Menjelaskan normalisasi
Normalisasi database adalah proses desain yang digunakan untuk menata set data tertentu ke dalam tabel dan kolom dalam database. Setiap tabel harus berisi data yang berkaitan dengan 'hal' tertentu dan hanya memiliki data yang mendukung 'hal' yang sama yang disertakan dalam tabel. Tujuan dari proses ini adalah untuk mengurangi data duplikat yang terkandung dalam database Anda, untuk mengurangi penurunan performa sisipan dan pembaruan database. Misalnya, perubahan alamat pelanggan jauh lebih mudah diterapkan jika satu-satunya tempat alamat pelanggan disimpan ada di tabel Pelanggan. Bentuk normalisasi yang paling umum adalah bentuk normal pertama, kedua, dan ketiga yang dijelaskan di bawah ini.
Bentuk normal pertama
Bentuk normal pertama memiliki spesifikasi berikut:
- Membuat tabel terpisah untuk setiap set data terkait
- Menghilangkan grup berulang dalam tabel individual
- Mengidentifikasi setiap set data terkait dengan kunci primer
Dalam model ini, Anda tidak boleh menggunakan beberapa kolom dalam satu tabel untuk menyimpan data serupa. Misalnya, jika produk dapat datang dalam beberapa warna, Anda tidak boleh memiliki beberapa kolom dalam satu baris yang berisi nilai warna yang berbeda. Tabel pertama, di bawah ini (ProductColors), tidak dalam bentuk normal pertama karena ada nilai berulang untuk warna. Untuk produk dengan hanya satu warna, ada ruang yang terbuang. Dan bagaimana jika suatu produk memiliki lebih dari tiga warna? Daripada harus mengatur jumlah warna maksimum, kita dapat membuat ulang tabel seperti yang ditunjukkan pada tabel kedua, ProductColor. Kami juga memiliki persyaratan untuk bentuk normal pertama bahwa ada kunci unik untuk tabel, yaitu kolom (atau kolom) yang nilainya secara unik mengidentifikasi baris. Tidak satu pun dari kolom dalam tabel kedua bersifat unik, tetapi bersama-sama, kombinasi ProductID dan Color bersifat unik. Ketika beberapa kolom diperlukan, kami menyebutnya kunci komposit.
| ProductID | Color1 | Color2 | Color3 |
|---|---|---|---|
| 1 | Merah | Hijau | Kuning |
| 2 | Kuning | ||
| 3 | Biru | Merah | |
| 4 | Biru | ||
| 5 | Merah |
| ProductID | Warna |
|---|---|
| 1 | Merah |
| 1 | Hijau |
| 1 | Kuning |
| 2 | Kuning |
| 3 | Biru |
| 3 | Merah |
| 4 | Biru |
| 5 | Merah |
Tabel ketiga, ProductInfo, dalam bentuk normal pertama karena setiap baris mengacu pada produk tertentu, tidak ada grup berulang, dan kita memiliki kolom ProductID untuk digunakan sebagai Kunci Primer.
| ProductID | ProductName | Harga | ProductionCountry | ShortLocation |
|---|---|---|---|---|
| 1 | Widget | 15,95 | Amerika Serikat | US |
| 2 | Foop | 41,95 | Inggris Raya | Inggris |
| 3 | Glombit | 49,95 | Inggris Raya | Inggris |
| 4 | Sorfin | 99,99 | Republik Filipina | RepPhil |
| 5 | Baut Batang | 29,95 | Amerika Serikat | US |
Bentuk normal kedua
Bentuk normal kedua memiliki spesifikasi berikut, selain spesifikasi yang diperlukan oleh bentuk normal pertama:
- Jika tabel memiliki kunci komposit, semua atribut harus bergantung pada kunci lengkap dan bukan hanya bagian darinya.
Bentuk normal kedua hanya relevan dengan tabel dengan kunci komposit, seperti dalam tabel ProductColor, yang merupakan tabel kedua di atas. Pertimbangkan kasus di mana tabel ProductColor juga menyertakan harga produk. Tabel ini memiliki kunci komposit pada ProductID dan Color, karena hanya dengan menggunakan kedua nilai kolom, kita dapat mengidentifikasi baris secara unik. Jika harga produk tidak berubah dengan warna, kita mungkin melihat data seperti yang ditunjukkan dalam tabel ini:
| ProductID | Warna | Harga |
|---|---|---|
| 1 | Merah | 15,95 |
| 1 | Hijau | 15,95 |
| 1 | Kuning | 15,95 |
| 2 | Kuning | 41,95 |
| 3 | Biru | 49,95 |
| 3 | Merah | 49,95 |
| 4 | Biru | 99,95 |
| 5 | Merah | 29,95 |
Tabel di atas tidak dalam bentuk normal kedua. Nilai harga tergantung pada ProductID tetapi tidak pada Color. Ada tiga baris untuk ProductID 1, sehingga harga untuk produk itu diulang tiga kali. Jika melanggar bentuk normal kedua, masalah yang timbul adalah bahwa jika kita harus memperbarui harganya, kita harus memastikan kita memperbaruinya di semua baris. Jika kita memperbarui harga di baris pertama, tetapi bukan yang kedua atau ketiga, kita akan memiliki sesuatu yang disebut 'anomali pembaruan'. Setelah pembaruan, kita tidak akan dapat mengetahui berapa harga sebenarnya untuk ProductID 1. Solusinya adalah memindahkan kolom Harga ke tabel yang memiliki ProductID sebagai kunci kolom tunggal, karena itu adalah satu-satunya kolom yang bergantung pada Harga. Misalnya, kita dapat menggunakan Tabel 3 untuk menyimpan Harga.
Jika harga untuk produk berbeda berdasarkan warnanya, tabel keempat akan berada dalam bentuk normal kedua, karena harga akan tergantung pada kedua bagian kunci: ProductID dan Color.
Bentuk normal ketiga
Bentuk normal ketiga biasanya merupakan tujuan untuk sebagian besar database OLTP. Bentuk normal ketiga memiliki spesifikasi berikut, selain spesifikasi yang diperlukan oleh bentuk normal kedua:
- Semua kolom non-kunci tidak bergantung pada kunci primer.
Hubungan transitif menyiratkan bahwa satu kolom dalam tabel terkait dengan kolom lain, melalui kolom kedua. Dependensi berarti bahwa kolom dapat memperoleh nilainya dari yang lain, sebagai akibat dari dependensi. Misalnya, usia Anda dapat ditentukan sejak tanggal lahir Anda, sehingga usia Anda tergantung pada tanggal lahir Anda. Lihat kembali tabel ketiga, ProductInfo. Tabel ini dalam bentuk normal kedua, tetapi tidak di bentuk normal ketiga. Kolom ShortLocation bergantung pada kolom ProductionCountry, yang bukan kuncinya. Seperti bentuk normal kedua, melanggar bentuk normal ketiga dapat menyebabkan anomali pembaruan. Kami akan berakhir dengan data yang tidak konsisten jika kami memperbarui ShortLocation dalam satu baris tetapi tidak memperbaruinya di semua baris tempat lokasi tersebut terjadi. Untuk mencegah hal ini, kita dapat membuat tabel terpisah untuk menyimpan nama negara/wilayah dan formulir yang dipersingkat.
Denormalisasi
Meskipun bentuk normal ketiga secara teoritis diinginkan, bentuk normal ketiga tidak selalu memungkinkan untuk semua data. Selain itu, database yang dinormalisasi tidak selalu memberi Anda performa terbaik. Data yang dinormalisasi sering memerlukan beberapa operasi gabungan agar semua data yang diperlukan ditampilkan dalam satu kueri. Ada tradeoff antara menormalkan data ketika jumlah gabungan yang diperlukan untuk mengembalikan hasil kueri memiliki pemanfaatan CPU yang tinggi, dan data denormalisasi yang memiliki lebih sedikit gabungan dan lebih sedikit CPU yang diperlukan, tetapi membuka kemungkinan anomali pembaruan.
Catatan
Data yang didenormalisasi tidak sama dengan yang belum dinormalisasi. Untuk denormalisasi, kita mulai dengan merancang tabel yang dinormalisasi. Kemudian kita dapat menambahkan kolom tambahan ke beberapa tabel untuk mengurangi jumlah gabungan yang diperlukan, tetapi seperti yang kita lakukan, kita menyadari kemungkinan anomali pembaruan. Kita kemudian memastikan kita memiliki pemicu atau jenis pemrosesan lain yang akan memastikan bahwa ketika kita melakukan pembaruan, semua data duplikat juga diperbarui.
Data yang didenormalisasi bisa lebih efisien untuk dikueri, terutama untuk membaca beban kerja berat seperti gudang data. Dalam kasus tersebut, memiliki kolom tambahan dapat menawarkan pola kueri yang lebih baik dan/atau kueri yang lebih sederhana.
Skema bintang
Sementara sebagian besar normalisasi ditujukan untuk beban kerja OLTP, gudang data memiliki struktur pemodelan sendiri, yang biasanya merupakan model didenormalisasi. Desain ini menggunakan tabel fakta, yang mencatat pengukuran atau metrik untuk kejadian tertentu seperti penjualan, dan menggabungkannya ke tabel dimensi, yang lebih kecil dalam hal jumlah baris, tetapi mungkin memiliki banyak kolom untuk menggambarkan data fakta. Beberapa dimensi contoh akan mencakup inventaris, waktu, dan/atau geografi. Pola desain ini digunakan untuk membuat database lebih mudah dikueri dan menawarkan keuntungan performa untuk beban kerja baca.
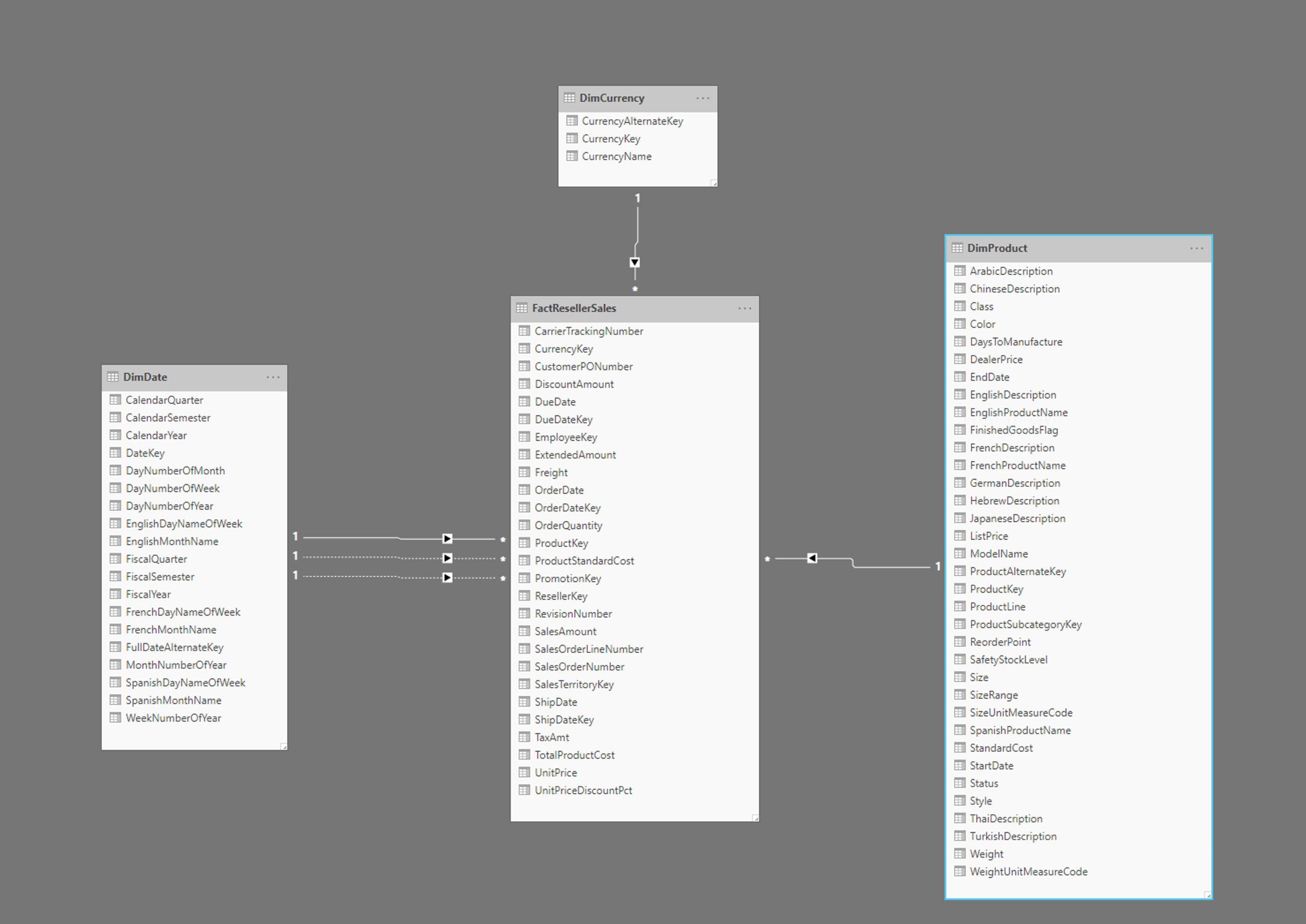
Gambar di atas menunjukkan contoh skema bintang, termasuk tabel fakta FactResellerSales, dan dimensi untuk tanggal, mata uang, dan produk. Tabel fakta berisi data yang terkait dengan transaksi penjualan dan dimensi hanya berisi data yang terkait dengan elemen tertentu dari data penjualan. Misalnya, tabel FactResellerSales hanya berisi ProductKey untuk menunjukkan produk mana yang dijual. Semua detail tentang setiap produk disimpan dalam tabel DimProduct , dan terkait kembali ke tabel fakta dengan kolom ProductKey .
Terkait dengan desain skema bintang adalah skema snowflake, yang menggunakan satu set tabel yang lebih dinormalisasi untuk satu entitas bisnis. Gambar berikut menunjukkan contoh dimensi tunggal untuk skema snowflake. Dimensi Produk dinormalisasi dan disimpan dalam tiga tabel yang disebut DimProductCategory, DimProductSubcategory, dan DimProduct.
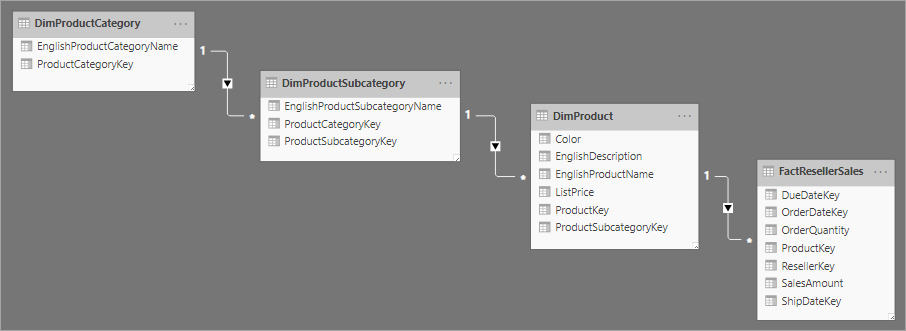
Perbedaan utama antara skema bintang dan snowflake adalah bahwa dimensi dalam skema snowflake dinormalisasi untuk mengurangi redundansi, yang menghemat ruang penyimpanan. Untung-ruginya adalah bahwa kueri Anda memerlukan lebih banyak gabungan, sehingga dapat meningkatkan kompleksitas dan mengurangi performa.