Menggunakan Azure AI Speech to Text API
Layanan Azure AI Speech mendukung pengenalan ucapan melalui dua REST API:
- API Ucapan ke teks, yang merupakan cara utama untuk melakukan pengenalan ucapan.
- Api Audio Pendek Ucapan ke teks, yang dioptimalkan untuk aliran singkat audio (hingga 60 detik).
Anda dapat menggunakan salah satu API untuk pengenalan ucapan interaktif, bergantung pada durasi input lisan yang diharapkan. Anda juga dapat menggunakan API Ucapan ke teks untuk transkripsi batch, menerjemahkan beberapa file audio ke teks sebagai operasi batch.
Anda dapat mempelajari selengkapnya tentang REST API dalam dokumentasi REST API Ucapan ke teks. Dalam praktiknya, sebagian besar aplikasi interaktif yang mendukung ucapan menggunakan layanan Ucapan melalui SDK khusus bahasa (pemrograman).
Menggunakan Azure AI Speech SDK
Meskipun detail spesifik bervariasi, tergantung pada SDK yang digunakan (Python, C#, dan sebagainya); ada pola yang konsisten untuk menggunakan API Ucapan ke teks :
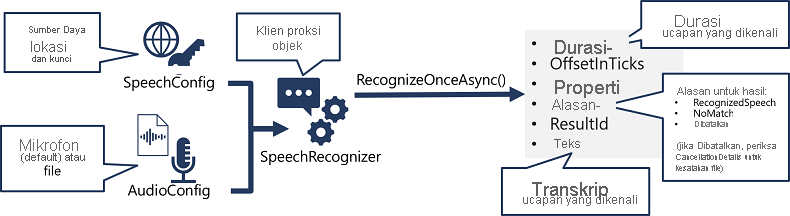
- Gunakan objek SpeechConfig untuk merangkum informasi yang diperlukan untuk menyambungkan ke sumber daya Azure AI Speech Anda. Khususnya, lokasi dan kuncinya.
- Secara opsional, gunakan AudioConfig untuk menentukan sumber input audio yang akan ditranskripsikan. Secara default, ini adalah mikrofon sistem default, tetapi Anda juga dapat menentukan file audio.
- Gunakan SpeechConfig dan AudioConfig untuk membuat objek SpeechRecognizer. Objek ini adalah klien proksi untuk API Ucapan ke teks .
- Gunakan metode objek SpeechRecognizer untuk memanggil fungsi API yang mendasarinya. Misalnya, metode RecognizeOnceAsync() menggunakan layanan Azure AI Speech untuk mentranskripsikan satu ucapan lisan secara asinkron.
- Proses respons dari layanan Azure AI Speech. Dalam kasus metode RecognizeOnceAsync(), hasilnya adalah objek SpeechRecognitionResult yang mencakup properti berikut:
- Durasi
- OffsetInTicks
- Properti
- Alasan
- ResultId
- Teks
Jika operasi berhasil, properti Reason memiliki nilai enumerasi RecognizedIntent, dan properti Text berisi transkripsi. Nilai lain yang mungkin untuk Hasil termasuk NoMatch (menunjukkan bahwa audio berhasil diurai tetapi tidak ada ucapan yang dikenali) atau Dibatalkan, yang menunjukkan bahwa terjadi kesalahan (dalam hal ini, Anda dapat memeriksa kumpulan Properti untuk properti CancellationReason untuk menentukan apa yang salah).