Having a problem with nodes being removed from active failover cluster membership
This article introduces how to resolve the problems in which nodes are removed from active failover cluster membership randomly.
Symptoms
When the issue occurs, you're seeing events like this event logged in your system event log:
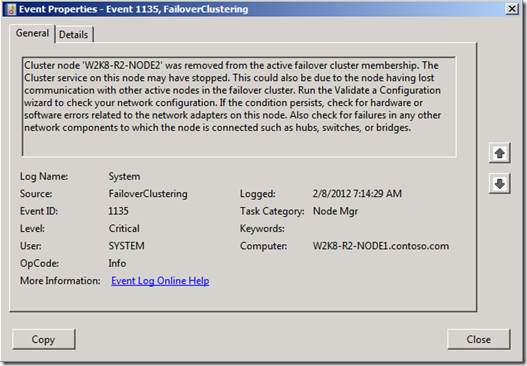
This event is logged on all nodes in the Cluster except for the node that was removed. The reason for this event is because one of the nodes in the Cluster marked that node as down. It then notifies all of the other nodes of the event. When the nodes are notified, they discontinue and tear down their heartbeat connections to the downed node.
What caused the node to be marked down
All nodes in a Windows Server Failover Cluster talk to each other over the networks that are set to allow cluster network communication on this network. The nodes send out heartbeat packets across these networks to all of the other nodes. These packets are supposed to be received by the other nodes and then a response is sent back. Each node in the Cluster has its own heartbeats that it's going to monitor to ensure the network is up and the other nodes are up. The following example should help clarify this behavior:

If any one of these packets isn't returned, then the specific heartbeat is considered failed. For example, W2K8-R2-NODE2 sends a request and receives a response from W2K8-R2-NODE1 to a heartbeat packet so it determines the network and the node is up. If W2K8-R2-NODE1 sends a request to W2K8-R2-NODE2 and W2K8-R2-NODE1 doesn't get the response, it's considered a lost heartbeat and W2K8-R2-NODE1 keeps track of it. This missed response can have W2K8-R2-NODE1 show the network as down until another heartbeat request is received.
By default, Cluster nodes have a limit of five failures in 5 seconds before the connection is marked down. So if W2K8-R2-NODE1 doesn't receive the response five times in the time period, it considers that particular route to W2K8-R2-NODE2 to be down. If other routes are still considered to be up, W2K8-R2-NODE2 will remain as an active member.
If all routes are marked down for W2K8-R2-NODE2, it's removed from active failover cluster membership and the Event 1135 that you see in the first section is logged. On W2K8-R2-NODE2, the Cluster Service is terminated and then restarted so it can try to rejoin the Cluster.
For more information on how we handle specific routes going down with three or more nodes, see "Partitioned" Cluster Networks blog that was written by Jeff Hughes.
Now that we know how the heartbeat process works, what are some of the known causes for the process to fail
Actual network hardware failures. If the packet is lost on the wire somewhere between the nodes, then the heartbeats fail. A network trace from both nodes involved will reveal this.
The profile for your network connections could possibly be bouncing from Domain to Public and back to Domain again. During the transition of these changes, network I/O can be blocked. You can check to see if this is the case by looking at the Network Profile Operational log. You can find this log by opening the Event Viewer and navigating to Applications and Services Logs\Microsoft\Windows\NetworkProfile\Operational. Look at the events in this log on the node that was mentioned in the Event ID 1135 and see if the profile was changing at this time. If so, see The network location profile changes from "Domain" to "Public" in Windows 7 or in Windows Server 2008 R2.
You have IPv6 enabled on the servers, but have the following two rules disabled for Inbound and Outbound in the Windows Firewall:
- Core Networking - Neighbor Discovery Advertisement
- Core Networking - Neighbor Discovery Solicitation
Anti-virus software could be interfering with this process also. If you suspect this, test by disabling or uninstalling the software. Do this at your own risk because you're unprotected from viruses at this point.
Latency on your network could also cause this to happen. The packets might not be lost between the nodes, but they might not get to the nodes fast enough before the timeout period expires.
IPv6 is the default protocol that Failover Clustering will use for its heartbeats. The heartbeat itself is a UDP unicast network packet that communicates over Port 3343. If there are switches, firewalls, or routers not configured properly to allow this traffic through, you can experience issues like this.
IPsec security policy refreshes can also cause this problem. The specific issue is that during an IPSec group policy update all IPsec Security Associations (SAs) are torn down by Windows Firewall with Advanced Security (WFAS). While this is happening, all network connectivity is blocked. When renegotiating the Security Associations if there are delays in performing authentication with Active Directory, these delays (where all network communication is blocked) will also block cluster heartbeats from getting through and cause cluster health monitoring to detect nodes as down if they don't respond within the 5-second threshold.
Old or out-of-date network card drivers and/or firmware. At times, a simple misconfiguration of the network card or switch can also cause loss of heartbeats.
Modern network cards and virtual network cards might be experiencing packet loss. This can be tracked by opening Performance Monitor and adding the counter "Network Interface\Packets Received Discarded." This counter is cumulative and only increases until the server is rebooted. Seeing a large number of packets dropped here could be a sign that the receive buffers on the network card are set too low or that the server is performing slowly and can't handle the inbound traffic. Each network card manufacturer chooses whether to expose these settings in the properties of the network card, therefore you need to refer to the manufacturer's website to learn how to increase these values and the recommended values should be used. If you're running on VMware, the following blog talks about this in a little more detail including how to tell if this is the issue as well as points you to the VMware article on the settings to change.
Nodes being removed from Failover Cluster membership on VMware ESX
These are the most common reasons that these events are logged, but there could be other reasons also. The point of this blog was to give you some insight into the process and also give ideas of what to look for. Some will raise the following values to their maximum values to try to get this problem to stop.
| Parameter | Default | Range |
|---|---|---|
| SameSubnetDelay | 1000 milliseconds | 250-2000 milliseconds |
| CrossSubnetDelay | 1000 milliseconds | 250-4000 milliseconds |
| SameSubnetThreshold | 5 | 3-10 |
| CrossSubnetThreshold | 5 | 3-10 |
Increasing these values to their maximum might make the event and node removal go away, it just masks the problem. It doesn't fix anything. The best thing to do is to find out the root cause of the heartbeat failures and get it fixed. The only real need for increasing these values is in a multi-site scenario where nodes reside in different locations and network latency can't be overcome.