Pembelajaran mendalam
Nota
Lihat tab Teks dan gambar untuk detail selengkapnya!
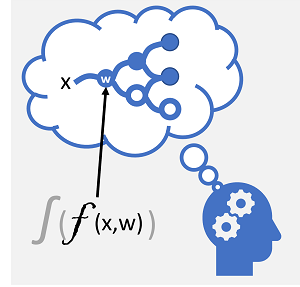
Pembelajaran mendalam adalah bentuk pembelajaran mesin lanjutan yang mencoba meniru cara otak manusia belajar. Kunci pembelajaran mendalam adalah pembuatan jaringan saraf buatan yang mensimulasikan aktivitas elektrokimia dalam neuron biologis dengan menggunakan fungsi matematika, seperti yang ditunjukkan di sini.
| Jaringan saraf biologis | Jaringan neural buatan |
|---|---|

|
|
| Neuron berkobar saat menerima rangsangan elektrokimia. Ketika ditembakkan, sinyal diteruskan ke neuron yang terhubung. | Setiap neuron berfungsi untuk mengolah nilai input (x) dan bobot (w). Fungsi ini dibungkus dalam fungsi aktivasi yang menentukan apakah akan meneruskan output. |
Jaringan saraf tiruan terdiri dari beberapa lapisan neuron - pada dasarnya mendefinisikan fungsi bersarang yang kompleks. Arsitektur ini adalah alasan teknik ini disebut sebagai pembelajaran mendalam dan model yang dihasilkan olehnya sering disebut sebagai jaringan neural mendalam (DNN). Anda dapat menggunakan jaringan neural mendalam untuk berbagai jenis masalah pembelajaran mesin, termasuk regresi dan klasifikasi, serta model yang lebih khusus untuk pemrosesan bahasa alami dan visi komputer.
Sama seperti teknik pembelajaran mesin lainnya yang dibahas dalam modul ini, pembelajaran mendalam melibatkan penyesuaian data pelatihan dengan fungsi yang dapat memprediksi label (y) berdasarkan nilai satu atau beberapa fitur (x). Fungsi (f(x)) adalah lapisan luar fungsi berlapis di mana setiap lapisan jaringan neural merangkum fungsi yang beroperasi pada nilai x dan bobot (w) yang terkait dengannya. Algoritma yang digunakan untuk melatih model melibatkan pengumpanan nilai fitur (x) secara berulang kali dalam data pelatihan ke depan melalui lapisan untuk menghitung nilai output untuk ŷ, memvalidasi model dan mengevaluasi seberapa jauh nilai ŷ yang dihitung berada dari nilai y yang diketahui (yang mengukur tingkat kesalahan, atau kerugian, dalam model), dan kemudian memodifikasi bobot (w) untuk mengurangi kerugian. Model terlatih mencakup nilai bobot akhir yang menghasilkan prediksi yang paling akurat.
Contoh - Menggunakan pembelajaran mendalam untuk klasifikasi
Untuk lebih memahami cara kerja model jaringan neural mendalam, mari kita jelajahi contoh di mana jaringan neural digunakan untuk menentukan model klasifikasi untuk spesies penguin.
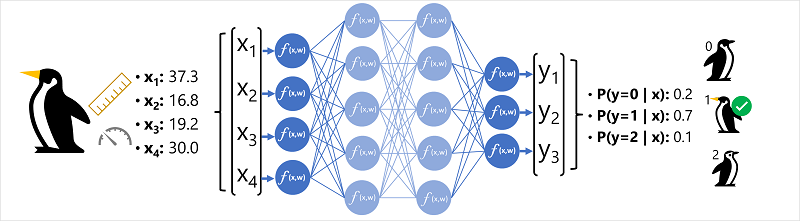
Data fitur (x) terdiri dari beberapa pengukuran seekor penguin. Secara khusus, pengukurannya adalah:
- Panjang paruh penguin.
- Kedalaman paruh penguin.
- Panjang sandal penguin.
- Bobot penguin.
Dalam hal ini, x adalah vektor empat nilai, atau matematis, x=[x1,x2,x3,x4].
Label yang kami coba prediksi (y) adalah spesies penguin, dan ada tiga spesies yang mungkin:
- Adelie
- Gentoo
- Chinstrap
Ini adalah contoh masalah klasifikasi, di mana model pembelajaran mesin harus memprediksi kelas yang paling mungkin di mana pengamatan berada. Model klasifikasi menyelesaikan masalah tersebut dengan memprediksi label yang terdiri dari peluang untuk setiap kelas. Dengan kata lain, y adalah vektor dari tiga nilai probabilitas; satu untuk setiap kelas yang mungkin: [P(y=0|x), P(y=1|x), P(y=2|x)].
Proses untuk menyimpulkan kelas penguin yang diprediksi menggunakan jaringan ini adalah:
- Vektor fitur untuk pengamatan penguin dimasukkan ke dalam lapisan input jaringan saraf, yang terdiri dari neuron untuk setiap nilai x . Dalam contoh ini, vektor x berikut digunakan sebagai input: [37.3, 16.8, 19.2, 30.0]
- Fungsi untuk lapisan pertama neuron masing-masing menghitung jumlah tertimbang dengan menggabungkan nilai x dan berat w , dan meneruskannya ke fungsi aktivasi yang menentukan apakah memenuhi ambang batas yang akan diteruskan ke lapisan berikutnya.
- Setiap neuron dalam lapisan terhubung ke semua neuron di lapisan berikutnya (arsitektur kadang-kadang disebut jaringan yang sepenuhnya terhubung) sehingga hasil dari setiap lapisan disalurkan ke depan melalui jaringan sampai mereka mencapai lapisan output.
- Lapisan output menghasilkan vektor nilai; dalam hal ini, menggunakan softmax atau fungsi serupa untuk menghitung distribusi probabilitas untuk tiga kelas penguin yang mungkin. Dalam contoh ini, vektor output adalah: [0.2, 0.7, 0.1]
- Elemen vektor mewakili probabilitas untuk kelas 0, 1, dan 2. Nilai kedua adalah yang tertinggi, sehingga model memprediksi bahwa spesies penguin adalah 1 (Gentoo).
Bagaimana jaringan neural belajar?
Bobot dalam jaringan neural berperan penting dalam cara menghitung nilai yang diprediksi untuk penanda. Selama proses pelatihan, model mempelajari bobot yang akan menghasilkan prediksi yang paling akurat. Mari kita jelajahi proses pelatihan secara lebih rinci untuk memahami bagaimana pembelajaran ini berlangsung.
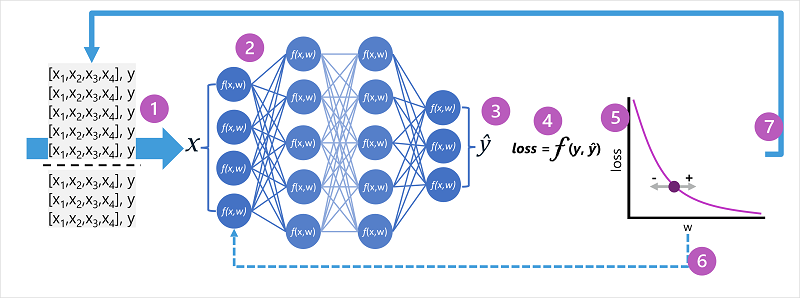
- Himpunan data pelatihan dan validasi ditentukan, dan fitur pelatihan dimasukkan ke dalam lapisan input.
- Neuron saraf di setiap lapisan jaringan menerapkan bobot mereka (yang awalnya ditetapkan secara acak) dan mengalirkan data melalui jaringan.
- Lapisan output menghasilkan vektor yang berisi nilai terhitung untuk ŷ. Misalnya, output untuk prediksi kelas penguin mungkin [0,3. 0.1. 0.6].
- Fungsi kerugian digunakan untuk membandingkan nilai ŷ yang diprediksi dengan nilai y yang diketahui dan menggabungkan perbedaan (yang dikenal sebagai kerugian). Misalnya, jika kelas yang diketahui untuk kasus yang mengembalikan output pada langkah sebelumnya adalah Chinstrap, maka nilai y harus [0,0, 0,0, 1,0]. Perbedaan absolut antara ini dan vektor ŷ adalah [0,3, 0,1, 0,4]. Pada kenyataannya, fungsi kerugian menghitung varian agregat untuk beberapa kasus dan meringkasnya sebagai nilai kerugian tunggal.
- Karena seluruh jaringan pada dasarnya adalah satu fungsi berlapis besar, fungsi pengoptimalan dapat menggunakan kalkulus diferensial untuk mengevaluasi pengaruh setiap berat dalam jaringan pada kehilangan, dan menentukan bagaimana mereka dapat disesuaikan (naik atau turun) untuk mengurangi jumlah kerugian keseluruhan. Teknik pengoptimalan khusus dapat bervariasi, tetapi biasanya melibatkan pendekatan penurunan gradien di mana setiap berat ditingkatkan atau dikurangi untuk meminimalkan kehilangan.
- Perubahan pada bobot dipropagasi kembali ke lapisan dalam jaringan, menggantikan nilai yang digunakan sebelumnya.
- Proses ini diulang selama beberapa iterasi (dikenal sebagai epoch) sampai kerugian diminimalkan dan model memprediksi secara akurat.
Nota
Meskipun lebih mudah untuk memikirkan setiap kasus dalam data pelatihan yang diteruskan melalui jaringan secara satu per satu, pada kenyataannya data dikelompokkan ke dalam matriks dan diproses menggunakan perhitungan aljabar linier. Untuk alasan ini, pelatihan jaringan neural paling baik dilakukan pada komputer dengan unit pemrosesan grafis (GPU) yang dioptimalkan untuk manipulasi vektor dan matriks.