Jaringan saraf konvolusional
Meskipun Anda dapat menggunakan model pembelajaran mendalam untuk segala jenis pembelajaran mesin, model tersebut sangat berguna untuk menangani data yang terdiri dari array besar nilai numerik - seperti gambar. Model pembelajaran mesin yang bekerja dengan gambar adalah fondasi untuk kecerdasan buatan area yang disebut visi komputer, dan teknik pembelajaran mendalam telah bertanggung jawab untuk mendorong kemajuan luar biasa di area ini selama beberapa tahun terakhir.
Inti dari keberhasilan pembelajaran mendalam di area ini adalah semacam model yang disebut jaringan saraf konvolusional, atau CNN. CNN biasanya bekerja dengan mengekstrak fitur dari gambar, dan kemudian mengumpankan fitur-fitur tersebut ke dalam jaringan neural yang terhubung sepenuhnya untuk menghasilkan prediksi. Lapisan ekstraksi fitur dalam jaringan memiliki efek mengurangi jumlah fitur dari array nilai piksel individual yang berpotensi besar ke set fitur yang lebih kecil yang mendukung prediksi label.
Lapisan dalam CNN
CN terdiri dari beberapa lapisan, masing-masing melakukan tugas tertentu dalam mengekstrak fitur atau memprediksi label.
Lapisan konvolusi
Salah satu jenis lapisan utama adalah lapisan konvolusional yang mengekstrak fitur penting dalam gambar. Lapisan konvolusional bekerja dengan menerapkan filter ke gambar. Filter didefinisikan oleh kernel yang terdiri dari matriks nilai berat.
Misalnya, filter 3x3 mungkin didefinisikan seperti ini:
1 -1 1
-1 0 -1
1 -1 1
Gambar juga hanyalah matriks nilai piksel. Untuk menerapkan filter, Anda "menimpakannya" pada gambar dan menghitung penjumlahan tertimbang dari nilai piksel gambar yang sesuai di bawah kernel filter. Hasilnya kemudian ditetapkan ke sel tengah patch 3x3 yang setara dalam matriks nilai baru yang berukuran sama dengan gambar. Misalnya, gambar 6 x 6 memiliki nilai piksel berikut:
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
Menerapkan filter ke patch 3x3 kiri atas gambar akan berfungsi seperti ini:
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
Hasilnya ditetapkan ke nilai piksel yang sesuai dalam matriks baru seperti ini:
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Sekarang filter dipindahkan bersama (yang dikonveksi ), biasanya menggunakan langkah ukuran 1 (jadi bergerak bersama satu piksel ke kanan), dan nilai untuk piksel berikutnya dihitung
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
Jadi sekarang kita dapat mengisi nilai berikutnya dari matriks baru.
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Proses ini berulang hingga kami menerapkan filter di semua patch gambar 3x3 untuk menghasilkan matriks nilai baru seperti ini:
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
Karena ukuran kernel filter, kami tidak dapat menghitung nilai untuk piksel di tepi; jadi kita biasanya hanya menerapkan nilai padding (sering 0):
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
Output konvolusi biasanya diteruskan ke fungsi aktivasi, yang sering merupakan fungsi Unit Linear Terkoreksi (ReLU) yang memastikan nilai negatif diatur ke 0:
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
Matriks yang dihasilkan adalah peta fitur nilai fitur yang dapat digunakan untuk melatih model pembelajaran mesin.
Catatan: Nilai dalam peta fitur bisa lebih besar dari nilai maksimum untuk piksel (255), jadi jika Anda ingin memvisualisasikan peta fitur sebagai gambar, Anda harus menormalkan nilai fitur antara 0 dan 255.
Proses konvolusi ditunjukkan pada animasi di bawah ini.

- Gambar diteruskan ke lapisan konvolusional. Dalam hal ini, gambar adalah bentuk geometris sederhana.
- Gambar terdiri dari array piksel dengan nilai antara 0 dan 255 (untuk gambar warna, ini biasanya array 3 dimensi dengan nilai untuk saluran merah, hijau, dan biru).
- Kernel filter umumnya diinisialisasi dengan bobot acak (dalam contoh ini, kami telah memilih nilai untuk menyoroti efek yang mungkin dimiliki filter pada nilai piksel; tetapi dalam CNN nyata, bobot awal biasanya akan dihasilkan dari distribusi Gaussian acak). Filter ini akan digunakan untuk mengekstrak peta fitur dari data gambar.
- Filter dikonvolasi di seluruh gambar, menghitung nilai fitur dengan menerapkan jumlah bobot dikalikan dengan nilai piksel yang sesuai di setiap posisi. Fungsi aktivasi Unit Linier Terkoreksi (ReLU) diterapkan untuk memastikan nilai negatif diatur ke 0.
- Setelah konvolusi, peta fitur berisi nilai fitur yang diekstrak, yang sering menekankan atribut visual utama gambar. Dalam hal ini, peta fitur menyoroti tepi dan sudut segitiga dalam gambar.
Biasanya, lapisan konvolusional menerapkan beberapa kernel filter. Setiap filter menghasilkan peta fitur yang berbeda, dan semua peta fitur diteruskan ke lapisan jaringan berikutnya.
Lapisan pengumpulan
Setelah mengekstrak nilai fitur dari gambar, lapisan pengumpulan (atau downsampling) digunakan untuk mengurangi jumlah nilai fitur sambil mempertahankan fitur pembeda utama yang telah diekstrak.
Salah satu jenis pengumpulan yang paling umum adalah pengumpulan maks di mana filter diterapkan ke gambar, dan hanya nilai piksel maksimum dalam area filter yang dipertahankan. Jadi misalnya, menerapkan kernel pengumpulan 2x2 ke patch gambar berikut akan menghasilkan hasil 155.
0 0
0 155
Perhatikan bahwa efek filter pengumpulan 2x2 adalah mengurangi jumlah nilai dari 4 menjadi 1.
Seperti halnya lapisan konvolusional, lapisan pengumpulan bekerja dengan menerapkan filter di seluruh peta fitur. Animasi di bawah ini menunjukkan contoh pengumpulan maks untuk peta gambar.

- Peta fitur yang diekstrak oleh filter dalam lapisan konvolusional berisi array nilai fitur.
- Kernel kumpulan digunakan untuk mengurangi jumlah nilai fitur. Dalam hal ini, ukuran kernel adalah 2x2, sehingga akan menghasilkan array dengan seperempat jumlah nilai fitur.
- Kernel pengumpulan dikonvolusi di seluruh peta fitur, hanya mempertahankan nilai piksel tertinggi di setiap posisi.
Menghapus lapisan
Salah satu tantangan paling sulit dalam CNN adalah menghindari overfitting, di mana model yang dihasilkan berkinerja baik dengan data pelatihan tetapi tidak dapat menggeneralisasi dengan baik ke data baru yang belum pernah digunakan untuk latihan. Salah satu teknik yang dapat Anda gunakan untuk mengurangi overfitting adalah menyertakan lapisan di mana proses pelatihan secara acak menghapus peta fitur (atau disebut sebagai "dropout"). Ini mungkin tampak berlawanan intuitif, tetapi ini adalah cara yang efektif untuk memastikan bahwa model tidak belajar terlalu bergantung pada gambar pelatihan.
Teknik lain yang dapat Anda gunakan untuk mengurangi overfitting termasuk membalik, mencerminkan, atau memiringkan gambar pelatihan secara acak untuk menghasilkan data yang bervariasi antara satu epoch pelatihan dengan epoch berikutnya.
Meratakan lapisan
Setelah menggunakan lapisan konvolusi dan pelapisan untuk mengekstrak fitur-fitur penting dalam gambar, peta fitur yang dihasilkan adalah array multidimensi dari nilai piksel. Lapisan perataan digunakan untuk meratakan peta fitur ke dalam vektor nilai yang dapat digunakan sebagai input ke lapisan terhubung penuh.
Lapisan yang sepenuhnya terhubung
Biasanya, CNN berakhir dengan jaringan yang sepenuhnya terhubung di mana nilai fitur diteruskan ke lapisan input, melalui satu atau beberapa lapisan tersembunyi, dan menghasilkan nilai yang diprediksi dalam lapisan output.
Arsitektur CNN dasar mungkin terlihat mirip dengan ini:
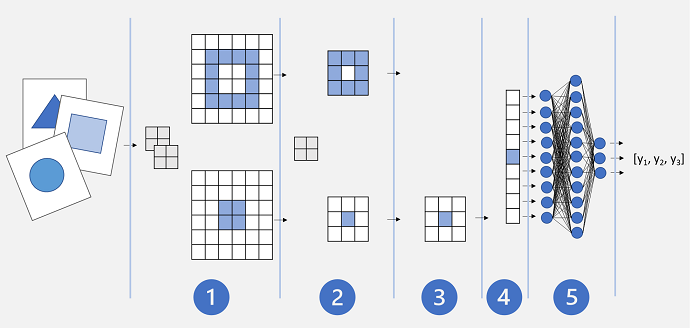
- Gambar diumpankan ke dalam lapisan konvolusional. Dalam hal ini, ada dua filter, sehingga setiap gambar menghasilkan dua peta fitur.
- Peta fitur diteruskan ke lapisan pooling, di mana kernel pooling 2x2 mengurangi ukuran peta fitur.
- Lapisan penurunan secara acak menghapus beberapa peta fitur untuk membantu mencegah overfitting.
- Lapisan perataan mengambil array dari peta fitur yang tersisa dan meratakannya menjadi vektor.
- Elemen vektor disalurkan ke dalam jaringan yang terhubung sepenuhnya, yang menghasilkan prediksi. Dalam hal ini, jaringan adalah model klasifikasi yang memprediksi probabilitas untuk tiga kemungkinan kelas gambar (segitiga, persegi, dan lingkaran).
Melatih model CNN
Seperti halnya jaringan neural mendalam, CNN dilatih dengan meneruskan batch data pelatihan melaluinya melalui beberapa epoch, menyesuaikan bobot dan nilai bias berdasarkan kerugian yang dihitung untuk setiap epoch. Dalam kasus CNN, backpropagation bobot yang disesuaikan mencakup bobot kernel filter yang digunakan dalam lapisan konvolusional serta bobot yang digunakan dalam lapisan yang sepenuhnya terhubung.