Menganalisis klasifikasi dengan kurva karakteristik operator penerima
Model klasifikasi harus menetapkan sampel ke kategori. Misalnya, model harus menggunakan fitur seperti ukuran, warna, dan gerakan untuk menentukan apakah objek adalah pendaki atau pohon.
Kita dapat meningkatkan model klasifikasi dalam banyak hal. Misalnya, kita dapat memastikan data kita seimbang, bersih, dan diskalakan. Kami juga dapat mengubah arsitektur model kami dan menggunakan hiperparameter untuk memeras performa sebanyak mungkin dari data dan arsitektur kami. Terakhir, kita tidak menemukan cara yang lebih baik untuk meningkatkan performa pada serangkaian pengujian kita (atau hold-out) dan menyatakan model kita siap.
Penyetelan model ke titik ini bisa menjadi kompleks, tetapi kita dapat menggunakan langkah sederhana terakhir untuk lebih meningkatkan seberapa baik model kita bekerja. Untuk memahami ini, kita harus kembali ke dasar.
Probabilitas dan kategori
Banyak model memiliki beberapa tahap pengambilan keputusan, dan yang terakhir sering kali hanya merupakan langkah binarisasi. Selama binarisasi, probabilitas dikonversi menjadi label keras. Misalnya, katakanlah model disediakan dengan fitur dan menghitung bahwa ada kemungkinan 75% bahwa model ditampilkan pendaki, dan 25% kemungkinan itu ditunjukkan pohon. Objek tidak boleh 75% pendaki dan 25% pohon; itu satu atau yang lain! Dengan demikian, model menerapkan ambang, yang biasanya 50%. Karena kelas pendaki lebih besar dari 50%, objek dinyatakan sebagai pendaki.
Ambang batas 50% bersifat logis; itu berarti bahwa label yang paling mungkin sesuai dengan model selalu dipilih. Namun, jika model bias, ambang 50% ini mungkin tidak sesuai. Misalnya, jika model memiliki sedikit kecenderungan untuk memilih pohon lebih dari pendaki, memilih pohon 10% lebih sering daripada yang seharusnya, kita dapat menyesuaikan ambang keputusan kita untuk memperhitungkan hal ini.
Refresher pada matriks keputusan
Matriks keputusan adalah cara yang bagus untuk menilai jenis kesalahan yang dibuat model. Ini memberi kita tingkat Positif Benar (TP), Negatif Benar (TN), Positif Palsu (FP), dan Negatif Palsu (FN)

Kita dapat menghitung beberapa karakteristik yang bermanfaat dari matriks kebingungan. Dua karakteristik populer adalah:
- True Positive Rate (sensitivitas): seberapa sering label "True" diidentifikasi dengan benar sebagai "True." Misalnya, seberapa sering model memprediksi "pendaki" ketika sampel yang ditampilkan sebenarnya adalah pendaki.
- False Positive Rate (tingkat alarm palsu): seberapa sering label "False" salah diidentifikasi sebagai "True." Misalnya, seberapa sering model memprediksi "pendaki" saat ditampilkan pohon.
Melihat tingkat positif benar dan positif palsu dapat membantu kami memahami performa model.
Pertimbangkan contoh pendaki kita. Idealnya, tingkat positif sejati sangat tinggi, dan tingkat positif palsu sangat rendah, karena ini berarti bahwa model mengidentifikasi pendaki dengan baik dan tidak mengidentifikasi pohon sebagai pendaki sangat sering. Namun, jika tingkat positif yang benar sangat tinggi, tetapi tingkat positif palsu juga sangat tinggi, maka model bias; ini mengidentifikasi hampir semua yang ditemuinya sebagai pendaki. Demikian pula, kita tidak ingin model dengan tingkat positif sejati yang rendah, karena kemudian ketika model menemukan pendaki, model akan memberi label sebagai pohon.
Kurva ROC
Kurva karakteristik operator penerima (ROC) adalah grafik tempat kita merencanakan tingkat positif benar versus tingkat positif palsu.
Kurva ROC dapat membingungkan bagi pemula karena dua alasan utama. Alasan pertama adalah bahwa pemula tahu bahwa model hanya memiliki satu nilai untuk tingkat positif sejati dan negatif sejati, sehingga plot ROC harus terlihat seperti ini:
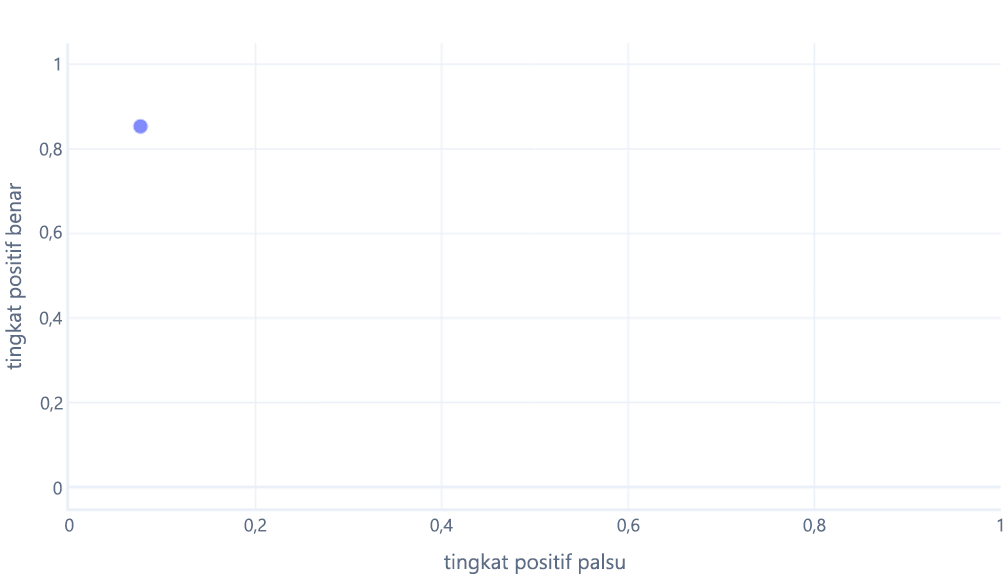
Jika Anda juga berpikir ini, Anda benar. Model terlatih hanya menghasilkan satu titik. Namun, ingatlah bahwa model kita memiliki ambang—biasanya 50%—yang digunakan untuk memutuskan apakah label benar (pendaki) atau salah (pohon) harus digunakan. Jika kita mengubah ambang ini menjadi 30% dan menghitung ulang tingkat positif benar dan positif palsu, kita mendapatkan titik lain:
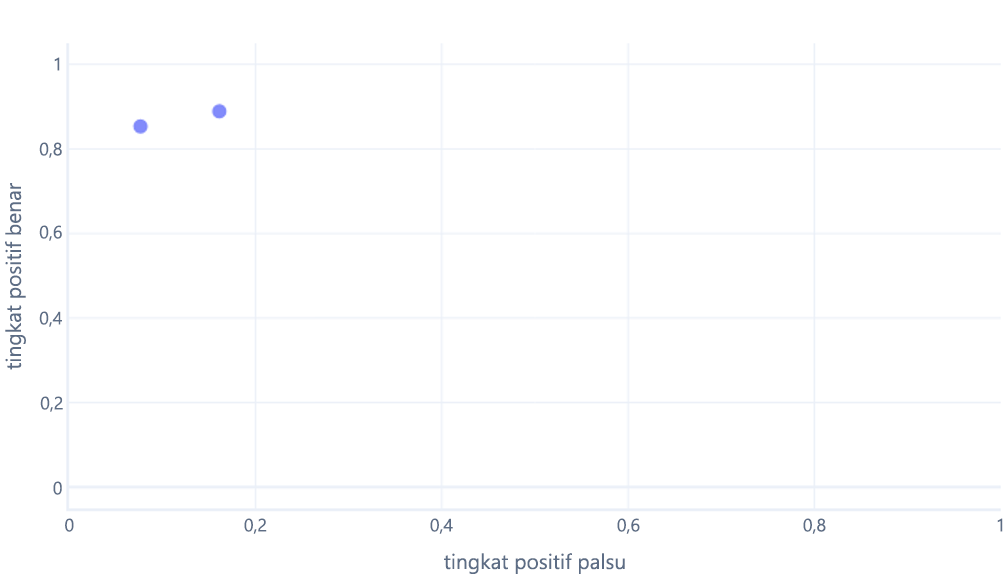
Jika kita melakukan ini untuk ambang batas antara 0%-100%, kita mungkin mendapatkan grafik seperti ini:
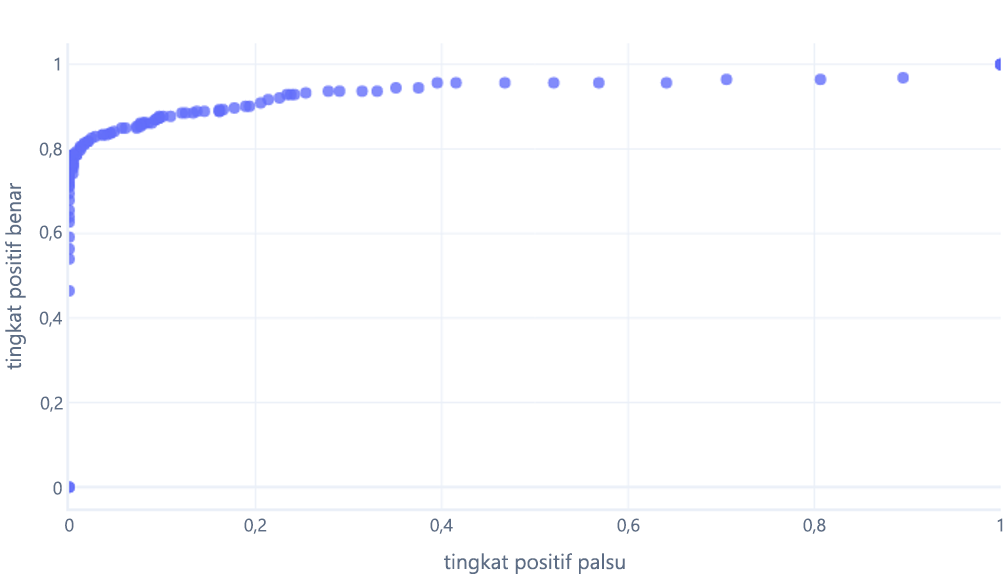
Yang biasanya kita tampilkan sebagai garis, sebagai gantinya:
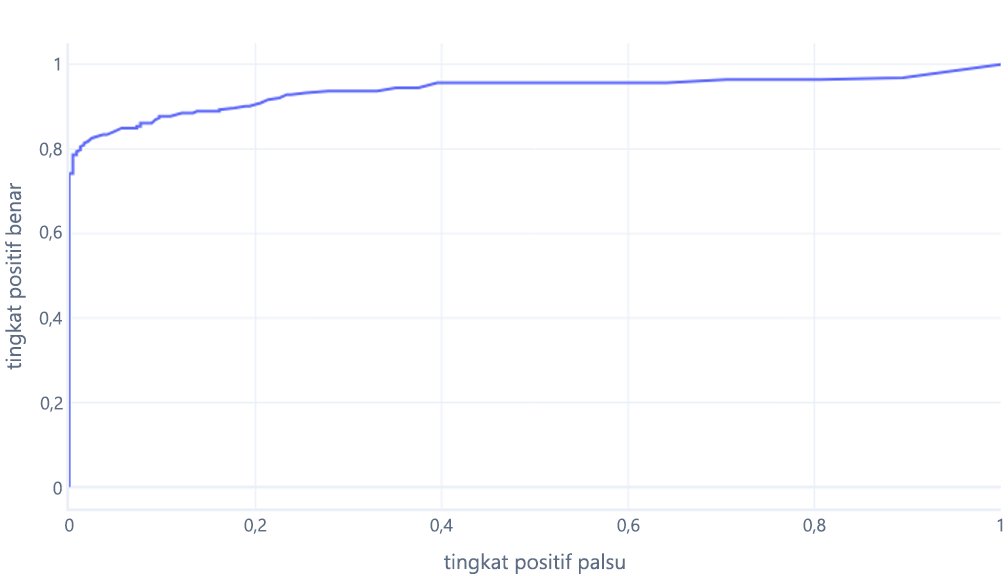
Alasan kedua grafik ini dapat membingungkan adalah jargon yang terlibat. Ingat bahwa kita menginginkan tingkat positif benar yang tinggi (mengidentifikasi pendaki seperti itu) dan tingkat positif palsu yang rendah (tidak mengidentifikasi pohon sebagai pendaki).
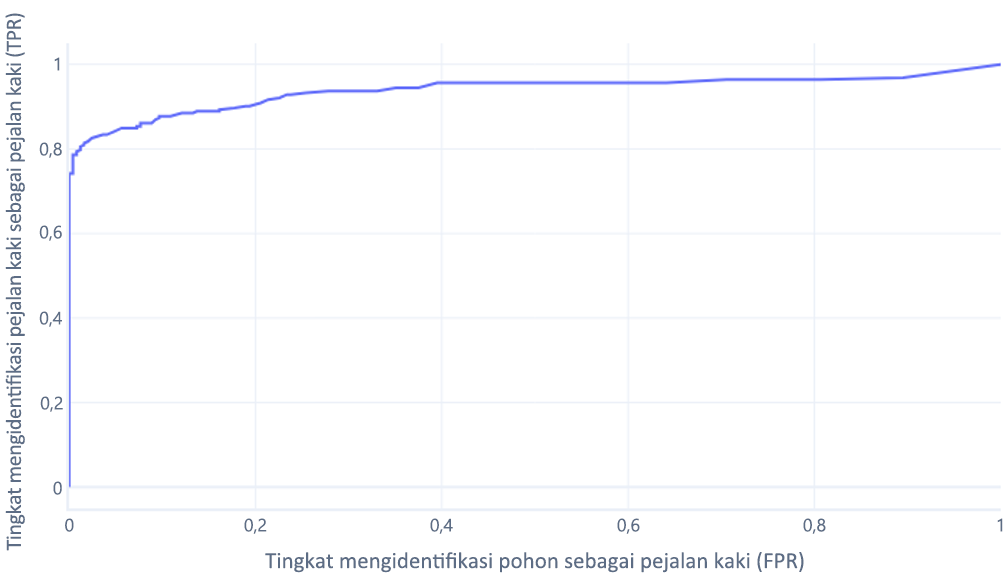
ROC yang baik, ROC yang buruk
Memahami kurva ROC yang baik dan yang buruk adalah hal terbaik yang dilakukan di lingkungan interaktif. Ketika Anda siap, langsung ke latihan berikutnya untuk menjelajahi topik ini.