Menggunakan Spark di notebook
Anda dapat menjalankan berbagai jenis aplikasi di Spark, termasuk kode dalam skrip Python atau Scala, kode Java yang dikompilasi sebagai Java Archive (JAR), dan lainnya. Spark umumnya digunakan dalam dua jenis beban kerja:
- Pekerjaan pemrosesan batch atau streaming untuk menyerap, membersihkan, dan mengubah data - sering kali berjalan sebagai bagian dari alur otomatis.
- Sesi analitik interaktif untuk mengeksplorasi, menganalisis, dan memvisualisasikan data.
Menjalankan kode Spark di notebook
Azure Databricks menyertakan antarmuka notebook terintegrasi untuk bekerja dengan Spark. Notebook menyediakan cara intuitif untuk menggabungkan kode dengan catatan Markdown, yang biasa digunakan oleh ilmuwan data dan analis data. Tampilan dan nuansa pengalaman notebook terintegrasi dalam Azure Databricks mirip dengan notebook Jupyter - platform notebook sumber terbuka yang populer.
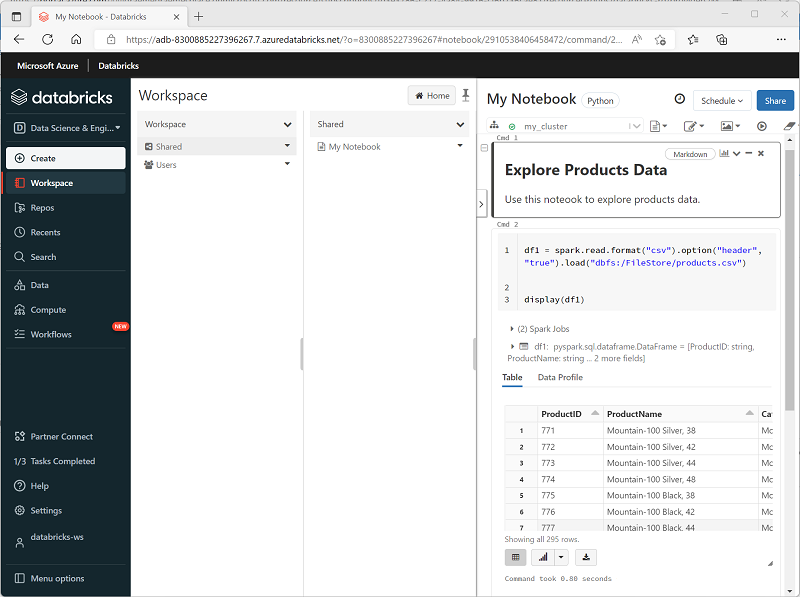
Notebook terdiri dari satu atau lebih sel, yang masing-masing berisi kode atau markdown. Sel kode di notebook memiliki beberapa fitur yang dapat membantu Anda menjadi lebih produktif, antara lain:
- Penyorotan sintaksis dan dukungan kesalahan.
- Pelengkapan otomatis kode.
- Visualisasi data interaktif.
- Kemampuan untuk mengekspor hasil.
Tip
Untuk mempelajari selengkapnya tentang bekerja dengan notebook di Azure Databricks, lihat artikel Notebooks dalam dokumentasi Azure Databricks.