Memvisualisasikan data
Salah satu cara paling intuitif untuk menganalisis hasil kueri data adalah dengan memvisualisasikannya sebagai diagram. Notebooks di Azure Databricks menyediakan kemampuan pembuatan bagan di antarmuka pengguna, dan ketika fungsionalitas tersebut tidak menyediakan hal yang dibutuhkan, Anda dapat menggunakan salah satu dari banyak pustaka grafis Python untuk membuat dan menampilkan visualisasi data di notebook.
Menggunakan diagram notebook bawaan
Saat menampilkan kerangka data atau menjalankan kueri SQL di notebook Spark di Azure Databricks, hasilnya ditampilkan di bagian sel kode. Secara default, hasil dirender sebagai tabel, tetapi Anda juga dapat melihat hasil sebagai visualisasi dan menyesuaikan cara bagan menampilkan data, seperti yang ditunjukkan di sini:
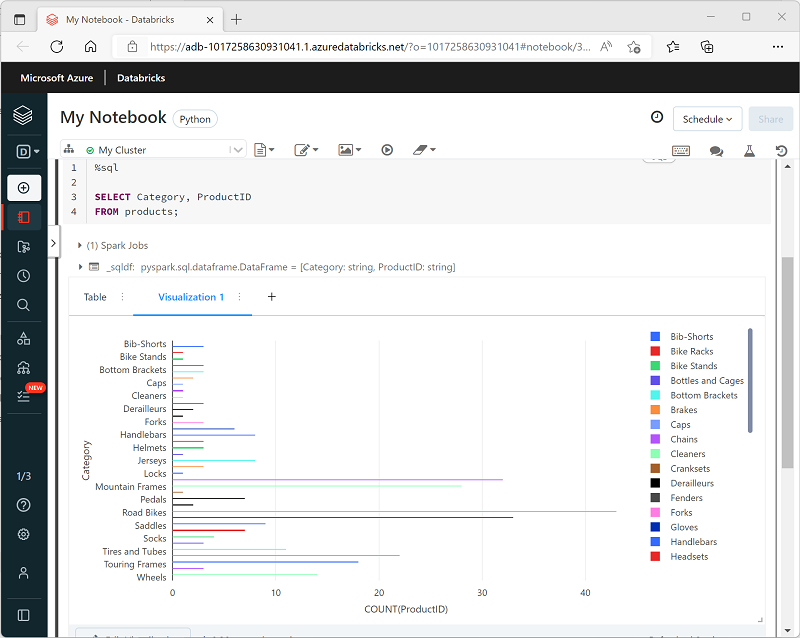
Fungsi visualisasi bawaan di notebook berguna saat Anda ingin meringkas data secara visual dengan cepat. Saat Anda ingin memiliki kontrol lebih banyak tentang cara data diformat, atau untuk menampilkan nilai yang telah Anda kumpulkan dalam kueri, Anda harus mempertimbangkan untuk menggunakan paket grafik untuk membuat visualisasi Anda sendiri.
Menggunakan paket grafik dalam kode
Ada banyak paket grafik yang dapat Anda gunakan untuk membuat visualisasi data dalam kode. Secara khusus, Python mendukung banyak pilihan paket; kebanyakan dari paket tersebut dibangun di pustaka Matplotlib dasar. Output dari pustaka grafik dapat dirender dalam notebook, sehingga memudahkan untuk menggabungkan kode untuk menyerap dan memanipulasi data dengan visualisasi data sebaris dan sel markdown untuk memberikan komentar.
Misalnya, Anda dapat menggunakan kode PySpark berikut untuk menggabungkan data dari data produk hipotetis yang dieksplorasi sebelumnya dalam modul ini, dan menggunakan Matplotlib untuk membuat diagram dari data yang dikumpulkan.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Pustaka Matplotlib mengharuskan data berada dalam kerangka data Pandas daripada kerangka data Spark, jadi metode toPandas digunakan untuk mengonversinya. Kode kemudian membuat gambar dengan ukuran tertentu dan mencatat plot diagram batang dengan beberapa konfigurasi properti kustom sebelum menampilkan plot yang dihasilkan.
Diagram yang dihasilkan oleh kode akan terlihat mirip dengan gambar berikut:
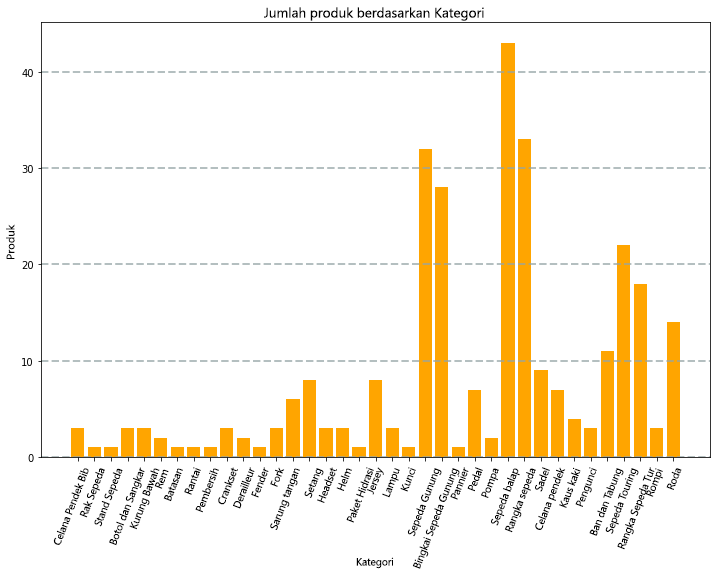
Anda dapat menggunakan pustaka Matplotlib untuk membuat berbagai jenis diagram; atau jika diinginkan, Anda dapat menggunakan pustaka lain seperti Seaborn untuk membuat diagram yang sangat disesuaikan.
Catatan
Pustaka Matplotlib dan Seaborn mungkin sudah diinstal pada kluster Databricks, bergantung pada Runtime Databricks untuk kluster. Jika tidak, atau jika Anda ingin menggunakan pustaka lain yang belum diinstal, Anda dapat menambahkannya ke kluster. Lihat Pustaka Kluster di dokumentasi Azure Databricks untuk detailnya.