Jelaskan pemrosesan kueri cerdas
Pada SQL Server 2017 dan 2019, serta dengan Azure SQL, Microsoft telah memperkenalkan banyak fitur baru ke tingkat kompatibilitas 140 dan 150. Banyak dari fitur ini memperbaiki apa yang sebelumnya dianggap sebagai pola yang tidak disarankan, seperti penggunaan fungsi nilai skalar yang didefinisikan oleh pengguna dan penggunaan variabel tabel.
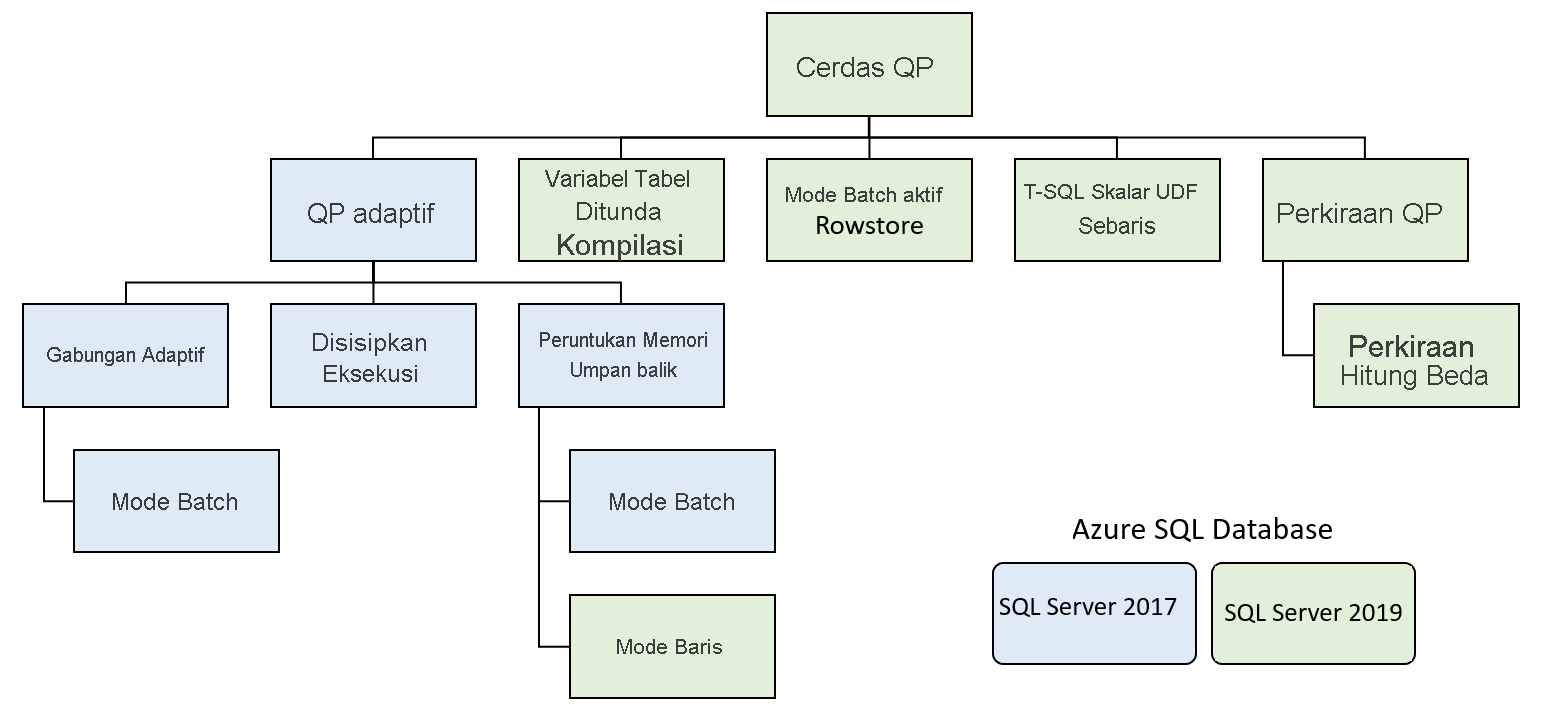
Fitur-fitur ini diuraikan menjadi beberapa kelompok fitur:
Pemrosesan kueri cerdas mencakup fitur yang meningkatkan performa beban kerja yang ada dengan upaya penerapan minimal.
Untuk membuat beban kerja secara otomatis memenuhi syarat untuk pemrosesan kueri cerdas, ubah tingkat kompatibilitas database yang berlaku menjadi 150. Contohnya:
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
Pemrosesan kueri adaptif
Pemrosesan kueri adaptif mencakup banyak opsi yang membuat pemrosesan kueri lebih dinamis, berdasarkan konteks eksekusi kueri. Opsi ini mencakup beberapa fitur yang meningkatkan pemrosesan kueri.
Gabungan Adaptif – mesin database menunda pilihan penggabungan antara hash dan perulangan berlapis berdasarkan jumlah baris yang masuk ke dalam gabungan. Gabungan adaptif saat ini hanya berfungsi dalam mode eksekusi batch.
Eksekusi Interleaved – Saat ini fitur ini mendukung fungsi bernilai tabel dengan banyak pernyataan (MSTVF). Sebelum SQL Server 2017, MSTVF menggunakan perkiraan baris tetap dari satu atau 100 baris, tergantung pada versi SQL Server. Perkiraan ini dapat menyebabkan rencana kueri suboptimal jika fungsi mengembalikan lebih banyak baris. Hitungan baris aktual dihasilkan dari MSTVF sebelum sisa rencana dikompilasi dengan eksekusi seling.
Umpan Balik Peruntukan Memori – SQL Server menghasilkan peruntukan memori dalam rencana awal kueri, berdasarkan perkiraan jumlah baris dari statistik. Kecenderungan data yang parah dapat menyebabkan perkiraan jumlah baris yang terlalu tinggi atau terlalu rendah, yang dapat menyebabkan pemberian memori berlebihan yang mengurangi konkurensi, atau pemberian yang kurang, yang dapat menyebabkan kueri menumpahkan data ke TempDB. Dengan umpan balik alokasi memori, SQL Server mendeteksi kondisi ini dan menyesuaikan jumlah memori yang diberikan ke kueri, baik dengan mengurangi atau menambahkannya, untuk menghindari pemborosan atau alokasi berlebih.
Semua fitur ini diaktifkan secara otomatis dalam mode kompatibilitas 150 dan tidak memerlukan perubahan lain untuk mengaktifkannya.
Kompilasi yang ditangguhkan variabel tabel
Seperti MSTVF, variabel tabel pada rencana eksekusi di SQL Server membawa perkiraan jumlah baris yang tetap satu baris. Sama seperti MSTVF, perkiraan tetap ini menyebabkan performa yang buruk ketika variabel memiliki jumlah baris yang lebih besar dari yang diharapkan. Dengan SQL Server 2019, variabel tabel sekarang dianalisis dan memiliki jumlah baris aktual. Kompilasi yang ditangguhkan mirip dengan eksekusi interleaved untuk MSTVF, kecuali bahwa hal itu dilakukan pada kompilasi pertama kueri alih-alih secara dinamis dalam rencana pelaksanaan.
Mode batch pada row store
Mode eksekusi batch memungkinkan data diproses dalam batch, bukan baris demi baris. Kueri yang dikenakan biaya CPU yang signifikan untuk perhitungan dan agregasi melihat manfaat terbesar dari model pemrosesan ini. Dengan memisahkan pemrosesan batch dan indeks penyimpanan kolom, lebih banyak beban kerja dapat memperoleh manfaat dari pemrosesan mode batch.
Penyisipan fungsi skalar yang ditentukan oleh pengguna
Pada versi SQL Server yang lebih lama, fungsi skalar berperforma buruk karena beberapa alasan. Fungsi skalar dieksekusi secara iteratif, secara efektif memproses satu baris dalam satu waktu. Mereka tidak memiliki estimasi biaya yang tepat dalam rencana eksekusi, dan mereka tidak mengizinkan paralelisme dalam rencana kueri. Dengan inlining fungsi yang ditentukan pengguna, fungsi-fungsi ini diubah menjadi subkueri skalar sebagai pengganti operator fungsi yang ditentukan pengguna dalam rencana eksekusi. Transformasi ini dapat menghasilkan peningkatan performa yang signifikan untuk kueri yang melibatkan panggilan fungsi skalar.
Perkiraan jumlah unik
Pola kueri gudang data yang umum adalah menghitung jumlah unik dari pesanan atau pengguna. Pola kueri ini dapat mahal untuk tabel besar. Perkiraan hitungan unik memperkenalkan pendekatan yang lebih cepat untuk mengumpulkan hitungan unik dengan mengelompokkan baris-baris. Fungsi ini menjamin tingkat kesalahan 2% dengan interval kepercayaan 97%.