Buat kluster Spark
Anda dapat membuat satu atau beberapa kluster di ruang kerja Azure Databricks anda dengan menggunakan portal Azure Databricks.
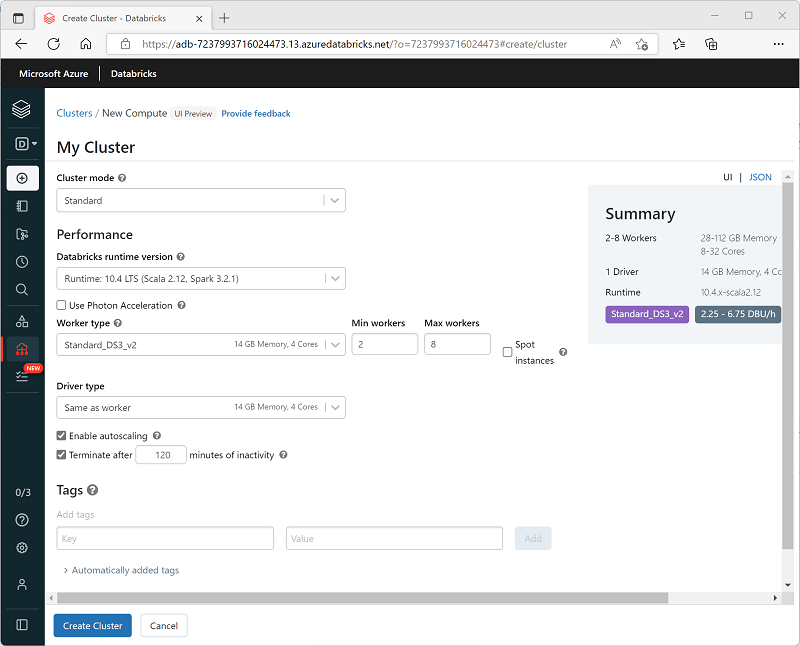
Saat membuat kluster, Anda dapat menentukan pengaturan konfigurasi, termasuk:
- Nama kluster.
- Mode kluster, yang dapat berupa:
- Standar: Cocok untuk beban kerja pengguna tunggal yang memerlukan beberapa node pekerja.
- Konkurensi Tinggi: Cocok untuk beban kerja di mana beberapa pengguna akan menggunakan kluster secara bersamaan.
- Simpul Tunggal: Cocok untuk beban kerja atau pengujian kecil, di mana hanya satu simpul pekerja yang diperlukan.
- Versi Databricks Runtime yang akan digunakan dalam kluster; yang menentukan versi Spark dan komponen individual seperti Python, Scala, dan komponen lain yang diinstal.
- Jenis mesin virtual (VM) yang digunakan untuk simpul pekerja dalam kluster.
- Jumlah minimum dan maksimum simpul pekerja dalam kluster.
- Jenis VM yang digunakan untuk simpul driver dalam kluster.
- Apakah kluster mendukung penskalaan otomatis untuk mengubah ukuran kluster secara dinamis.
- Durasi kluster dapat tetap diam sebelum dimatikan secara otomatis.
Cara Azure mengelola sumber daya kluster
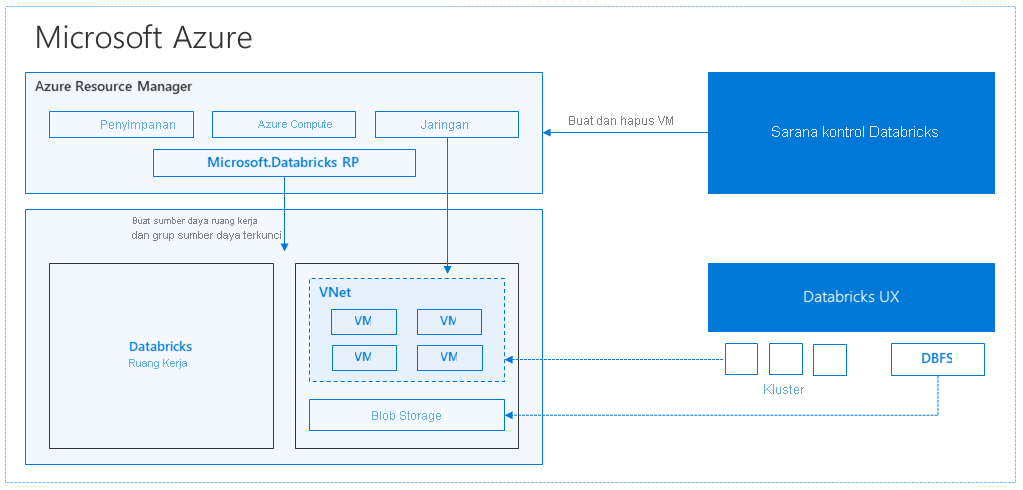
Saat Anda membuat ruang kerja Azure Databricks, appliance Databricks disebarkan sebagai sumber daya Azure di langganan Anda. Saat Anda membuat kluster di ruang kerja, Anda menentukan jenis dan ukuran mesin virtual (VM) yang akan digunakan untuk simpul driver dan pekerja, dan beberapa opsi konfigurasi lainnya, tetapi Azure Databricks mengelola semua aspek kluster lainnya.
Appliance Databricks disebarkan ke Azure sebagai grup sumber daya terkelola dalam langganan Anda. Grup sumber daya ini berisi VM driver dan pekerja untuk kluster Anda, beserta sumber daya lain yang diperlukan, termasuk jaringan virtual, grup keamanan, dan akun penyimpanan. Semua metadata untuk klaster Anda, seperti tugas terjadwal, disimpan dalam Database Azure dengan replikasi geografis untuk toleransi kesalahan.
Secara internal, Azure Kubernetes Service (AKS) digunakan untuk menjalankan sarana-kontrol dan data-plane Azure Databricks melalui kontainer yang berjalan pada perangkat keras Azure (VM Dv3) generasi terbaru, dengan NvMe SSD yang mampu menghasilkan latensi 100us pada mesin virtual Azure kinerja tinggi dengan jaringan yang dipercepat. Azure Databricks menggunakan fitur Azure ini untuk lebih meningkatkan kinerja Spark. Setelah layanan dalam grup sumber daya terkelola Anda siap, Anda dapat mengelola kluster Databricks melalui UI Azure Databricks dan melalui fitur seperti penskalaan otomatis dan penghentian otomatis.
Catatan
Anda juga memiliki opsi untuk melampirkan kluster Anda ke kumpulan simpul diam untuk mengurangi waktu memulai kluster. Untuk informasi selengkapnya, lihat Kumpulan dalam dokumentasi Azure Databricks.