Apa itu klasifikasi?
Klasifikasi biner adalah klasifikasi dengan dua kategori. Misalnya, kita dapat memberi label pasien sebagai bukan penderita diabetes atau penderita diabetes.
Prediksi kelas dibuat dengan menentukan probabilitas untuk setiap kemungkinan kelas sebagai nilai antara 0 (tidak mungkin) dan 1 (pasti). Probabilitas total untuk semua kelas selalu 1, karena pasien pasti diabetes atau non-diabetes. Jadi, jika probabilitas yang diprediksi pasien diabetes adalah 0,3, maka ada kemungkinan yang sesuai 0,7 bahwa pasien tidak diabetes.
Nilai ambang batas, seringkali 0,5, digunakan untuk menentukan kelas yang diprediksi. Jika kelas positif (dalam hal ini, diabetes) memiliki probabilitas yang diprediksi lebih besar dari ambang batas, maka klasifikasi diabetes diprediksi.
Melatih dan mengevaluasi model klasifikasi
Klasifikasi adalah contoh teknik pembelajaran mesin yang diawasi, yang berarti bergantung pada data yang mencakup nilai fitur yang diketahui dan nilai label yang diketahui. Dalam contoh ini, nilai fitur adalah pengukuran diagnostik untuk pasien, dan nilai label adalah klasifikasi non-diabetes atau diabetes. Algoritma klasifikasi digunakan untuk menyesuaikan subset data ke dalam fungsi yang dapat menghitung probabilitas untuk setiap label kelas dari nilai fitur. Data yang tersisa digunakan untuk mengevaluasi model dengan membandingkan prediksi yang dihasilkan dari fitur dengan label kelas yang diketahui.
Contoh sederhana
Mari kita jelajahi contoh untuk membantu menjelaskan prinsip-prinsip utama. Misalkan kita memiliki data pasien berikut, yang terdiri dari satu fitur (tingkat glukosa darah) dan label kelas 0 untuk non-diabetes, 1 untuk diabetes.
| Gula darah | penderita diabetes |
|---|---|
| 82 | 0 |
| 92 | 0 |
| 112 | 1 |
| 102 | 0 |
| 115 | 1 |
| 107 | 1 |
| 87 | 0 |
| 120 | 1 |
| 83 | 0 |
| 119 | 1 |
| 104 | 1 |
| 105 | 0 |
| 86 | 0 |
| 109 | 1 |
Kami menggunakan delapan pengamatan pertama untuk melatih model klasifikasi, dan kami mulai dengan merencanakan fitur glukosa darah (x) dan label diabetes yang diprediksi (y).
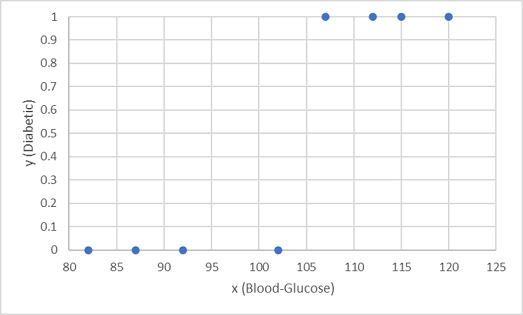
Yang kita butuhkan adalah fungsi yang menghitung nilai probabilitas untuk y berdasarkan x (dengan kata lain, kita membutuhkan fungsi f(x) = y). Anda dapat melihat dari grafik bahwa pasien dengan kadar glukosa darah rendah semuanya non-diabetes, sedangkan pasien dengan kadar glukosa darah yang lebih tinggi adalah diabetes. Sepertinya semakin tinggi tingkat glukosa darah, semakin mungkin pasien diabetes, dengan titik infleksi berada di suatu tempat antara 100 dan 110. Kita perlu menyesuaikan fungsi yang menghitung nilai antara 0 dan 1 untuk y ke nilai ini.
Salah satu fungsi tersebut adalah fungsi logistik , yang membentuk kurva sigmoidal (berbentuk S).
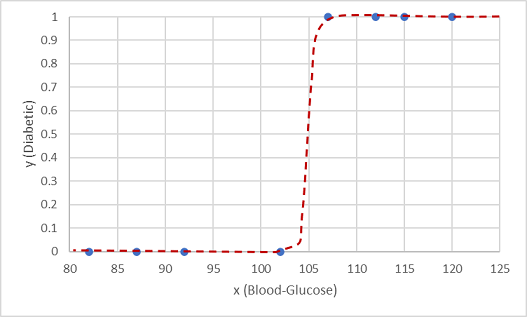
Sekarang kita dapat menggunakan fungsi tersebut untuk menghitung nilai probabilitas bahwa y positif, artinya pasien diabetes, dari sembarang nilai x dengan mencari titik pada garis fungsi untuk x. Kita dapat menetapkan nilai ambang 0,5 sebagai titik potong untuk prediksi label kelas.
Mari kita uji dengan dua nilai data yang kita tahan.
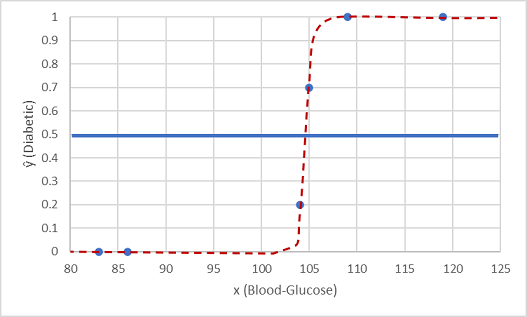
Poin yang diplot di bawah garis ambang menghasilkan kelas prediksi 0 (non-diabetes) dan titik di atas garis diprediksi sebagai 1 (diabetes).
Sekarang kita dapat membandingkan prediksi label (ŷ, atau "y-hat"), berdasarkan fungsi logistik yang dienkapsulasi dalam model, dengan label kelas aktual (y).
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |