Mengoptimalkan sistem sumber - tingkat lanjut
Pemisahan tabel ID Baris Oracle
SAP telah merilis Catatan SAP #1043380, yang berisi skrip yang mengubah klausul WHERE dalam file WHR menjadi nilai ROW ID. Atau, versi terbaru SAPInst secara otomatis menghasilkan file WHR pemisahan ID BARIS jika SWPM dikonfigurasi untuk migrasi Oracle ke Oracle R3load. File STR dan WHR yang dihasilkan oleh SWPM bersifat independen dari sistem operasi dan database (seperti semua aspek dari proses migrasi OS/DB).
Catatan OSS berisi pernyataan "pemisahan tabel ID BARIS TIDAK DAPAT digunakan jika database target adalah database non-Oracle". Secara teknis, file dump R3load tidak bergantung pada database dan sistem operasi. Namun, ada satu pembatasan, mulai ulang paket selama impor tidak dimungkinkan di SQL Server. Dalam skenario ini, seluruh tabel perlu dihilangkan dan semua paket untuk tabel dimulai ulang. Selalu disarankan untuk menghentikan tugas R3load untuk tabel terpisah tertentu, TRUNCATE tabel dan restart seluruh proses impor jika satu R3load terpisah membatalkan. Alasan untuk ini adalah bahwa proses pemulihan yang dibangun ke dalam R3load melibatkan melakukan pernyataan DELETE baris demi baris tunggal untuk menghapus catatan yang dimuat oleh proses R3load yang membatalkan. File ini lambat dan akan sering menyebabkan situasi pemblokiran/penguncian pada database. Pengalaman menunjukkan bahwa lebih cepat untuk memulai impor tabel khusus ini dari awal, oleh karena itu batasan yang disebutkan dalam Catatan SAP #1043380 bukan merupakan batasan.
ROW ID memiliki kelemahan dalam penghitungan pemisahan yang harus dilakukan selama waktu henti – lihat Catatan SAP #1043380.
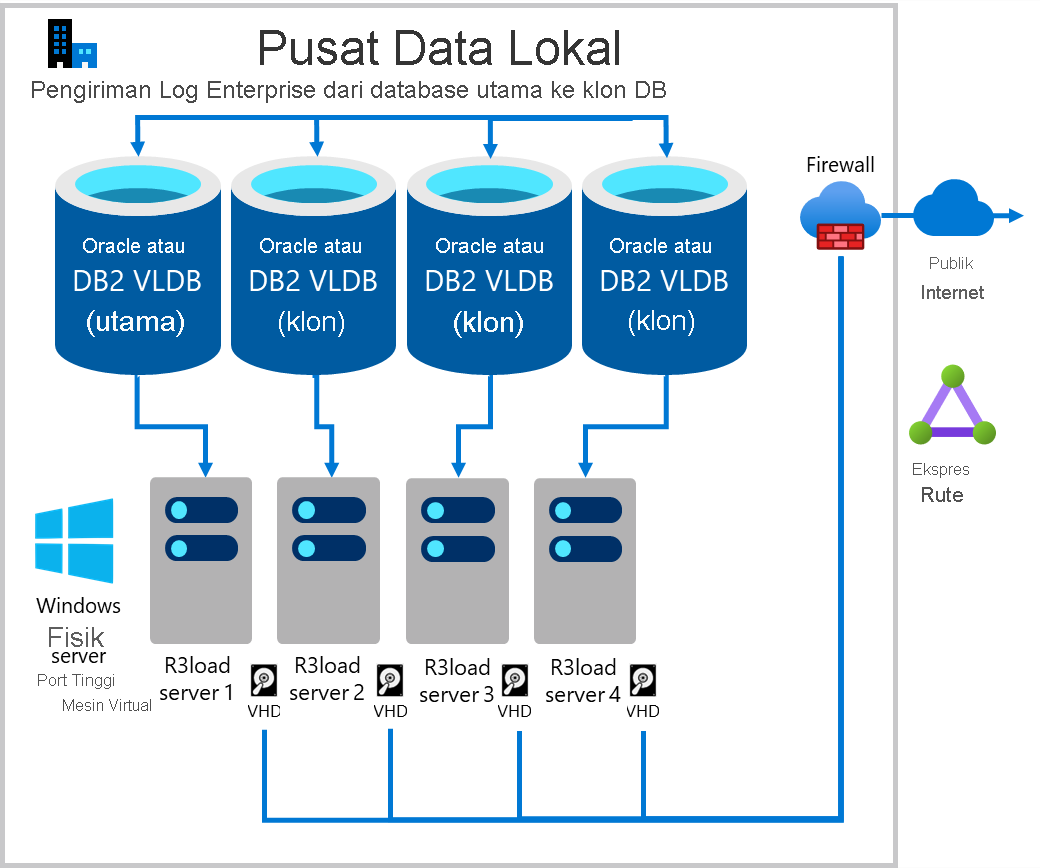
Membuat beberapa "klon" dari database sumber dan ekspor secara paralel
Salah satu metode untuk meningkatkan kinerja ekspor adalah mengekspor dari beberapa salinan database yang sama. Jika infrastruktur yang mendasarinya termasuk server, jaringan, dan penyimpanan dapat diskalakan, maka pendekatan ini cenderung dapat diskalakan secara linier. Mengekspor dari dua salinan database yang sama dua kali lebih cepat, empat salinan empat kali lebih cepat. Pemantau Migrasi dikonfigurasi untuk mengekspor pada sejumlah tabel tertentu dari setiap "klon" database. Dalam kasus berikut, beban kerja ekspor didistribusikan sekitar 25% pada masing-masing dari empat server database.
- Server DB 1 & ekspor server 1 – didedikasikan untuk tabel 1-4 terbesar (tergantung pada seberapa condong distribusi data pada database sumber)
- Server DB 2 & ekspor server 2 – didedikasikan untuk tabel dengan pemisahan tabel
- Server DB 3 & ekspor server 3 – didedikasikan untuk tabel dengan pemisahan tabel
- Server DB 4 & ekspor server 4 – semua tabel yang tersisa
Perawatan harus dilakukan untuk memastikan bahwa database disinkronkan dengan tepat, jika tidak, kehilangan data atau inkonsistensi data dapat terjadi. Jika langkah-langkah yang disediakan diikuti dengan tepat, integritas data dipertahankan.
Teknik ini sederhana dan murah dengan perangkat keras Intel komoditas standar tetapi juga dimungkinkan bagi pelanggan yang menjalankan perangkat keras UNIX eksklusif. Sumber daya perangkat keras yang substansial bebas menuju tengah proyek migrasi OS/DB ketika sistem Sandbox, Development, QAS, Training, dan DR telah pindah ke Azure. Tidak ada persyaratan ketat bahwa server "klon" memiliki sumber daya perangkat keras yang identik. Dengan kinerja CPU, RAM, disk, dan jaringan yang memadai, penambahan setiap klon meningkatkan performa.
Jika performa ekspor tambahan masih diperlukan, buka insiden SAP di BC-DB-MSS untuk langkah tambahan guna meningkatkan performa ekspor (khusus konsultan tingkat lanjut).
Langkah untuk mengimplementasikan beberapa ekspor paralel adalah sebagai berikut:
- Cadangkan database utama dan pulihkan ke jumlah server "n" (di mana n = jumlah kloning). Untuk contoh ini, asumsikan n = 3 server yang menghasilkan total empat server DB.
- Pulihkan cadangan ke tiga server.
- Buat pengiriman log dari server DB sumber utama ke tiga server "kloning" target.
- Pantau pengiriman log selama beberapa hari dan pastikan pengiriman log bekerja dengan andal.
- Pada awal waktu henti, matikan semua server aplikasi SAP kecuali PAS. Pastikan semua pemrosesan batch dihentikan dan semua lalu lintas RFC dihentikan.
- Dalam transaksi SM02, masukkan teks "Titik Pemeriksaan PAS Berjalan". Ini memperbarui tabel TEMSG.
- Hentikan Server Aplikasi Utama. SAP sekarang dimatikan. Tidak ada lagi aktivitas menulis yang dapat terjadi di sumber DB. Pastikan bahwa tidak ada aplikasi non-SAP yang terhubung ke sumber DB (tidak seharusnya ada, tetapi periksa sesi non-SAP di tingkat DB).
- Jalankan kueri ini di server DB Utama:
SELECT EMTEXT FROM [schema].TEMSG; - Jalankan pernyataan tingkat DBMS asli:
INSERT INTO [schema].TEMSG “CHECKPOINT R3LOAD EXPORT STOP dd:mm:yy hh:mm:ss”(sintaks yang tepat tergantung pada sumber DBMS. INSERT ke EMTEXT) - Hentikan cadangan log otomatis. Jalankan satu cadangan log akhir secara manual di server DB Utama. Pastikan cadangan log disalin ke server klon.
- Pulihkan cadangan log transaksi akhir pada ketiga simpul.
- Pulihkan database pada 3 node "klon".
- Jalankan pernyataan SELECT berikut pada keempat simpul:
SELECT EMTEXT FROM [schema].TEMSG; - Ambil hasil layar pernyataan SELECT untuk masing-masing dari empat server DB (utama dan tiga kloning). Pastikan untuk dengan hati-hati menyertakan setiap nama host - untuk berfungsi sebagai bukti bahwa klon DB dan primer identik dan berisi data yang sama dari titik waktu yang sama.
- Mulai export_monitor.bat pada setiap server ekspor Intel R3load.
- Mulai proses penyalinan file cadangan ke Azure (baik AzCopy atau Robocopy).
- Mulai import_monitor.bat pada Mesin Virtual Azure R3load.
Diagram berikut menunjukkan pengiriman log server DB Produksi yang ada ke database "klon". Setiap server DB memiliki satu atau lebih server R3load Intel.