Ketimpangan data
Ketika label data kami memiliki lebih dari satu kategori daripada kategori lainnya, kami mengatakan bahwa kami memiliki ketidakseimbangan data. Misalnya, ingat bahwa dalam skenario kami, kami mencoba mengidentifikasi objek yang ditemukan oleh sensor drone. Data kami tidak seimbang karena ada sejumlah besar pendaki, hewan, pohon, dan batu dalam data pelatihan kami. Kita dapat melihatnya dengan tabulasi data ini:
| Label | Pendaki | Binatang | Pohon | Batu |
|---|---|---|---|---|
| Hitung | 400 | 200 | 800 | 800 |
Atau membuatkannya plot:
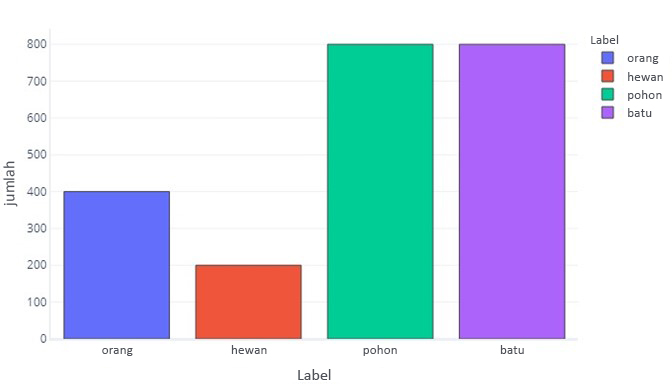
Perhatikan bagaimana sebagian besar data berupa pohon atau batu. Himpunan data yang seimbang tidak mengalami masalah ini.
Misalnya, jika kita mencoba memprediksi apakah objek adalah pendaki, hewan, pohon, atau batu, idealnya kita menginginkan jumlah yang sama dari semua kategori, seperti:
| Label | Pendaki | Binatang | Pohon | Batu |
|---|---|---|---|---|
| Hitung | 550 | 550 | 550 | 550 |
Jika kita hanya mencoba memprediksi apakah objek adalah pendaki, idealnya kita menginginkan jumlah objek pendaki dan bukan pendaki yang sama:
| Label | Pendaki | Non-pendaki |
|---|---|---|
| Hitung | 1100 | 1100 |
Mengapa ketimpangan data penting?
Ketimpangan data penting karena model dapat belajar meniru ketimpangan ini ketika tidak diinginkan. Contoh, misalkan kita melatih model regresi logistik untuk mengidentifikasi objek sebagai pendaki atau non-pendaki. Jika data pelatihan sangat didominasi oleh label "pendaki", pelatihan akan membuat model menjadi hampir selalu mengembalikan label "pendaki". Namun, di dunia nyata, kita mungkin menemukan bahwa sebagian besar hal yang ditemukan drone adalah pohon. Model bias ini mungkin akan melabeli banyak pohon ini sebagai pendaki.
Fenomena ini terjadi karena fungsi biaya, secara default, menentukan apakah respons yang benar diberikan. Ini berarti bahwa untuk himpunan data bias, cara paling sederhana agar model dapat mencapai performa optimal adalah dengan secara virtual mengabaikan fitur yang disediakan dan selalu, atau hampir selalu, menampilkan jawaban yang sama. Hal ini bisa memiliki konsekuensi yang menghancurkan. Misalnya, bayangkan model pendaki/pendaki kami dilatih pada data di mana hanya satu per 1000 sampel yang berisi pendaki. Model yang telah belajar mengembalikan "not-hiker" setiap kali memiliki akurasi 99,9%! Statistik ini tampaknya luar biasa, tetapi model itu tidak berguna karena tidak akan pernah memberi tahu kita jika seseorang berada di gunung, dan kita tidak akan tahu untuk menyelamatkan mereka jika longsoran salju menerjang.
Bias dalam matriks kebingungan
Matriks kebingungan adalah kunci untuk mengidentifikasi ketimpangan data atau bias model. Dalam skenario yang ideal, data pengujian memiliki jumlah label yang kira-kira merata, dan prediksi yang dibuat oleh model juga kira-kira tersebar di seluruh label. Untuk 1000 sampel, model yang tidak dibiaskan, tetapi sering kali mendapat jawaban yang salah, mungkin terlihat seperti ini:
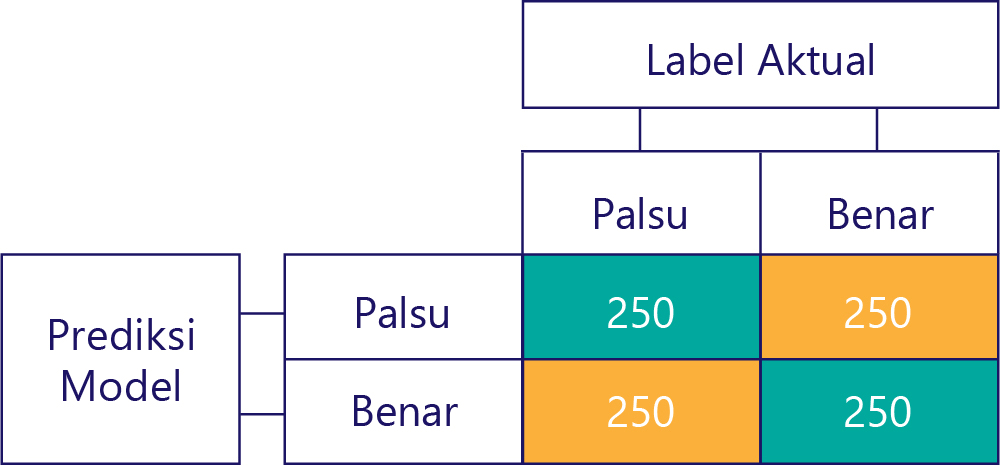
Kita dapat mengetahui bahwa data input tidak bias, karena jumlah baris sama (masing-masing 500), menunjukkan bahwa setengah label "benar", dan setengahnya adalah "false". Demikian pula, kita dapat mengetahui bahwa model memberikan tanggapan yang tidak dibiaskan karena menampilkan true setengah waktu dan false setengah waktu lainnya.
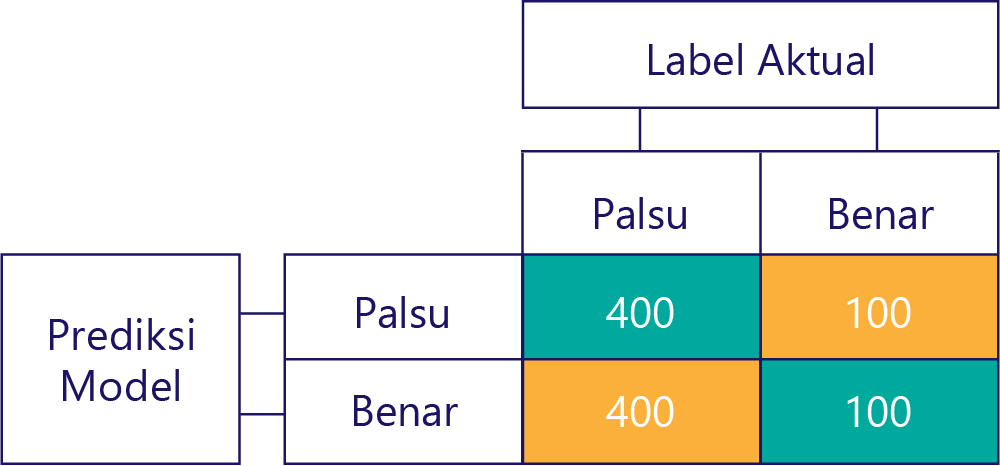
Sebaliknya, data yang dibiaskan sebagian besar berisi satu jenis label, seperti:
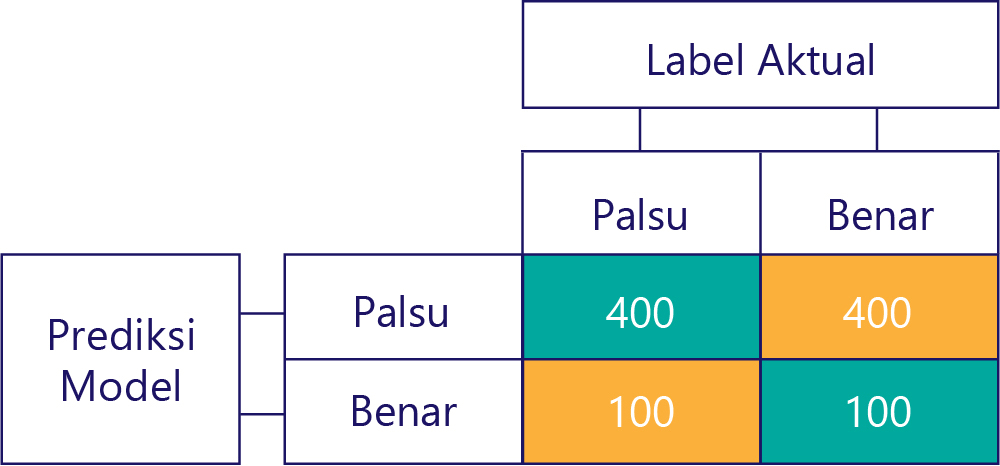
Demikian pula, model yang dibiaskan sebagian besar menghasilkan satu jenis label, seperti berikut:
Bias model bukanlah akurasi
Ingat bahwa bias bukan akurasi. Misalnya, beberapa contoh sebelumnya bias, dan yang lain tidak, tetapi semuanya menunjukkan model yang mendapatkan jawaban benar 50% dari waktu. Sebagai contoh yang lebih ekstrem, matriks di bawah menunjukkan model yang tidak dibiaskan yang tidak akurat:
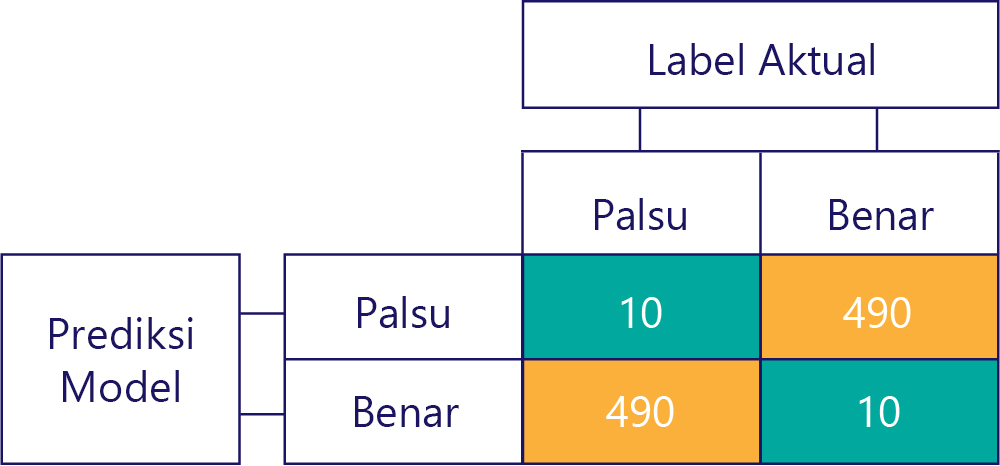
Perhatikan bagaimana jumlah baris dan kolom semuanya berjumlah 500, yang menunjukkan bahwa kedua data seimbang dan model tidak dibiaskan. Meskipun demikian, model ini hampir semuanya mendapatkan respons yang salah!
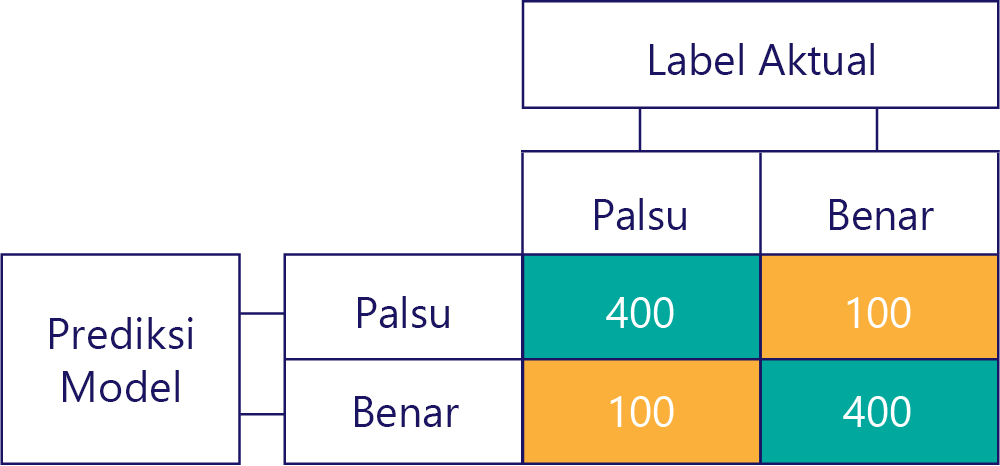
Tentu saja, tujuan kita adalah memiliki model yang akurat dan tidak bias, seperti:
... tetapi kita perlu memastikan model akurat kita tidak bias, hanya karena datanya:
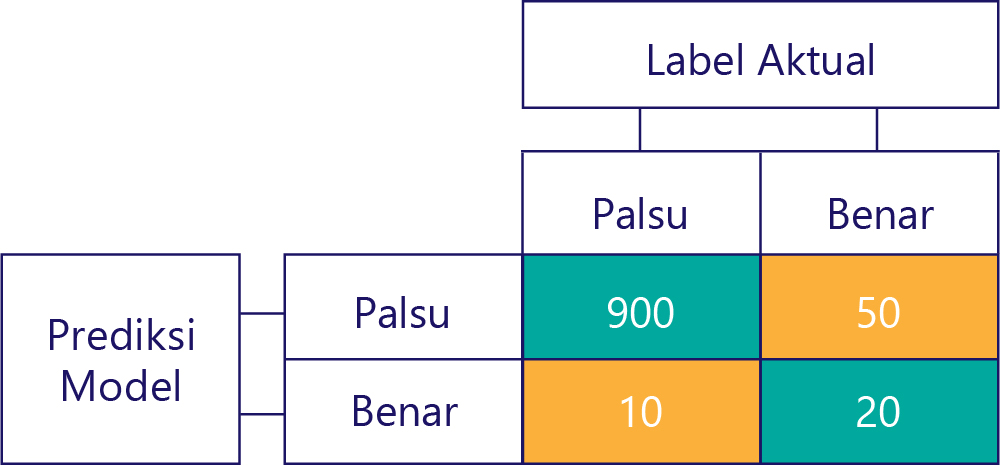
Dalam contoh ini, perhatikan bagaimana label aktual sebagian besar false (kolom kiri, menunjukkan ketimpangan data) dan model juga sering menampilkan false (baris atas, memperlihatkan bias model). Model ini tidak tepat dalam memberikan tanggapan 'True' dengan benar.
Menghindari konsekuensi dari data yang tidak seimbang
Beberapa cara termudah untuk menghindari konsekuensi data tidak seimbang adalah:
- Hindari melalui pemilihan data yang lebih baik.
- "Resample" data Anda sehingga berisi duplikat kelas label minoritas.
- Buat perubahan pada fungsi biaya sehingga memprioritaskan label yang kurang umum. Misalnya, jika respons yang salah diberikan ke Tree, fungsi biaya mungkin mengembalikan 1; sementara jika respons yang salah dibuat untuk Pendaki, itu mungkin mengembalikan 10.
Kita akan mengeksplorasi metode ini dalam latihan berikut.