Normalisasi dan standardisasi
Penskalaan Fitur adalah teknik yang mengubah rentang nilai yang dimiliki fitur. Melakukannya membantu model belajar lebih cepat dan lebih kuat.
Standardisasi versus normalisasi
Normalisasi berarti menskalakan nilai sehingga semuanya sesuai dalam rentang tertentu, biasanya 0–1. Misalnya, jika Anda memiliki daftar orang berusia 0, 50, dan 100 tahun, Anda dapat menstandarkan dengan membagi usia dengan 100, sehingga nilai Anda adalah 0, 0,5, dan 1.
Standardisasi serupa, tetapi sebaliknya, kita mengurangi rata-rata (juga dikenal sebagai rata-rata) nilai dan dibagi dengan simpangan baku. Jika Anda tidak terbiasa dengan simpangan baku, tidak perlu khawatir, artinya setelah standardisasi, nilai rata-rata kita adalah nol, dan sekitar 95% nilai berada antara -2 dan 2.
Ada cara lain untuk menskalakan data, tetapi nuansa ini di luar apa yang perlu kita ketahui sekarang. Mari kita jelajahi mengapa kita menerapkan normalisasi atau standardisasi.
Mengapa kita perlu menskalakan?
Ada banyak alasan kita menormalkan atau menstandarkan data sebelum pelatihan. Anda dapat memahami ini dengan lebih mudah dengan contoh. Katakanlah kita ingin melatih model untuk memprediksi apakah anjing akan berhasil bekerja di salju. Data kami ditampilkan dalam grafik berikut sebagai titik, dan garis tren yang coba kami temukan ditampilkan sebagai garis solid:
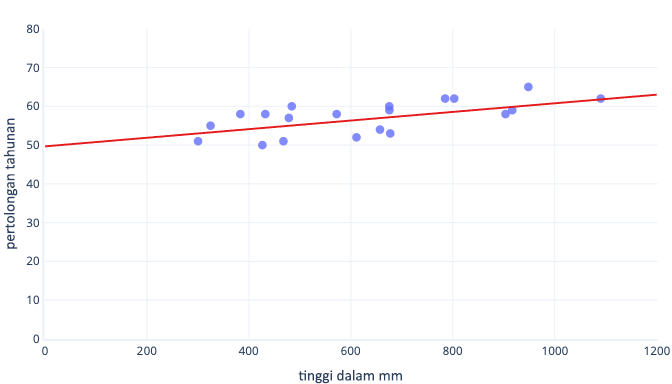
Penskalaan memberi pembelajaran titik awal yang lebih baik
Baris optimal dalam grafik sebelumnya memiliki dua parameter: intersepsi, yaitu 50, garis di x=0, dan kelereng, yaitu 0,01; setiap 1000 milimeter meningkatkan penyelamatan sebesar 10. Mari kita asumsikan kita mulai pelatihan dengan perkiraan awal 0 untuk kedua parameter ini.
Jika iterasi pelatihan kami mengubah parameter rata-rata sekitar 0,01 per iterasi, dibutuhkan setidaknya 5000 iterasi sebelum intersepsi ditemukan: 50 / 0,01 = 5000 iterasi. Standardisasi dapat membawa intersepsi optimal ini mendekati nol, yang berarti kita dapat menemukannya lebih cepat. Misalnya, jika kita mengurangi rata-rata dari label kita—penyelamatan tahunan—dan fitur kita—tinggi—potongan adalah -0,5, bukan 50, yang dapat kita temukan sekitar 100 kali lebih cepat.
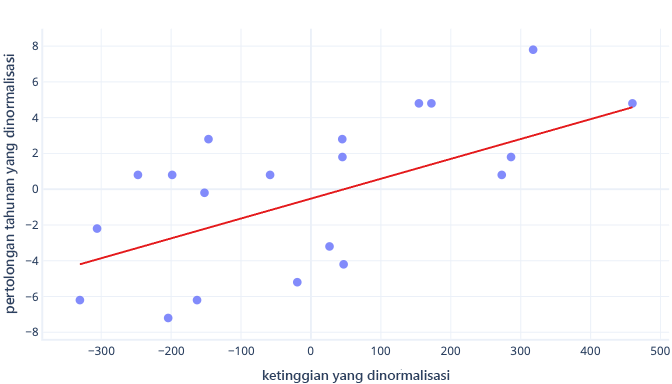
Ada alasan lain bahwa model kompleks bisa sangat lambat untuk dilatih ketika tebakan awal jauh dari tanda, tetapi solusinya masih sama: mengimbangi fitur ke sesuatu yang lebih dekat dengan tebakan awal.
Standardisasi memungkinkan parameter berlatih dengan kecepatan yang sama
Dalam data offset kami yang baru, kami memiliki offset ideal -0,5 dan kelopak ideal 0,01. Meskipun offsetting membantu mempercepat semuanya, masih jauh lebih lambat untuk melatih offset daripada melatih kelereng. Ini dapat memperlambat hal-hal dan membuat pelatihan tidak stabil.
Misalnya, tebakan awal kita untuk offset dan kemiringan sama-sama nol. Jika kita mengubah parameter sekitar 0,1 pada setiap iterasi, kita akan menemukan offset dengan cepat, tetapi akan sangat sulit untuk menemukan kelereng yang benar, karena peningkatan kelereng akan terlalu besar (0 + 0,1 > 0,01) dan dapat melampaui nilai ideal. Kita dapat membuat penyesuaian yang lebih kecil, tetapi ini akan memperlambat berapa lama waktu yang diperlukan untuk menemukan potongan.
Apa yang terjadi jika kita menskalakan fitur tinggi kita?
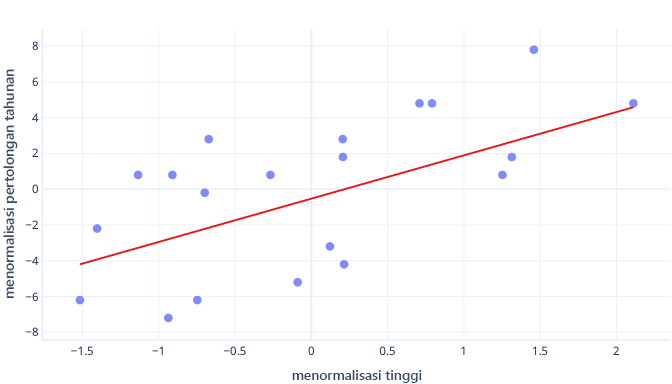
Kemiringan garis sekarang adalah 0,5. Perhatikan sumbu-x. Potongan optimal -0,5 dan kemiringan 0,5 kita adalah skala yang sama! Sekarang mudah untuk memilih ukuran langkah yang masuk akal, yaitu seberapa cepat parameter pembaruan turunan gradien.
Penskalaan membantu dengan beberapa fitur
Saat kita bekerja dengan banyak fitur, memilikinya pada skala yang berbeda dapat menyebabkan masalah dalam pemasangan, mirip dengan yang baru saja kita lihat dengan contoh potongan dan kemiringan. Misalnya, jika kita melatih model yang menerima tinggi mm dan berat dalam metrik ton, banyak jenis model akan berjuang untuk menghargai pentingnya fitur berat badan, hanya karena sangat kecil relatif terhadap fitur tinggi.
Apakah saya harus selalu menskalakan?
Kita tidak selalu perlu menskalakan. Beberapa jenis model, termasuk model sebelumnya dengan garis lurus, bisa pas tanpa prosedur berulang seperti penurunan gradien, sehingga mereka tidak keberatan fitur menjadi ukuran yang salah. Model lain memang membutuhkan penskalaan untuk berlatih dengan baik, tetapi perpustakaan model itu sering melakukan penskalaan fitur secara otomatis.
Secara umum, satu-satunya kelemahan nyata dari normalisasi atau standardisasi adalah bahwa hal itu dapat mempersulit interpretasi model kita dan kita harus menulis sedikit lebih banyak kode. Karena alasan ini, penskalaan fitur adalah bagian standar dalam membuat model pembelajaran mesin.