Mengevaluasi model klasifikasi
Akurasi pelatihan model klasifikasi jauh lebih penting daripada seberapa baik model itu akan bekerja ketika diberikan data baru yang tidak terlihat. Bagaimanapun juga, kita melatih model agar dapat digunakan pada data baru yang ditemukan di dunia nyata. Jadi, setelah kami melatih model klasifikasi, kami akan mengevaluasi performanya pada sekumpulan data baru yang tidak terlihat.
Pada pelajaran sebelumnya, kita membuat model yang akan memprediksi apakah pasien menderita diabetes atau tidak berdasarkan kadar glukosa darahnya. Sekarang, ketika diterapkan ke beberapa data yang bukan bagian dari set pelatihan, kita mendapatkan prediksi berikut.
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |
Ingat bahwa x mengacu pada tingkat glukosa darah, y mengacu pada apakah mereka benar-benar diabetes, dan ŷ mengacu pada prediksi model apakah mereka diabetes atau tidak.
Hanya menghitung berapa banyak prediksi yang benar kadang-kadang menyesatkan atau terlalu sederhana bagi kita untuk memahami jenis kesalahan yang akan dibuatnya di dunia nyata. Untuk mendapatkan informasi yang lebih rinci, kita dapat menayangkan hasil dalam struktur yang disebut matriks kebingungan, seperti ini:
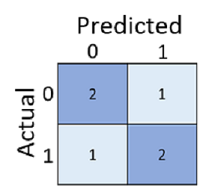
Matriks kebingungan menunjukkan jumlah total kasus di mana:
- Model memprediksi 0 dan label aktual adalah 0 (negatif sejati, paling kiri atas)
- Model memprediksi 1 dan label aktual adalah 1 (positif benar, kanan bawah)
- Model memprediksi 0 dan label aktual adalah 1 (negatif palsu, kiri bawah)
- Model memprediksi 1, label aktual adalah 0 (positif palsu, di kanan atas)
Sel dalam matriks kebingungan sering berbayang sehingga nilai yang lebih tinggi memiliki bayangan yang lebih dalam. Hal ini memudahkan untuk melihat tren diagonal yang kuat dari kiri atas ke kanan bawah, menyoroti sel di mana nilai prediksi dan nilai sebenarnya sama.
Dari nilai inti ini, Anda dapat menghitung rentang metrik lain yang dapat membantu Anda mengevaluasi performa model. Contohnya:
- Akurasi: (TP+TN)/(TP+TN+FP+FN) - dari semua prediksi, berapa banyak yang benar?
- Recall: TP/(TP+FN) - dari seluruh kasus yang positif, berapa banyak yang diidentifikasi model?
- Presisi: TP/(TP+FP) - dari semua kasus yang diprediksi model positif, berapa banyak yang sebenarnya positif?