Model bahasa semantik
Nota
Lihat tab Teks dan gambar untuk detail selengkapnya!
Karena teknologi NLP yang canggih telah berkembang, kemampuan untuk melatih model yang mengakomodasi hubungan semantik antara token telah menyebabkan munculnya model bahasa dengan pembelajaran mendalam yang kuat. Inti dari model ini adalah pengodean token bahasa sebagai vektor (array angka multinilai) yang dikenal sebagai penyematan.
Pendekatan berbasis vektor untuk pemodelan teks ini menjadi umum dengan teknik seperti Word2Vec dan GloVe, di mana token teks direpresentasikan sebagai vektor padat dengan beberapa dimensi. Selama pelatihan model, nilai dimensi ditetapkan untuk mencerminkan karakteristik semantik dari setiap token berdasarkan penggunaannya dalam teks pelatihan. Hubungan matematika antara vektor kemudian dapat dieksploitasi untuk melakukan tugas analisis teks umum lebih efisien daripada teknik statistik murni yang lebih lama. Kemajuan yang lebih baru dalam pendekatan ini adalah menggunakan teknik yang disebut perhatian untuk mempertimbangkan setiap token dalam konteks, dan menghitung pengaruh token di sekitarnya. Penyematan kontekstual yang dihasilkan, seperti yang ditemukan dalam keluarga model GPT, memberikan dasar AI generatif modern.
Mewakili teks sebagai vektor
Vektor mewakili titik dalam ruang multidimensi, yang ditentukan oleh koordinat di sepanjang beberapa sumbu. Setiap vektor menjelaskan arah dan jarak dari asal. Token yang mirip secara semantik harus menghasilkan vektor yang memiliki orientasi serupa - dengan kata lain mereka menunjuk ke arah yang sama.
Misalnya, pertimbangkan penyematan tiga dimensi berikut untuk beberapa kata umum:
| Microsoft Word | Vector |
|---|---|
dog |
[0.8, 0.6, 0.1] |
puppy |
[0.9, 0.7, 0.4] |
cat |
[0.7, 0.5, 0.2] |
kitten |
[0.8, 0.6, 0.5] |
young |
[0.1, 0.1, 0.3] |
ball |
[0.3, 0.9, 0.1] |
tree |
[0.2, 0.1, 0.9] |
Kita dapat memvisualisasikan vektor ini dalam ruang tiga dimensi seperti yang ditunjukkan di sini:

Vektor untuk "dog" dan "cat" serupa (keduanya hewan peliharaan), seperti "puppy" dan "kitten" (keduanya hewan muda). Kata -kata "tree", "young", dan ball" memiliki orientasi vektor yang berbeda, mencerminkan makna semantik yang berbeda.
Karakteristik semantik yang dikodekan dalam vektor memungkinkan untuk menggunakan operasi berbasis vektor yang membandingkan kata-kata dan mengaktifkan perbandingan analitis.
Menemukan istilah terkait
Karena orientasi vektor ditentukan oleh nilai dimensinya, kata-kata dengan makna semantik yang serupa cenderung memiliki orientasi yang sama. Ini berarti Anda dapat menggunakan perhitungan seperti kesamaan kosinus antara vektor untuk membuat perbandingan yang bermakna.
Misalnya, untuk menentukan "ganjil satu keluar" antara "dog", , "cat"dan "tree", Anda dapat menghitung kesamaan kosinus antara pasangan vektor. Kesamaan kosinus dihitung sebagai:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
Di mana A · B adalah produk titik dan ||A|| merupakan besarnya vektor A.
Menghitung kesamaan antara tiga kata:
dog[0.8, 0.6, 0.1] dancat[0.7, 0.5, 0.2]:- Produk titik: (0,8 × 0,7) + (0,6 × 0,5) + (0,1 × 0,2) = 0,56 + 0,30 + 0,02 = 0,88
- Magnitudo
dog: √(0,8² + 0,6² + 0,1²) = √(0,64 + 0,36 + 0,01) = √1,01 ≈ 1,005 - Besarnya
cat: √(0,7² + 0,5² + 0,2²) = √(0,49 + 0,25 + 0,04) = √0,78 ≈ 0,883 - Kesamaan kosinus: 0,88 / (1,005 × 0,883) ≈ 0,992 (kesamaan tinggi)
dog[0.8, 0.6, 0.1] dantree[0.2, 0.1, 0.9]:- Produk titik: (0,8 × 0,2) + (0,6 × 0,1) + (0,1 × 0,9) = 0,16 + 0,06 + 0,09 = 0,31
- Besaran
tree: √(0,2² + 0,1² + 0,9²) = √(0,04 + 0,01 + 0,81) = √0,86 ≈ 0,927 - Kesamaan kosinus: 0,31 / (1,005 × 0,927) ≈ 0,333 (kesamaan rendah)
cat[0.7, 0.5, 0.2] dantree[0.2, 0.1, 0.9]:- Produk titik: (0,7 × 0,2) + (0,5 × 0,1) + (0,2 × 0,9) = 0,14 + 0,05 + 0,18 = 0,37
- Kesamaan kosinus: 0,37 / (0,883 × 0,927) ≈ 0,452 (kesamaan rendah)
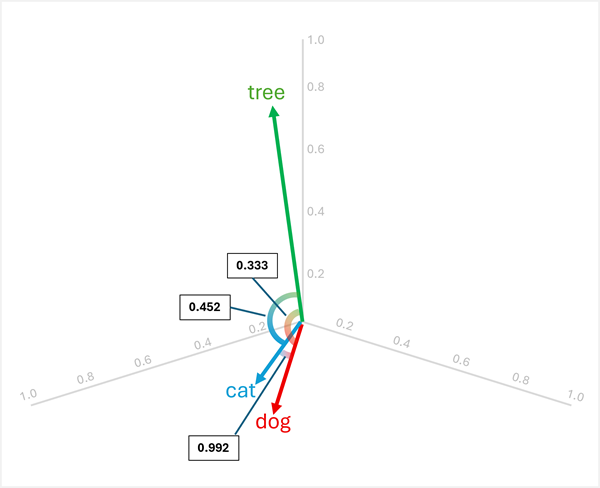
Hasilnya menunjukkan bahwa "dog" dan "cat" sangat mirip (0,992), sementara "tree" memiliki kesamaan yang lebih rendah dengan keduanya "dog" (0,333) dan "cat" (0,452). Oleh karena itu, tree jelas merupakan yang berbeda.
Terjemahan vektor melalui penambahan dan pengurangan
Anda dapat menambahkan atau mengurangi vektor untuk menghasilkan hasil berbasis vektor baru; yang kemudian dapat digunakan untuk menemukan token dengan vektor yang cocok. Teknik ini memungkinkan logika berbasis aritmatika intuitif untuk menentukan istilah yang sesuai berdasarkan hubungan linguistik.
Misalnya, menggunakan vektor dari sebelumnya:
-
dog+young= [0,8, 0,6, 0,1] + [0,1, 0,1, 0,3] = [0,9, 0,7, 0,4] =puppy -
cat+young= [0,7, 0,5, 0,2] + [0,1, 0,1, 0,3] = [0,8, 0,6, 0,5] =kitten
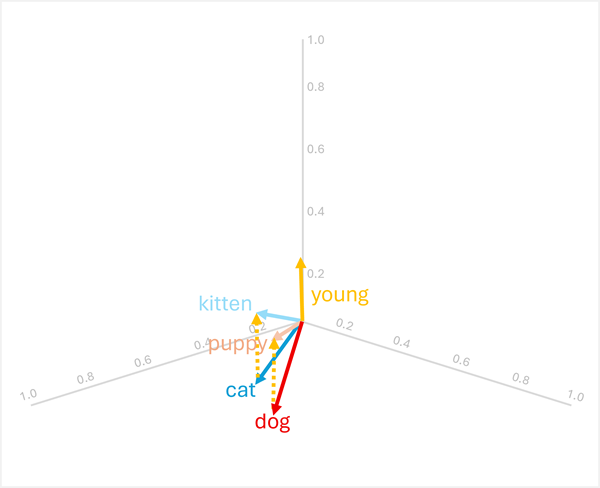
Operasi ini bekerja karena vektor untuk "young" mengodekan transformasi semantik dari hewan dewasa ke rekan mudanya.
Nota
Dalam praktiknya, aritmatika vektor jarang menghasilkan kecocokan yang tepat; sebagai gantinya, Anda akan mencari kata yang vektornya paling dekat (paling mirip) dengan hasilnya.
Aritmatika bekerja secara terbalik juga:
-
puppy-young= [0,9, 0,7, 0,4] - [0,1, 0,1, 0,3] = [0,8, 0,6, 0,1] =dog -
kitten-young= [0,8, 0,6, 0,5] - [0,1, 0,1, 0,3] = [0,7, 0,5, 0,2] =cat
Penalaran analogis
Aritmetika vektor juga dapat menjawab pertanyaan analogi seperti "
Untuk mengatasinya, hitung: kitten - puppy + dog
- [0.8, 0.6, 0.5] - [0.9, 0.7, 0.4] + [0.8, 0.6, 0.1]
- = [-0.1, -0.1, 0.1] + [0.8, 0.6, 0.1]
- = [0,7, 0,5, 0,2]
- =
cat
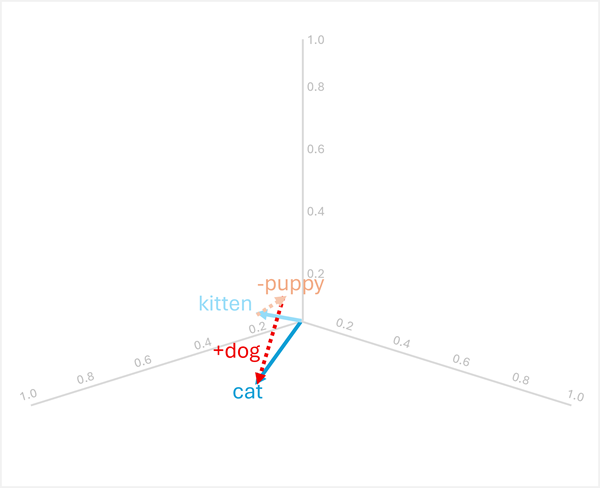
Contoh-contoh ini menunjukkan bagaimana operasi vektor dapat menangkap hubungan linguistik dan memungkinkan penalaran tentang pola semantik.
Menggunakan model semantik untuk analisis teks
Model semantik berbasis vektor menyediakan kemampuan yang kuat untuk banyak tugas analisis teks umum.
Ringkasan teks
Penyematan semantik memungkinkan ringkasan ekstraktif dengan mengidentifikasi kalimat dengan vektor yang paling mewakili keseluruhan dokumen. Dengan mengodekan setiap kalimat sebagai vektor (seringkali dengan merata-ratakan atau mengumpulkan embedding kata-kata konstituennya), Anda dapat menghitung kalimat mana yang paling penting untuk makna dokumen. Kalimat pusat ini dapat diekstrak untuk membentuk ringkasan yang menangkap tema utama.
Ekstraksi kata kunci
Kesamaan vektor dapat mengidentifikasi istilah terpenting dalam dokumen dengan membandingkan penyematan setiap kata dengan representasi semantik dokumen secara keseluruhan. Kata-kata yang vektornya paling mirip dengan vektor dokumen, atau yang paling terpusat ketika mempertimbangkan semua vektor kata dalam dokumen, kemungkinan menjadi istilah kunci yang mewakili topik utama.
Pengenalan entitas karakter
Model semantik dapat disempurnakan untuk mengenali entitas bernama (orang, organisasi, lokasi, dll.) dengan mempelajari representasi vektor yang mengelompokan jenis entitas serupa bersama-sama. Selama inferensi, model memeriksa penyematan setiap token dan konteksnya untuk menentukan apakah itu mewakili entitas bernama dan, jika demikian, jenis apa.
Klasifikasi teks
Untuk tugas seperti analisis sentimen atau kategorisasi topik, dokumen dapat diwakili sebagai vektor agregat (seperti rata-rata semua penyematan kata dalam dokumen). Vektor dokumen ini kemudian dapat digunakan sebagai fitur untuk pengklasifikasi pembelajaran mesin, atau dibandingkan langsung dengan vektor prototipe kelas untuk menetapkan kategori. Karena dokumen serupa secara semantik memiliki orientasi vektor yang sama, pendekatan ini secara efektif mengelompokkan konten terkait dan membedakan kategori yang berbeda.