Indeks tabel
Penyempitan performa dapat muncul karena lebih banyak pengguna mengakses aplikasi dan data dalam database. Untuk menjaga kepuasan pengguna tetap tinggi dan mendorong kunjungan berulang, pengoptimalan database harus dimulai dengan desain tabel awal.
Ribuan orang di seluruh dunia akan menggunakan aplikasi referensi kartu online dalam skenario kami. Karena permintaan ini, Anda perlu memastikan bahwa kueri terhadap data pengembalian database secepat mungkin. Untuk membantu mencegah penyempitan performa aplikasi, Anda dapat menempatkan indeks pada kolom atau set pada kolom pada tabel.
Unit ini akan memberi Anda gambaran umum indeks tabel untuk membantu Anda memutuskan mana yang akan digunakan dan kapan menggunakannya pada tabel dan di aplikasi Anda.
Merancang indeks tabel
Ketika seseorang memikirkan indeks kata, biasanya indeks di bagian belakang buku muncul dalam pikiran; gambaran umum lengkap teks dalam buku dan tempat menemukan kata dan topik utama. Indeks pada tabel di Azure SQL mirip dengan indeks di bagian belakang buku. Indeks membantu Anda masuk ke baris yang Anda cari dengan cepat dengan menyediakan peta database tempatnya berada. Jika Anda ingat, tabel disimpan di halaman di Azure SQL Database, dan indeks membantu database menemukan data yang Anda inginkan dalam halaman ini dengan cepat. Indeks itu sendiri juga disimpan di halaman, yang disebut Halaman Indeks.
Bergantung pada kasus penggunaan atau beban kerja aplikasi Anda, ada beberapa pilihan yang harus dibuat pada jenis indeks. Jika Anda perlu menemukan informasi tentang baris atau informasi tertentu di dalam baris tertentu (pikirkan nama kartu dalam skenario), indeks rowstore akan paling cocok di sini. Jika beban kerja didasarkan pada kueri analitik besar pada gudang data, kami akan merekomendasikan indeks penyimpan kolom.
Membuat tabel tanpa indeks menyebabkan tabel disimpan sebagai struktur tumpukan; tidak ada pengurutan data. Bayangkan skenario dengan dek kartu yang tidak terurai. Tidak memiliki indeks yang berfungsi dengan baik untuk tabel yang digunakan terutama untuk sisipan data/baris, karena tidak ada overhead dengan mencari baris pada saat ini. Dengan dek kartu imajiner, rasanya seperti hanya menambahkan kartu di bagian atas tumpukan; cepat dan mudah, jika itu yang Anda tetapkan untuk dilakukan. Tapi bayangkan mencoba mencari satu baris dalam tabel satu juta rekaman, atau kartu individu di tumpukan kartu imajiner. Seiring bertambahnya data (atau tumpukan kartu), Anda akan memerlukan beberapa cara untuk mengambil informasi dan mengirimkannya kembali kepada pengguna secepat mungkin.
Memahami indeks rowstore
Ada dua jenis indeks rowstore berbasis disk yang digunakan dengan Azure SQL Database: berkluster dan non-kluster. Indeks berkluster mengurutkan dan menyimpan baris data dalam tabel berdasarkan nilai kuncinya, biasanya kunci primer. Saat baris ditulis ke tabel dengan indeks berkluster, baris diurutkan dan ditempatkan dalam penyimpanan dalam urutan yang benar. Pikirkan kamus atau ensiklopedia dan ketika entri baru ditambahkan. Indeks berkluster akan mengurutkan dan menyimpan data baris lengkap di halaman yang benar pada disk (ingat bagaimana tabel disimpan di halaman pada disk). Karena indeks berkluster menentukan bagaimana data akan disimpan pada disk di halaman, hanya boleh ada satu indeks berkluster pada tabel. Tidak mungkin untuk mengurutkan dan menyimpan beberapa kolom dalam satu halaman. Cobalah untuk mengurutkan buku alamat Anda berdasarkan nama belakang orang dan status secara bersamaan; itu satu atau yang lain. Bahkan, saat Anda membuat kunci utama pada tabel, Azure SQL Database secara otomatis membuat indeks berkluster pada tabel untuk Anda.
Indeks nonclustered membuat struktur terpisah untuk mengurutkan data dalam tabel, lalu menggunakan pencari baris untuk menunjuk kembali ke baris yang berisi informasi yang Anda cari. Anda dapat memikirkan perbedaan antara indeks berkluster dan non-kluster dengan contoh ini: indeks berkluster mirip dengan bagaimana kamus memiliki kata-kata yang diurutkan menurut abjad pada halaman dengan definisi dan pengucapan semuanya di tempat yang sama; indeks non-kluster seperti indeks kamus, memperlihatkan penunjuk (nomor halaman) ke tempat Anda dapat menemukan kata dan definisi tersebut.
Memahami indeks penyimpan kolom
Indeks penyimpan kolom memberikan manfaat performa besar untuk kueri analitik dan penghematan penyimpanan dari kompresi yang digunakannya. Indeks penyimpan kolom berfungsi dengan menyimpan data dalam kolom alih-alih baris dan menempatkan setiap kolom di halaman terpisah di server database. Dalam skenario kartu, bayangkan menempatkan indeks penyimpan kolom pada tabel kartu utama. Kemudian akan membagi setiap kolom menjadi halaman dan memiliki halaman untuk nama kartu, warna kartu, jenis kartu, dan sebagainya.
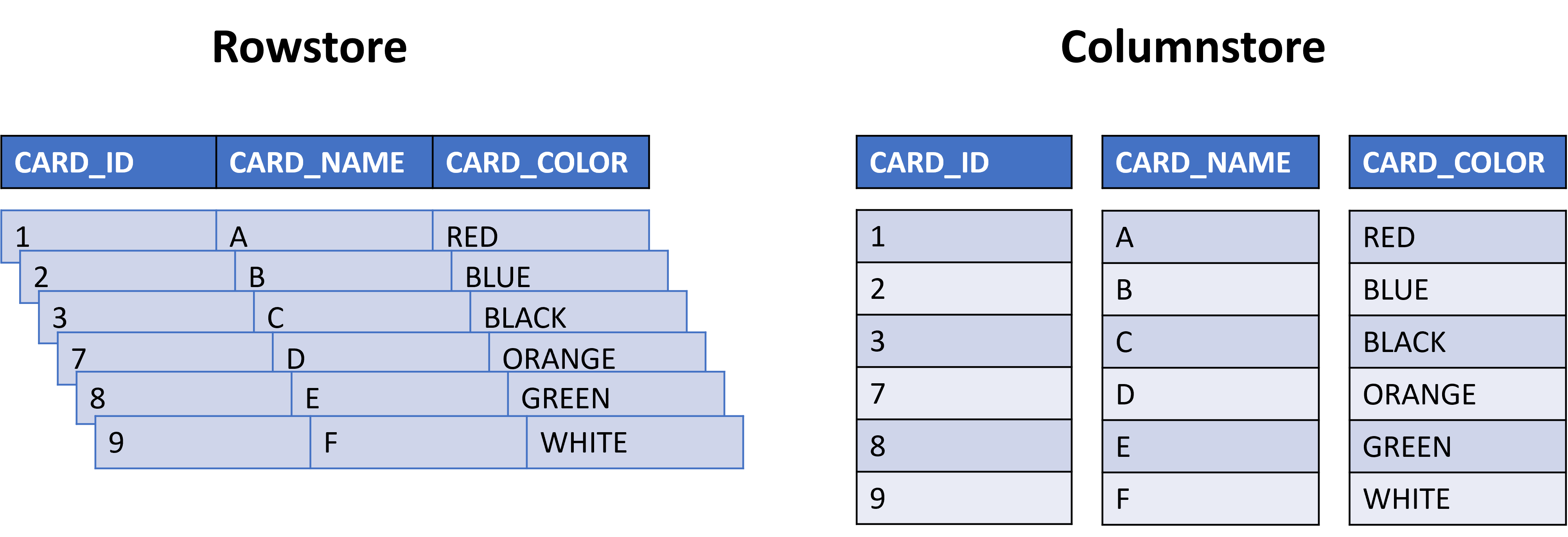
Indeks penyimpan kolom, seperti indeks rowstore, hadir sebagai terkluster dan tidak terkluster. Sama seperti indeks rowstore, indeks penyimpan kolom berkluster akan mengurutkan data saat disimpan di halaman. Indeks penyimpan kolom noncluster adalah penunjuk ke tempat baris disimpan di halaman. Pikirkan kembali ke contoh kamus yang membandingkan entri kata pada halaman dan indeks di bagian belakang buku. Indeks penyimpan kolom berkluster akan memiliki kata-kata yang diurutkan menurut abjad pada halaman dengan definisi dan pengucapan. Indeks penyimpan kolom non-kluster seperti indeks kamus; memperlihatkan penunjuk (nomor halaman) ke tempat Anda dapat menemukan kata dan definisi tersebut.
Catatan
Ingat, tabel hanya dapat memiliki satu indeks berkluster, baik itu penyimpan kolom atau rowstore, tetapi Anda dapat memiliki indeks penyimpan kolom non-kluster pada tabel dengan indeks rowstore berkluster jika Anda memiliki tabel yang digunakan untuk penyisipan data dan kueri analitik.
Kapan menggunakan indeks penyimpan kolom
Anda akan menemukan indeks penyimpan kolom di gudang data dan skenario analitik. Di sini, di gudang data/ruang analitik, orang data umumnya mencari bukan satu baris, melainkan tren, rentang, dan agregasi di seluruh kolom tertentu. Dengan menyimpan data sebagai kolom, database dapat melihat rentang dengan lebih mudah (seperti nilai min/maks) dan hanya mengambil halaman data untuk kolom dalam kueri.
Perolehan performa untuk kueri analitik berasal dari bagaimana data diambil dari database. Dengan rowstore, jika seseorang mencari tren atau nilai min/maks di kolom tertentu, database akan mengambil semua halaman dalam penyimpanan untuk baris yang diperlukan untuk kueri. Melihat tabel kartu, katakanlah Anda ingin menemukan daya kartu rata-rata di seluruh set. Indeks rowstore akan mengembalikan keempat halaman dengan semua kolom, meskipun Anda hanya menginginkan daya kartu.
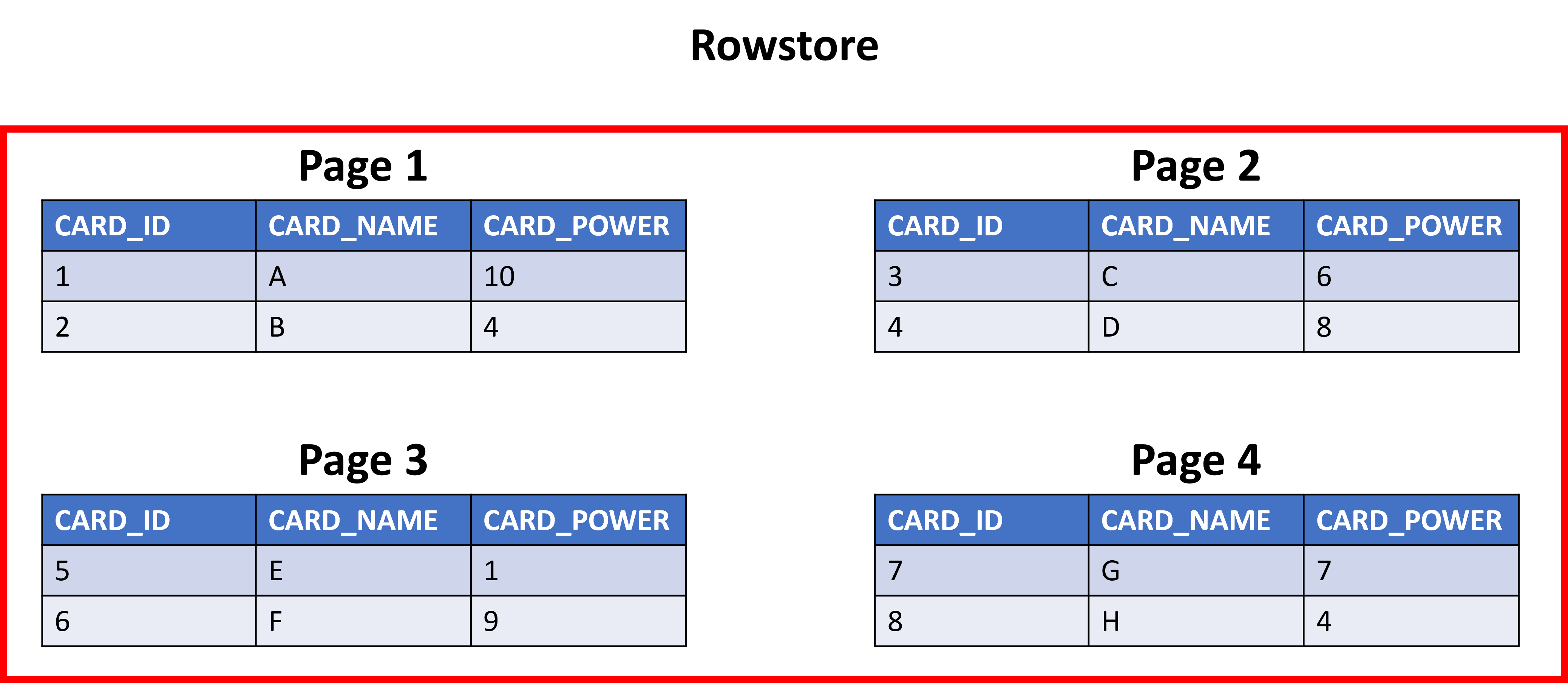
Sekarang, jika Anda menggunakan indeks penyimpan kolom, Anda hanya akan mengambil halaman yang menyimpan daya kartu dan mengabaikan data lainnya, mempercepat waktu kueri.
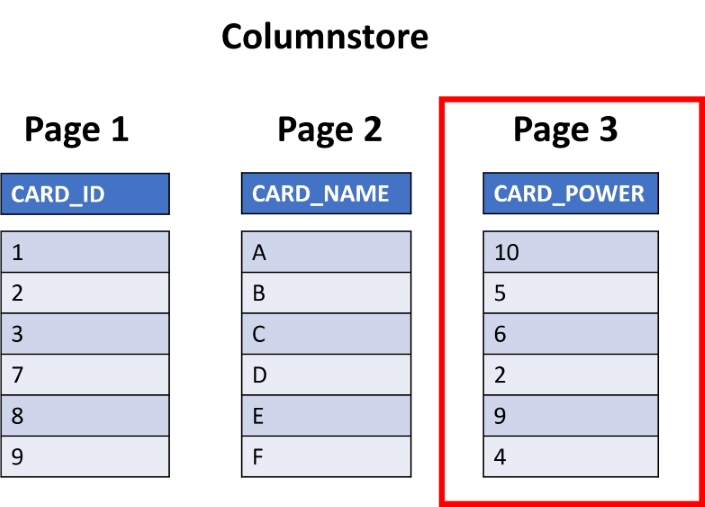
Dalam aplikasi referensi online, Anda akan mengembalikan semua data dalam baris, sehingga indeks penyimpan kolom tidak akan sesuai untuk kasus penggunaan tersebut.
Indeks teks lengkap
Bukankah itu fitur yang baik dalam aplikasi referensi kartu jika pengguna dapat memasukkan beberapa teks dan kemudian mengembalikan semua hasil yang cocok? Mungkin fitur ini juga dapat memperhitungkan kesalahan ejaan dan mengabaikan sensitivitas kasus? Azure SQL Database memiliki indeks pencarian teks lengkap yang memungkinkan pengguna dan aplikasi menjalankan kueri teks lengkap terhadap kolom berbasis karakter, yang berguna untuk kolom card_name dan card_text . Kita dapat menerapkan indeks teks lengkap ke kolom yang memiliki salah satu jenis data berikut: char, , , textntextncharvarcharnvarchar, , image, xml, atau .FILESTREAMvarbinary(max)