Menggunakan Azure Data Lake Storage Gen2 dalam beban kerja analitik data
Azure Data Lake Store Gen2 adalah teknologi yang memungkinkan untuk beberapa kasus penggunaan analitik data. Mari kita jelajahi beberapa jenis beban kerja analitik umum, dan mengidentifikasi cara kerja Azure Data Lake Storage Gen2 dengan layanan Azure lainnya untuk mendukungnya.
Pemrosesan dan analitik big data
Skenario big data biasanya mengacu pada beban kerja analitik yang melibatkan volume data besar-besaran dalam berbagai format yang perlu diproses dengan kecepatan cepat - yang disebut "tiga v". Azure Data Lake Storage Gen 2 menyediakan penyimpanan data terdistribusi yang dapat diskalakan dan aman di mana layanan big data seperti Azure Synapse Analytics, Azure Databricks, dan Azure HDInsight dapat menerapkan kerangka kerja pemrosesan data seperti Apache Spark, Hive, dan Hadoop. Sifat penyimpanan terdistribusi dan komputasi pemrosesan memungkinkan tugas dilakukan secara paralel, menghasilkan performa dan skalabilitas tinggi bahkan saat memproses data dalam jumlah besar.
Pergudangan data
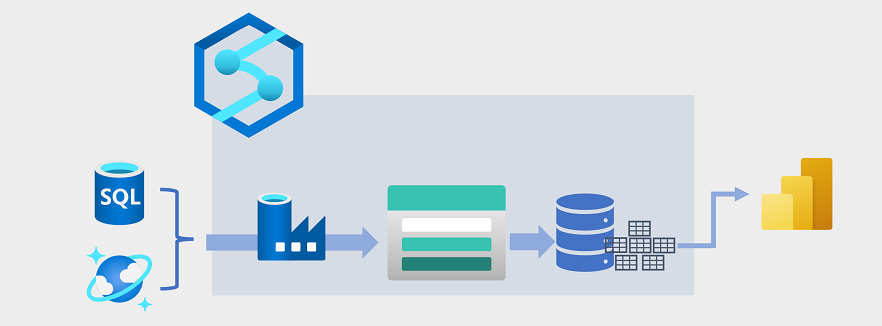
Pergudangan data telah berkembang dalam beberapa tahun terakhir untuk mengintegrasikan data dalam volume besar yang disimpan sebagai file di data lake dengan tabel relasional di gudang data. Dalam contoh umum solusi pergudangan data, data diekstrak dari penyimpanan data operasional, seperti database Azure SQL atau Azure Cosmos DB, dan diubah menjadi struktur yang lebih cocok untuk beban kerja analitis. Seringkali, data ditahapkan di data lake untuk memfasilitasi pemrosesan terdistribusi sebelum dimuat ke dalam gudang data relasional. Dalam beberapa kasus, gudang data menggunakan tabel eksternal untuk menentukan lapisan metadata relasional atas file di data lake dan membuat arsitektur "data lakehouse" atau "lake database" hibrid. Gudang data kemudian dapat mendukung kueri analitik untuk pelaporan dan visualisasi.
Ada beberapa cara untuk menerapkan arsitektur pergudangan data semacam ini. Diagram menunjukkan solusi di mana Azure Synapse Analytics menghosting alur untuk melakukan proses ekstraksi, transformasi, dan pemuatan (ETL) menggunakan teknologi Azure Data Factory. Proses ini mengekstrak data dari sumber data operasional dan memuatnya ke dalam data lake yang dihosting dalam kontainer Azure Data Lake Storage Gen2. Data kemudian diproses dan dimuat ke dalam gudang data relasional di kumpulan SQL khusus Azure Synapse Analytics, dari mana data tersebut dapat mendukung visualisasi dan pelaporan data menggunakan Microsoft Power BI.
Analitik data real time
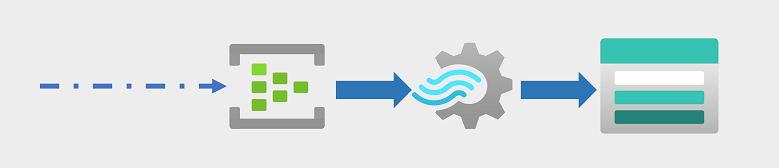
Semakin banyak, bisnis dan organisasi lain perlu menangkap dan menganalisis aliran data abadi, dan menganalisisnya secara real time (atau sedekat mungkin secara real-time). Aliran data ini dapat dihasilkan dari perangkat yang terhubung (sering disebut sebagai perangkat internet-of-things atau IoT ) atau dari data yang dihasilkan oleh pengguna di platform media sosial atau aplikasi lain. Tidak seperti beban kerja pemrosesan batch tradisional, data streaming memerlukan solusi yang dapat menangkap dan memproses aliran peristiwa data tanpa batas saat terjadi.
Peristiwa streaming sering diambil dalam antrean untuk diproses. Ada beberapa teknologi yang dapat Anda gunakan untuk melakukan tugas ini, termasuk Azure Event Hubs seperti yang ditunjukkan pada gambar. Dari sini, data diproses, sering kali untuk menggabungkan data melalui jendela temporal (misalnya untuk menghitung jumlah pesan media sosial dengan tag tertentu setiap lima menit, atau untuk menghitung pembacaan rata-rata sensor yang terhubung ke Internet per menit). Azure Stream Analytics memungkinkan Anda membuat pekerjaan yang mengkueri dan menggabungkan data peristiwa saat tiba, dan menulis hasilnya di sink output. Salah satu sink tersebut adalah Azure Data Lake Storage Gen2; dari mana data real-time yang diambil dapat dianalisis dan divisualisasikan.
Ilmu data dan pembelajaran mesin

Ilmu data melibatkan analisis statistik data dalam volume besar, sering menggunakan alat seperti Apache Spark dan bahasa pembuatan skrip seperti Python. Azure Data Lake Storage Gen 2 menyediakan penyimpanan data berbasis cloud yang sangat dapat diskalakan untuk volume data yang diperlukan dalam beban kerja ilmu data.
Pembelajaran mesin adalah subarea ilmu data yang berkaitan dengan model prediktif pelatihan. Pelatihan model membutuhkan sejumlah besar data, dan kemampuan untuk memproses data tersebut secara efisien. Azure Pembelajaran Mesin adalah layanan cloud di mana ilmuwan data dapat menjalankan kode Python di notebook menggunakan sumber daya komputasi terdistribusi yang dialokasikan secara dinamis. Komputasi memproses data dalam kontainer Azure Data Lake Storage Gen2 untuk melatih model, yang kemudian dapat disebarkan sebagai layanan web produksi untuk mendukung beban kerja analitik prediktif.