Indeks desain
SQL Server memiliki beberapa jenis indeks untuk mendukung berbagai jenis beban kerja. Pada tingkat tinggi, indeks dapat dianggap sebagai struktur on-disk yang berkaitan dengan tabel atau tampilan, yang memungkinkan SQL Server untuk lebih mudah menemukan baris atau baris yang terkait dengan kunci indeks (yang terdiri dari satu kolom atau lebih dalam tabel atau tampilan), dibandingkan dengan memindai seluruh tabel.
Indeks berkluster
Pertanyaan wawancara kerja DBA yang umum adalah menanyakan kandidat perbedaan antara indeks berkluster dan non-kluster, karena indeks adalah teknologi penyimpanan data mendasar di SQL Server. Indeks berkluster adalah tabel dasar, yang disimpan dalam urutan tersortir berdasarkan nilai kunci. Hanya ada satu indeks berkluster pada tabel tertentu, karena baris dapat disimpan dalam satu urutan. Tabel tanpa indeks berkluster disebut heap atau tumpukan dan tumpukan biasanya hanya digunakan sebagai tabel pentahapan. Prinsip desain performa yang penting adalah menjaga kunci indeks berkluster Anda sedetail mungkin. Saat mempertimbangkan kolom kunci untuk indeks berkluster, Anda harus mempertimbangkan kolom yang unik atau yang berisi banyak nilai berbeda. Properti lain dari kunci indeks berkluster yang baik adalah untuk rekaman yang diakses secara berurutan dan sering digunakan untuk mengurutkan data yang diambil dari tabel. Memiliki indeks berkulster pada kolom yang digunakan untuk pengurutan dapat mencegah biaya pengurutan setiap kali kueri dijalankan, karena data akan sudah disimpan dalam urutan yang diinginkan.
Catatan
Ketika kita mengatakan bahwa tabel 'disimpan' dalam urutan tertentu, kita mengacu pada urutan logis, belum tentu urutan fisik, on-disk. Indeks memiliki pointer di antara halaman dan pointer membantu membuat urutan logika. Saat memindai indeks 'secara berurutan', SQL Server mengikuti pointer dari halaman ke halaman. Segera setelah membuat indeks, kemungkinan besar juga disimpan dalam urutan fisik pada disk, tetapi setelah Anda mulai membuat modifikasi pada data, dan halaman baru perlu ditambahkan ke indeks, pointer masih akan memberikan urutan logis yang benar, tetapi halaman barunya kemungkinan besar tidak berada dalam urutan disk fisik.
Indeks non-kluster
Indeks non-kluster adalah struktur terpisah dari baris data. Indeks non-kluster berisi nilai kunci yang ditentukan untuk indeks dan pointer ke baris data yang berisi nilai kunci. Anda dapat menambahkan kolom non-kunci lain ke tingkat daun indeks nonclustered untuk mencakup lebih banyak kolom menggunakan fitur kolom yang disertakan di SQL Server. Anda dapat membuat beberapa indeks non-kluster pada sebuah tabel.
Contoh kapan Anda perlu menambahkan indeks atau menambahkan kolom ke indeks non-kluster yang ada diperlihatkan di bawah ini:

Rencana kueri menunjukkan bahwa untuk setiap baris yang diambil menggunakan pencarian indeks, lebih banyak data perlu diambil dari indeks berkluster (tabel itu sendiri). Ada indeks nonkluster, tetapi hanya menyertakan kolom produk. Jika Anda menambahkan kolom lain dalam kueri ke indeks non-kluster seperti yang diperlihatkan di bawah ini, Anda bisa melihat perubahan rencana eksekusi untuk menghilangkan pencarian kunci.

Indeks yang dibuat di atas adalah contoh indeks yang mencakup, di mana selain kolom kunci Anda menyertakan kolom tambahan untuk mencakup kueri dan menghilangkan kebutuhan untuk mengakses tabel itu sendiri.
Indeks non-kluster dan berkluster dapat didefinisikan sebagai unik, yang berarti tidak ada duplikasi nilai kunci. Indeks unik secara otomatis dibuat saat Anda membuat KUNCI PRIMER atau batasan UNIK pada tabel.
Fokus bagian ini adalah pada indeks b-tree di SQL Server—hal ini juga dikenal sebagai indeks penyimpanan baris. Struktur umum b-tree ditunjukkan di bawah ini:
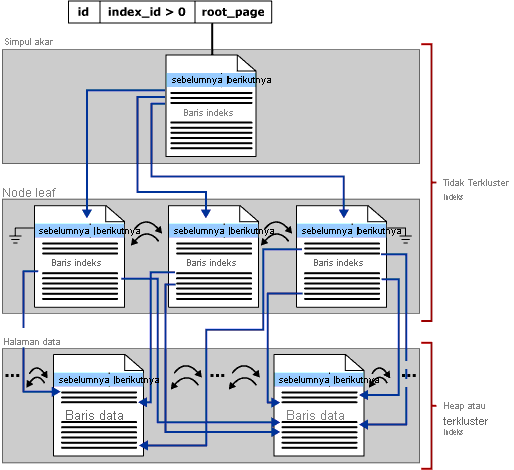
Setiap halaman dalam indeks b-tree adalah yang disebut node indeks dan node atas b-tree disebut node akar. Node bawah dalam indeks disebut node daun dan kumpulan node daun disebut tingkat daun.
Desain indeks adalah campuran seni dan sains. Indeks sempit dengan beberapa kolom di kuncinya membutuhkan lebih sedikit waktu untuk diperbarui dan memiliki overhead pemeliharaan yang lebih rendah. Namun, indeks ini mungkin tidak berguna untuk kueri yang banyak sebagaimana indeks luas yang menyertakan lebih banyak kolom. Anda mungkin perlu bereksperimen dengan beberapa pendekatan pengindeksan berdasarkan kolom yang dipilih oleh kueri aplikasi Anda. Pengoptimal kueri umumnya akan memilih apa yang dianggap sebagai indeks terbaik yang ada untuk kueri; namun, itu tidak berarti bahwa tidak ada indeks yang lebih baik yang dapat dibangun.
Mengindeks database dengan benar adalah tugas yang kompleks. Saat merencanakan indeks Anda untuk tabel, Anda harus mengingat beberapa prinsip dasar:
- Memahami beban kerja sistem. Tabel yang digunakan terutama untuk operasi penyisipan akan mendapat manfaat jauh lebih sedikit dari indeks tambahan daripada tabel yang digunakan untuk operasi gudang data yang merupakan aktivitas baca 90%.
- Pahami kueri apa yang paling sering dijalankan, dan optimalkan indeks Anda di sekitar kueri tersebut.
- Memahami tipe data kolom yang digunakan dalam kueri Anda. Indeks ideal untuk tipe data bilangan bulat atau kolom unik atau bukan null.
- Buat indeks non-kluster pada kolom yang sering digunakan dalam klausul predikat dan gabungan, dan buat indeks tersebut sesempit mungkin untuk menghindari overhead.
- Pahami ukuran/volume data Anda – Pemindaian tabel pada tabel kecil akan menjadi operasi yang relatif murah dan SQL Server dapat memutuskan untuk melakukan pemindaian tabel hanya karena mudah (sepele) untuk dilakukan. Pemindaian tabel pada tabel besar akan mahal.
Opsi lain yang disediakan SQL Server adalah pembuatan indeks yang difilter. Indeks yang difilter paling cocok untuk kolom dalam tabel besar di mana persentase besar baris memiliki nilai yang sama di kolom tersebut. Contoh praktis adalah tabel karyawan, seperti yang ditunjukkan di bawah ini, yang menyimpan catatan semua karyawan, termasuk yang telah pergi atau pensiun.
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
Dalam tabel ini, ada kolom yang disebut CurrentFlag, yang menunjukkan apakah karyawan saat ini dipekerjakan. Contoh ini menggunakan jenis data bit, yang menunjukkan hanya dua nilai, satu untuk yang saat ini digunakan dan nol untuk yang saat ini tidak digunakan. Indeks yang difilter dengan WHERE CurrentFlag = 1, pada kolom CurrentFlag akan memungkinkan kueri karyawan saat ini yang efisien.
Anda juga bisa membuat indeks pada tampilan, yang bisa memberikan perolehan performa yang signifikan saat tampilan berisi elemen kueri seperti agregasi dan/atau gabungan tabel.
Panduan Indeks Penyimpan Kolom
Columnstore menawarkan peningkatan performa untuk kueri yang menjalankan beban kerja agregasi besar. Jenis indeks ini awalnya ditargetkan pada gudang data, tetapi seiring waktu indeks penyimpan kolom telah digunakan dalam banyak beban kerja lain untuk membantu menyelesaikan masalah performa kueri pada tabel besar. Pada SQL Server 2014, ada indeks penyimpan kolom non-kluster dan berkluster. Seperti indeks b-tree, indeks penyimpan kolom berkluster adalah tabel itu sendiri disimpan dengan cara khusus, dan indeks penyimpan kolom non-kluster disimpan secara independen dari tabel. Indeks penyimpanan kolom berkluster secara inheren menyertakan semua kolom dalam tabel tertentu. Namun, tidak seperti indeks penyimpanan baris berkluster, indeks penyimpanan kolom berkluster TIDAK diurutkan.
Indeks penyimpan kolom non-kluster biasanya digunakan dalam dua skenario, yang pertama adalah ketika kolom dalam tabel memiliki tipe data yang tidak didukung dalam indeks penyimpan kolom. Sebagian besar jenis data didukung tetapi XML, CLR, sql_variant, ntext, teks, dan gambar tidak didukung dalam indeks penyimpan kolom. Karena penyimpanan berkluster selalu berisi semua kolom tabel (karena ia memang tabel), maka satu-satunya opsi adalah penyimpanan kolom non-kluster. Skenario kedua adalah indeks yang difilter—skenario ini digunakan dalam arsitektur yang disebut pemrosesan analitik transaksional hibrida (HTAP). Dalam skenario ini, data dimuat ke dalam tabel yang mendasarinya dan pada saat yang sama laporan dijalankan di tabel. Dengan memfilter indeks (biasanya pada bidang tanggal), desain ini memungkinkan performa penyisipan dan pelaporan yang baik.
Indeks penyimpanan kolom bersifat unik dalam mekanisme penyimpanannya, yakni setiap kolom dalam indeks disimpan secara independen. Ini menawarkan manfaat dua kali lipat. Kueri yang menggunakan indeks penyimpan kolom hanya perlu memindai kolom yang diperlukan untuk memenuhi kueri, mengurangi total IO yang dilakukan, dan memungkinkan pemadatan yang lebih besar, karena data di kolom yang sama kemungkinan mirip secara alami.
Indeks penyimpanan kolom melakukan performa terbaik pada kueri analitik yang memindai data dalam jumlah besar, seperti tabel fakta di gudang data. Dimulai dengan SQL Server 2016 Anda dapat menambah indeks penyimpan kolom dengan indeks nonclustered b-tree lainnya, yang dapat membantu jika beberapa kueri Anda melakukan pencarian terhadap nilai singleton.
Indeks penyimpanan kolom juga mendapat keuntungan dari mode eksekusi batch, yang mengacu pada pemrosesan satu set baris (biasanya sekitar 900) sekaligus versus mesin database yang memproses baris tersebut satu per satu. Alih-alih memuat setiap rekaman secara independen dan memprosesnya, mesin kueri melakukan komputasi penghitungan dalam grup 900 rekaman itu. Model pemrosesan ini mengurangi jumlah instruksi CPU secara signifikan.
SELECT SUM(Sales) FROM SalesAmount;
Mode batch dapat memberikan peningkatan performa yang signifikan dibandingkan pemrosesan baris tradisional. SQL Server 2019 juga menyertakan mode batch untuk data penyimpanan baris. Meskipun mode batch untuk rowstore tidak memiliki tingkat performa baca yang sama dengan indeks penyimpan kolom, kueri analitik mungkin melihat peningkatan performa hingga 5x.
Keuntungan lain yang ditawarkan indeks penyimpanan untuk beban kerja gudang data adalah jalur beban yang dioptimalkan untuk operasi penyisipan massal 102.400 baris atau lebih. 102.400 adalah nilai minimum untuk dimuat langsung ke penyimpanan kolom. Namun, setiap koleksi baris, yang disebut grup baris, bisa memuat hingga sekitar 1.024.000 baris. Memiliki lebih sedikit grup baris, tetapi lebih penuh, membuat kueri SELECT menjadi lebih efisien. Hal ini dikarenakan ada lebih sedikit grup baris yang perlu dipindai untuk mengambil rekaman yang diminta. Beban ini berada dalam memori dan langsung dimuat ke indeks. Untuk volume yang lebih kecil, data ditulis ke struktur b-tree yang disebut penyimpanan delta, dan dimuat secara asinkron ke dalam indeks.
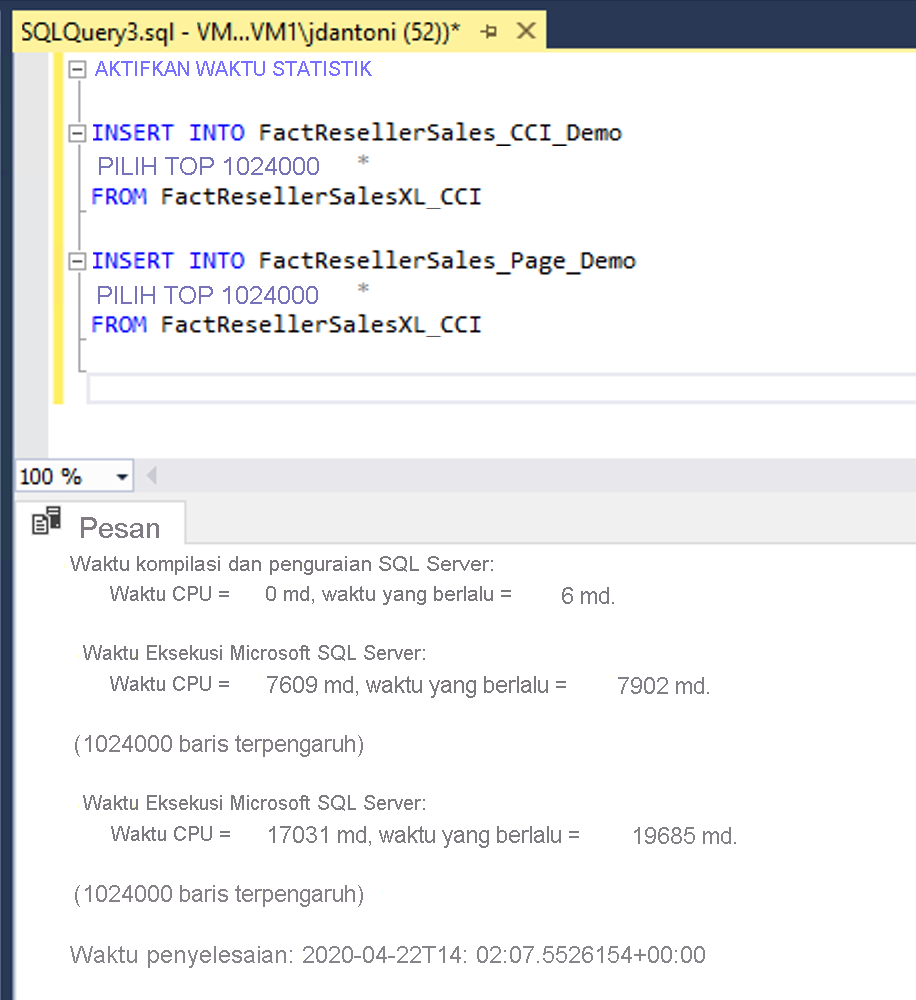
Dalam contoh ini, data yang sama sedang dimuat ke dalam dua tabel, FactResellerSales_CCI_Demo dan FactResellerSales_Page_Demo. FactResellerSales_CCI_Demo memiliki indeks penyimpan kolom berkluster, dan FactResellerSales_Page_Demo memiliki indeks pohon b berkluster dengan dua kolom dan dikompresi halaman. Seperti yang Anda lihat setiap tabel memuat 1.024.000 baris dari tabel FactResellerSalesXL_CCI . Ketika SET STATISTICS TIME adalah ON, SQL Server melacak waktu yang berlalu dari eksekusi kueri. Memuat data ke dalam tabel penyimpanan kolom membutuhkan waktu sekitar 8 detik, sedangkan memuat data ke dalam tabel dengan pemadatan halaman membutuhkan waktu hampir 20 detik. Dalam contoh ini, semua baris yang masuk ke indeks penyimpanan kolom dimuat ke dalam satu grup baris.
Jika Anda memuat kurang dari 102.400 baris data ke dalam indeks penyimpan kolom dalam satu operasi, itu dimuat dalam struktur pohon b yang dikenal sebagai penyimpanan delta. Mesin database memindahkan data ini ke dalam indeks penyimpanan kolom menggunakan proses asinkron yang disebut penggerak tuple. Memiliki penyimpanan delta terbuka dapat memengaruhi performa kueri Anda, karena membaca rekaman tersebut kurang efisien daripada membaca dari penyimpan kolom. Anda juga dapat mengatur ulang indeks dengan COMPRESS_ALL_ROW_GROUPS opsi untuk memaksa penyimpanan delta ditambahkan dan dikompresi ke dalam indeks penyimpan kolom.