Mempelajari Spark Lebih Lanjut
Untuk mendapatkan pemahaman yang lebih baik tentang cara memproses dan menganalisis data dengan Apache Spark di Azure Databricks, Anda harus memahami arsitektur yang mendasarinya.
Ringkasan tingkat tinggi
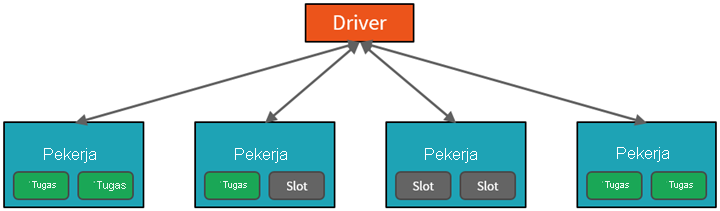
Dari tingkat tinggi, layanan Azure Databricks meluncurkan dan mengelola kluster Apache Spark dalam langganan Azure Anda. Cluster Apache Spark adalah kelompok komputer yang diperlakukan sebagai satu komputer dan menangani eksekusi perintah yang dikeluarkan dari notebook. Kluster memungkinkan pemrosesan data diparalelkan di banyak komputer untuk meningkatkan skala dan performa. Kluster terdiri dari node driver dan pekerja Spark. Node driver mengirimkan pekerjaan ke node dan memerintahkannya untuk menarik data dari sumber data tertentu.
Di Databricks, antarmuka notebook biasanya merupakan program driver. Program driver ini berisi perulangan utama untuk program dan membuat himpunan data terdistribusi pada kluster, kemudian menerapkan operasi ke himpunan data tersebut. Program driver mengakses Apache Spark melalui objek SparkSession terlepas dari lokasi penyebaran.
Microsoft Azure mengelola kluster, dan menskalakannya secara otomatis sesuai kebutuhan berdasarkan penggunaan Anda dan pengaturan yang digunakan saat mengonfigurasi kluster. Penghentian otomatis juga dapat diaktifkan, yang memungkinkan Azure untuk menghentikan klaster setelah beberapa menit tidak aktif.
Detail pekerjaan Spark
Pekerjaan yang dikirimkan ke kluster dibagi menjadi sebanyak mungkin pekerjaan independen yang diperlukan. Ini adalah bagaimana pekerjaan didistribusikan di seluruh node Cluster. Pekerjaan dibagi lagi menjadi tugas. Input ke pekerjaan dipartisi menjadi satu atau lebih partisi. Partisi ini adalah unit kerja untuk setiap slot. Di antara tugas, partisi mungkin perlu diatur ulang dan dibagikan melalui jaringan.
Rahasia performa tinggi Spark adalah paralelisme. Penskalaan vertikal (dengan menambahkan sumber daya ke satu komputer) terbatas pada jumlah RAM, Utas, dan kecepatan CPU yang terbatas; tetapi kluster menskalakan secara horizontal, menambahkan node baru ke kluster sesuai kebutuhan.
Spark memparalelkan pekerjaan di dua tingkat:
- Tingkat paralelisasi pertama adalah Eksekutor - mesin virtual Java (JVM) yang berjalan pada node pekerja, biasanya, satu instans per node.
- Tingkat paralelisasi kedua adalah slot - yang jumlahnya ditentukan oleh jumlah core dan CPU setiap node.
- Setiap eksekutor memiliki beberapa slot tempat tugas paralel dapat ditetapkan.
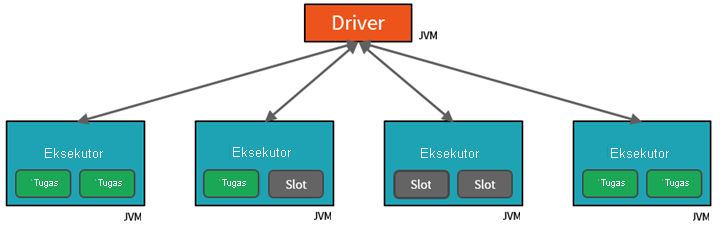
JVM secara alami bersifat multi-utas, tetapi JVM tunggal, seperti yang mengoordinasikan pekerjaan pada driver, memiliki batas atas yang terbatas. Dengan membagi pekerjaan menjadi tugas, driver dapat menetapkan unit pekerjaan ke *slot di eksekutor pada node pekerja untuk eksekusi paralel. Selain itu, driver menentukan cara mempartisi data sehingga dapat didistribusikan untuk pemrosesan paralel. Jadi, driver menetapkan partisi data untuk setiap tugas sehingga setiap tugas mengetahui bagian data mana yang akan diproses. Setelah dimulai, setiap tugas akan mengambil partisi data yang ditetapkan untuknya.
Pekerjaan dan tahapan
Tergantung pada pekerjaan yang dilakukan, beberapa pekerjaan paralel mungkin diperlukan. Setiap pekerjaan dibagi menjadi beberapa tahapan. Analogi yang lebih mudah adalah membayangkan bahwa pekerjaannya adalah membangun rumah:
- Tahap pertama adalah meletakkan fondasi.
- Tahap kedua adalah mendirikan dinding.
- Tahap ketiga adalah menambahkan atap.
Mencoba melakukan salah satu dari langkah-langkah ini tidak masuk akal, dan mungkin sebenarnya tidak mungkin. Demikian pula, Spark memecah setiap pekerjaan menjadi beberapa tahapan untuk memastikan semuanya dilakukan dalam urutan yang benar.