirancang untuk meningkatkan performa kueri yang sering digunakan yang tidak tercakup oleh indeks berkluster.
Mirip dengan cara Anda menggunakan indeks dalam buku, pengoptimal kueri mencari nilai data dengan mencari indeks nonclustered untuk menemukan lokasi nilai data dalam tabel lalu mengambil data langsung dari lokasi tersebut. Ini membuat indeks non-kluster pilihan optimal untuk kueri kecocokan yang tepat karena indeks berisi entri yang menjelaskan lokasi yang tepat dalam tabel nilai data yang sedang dicari dalam kueri. Misalnya, untuk mengkueri HumanResources.Employee tabel untuk semua karyawan yang melaporkan ke manajer tertentu, pengoptimal kueri mungkin menggunakan indeks IX_Employee_ManagerIDnonclustered ; ini memiliki ManagerID sebagai kolom kuncinya. Pengoptimal kueri dapat dengan cepat menemukan semua entri dalam indeks yang cocok dengan yang ditentukan ManagerID. Setiap entri indeks menunjuk ke halaman dan baris yang tepat dalam tabel, atau indeks berkluster, di mana data yang sesuai dapat ditemukan. Setelah pengoptimal kueri menemukan semua entri dalam indeks, pengoptimal kueri dapat langsung masuk ke halaman dan baris yang tepat untuk mengambil data.
Arsitektur indeks nonclustered
Indeks nonclustered rowstore berbasis disk memiliki struktur pohon B+ yang sama dengan indeks berkluster, kecuali untuk perbedaan signifikan berikut:
Baris data tabel yang mendasar tidak diurutkan dan disimpan secara berurutan berdasarkan kunci non-klusternya.
Tingkat daun indeks non-klusster terdiri dari halaman indeks alih-alih halaman data. Halaman indeks pada tingkat daun indeks nonclustered berisi kolom kunci dan kolom yang disertakan.
Pencari baris dalam baris indeks non-kluster adalah penunjuk ke baris atau merupakan kunci indeks berkluster untuk baris, seperti yang dijelaskan dalam hal berikut:
Jika tabel adalah tumpukan, yang berarti tidak memiliki indeks berkluster, pencari baris adalah penunjuk ke baris. Penunjuk dibangun dari pengidentifikasi file (ID), nomor halaman, dan jumlah baris di halaman. Seluruh pointer dikenal sebagai ID Baris (RID).
Jika tabel memiliki indeks berkluster, atau indeks berada pada tampilan terindeks, pencari baris adalah kunci indeks berkluster untuk baris tersebut.
Pencari baris juga memastikan keunikan untuk baris indeks nonclustered. Tabel berikut ini menjelaskan bagaimana Mesin Database menambahkan pencari baris ke indeks non-kluster:
| Jenis tabel | Jenis indeks nonclustered | Pencari lokasi baris |
|---|---|---|
| Tumpukan | ||
| Nonunique | RID ditambahkan ke kolom kunci | |
| Unik | RID ditambahkan ke kolom yang disertakan | |
| Indeks berkluster unik | ||
| Nonunique | Kunci indeks berkluster ditambahkan ke kolom kunci | |
| Unik | Kunci indeks berkluster ditambahkan ke kolom yang disertakan | |
| Indeks berkluster yang tidak unik | ||
| Nonunique | Kunci indeks berkluster dan pengidentifikasi unik (saat ada) ditambahkan ke kolom kunci | |
| Unik | Kunci indeks berkluster dan pengidentifikasi unik (saat ada) ditambahkan ke kolom yang disertakan |
Mesin Database tidak pernah menyimpan kolom tertentu dua kali dalam indeks nonclustered. Urutan kunci indeks yang ditentukan oleh pengguna ketika mereka membuat indeks non-kluster selalu dihormati: kolom pencari baris apa pun yang perlu ditambahkan ke kunci indeks non-kluster, ditambahkan di akhir kunci, mengikuti kolom yang ditentukan dalam definisi indeks. Kolom pencari lokasi baris berbasis kunci indeks berkluster dalam indeks non-kluster dapat digunakan oleh pengoptimal kueri, terlepas dari apakah mereka secara eksplisit ditentukan dalam definisi indeks.
Contoh berikut menunjukkan bagaimana pencari baris diimplementasikan dalam indeks nonclustered:
| Indeks dalam kluster | Definisi indeks yang tidak di-noncluster | Definisi indeks yang tidak terkluster dengan pencari baris | Penjelasan |
|---|---|---|---|
Indeks berkluster unik dengan kolom kunci (A, B, C) |
Indeks nonunique nonclustered dengan kolom kunci (B, A) dan kolom yang disertakan (E, G) |
Kolom kunci (B, , AC) dan kolom yang disertakan (E, G) |
Indeks nonclustered nonunique, sehingga pencari baris perlu ada di kunci indeks. B Kolom dan A dari pencari baris sudah ada, jadi hanya kolom c yang ditambahkan. Kolom c ditambahkan ke akhir daftar kolom kunci. |
Indeks berkluster unik dengan kolom kunci (A) |
Indeks nonunique nonclustered dengan kolom kunci (B, C) dan kolom yang disertakan (A) |
Kolom kunci (B, C, A) |
Indeks nonclustered nonunique, sehingga pencari baris ditambahkan ke kunci. Kolom A belum ditentukan sebagai kolom kunci, sehingga ditambahkan ke akhir daftar kolom kunci. Kolom A sekarang ada di kunci, jadi tidak perlu menyimpannya sebagai kolom yang disertakan. |
Indeks berkluster unik dengan kolom kunci (A, B) |
Indeks nonclustered unik dengan kolom kunci (C) |
Kolom kunci (C) dan kolom yang disertakan (A, B) |
Indeks nonclustered unik, sehingga pencari baris ditambahkan ke kolom yang disertakan. |
Indeks nonclustered memiliki satu baris dalam sys.partitions dengan index_id > 1 untuk setiap partisi yang digunakan oleh indeks. Secara default, indeks nonclustered memiliki satu partisi. Ketika indeks nonclustered memiliki beberapa partisi, setiap partisi memiliki struktur pohon B+ yang berisi baris indeks untuk partisi tertentu tersebut. Misalnya, jika indeks nonclustered memiliki empat partisi, ada empat struktur pohon B+, dengan satu di setiap partisi.
Bergantung pada jenis data dalam indeks nonclustered, setiap struktur indeks nonclustered memiliki satu atau beberapa unit alokasi untuk menyimpan dan mengelola data untuk partisi tertentu. Minimal, setiap indeks non-kluster memiliki satu unit alokasi IN_ROW_DATA per partisi yang menyimpan indeks halaman pohon B+. Indeks nonclustered juga memiliki satu unit alokasi LOB_DATA per partisi jika berisi kolom objek besar (LOB). Selain itu, ia memiliki satu unit alokasi ROW_OVERFLOW_DATA per partisi jika berisi kolom panjang variabel yang melebihi batas ukuran baris 8.060 byte.
Ilustrasi berikut menunjukkan struktur indeks nonclustered dalam satu partisi.
Pertimbangan {i>database
Pertimbangkan karakteristik database saat merancang indeks non-kluster.
Database atau tabel dengan persyaratan pembaruan rendah, tetapi data dalam volume besar dapat memperoleh manfaat dari banyak indeks yang tidak terkluster untuk meningkatkan performa kueri. Pertimbangkan untuk membuat indeks yang difilter untuk subset data yang terdefinisi dengan baik untuk meningkatkan performa kueri, mengurangi biaya penyimpanan indeks, dan mengurangi biaya pemeliharaan indeks dibandingkan dengan indeks nonclustered tabel penuh.
Aplikasi dan database Sistem Dukungan Keputusan yang terutama berisi data baca-saja dapat memperoleh manfaat dari banyak indeks non-kluster. Pengoptimal kueri memiliki lebih banyak indeks untuk dipilih untuk menentukan metode akses tercepat, dan karakteristik pembaruan rendah dari database berarti pemeliharaan indeks tidak menghambat performa.
Aplikasi dan database Pemrosesan Transaksi Online (OLTP) yang berisi tabel yang sangat diperbarui harus menghindari pengindeksan berlebihan. Selain itu, indeks harus sempit, yaitu, dengan kolom seserang mungkin.
Sejumlah besar indeks pada tabel memengaruhi performa INSERTpernyataan , , UPDATEDELETE, dan MERGE karena semua indeks harus disesuaikan dengan tepat saat data dalam tabel berubah.
Pertimbangan kueri
Sebelum membuat indeks non-kluster, Anda harus memahami bagaimana data Anda diakses. Pertimbangkan untuk menggunakan indeks nonclustered untuk kueri yang memiliki atribut berikut:
Gunakan JOIN klausa atau GROUP BY .
Buat beberapa indeks non-kluster pada kolom yang terlibat dalam operasi gabungan dan pengelompokan, dan indeks berkluster pada kolom kunci asing apa pun.
Kueri yang tidak mengembalikan tataan hasil besar.
Buat indeks yang difilter untuk mencakup kueri yang mengembalikan subset baris yang ditentukan dengan baik dari tabel besar.
Tip
WHERE Biasanya klausul CREATE INDEX pernyataan cocok dengan WHERE klausul kueri yang sedang dibahas.
Berisi kolom yang sering terlibat dalam kondisi pencarian kueri, seperti WHERE klausa, yang mengembalikan kecocokan persis.
Tip
Pertimbangkan biaya versus manfaat saat menambahkan indeks baru. Mungkin lebih baik untuk mengonsolidasikan kebutuhan kueri tambahan ke dalam indeks yang sudah ada. Misalnya, pertimbangkan untuk menambahkan satu atau dua kolom tingkat daun tambahan ke indeks yang ada, jika memungkinkan cakupan beberapa kueri penting, alih-alih memiliki satu indeks yang benar-benar mencakup per setiap kueri penting.
Pertimbangan kolom
Pertimbangkan kolom yang memiliki satu atau beberapa atribut ini:
Tutupi kueri.
Perolehan performa dicapai saat indeks berisi semua kolom dalam kueri. Pengoptimal kueri dapat menemukan semua nilai kolom dalam indeks; tabel atau data indeks terkluster tidak diakses sehingga menghasilkan lebih sedikit operasi I/O disk. Gunakan indeks dengan kolom yang disertakan untuk menambahkan kolom penutup alih-alih membuat kunci indeks yang lebar.
Jika tabel memiliki indeks berkluster, kolom atau kolom yang ditentukan dalam indeks berkluster secara otomatis ditambahkan ke setiap indeks non-kluster pada tabel. Ini dapat menghasilkan kueri tercakup tanpa menentukan kolom indeks berkluster dalam definisi indeks non-kluster. Misalnya, jika tabel memiliki indeks berkluster pada kolom C, indeks nonunique nonclustered pada kolom B dan A memiliki sebagai kolom Bnilai kuncinya , , Adan C. Untuk informasi selengkapnya, kunjungi arsitektur indeks non-klusster.
Banyak nilai yang berbeda, seperti kombinasi nama keluarga dan nama depan, jika indeks berkluster digunakan untuk kolom lain.
Jika ada sangat sedikit nilai yang berbeda, seperti hanya 1 dan 0, sebagian besar kueri tidak akan menggunakan indeks karena pemindaian tabel umumnya lebih efisien. Untuk jenis data ini, pertimbangkan untuk membuat indeks yang difilter pada nilai berbeda yang hanya terjadi dalam beberapa baris. Misalnya, jika sebagian besar nilai adalah 0, pengoptimal kueri dapat menggunakan indeks yang difilter untuk baris data yang berisi 1.
Gunakan kolom yang disertakan untuk memperluas indeks non-klusster
Anda dapat memperluas fungsionalitas indeks nonclustered dengan menambahkan kolom non-kunci ke tingkat daun indeks nonclustered. Dengan menyertakan kolom non-kunci, Anda dapat membuat indeks nonclustered yang mencakup lebih banyak kueri. Ini karena kolom non-kunci memiliki manfaat berikut:
Mereka bisa menjadi jenis data yang tidak diizinkan sebagai kolom kunci indeks.
Kolom tidak dipertimbangkan oleh Mesin Database saat menghitung jumlah kolom kunci indeks atau ukuran kunci indeks.
Indeks dengan kolom non-kunci yang disertakan dapat secara signifikan meningkatkan performa kueri ketika semua kolom dalam kueri disertakan dalam indeks baik sebagai kolom kunci atau non-kunci. Perolehan performa dicapai karena pengoptimal kueri dapat menemukan semua nilai kolom dalam indeks; tabel atau data indeks terkluster tidak diakses sehingga menghasilkan lebih sedikit operasi I/O disk.
Catatan
Saat indeks berisi semua kolom yang dirujuk oleh kueri, indeks biasanya disebut sebagai mencakup kueri.
Meskipun kolom kunci disimpan di semua tingkat indeks, kolom non-kunci hanya disimpan di tingkat daun.
Menggunakan kolom yang disertakan untuk menghindari batas ukuran
Anda dapat menyertakan kolom non-kunci dalam indeks non-kluster untuk menghindari melebihi batasan ukuran indeks saat ini dari maksimum 16 kolom kunci dan ukuran kunci indeks maksimum 900 byte. Mesin Database tidak mempertimbangkan kolom non-kunci saat menghitung jumlah kolom kunci indeks atau ukuran kunci indeks.
Misalnya, asumsikan bahwa Anda ingin mengindeks kolom berikut dalam Document tabel:
Title NVARCHAR(50)
Revision NCHAR(5)
FileName NVARCHAR(400)
Karena jenis data nchar dan nvarchar memerlukan 2 byte untuk setiap karakter, indeks yang berisi ketiga kolom ini akan melebihi batasan ukuran 900 byte sebesar 10 byte (455 * 2). Dengan menggunakan INCLUDE klausa CREATE INDEX pernyataan, kunci indeks dapat didefinisikan sebagai (Title, Revision) dan FileName didefinisikan sebagai kolom non-kunci. Dengan cara ini, ukuran kunci indeks adalah 110 byte (55 * 2), dan indeks masih akan berisi semua kolom yang diperlukan. Pernyataan berikut membuat indeks seperti itu.
CREATE INDEX IX_Document_Title
ON Production.Document (Title, Revision)
INCLUDE (FileName);
GO
Jika Anda mengikuti contoh kode, Anda dapat menghilangkan indeks ini menggunakan pernyataan Transact-SQL ini:
DROP INDEX IX_Document_Title
ON Production.Document;
GO
Indeks dengan panduan kolom yang disertakan
Saat Anda merancang indeks nonclustered dengan kolom yang disertakan, pertimbangkan panduan berikut:
Kolom non-kunci didefinisikan dalam INCLUDE klausa CREATE INDEX pernyataan.
Kolom non-kunci hanya dapat ditentukan pada indeks nonclustered pada tabel atau tampilan terindeks.
Semua jenis data diizinkan kecuali teks, ntext, dan gambar.
Kolom komputasi yang deterministik dan tepat atau tidak tepat dapat disertakan kolom. Untuk informasi selengkapnya, lihat Indeks pada kolom komputasi.
Seperti halnya kolom kunci, kolom komputasi yang berasal dari tipe data gambar, ntext, dan teks dapat berupa kolom non-kunci (disertakan) selama jenis data kolom komputasi diizinkan sebagai kolom indeks non-kunci.
Nama kolom tidak dapat ditentukan dalam INCLUDE daftar dan di daftar kolom kunci.
Nama kolom tidak dapat diulang dalam INCLUDE daftar.
Panduan ukuran kolom
Setidaknya satu kolom kunci harus ditentukan. Jumlah maksimum kolom non-kunci adalah 1.023 kolom. Ini adalah jumlah maksimum kolom tabel dikurangi 1.
Kolom kunci indeks, tidak termasuk non-kunci, harus mengikuti batasan ukuran indeks yang ada maksimum 16 kolom kunci, dan ukuran kunci indeks total 900 byte.
Ukuran total semua kolom nonkey hanya dibatasi oleh ukuran kolom yang ditentukan dalam INCLUDE klausul; misalnya, kolom varchar(max) dibatasi hingga 2 GB.
Panduan modifikasi kolom
Saat Anda mengubah kolom tabel yang telah didefinisikan sebagai kolom yang disertakan, pembatasan berikut berlaku:
Kolom non-kunci tidak dapat dihilangkan dari tabel kecuali indeks dihilangkan terlebih dahulu.
Kolom non-kunci tidak dapat diubah, kecuali untuk melakukan hal berikut:
Ubah nullability kolom dari NOT NULL ke NULL.
Tingkatkan panjang kolom varchar, nvarchar, atau varbinary .
Catatan
Pembatasan modifikasi kolom ini juga berlaku untuk kolom kunci indeks.
Rekomendasi desain
Desain ulang indeks non-kluster dengan ukuran kunci indeks besar sehingga hanya kolom yang digunakan untuk pencarian dan pencarian yang merupakan kolom kunci. Buat semua kolom lain yang mencakup kolom nonkey yang disertakan kueri. Dengan cara ini, Anda memiliki semua kolom yang diperlukan untuk mencakup kueri, tetapi kunci indeks itu sendiri kecil dan efisien.
Misalnya, asumsikan bahwa Anda ingin merancang indeks untuk mencakup kueri berikut.
SELECT AddressLine1, AddressLine2, City, StateProvinceID, PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
GO
Untuk mencakup kueri, setiap kolom harus ditentukan dalam indeks. Meskipun Anda dapat menentukan semua kolom sebagai kolom kunci, ukuran kuncinya adalah 334 byte. Karena satu-satunya kolom yang digunakan sebagai kriteria pencarian adalah PostalCode kolom , memiliki panjang 30 byte, desain indeks yang lebih baik akan menentukan PostalCode sebagai kolom kunci dan menyertakan semua kolom lain sebagai kolom non-kunci.
Pernyataan berikut membuat indeks dengan kolom yang disertakan untuk mencakup kueri.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Untuk memvalidasi bahwa indeks mencakup kueri, buat indeks, lalu tampilkan perkiraan rencana eksekusi.
Jika rencana eksekusi hanya SELECT memperlihatkan operator dan operator Pencarian Indeks untuk IX_Address_PostalCode indeks, kueri dicakup oleh indeks.
Anda dapat menghilangkan indeks dengan pernyataan berikut:
DROP INDEX IX_Address_PostalCode
ON Person.Address;
GO
Pertimbangan performa
Hindari menambahkan kolom yang tidak perlu. Menambahkan terlalu banyak kolom indeks, kunci, atau non-kunci, dapat memiliki implikasi performa berikut:
Lebih sedikit baris indeks yang pas pada halaman. Ini dapat menciptakan peningkatan I/O dan mengurangi efisiensi cache.
Lebih banyak ruang disk diperlukan untuk menyimpan indeks. Secara khusus, menambahkan jenis data varchar(max), nvarchar(max), varbinary(max), atau xml karena kolom indeks nonkey dapat secara signifikan meningkatkan persyaratan ruang disk. Ini karena nilai kolom disalin ke tingkat daun indeks. Oleh karena itu, mereka berada di indeks dan tabel dasar.
Pemeliharaan indeks dapat meningkatkan waktu yang diperlukan untuk melakukan modifikasi, penyisipan, pembaruan, atau penghapusan, ke tabel atau tampilan terindeks yang mendasar.
Anda harus menentukan apakah perolehan dalam performa kueri melebihi efek terhadap performa selama modifikasi data dan dalam persyaratan ruang disk tambahan.
Panduan desain indeks unik
Indeks unik menjamin bahwa kunci indeks tidak berisi nilai duplikat dan oleh karena itu setiap baris dalam tabel dalam beberapa cara unik. Menentukan indeks unik masuk akal hanya ketika keunikan adalah karakteristik data itu sendiri. Misalnya, jika Anda ingin memastikan bahwa nilai dalam NationalIDNumber kolom dalam HumanResources.Employee tabel unik, saat kunci utama adalah EmployeeID, buat UNIQUE batasan pada NationalIDNumber kolom. Jika pengguna mencoba memasukkan nilai yang sama di kolom tersebut untuk lebih dari satu karyawan, pesan kesalahan ditampilkan dan nilai duplikat tidak dimasukkan.
Dengan indeks unik multikolom, indeks menjamin bahwa setiap kombinasi nilai dalam kunci indeks unik. Misalnya, jika indeks unik dibuat pada kombinasi LastNamekolom , , FirstNamedan MiddleName , tidak ada dua baris dalam tabel yang dapat memiliki kombinasi nilai yang sama untuk kolom ini.
Indeks berkluster dan non-kluster dapat bersifat unik. Jika data dalam kolom unik, Anda dapat membuat indeks berkluster unik dan beberapa indeks berkluster unik pada tabel yang sama.
Manfaat indeks unik meliputi yang berikut ini:
- Integritas data kolom yang ditentukan dipastikan.
- Informasi tambahan yang berguna untuk pengoptimal kueri disediakan.
PRIMARY KEY Membuat atau UNIQUE membatasi secara otomatis membuat indeks unik pada kolom yang ditentukan. Tidak ada perbedaan signifikan antara membuat UNIQUE batasan dan membuat indeks unik yang independen dari batasan. Validasi data terjadi dengan cara yang sama dan pengoptimal kueri tidak membedakan antara indeks unik yang dibuat oleh batasan atau dibuat secara manual. Namun, Anda harus membuat UNIQUE batasan atau PRIMARY KEY pada kolom saat integritas data adalah tujuannya. Dengan melakukan ini, tujuan indeks jelas.
Pertimbangan
Indeks, UNIQUE batasan, atau PRIMARY KEY batasan unik tidak dapat dibuat jika nilai kunci duplikat ada dalam data.
Jika data unik dan Anda ingin keunikan diberlakukan, membuat indeks unik alih-alih indeks nonunique pada kombinasi kolom yang sama menyediakan informasi tambahan untuk pengoptimal kueri yang dapat menghasilkan rencana eksekusi yang lebih efisien. Membuat indeks unik (sebaiknya dengan membuat UNIQUE batasan) direkomendasikan dalam kasus ini.
Indeks nonclustered unik dapat berisi kolom non-kunci yang disertakan. Untuk informasi selengkapnya, lihat Indeks dengan kolom yang disertakan.
Panduan desain indeks yang difilter
Indeks yang difilter adalah indeks non-kluster yang dioptimalkan, terutama cocok untuk mencakup kueri yang memilih dari subset data yang ditentukan dengan baik. Ini menggunakan predikat filter untuk mengindeks sebagian baris dalam tabel. Indeks terfilter yang dirancang dengan baik dapat meningkatkan performa kueri, mengurangi biaya pemeliharaan indeks, dan mengurangi biaya penyimpanan indeks dibandingkan dengan indeks tabel penuh.
Indeks yang difilter dapat memberikan keuntungan berikut daripada indeks tabel penuh:
Peningkatan performa kueri dan kualitas rencana
Indeks terfilter yang dirancang dengan baik meningkatkan performa kueri dan kualitas rencana eksekusi karena lebih kecil dari indeks nonclustered tabel penuh dan memiliki statistik yang difilter. Statistik yang difilter lebih akurat daripada statistik tabel penuh karena hanya mencakup baris dalam indeks yang difilter.
Mengurangi biaya pemeliharaan indeks
Indeks dipertahankan hanya ketika pernyataan bahasa manipulasi data (DML) memengaruhi data dalam indeks. Indeks yang difilter mengurangi biaya pemeliharaan indeks dibandingkan dengan indeks non-kluster tabel penuh karena lebih kecil dan hanya dipertahankan ketika data dalam indeks terpengaruh. Dimungkinkan untuk memiliki sejumlah besar indeks yang difilter, terutama ketika berisi data yang jarang terpengaruh. Demikian pula, jika indeks yang difilter hanya berisi data yang sering terpengaruh, ukuran indeks yang lebih kecil mengurangi biaya pembaruan statistik.
Mengurangi biaya penyimpanan indeks
Membuat indeks yang difilter dapat mengurangi penyimpanan disk untuk indeks non-kluster saat indeks tabel penuh tidak diperlukan. Anda dapat mengganti indeks non-kluster tabel penuh dengan beberapa indeks yang difilter tanpa meningkatkan persyaratan penyimpanan secara signifikan.
Indeks yang difilter berguna saat kolom berisi subset data yang ditentukan dengan baik yang direferensikan dalam SELECT pernyataan. Contohnya adalah:
- Kolom jarang yang hanya berisi beberapa nilai non.
NULL
- Kolom heterogen yang berisi kategori data.
- Kolom yang berisi rentang nilai seperti jumlah dolar, waktu, dan tanggal.
- Partisi tabel yang ditentukan oleh logika perbandingan sederhana untuk nilai kolom.
Mengurangi biaya pemeliharaan untuk indeks yang difilter paling terlihat ketika jumlah baris dalam indeks kecil dibandingkan dengan indeks tabel penuh. Jika indeks yang difilter menyertakan sebagian besar baris dalam tabel, mungkin lebih mahal untuk dipertahankan daripada indeks tabel penuh. Dalam hal ini, Anda harus menggunakan indeks tabel penuh alih-alih indeks yang difilter.
Indeks yang difilter ditentukan pada satu tabel dan hanya mendukung operator perbandingan sederhana. Jika Anda memerlukan ekspresi filter yang mereferensikan beberapa tabel atau memiliki logika kompleks, Anda harus membuat tampilan.
Pertimbangan Desain
Untuk merancang indeks yang difilter yang efektif, penting untuk memahami kueri apa yang digunakan aplikasi Anda dan bagaimana mereka berhubungan dengan subset data Anda. Beberapa contoh data yang memiliki subset yang terdefinisi dengan baik adalah kolom dengan sebagian besar NULL nilai, kolom dengan kategori nilai dan kolom heterogen dengan rentang nilai yang berbeda. Pertimbangan desain berikut memberikan berbagai skenario ketika indeks yang difilter dapat memberikan keuntungan daripada indeks tabel penuh.
Tip
Definisi indeks penyimpan kolom non-kluster mendukung penggunaan kondisi yang difilter. Untuk meminimalkan dampak performa penambahan indeks penyimpan kolom pada tabel OLTP, gunakan kondisi yang difilter untuk membuat indeks penyimpan kolom non-kluster hanya pada data dingin beban kerja operasional Anda.
Indeks yang difilter untuk subset data
Saat kolom hanya memiliki beberapa nilai yang relevan untuk kueri, Anda dapat membuat indeks yang difilter pada subset nilai. Misalnya, saat nilai dalam kolom sebagian NULL besar dan kueri hanya memilih dari nilai non,NULL Anda dapat membuat indeks yang difilter untuk baris non-dataNULL . Indeks yang dihasilkan lebih kecil dan biayanya lebih murah untuk dipertahankan daripada indeks nonkluster tabel penuh yang ditentukan pada kolom kunci yang sama.
Misalnya, database sampel AdventureWorks memiliki Production.BillOfMaterials tabel dengan 2.679 baris. Kolom EndDate hanya memiliki 199 baris yang berisi non-nilaiNULL dan 2480 baris lainnya berisi NULL. Indeks yang difilter berikut akan mencakup kueri yang mengembalikan kolom yang ditentukan dalam indeks dan yang hanya memilih baris dengan nilai bukanNULL untuk EndDate.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
GO
Indeks FIBillOfMaterialsWithEndDate yang difilter valid untuk kueri berikut. Tampilkan Perkiraan Rencana Eksekusi untuk menentukan apakah pengoptimal kueri menggunakan indeks yang difilter.
SELECT ProductAssemblyID, ComponentID, StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
GO
Untuk informasi selengkapnya tentang cara membuat indeks yang difilter dan cara menentukan ekspresi predikat indeks yang difilter, lihat Membuat indeks yang difilter.
Indeks yang difilter untuk data heterogen
Saat tabel memiliki baris data heterogen, Anda bisa membuat indeks yang difilter untuk satu atau beberapa kategori data.
Misalnya, produk yang tercantum dalam Production.Product tabel masing-masing ditetapkan ke ProductSubcategoryID, yang pada gilirannya terkait dengan kategori produk Sepeda, Komponen, Pakaian, atau Aksesori. Kategori ini bersifat heterogen karena nilai kolomnya dalam Production.Product tabel tidak berkorelasi erat. Misalnya, kolom Color, , ReorderPointListPrice, Weight, Class, dan Style memiliki karakteristik unik untuk setiap kategori produk. Misalkan ada kueri yang sering untuk aksesori, yang memiliki subkatoner antara 27 dan 36 inklusif. Anda dapat meningkatkan performa kueri untuk aksesori dengan membuat indeks yang difilter pada subkatoner aksesori seperti yang ditunjukkan dalam contoh berikut.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
Include (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
GO
Indeks FIProductAccessories yang difilter mencakup kueri berikut karena hasil kueri terkandung dalam indeks dan rencana kueri tidak menyertakan pencarian tabel dasar. Misalnya, ekspresi ProductSubcategoryID = 33 predikat kueri adalah subset dari predikat ProductSubcategoryID >= 27 indeks yang difilter dan ProductSubcategoryID <= 36, ProductSubcategoryID kolom dan ListPrice dalam predikat kueri adalah kolom kunci dalam indeks, dan nama disimpan dalam tingkat daun indeks sebagai kolom yang disertakan.
SELECT Name, ProductSubcategoryID, ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33 AND ListPrice > 25.00;
GO
Kolom kunci
Ini adalah praktik terbaik untuk menyertakan beberapa kunci atau kolom yang disertakan dalam definisi indeks yang difilter, dan untuk menggabungkan hanya kolom yang diperlukan bagi pengoptimal kueri untuk memilih indeks yang difilter untuk rencana eksekusi kueri. Pengoptimal kueri dapat memilih indeks yang difilter untuk kueri terlepas dari apakah itu terjadi atau tidak mencakup kueri. Namun, pengoptimal kueri lebih mungkin memilih indeks yang difilter jika mencakup kueri.
Dalam beberapa kasus, indeks yang difilter mencakup kueri tanpa menyertakan kolom dalam ekspresi indeks yang difilter sebagai kunci atau kolom yang disertakan dalam definisi indeks yang difilter. Panduan berikut menjelaskan kapan kolom dalam ekspresi indeks yang difilter harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter. Contoh mengacu pada indeks yang difilter, FIBillOfMaterialsWithEndDate yang dibuat sebelumnya.
Kolom dalam ekspresi indeks yang difilter tidak perlu menjadi kunci atau kolom yang disertakan dalam definisi indeks yang difilter jika ekspresi indeks yang difilter setara dengan predikat kueri dan kueri tidak mengembalikan kolom dalam ekspresi indeks yang difilter dengan hasil kueri. Misalnya, FIBillOfMaterialsWithEndDate mencakup kueri berikut karena predikat kueri setara dengan ekspresi filter, dan EndDate tidak dikembalikan dengan hasil kueri. FIBillOfMaterialsWithEndDate tidak perlu EndDate sebagai kunci atau kolom yang disertakan dalam definisi indeks yang difilter.
SELECT ComponentID, StartDate FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Kolom dalam ekspresi indeks yang difilter harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter jika predikat kueri menggunakan kolom dalam perbandingan yang tidak setara dengan ekspresi indeks yang difilter. Misalnya, FIBillOfMaterialsWithEndDate valid untuk kueri berikut karena memilih subset baris dari indeks yang difilter. Namun, kueri ini tidak mencakup kueri berikut karena EndDate digunakan dalam perbandingan EndDate > '20040101', yang tidak setara dengan ekspresi indeks yang difilter. Prosesor kueri tidak dapat menjalankan kueri ini tanpa mencari nilai EndDate. Oleh karena itu, EndDate harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter.
SELECT ComponentID, StartDate FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
Kolom dalam ekspresi indeks yang difilter harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter jika kolom berada dalam tataan hasil kueri. Misalnya, FIBillOfMaterialsWithEndDate tidak mencakup kueri berikut karena mengembalikan EndDate kolom dalam hasil kueri. Oleh karena itu, EndDate harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter.
SELECT ComponentID, StartDate, EndDate FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Kunci indeks terkluster tabel tidak perlu menjadi kunci atau kolom yang disertakan dalam definisi indeks yang difilter. Kunci indeks berkluster secara otomatis disertakan dalam semua indeks non-kluster, termasuk indeks yang difilter.
Untuk menghilangkan FIBillOfMaterialsWithEndDate indeks dan FIProductAccessories , jalankan pernyataan berikut:
DROP INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials;
GO
DROP INDEX FIProductAccessories
ON Production.Product;
GO
Operator konversi data dalam predikat filter
Jika operator perbandingan yang ditentukan dalam ekspresi indeks yang difilter dari indeks yang difilter menghasilkan konversi data implisit atau eksplisit, kesalahan terjadi jika konversi terjadi di sisi kiri operator perbandingan. Solusinya adalah menulis ekspresi indeks yang difilter dengan operator konversi data (CAST atau CONVERT) di sisi kanan operator perbandingan.
Contoh berikut membuat tabel dengan berbagai jenis data.
CREATE TABLE dbo.TestTable (
a INT,
b VARBINARY(4)
);
GO
Dalam definisi indeks yang difilter berikut, kolom b secara implisit dikonversi ke jenis data bilangan bulat untuk tujuan membandingkannya dengan konstanta 1. Ini menghasilkan pesan kesalahan 10611 karena konversi terjadi di sisi kiri operator dalam predikat yang difilter.
CREATE NONCLUSTERED INDEX TestTabIndex ON dbo.TestTable (a, b)
WHERE b = 1;
GO
Solusinya adalah mengonversi konstanta di sisi kanan menjadi tipe yang sama dengan kolom b, seperti yang terlihat dalam contoh berikut:
CREATE INDEX TestTabIndex ON dbo.TestTable (a, b)
WHERE b = CONVERT(VARBINARY(4), 1);
GO
Memindahkan konversi data dari sisi kiri ke sisi kanan operator perbandingan dapat mengubah arti konversi. Dalam contoh sebelumnya, ketika CONVERT operator ditambahkan ke sisi kanan, perbandingan berubah dari perbandingan bilangan bulat dengan perbandingan varbiner .
Hilangkan objek yang dibuat dalam contoh ini dengan menjalankan pernyataan berikut:
DROP TABLE TestTable;
GO
Arsitektur indeks penyimpan kolom
Indeks penyimpan kolom adalah teknologi untuk menyimpan, mengambil, dan mengelola data dengan menggunakan format data kolom, yang disebut penyimpan kolom. Untuk informasi selengkapnya, lihat Indeks penyimpan kolom: Gambaran Umum.
Untuk informasi versi dan untuk mengetahui apa yang baru, kunjungi Apa yang baru dalam indeks penyimpan kolom.
Mengetahui dasar-dasar ini memudahkan untuk memahami artikel penyimpan kolom lain yang menjelaskan cara menggunakannya secara efektif.
Penyimpanan data menggunakan penyimpan kolom dan kompresi rowstore
Saat membahas indeks penyimpan kolom, kami menggunakan istilah rowstore dan columnstore untuk menekankan format untuk penyimpanan data. Indeks penyimpan kolom menggunakan kedua jenis penyimpanan.
Penyimpan kolom adalah data yang secara logis diatur sebagai tabel dengan baris dan kolom, dan disimpan secara fisik dalam format data yang bijaksana kolom.
Indeks penyimpan kolom secara fisik menyimpan sebagian besar data dalam format penyimpan kolom. Dalam format penyimpan kolom, data dikompresi dan tidak dikompresi sebagai kolom. Tidak perlu membongkar nilai lain di setiap baris yang tidak diminta oleh kueri. Ini membuatnya cepat untuk memindai seluruh kolom tabel besar.
Rowstore adalah data yang secara logis diatur sebagai tabel dengan baris dan kolom, lalu disimpan secara fisik dalam format data yang bijaksana baris. Ini telah menjadi cara tradisional untuk menyimpan data tabel relasional seperti timbunan atau indeks pohon B+ berkluster.
Indeks penyimpan kolom juga secara fisik menyimpan beberapa baris dalam format rowstore yang disebut deltastore. Deltastore, juga disebut grup baris delta, adalah tempat penahanan untuk baris yang jumlahnya terlalu sedikit untuk memenuhi syarat kompresi ke penyimpanan kolom. Setiap grup baris delta diimplementasikan sebagai indeks pohon B+ berkluster.
Deltastore adalah tempat penahanan untuk baris yang jumlahnya terlalu sedikit untuk dikompresi ke dalam penyimpan kolom. Deltastore menyimpan baris dalam format rowstore.
Untuk informasi selengkapnya tentang istilah dan konsep penyimpan kolom, lihat Indeks penyimpan kolom: Gambaran Umum.
Operasi dilakukan pada grup baris dan segmen kolom
Indeks penyimpan kolom mengelompokkan baris ke dalam unit yang dapat dikelola. Masing-masing unit ini disebut grup baris. Untuk performa terbaik, jumlah baris dalam grup baris cukup besar untuk meningkatkan tingkat kompresi dan cukup kecil untuk mendapatkan manfaat dari operasi dalam memori.
Misalnya, indeks penyimpan kolom melakukan operasi ini pada grup baris:
- Memadatkan grup baris ke dalam penyimpan kolom. Pemadatan dilakukan pada setiap segmen kolom dalam grup baris.
- Menggabungkan grup baris selama
ALTER INDEX ... REORGANIZE operasi, termasuk menghapus data yang dihapus.
- Membuat grup baris baru selama
ALTER INDEX ... REBUILD operasi.
- Laporan tentang kesehatan grup baris dan fragmentasi dalam tampilan manajemen dinamis (DMV).
Deltastore terdiri dari satu atau beberapa grup baris yang disebut grup baris delta. Setiap grup baris delta adalah indeks pohon B+ berkluster yang menyimpan beban massal kecil dan menyisipkan hingga grup baris berisi 1.048.576 baris, pada saat itu proses yang disebut tuple-mover secara otomatis memadatkan grup baris tertutup ke dalam columnstore.
Untuk informasi selengkapnya tentang status grup baris, lihat sys.dm_db_column_store_row_group_physical_stats.
Tip
Memiliki terlalu banyak grup baris kecil mengurangi kualitas indeks penyimpan kolom. Operasi reorganisasi menggabungkan grup baris yang lebih kecil, mengikuti kebijakan ambang internal yang menentukan cara menghapus baris yang dihapus dan menggabungkan grup baris terkompresi. Setelah penggabungan, kualitas indeks harus ditingkatkan.
Di SQL Server 2019 (15.x) dan versi yang lebih baru, tuple-mover dibantu oleh tugas penggabungan latar belakang yang secara otomatis memadatkan grup baris delta yang lebih OPEN kecil yang telah ada selama beberapa waktu seperti yang ditentukan oleh ambang internal, atau menggabungkan COMPRESSED grup baris dari tempat sejumlah besar baris telah dihapus.
Setiap kolom memiliki beberapa nilainya di setiap grup baris. Nilai-nilai ini disebut segmen kolom. Setiap grup baris berisi satu segmen kolom untuk setiap kolom dalam tabel. Setiap kolom memiliki satu segmen kolom di setiap grup baris.
Saat indeks penyimpan kolom memadatkan grup baris, indeks tersebut memadatkan setiap segmen kolom secara terpisah. Untuk membongkar seluruh kolom, indeks penyimpan kolom hanya perlu membongkar satu segmen kolom dari setiap grup baris.
Untuk informasi selengkapnya tentang istilah dan konsep penyimpan kolom, lihat Indeks penyimpan kolom: Gambaran Umum.
Beban dan sisipan kecil masuk ke deltastore
Indeks penyimpan kolom meningkatkan pemadatan dan performa penyimpan kolom dengan memadatkan setidaknya 102.400 baris sekaligus ke dalam indeks penyimpan kolom. Untuk memadatkan baris secara massal, indeks penyimpan kolom mengakumulasi beban kecil dan sisipan di deltastore. Operasi deltastore ditangani di belakang layar. Untuk mengembalikan hasil kueri yang benar, indeks penyimpan kolom berkluster menggabungkan hasil kueri dari penyimpan kolom dan deltastore.
Baris masuk ke deltastore saat:
- Disisipkan dengan
INSERT INTO ... VALUES pernyataan.
- Di akhir beban massal, dan jumlahnya kurang dari 102.400.
- Diperbarui. Setiap pembaruan diimplementasikan sebagai penghapusan dan penyisipan.
Deltastore juga menyimpan daftar ID untuk baris yang dihapus yang telah ditandai sebagai dihapus tetapi belum dihapus secara fisik dari penyimpan kolom.
Untuk informasi selengkapnya tentang istilah dan konsep penyimpan kolom, lihat Indeks penyimpan kolom: Gambaran Umum.
Saat grup baris delta penuh, grup baris tersebut akan dikompresi ke dalam penyimpan kolom
Indeks penyimpan kolom berkluster mengumpulkan hingga 1.048.576 baris di setiap grup baris delta sebelum memadatkan grup baris ke dalam penyimpan kolom. Ini meningkatkan pemadatan indeks penyimpan kolom. Saat grup baris delta mencapai jumlah baris maksimum, grup baris tersebut beralih dari status OPEN ke CLOSED . Proses latar belakang bernama tuple-mover memeriksa grup baris tertutup. Jika proses menemukan grup baris tertutup, proses akan memadatkan grup baris dan menyimpannya ke dalam penyimpan kolom.
Ketika grup baris delta telah dikompresi, grup baris delta yang ada beralih ke status TOMBSTONE untuk dihapus nanti oleh tuple-mover ketika tidak ada referensi ke sana, dan grup baris terkompresi baru ditandai sebagai COMPRESSED.
Untuk informasi selengkapnya tentang status grup baris, lihat sys.dm_db_column_store_row_group_physical_stats.
Anda dapat memaksa grup baris delta ke dalam penyimpan kolom dengan menggunakan ALTER INDEX untuk membangun kembali atau mengatur ulang indeks. Jika ada tekanan memori selama pemadatan, indeks penyimpan kolom mungkin mengurangi jumlah baris dalam grup baris terkompresi.
Untuk informasi selengkapnya tentang istilah dan konsep penyimpan kolom, lihat Indeks penyimpan kolom: Gambaran Umum.
Setiap partisi tabel memiliki grup baris dan grup baris delta sendiri
Konsep pemartisian sama dalam indeks berkluster, timbunan, dan indeks penyimpan kolom. Pemartisian tabel membagi tabel menjadi grup baris yang lebih kecil sesuai dengan rentang nilai kolom. Ini sering digunakan untuk mengelola data. Misalnya, Anda dapat membuat partisi untuk setiap tahun data, lalu menggunakan pengalihan partisi untuk mengarsipkan data ke penyimpanan yang lebih murah. Pengalihan partisi berfungsi pada indeks penyimpan kolom dan memudahkan untuk memindahkan partisi data ke lokasi lain.
Grup baris selalu ditentukan dalam partisi tabel. Ketika indeks penyimpan kolom dipartisi, setiap partisi memiliki grup baris terkompresi dan grup baris delta sendiri.
Tip
Pertimbangkan untuk menggunakan pemartisian tabel jika ada kebutuhan untuk menghapus data dari penyimpan kolom. Beralih dan memotong partisi yang tidak diperlukan lagi adalah strategi yang efisien untuk menghapus data tanpa menghasilkan fragmentasi yang diperkenalkan dengan memiliki grup baris yang lebih kecil.
Setiap partisi dapat memiliki beberapa grup baris delta
Setiap partisi dapat memiliki lebih dari satu grup baris delta. Ketika indeks penyimpan kolom perlu menambahkan data ke grup baris delta dan grup baris delta dikunci, indeks penyimpan kolom mencoba mendapatkan kunci pada grup baris delta yang berbeda. Jika tidak ada grup baris delta yang tersedia, indeks penyimpan kolom membuat grup baris delta baru. Misalnya, tabel dengan 10 partisi dapat dengan mudah memiliki 20 grup baris delta atau lebih.
Menggabungkan indeks penyimpan kolom dan rowstore pada tabel yang sama
Indeks nonclustered berisi salinan bagian atau semua baris dan kolom dalam tabel yang mendasar. Indeks didefinisikan sebagai satu atau beberapa kolom tabel, dan memiliki kondisi opsional yang memfilter baris.
Anda dapat membuat indeks penyimpan kolom nonclustered yang dapat diperbarui pada tabel rowstore. Indeks penyimpan kolom menyimpan salinan data sehingga Anda memerlukan penyimpanan tambahan. Namun, data dalam indeks penyimpan kolom dikompresi ke ukuran yang lebih kecil dari yang diperlukan tabel rowstore. Dengan melakukan ini, Anda dapat menjalankan analitik pada indeks penyimpan kolom dan transaksi pada indeks rowstore secara bersamaan. Penyimpan kolom diperbarui saat data berubah dalam tabel rowstore, sehingga kedua indeks bekerja terhadap data yang sama.
Anda dapat memiliki satu atau beberapa indeks rowstore nonclustered pada indeks penyimpan kolom. Dengan melakukan ini, Anda dapat melakukan pencarian tabel yang efisien di penyimpan kolom yang mendasar. Opsi lain juga tersedia. Misalnya, Anda dapat menerapkan batasan kunci utama dengan menggunakan UNIQUE batasan pada tabel rowstore. Karena nilai nonunique gagal disisipkan ke dalam tabel rowstore, Mesin Database tidak dapat menyisipkan nilai ke dalam penyimpan kolom.
Pertimbangan performa
Definisi indeks penyimpan kolom non-kluster mendukung penggunaan kondisi yang difilter. Untuk meminimalkan dampak performa penambahan indeks penyimpan kolom pada tabel OLTP, gunakan kondisi yang difilter untuk membuat indeks penyimpan kolom non-kluster hanya pada data dingin beban kerja operasional Anda.
Tabel dalam memori dapat memiliki satu indeks penyimpan kolom. Anda dapat membuatnya saat tabel dibuat atau menambahkannya nanti dengan ALTER TABLE (Transact-SQL). Sebelum SQL Server 2016 (13.x), hanya tabel berbasis disk yang dapat memiliki indeks penyimpan kolom.
Untuk informasi selengkapnya, lihat Indeks penyimpan kolom - Performa kueri.
Panduan desain
- Tabel rowstore dapat memiliki satu indeks penyimpan kolom nonclustered yang dapat diperbarui. Sebelum SQL Server 2014 (12.x), indeks penyimpan kolom non-kluster bersifat baca-saja.
Untuk informasi selengkapnya, lihat Indeks penyimpan kolom - Panduan desain.
Panduan desain indeks hash
Semua tabel yang dioptimalkan memori harus memiliki setidaknya satu indeks, karena ini adalah indeks yang menghubungkan baris bersama-sama. Pada tabel yang dioptimalkan memori, setiap indeks juga dioptimalkan memori. Indeks hash adalah salah satu jenis indeks yang mungkin dalam tabel yang dioptimalkan memori. Untuk informasi selengkapnya, lihat Indeks pada Tabel yang Dioptimalkan Memori.
Berlaku untuk: SQL Server, Azure SQL Database, dan Azure SQL Managed Instance.
Arsitektur indeks hash
Indeks hash terdiri dari array pointer, dan setiap elemen array disebut wadah hash.
- Setiap wadah adalah 8 byte, yang digunakan untuk menyimpan alamat memori daftar tautan entri kunci.
- Setiap entri adalah nilai untuk kunci indeks, ditambah alamat baris yang sesuai dalam tabel yang dioptimalkan memori yang mendasar.
- Setiap entri menunjuk ke entri berikutnya dalam daftar tautan entri, semua ditautkan ke wadah saat ini.
Jumlah wadah harus ditentukan pada waktu definisi indeks:
- Semakin rendah rasio wadah terhadap baris tabel atau ke nilai yang berbeda, semakin lama daftar tautan wadah rata-rata.
- Daftar tautan pendek berkinerja lebih cepat daripada daftar tautan panjang.
- Jumlah maksimum wadah dalam indeks hash adalah 1.073.741.824.
Tip
Untuk menentukan hak BUCKET_COUNT untuk data Anda, lihat Mengonfigurasi jumlah wadah indeks hash.
Fungsi hash diterapkan ke kolom kunci indeks dan hasil fungsi menentukan wadah apa yang termasuk dalam kunci tersebut. Setiap wadah memiliki pointer ke baris yang nilai kunci hash-nya dipetakan ke wadah tersebut.
Fungsi hashing yang digunakan untuk indeks hash memiliki karakteristik berikut:
- Mesin Database memiliki satu fungsi hash yang digunakan untuk semua indeks hash.
- Fungsi hash adalah deterministik. Nilai kunci input yang sama selalu dipetakan ke wadah yang sama dalam indeks hash.
- Beberapa kunci indeks mungkin dipetakan ke wadah hash yang sama.
- Fungsi hash seimbang, yang berarti bahwa distribusi nilai kunci indeks melalui wadah hash biasanya mengikuti Distribusi kurva Poisson atau bel, bukan distribusi linier datar.
- Distribusi Poisson bukanlah distribusi yang merata. Nilai kunci indeks tidak didistribusikan secara merata dalam wadah hash.
- Jika dua kunci indeks dipetakan ke wadah hash yang sama, ada tabrakan hash. Sejumlah besar tabrakan hash dapat berdampak pada performa pada operasi baca. Tujuan realistis adalah untuk 30 persen wadah berisi dua nilai kunci yang berbeda.
Interplay indeks hash dan wadah dirangkum dalam gambar berikut.
Mengonfigurasi jumlah wadah indeks hash
Jumlah wadah indeks hash ditentukan pada waktu pembuatan indeks, dan dapat diubah menggunakan ALTER TABLE...ALTER INDEX REBUILD sintaks.
Dalam kebanyakan kasus, jumlah wadah idealnya adalah antara 1 dan 2 kali jumlah nilai yang berbeda dalam kunci indeks.
Anda mungkin tidak selalu dapat memprediksi berapa banyak nilai yang dapat dimiliki kunci indeks tertentu, atau akan memilikinya. Performa biasanya masih baik jika BUCKET_COUNT nilainya dalam 10 kali dari jumlah nilai kunci aktual, dan menilai secara berlebihan umumnya lebih baik daripada meremehkan.
Terlalu sedikit wadah dapat memiliki kelemahan berikut:
- Lebih banyak tabrakan hash dari nilai kunci yang berbeda.
- Setiap nilai berbeda dipaksa untuk berbagi wadah yang sama dengan nilai yang berbeda.
- Panjang rantai rata-rata per ember tumbuh.
- Semakin lama rantai wadah, semakin lambat kecepatan pencarian kesetaraan dalam indeks.
Terlalu banyak wadah dapat memiliki kelemahan berikut:
- Jumlah wadah yang terlalu tinggi dapat menghasilkan wadah yang lebih kosong.
- Wadah kosong memengaruhi performa pemindaian indeks penuh. Jika pemindaian dilakukan secara teratur, pertimbangkan untuk memilih jumlah wadah yang dekat dengan jumlah nilai kunci indeks yang berbeda.
- Wadah kosong menggunakan memori, meskipun setiap wadah hanya menggunakan 8 byte.
Catatan
Menambahkan lebih banyak wadah tidak melakukan apa pun untuk mengurangi penautan bersama entri yang berbagi nilai duplikat. Tingkat duplikasi nilai digunakan untuk memutuskan apakah hash adalah jenis indeks yang sesuai, bukan untuk menghitung jumlah wadah.
Pertimbangan performa
Performa indeks hash adalah:
- Sangat baik ketika predikat dalam
WHERE klausul menentukan nilai yang tepat untuk setiap kolom dalam kunci indeks hash. Indeks hash kembali ke pemindaian yang diberikan predikat ketidaksetaraan.
- Buruk ketika predikat dalam
WHERE klausa mencari rentang nilai dalam kunci indeks.
- Buruk ketika predikat dalam
WHERE klausul menetapkan satu nilai tertentu untuk kolom pertama dari kunci indeks hash dua kolom, tetapi tidak menentukan nilai untuk kolom kunci lainnya .
Tip
Predikat harus menyertakan semua kolom dalam kunci indeks hash. Indeks hash memerlukan kunci (untuk hash) untuk dicari ke dalam indeks.
Jika kunci indeks terdiri dari dua kolom dan WHERE klausa hanya menyediakan kolom pertama, Mesin Database tidak memiliki kunci lengkap untuk hash. Ini menghasilkan rencana kueri pemindaian indeks.
Jika indeks hash digunakan, dan jumlah kunci indeks unik adalah 100 kali (atau lebih) dari jumlah baris, pertimbangkan untuk meningkatkan ke jumlah wadah yang lebih besar untuk menghindari rantai baris besar, atau gunakan indeks yang tidak dikluster sebagai gantinya.
Pertimbangan deklarasi
Indeks hash hanya dapat ada pada tabel yang dioptimalkan memori. Ini tidak dapat ada pada tabel berbasis disk.
Indeks hash dapat dinyatakan sebagai:
UNIQUE, atau dapat default ke nonunique.NONCLUSTERED, yang merupakan default.
Contoh sintaks berikut membuat indeks hash, di luar CREATE TABLE pernyataan:
ALTER TABLE MyTable_memop
ADD INDEX ix_hash_Column2 UNIQUE
HASH (Column2) WITH (BUCKET_COUNT = 64);
Versi baris dan pengumpulan sampah
Dalam tabel yang dioptimalkan memori, saat baris dipengaruhi oleh UPDATE, tabel membuat versi baris yang diperbarui. Selama transaksi pembaruan, sesi lain mungkin dapat membaca versi baris yang lebih lama, sehingga menghindari perlambatan performa yang terkait dengan kunci baris.
Indeks hash juga dapat memiliki versi entri yang berbeda untuk mengakomodasi pembaruan.
Kemudian ketika versi lama tidak lagi diperlukan, utas pengumpulan sampah (GC) melintasi wadah dan daftar tautan mereka untuk membersihkan entri lama. Utas GC berkinerja lebih baik jika panjang rantai daftar tautan pendek. Untuk informasi selengkapnya, lihat Pengumpulan Sampah OLTP Dalam Memori.
Pedoman desain indeks nonclustered yang dioptimalkan memori
Indeks nonkluster adalah salah satu jenis indeks yang mungkin dalam tabel yang dioptimalkan memori. Untuk informasi selengkapnya, lihat Indeks pada Tabel yang Dioptimalkan Memori.
Berlaku untuk: SQL Server, Azure SQL Database, dan Azure SQL Managed Instance.
Arsitektur indeks nonclustered dalam memori
Indeks nonclustered dalam memori diimplementasikan menggunakan struktur data yang disebut pohon Bw, awalnya digambarkan dan dijelaskan oleh Microsoft Research pada tahun 2011. Pohon Bw adalah variasi kunci dan bebas kait dari pohon B. Untuk informasi selengkapnya, lihat Bw-tree: Pohon B untuk Platform Perangkat Keras Baru.
Pada tingkat tinggi, pohon Bw dapat dipahami sebagai peta halaman yang diatur oleh ID halaman (PidMap), fasilitas untuk mengalokasikan dan menggunakan kembali ID halaman (PidAlloc) dan sekumpulan halaman yang ditautkan dalam peta halaman dan satu sama lain. Ketiga subkomponen tingkat tinggi ini membentuk struktur internal dasar pohon Bw.
Strukturnya mirip dengan pohon B normal dalam arti setiap halaman memiliki sekumpulan nilai kunci yang diurutkan dan ada tingkat dalam indeks yang masing-masing menunjuk ke tingkat yang lebih rendah dan tingkat daun menunjuk ke baris data. Namun ada beberapa perbedaan.
Sama seperti indeks hash, beberapa baris data dapat ditautkan bersama-sama (versi). Penunjuk halaman di antara tingkat adalah ID halaman logis, yang merupakan offset ke dalam tabel pemetaan halaman, yang pada gilirannya memiliki alamat fisik untuk setiap halaman.
Tidak ada pembaruan halaman indeks di tempat. Halaman delta baru diperkenalkan untuk tujuan ini.
- Tidak diperlukan kait atau penguncian untuk pembaruan halaman.
- Halaman indeks bukan ukuran tetap.
Nilai kunci di setiap halaman tingkat nonleaf yang digambarkan adalah nilai tertinggi yang ditunjukkan anak tersebut, dan setiap baris juga berisi ID halaman logis halaman tersebut. Pada halaman tingkat daun, bersama dengan nilai kunci, berisi alamat fisik baris data.
Pencarian titik mirip dengan pohon B, kecuali karena halaman ditautkan hanya dalam satu arah, Mesin Database SQL Server mengikuti penunjuk halaman kanan, di mana setiap halaman nonleaf memiliki nilai tertinggi anaknya, bukan nilai terendah seperti di pohon B.
Jika halaman tingkat daun harus berubah, Mesin Database SQL Server tidak mengubah halaman itu sendiri. Sebaliknya, Mesin Database SQL Server membuat catatan delta yang menjelaskan perubahan, dan menambahkannya ke halaman sebelumnya. Kemudian juga memperbarui alamat tabel peta halaman untuk halaman sebelumnya, ke alamat catatan delta yang sekarang menjadi alamat fisik untuk halaman ini.
Ada tiga operasi berbeda yang dapat diperlukan untuk mengelola struktur pohon Bw: konsolidasi, pemisahan, dan penggabungan.
Konsolidasi Delta
Rantai panjang rekaman delta akhirnya dapat menurunkan performa pencarian karena itu bisa berarti kita melintasi rantai panjang saat mencari melalui indeks. Jika catatan delta baru ditambahkan ke rantai yang sudah memiliki 16 elemen, perubahan dalam rekaman delta dikonsolidasikan ke dalam halaman indeks yang direferensikan, dan halaman kemudian dibangun kembali, termasuk perubahan yang ditunjukkan oleh rekaman delta baru yang memicu konsolidasi. Halaman yang baru dibangun ulang memiliki ID halaman yang sama tetapi alamat memori baru.
Pisahkan halaman
Halaman indeks di pohon Bw tumbuh sesuai kebutuhan mulai dari menyimpan satu baris hingga menyimpan maksimum 8 KB. Setelah halaman indeks tumbuh menjadi 8 KB, sisipan baru dari satu baris menyebabkan halaman indeks terpisah. Untuk halaman internal, ini berarti ketika tidak ada lagi ruang untuk menambahkan nilai kunci dan penunjuk lain, dan untuk halaman daun, itu berarti bahwa baris akan terlalu besar agar pas di halaman setelah semua rekaman delta dimasukkan. Informasi statistik di header halaman untuk halaman daun melacak berapa banyak ruang yang diperlukan untuk mengonsolidasikan rekaman delta. Informasi ini disesuaikan saat setiap catatan delta baru ditambahkan.
Operasi pemisahan dilakukan dalam dua langkah atom. Dalam diagram berikut, asumsikan halaman daun memaksa pemisahan karena kunci dengan nilai 5 sedang disisipkan, dan halaman nonleaf ada yang menunjuk ke akhir halaman tingkat daun saat ini (nilai kunci 4).
Langkah 1: Alokasikan dua halaman P1 baru dan P2, dan pisahkan baris dari halaman lama P1 ke halaman baru ini, termasuk baris yang baru disisipkan. Slot baru dalam tabel pemetaan halaman digunakan untuk menyimpan alamat fisik halaman P2. Halaman-halaman ini, P1 dan P2 belum dapat diakses oleh operasi bersamaan. Selain itu, pointer logis dari P1 ke P2 diatur. Kemudian, dalam satu langkah atom memperbarui tabel pemetaan halaman untuk mengubah penunjuk dari lama P1 ke yang baru P1.
Langkah 2: Halaman nonleaf menunjuk ke P1 tetapi tidak ada penunjuk langsung dari halaman nonleaf ke P2. P2 hanya dapat dijangkau melalui P1. Untuk membuat penunjuk dari halaman nonleaf ke P2, alokasikan halaman nonleaf baru (halaman indeks internal), salin semua baris dari halaman nonleaf lama, dan tambahkan baris baru untuk menunjuk ke P2. Setelah ini selesai, dalam satu langkah atom, perbarui tabel pemetaan halaman untuk mengubah penunjuk dari halaman nonleaf lama ke halaman nonleaf baru.
Gabungkan halaman
DELETE Ketika operasi menghasilkan halaman yang memiliki kurang dari 10 persen dari ukuran halaman maksimum (saat ini 8 KB), atau dengan satu baris di dalamnya, halaman tersebut digabungkan dengan halaman yang berdekatan.
Saat baris dihapus dari halaman, catatan delta untuk penghapusan ditambahkan. Selain itu, pemeriksaan dilakukan untuk menentukan apakah halaman indeks (halaman nonleaf) memenuhi syarat untuk Penggabungan. Pemeriksaan ini memverifikasi apakah ruang yang tersisa setelah menghapus baris kurang dari 10 persen dari ukuran halaman maksimum. Jika memenuhi syarat, Penggabungan dilakukan dalam tiga langkah atom.
Dalam gambar berikut, asumsikan DELETE operasi menghapus nilai kunci 10.
Langkah 1: Halaman delta yang mewakili nilai 10 kunci (segitiga biru) dibuat dan penunjuknya di halaman Pp1 nonleaf diatur ke halaman delta baru. Selain itu, halaman merge-delta khusus (segitiga hijau) dibuat, dan ditautkan untuk menunjuk ke halaman delta. Pada tahap ini, kedua halaman (halaman delta dan halaman merge-delta) tidak terlihat oleh transaksi bersamaan. Dalam satu langkah atomik, penunjuk ke halaman P1 tingkat daun dalam tabel pemetaan halaman diperbarui untuk menunjuk ke halaman merge-delta. Setelah langkah ini, entri untuk nilai 10 kunci di Pp1 sekarang menunjuk ke halaman merge-delta.
Langkah 2: Baris yang mewakili nilai 7 kunci di halaman Pp1 nonleaf perlu dihapus, dan entri untuk nilai 10 kunci yang diperbarui untuk menunjuk ke P1. Untuk melakukan ini, halaman Pp2 nonleaf baru dialokasikan dan semua baris dari Pp1 disalin, kecuali untuk baris yang mewakili nilai 7kunci ; maka baris untuk nilai 10 kunci diperbarui untuk menunjuk ke halaman P1. Setelah ini selesai, dalam satu langkah atom, entri tabel pemetaan halaman yang menunjuk ke Pp1 diperbarui untuk menunjuk ke Pp2. Pp1 tidak lagi dapat dijangkau.
Langkah 3: Halaman tingkat P2 daun dan P1 digabungkan dan halaman delta dihapus. Untuk melakukan ini, halaman P3 baru dialokasikan dan baris dari P2 dan P1 digabungkan, dan perubahan halaman delta disertakan dalam baru P3. Kemudian, dalam satu langkah atomik, entri tabel pemetaan halaman yang menunjuk ke halaman P1 diperbarui untuk menunjuk ke halaman P3.
Pertimbangan performa
Performa indeks nonclustered lebih baik daripada indeks hash nonclustered saat mengkueri tabel yang dioptimalkan memori dengan predikat ketidaksamaan.
Kolom dalam tabel yang dioptimalkan memori dapat menjadi bagian dari indeks hash dan indeks nonclustered.
Saat kolom kunci dalam indeks yang tidak dikluster memiliki banyak nilai duplikat, performa dapat menurun untuk pembaruan, penyisipan, dan penghapusan. Salah satu cara untuk meningkatkan performa dalam situasi ini adalah dengan menambahkan kolom yang memiliki selektivitas yang lebih baik dalam kunci indeks.
Konten terkait
- BUAT INDEKS (Transact-SQL)
- Optimalkan pemeliharaan indeks untuk meningkatkan performa kueri dan mengurangi konsumsi sumber daya
- Tabel dan indeks yang dipartisi
- Indeks pada Tabel yang Dioptimalkan Memori
- Indeks Penyimpan Kolom: Ringkasan
- Indeks pada kolom komputasi
- Menyetel indeks non-kluster dengan saran indeks yang hilang
Pertimbangkan karakteristik database saat merancang indeks non-kluster.
Database atau tabel dengan persyaratan pembaruan rendah, tetapi data dalam volume besar dapat memperoleh manfaat dari banyak indeks yang tidak terkluster untuk meningkatkan performa kueri. Pertimbangkan untuk membuat indeks yang difilter untuk subset data yang terdefinisi dengan baik untuk meningkatkan performa kueri, mengurangi biaya penyimpanan indeks, dan mengurangi biaya pemeliharaan indeks dibandingkan dengan indeks nonclustered tabel penuh.
Aplikasi dan database Sistem Dukungan Keputusan yang terutama berisi data baca-saja dapat memperoleh manfaat dari banyak indeks non-kluster. Pengoptimal kueri memiliki lebih banyak indeks untuk dipilih untuk menentukan metode akses tercepat, dan karakteristik pembaruan rendah dari database berarti pemeliharaan indeks tidak menghambat performa.
Aplikasi dan database Pemrosesan Transaksi Online (OLTP) yang berisi tabel yang sangat diperbarui harus menghindari pengindeksan berlebihan. Selain itu, indeks harus sempit, yaitu, dengan kolom seserang mungkin.
Sejumlah besar indeks pada tabel memengaruhi performa
INSERTpernyataan , ,UPDATEDELETE, danMERGEkarena semua indeks harus disesuaikan dengan tepat saat data dalam tabel berubah.
Pertimbangan kueri
Sebelum membuat indeks non-kluster, Anda harus memahami bagaimana data Anda diakses. Pertimbangkan untuk menggunakan indeks nonclustered untuk kueri yang memiliki atribut berikut:
Gunakan
JOINklausa atauGROUP BY.Buat beberapa indeks non-kluster pada kolom yang terlibat dalam operasi gabungan dan pengelompokan, dan indeks berkluster pada kolom kunci asing apa pun.
Kueri yang tidak mengembalikan tataan hasil besar.
Buat indeks yang difilter untuk mencakup kueri yang mengembalikan subset baris yang ditentukan dengan baik dari tabel besar.
Tip
WHEREBiasanya klausulCREATE INDEXpernyataan cocok denganWHEREklausul kueri yang sedang dibahas.Berisi kolom yang sering terlibat dalam kondisi pencarian kueri, seperti
WHEREklausa, yang mengembalikan kecocokan persis.Tip
Pertimbangkan biaya versus manfaat saat menambahkan indeks baru. Mungkin lebih baik untuk mengonsolidasikan kebutuhan kueri tambahan ke dalam indeks yang sudah ada. Misalnya, pertimbangkan untuk menambahkan satu atau dua kolom tingkat daun tambahan ke indeks yang ada, jika memungkinkan cakupan beberapa kueri penting, alih-alih memiliki satu indeks yang benar-benar mencakup per setiap kueri penting.
Pertimbangan kolom
Pertimbangkan kolom yang memiliki satu atau beberapa atribut ini:
Tutupi kueri.
Perolehan performa dicapai saat indeks berisi semua kolom dalam kueri. Pengoptimal kueri dapat menemukan semua nilai kolom dalam indeks; tabel atau data indeks terkluster tidak diakses sehingga menghasilkan lebih sedikit operasi I/O disk. Gunakan indeks dengan kolom yang disertakan untuk menambahkan kolom penutup alih-alih membuat kunci indeks yang lebar.
Jika tabel memiliki indeks berkluster, kolom atau kolom yang ditentukan dalam indeks berkluster secara otomatis ditambahkan ke setiap indeks non-kluster pada tabel. Ini dapat menghasilkan kueri tercakup tanpa menentukan kolom indeks berkluster dalam definisi indeks non-kluster. Misalnya, jika tabel memiliki indeks berkluster pada kolom
C, indeks nonunique nonclustered pada kolomBdanAmemiliki sebagai kolomBnilai kuncinya , ,AdanC. Untuk informasi selengkapnya, kunjungi arsitektur indeks non-klusster.Banyak nilai yang berbeda, seperti kombinasi nama keluarga dan nama depan, jika indeks berkluster digunakan untuk kolom lain.
Jika ada sangat sedikit nilai yang berbeda, seperti hanya
1dan0, sebagian besar kueri tidak akan menggunakan indeks karena pemindaian tabel umumnya lebih efisien. Untuk jenis data ini, pertimbangkan untuk membuat indeks yang difilter pada nilai berbeda yang hanya terjadi dalam beberapa baris. Misalnya, jika sebagian besar nilai adalah0, pengoptimal kueri dapat menggunakan indeks yang difilter untuk baris data yang berisi1.
Gunakan kolom yang disertakan untuk memperluas indeks non-klusster
Anda dapat memperluas fungsionalitas indeks nonclustered dengan menambahkan kolom non-kunci ke tingkat daun indeks nonclustered. Dengan menyertakan kolom non-kunci, Anda dapat membuat indeks nonclustered yang mencakup lebih banyak kueri. Ini karena kolom non-kunci memiliki manfaat berikut:
Mereka bisa menjadi jenis data yang tidak diizinkan sebagai kolom kunci indeks.
Kolom tidak dipertimbangkan oleh Mesin Database saat menghitung jumlah kolom kunci indeks atau ukuran kunci indeks.
Indeks dengan kolom non-kunci yang disertakan dapat secara signifikan meningkatkan performa kueri ketika semua kolom dalam kueri disertakan dalam indeks baik sebagai kolom kunci atau non-kunci. Perolehan performa dicapai karena pengoptimal kueri dapat menemukan semua nilai kolom dalam indeks; tabel atau data indeks terkluster tidak diakses sehingga menghasilkan lebih sedikit operasi I/O disk.
Catatan
Saat indeks berisi semua kolom yang dirujuk oleh kueri, indeks biasanya disebut sebagai mencakup kueri.
Meskipun kolom kunci disimpan di semua tingkat indeks, kolom non-kunci hanya disimpan di tingkat daun.
Menggunakan kolom yang disertakan untuk menghindari batas ukuran
Anda dapat menyertakan kolom non-kunci dalam indeks non-kluster untuk menghindari melebihi batasan ukuran indeks saat ini dari maksimum 16 kolom kunci dan ukuran kunci indeks maksimum 900 byte. Mesin Database tidak mempertimbangkan kolom non-kunci saat menghitung jumlah kolom kunci indeks atau ukuran kunci indeks.
Misalnya, asumsikan bahwa Anda ingin mengindeks kolom berikut dalam Document tabel:
Title NVARCHAR(50)
Revision NCHAR(5)
FileName NVARCHAR(400)
Karena jenis data nchar dan nvarchar memerlukan 2 byte untuk setiap karakter, indeks yang berisi ketiga kolom ini akan melebihi batasan ukuran 900 byte sebesar 10 byte (455 * 2). Dengan menggunakan INCLUDE klausa CREATE INDEX pernyataan, kunci indeks dapat didefinisikan sebagai (Title, Revision) dan FileName didefinisikan sebagai kolom non-kunci. Dengan cara ini, ukuran kunci indeks adalah 110 byte (55 * 2), dan indeks masih akan berisi semua kolom yang diperlukan. Pernyataan berikut membuat indeks seperti itu.
CREATE INDEX IX_Document_Title
ON Production.Document (Title, Revision)
INCLUDE (FileName);
GO
Jika Anda mengikuti contoh kode, Anda dapat menghilangkan indeks ini menggunakan pernyataan Transact-SQL ini:
DROP INDEX IX_Document_Title
ON Production.Document;
GO
Indeks dengan panduan kolom yang disertakan
Saat Anda merancang indeks nonclustered dengan kolom yang disertakan, pertimbangkan panduan berikut:
Kolom non-kunci didefinisikan dalam
INCLUDEklausaCREATE INDEXpernyataan.Kolom non-kunci hanya dapat ditentukan pada indeks nonclustered pada tabel atau tampilan terindeks.
Semua jenis data diizinkan kecuali teks, ntext, dan gambar.
Kolom komputasi yang deterministik dan tepat atau tidak tepat dapat disertakan kolom. Untuk informasi selengkapnya, lihat Indeks pada kolom komputasi.
Seperti halnya kolom kunci, kolom komputasi yang berasal dari tipe data gambar, ntext, dan teks dapat berupa kolom non-kunci (disertakan) selama jenis data kolom komputasi diizinkan sebagai kolom indeks non-kunci.
Nama kolom tidak dapat ditentukan dalam
INCLUDEdaftar dan di daftar kolom kunci.Nama kolom tidak dapat diulang dalam
INCLUDEdaftar.
Panduan ukuran kolom
Setidaknya satu kolom kunci harus ditentukan. Jumlah maksimum kolom non-kunci adalah 1.023 kolom. Ini adalah jumlah maksimum kolom tabel dikurangi 1.
Kolom kunci indeks, tidak termasuk non-kunci, harus mengikuti batasan ukuran indeks yang ada maksimum 16 kolom kunci, dan ukuran kunci indeks total 900 byte.
Ukuran total semua kolom nonkey hanya dibatasi oleh ukuran kolom yang ditentukan dalam
INCLUDEklausul; misalnya, kolom varchar(max) dibatasi hingga 2 GB.
Panduan modifikasi kolom
Saat Anda mengubah kolom tabel yang telah didefinisikan sebagai kolom yang disertakan, pembatasan berikut berlaku:
Kolom non-kunci tidak dapat dihilangkan dari tabel kecuali indeks dihilangkan terlebih dahulu.
Kolom non-kunci tidak dapat diubah, kecuali untuk melakukan hal berikut:
Ubah nullability kolom dari
NOT NULLkeNULL.Tingkatkan panjang kolom varchar, nvarchar, atau varbinary .
Catatan
Pembatasan modifikasi kolom ini juga berlaku untuk kolom kunci indeks.
Rekomendasi desain
Desain ulang indeks non-kluster dengan ukuran kunci indeks besar sehingga hanya kolom yang digunakan untuk pencarian dan pencarian yang merupakan kolom kunci. Buat semua kolom lain yang mencakup kolom nonkey yang disertakan kueri. Dengan cara ini, Anda memiliki semua kolom yang diperlukan untuk mencakup kueri, tetapi kunci indeks itu sendiri kecil dan efisien.
Misalnya, asumsikan bahwa Anda ingin merancang indeks untuk mencakup kueri berikut.
SELECT AddressLine1, AddressLine2, City, StateProvinceID, PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
GO
Untuk mencakup kueri, setiap kolom harus ditentukan dalam indeks. Meskipun Anda dapat menentukan semua kolom sebagai kolom kunci, ukuran kuncinya adalah 334 byte. Karena satu-satunya kolom yang digunakan sebagai kriteria pencarian adalah PostalCode kolom , memiliki panjang 30 byte, desain indeks yang lebih baik akan menentukan PostalCode sebagai kolom kunci dan menyertakan semua kolom lain sebagai kolom non-kunci.
Pernyataan berikut membuat indeks dengan kolom yang disertakan untuk mencakup kueri.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Untuk memvalidasi bahwa indeks mencakup kueri, buat indeks, lalu tampilkan perkiraan rencana eksekusi.
Jika rencana eksekusi hanya SELECT memperlihatkan operator dan operator Pencarian Indeks untuk IX_Address_PostalCode indeks, kueri dicakup oleh indeks.
Anda dapat menghilangkan indeks dengan pernyataan berikut:
DROP INDEX IX_Address_PostalCode
ON Person.Address;
GO
Pertimbangan performa
Hindari menambahkan kolom yang tidak perlu. Menambahkan terlalu banyak kolom indeks, kunci, atau non-kunci, dapat memiliki implikasi performa berikut:
Lebih sedikit baris indeks yang pas pada halaman. Ini dapat menciptakan peningkatan I/O dan mengurangi efisiensi cache.
Lebih banyak ruang disk diperlukan untuk menyimpan indeks. Secara khusus, menambahkan jenis data varchar(max), nvarchar(max), varbinary(max), atau xml karena kolom indeks nonkey dapat secara signifikan meningkatkan persyaratan ruang disk. Ini karena nilai kolom disalin ke tingkat daun indeks. Oleh karena itu, mereka berada di indeks dan tabel dasar.
Pemeliharaan indeks dapat meningkatkan waktu yang diperlukan untuk melakukan modifikasi, penyisipan, pembaruan, atau penghapusan, ke tabel atau tampilan terindeks yang mendasar.
Anda harus menentukan apakah perolehan dalam performa kueri melebihi efek terhadap performa selama modifikasi data dan dalam persyaratan ruang disk tambahan.
Panduan desain indeks unik
Indeks unik menjamin bahwa kunci indeks tidak berisi nilai duplikat dan oleh karena itu setiap baris dalam tabel dalam beberapa cara unik. Menentukan indeks unik masuk akal hanya ketika keunikan adalah karakteristik data itu sendiri. Misalnya, jika Anda ingin memastikan bahwa nilai dalam NationalIDNumber kolom dalam HumanResources.Employee tabel unik, saat kunci utama adalah EmployeeID, buat UNIQUE batasan pada NationalIDNumber kolom. Jika pengguna mencoba memasukkan nilai yang sama di kolom tersebut untuk lebih dari satu karyawan, pesan kesalahan ditampilkan dan nilai duplikat tidak dimasukkan.
Dengan indeks unik multikolom, indeks menjamin bahwa setiap kombinasi nilai dalam kunci indeks unik. Misalnya, jika indeks unik dibuat pada kombinasi LastNamekolom , , FirstNamedan MiddleName , tidak ada dua baris dalam tabel yang dapat memiliki kombinasi nilai yang sama untuk kolom ini.
Indeks berkluster dan non-kluster dapat bersifat unik. Jika data dalam kolom unik, Anda dapat membuat indeks berkluster unik dan beberapa indeks berkluster unik pada tabel yang sama.
Manfaat indeks unik meliputi yang berikut ini:
- Integritas data kolom yang ditentukan dipastikan.
- Informasi tambahan yang berguna untuk pengoptimal kueri disediakan.
PRIMARY KEY Membuat atau UNIQUE membatasi secara otomatis membuat indeks unik pada kolom yang ditentukan. Tidak ada perbedaan signifikan antara membuat UNIQUE batasan dan membuat indeks unik yang independen dari batasan. Validasi data terjadi dengan cara yang sama dan pengoptimal kueri tidak membedakan antara indeks unik yang dibuat oleh batasan atau dibuat secara manual. Namun, Anda harus membuat UNIQUE batasan atau PRIMARY KEY pada kolom saat integritas data adalah tujuannya. Dengan melakukan ini, tujuan indeks jelas.
Pertimbangan
Indeks,
UNIQUEbatasan, atauPRIMARY KEYbatasan unik tidak dapat dibuat jika nilai kunci duplikat ada dalam data.Jika data unik dan Anda ingin keunikan diberlakukan, membuat indeks unik alih-alih indeks nonunique pada kombinasi kolom yang sama menyediakan informasi tambahan untuk pengoptimal kueri yang dapat menghasilkan rencana eksekusi yang lebih efisien. Membuat indeks unik (sebaiknya dengan membuat
UNIQUEbatasan) direkomendasikan dalam kasus ini.Indeks nonclustered unik dapat berisi kolom non-kunci yang disertakan. Untuk informasi selengkapnya, lihat Indeks dengan kolom yang disertakan.
Panduan desain indeks yang difilter
Indeks yang difilter adalah indeks non-kluster yang dioptimalkan, terutama cocok untuk mencakup kueri yang memilih dari subset data yang ditentukan dengan baik. Ini menggunakan predikat filter untuk mengindeks sebagian baris dalam tabel. Indeks terfilter yang dirancang dengan baik dapat meningkatkan performa kueri, mengurangi biaya pemeliharaan indeks, dan mengurangi biaya penyimpanan indeks dibandingkan dengan indeks tabel penuh.
Indeks yang difilter dapat memberikan keuntungan berikut daripada indeks tabel penuh:
Peningkatan performa kueri dan kualitas rencana
Indeks terfilter yang dirancang dengan baik meningkatkan performa kueri dan kualitas rencana eksekusi karena lebih kecil dari indeks nonclustered tabel penuh dan memiliki statistik yang difilter. Statistik yang difilter lebih akurat daripada statistik tabel penuh karena hanya mencakup baris dalam indeks yang difilter.
Mengurangi biaya pemeliharaan indeks
Indeks dipertahankan hanya ketika pernyataan bahasa manipulasi data (DML) memengaruhi data dalam indeks. Indeks yang difilter mengurangi biaya pemeliharaan indeks dibandingkan dengan indeks non-kluster tabel penuh karena lebih kecil dan hanya dipertahankan ketika data dalam indeks terpengaruh. Dimungkinkan untuk memiliki sejumlah besar indeks yang difilter, terutama ketika berisi data yang jarang terpengaruh. Demikian pula, jika indeks yang difilter hanya berisi data yang sering terpengaruh, ukuran indeks yang lebih kecil mengurangi biaya pembaruan statistik.
Mengurangi biaya penyimpanan indeks
Membuat indeks yang difilter dapat mengurangi penyimpanan disk untuk indeks non-kluster saat indeks tabel penuh tidak diperlukan. Anda dapat mengganti indeks non-kluster tabel penuh dengan beberapa indeks yang difilter tanpa meningkatkan persyaratan penyimpanan secara signifikan.
Indeks yang difilter berguna saat kolom berisi subset data yang ditentukan dengan baik yang direferensikan dalam SELECT pernyataan. Contohnya adalah:
- Kolom jarang yang hanya berisi beberapa nilai non.
NULL - Kolom heterogen yang berisi kategori data.
- Kolom yang berisi rentang nilai seperti jumlah dolar, waktu, dan tanggal.
- Partisi tabel yang ditentukan oleh logika perbandingan sederhana untuk nilai kolom.
Mengurangi biaya pemeliharaan untuk indeks yang difilter paling terlihat ketika jumlah baris dalam indeks kecil dibandingkan dengan indeks tabel penuh. Jika indeks yang difilter menyertakan sebagian besar baris dalam tabel, mungkin lebih mahal untuk dipertahankan daripada indeks tabel penuh. Dalam hal ini, Anda harus menggunakan indeks tabel penuh alih-alih indeks yang difilter.
Indeks yang difilter ditentukan pada satu tabel dan hanya mendukung operator perbandingan sederhana. Jika Anda memerlukan ekspresi filter yang mereferensikan beberapa tabel atau memiliki logika kompleks, Anda harus membuat tampilan.
Pertimbangan Desain
Untuk merancang indeks yang difilter yang efektif, penting untuk memahami kueri apa yang digunakan aplikasi Anda dan bagaimana mereka berhubungan dengan subset data Anda. Beberapa contoh data yang memiliki subset yang terdefinisi dengan baik adalah kolom dengan sebagian besar NULL nilai, kolom dengan kategori nilai dan kolom heterogen dengan rentang nilai yang berbeda. Pertimbangan desain berikut memberikan berbagai skenario ketika indeks yang difilter dapat memberikan keuntungan daripada indeks tabel penuh.
Tip
Definisi indeks penyimpan kolom non-kluster mendukung penggunaan kondisi yang difilter. Untuk meminimalkan dampak performa penambahan indeks penyimpan kolom pada tabel OLTP, gunakan kondisi yang difilter untuk membuat indeks penyimpan kolom non-kluster hanya pada data dingin beban kerja operasional Anda.
Indeks yang difilter untuk subset data
Saat kolom hanya memiliki beberapa nilai yang relevan untuk kueri, Anda dapat membuat indeks yang difilter pada subset nilai. Misalnya, saat nilai dalam kolom sebagian NULL besar dan kueri hanya memilih dari nilai non,NULL Anda dapat membuat indeks yang difilter untuk baris non-dataNULL . Indeks yang dihasilkan lebih kecil dan biayanya lebih murah untuk dipertahankan daripada indeks nonkluster tabel penuh yang ditentukan pada kolom kunci yang sama.
Misalnya, database sampel AdventureWorks memiliki Production.BillOfMaterials tabel dengan 2.679 baris. Kolom EndDate hanya memiliki 199 baris yang berisi non-nilaiNULL dan 2480 baris lainnya berisi NULL. Indeks yang difilter berikut akan mencakup kueri yang mengembalikan kolom yang ditentukan dalam indeks dan yang hanya memilih baris dengan nilai bukanNULL untuk EndDate.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
GO
Indeks FIBillOfMaterialsWithEndDate yang difilter valid untuk kueri berikut. Tampilkan Perkiraan Rencana Eksekusi untuk menentukan apakah pengoptimal kueri menggunakan indeks yang difilter.
SELECT ProductAssemblyID, ComponentID, StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
GO
Untuk informasi selengkapnya tentang cara membuat indeks yang difilter dan cara menentukan ekspresi predikat indeks yang difilter, lihat Membuat indeks yang difilter.
Indeks yang difilter untuk data heterogen
Saat tabel memiliki baris data heterogen, Anda bisa membuat indeks yang difilter untuk satu atau beberapa kategori data.
Misalnya, produk yang tercantum dalam Production.Product tabel masing-masing ditetapkan ke ProductSubcategoryID, yang pada gilirannya terkait dengan kategori produk Sepeda, Komponen, Pakaian, atau Aksesori. Kategori ini bersifat heterogen karena nilai kolomnya dalam Production.Product tabel tidak berkorelasi erat. Misalnya, kolom Color, , ReorderPointListPrice, Weight, Class, dan Style memiliki karakteristik unik untuk setiap kategori produk. Misalkan ada kueri yang sering untuk aksesori, yang memiliki subkatoner antara 27 dan 36 inklusif. Anda dapat meningkatkan performa kueri untuk aksesori dengan membuat indeks yang difilter pada subkatoner aksesori seperti yang ditunjukkan dalam contoh berikut.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
Include (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
GO
Indeks FIProductAccessories yang difilter mencakup kueri berikut karena hasil kueri terkandung dalam indeks dan rencana kueri tidak menyertakan pencarian tabel dasar. Misalnya, ekspresi ProductSubcategoryID = 33 predikat kueri adalah subset dari predikat ProductSubcategoryID >= 27 indeks yang difilter dan ProductSubcategoryID <= 36, ProductSubcategoryID kolom dan ListPrice dalam predikat kueri adalah kolom kunci dalam indeks, dan nama disimpan dalam tingkat daun indeks sebagai kolom yang disertakan.
SELECT Name, ProductSubcategoryID, ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33 AND ListPrice > 25.00;
GO
Kolom kunci
Ini adalah praktik terbaik untuk menyertakan beberapa kunci atau kolom yang disertakan dalam definisi indeks yang difilter, dan untuk menggabungkan hanya kolom yang diperlukan bagi pengoptimal kueri untuk memilih indeks yang difilter untuk rencana eksekusi kueri. Pengoptimal kueri dapat memilih indeks yang difilter untuk kueri terlepas dari apakah itu terjadi atau tidak mencakup kueri. Namun, pengoptimal kueri lebih mungkin memilih indeks yang difilter jika mencakup kueri.
Dalam beberapa kasus, indeks yang difilter mencakup kueri tanpa menyertakan kolom dalam ekspresi indeks yang difilter sebagai kunci atau kolom yang disertakan dalam definisi indeks yang difilter. Panduan berikut menjelaskan kapan kolom dalam ekspresi indeks yang difilter harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter. Contoh mengacu pada indeks yang difilter, FIBillOfMaterialsWithEndDate yang dibuat sebelumnya.
Kolom dalam ekspresi indeks yang difilter tidak perlu menjadi kunci atau kolom yang disertakan dalam definisi indeks yang difilter jika ekspresi indeks yang difilter setara dengan predikat kueri dan kueri tidak mengembalikan kolom dalam ekspresi indeks yang difilter dengan hasil kueri. Misalnya, FIBillOfMaterialsWithEndDate mencakup kueri berikut karena predikat kueri setara dengan ekspresi filter, dan EndDate tidak dikembalikan dengan hasil kueri. FIBillOfMaterialsWithEndDate tidak perlu EndDate sebagai kunci atau kolom yang disertakan dalam definisi indeks yang difilter.
SELECT ComponentID, StartDate FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Kolom dalam ekspresi indeks yang difilter harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter jika predikat kueri menggunakan kolom dalam perbandingan yang tidak setara dengan ekspresi indeks yang difilter. Misalnya, FIBillOfMaterialsWithEndDate valid untuk kueri berikut karena memilih subset baris dari indeks yang difilter. Namun, kueri ini tidak mencakup kueri berikut karena EndDate digunakan dalam perbandingan EndDate > '20040101', yang tidak setara dengan ekspresi indeks yang difilter. Prosesor kueri tidak dapat menjalankan kueri ini tanpa mencari nilai EndDate. Oleh karena itu, EndDate harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter.
SELECT ComponentID, StartDate FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
Kolom dalam ekspresi indeks yang difilter harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter jika kolom berada dalam tataan hasil kueri. Misalnya, FIBillOfMaterialsWithEndDate tidak mencakup kueri berikut karena mengembalikan EndDate kolom dalam hasil kueri. Oleh karena itu, EndDate harus berupa kunci atau kolom yang disertakan dalam definisi indeks yang difilter.
SELECT ComponentID, StartDate, EndDate FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Kunci indeks terkluster tabel tidak perlu menjadi kunci atau kolom yang disertakan dalam definisi indeks yang difilter. Kunci indeks berkluster secara otomatis disertakan dalam semua indeks non-kluster, termasuk indeks yang difilter.
Untuk menghilangkan FIBillOfMaterialsWithEndDate indeks dan FIProductAccessories , jalankan pernyataan berikut:
DROP INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials;
GO
DROP INDEX FIProductAccessories
ON Production.Product;
GO
Operator konversi data dalam predikat filter
Jika operator perbandingan yang ditentukan dalam ekspresi indeks yang difilter dari indeks yang difilter menghasilkan konversi data implisit atau eksplisit, kesalahan terjadi jika konversi terjadi di sisi kiri operator perbandingan. Solusinya adalah menulis ekspresi indeks yang difilter dengan operator konversi data (CAST atau CONVERT) di sisi kanan operator perbandingan.
Contoh berikut membuat tabel dengan berbagai jenis data.
CREATE TABLE dbo.TestTable (
a INT,
b VARBINARY(4)
);
GO
Dalam definisi indeks yang difilter berikut, kolom b secara implisit dikonversi ke jenis data bilangan bulat untuk tujuan membandingkannya dengan konstanta 1. Ini menghasilkan pesan kesalahan 10611 karena konversi terjadi di sisi kiri operator dalam predikat yang difilter.
CREATE NONCLUSTERED INDEX TestTabIndex ON dbo.TestTable (a, b)
WHERE b = 1;
GO
Solusinya adalah mengonversi konstanta di sisi kanan menjadi tipe yang sama dengan kolom b, seperti yang terlihat dalam contoh berikut:
CREATE INDEX TestTabIndex ON dbo.TestTable (a, b)
WHERE b = CONVERT(VARBINARY(4), 1);
GO
Memindahkan konversi data dari sisi kiri ke sisi kanan operator perbandingan dapat mengubah arti konversi. Dalam contoh sebelumnya, ketika CONVERT operator ditambahkan ke sisi kanan, perbandingan berubah dari perbandingan bilangan bulat dengan perbandingan varbiner .
Hilangkan objek yang dibuat dalam contoh ini dengan menjalankan pernyataan berikut:
DROP TABLE TestTable;
GO
Arsitektur indeks penyimpan kolom
Indeks penyimpan kolom adalah teknologi untuk menyimpan, mengambil, dan mengelola data dengan menggunakan format data kolom, yang disebut penyimpan kolom. Untuk informasi selengkapnya, lihat Indeks penyimpan kolom: Gambaran Umum.
Untuk informasi versi dan untuk mengetahui apa yang baru, kunjungi Apa yang baru dalam indeks penyimpan kolom.
Mengetahui dasar-dasar ini memudahkan untuk memahami artikel penyimpan kolom lain yang menjelaskan cara menggunakannya secara efektif.
Penyimpanan data menggunakan penyimpan kolom dan kompresi rowstore
Saat membahas indeks penyimpan kolom, kami menggunakan istilah rowstore dan columnstore untuk menekankan format untuk penyimpanan data. Indeks penyimpan kolom menggunakan kedua jenis penyimpanan.
Penyimpan kolom adalah data yang secara logis diatur sebagai tabel dengan baris dan kolom, dan disimpan secara fisik dalam format data yang bijaksana kolom.
Indeks penyimpan kolom secara fisik menyimpan sebagian besar data dalam format penyimpan kolom. Dalam format penyimpan kolom, data dikompresi dan tidak dikompresi sebagai kolom. Tidak perlu membongkar nilai lain di setiap baris yang tidak diminta oleh kueri. Ini membuatnya cepat untuk memindai seluruh kolom tabel besar.
Rowstore adalah data yang secara logis diatur sebagai tabel dengan baris dan kolom, lalu disimpan secara fisik dalam format data yang bijaksana baris. Ini telah menjadi cara tradisional untuk menyimpan data tabel relasional seperti timbunan atau indeks pohon B+ berkluster.
Indeks penyimpan kolom juga secara fisik menyimpan beberapa baris dalam format rowstore yang disebut deltastore. Deltastore, juga disebut grup baris delta, adalah tempat penahanan untuk baris yang jumlahnya terlalu sedikit untuk memenuhi syarat kompresi ke penyimpanan kolom. Setiap grup baris delta diimplementasikan sebagai indeks pohon B+ berkluster.
Deltastore adalah tempat penahanan untuk baris yang jumlahnya terlalu sedikit untuk dikompresi ke dalam penyimpan kolom. Deltastore menyimpan baris dalam format rowstore.
Untuk informasi selengkapnya tentang istilah dan konsep penyimpan kolom, lihat Indeks penyimpan kolom: Gambaran Umum.
Operasi dilakukan pada grup baris dan segmen kolom
Indeks penyimpan kolom mengelompokkan baris ke dalam unit yang dapat dikelola. Masing-masing unit ini disebut grup baris. Untuk performa terbaik, jumlah baris dalam grup baris cukup besar untuk meningkatkan tingkat kompresi dan cukup kecil untuk mendapatkan manfaat dari operasi dalam memori.
Misalnya, indeks penyimpan kolom melakukan operasi ini pada grup baris:
- Memadatkan grup baris ke dalam penyimpan kolom. Pemadatan dilakukan pada setiap segmen kolom dalam grup baris.
- Menggabungkan grup baris selama
ALTER INDEX ... REORGANIZEoperasi, termasuk menghapus data yang dihapus. - Membuat grup baris baru selama
ALTER INDEX ... REBUILDoperasi. - Laporan tentang kesehatan grup baris dan fragmentasi dalam tampilan manajemen dinamis (DMV).
Deltastore terdiri dari satu atau beberapa grup baris yang disebut grup baris delta. Setiap grup baris delta adalah indeks pohon B+ berkluster yang menyimpan beban massal kecil dan menyisipkan hingga grup baris berisi 1.048.576 baris, pada saat itu proses yang disebut tuple-mover secara otomatis memadatkan grup baris tertutup ke dalam columnstore.
Untuk informasi selengkapnya tentang status grup baris, lihat sys.dm_db_column_store_row_group_physical_stats.
Tip
Memiliki terlalu banyak grup baris kecil mengurangi kualitas indeks penyimpan kolom. Operasi reorganisasi menggabungkan grup baris yang lebih kecil, mengikuti kebijakan ambang internal yang menentukan cara menghapus baris yang dihapus dan menggabungkan grup baris terkompresi. Setelah penggabungan, kualitas indeks harus ditingkatkan.
Di SQL Server 2019 (15.x) dan versi yang lebih baru, tuple-mover dibantu oleh tugas penggabungan latar belakang yang secara otomatis memadatkan grup baris delta yang lebih OPEN kecil yang telah ada selama beberapa waktu seperti yang ditentukan oleh ambang internal, atau menggabungkan COMPRESSED grup baris dari tempat sejumlah besar baris telah dihapus.
Setiap kolom memiliki beberapa nilainya di setiap grup baris. Nilai-nilai ini disebut segmen kolom. Setiap grup baris berisi satu segmen kolom untuk setiap kolom dalam tabel. Setiap kolom memiliki satu segmen kolom di setiap grup baris.
Saat indeks penyimpan kolom memadatkan grup baris, indeks tersebut memadatkan setiap segmen kolom secara terpisah. Untuk membongkar seluruh kolom, indeks penyimpan kolom hanya perlu membongkar satu segmen kolom dari setiap grup baris.
Untuk informasi selengkapnya tentang istilah dan konsep penyimpan kolom, lihat Indeks penyimpan kolom: Gambaran Umum.
Beban dan sisipan kecil masuk ke deltastore
Indeks penyimpan kolom meningkatkan pemadatan dan performa penyimpan kolom dengan memadatkan setidaknya 102.400 baris sekaligus ke dalam indeks penyimpan kolom. Untuk memadatkan baris secara massal, indeks penyimpan kolom mengakumulasi beban kecil dan sisipan di deltastore. Operasi deltastore ditangani di belakang layar. Untuk mengembalikan hasil kueri yang benar, indeks penyimpan kolom berkluster menggabungkan hasil kueri dari penyimpan kolom dan deltastore.
Baris masuk ke deltastore saat:
- Disisipkan dengan
INSERT INTO ... VALUESpernyataan. - Di akhir beban massal, dan jumlahnya kurang dari 102.400.
- Diperbarui. Setiap pembaruan diimplementasikan sebagai penghapusan dan penyisipan.
Deltastore juga menyimpan daftar ID untuk baris yang dihapus yang telah ditandai sebagai dihapus tetapi belum dihapus secara fisik dari penyimpan kolom.
Untuk informasi selengkapnya tentang istilah dan konsep penyimpan kolom, lihat Indeks penyimpan kolom: Gambaran Umum.
Saat grup baris delta penuh, grup baris tersebut akan dikompresi ke dalam penyimpan kolom
Indeks penyimpan kolom berkluster mengumpulkan hingga 1.048.576 baris di setiap grup baris delta sebelum memadatkan grup baris ke dalam penyimpan kolom. Ini meningkatkan pemadatan indeks penyimpan kolom. Saat grup baris delta mencapai jumlah baris maksimum, grup baris tersebut beralih dari status OPEN ke CLOSED . Proses latar belakang bernama tuple-mover memeriksa grup baris tertutup. Jika proses menemukan grup baris tertutup, proses akan memadatkan grup baris dan menyimpannya ke dalam penyimpan kolom.
Ketika grup baris delta telah dikompresi, grup baris delta yang ada beralih ke status TOMBSTONE untuk dihapus nanti oleh tuple-mover ketika tidak ada referensi ke sana, dan grup baris terkompresi baru ditandai sebagai COMPRESSED.
Untuk informasi selengkapnya tentang status grup baris, lihat sys.dm_db_column_store_row_group_physical_stats.
Anda dapat memaksa grup baris delta ke dalam penyimpan kolom dengan menggunakan ALTER INDEX untuk membangun kembali atau mengatur ulang indeks. Jika ada tekanan memori selama pemadatan, indeks penyimpan kolom mungkin mengurangi jumlah baris dalam grup baris terkompresi.
Untuk informasi selengkapnya tentang istilah dan konsep penyimpan kolom, lihat Indeks penyimpan kolom: Gambaran Umum.
Setiap partisi tabel memiliki grup baris dan grup baris delta sendiri
Konsep pemartisian sama dalam indeks berkluster, timbunan, dan indeks penyimpan kolom. Pemartisian tabel membagi tabel menjadi grup baris yang lebih kecil sesuai dengan rentang nilai kolom. Ini sering digunakan untuk mengelola data. Misalnya, Anda dapat membuat partisi untuk setiap tahun data, lalu menggunakan pengalihan partisi untuk mengarsipkan data ke penyimpanan yang lebih murah. Pengalihan partisi berfungsi pada indeks penyimpan kolom dan memudahkan untuk memindahkan partisi data ke lokasi lain.
Grup baris selalu ditentukan dalam partisi tabel. Ketika indeks penyimpan kolom dipartisi, setiap partisi memiliki grup baris terkompresi dan grup baris delta sendiri.
Tip
Pertimbangkan untuk menggunakan pemartisian tabel jika ada kebutuhan untuk menghapus data dari penyimpan kolom. Beralih dan memotong partisi yang tidak diperlukan lagi adalah strategi yang efisien untuk menghapus data tanpa menghasilkan fragmentasi yang diperkenalkan dengan memiliki grup baris yang lebih kecil.
Setiap partisi dapat memiliki beberapa grup baris delta
Setiap partisi dapat memiliki lebih dari satu grup baris delta. Ketika indeks penyimpan kolom perlu menambahkan data ke grup baris delta dan grup baris delta dikunci, indeks penyimpan kolom mencoba mendapatkan kunci pada grup baris delta yang berbeda. Jika tidak ada grup baris delta yang tersedia, indeks penyimpan kolom membuat grup baris delta baru. Misalnya, tabel dengan 10 partisi dapat dengan mudah memiliki 20 grup baris delta atau lebih.
Menggabungkan indeks penyimpan kolom dan rowstore pada tabel yang sama
Indeks nonclustered berisi salinan bagian atau semua baris dan kolom dalam tabel yang mendasar. Indeks didefinisikan sebagai satu atau beberapa kolom tabel, dan memiliki kondisi opsional yang memfilter baris.
Anda dapat membuat indeks penyimpan kolom nonclustered yang dapat diperbarui pada tabel rowstore. Indeks penyimpan kolom menyimpan salinan data sehingga Anda memerlukan penyimpanan tambahan. Namun, data dalam indeks penyimpan kolom dikompresi ke ukuran yang lebih kecil dari yang diperlukan tabel rowstore. Dengan melakukan ini, Anda dapat menjalankan analitik pada indeks penyimpan kolom dan transaksi pada indeks rowstore secara bersamaan. Penyimpan kolom diperbarui saat data berubah dalam tabel rowstore, sehingga kedua indeks bekerja terhadap data yang sama.
Anda dapat memiliki satu atau beberapa indeks rowstore nonclustered pada indeks penyimpan kolom. Dengan melakukan ini, Anda dapat melakukan pencarian tabel yang efisien di penyimpan kolom yang mendasar. Opsi lain juga tersedia. Misalnya, Anda dapat menerapkan batasan kunci utama dengan menggunakan UNIQUE batasan pada tabel rowstore. Karena nilai nonunique gagal disisipkan ke dalam tabel rowstore, Mesin Database tidak dapat menyisipkan nilai ke dalam penyimpan kolom.
Pertimbangan performa
Definisi indeks penyimpan kolom non-kluster mendukung penggunaan kondisi yang difilter. Untuk meminimalkan dampak performa penambahan indeks penyimpan kolom pada tabel OLTP, gunakan kondisi yang difilter untuk membuat indeks penyimpan kolom non-kluster hanya pada data dingin beban kerja operasional Anda.
Tabel dalam memori dapat memiliki satu indeks penyimpan kolom. Anda dapat membuatnya saat tabel dibuat atau menambahkannya nanti dengan ALTER TABLE (Transact-SQL). Sebelum SQL Server 2016 (13.x), hanya tabel berbasis disk yang dapat memiliki indeks penyimpan kolom.
Untuk informasi selengkapnya, lihat Indeks penyimpan kolom - Performa kueri.
Panduan desain
- Tabel rowstore dapat memiliki satu indeks penyimpan kolom nonclustered yang dapat diperbarui. Sebelum SQL Server 2014 (12.x), indeks penyimpan kolom non-kluster bersifat baca-saja.
Untuk informasi selengkapnya, lihat Indeks penyimpan kolom - Panduan desain.
Panduan desain indeks hash
Semua tabel yang dioptimalkan memori harus memiliki setidaknya satu indeks, karena ini adalah indeks yang menghubungkan baris bersama-sama. Pada tabel yang dioptimalkan memori, setiap indeks juga dioptimalkan memori. Indeks hash adalah salah satu jenis indeks yang mungkin dalam tabel yang dioptimalkan memori. Untuk informasi selengkapnya, lihat Indeks pada Tabel yang Dioptimalkan Memori.
Berlaku untuk: SQL Server, Azure SQL Database, dan Azure SQL Managed Instance.
Arsitektur indeks hash
Indeks hash terdiri dari array pointer, dan setiap elemen array disebut wadah hash.
- Setiap wadah adalah 8 byte, yang digunakan untuk menyimpan alamat memori daftar tautan entri kunci.
- Setiap entri adalah nilai untuk kunci indeks, ditambah alamat baris yang sesuai dalam tabel yang dioptimalkan memori yang mendasar.
- Setiap entri menunjuk ke entri berikutnya dalam daftar tautan entri, semua ditautkan ke wadah saat ini.
Jumlah wadah harus ditentukan pada waktu definisi indeks:
- Semakin rendah rasio wadah terhadap baris tabel atau ke nilai yang berbeda, semakin lama daftar tautan wadah rata-rata.
- Daftar tautan pendek berkinerja lebih cepat daripada daftar tautan panjang.
- Jumlah maksimum wadah dalam indeks hash adalah 1.073.741.824.
Tip
Untuk menentukan hak BUCKET_COUNT untuk data Anda, lihat Mengonfigurasi jumlah wadah indeks hash.
Fungsi hash diterapkan ke kolom kunci indeks dan hasil fungsi menentukan wadah apa yang termasuk dalam kunci tersebut. Setiap wadah memiliki pointer ke baris yang nilai kunci hash-nya dipetakan ke wadah tersebut.
Fungsi hashing yang digunakan untuk indeks hash memiliki karakteristik berikut:
- Mesin Database memiliki satu fungsi hash yang digunakan untuk semua indeks hash.
- Fungsi hash adalah deterministik. Nilai kunci input yang sama selalu dipetakan ke wadah yang sama dalam indeks hash.
- Beberapa kunci indeks mungkin dipetakan ke wadah hash yang sama.
- Fungsi hash seimbang, yang berarti bahwa distribusi nilai kunci indeks melalui wadah hash biasanya mengikuti Distribusi kurva Poisson atau bel, bukan distribusi linier datar.
- Distribusi Poisson bukanlah distribusi yang merata. Nilai kunci indeks tidak didistribusikan secara merata dalam wadah hash.
- Jika dua kunci indeks dipetakan ke wadah hash yang sama, ada tabrakan hash. Sejumlah besar tabrakan hash dapat berdampak pada performa pada operasi baca. Tujuan realistis adalah untuk 30 persen wadah berisi dua nilai kunci yang berbeda.
Interplay indeks hash dan wadah dirangkum dalam gambar berikut.
Mengonfigurasi jumlah wadah indeks hash
Jumlah wadah indeks hash ditentukan pada waktu pembuatan indeks, dan dapat diubah menggunakan ALTER TABLE...ALTER INDEX REBUILD sintaks.
Dalam kebanyakan kasus, jumlah wadah idealnya adalah antara 1 dan 2 kali jumlah nilai yang berbeda dalam kunci indeks.
Anda mungkin tidak selalu dapat memprediksi berapa banyak nilai yang dapat dimiliki kunci indeks tertentu, atau akan memilikinya. Performa biasanya masih baik jika BUCKET_COUNT nilainya dalam 10 kali dari jumlah nilai kunci aktual, dan menilai secara berlebihan umumnya lebih baik daripada meremehkan.
Terlalu sedikit wadah dapat memiliki kelemahan berikut:
- Lebih banyak tabrakan hash dari nilai kunci yang berbeda.
- Setiap nilai berbeda dipaksa untuk berbagi wadah yang sama dengan nilai yang berbeda.
- Panjang rantai rata-rata per ember tumbuh.
- Semakin lama rantai wadah, semakin lambat kecepatan pencarian kesetaraan dalam indeks.
Terlalu banyak wadah dapat memiliki kelemahan berikut:
- Jumlah wadah yang terlalu tinggi dapat menghasilkan wadah yang lebih kosong.
- Wadah kosong memengaruhi performa pemindaian indeks penuh. Jika pemindaian dilakukan secara teratur, pertimbangkan untuk memilih jumlah wadah yang dekat dengan jumlah nilai kunci indeks yang berbeda.
- Wadah kosong menggunakan memori, meskipun setiap wadah hanya menggunakan 8 byte.
Catatan
Menambahkan lebih banyak wadah tidak melakukan apa pun untuk mengurangi penautan bersama entri yang berbagi nilai duplikat. Tingkat duplikasi nilai digunakan untuk memutuskan apakah hash adalah jenis indeks yang sesuai, bukan untuk menghitung jumlah wadah.
Pertimbangan performa
Performa indeks hash adalah:
- Sangat baik ketika predikat dalam
WHEREklausul menentukan nilai yang tepat untuk setiap kolom dalam kunci indeks hash. Indeks hash kembali ke pemindaian yang diberikan predikat ketidaksetaraan. - Buruk ketika predikat dalam
WHEREklausa mencari rentang nilai dalam kunci indeks. - Buruk ketika predikat dalam
WHEREklausul menetapkan satu nilai tertentu untuk kolom pertama dari kunci indeks hash dua kolom, tetapi tidak menentukan nilai untuk kolom kunci lainnya .
Tip
Predikat harus menyertakan semua kolom dalam kunci indeks hash. Indeks hash memerlukan kunci (untuk hash) untuk dicari ke dalam indeks.
Jika kunci indeks terdiri dari dua kolom dan WHERE klausa hanya menyediakan kolom pertama, Mesin Database tidak memiliki kunci lengkap untuk hash. Ini menghasilkan rencana kueri pemindaian indeks.
Jika indeks hash digunakan, dan jumlah kunci indeks unik adalah 100 kali (atau lebih) dari jumlah baris, pertimbangkan untuk meningkatkan ke jumlah wadah yang lebih besar untuk menghindari rantai baris besar, atau gunakan indeks yang tidak dikluster sebagai gantinya.
Pertimbangan deklarasi
Indeks hash hanya dapat ada pada tabel yang dioptimalkan memori. Ini tidak dapat ada pada tabel berbasis disk.
Indeks hash dapat dinyatakan sebagai:
UNIQUE, atau dapat default ke nonunique.NONCLUSTERED, yang merupakan default.
Contoh sintaks berikut membuat indeks hash, di luar CREATE TABLE pernyataan:
ALTER TABLE MyTable_memop
ADD INDEX ix_hash_Column2 UNIQUE
HASH (Column2) WITH (BUCKET_COUNT = 64);
Versi baris dan pengumpulan sampah
Dalam tabel yang dioptimalkan memori, saat baris dipengaruhi oleh UPDATE, tabel membuat versi baris yang diperbarui. Selama transaksi pembaruan, sesi lain mungkin dapat membaca versi baris yang lebih lama, sehingga menghindari perlambatan performa yang terkait dengan kunci baris.
Indeks hash juga dapat memiliki versi entri yang berbeda untuk mengakomodasi pembaruan.
Kemudian ketika versi lama tidak lagi diperlukan, utas pengumpulan sampah (GC) melintasi wadah dan daftar tautan mereka untuk membersihkan entri lama. Utas GC berkinerja lebih baik jika panjang rantai daftar tautan pendek. Untuk informasi selengkapnya, lihat Pengumpulan Sampah OLTP Dalam Memori.
Pedoman desain indeks nonclustered yang dioptimalkan memori
Indeks nonkluster adalah salah satu jenis indeks yang mungkin dalam tabel yang dioptimalkan memori. Untuk informasi selengkapnya, lihat Indeks pada Tabel yang Dioptimalkan Memori.
Berlaku untuk: SQL Server, Azure SQL Database, dan Azure SQL Managed Instance.
Arsitektur indeks nonclustered dalam memori
Indeks nonclustered dalam memori diimplementasikan menggunakan struktur data yang disebut pohon Bw, awalnya digambarkan dan dijelaskan oleh Microsoft Research pada tahun 2011. Pohon Bw adalah variasi kunci dan bebas kait dari pohon B. Untuk informasi selengkapnya, lihat Bw-tree: Pohon B untuk Platform Perangkat Keras Baru.
Pada tingkat tinggi, pohon Bw dapat dipahami sebagai peta halaman yang diatur oleh ID halaman (PidMap), fasilitas untuk mengalokasikan dan menggunakan kembali ID halaman (PidAlloc) dan sekumpulan halaman yang ditautkan dalam peta halaman dan satu sama lain. Ketiga subkomponen tingkat tinggi ini membentuk struktur internal dasar pohon Bw.
Strukturnya mirip dengan pohon B normal dalam arti setiap halaman memiliki sekumpulan nilai kunci yang diurutkan dan ada tingkat dalam indeks yang masing-masing menunjuk ke tingkat yang lebih rendah dan tingkat daun menunjuk ke baris data. Namun ada beberapa perbedaan.
Sama seperti indeks hash, beberapa baris data dapat ditautkan bersama-sama (versi). Penunjuk halaman di antara tingkat adalah ID halaman logis, yang merupakan offset ke dalam tabel pemetaan halaman, yang pada gilirannya memiliki alamat fisik untuk setiap halaman.
Tidak ada pembaruan halaman indeks di tempat. Halaman delta baru diperkenalkan untuk tujuan ini.
- Tidak diperlukan kait atau penguncian untuk pembaruan halaman.
- Halaman indeks bukan ukuran tetap.
Nilai kunci di setiap halaman tingkat nonleaf yang digambarkan adalah nilai tertinggi yang ditunjukkan anak tersebut, dan setiap baris juga berisi ID halaman logis halaman tersebut. Pada halaman tingkat daun, bersama dengan nilai kunci, berisi alamat fisik baris data.
Pencarian titik mirip dengan pohon B, kecuali karena halaman ditautkan hanya dalam satu arah, Mesin Database SQL Server mengikuti penunjuk halaman kanan, di mana setiap halaman nonleaf memiliki nilai tertinggi anaknya, bukan nilai terendah seperti di pohon B.
Jika halaman tingkat daun harus berubah, Mesin Database SQL Server tidak mengubah halaman itu sendiri. Sebaliknya, Mesin Database SQL Server membuat catatan delta yang menjelaskan perubahan, dan menambahkannya ke halaman sebelumnya. Kemudian juga memperbarui alamat tabel peta halaman untuk halaman sebelumnya, ke alamat catatan delta yang sekarang menjadi alamat fisik untuk halaman ini.
Ada tiga operasi berbeda yang dapat diperlukan untuk mengelola struktur pohon Bw: konsolidasi, pemisahan, dan penggabungan.
Konsolidasi Delta
Rantai panjang rekaman delta akhirnya dapat menurunkan performa pencarian karena itu bisa berarti kita melintasi rantai panjang saat mencari melalui indeks. Jika catatan delta baru ditambahkan ke rantai yang sudah memiliki 16 elemen, perubahan dalam rekaman delta dikonsolidasikan ke dalam halaman indeks yang direferensikan, dan halaman kemudian dibangun kembali, termasuk perubahan yang ditunjukkan oleh rekaman delta baru yang memicu konsolidasi. Halaman yang baru dibangun ulang memiliki ID halaman yang sama tetapi alamat memori baru.
Pisahkan halaman
Halaman indeks di pohon Bw tumbuh sesuai kebutuhan mulai dari menyimpan satu baris hingga menyimpan maksimum 8 KB. Setelah halaman indeks tumbuh menjadi 8 KB, sisipan baru dari satu baris menyebabkan halaman indeks terpisah. Untuk halaman internal, ini berarti ketika tidak ada lagi ruang untuk menambahkan nilai kunci dan penunjuk lain, dan untuk halaman daun, itu berarti bahwa baris akan terlalu besar agar pas di halaman setelah semua rekaman delta dimasukkan. Informasi statistik di header halaman untuk halaman daun melacak berapa banyak ruang yang diperlukan untuk mengonsolidasikan rekaman delta. Informasi ini disesuaikan saat setiap catatan delta baru ditambahkan.
Operasi pemisahan dilakukan dalam dua langkah atom. Dalam diagram berikut, asumsikan halaman daun memaksa pemisahan karena kunci dengan nilai 5 sedang disisipkan, dan halaman nonleaf ada yang menunjuk ke akhir halaman tingkat daun saat ini (nilai kunci 4).

Langkah 1: Alokasikan dua halaman P1 baru dan P2, dan pisahkan baris dari halaman lama P1 ke halaman baru ini, termasuk baris yang baru disisipkan. Slot baru dalam tabel pemetaan halaman digunakan untuk menyimpan alamat fisik halaman P2. Halaman-halaman ini, P1 dan P2 belum dapat diakses oleh operasi bersamaan. Selain itu, pointer logis dari P1 ke P2 diatur. Kemudian, dalam satu langkah atom memperbarui tabel pemetaan halaman untuk mengubah penunjuk dari lama P1 ke yang baru P1.
Langkah 2: Halaman nonleaf menunjuk ke P1 tetapi tidak ada penunjuk langsung dari halaman nonleaf ke P2. P2 hanya dapat dijangkau melalui P1. Untuk membuat penunjuk dari halaman nonleaf ke P2, alokasikan halaman nonleaf baru (halaman indeks internal), salin semua baris dari halaman nonleaf lama, dan tambahkan baris baru untuk menunjuk ke P2. Setelah ini selesai, dalam satu langkah atom, perbarui tabel pemetaan halaman untuk mengubah penunjuk dari halaman nonleaf lama ke halaman nonleaf baru.
Gabungkan halaman
DELETE Ketika operasi menghasilkan halaman yang memiliki kurang dari 10 persen dari ukuran halaman maksimum (saat ini 8 KB), atau dengan satu baris di dalamnya, halaman tersebut digabungkan dengan halaman yang berdekatan.
Saat baris dihapus dari halaman, catatan delta untuk penghapusan ditambahkan. Selain itu, pemeriksaan dilakukan untuk menentukan apakah halaman indeks (halaman nonleaf) memenuhi syarat untuk Penggabungan. Pemeriksaan ini memverifikasi apakah ruang yang tersisa setelah menghapus baris kurang dari 10 persen dari ukuran halaman maksimum. Jika memenuhi syarat, Penggabungan dilakukan dalam tiga langkah atom.
Dalam gambar berikut, asumsikan DELETE operasi menghapus nilai kunci 10.

Langkah 1: Halaman delta yang mewakili nilai 10 kunci (segitiga biru) dibuat dan penunjuknya di halaman Pp1 nonleaf diatur ke halaman delta baru. Selain itu, halaman merge-delta khusus (segitiga hijau) dibuat, dan ditautkan untuk menunjuk ke halaman delta. Pada tahap ini, kedua halaman (halaman delta dan halaman merge-delta) tidak terlihat oleh transaksi bersamaan. Dalam satu langkah atomik, penunjuk ke halaman P1 tingkat daun dalam tabel pemetaan halaman diperbarui untuk menunjuk ke halaman merge-delta. Setelah langkah ini, entri untuk nilai 10 kunci di Pp1 sekarang menunjuk ke halaman merge-delta.
Langkah 2: Baris yang mewakili nilai 7 kunci di halaman Pp1 nonleaf perlu dihapus, dan entri untuk nilai 10 kunci yang diperbarui untuk menunjuk ke P1. Untuk melakukan ini, halaman Pp2 nonleaf baru dialokasikan dan semua baris dari Pp1 disalin, kecuali untuk baris yang mewakili nilai 7kunci ; maka baris untuk nilai 10 kunci diperbarui untuk menunjuk ke halaman P1. Setelah ini selesai, dalam satu langkah atom, entri tabel pemetaan halaman yang menunjuk ke Pp1 diperbarui untuk menunjuk ke Pp2. Pp1 tidak lagi dapat dijangkau.
Langkah 3: Halaman tingkat P2 daun dan P1 digabungkan dan halaman delta dihapus. Untuk melakukan ini, halaman P3 baru dialokasikan dan baris dari P2 dan P1 digabungkan, dan perubahan halaman delta disertakan dalam baru P3. Kemudian, dalam satu langkah atomik, entri tabel pemetaan halaman yang menunjuk ke halaman P1 diperbarui untuk menunjuk ke halaman P3.
Pertimbangan performa
Performa indeks nonclustered lebih baik daripada indeks hash nonclustered saat mengkueri tabel yang dioptimalkan memori dengan predikat ketidaksamaan.
Kolom dalam tabel yang dioptimalkan memori dapat menjadi bagian dari indeks hash dan indeks nonclustered.
Saat kolom kunci dalam indeks yang tidak dikluster memiliki banyak nilai duplikat, performa dapat menurun untuk pembaruan, penyisipan, dan penghapusan. Salah satu cara untuk meningkatkan performa dalam situasi ini adalah dengan menambahkan kolom yang memiliki selektivitas yang lebih baik dalam kunci indeks.
Konten terkait
- BUAT INDEKS (Transact-SQL)
- Optimalkan pemeliharaan indeks untuk meningkatkan performa kueri dan mengurangi konsumsi sumber daya
- Tabel dan indeks yang dipartisi
- Indeks pada Tabel yang Dioptimalkan Memori
- Indeks Penyimpan Kolom: Ringkasan
- Indeks pada kolom komputasi
- Menyetel indeks non-kluster dengan saran indeks yang hilang