Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini memberikan rekomendasi untuk perencanaan kapasitas untuk Active Directory Domain Services (AD DS).
Tujuan perencanaan kapasitas
Perencanaan kapasitas tidak sama dengan memecahkan masalah insiden performa. Tujuan perencanaan kapasitas adalah:
- Menerapkan dan mengoperasikan lingkungan dengan benar.
- Minimalkan waktu yang dihabiskan untuk memecahkan masalah performa.
Dalam perencanaan kapasitas, organisasi mungkin memiliki target dasar pemanfaatan prosesor 40% selama periode puncak untuk memenuhi persyaratan performa klien dan memberikan cukup waktu untuk meningkatkan perangkat keras di pusat data. Sementara itu, mereka menetapkan ambang pemberitahuan pemantauan mereka untuk masalah performa pada 90% selama interval lima menit.
Ketika Anda terus melebihi ambang manajemen kapasitas, maka menambahkan lebih banyak atau lebih cepat prosesor untuk meningkatkan kapasitas atau menskalakan layanan di beberapa server akan menjadi solusi. Ambang pemberitahuan performa memberi tahu Anda kapan Anda perlu mengambil tindakan segera ketika masalah performa berdampak negatif pada pengalaman klien. Sebaliknya, solusi pemecahan masalah akan lebih berkaitan dengan mengatasi peristiwa satu kali.
Manajemen kapasitas seperti langkah-langkah pencegahan yang akan Anda ambil untuk menghindari kecelakaan mobil, seperti mengemudi defensif, memastikan rem berfungsi dengan baik, dan sebagainya. Pemecahan masalah performa lebih seperti ketika polisi, pemadam kebakaran, dan profesional medis darurat merespons kecelakaan.
Selama beberapa tahun terakhir, panduan perencanaan kapasitas untuk sistem peningkatan skala telah berubah secara dramatis. Perubahan berikut dalam arsitektur sistem menantang asumsi mendasar tentang merancang dan menskalakan layanan:
- Platform server 64-bit
- Virtualisasi
- Peningkatan perhatian terhadap konsumsi daya
- Penyimpanan SSD
- Skenario cloud
Pendekatan perencanaan kapasitas juga beralih dari latihan perencanaan berbasis server ke latihan berbasis layanan. Active Directory Domain Services (AD DS), layanan terdistribusi yang matang yang digunakan banyak produk Microsoft dan pihak ketiga sebagai backend, sekarang menjadi salah satu produk paling penting dalam memastikan aplikasi Anda yang lain memiliki kapasitas yang diperlukan untuk dijalankan.
Informasi penting yang perlu dipertimbangkan sebelum Anda mulai merencanakan
Untuk mendapatkan hasil maksimal dari artikel ini, Anda harus melakukan hal-hal berikut:
- Pastikan Anda telah membaca dan memahami Panduan Penyetelan Performa untuk Windows Server 2012 R2.
- Pahami bahwa platform Windows Server adalah arsitektur berbasis x64. Selain itu, Anda harus memahami bahwa panduan artikel ini masih berlaku bahkan jika lingkungan Direktori Aktif Anda diinstal pada Windows Server 2003 x86 (sekarang di luar akhir siklus hidup dukungan) dan memiliki pohon informasi direktori (DIT) yang lebih kecil dari 1,5 GB dan dapat dengan mudah disimpan dalam memori.
- Pahami bahwa perencanaan kapasitas adalah proses berkelanjutan, jadi Anda harus secara teratur meninjau seberapa baik lingkungan yang Anda bangun memenuhi harapan Anda.
- Pahami bahwa pengoptimalan terjadi pada beberapa siklus hidup perangkat keras saat biaya perangkat keras berubah. Misalnya, jika memori menjadi lebih murah, biaya per inti menurun, atau harga opsi penyimpanan yang berbeda berubah.
- Rencanakan periode sibuk puncak setiap hari. Kami sarankan Anda membuat paket berdasarkan interval 30 menit atau jam. Interval yang lebih besar dari satu jam dapat bersembunyi ketika layanan Anda benar-benar mencapai kapasitas puncak, dan interval kurang dari 30 menit dapat memberi Anda informasi yang tidak akurat yang membuat peningkatan sementara terlihat lebih penting daripada yang sebenarnya.
- Rencanakan pertumbuhan selama siklus hidup perangkat keras untuk perusahaan. Perencanaan ini dapat mencakup strategi untuk meningkatkan atau menambahkan perangkat keras dengan cara yang terhuyung-huyung, atau refresh lengkap setiap tiga hingga lima tahun. Setiap rencana pertumbuhan mengharuskan Anda memperkirakan berapa banyak beban pada Direktori Aktif tumbuh. Data historis dapat membantu Anda membuat penilaian yang lebih akurat.
- Rencanakan toleransi kesalahan. Setelah Anda memperoleh perkiraan N, rencanakan skenario yang mencakup N - 1, N - 2, dan N - x.
Berdasarkan rencana pertumbuhan Anda, tambahkan server tambahan sesuai dengan kebutuhan organisasi untuk memastikan bahwa kehilangan satu atau beberapa server tidak menyebabkan sistem melebihi perkiraan kapasitas puncak maksimum.
Ingat juga bahwa Anda harus mengintegrasikan rencana pertumbuhan dan toleransi kesalahan Anda. Misalnya, jika Anda tahu penyebaran Anda saat ini memerlukan satu pengendali domain (DC) untuk mendukung beban tetapi perkiraan Anda mengatakan beban akan dua kali lipat pada tahun depan dan memerlukan dua DC untuk dibawa, maka sistem Anda tidak memiliki kapasitas yang cukup untuk mendukung toleransi kesalahan. Untuk mencegah kurangnya kapasitas ini, Anda harus berencana untuk memulai dengan tiga DC. Jika anggaran Anda tidak memungkinkan untuk tiga DC, Anda juga dapat memulai dengan dua DC, maka rencanakan untuk menambahkan yang ketiga setelah tiga atau enam bulan.
Catatan
Menambahkan aplikasi sadar Direktori Aktif mungkin berdampak nyata pada beban DC, apakah beban berasal dari server aplikasi atau klien.
Siklus perencanaan kapasitas tiga bagian
Sebelum memulai siklus perencanaan, Anda perlu memutuskan kualitas layanan apa yang diperlukan organisasi Anda. Semua rekomendasi dan panduan dalam artikel ini adalah untuk lingkungan performa yang optimal. Namun, Anda dapat secara selektif melonggarkannya jika Anda tidak memerlukan pengoptimalan. Misalnya, jika organisasi Anda membutuhkan tingkat konkurensi yang lebih tinggi dan pengalaman pengguna yang lebih konsisten, Anda harus melihat menyiapkan pusat data. Pusat data memungkinkan Anda memperhatikan redundansi yang lebih besar dan meminimalkan penyempitan sistem dan infrastruktur. Sebaliknya, jika Anda merencanakan penyebaran untuk kantor satelit hanya dengan beberapa pengguna, Anda tidak perlu khawatir sebanyak tentang pengoptimalan perangkat keras dan infrastruktur, yang memungkinkan Anda memilih opsi bernilai lebih rendah.
Selanjutnya, Anda harus memutuskan apakah akan menggunakan komputer virtual atau fisik. Dari sudut simpul perencanaan kapasitas, tidak ada jawaban yang benar atau salah. Namun, Anda perlu diingat bahwa setiap skenario memberi Anda serangkaian variabel yang berbeda untuk dikerjakan.
Skenario virtualisasi memberi Anda dua opsi:
- Pemetaan langsung, di mana Anda hanya memiliki satu tamu per host.
- Skenario host bersama, di mana Anda memiliki beberapa tamu per host.
Anda dapat memperlakukan skenario pemetaan langsung secara identik dengan host fisik. Jika Anda memilih skenario host bersama, ini memperkenalkan variabel lain yang harus Anda pertimbangkan di bagian selanjutnya. Host bersama juga bersaing untuk sumber daya dengan Active Directory Domain Services (AD DS), yang dapat memengaruhi performa sistem dan pengalaman pengguna.
Sekarang setelah kita menjawab pertanyaan-pertanyaan itu, mari kita lihat siklus perencanaan kapasitas itu sendiri. Setiap siklus perencanaan kapasitas melibatkan proses tiga langkah:
- Ukur lingkungan yang ada, tentukan di mana penyempitan sistem saat ini berada, dan dapatkan dasar-dasar lingkungan yang diperlukan untuk merencanakan jumlah kapasitas kebutuhan penyebaran Anda.
- Tentukan perangkat keras apa yang Anda butuhkan berdasarkan persyaratan kapasitas Anda.
- Pantau dan validasi bahwa infrastruktur yang Anda siapkan beroperasi dalam spesifikasi. Data yang Anda kumpulkan dalam langkah ini menjadi garis besar untuk siklus perencanaan kapasitas berikutnya.
Menerapkan proses
Untuk mengoptimalkan performa, pastikan komponen utama berikut dipilih dengan benar dan disetel ke beban aplikasi:
- Memori
- Jaringan
- Storage
- Pemroses
- Logon Jaringan
Persyaratan penyimpanan dasar untuk AD DS dan perilaku umum perangkat lunak klien yang kompatibel memungkinkan lingkungan dengan sebanyak 10.000 hingga 20.000 pengguna untuk mengabaikan perencanaan kapasitas untuk perangkat keras fisik, karena sebagian besar sistem kelas server modern sudah dapat menangani beban sebesar itu. Namun, tabel dalam tabel ringkasan pengumpulan data menjelaskan cara mengevaluasi lingkungan yang ada untuk memilih perangkat keras yang tepat. Bagian setelah itu masuk ke detail lebih lanjut tentang rekomendasi dasar dan prinsip khusus lingkungan untuk perangkat keras untuk membantu admin AD DS mengevaluasi infrastruktur mereka.
Informasi lain yang harus Anda ingat saat merencanakan:
- Ukuran apa pun berdasarkan data saat ini hanya akurat untuk lingkungan saat ini.
- Saat membuat perkiraan, harapkan permintaan tumbuh selama siklus hidup perangkat keras.
- Akomodasi pertumbuhan di masa depan dengan menentukan apakah Anda harus mengubah ukuran lingkungan Anda hari ini atau secara bertahap menambahkan kapasitas selama siklus hidup.
- Semua prinsip dan metodologi perencanaan kapasitas yang akan Anda terapkan untuk penyebaran fisik juga berlaku untuk penyebaran virtual. Namun, saat merencanakan lingkungan virtual, Anda perlu ingat untuk menambahkan overhead virtualisasi ke perencanaan atau perkiraan terkait domain apa pun.
- Perencanaan kapasitas adalah prediksi, bukan nilai yang benar sempurna, jadi jangan harap itu akurat. Selalu ingat untuk menyesuaikan kapasitas sesuai kebutuhan dan terus memvalidasi bahwa lingkungan Anda berfungsi seperti yang dimaksudkan.
Tabel ringkasan pengumpulan data
Tabel berikut mencantumkan dan menjelaskan kriteria untuk menentukan perkiraan perangkat keras Anda.
Lingkungan kerja
| Komponen | Perkiraan |
|---|---|
| Ukuran Penyimpanan/Database | 40 KB hingga 60 KB untuk setiap pengguna |
| MAA | Ukuran Database Rekomendasi sistem operasi dasar Aplikasi pihak ketiga |
| Jaringan | 1 GB |
| CPU | 1.000 pengguna bersamaan untuk setiap inti |
Kriteria evaluasi tingkat tinggi
| Komponen | Kriteria evaluasi | Pertimbangan perencanaan |
|---|---|---|
| Ukuran penyimpanan/database | Defragmentasi offline | |
| Performa penyimpanan/database |
|
|
| MAA |
|
|
| Jaringan |
|
|
| CPU |
|
|
| Masuk Jaringan |
|
|
Perencanaan
Untuk waktu yang lama, rekomendasi yang biasa untuk ukuran AD DS adalah memasukkan RAM sebanyak ukuran database. Sekarang setelah lingkungan AD DS dan ekosistem yang mengonsumsinya telah tumbuh jauh lebih besar, hal-hal telah berubah. Meskipun peningkatan daya komputasi dan peralihan dari arsitektur x86 ke x64 membuat aspek ukuran yang lebih halus untuk performa yang tidak relevan bagi pelanggan yang menjalankan AD DS pada komputer fisik, virtualisasi telah membuat penyetelan menjadi perhatian yang jauh lebih besar.
Untuk mengatasi masalah tersebut, bagian berikut menjelaskan cara menentukan dan merencanakan tuntutan Direktori Aktif sebagai layanan. Anda dapat menerapkan panduan ini ke lingkungan apa pun terlepas dari apakah lingkungan Anda bersifat fisik, virtual, atau campuran. Untuk memaksimalkan performa Anda, tujuan Anda adalah untuk mendapatkan lingkungan AD DS Anda sedekat mungkin dengan prosesor yang terikat.
MAA
Semakin banyak penyimpanan yang dapat Anda cache di RAM, semakin sedikit kebutuhan untuk pergi ke disk. Untuk memaksimalkan skalabilitas server, jumlah minimum RAM yang Anda gunakan harus sama dengan jumlah ukuran database saat ini, ukuran total nilai sistem, jumlah yang direkomendasikan untuk sistem operasi Anda, dan rekomendasi vendor untuk agen (program antivirus, pemantauan, pencadangan, dan sebagainya). Anda juga harus menyertakan RAM tambahan untuk mengakomodasi pertumbuhan di masa depan selama masa pakai server. Perkiraan ini akan berubah berdasarkan pertumbuhan database dan perubahan lingkungan.
Untuk lingkungan di mana memaksimalkan RAM tidak hemat biaya atau tidak layak, seperti lokasi satelit atau ketika Pohon Informasi Direktori (DIT) terlalu besar, lewati ke Penyimpanan untuk memastikan penyimpanan Anda dikonfigurasi dengan benar.
Hal penting lain yang perlu dipertimbangkan untuk ukuran memori adalah ukuran file halaman. Dalam ukuran disk, seperti hal lain yang terkait dengan memori, tujuannya adalah untuk meminimalkan penggunaan disk. Secara khusus, berapa banyak RAM yang Anda butuhkan untuk meminimalkan penomor? Beberapa bagian berikutnya harus memberi Anda informasi yang Anda butuhkan untuk menjawab pertanyaan ini. Pertimbangan lain untuk ukuran halaman yang tidak selalu memengaruhi performa AD DS adalah rekomendasi sistem operasi (OS) dan mengonfigurasi sistem Anda untuk cadangan memori.
Menentukan berapa banyak RAM yang dibutuhkan pengendali domain (DC) bisa sulit karena banyak faktor kompleks:
- Sistem yang ada tidak selalu dapat diandalkan indikator persyaratan RAM karena Local Security Authority Subsystem Service (LSSAS) memangkas RAM di bawah kondisi tekanan memori, persyaratan yang mengempis secara buatan.
- DC individual hanya perlu menyimpan data yang diminati klien mereka. Ini berarti data yang di-cache di lingkungan yang berbeda akan berubah tergantung pada jenis klien apa yang dikandungnya. Misalnya, DC di lingkungan dengan Server Exchange akan mengumpulkan data yang berbeda dari DC yang hanya mengautentikasi pengguna.
- Jumlah upaya yang Anda butuhkan untuk mengevaluasi RAM untuk setiap DC berdasarkan kasus per kasus sering berlebihan dan berubah saat lingkungan berubah.
Kriteria di balik rekomendasi dapat membantu Anda membuat keputusan yang lebih tepat:
- Semakin Banyak Anda cache dalam RAM, semakin sedikit Anda perlu pergi ke disk.
- Penyimpanan adalah komponen terlambat komputer. Akses data pada media penyimpanan berbasis spindle dan SSD adalah jutaan kali lebih lambat daripada akses data dalam RAM.
Pertimbangan virtualisasi untuk RAM
Tujuan Anda untuk mengoptimalkan RAM adalah untuk meminimalkan jumlah waktu yang dihabiskan untuk pergi ke disk. Anda juga harus menghindari penerapan memori berlebihan di host. Dalam skenario virtualisasi, memori yang terlalu berkomitmen adalah ketika sistem mengalokasikan lebih banyak RAM untuk tamu daripada apa yang ada di komputer fisik itu sendiri. Meskipun penerapan berlebihan tidak menjadi masalah sendiri, ketika total memori yang digunakan oleh semua tamu melebihi kemampuan RAM host, itu menyebabkan host ke halaman. Halaman membuat disk performa terikat dalam kasus di mana DC masuk ke file NTDS.nit atau halaman untuk mendapatkan data atau host masuk ke disk untuk mencoba mengakses data RAM. Akibatnya, proses ini sangat mengurangi performa dan pengalaman pengguna secara keseluruhan.
Contoh ringkasan perhitungan
| Komponen | Perkiraan memori (contoh) |
|---|---|
| RAM yang direkomendasikan sistem operasi dasar (Windows Server 2008) | 2 GB |
| Tugas internal LSASS | 200 MB |
| Agen pemantauan | 100 MB |
| Antivirus | 100 MB |
| Database (Katalog Global) | 8,5 GB |
| Bantalan agar pencadangan berjalan, administrator untuk masuk tanpa dampak | 1 GB |
| Jumlah | 12 GB |
Disarankan: 16 GB
Seiring waktu, lebih banyak data ditambahkan ke database, dan masa pakai server rata-rata sekitar tiga hingga lima tahun. Berdasarkan perkiraan pertumbuhan 333%, 16 GB adalah jumlah RAM yang wajar untuk dimasukkan ke server fisik.
Jaringan
Bagian ini adalah tentang mengevaluasi berapa banyak total bandwidth dan kapasitas jaringan yang dibutuhkan penyebaran Anda, termasuk kueri klien, pengaturan Kebijakan Grup, dan sebagainya. Anda dapat mengumpulkan data untuk membuat perkiraan Anda dengan menggunakan penghitung Network Interface(*)\Bytes Received/sec kinerja dan Network Interface(*)\Bytes Sent/sec . Interval sampel untuk penghitung Antarmuka Jaringan harus 15, 30, atau 60 menit. Apa pun yang kurang akan terlalu mudah menguap untuk pengukuran yang baik, dan apa pun yang lebih besar akan memuluskan puncak harian secara berlebihan.
Catatan
Umumnya, sebagian besar lalu lintas jaringan pada DC keluar karena DC merespons kueri klien. Akibatnya, bagian ini terutama berfokus pada lalu lintas keluar. Namun, kami juga menyarankan Anda juga mengevaluasi setiap lingkungan Anda untuk lalu lintas masuk. Anda juga dapat menggunakan panduan dalam artikel ini untuk mengevaluasi persyaratan lalu lintas jaringan masuk. Untuk informasi selengkapnya, lihat 929851: Rentang port dinamis default untuk TCP/IP telah berubah di Windows Vista dan di Windows Server 2008.
Kebutuhan bandwidth
Perencanaan untuk skalabilitas jaringan mencakup dua kategori yang berbeda: jumlah lalu lintas dan beban CPU dari lalu lintas jaringan.
Ada dua hal yang perlu Anda perhitungkan ketika perencanaan kapasitas untuk dukungan lalu lintas. Pertama, Anda perlu tahu berapa banyak Lalu Lintas Replikasi Direktori Aktif yang terjadi antara pusat data Anda. Kedua, Anda harus mengevaluasi lalu lintas klien-ke-server intrasite Anda. Lalu lintas intrasit terutama menerima permintaan kecil dari klien relatif terhadap sejumlah besar data yang dikirimnya kembali ke klien. 100 MB biasanya cukup untuk lingkungan dengan hingga 5.000 pengguna per server. Untuk lingkungan lebih dari 5.000 pengguna, kami sarankan Anda menggunakan adaptor jaringan 1 GB dan dukungan Receive Side Scaling (RSS).
Untuk mengevaluasi kapasitas lalu lintas intrasit, terutama dalam skenario konsolidasi server, Anda harus melihat penghitung kinerja di Network Interface(*)\Bytes/sec semua DC di situs, menambahkannya bersama-sama, lalu membagi jumlah dengan jumlah target DC. Cara mudah untuk menghitung angka ini adalah dengan membuka Monitor Keandalan dan Performa Windows dan melihat tampilan Area Bertumpuk . Pastikan semua penghitung diskalakan sama.
Mari kita lihat contoh cara yang lebih kompleks untuk memvalidasi bahwa aturan umum ini berlaku untuk lingkungan tertentu. Dalam contoh ini, kami membuat asumsi berikut:
- Tujuannya adalah untuk mengurangi jejak ke server sesedikitan mungkin. Idealnya, satu server membawa beban, lalu Anda menyebarkan server tambahan untuk redundansi (skenario n + 1).
- Dalam skenario ini, adaptor jaringan saat ini hanya mendukung 100 MB dan berada di lingkungan yang dialihkan.
- Pemanfaatan bandwidth jaringan target maksimum adalah 60% dalam skenario n (hilangnya DC).
- Setiap server memiliki sekitar 10.000 klien yang terhubung ke server tersebut.
Sekarang, mari kita lihat apa yang dikatakan bagan di Network Interface(*)\Bytes Sent/sec penghitung tentang contoh skenario ini:
- Hari kerja mulai ramping sekitar pukul 05.30 dan angin turun pukul 19.00.
- Periode puncak tersibuk adalah dari pukul 08.00 hingga 08.15, dengan lebih dari 25 byte dikirim per detik pada DC tersibuk.
Catatan
Semua data performa bersifat historis, sehingga titik data puncak pada pukul 08.15 menunjukkan beban dari pukul 08.00 hingga 08.15.
- Ada lonjakan sebelum pukul 04.00, dengan lebih dari 20 byte dikirim per detik pada DC tersibuk, yang dapat menunjukkan beban dari zona waktu yang berbeda atau aktivitas infrastruktur latar belakang, seperti cadangan. Karena puncaknya pada pukul 08.00 melebihi aktivitas ini, tidak relevan.
- Ada lima DC di situs ini.
- Beban maksimum adalah sekitar 5,5 MBps per DC, yang mewakili 44% dari koneksi 100 MB. Dengan menggunakan data ini, kita dapat memperkirakan bahwa total bandwidth yang diperlukan antara pukul 08.00 dan 08.15 adalah 28 MBps.
Catatan
Penghitung kirim/terima Antarmuka Jaringan dalam byte, tetapi bandwidth jaringan diukur dalam bit. Oleh karena itu, untuk menghitung total bandwidth, Anda harus melakukan 100 MB ÷ 8 = 12,5 MB dan 1 GB ÷ 8 = 128 MB.
Sekarang setelah kita meninjau data, kesimpulan apa yang dapat kita gambar darinya?
- Lingkungan saat ini memenuhi tingkat toleransi kesalahan n + 1 pada pemanfaatan target 60%. Mengambil satu sistem offline akan mengalihkan bandwidth per server dari sekitar 5,5 MBps (44%) menjadi sekitar 7 MBps (56%).
- Berdasarkan tujuan yang dinyatakan sebelumnya untuk mengonsolidasikan ke satu server, perubahan ini melebihi pemanfaatan target maksimum dan kemungkinan pemanfaatan koneksi 100 MB.
- Dengan koneksi 1 GB, nilai ini mewakili 22% dari total kapasitas.
- Dalam kondisi operasi normal dalam skenario n + 1, beban klien relatif merata pada sekitar 14 MBps per server atau 11% dari total kapasitas.
- Untuk memastikan Anda memiliki kapasitas yang cukup saat DC tidak tersedia, target operasi normal per server adalah sekitar 30% pemanfaatan jaringan atau 38 MBps per server. Target failover adalah pemanfaatan jaringan 60% atau 72 MBps per server.
Penyebaran sistem akhir harus memiliki adaptor jaringan 1 GB dan koneksi ke infrastruktur jaringan yang akan mendukung beban tersebut. Karena jumlah lalu lintas jaringan, beban CPU dari komunikasi jaringan berpotensi membatasi skalabilitas maksimum AD DS. Anda dapat menggunakan proses yang sama ini untuk memperkirakan komunikasi masuk ke DC. Namun, dalam sebagian besar skenario, Anda tidak perlu menghitung lalu lintas masuk karena lebih kecil dari lalu lintas keluar.
Penting untuk memastikan perangkat keras Anda mendukung RSS di lingkungan dengan lebih dari 5.000 pengguna per server. Untuk skenario lalu lintas jaringan tinggi, menyeimbangkan beban interupsi dapat menjadi hambatan. Anda dapat mendeteksi potensi hambatan Processor(*)\% Interrupt Time dengan memeriksa penghitung untuk melihat apakah waktu interupsi didistribusikan secara tidak merata di seluruh CPU. Pengontrol antarmuka jaringan (NIC) berkemampuan RSS dapat mengurangi batasan ini dan meningkatkan skalabilitas.
Catatan
Anda dapat mengambil pendekatan serupa untuk memperkirakan apakah Anda membutuhkan lebih banyak kapasitas saat mengonsolidasikan pusat data atau menghentikan DC di lokasi satelit. Untuk memperkirakan kapasitas yang diperlukan, cukup lihat data untuk lalu lintas keluar dan masuk ke klien. Hasilnya adalah jumlah lalu lintas od yang ada di tautan wide area network (WAN).
Dalam beberapa kasus, Anda mungkin mengalami lebih banyak lalu lintas dari yang diharapkan karena lalu lintas lebih lambat, seperti ketika pemeriksaan sertifikat gagal memenuhi batas waktu agresif pada WAN. Untuk alasan ini, ukuran dan pemanfaatan WAN harus menjadi proses yang berulang dan sedang berlangsung.
Pertimbangan virtualisasi untuk bandwidth jaringan
Rekomendasi umum untuk server fisik adalah 1 GB untuk server yang mendukung lebih dari 5.000 pengguna. Setelah beberapa tamu mulai berbagi infrastruktur sakelar virtual yang mendasar, Anda harus memperhatikan ekstra apakah host memiliki bandwidth jaringan yang memadai untuk mendukung semua tamu dalam sistem. Anda perlu mempertimbangkan bandwidth terlepas dari apakah jaringan menyertakan DC yang berjalan sebagai VM pada host dengan lalu lintas jaringan melalui sakelar virtual atau terhubung langsung ke sakelar fisik. Sakelar virtual adalah komponen di mana uplink harus mendukung jumlah data yang dikirimkan koneksi, yang berarti adaptor jaringan host fisik yang ditautkan ke sakelar harus dapat mendukung beban DC ditambah semua tamu lain yang berbagi sakelar virtual yang terhubung ke adaptor jaringan fisik.
Contoh ringkasan perhitungan jaringan
Tabel berikut berisi nilai dari contoh skenario yang dapat kita gunakan untuk menghitung kapasitas jaringan:
| Sistem | Bandwidth puncak |
|---|---|
| DC 1 | 6,5 MBps |
| DC 2 | 6,25 MBps |
| DC 3 | 6,25 MBps |
| DC 4 | 5,75 MBps |
| DC 5 | 4,75 MBps |
| Jumlah | 28,5 MBps |
Berdasarkan tabel ini, bandwidth yang direkomendasikan adalah 72 MBps (28,5 MBps ÷ 40%).
| Jumlah sistem target | Total bandwidth (dari atas) |
|---|---|
| 2 | 28,5 MBps |
| Menghasilkan perilaku normal | 28,5 ÷ 2 = 14,25 MBps |
Seperti biasa, Anda harus berasumsi bahwa beban klien akan meningkat dari waktu ke waktu, jadi Anda harus merencanakan pertumbuhan ini sedini mungkin. Kami menyarankan Anda merencanakan setidaknya 50% perkiraan pertumbuhan lalu lintas jaringan.
Storage
Ada dua hal yang harus Anda pertimbangkan ketika perencanaan kapasitas untuk penyimpanan:
- Kapasitas atau ukuran penyimpanan
- Performa
Meskipun kapasitas penting, penting untuk tidak mengabaikan performa. Dengan biaya perangkat keras saat ini, sebagian besar lingkungan tidak cukup besar untuk kedua faktor tersebut menjadi perhatian utama. Oleh karena itu, rekomendasi yang biasa adalah memasukkan RAM sebanyak ukuran database. Namun, rekomendasi ini mungkin berlebihan untuk lokasi satelit di lingkungan yang lebih besar.
Pengukuran
Mengevaluasi untuk penyimpanan
Dibandingkan dengan ketika Active Directory pertama kali tiba pada satu waktu ketika drive 4 GB dan 9 GB adalah ukuran drive yang paling umum, sekarang ukuran untuk Direktori Aktif bahkan bukan pertimbangan untuk semua kecuali lingkungan terbesar. Dengan ukuran hard drive terkecil yang tersedia dalam rentang 180 GB, seluruh sistem operasi, SYSVOL, dan NTDS.dit dapat dengan mudah muat pada satu drive. Akibatnya, kami sarankan Anda menghindari investasi terlalu berat di area ini.
Satu-satunya rekomendasi kami adalah Anda memastikan 110% dari ukuran NTS.dit tersedia sehingga Anda dapat mendefragmentasi penyimpanan Anda. Di luar itu, Anda harus mengambil pertimbangan biasa dalam mengakomodasi pertumbuhan di masa depan.
Jika Anda akan mengevaluasi penyimpanan Anda, maka pertama-tama Anda harus mengevaluasi seberapa besar NTDS.dit dan SYSVOL harus. Pengukuran ini akan membantu Anda mengukur alokasi disk tetap dan RAM. Karena komponennya biayanya relatif rendah, Anda tidak perlu super tepat saat melakukan matematika. Untuk informasi selengkapnya tentang evaluasi penyimpanan, lihat Batas Penyimpanan dan Perkiraan Pertumbuhan untuk Pengguna Direktori Aktif dan Unit Organisasi.
Catatan
Artikel yang ditautkan dalam paragraf sebelumnya didasarkan pada perkiraan ukuran data yang dibuat selama rilis Direktori Aktif di Windows 2000. Saat membuat perkiraan Anda sendiri, gunakan ukuran objek yang mencerminkan ukuran objek aktual di lingkungan Anda.
Saat Anda meninjau lingkungan yang ada dengan beberapa domain, Anda mungkin melihat variasi dalam ukuran database. Saat Anda menemukan variasi ini, gunakan katalog global terkecil (GC) dan ukuran non-GC.
Ukuran database dapat bervariasi di antara versi OS. DC yang menjalankan versi OS sebelumnya seperti Windows Server 2003 memiliki ukuran database yang lebih kecil daripada yang menjalankan versi yang lebih baru seperti Windows Server 2008 R2. DC yang memiliki fitur seperti Active Directory REcycle Bin atau Credential Roaming yang diaktifkan juga dapat memengaruhi ukuran database.
Catatan
- Untuk lingkungan baru, ingatlah bahwa 100.000 pengguna di domain yang sama menggunakan sekitar 450 MB ruang. Atribut yang Anda isi dapat berdampak besar pada jumlah total ruang yang dikonsumsi. Atribut diisi oleh banyak objek dari produk pihak ketiga dan Microsoft, termasuk Microsoft Server Exchange dan Lync. Akibatnya, kami sarankan Anda mengevaluasi berdasarkan portofolio produk lingkungan. Namun, Anda juga harus ingat bahwa melakukan matematika dan pengujian untuk perkiraan yang tepat untuk semua tetapi lingkungan terbesar mungkin tidak bernilai waktu atau upaya yang signifikan.
- Pastikan ruang kosong yang Anda miliki tersedia adalah 110% dari ukuran NTDS.dit untuk mengaktifkan defrag offline. Ruang kosong ini juga memungkinkan Anda merencanakan pertumbuhan selama masa pakai perangkat keras tiga hingga lima tahun server. Jika Anda memiliki penyimpanan untuk itu, mengalokasikan ruang kosong yang cukup hingga 300% dari DIT untuk penyimpanan adalah cara yang aman untuk mengakomodasi pertumbuhan dan defragging.
Pertimbangan virtualisasi untuk penyimpanan
Dalam skenario di mana Anda mengalokasikan beberapa file Virtual Hard Disk (VHD) ke satu volume, Anda harus menggunakan disk status tetap setidaknya 210% ukuran DIT (100% dari DIT + 110% ruang kosong) untuk memastikan Anda memiliki cukup ruang yang disediakan untuk kebutuhan Anda.
Contoh ringkasan perhitungan penyimpanan
Tabel berikut mencantumkan nilai yang akan Anda gunakan untuk memperkirakan persyaratan ruang untuk skenario penyimpanan hipotetis.
| Data yang dikumpulkan dari fase evaluasi | Ukuran |
|---|---|
| Ukuran NTDS.dit | 35 GB |
| Pengubah untuk mengizinkan defrag offline | 2,1 GB |
| Total penyimpanan yang diperlukan | 73,5 GB |
Catatan
Perkiraan penyimpanan juga harus mencakup berapa banyak penyimpanan yang Anda butuhkan untuk SYSVOL, OS, file halaman, file sementara, data cache lokal seperti file penginstal, dan aplikasi.
Performa penyimpanan
Sebagai komponen terlambat dalam komputer apa pun, penyimpanan dapat memiliki dampak buruk terbesar pada pengalaman klien. Untuk lingkungan yang cukup besar sehingga rekomendasi ukuran RAM dalam artikel ini tidak layak, konsekuensi dari mengabaikan perencanaan kapasitas untuk penyimpanan dapat menghancurkan performa sistem. Kompleksitas dan varietas teknologi penyimpanan yang tersedia semakin meningkatkan risiko, karena rekomendasi umum untuk menempatkan OS, log, dan database pada disk fisik terpisah tidak berlaku secara universal di semua skenario.
Rekomendasi lama tentang disk mengasumsikan bahwa disk adalah spindle khusus yang memungkinkan untuk I/O terisolasi. Asumsi ini tidak lagi benar karena pengenalan jenis penyimpanan berikut:
- RAID
- Jenis penyimpanan baru dan skenario penyimpanan virtual dan bersama
- Spindle bersama pada Jaringan Area Penyimpanan (SAN)
- File VHD pada penyimpanan yang terpasang pada SAN atau jaringan
- Solid State Drive (SSD)
- Arsitektur penyimpanan berjenjang, seperti penyimpanan tingkat SSD penembolokan penyimpanan berbasis spindle yang lebih besar
Penyimpanan bersama, seperti RAID, SAN, NAS, JBOD, Storage Spaces, dan VHD, mampu kelebihan beban kerja yang Anda tempatkan di penyimpanan back-end. Jenis penyimpanan ini juga menghadirkan tantangan tambahan: MASALAH SAN, jaringan, atau driver antara disk fisik dan aplikasi AD dapat menyebabkan pembatasan dan penundaan. Untuk memperjelas, ini bukan konfigurasi yang buruk, tetapi lebih kompleks, yang berarti Anda perlu memberikan perhatian ekstra untuk memastikan setiap komponen berfungsi seperti yang dimaksudkan. Untuk penjelasan lebih rinci, lihat Lampiran C dan Lampiran D nanti di artikel ini. Selain itu, meskipun SSD tidak dibatasi oleh hard drive yang hanya dapat memproses satu I/O sekaligus, SSD masih memiliki batasan I/O yang dapat kelebihan beban.
Singkatnya, tujuan dari semua perencanaan performa penyimpanan, terlepas dari arsitektur penyimpanan, adalah untuk memastikan bahwa jumlah I/Os yang diperlukan selalu tersedia dan bahwa itu terjadi dalam jangka waktu yang dapat diterima. Untuk skenario dengan penyimpanan yang terpasang secara lokal, lihat Lampiran C untuk informasi selengkapnya tentang desain dan perencanaan. Anda dapat menerapkan prinsip-prinsip dalam lampiran ke skenario penyimpanan yang lebih kompleks, serta percakapan dengan vendor yang mendukung solusi penyimpanan back-end Anda.
Karena berapa banyak opsi penyimpanan yang tersedia hari ini, kami sarankan Anda berkonsultasi dengan tim atau vendor dukungan perangkat keras Anda sambil berencana untuk memastikan solusi memenuhi kebutuhan penyebaran AD DS Anda. Selama percakapan ini, Anda mungkin menemukan penghitung kinerja berikut berguna, terutama ketika database Anda terlalu besar untuk RAM Anda:
-
LogicalDisk(*)\Avg Disk sec/Read(misalnya, jika NTDS.dit disimpan di drive D, jalur lengkapnya adalahLogicalDisk(D:)\Avg Disk sec/Read) LogicalDisk(*)\Avg Disk sec/WriteLogicalDisk(*)\Avg Disk sec/TransferLogicalDisk(*)\Reads/secLogicalDisk(*)\Writes/secLogicalDisk(*)\Transfers/sec
Saat Anda memberikan data, Anda harus memastikan data diambil sampelnya dalam interval 15, 30, atau 60 menit untuk memberikan gambaran paling akurat tentang lingkungan Anda saat ini.
Mengevaluasi hasil
Bagian ini berfokus pada bacaan dari database, karena database biasanya merupakan komponen yang paling menuntut. Anda dapat menerapkan logika yang sama untuk menulis ke file log dengan mengganti <NTDS Log>)\Avg Disk sec/Write dan LogicalDisk(<NTDS Log>)\Writes/sec).
Penghitung LogicalDisk(<NTDS>)\Avg Disk sec/Read menunjukkan apakah penyimpanan saat ini berukuran memadai. Jika nilai kira-kira sama dengan Waktu Akses Disk yang diharapkan untuk jenis disk, LogicalDisk(<NTDS>)\Reads/sec penghitung adalah ukuran yang valid. Jika hasilnya kira-kira sama dengan Waktu Akses Disk untuk jenis disk, LogicalDisk(<NTDS>)\Reads/sec penghitung adalah ukuran yang valid. Meskipun ini dapat berubah tergantung pada spesifikasi produsen mana yang dimiliki penyimpanan back-end Anda, tetapi rentang yang baik untuk LogicalDisk(<NTDS>)\Avg Disk sec/Read kira-kira akan:
- 7200 rpm: 9 hingga 12,5 milidetik (ms)
- 10.000 rpm: 6 hingga 10 mdtk
- 15.000 rpm: 4 hingga 6 mdtk
- SSD – 1 hingga 3 mdtk
Anda mungkin mendengar dari sumber lain bahwa performa penyimpanan terdegradasi pada 15 mdtk menjadi 20 mdtk. Perbedaan antara nilai tersebut dan nilai dalam daftar sebelumnya adalah bahwa nilai daftar memperlihatkan rentang operasi normal. Nilai lainnya adalah untuk tujuan pemecahan masalah, yang membantu Anda mengidentifikasi kapan pengalaman klien telah cukup terdegradasi sehingga menjadi terlihat. Untuk informasi selengkapnya, lihat Lampiran C.
-
LogicalDisk(<NTDS>)\Reads/secadalah jumlah I/O yang saat ini dilakukan sistem.- Jika
LogicalDisk(<NTDS>)\Avg Disk sec/Readberada dalam rentang optimal untuk penyimpanan backend, Anda dapat langsung menggunakanLogicalDisk(<NTDS>)\Reads/secuntuk mengukur penyimpanan. - Jika
LogicalDisk(<NTDS>)\Avg Disk sec/Readtidak berada dalam rentang optimal untuk penyimpanan backend, I/O tambahan diperlukan sesuai dengan rumus berikut:LogicalDisk(<NTDS>)\Avg Disk sec/Read÷ Waktu Akses Disk Media Fisik ×LogicalDisk(<NTDS>)\Avg Disk sec/Read
- Jika
Saat Anda membuat perhitungan ini, berikut adalah beberapa hal yang harus Anda pertimbangkan:
- Jika server memiliki jumlah RAM sub-optimal, nilai yang dihasilkan akan terlalu tinggi dan tidak akan cukup akurat untuk berguna untuk perencanaan. Namun, Anda masih dapat menggunakannya untuk memprediksi skenario terburuk.
- Jika Anda menambahkan atau mengoptimalkan RAM, Anda juga mengurangi jumlah I/O
LogicalDisk(<NTDS>)\Reads/Secbaca . Penurunan ini dapat menyebabkan solusi penyimpanan tidak sekuat yang ditebak oleh perhitungan asli. Sayangnya, kami tidak dapat memberikan lebih spesifik tentang apa arti pernyataan ini, karena perhitungan sangat bervariasi tergantung pada lingkungan individu, terutama beban klien. Namun, kami sarankan Anda menyesuaikan ukuran penyimpanan setelah mengoptimalkan RAM.
Pertimbangan virtualisasi untuk performa
Sama seperti bagian sebelumnya, tujuan kami di sini adalah memastikan infrastruktur bersama dapat mendukung beban total semua konsumen. Anda perlu mengingat tujuan ini saat merencanakan skenario berikut:
- CD fisik yang berbagi media yang sama pada infrastruktur SAN, NAS, atau iSCSI sebagai server atau aplikasi lain.
- Pengguna yang menggunakan akses pass-through ke infrastruktur SAN, NAS, atau iSCSI yang berbagi media.
- Pengguna yang menggunakan file VHD di media bersama secara lokal atau infrastruktur SAN, NAS, atau iSCSI.
Dari perspektif pengguna tamu, harus melalui host untuk mengakses performa dampak penyimpanan apa pun, karena pengguna harus melakukan perjalanan ke jalur kode tambahan untuk mendapatkan akses. Pengujian performa menunjukkan virtualisasi berdampak pada throughput berdasarkan berapa banyak prosesor yang digunakan sistem host. Pemanfaatan prosesor juga dipengaruhi oleh berapa banyak sumber daya yang diminta pengguna tamu dari host. Permintaan ini berkontribusi pada pertimbangan Virtualisasi untuk pemrosesan yang harus Anda ambil untuk kebutuhan pemrosesan dalam skenario virtual. Untuk informasi selengkapnya, lihat Lampiran A.
Masalah yang lebih rumit adalah berapa banyak opsi penyimpanan yang saat ini tersedia, masing-masing dengan dampak performa yang sangat berbeda. Opsi ini termasuk penyimpanan pass-through, adaptor SCSI, dan IDE. Saat bermigrasi dari lingkungan fisik ke virtual, Anda harus menyesuaikan untuk opsi penyimpanan yang berbeda untuk pengguna tamu virtual dengan menggunakan pengali 1.10. Namun, Anda tidak perlu mempertimbangkan penyesuaian saat mentransfer antara skenario penyimpanan yang berbeda, karena apakah penyimpanan bersifat lokal, SAN, NAS, atau iSCSI lebih penting.
Contoh perhitungan virtualisasi
Menentukan jumlah I/O yang diperlukan untuk sistem yang sehat dalam kondisi operasi normal:
- LogicalDisk(
<NTDS Database Drive>) ÷ Transfer per detik selama periode puncak 15 menit - Untuk menentukan jumlah I/O yang diperlukan untuk penyimpanan di mana kapasitas penyimpanan yang mendasar terlampaui:
IOPS yang diperlukan = (LogicalDisk(
<NTDS Database Drive>)) ÷ Avg Disk Read/detik ÷<Target Avg Disk Read/sec>) × LogicalDisk(<NTDS Database Drive>)\Read/sec
| Penghitung | Nilai |
|---|---|
LogicalDisk Aktual(<NTDS Database Drive>)\Rata-rata Disk detik/Transfer |
.02 detik (20 milidetik) |
LogicalDisk Target(<NTDS Database Drive>)\Rata-rata Disk sec/Transfer |
.01 detik |
| Pengali untuk perubahan I/O yang tersedia | 0,02 ÷ 0,01 = 2 |
| Nama nilai | Nilai |
|---|---|
LogicalDisk(<NTDS Database Drive>)\Transfers/dtk |
400 |
| Pengali untuk perubahan I/O yang tersedia | 2 |
| Total IOPS yang diperlukan selama periode puncak | delapan ratus |
Untuk menentukan tingkat di mana Anda harus menghangatkan cache:
- Tentukan waktu maksimum yang dapat Anda terima untuk dihabiskan untuk pemanasan cache. Dalam skenario umum, jumlah waktu yang dapat diterima adalah berapa lama waktu yang diperlukan untuk memuat seluruh database dari disk. Dalam skenario di mana RAM tidak dapat memuat seluruh database, gunakan waktu yang diperlukan untuk mengisi seluruh RAM.
- Tentukan ukuran database, tidak termasuk ruang yang tidak Anda rencanakan untuk digunakan. Untuk informasi selengkapnya, lihat Mengevaluasi penyimpanan.
- Bagi ukuran database dengan 8 KB untuk mendapatkan jumlah total I/Os yang Anda butuhkan untuk memuat database.
- Bagi total I/Os dengan jumlah detik dalam jangka waktu yang ditentukan.
Jumlah yang Anda hitung sebagian besar akurat, tetapi mungkin tidak tepat karena Anda belum mengonfigurasi (Extensible Storage Engine) ESE untuk memiliki ukuran cache tetap, maka AD DS akan mengeluarkan halaman yang dimuat sebelumnya karena menggunakan ukuran cache variabel secara default.
| Poin data yang akan dikumpulkan | Nilai |
|---|---|
| Waktu maksimum yang dapat diterima untuk menghangatkan | 10 menit (600 detik) |
| Ukuran database | 2 GB |
| Langkah penghitungan | Rumus | Hasil |
|---|---|---|
| Menghitung ukuran database di halaman | (2 GB × 1024 × 1024) = Ukuran database dalam KB | 2.097.152 KB |
| Menghitung jumlah halaman dalam database | 2.097.152 KB ÷ 8 KB = Jumlah halaman | 262.144 halaman |
| Hitung IOPS yang diperlukan untuk menghangatkan cache sepenuhnya | 262.144 halaman ÷ 600 detik = IOPS diperlukan | 437 IOPS |
Sedang diproses
Mengevaluasi penggunaan prosesor Direktori Aktif
Untuk sebagian besar lingkungan, mengelola kapasitas pemrosesan adalah komponen yang paling layak mendapat perhatian. Saat Anda mengevaluasi berapa banyak kapasitas CPU yang dibutuhkan penyebaran, Anda harus mempertimbangkan dua hal berikut:
- Apakah aplikasi di lingkungan Anda berperilaku seperti yang dimaksudkan dalam infrastruktur layanan bersama berdasarkan kriteria yang diuraikan dalam Melacak pencarian yang mahal dan tidak efisien? Di lingkungan yang lebih besar, aplikasi berkode buruk dapat membuat beban CPU menjadi volatil, mengambil jumlah waktu CPU yang tidak biasa dengan mengorbankan aplikasi lain, meningkatkan kebutuhan kapasitas, dan mendistribusikan beban yang tidak merata terhadap DC.
- AD DS adalah lingkungan terdistribusi dengan banyak klien potensial yang kebutuhan pemrosesannya sangat bervariasi. Estimasi biaya untuk setiap klien dapat bervariasi karena pola penggunaan dan berapa banyak aplikasi yang menggunakan AD DS. Sama seperti di Jaringan, Anda harus mendekati estimasi sebagai evaluasi dari total kapasitas yang diperlukan di lingkungan alih-alih melihat setiap klien satu per satu.
Anda seharusnya hanya membuat perkiraan ini setelah menyelesaikan perkiraan penyimpanan , karena Anda tidak akan dapat membuat tebakan yang akurat tanpa data yang valid tentang beban prosesor Anda. Penting juga untuk memastikan hambatan apa pun tidak disebabkan oleh penyimpanan sebelum memecahkan masalah prosesor. Saat Anda menghapus status tunggu prosesor, pemanfaatan CPU meningkat karena tidak perlu lagi menunggu data. Oleh karena itu, penghitung kinerja yang harus Anda perhatikan adalah Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read dan Process(lsass)\ Processor Time. Jika penghitung Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read lebih dari 10 atau 15 milidetik, maka data di Process(lsass)\ Processor Time secara buatan rendah dan masalahnya terkait dengan performa penyimpanan. Sebaiknya atur interval sampel ke 15, 30, atau 60 menit untuk data yang paling akurat.
Gambaran umum pemrosesan
Untuk merencanakan perencanaan kapasitas untuk pengendali domain, daya pemrosesan membutuhkan perhatian dan pemahaman yang paling. Ketika sistem ukuran untuk memastikan performa maksimum, selalu ada komponen yang menjadi hambatan, dan dalam Pengendali Domain berukuran tepat, komponen ini adalah prosesor.
Mirip dengan bagian jaringan di mana permintaan lingkungan ditinjau berdasarkan situs demi situs, hal yang sama harus dilakukan untuk kapasitas komputasi yang diminta. Tidak seperti bagian jaringan, di mana teknologi jaringan yang tersedia jauh melebihi permintaan normal, lebih memperhatikan kapasitas CPU ukuran. Sebagai lingkungan dengan ukuran yang bahkan sedang; apa pun lebih dari beberapa ribu pengguna bersamaan dapat menempatkan beban yang signifikan pada CPU.
Sayangnya, karena varian besar aplikasi klien yang memanfaatkan AD, perkiraan umum pengguna per CPU sangat tidak dapat diterapkan ke semua lingkungan. Secara khusus, tuntutan komputasi tunduk pada perilaku pengguna dan profil aplikasi. Oleh karena itu, setiap lingkungan perlu berukuran individual.
Profil perilaku situs target
Ketika Anda merencanakan kapasitas untuk seluruh situs, tujuan Anda harus berupa desain kapasitas N + 1. Dalam desain ini, bahkan jika satu sistem gagal selama periode puncak, layanan masih dapat berlanjut pada tingkat kualitas yang dapat diterima. Dalam skenario N, beban pada semua kotak harus kurang dari 80%-100% selama periode puncak.
Selain itu, aplikasi dan klien situs yang menggunakan metode fungsi DsGetDcName yang direkomendasikan untuk menemukan DC seharusnya sudah didistribusikan secara merata, hanya dengan adanya lonjakan kecil sementara.
Sekarang kita akan melihat dua contoh lingkungan yang tepat sasaran dan di luar target. Pertama, kita akan melihat contoh lingkungan yang berfungsi seperti yang dimaksudkan dan tidak melebihi target perencanaan kapasitas.
Untuk contoh pertama, kami membuat asumsi berikut:
- Masing-masing dari lima DC di situs memiliki empat CPU.
- Total penggunaan CPU target selama jam kerja adalah 40% dalam kondisi operasi normal (N + 1) dan 60% sebaliknya (N). Selama jam non-bisnis, penggunaan CPU target adalah 80% karena kami mengharapkan perangkat lunak cadangan dan proses pemeliharaan lainnya untuk mengonsumsi semua sumber daya yang tersedia.
Sekarang, mari kita lihat (Processor Information(_Total)\% Processor Utility) bagan, untuk setiap DC, seperti yang ditunjukkan pada gambar berikut.
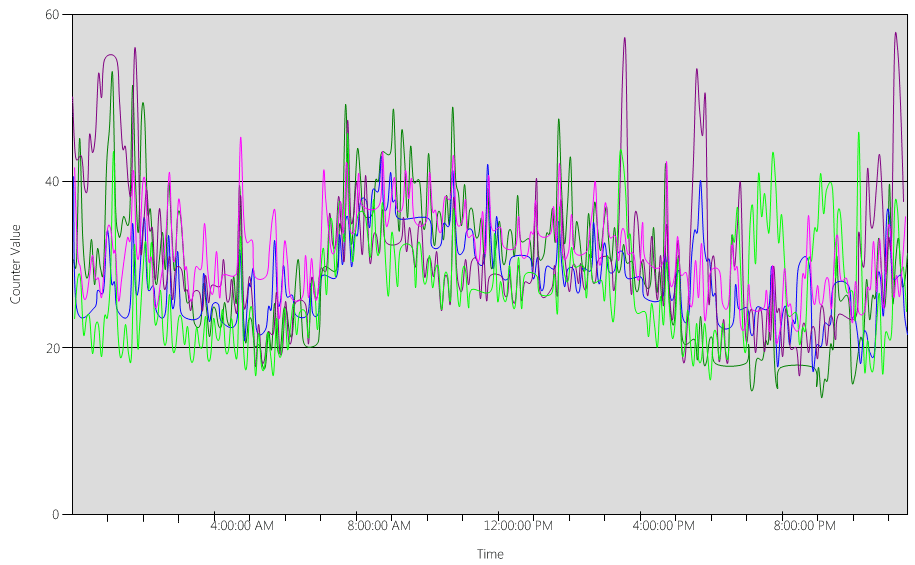
Bebannya relatif merata, yang kami harapkan ketika klien menggunakan pencari lokasi DC dan pencarian yang ditulis dengan baik.
Dalam beberapa interval lima menit, ada lonjakan pada 10%, kadang-kadang bahkan 20%. Namun, kecuali lonjakan ini menyebabkan penggunaan CPU melebihi target rencana kapasitas, Anda tidak perlu menyelidikinya.
Periode puncak untuk semua sistem adalah antara pukul 08.00 dan 09.15. Rata-rata hari kerja berlangsung dari pukul 05.00 hingga 17.00. Oleh karena itu, setiap lonjakan acak penggunaan CPU yang terjadi antara pukul 17.00 dan 04.00 berada di luar jam kerja, dan oleh karena itu Anda tidak perlu menyertakannya dalam masalah perencanaan kapasitas Anda.
Catatan
Pada sistem yang dikelola dengan baik, lonjakan yang terjadi selama periode di luar puncak biasanya disebabkan oleh perangkat lunak cadangan, pemindaian antivirus sistem penuh, inventarisasi perangkat keras atau perangkat lunak, penyebaran perangkat lunak atau patch, dan sebagainya. Karena lonjakan ini terjadi di luar jam kerja, mereka tidak dihitung untuk melebihi target perencanaan kapasitas.
Karena setiap sistem sekitar 40% dan semuanya memiliki jumlah CPU yang sama, jika salah satunya offline, sistem yang tersisa berjalan pada perkiraan 53%. Sistem D memiliki beban 40% yang dibagi secara merata dan ditambahkan ke Sistem A dan C beban 40% yang ada. Asumsi linier ini tidak akurat secara sempurna, tetapi memberikan akurasi yang cukup untuk mengukur.
Selanjutnya, mari kita lihat contoh lingkungan yang tidak memiliki penggunaan CPU yang baik dan melebihi target perencanaan kapasitas.
Dalam contoh ini, kami memiliki dua DC yang berjalan pada 40%. Satu pengendali domain offline, yang menyebabkan perkiraan penggunaan CPU pada DC yang tersisa mencapai 80%. Tingkat penggunaan CPU ini jauh melebihi ambang batas untuk rencana kapasitas dan mulai membatasi jumlah headroom untuk 10% hingga 20% dari profil beban. Akibatnya, setiap lonjakan berpotensi mendorong DC menjadi 90% atau bahkan 100 % selama skenario N , mengurangi responsivitasnya.
Menghitung permintaan CPU
Penghitung Process\% Processor Time kinerja melacak jumlah total waktu yang dihabiskan semua utas aplikasi pada CPU, lalu membagi jumlah tersebut dengan jumlah total waktu sistem yang dilewati. Aplikasi mutlithreaded pada sistem multi-CPU dapat melebihi 100% waktu CPU, dan Anda akan menafsirkan datanya dengan sangat berbeda dari Processor Information\% Processor Utility penghitung. Dalam praktiknya, penghitung Process(lsass)\% Processor Time melacak berapa banyak CPU yang berjalan pada 100% yang diperlukan sistem untuk mendukung tuntutan proses. Misalnya, jika penghitung memiliki nilai 200%, itu berarti sistem membutuhkan dua CPU yang berjalan pada 100% untuk mendukung beban AD DS penuh. Meskipun CPU yang berjalan pada kapasitas 100% adalah yang paling hemat biaya dalam hal konsumsi daya dan energi, karena alasan yang diuraikan dalam Lampiran A, sistem multithreaded lebih responsif ketika sistemnya tidak berjalan pada 100%.
Untuk mengakomodasi lonjakan sementara dalam beban klien, kami sarankan Anda menargetkan CPU periode puncak antara 40% dan 60% kapasitas sistem. Misalnya, dalam contoh pertama dalam Profil perilaku situs target, Anda memerlukan antara CPU 3,33 (target 60%) dan 5 CPU (target 40%) untuk mendukung beban AD DS. Anda harus menambahkan kapasitas tambahan sesuai dengan tuntutan OS dan agen lain yang diperlukan, seperti antivirus, cadangan, pemantauan, dan sebagainya. Meskipun Anda harus mengevaluasi dampak agen pada agen CPU secara per lingkungan, umumnya Anda dapat mengalokasikan antara 5% dan 10% untuk proses agen pada satu CPU. Untuk mengunjungi kembali contoh kami, kita akan membutuhkan antara 3,43 (target 60%) dan CPU 5,1 (40% target) untuk mendukung beban selama periode puncak.
Sekarang, mari kita lihat contoh perhitungan untuk proses tertentu. Dalam hal ini, kita melihat proses LSASS.
Menghitung penggunaan CPU untuk proses LSASS
Dalam contoh ini, sistem adalah skenario N + 1 di mana satu server membawa beban AD DS sementara server tambahan ada untuk redundansi.
Bagan berikut menunjukkan waktu prosesor untuk proses LSASS di semua prosesor untuk skenario contoh ini. Data ini dikumpulkan dari penghitung Process(lsass)\% Processor Time kinerja.
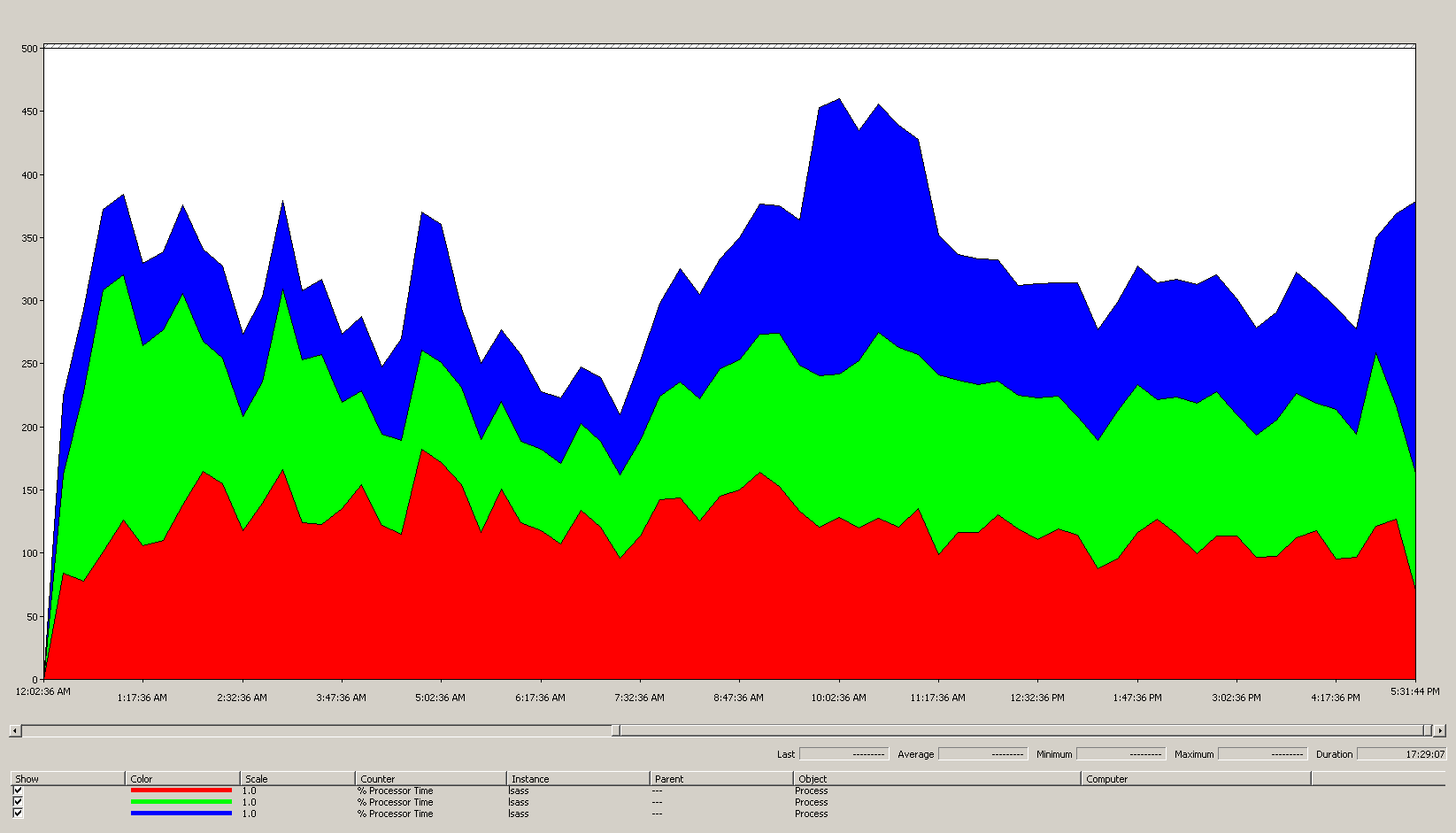
Berikut adalah apa yang diceritakan bagan ini tentang lingkungan skenario:
- Ada tiga pengendali domain di situs ini.
- Hari kerja mulai naik sekitar pukul 07.00, lalu turun pada pukul 17.00.
- Periode tersibuk dalam sehari adalah dari pukul 09.30 hingga 11.00.
Catatan
Semua data performa bersifat historis. Titik data puncak pada pukul 09.15 menunjukkan beban dari pukul 09.00 hingga 09.15.
- Lonjakan sebelum pukul 07.00 dapat menunjukkan beban tambahan dari zona waktu atau aktivitas infrastruktur latar belakang yang berbeda, seperti pencadangan. Namun, karena lonjakan ini lebih rendah dari aktivitas puncak pada pukul 09.30, itu bukan penyebab kekhawatiran.
Pada beban maksimum, proses lsass mengonsumsi sekitar 4,85 CPU yang berjalan pada 100%, yang akan menjadi 485% pada satu CPU. Hasil ini menunjukkan situs skenario membutuhkan sekitar CPU 12/25 untuk menangani AD DS. Ketika Anda membawa kapasitas tambahan 5% hingga 10% yang direkomendasikan untuk proses latar belakang, server membutuhkan CPU 12,30 hingga 12,25 untuk mendukung bebannya saat ini. Memperkirakan mengantisipasi pertumbuhan di masa mendatang membuat jumlah ini semakin tinggi.
Kapan harus menyetel bobot LDAP
Ada skenario tertentu di mana Anda harus mempertimbangkan untuk menyetel LdapSrvWeight. Dalam konteks perencanaan kapasitas, Anda akan menyetelnya saat aplikasi, pengguna dimuat, atau kemampuan sistem yang mendasar tidak seimbang secara merata.
Bagian berikut menjelaskan dua contoh skenario di mana Anda harus menyetel bobot Lightweight Directory Access Protocol (LDAP).
Contoh 1: Lingkungan emulator PDC
Jika Anda menggunakan emulator Pengontrol Domain Utama (PDC), perilaku pengguna atau aplikasi yang didistribusikan secara tidak merata dapat memengaruhi beberapa lingkungan sekaligus. Sumber daya CPU pada emulator PDC sering kali lebih banyak diminta daripada di tempat lain dalam penyebaran karena beberapa alat dan tindakan menargetkannya, seperti alat manajemen Kebijakan Grup, upaya autentikasi kedua, pembentukan kepercayaan, dan sebagainya.
- Anda harus menyetel emulator PDC hanya jika ada perbedaan nyata dalam pemanfaatan CPU. Penyetelan harus mengurangi beban pada emulator PDC dan meningkatkan beban pada DC lain, memungkinkan distribusi beban yang lebih merata.
- Dalam kasus ini, tetapkan nilai untuk
LDAPSrvWeightantara 50 dan 75 untuk emulator PDC.
| Sistem | Pemanfaatan CPU dengan default | LdapSrvWeight Baru | Perkiraan pemanfaatan CPU baru |
|---|---|---|---|
| DC 1 (emulator PDC) | 53% | 57 | 40% |
| DC 2 | 33% | 100 | 40% |
| DC 3 | 33% | 100 | 40% |
Tangkapannya adalah bahwa jika peran emulator PDC ditransfer atau disita, terutama ke pengontrol domain lain di situs, maka pemanfaatan CPU meningkat secara dramatis pada emulator PDC baru.
Dalam contoh skenario ini, kami berasumsi berdasarkan profil perilaku situs Target bahwa ketiga pengendali domain di situs ini memiliki empat CPU. Dalam kondisi normal, apa yang akan terjadi jika salah satu DC ini memiliki delapan CPU? Akan ada dua DC pada pemanfaatan 40% dan satu pada pemanfaatan 20%. Meskipun konfigurasi ini tidak selalu buruk, ada kesempatan di sini bagi Anda untuk menggunakan penyetelan berat LDAP untuk menyeimbangkan beban dengan lebih baik.
Contoh 2: lingkungan dengan jumlah CPU yang berbeda
Ketika Anda memiliki server dengan jumlah dan kecepatan CPU yang berbeda di situs yang sama, Anda perlu memastikannya didistribusikan secara merata. Misalnya, jika situs Anda memiliki dua server delapan inti dan satu server empat inti, server empat inti hanya memiliki setengah kekuatan pemrosesan dari dua server lainnya. Jika beban klien didistribusikan secara merata, itu berarti server empat inti perlu bekerja dua kali lebih keras daripada dua server delapan inti untuk mengelola beban CPU-nya. Di atas itu, jika salah satu dari delapan server inti offline, server empat inti akan kelebihan beban.
| Sistem | Informasi Prosesor\ % Utilitas Prosesor(_Total) Pemanfaatan CPU dengan default |
LdapSrvWeight Baru | Perkiraan pemanfaatan CPU baru |
|---|---|---|---|
| 4-CPU DC 1 | 40 | 100 | 30% |
| 4-CPU DC 2 | 40 | 100 | 30% |
| 8-CPU DC 3 | 20 | 200 | 30% |
Merencanakan skenario "N + 1" sangat penting. Dampak satu DC menjadi offline harus dihitung untuk setiap skenario. Dalam skenario sebelumnya di mana distribusi beban merata, untuk memastikan beban 60% selama skenario "N", dengan beban seimbang secara merata di semua server, distribusinya baik-baik saja karena rasio tetap konsisten. Saat Anda melihat skenario penyetelan emulator PDC, atau skenario umum di mana beban pengguna atau aplikasi tidak seimbang, efeknya sangat berbeda:
| Sistem | Pemanfaatan yang Disetel | LdapSrvWeight Baru | Perkiraan Pemanfaatan Baru |
|---|---|---|---|
| DC 1 (emulator PDC) | 40% | 85 | 47% |
| DC 2 | 40% | 100 | 53% |
| DC 3 | 40% | 100 | 53% |
Pertimbangan virtualisasi untuk pemrosesan
Saat Anda merencanakan kapasitas untuk lingkungan virtual, ada dua tingkat yang perlu Anda pertimbangkan: tingkat host dan tingkat tamu. Di tingkat host, Anda harus mengidentifikasi periode puncak siklus bisnis Anda. Karena menjadwalkan utas tamu pada CPU untuk komputer virtual mirip dengan mendapatkan utas AD DS pada CPU untuk komputer fisik, kami masih menyarankan Anda menggunakan 40% hingga 60% dari host yang mendasar. Di tingkat tamu, karena prinsip penjadwalan utas yang mendasarinya tidak berubah, kami juga masih menyarankan Anda menyimpan penggunaan CPU dalam rentang 40% hingga 60%.
Dalam skenario yang dipetakan langsung dengan satu tamu per host, Anda harus membawa semua perkiraan perencanaan kapasitas yang telah Anda lakukan di bagian sebelumnya untuk membuat perkiraan Anda. Untuk skenario host berbagi, terdapat dampak sekitar 10% pada efisiensi prosesor yang mendasari, yang berarti jika sebuah situs memerlukan 10 CPU dengan target 40%, jumlah CPU virtual yang direkomendasikan yang harus Anda alokasikan di semua tamu N adalah 11. Di situs dengan distribusi campuran server fisik dan virtual, pengubah ini hanya berlaku untuk komputer virtual (VM). Misalnya, dalam skenario N + 1, satu server fisik atau yang dipetakan langsung dengan 10 CPU hampir sama dengan satu tamu dengan 11 CPU pada host dengan 11 CPU lagi yang dicadangkan untuk DC.
Saat Anda menganalisis dan menghitung berapa banyak CPU yang Anda butuhkan untuk mendukung beban AD DS, perlu diingat bahwa jika Anda berencana untuk membeli perangkat keras fisik, jenis perangkat keras yang tersedia di pasar mungkin tidak memetakan persis ke perkiraan Anda. Namun, Anda tidak memiliki masalah saat menggunakan virtualisasi. Menggunakan VM mengurangi upaya yang diperlukan bagi Anda untuk menambahkan kapasitas komputasi ke situs, karena Anda dapat menambahkan CPU sebanyak mungkin dengan spesifikasi yang anda inginkan ke VM. Namun, virtualisasi tidak menghilangkan tanggung jawab Anda untuk mengevaluasi secara akurat berapa banyak daya komputasi yang Anda butuhkan untuk menjamin perangkat keras dasar Anda tersedia ketika tamu membutuhkan lebih banyak CPU. Seperti biasa, ingatlah untuk merencanakan ke depan untuk pertumbuhan.
Contoh ringkasan perhitungan virtualisasi
| Sistem | CPU puncak |
|---|---|
| DC 1 | 120% |
| DC 2 | 147% |
| DC 3 | 218% |
| Total penggunaan CPU | 485% |
| Jumlah sistem target | Total bandwidth (dari atas) |
|---|---|
| CPU diperlukan pada target 40% | 4,85 ÷ .4 = 12.25 |
Ketika merencanakan ke depan untuk pertumbuhan dalam skenario ini, jika Anda mengasumsikan bahwa permintaan akan tumbuh sebesar 50% selama tiga tahun ke depan, Anda perlu memastikannya memiliki 18,375 CPU (12,25 × 1,5) pada saat itu. Atau, Anda dapat meninjau permintaan setelah tahun pertama, lalu menambahkan kapasitas tambahan berdasarkan apa yang dikatakan hasilnya kepada Anda.
Beban autentikasi klien lintas kepercayaan untuk NTLM
Mengevaluasi beban autentikasi klien lintas kepercayaan
Banyak lingkungan mungkin memiliki satu atau beberapa domain yang terhubung oleh kepercayaan. Permintaan autentikasi untuk identitas di domain lain yang tidak menggunakan Kerberos perlu melintasi kepercayaan menggunakan saluran aman antara dua pengontrol domain. Pengendali domain yang coba diakses pengguna di situs tersambung ke pengontrol domain lain yang terletak di domain tujuan atau di suatu tempat lebih jauh ke jalur menuju domain tujuan. Berapa banyak panggilan yang dapat dilakukan DC ke DC lain di domain tepercaya dikontrol oleh pengaturan *MaxConcurrentAPI . Untuk memastikan saluran aman dapat menangani jumlah beban yang diperlukan DC untuk berkomunikasi satu sama lain, Anda dapat menyetel MaxConcurrentAPI atau, jika Anda berada di forest, membuat kepercayaan pintasan. Pelajari selengkapnya tentang cara menentukan volume lalu lintas di seluruh kepercayaan di Cara melakukan penyetelan performa untuk autentikasi NTLM dengan menggunakan pengaturan MaxConcurrentApi.
Seperti skenario sebelumnya, Anda harus mengumpulkan data selama periode sibuk puncak hari itu agar berguna.
Catatan
Skenario intraforest dan interforest dapat menyebabkan autentikasi melintasi beberapa kepercayaan, yang berarti Anda perlu menyetel selama setiap tahap proses.
Perencanaan virtualisasi
Ada beberapa hal yang harus Anda ingat ketika perencanaan kapasitas untuk virtualisasi:
- Banyak aplikasi menggunakan autentikasi Network Level Trust Manager (NTLM) secara default atau dalam konfigurasi tertentu.
- Ketika jumlah klien aktif meningkat, begitu juga kebutuhan server aplikasi untuk memiliki lebih banyak kapasitas.
- Klien terkadang menjaga sesi tetap terbuka untuk waktu yang terbatas dan sebaliknya terhubung kembali secara teratur untuk layanan seperti sinkronisasi penarikan email.
- Server proksi web yang memerlukan autentikasi untuk akses internet dapat menyebabkan beban NTLM yang tinggi.
Aplikasi ini dapat membuat beban besar untuk autentikasi NTLM, yang memberikan tekanan signifikan pada DC, terutama ketika pengguna dan sumber daya berada di domain yang berbeda.
Ada banyak pendekatan yang dapat Anda ambil untuk mengelola beban lintas kepercayaan, yang seringkali dapat dan harus Anda gunakan bersama-sama pada saat yang sama:
- Kurangi autentikasi klien lintas kepercayaan dengan menemukan layanan yang digunakan pengguna di domain tempat mereka berada.
- Tingkatkan jumlah saluran aman yang tersedia. Saluran ini disebut kepercayaan pintasan dan relevan dengan lalu lintas intraforest dan lintas hutan.
- Sesuaikan pengaturan default untuk MaxConcurrentAPI.
Untuk menyetel MaxConcurrentAPI pada server yang ada, gunakan persamaan berikut:
New_MaxConcurrentApi_setting ≥ (semaphore_acquires + ) × average_semaphore_hold_time ÷ time_collection_length
Untuk informasi selengkapnya, lihat artikel KB 2688798: Cara melakukan penyetelan performa untuk autentikasi NTLM dengan menggunakan pengaturan MaxConcurrentApi.
Pertimbangan virtualisasi
Tidak ada pertimbangan khusus yang perlu Anda buat, karena virtualisasi adalah pengaturan penyetelan sistem operasi.
Contoh perhitungan penyetelan virtualisasi
| Jenis Data | Nilai |
|---|---|
| Akuisisi Semaphore (Minimum) | 6,161 |
| Akuisisi Semaphore (Maksimum) | 6,762 |
| Batas Waktu Semaphore | 0 |
| Rata-rata Waktu Penahanan Semaphore | 0.012 |
| Durasi Pengumpulan (detik) | 1:11 menit (71 detik) |
| Rumus (dari 2688798 KB) | ((6762 - 6161) + 0) × 0,012 / |
| Nilai minimum untuk MaxConcurrentAPI | ((6762 - 6161) + 0) × 0,012 ÷ 71 = .101 |
Untuk sistem ini untuk periode waktu ini, nilai default dapat diterima.
Pemantauan untuk kepatuhan dengan tujuan perencanaan kapasitas
Sepanjang artikel ini, kami telah membahas bagaimana perencanaan dan penskalaan menuju target pemanfaatan. Tabel berikut ini meringkas ambang yang direkomendasikan yang harus Anda pantau untuk memastikan sistem beroperasi seperti yang dimaksudkan. Perlu diingat bahwa ini bukan ambang performa, hanya ambang batas perencanaan kapasitas. Server yang beroperasi melebihi ambang batas ini masih akan berfungsi, tetapi Anda perlu memvalidasi aplikasi Anda berfungsi seperti yang dimaksudkan sebelum Anda mulai melihat masalah performa saat permintaan pengguna meningkat. Jika aplikasi baik-baik saja, Maka Anda harus mulai mengevaluasi peningkatan perangkat keras atau perubahan konfigurasi lainnya.
| Kategori | Penghitung kinerja | Interval/Pengambilan Sampel | Sasaran | Peringatan |
|---|---|---|---|---|
| Pemroses | Processor Information(_Total)\% Processor Utility |
60 menit | 40% | 60% |
| RAM (Windows Server 2008 R2 atau yang lebih lama) | Memori\Tersedia MB | < 100 MB | T/A | < 100 MB |
| RAM (Windows Server 2012) | Memori\Masa Pakai Siaga Rata-Rata Jangka Panjang | 30 menit | Harus diuji | Harus diuji |
| Jaringan | Antarmuka Jaringan(*)\Byte Terkirim/detik Antarmuka Jaringan(*)\Byte Diterima/detik |
30 menit | 40% | 60% |
| Storage | LogicalDisk((<NTDS Database Drive>))\Rata-rata Disk dtk/BacaLogicalDisk(( |
60 menit | 10 md | 15 mdtk |
| Layanan AD | Netlogon(*)\Rata-rata Waktu Penahanan Semaphore | 60 menit | 0 | 1 detik |
Lampiran A: Kriteria ukuran CPU
Lampiran ini membahas istilah dan konsep berguna yang dapat membantu Anda memperkirakan kebutuhan ukuran CPU lingkungan Anda.
Definisi: Ukuran CPU
Prosesor (microprocessor) adalah komponen yang membaca dan menjalankan instruksi program.
Prosesor multi-inti memiliki beberapa CPU pada sirkuit terintegrasi yang sama.
Sistem multi-CPU memiliki beberapa CPU yang tidak berada di sirkuit terintegrasi yang sama.
Prosesor logis adalah prosesor yang hanya memiliki satu mesin komputasi logis dari perspektif sistem operasi.
Definisi ini termasuk hyper-threaded, satu core pada prosesor multi-core, atau prosesor inti tunggal.
Karena sistem server saat ini memiliki beberapa prosesor, beberapa prosesor multi-inti, dan hyper-threading, definisi ini digeneralisasi untuk mencakup kedua skenario. Kami menggunakan istilah prosesor logis karena mewakili perspektif OS dan aplikasi dari mesin komputasi yang tersedia.
Paralelisme tingkat utas
Setiap utas adalah tugas independen, karena setiap utas memiliki tumpukan dan instruksinya sendiri. AD DS bekerja dengan banyak utas dan Anda dapat menyetel jumlah utas yang tersedia dengan mengikuti petunjuk dalam Cara melihat dan mengatur kebijakan LDAP di Active Directory dengan menggunakan Ntdsutil.exe, diskalakan dengan baik di beberapa prosesor logis.
Paralelisme tingkat data
Paralelisme tingkat data adalah ketika layanan berbagi data di banyak utas untuk proses yang sama dan berbagi banyak utas di beberapa proses. Proses AD DS saja akan dihitung sebagai data berbagi layanan di beberapa utas untuk satu proses. Setiap perubahan pada data tercermin di semua utas yang berjalan di semua tingkat cache, setiap inti, dan pembaruan apa pun pada memori bersama. Performa dapat menurun selama operasi tulis karena semua lokasi memori menyesuaikan dengan perubahan sebelum pemrosesan instruksi dapat dilanjutkan.
Kecepatan CPU versus pertimbangan multi-inti
Umumnya, prosesor logis yang lebih cepat mengurangi waktu yang diperlukan untuk memproses serangkaian instruksi. Prosesor yang lebih logis berarti Anda dapat menjalankan lebih banyak tugas secara bersamaan. Namun, aturan ini tidak berlaku dalam skenario yang lebih kompleks, seperti mengambil data dari memori bersama, menunggu paralelisme tingkat data, dan overhead pengelolaan beberapa utas sekaligus. Akibatnya, skalabilitas dalam sistem multi-inti tidak linier.
Untuk memahami mengapa perubahan ini terjadi, ini membantu memikirkan skenario ini seperti jalan raya. Setiap utas adalah mobil individual, setiap jalur adalah inti, dan batas kecepatannya adalah kecepatan jam.
Jika hanya ada satu mobil di jalan raya, tidak masalah jika ada dua atau 12 jalur. Mobil itu hanya melaju secepat batas kecepatan.
Jika data yang dibutuhkan utas tidak segera tersedia, maka utas tidak dapat memproses instruksi hingga mengambil data yang relevan dari memori. Ini seperti jika segmen jalan raya dimatikan. Bahkan jika hanya ada satu mobil di jalan raya, batas kecepatan tidak akan mempengaruhi kemampuannya untuk bepergian, karena tidak dapat pergi ke mana pun sampai jalan dibuka kembali.
Seiring meningkatnya jumlah mobil, overhead yang dibutuhkan jalan raya untuk mengelola jumlah mobil juga meningkat. Pengemudi harus fokus lebih keras saat mengemudi di jalan raya saat lalu lintas jam sibuk dibandingkan dengan sore hari ketika sebagian besar jalan kosong. Selain itu, mengemudi di jalan raya dua jalur di mana Anda hanya perlu khawatir tentang satu jalur lain membutuhkan lebih sedikit fokus daripada mengemudi di jalan raya enam jalur di mana Anda memiliki lima jalur lalu lintas lain untuk diperhatikan.
Singkatnya, pertanyaan tentang apakah Anda harus menambahkan lebih banyak atau lebih cepat prosesor menjadi sangat subjektif dan harus dipertimbangkan berdasarkan kasus per kasus. Khususnya untuk AD DS, kebutuhan pemrosesannya bergantung pada faktor lingkungan dan dapat bervariasi dari server ke server dalam satu lingkungan. Akibatnya, bagian sebelumnya dalam artikel ini tidak berinvestasi besar-besaran dalam membuat perhitungan yang super tepat. Saat Anda membuat keputusan pembelian berbasis anggaran, kami sarankan Anda terlebih dahulu mengoptimalkan penggunaan prosesor pada 40% atau nomor mana pun yang diperlukan lingkungan spesifik Anda. Jika sistem Anda tidak dioptimalkan, maka Anda tidak mendapat manfaat sebanyak dari membeli prosesor tambahan.
Catatan
Hukum Amdahl dan hukum Gustafson adalah konsep yang relevan di sini.
Waktu respons dan bagaimana tingkat aktivitas sistem memengaruhi performa
Teori antrean adalah studi matematika tentang garis tunggu, atau antrean. Dalam mengantre teori untuk komputasi, undang-undang pemanfaatan diwakili oleh persamaan:
U k = B ÷ T
Di mana U k adalah persentase pemanfaatan, B adalah jumlah waktu yang dihabiskan untuk sibuk, dan T adalah total waktu yang dihabiskan untuk mengamati sistem. Dalam konteks Microsoft, ini berarti jumlah utas interval 100-nanodetik (ns) yang berada dalam status Berjalan dibagi dengan berapa banyak interval 100-ns yang tersedia dalam interval waktu tertentu. Ini adalah rumus yang sama yang menghitung persentase pemanfaatan prosesor yang diperlihatkan dalam Objek Prosesor dan PERF_100NSEC_TIMER_INV.
Teori antrean juga menyediakan rumus: N = U k ÷ (1 - U k) untuk memperkirakan jumlah item tunggu berdasarkan pemanfaatan, di mana N adalah panjang antrean. Membuat bagan persamaan ini atas semua interval pemanfaatan memberikan perkiraan berikut tentang berapa lama antrean untuk masuk ke prosesor berada pada beban CPU tertentu.
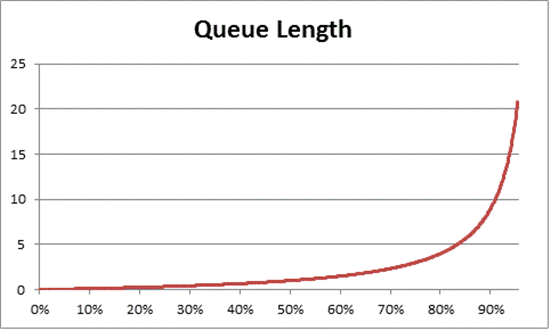
Berdasarkan perkiraan ini, kita dapat mengamati bahwa setelah beban CPU 50%, rata-rata menunggu biasanya mencakup satu item lain dalam antrean, dan meningkat dengan cepat hingga pemanfaatan CPU 70%.
Untuk memahami bagaimana teori antrean diterapkan pada penyebaran AD DS Anda, mari kita kembali menggunakan metafora jalan raya yang sebelumnya kita gunakan dalam kecepatan CPU versus pertimbangan multi-inti.
Waktu yang lebih sibuk pada pertengahan sore akan jatuh ke suatu tempat ke dalam kisaran kapasitas 40% hingga 70%. Ada cukup lalu lintas sehingga kemampuan Anda untuk memilih jalur yang akan dilalui tidak terlalu dibatasi. Meskipun kemungkinan pengemudi lain menghalangi jalan Anda tinggi, tidak memerlukan tingkat upaya yang sama, Anda harus menemukan celah yang aman antara mobil lain di jalur seperti pada jam sibuk.
Ketika jam sibuk mendekat, sistem jalan mendekati kapasitas 100%. Mengubah jalur pada jam sibuk menjadi sangat menantang karena mobil sangat berdekatan sehingga Anda tidak memiliki banyak ruang untuk bermanuver saat mengubah jalur.
Inilah sebabnya mengapa memperkirakan rata-rata jangka panjang untuk kapasitas pada 40% memungkinkan lebih banyak ruang kepala untuk lonjakan beban abnormal, apakah lonjakan tersebut bersifat transitori, seperti dengan kueri berkode buruk yang membutuhkan waktu cukup lama untuk dijalankan, atau ledakan abnormal dalam beban umum, seperti lonjakan aktivitas di pagi hari setelah akhir pekan liburan.
Pernyataan sebelumnya mengenai persentase perhitungan waktu prosesor sama dengan persamaan hukum pemanfaatan. Versi yang disederhanakan ini dimaksudkan untuk memperkenalkan konsep kepada pengguna baru. Namun, untuk matematika yang lebih canggih, Anda dapat menggunakan referensi berikut sebagai panduan:
- Menerjemahkan PERF_100NSEC_TIMER_INV
- B = Jumlah interval 100-ns yang dihabiskan utas menganggur pada prosesor logis. Perubahan variabel X dalam perhitungan PERF_100NSEC_TIMER_INV
- T = jumlah total interval 100-ns dalam rentang waktu tertentu. Perubahan variabel Y dalam perhitungan PERF_100NSEC_TIMER_INV .
- U k = Persentase pemanfaatan prosesor logis oleh Thread Idle atau % Idle Time.
- Mengerjakan matematika:
- U k = 1 – Waktu %Processor
- %Processor Waktu = 1 – U k
- %Processor Waktu = 1 – B / T
- %Processor Waktu = 1 – X1 – X0 / Y1 – Y0
Menerapkan konsep ini ke perencanaan kapasitas
Matematika di bagian sebelumnya mungkin membuat menentukan berapa banyak prosesor logis yang Anda butuhkan dalam sistem tampaknya sangat kompleks. Akibatnya, pendekatan Anda untuk mengukur sistem harus fokus pada penentuan pemanfaatan target maksimum berdasarkan beban saat ini, lalu menghitung jumlah prosesor logis yang Anda butuhkan untuk mencapai target tersebut. Selain itu, perkiraan Anda tidak perlu tepat. Meskipun kecepatan prosesor logis memang berdampak signifikan pada sinkronisasi, performa juga dapat dipengaruhi oleh area lain:
- Efisiensi cache
- Persyaratan koherensi memori
- Penjadwalan dan sinkronisasi alur
- Beban klien yang tidak seimbang
Karena daya komputasi relatif berbiaya rendah, tidak ada baiknya menginvestasikan terlalu banyak waktu dalam menghitung jumlah CPU yang sangat tepat yang Anda butuhkan.
Penting juga untuk diingat bahwa rekomendasi 40%, dalam hal ini, bukan persyaratan wajib. Kami menggunakannya sebagai awal yang wajar untuk membuat perhitungan. Berbagai jenis pengguna AD membutuhkan tingkat respons yang berbeda. Bahkan mungkin ada skenario di mana lingkungan dapat berjalan pada pemanfaatan 80% atau bahkan 90% pada rata-rata berkelanjutan tanpa peningkatan waktu tunggu untuk akses prosesor yang sangat memengaruhi performa klien.
Ada juga area lain dalam sistem yang jauh lebih lambat daripada prosesor logis yang juga harus Anda setel, termasuk akses RAM, akses disk, dan respons transmisi melalui jaringan. Contohnya:
Jika Anda menambahkan prosesor ke sistem yang berjalan pada pemanfaatan 90% yang terikat disk, mungkin tidak akan secara signifikan meningkatkan performa. Jika Anda melihat lebih dekat sistem, ada banyak utas yang bahkan tidak masuk ke prosesor karena mereka menunggu operasi I/O selesai.
Mengatasi masalah terikat disk dapat berarti bahwa utas yang sebelumnya macet dalam status tunggu berhenti macet, menciptakan lebih banyak persaingan untuk waktu CPU. Akibatnya, pemanfaatan 90% akan menjadi 100%. Anda perlu menyetel kedua komponen untuk menurunkan pemanfaatan kembali ke tingkat yang dapat dikelola.
Catatan
Penghitung
Processor Information(*)\% Processor Utilitydapat melebihi 100% dengan sistem yang memiliki mode Turbo. Mode turbo memungkinkan CPU melebihi kecepatan prosesor yang dinilai untuk jangka pendek. Jika Anda memerlukan informasi lebih lanjut, lihat dokumentasi produsen CPU dan deskripsi penghitung.
Membahas pertimbangan pemanfaatan seluruh sistem juga melibatkan pengendali domain sebagai tamu virtual. Waktu respons dan bagaimana tingkat aktivitas sistem memengaruhi performa berlaku untuk host dan tamu dalam skenario virtual. Dalam host hanya dengan satu tamu, DC atau sistem memiliki performa yang hampir sama seperti pada perangkat keras fisik. Menambahkan lebih banyak tamu ke host meningkatkan pemanfaatan host yang mendasar, juga meningkatkan waktu tunggu untuk mendapatkan akses ke prosesor. Oleh karena itu, Anda harus mengelola pemanfaatan prosesor logis di tingkat host dan tamu.
Mari kita lihat kembali metafora jalan raya dari bagian sebelumnya, hanya saja kali ini kita membayangkan VM tamu sebagai bus ekspres. Bus ekspres, dibandingkan dengan bus angkutan umum atau sekolah, langsung menuju tujuan pengendara tanpa berhenti.
Sekarang, mari kita bayangkan empat skenario:
- Jam sibuk sistem seperti naik bus ekspres larut malam. Ketika pengendara naik, hampir tidak ada penumpang lain dan jalan hampir kosong. Karena tidak ada lalu lintas untuk bersaing dengan bus, perjalanan mudah dan secepat jika pengendara telah mengemudi di sana dengan mobil mereka sendiri. Namun, waktu tempuh pengendara juga dibatasi oleh batas kecepatan lokal.
- Jam sibuk ketika pemanfaatan CPU sistem terlalu tinggi seperti perjalanan larut malam ketika sebagian besar jalur di jalan raya ditutup. Meskipun bus itu sendiri sebagian besar kosong, jalan masih padat dari lalu lintas sisa yang berurusan dengan jalur terbatas. Meskipun pengendara bebas duduk di mana saja yang mereka inginkan, waktu perjalanan mereka yang sebenarnya ditentukan oleh lalu lintas di luar bus.
- Sistem dengan pemanfaatan CPU yang tinggi selama jam sibuk seperti bus pada jam sibuk. Perjalanan tidak hanya memakan waktu lebih lama, tetapi naik dan turun bus lebih sulit karena bus penuh dengan penumpang lain. Menambahkan lebih banyak prosesor logis ke sistem tamu untuk mencoba mempercepat waktu tunggu akan seperti mencoba menyelesaikan masalah lalu lintas dengan menambahkan lebih banyak bus. Masalahnya bukan jumlah bus, tetapi berapa lama perjalanan berlangsung.
- Sistem dengan pemanfaatan CPU tinggi selama jam sibuk seperti itu bus ramai yang sama di jalan yang sebagian besar kosong di malam hari. Sementara pengendara mungkin kesulitan menemukan tempat duduk atau naik dan turun bus, perjalanan cukup lancar setelah bus mengambil semua penumpangnya. Skenario ini adalah satu-satunya di mana performa akan meningkat dengan menambahkan lebih banyak bus.
Berdasarkan contoh sebelumnya, Anda dapat melihat bahwa ada banyak skenario antara pemanfaatan 0% dan 100% yang memiliki berbagai tingkat dampak pada performa. Selain itu, menambahkan prosesor yang lebih logis tidak selalu meningkatkan performa di luar skenario yang sangat spesifik. Harus cukup sederhana untuk menerapkan prinsip-prinsip ini ke target pemanfaatan CPU 40% yang direkomendasikan untuk host dan tamu.
Lampiran B: Pertimbangan mengenai kecepatan prosesor yang berbeda
Dalam Pemrosesan, kami berasumsi bahwa prosesor berjalan pada kecepatan jam 100% saat Anda mengumpulkan data, dan bahwa setiap sistem pengganti memiliki kecepatan pemrosesan yang sama. Meskipun asumsi ini tidak akurat, terutama untuk Windows Server 2008 R2 dan yang lebih baru, di mana rencana daya default Seimbang, asumsi ini masih berfungsi untuk perkiraan konservatif. Meskipun potensi kesalahan dapat meningkat, itu hanya meningkatkan margin keamanan saat kecepatan prosesor meningkat.
- Misalnya, dalam skenario yang menuntut CPU 11,25, jika prosesor berjalan dengan kecepatan setengah saat Anda mengumpulkan data Anda, perkiraan yang lebih akurat dari permintaan mereka adalah 5,125 ÷ 2.
- Tidak mungkin untuk menjamin bahwa menggandakan kecepatan jam menggandakan jumlah pemrosesan yang terjadi dalam periode waktu yang dicatat. Jumlah waktu yang dihabiskan prosesor untuk menunggu RAM atau komponen lain tetap kurang lebih sama. Oleh karena itu, prosesor yang lebih cepat mungkin menghabiskan persentase waktu diam yang lebih besar sambil menunggu sistem mengambil data. Kami sarankan Anda tetap dengan denominator umum terendah, jaga perkiraan Anda tetap konservatif, dan hindari dengan asumsi perbandingan linier antara kecepatan prosesor yang dapat membuat hasil Anda tidak akurat.
Jika kecepatan prosesor dalam perangkat keras pengganti Anda lebih rendah dari perangkat keras Anda saat ini, Anda harus secara proporsional meningkatkan perkiraan berapa banyak prosesor yang Anda butuhkan. Misalnya, mari kita lihat skenario di mana Anda menghitung Bahwa Anda memerlukan 10 prosesor untuk mempertahankan beban situs Anda. Prosesor saat ini berjalan pada 3,3 GHz, dan prosesor yang Anda rencanakan untuk menggantinya dengan eksekusi pada 2,6 GHz. Mengganti hanya 10 prosesor asli yang akan memberi Anda penurunan kecepatan 21%. Untuk meningkatkan kecepatan, Anda perlu mendapatkan setidaknya 12 prosesor alih-alih 10.
Namun, varianbilitas ini tidak mengubah target pemanfaatan prosesor manajemen kapasitas. Kecepatan jam prosesor menyesuaikan secara dinamis berdasarkan permintaan beban, sehingga menjalankan sistem di bawah beban yang lebih tinggi menyebabkan CPU menghabiskan lebih banyak waktu dalam keadaan kecepatan jam yang lebih tinggi. Tujuan utamanya adalah agar CPU berada pada pemanfaatan 40% dalam status kecepatan jam 100% selama jam kerja puncak. Apa pun yang kurang akan menghasilkan penghematan daya dengan membatasi kecepatan CPU selama skenario di luar puncak.
Catatan
Anda dapat menonaktifkan manajemen daya pada prosesor selama pengumpulan data dengan mengatur rencana daya ke Performa Tinggi. Mematikan manajemen daya memberi Anda pembacaan konsumsi CPU yang lebih akurat di server target.
Untuk menyesuaikan perkiraan untuk prosesor yang berbeda, kami sarankan Anda menggunakan tolok ukur SPECint_rate2006 dari Standard Performance Evaluation Corporation. Untuk menggunakan tolok ukur ini:
Kunjungi ke situs web Standard Performance Evaluation Corporation (SPEC).
Pilih Hasil.
Masukkan CPU2006 dan pilih Cari.
Di menu drop-down untuk Konfigurasi yang Tersedia, pilih Semua CPU2006 SPEC.
Di bidang Permintaan Formulir Pencarian , pilih Sederhana, lalu pilih Buka!.
Di bawah Permintaan Sederhana, masukkan kriteria pencarian untuk prosesor target Anda. Misalnya, jika Anda mencari prosesor ES-2630, di menu drop-down, pilih Prosesor, lalu masukkan nama prosesor di bidang pencarian. Setelah selesai, pilih Jalankan Pengambilan Sederhana.
Cari konfigurasi server dan prosesor Anda di hasil pencarian. Jika mesin pencari tidak mengembalikan kecocokan yang tepat, cari kecocokan terdekat yang mungkin.
Rekam nilai dalam kolom Hasil dan # Core .
Tentukan pengubah dengan menggunakan persamaan ini:
((Nilai skor per inti platform target) × (MHz per inti pada platform dasar)) ÷ ((Nilai skor per inti pada platform dasar) × (MHz per inti pada platform target))
Misalnya, berikut adalah cara Anda menemukan pengubah untuk prosesor ES-2630:
(35,83 × 2000) ÷ (33,75 × 2300) = 0,92
Kalikan jumlah prosesor yang Anda perkirakan yang Anda butuhkan oleh pengubah ini.
Untuk contoh prosesor ES-2630, 0,92 × 10,3 = 10,35 prosesor.
Lampiran C: Bagaimana sistem operasi berinteraksi dengan penyimpanan
Konsep teori antrean yang kami bahas dalam Waktu respons dan bagaimana tingkat aktivitas sistem memengaruhi performa juga berlaku untuk penyimpanan. Anda harus terbiasa dengan bagaimana OS Anda menangani I/O untuk menerapkan konsep ini secara efektif. Di OS Windows, OS membuat antrean yang menyimpan permintaan I/O untuk setiap disk fisik. Namun, disk fisik belum tentu satu disk. OS juga dapat mendaftarkan agregasi spindle pada pengontrol array atau SAN sebagai disk fisik. Pengontrol array dan SAN juga dapat menggabungkan beberapa disk menjadi satu set array, membaginya menjadi beberapa partisi, lalu menggunakan setiap partisi sebagai disk fisik, seperti yang ditunjukkan pada gambar berikut.
Dalam ilustrasi ini, dua spindel dicerminkan dan dibagi menjadi area logis untuk penyimpanan data, berlabel Data 1 dan Data 2. OS mendaftarkan masing-masing area logis ini sebagai disk fisik terpisah.
Sekarang setelah kami mengklarifikasi apa yang mendefinisikan disk fisik, Anda juga harus terbiasa dengan istilah-istilah berikut untuk membantu Anda lebih memahami informasi dalam Lampiran ini.
- Spindle adalah perangkat yang diinstal secara fisik di server.
- Array adalah kumpulan spindle yang dikumpulkan oleh pengontrol.
- Partisi array adalah partisi dari array agregat.
- Nomor Unit Logis (LUN) adalah array perangkat SCSI yang terhubung ke komputer. Artikel ini menggunakan istilah-istilah ini saat berbicara tentang WAN.
- Disk mencakup spindle atau partisi apa pun yang didaftarkan OS sebagai disk fisik tunggal.
- Partisi adalah pembagian logis dari apa yang dikenali OS sebagai disk fisik.
Pertimbangan arsitektur sistem operasi
OS membuat antrean I/O First In, First Out (FIFO) untuk setiap disk yang didaftarkannya. Disk ini dapat berupa spindle, array, atau partisi array. Ketika datang ke bagaimana OS menangani I/O, semakin aktif antrean, semakin baik. Ketika OS menserialisasikan antrean FIFO, OS harus memproses semua permintaan I/O FIFO yang dikeluarkan ke subsistem penyimpanan dalam urutan kedatangan. Ketika OS menghubungkan setiap disk dengan spindle atau array, OS mempertahankan antrean I/O untuk setiap set disk yang unik, menghilangkan persaingan untuk sumber daya I/O yang langka di seluruh disk dan mengisolasi permintaan I/O ke satu disk. Namun, Windows Server 2008 memperkenalkan pengecualian dalam bentuk prioritas I/O. Aplikasi yang dirancang untuk menggunakan I/O prioritas rendah dipindahkan ke bagian belakang antrean tidak peduli kapan OS menerimanya. Aplikasi tidak secara khusus dikodekan untuk menggunakan pengaturan prioritas rendah default ke prioritas normal sebagai gantinya.
Memperkenalkan subsistem penyimpanan sederhana
Di bagian ini, kita berbicara tentang subsistem penyimpanan sederhana. Mari kita mulai dengan contoh: satu hard drive di dalam komputer. Jika kita memecah sistem ini menjadi komponen subsistem penyimpanan utamanya, inilah yang kita dapatkan:
- Satu 10.000 RPM Ultra Fast SCSI HD (Ultra Fast SCSI memiliki tingkat transfer 20 MBps)
- Satu SCSI Bus (kabel)
- Satu Adaptor SCSI Ultra Cepat
- Satu bus PCI 32-bit 33 MHz
Catatan
Contoh ini tidak mencerminkan cache disk di mana sistem biasanya menyimpan data satu silinder. Dalam hal ini, I/O pertama membutuhkan 10 mdtk dan disk membaca seluruh silinder. Semua I/Os berurutan lainnya dipenuhi oleh cache. Akibatnya, cache dalam disk dapat meningkatkan performa I/O berurutan.
Setelah mengidentifikasi komponen, Anda dapat mulai mendapatkan gambaran tentang berapa banyak data yang dapat ditransmisikan sistem dan berapa banyak I/O yang dapat ditanganinya. Jumlah I/O dan kuantitas data yang dapat transit sistem terkait satu sama lain, tetapi bukan nilai yang sama. Korelasi ini tergantung pada ukuran blok dan apakah I/O disk acak atau berurutan. Sistem menulis semua data ke disk sebagai blok, tetapi aplikasi yang berbeda dapat menggunakan ukuran blok yang berbeda.
Selanjutnya, mari kita analisis item ini berdasarkan komponen demi komponen.
Waktu akses hard drive
Hard drive 10.000 RPM rata-rata memiliki waktu pencarian 7 mdtk dan waktu akses 3 mdtk. Waktu pencarian adalah jumlah waktu rata-rata yang dibutuhkan kepala baca atau tulis untuk pindah ke lokasi di piring. Waktu akses adalah jumlah waktu rata-rata yang diperlukan kepala untuk membaca atau menulis data ke disk setelah berada di lokasi yang benar. Oleh karena itu, waktu rata-rata untuk membaca blok data unik dalam HD 10.000-RPM mencakup waktu pencarian dan akses dengan total sekitar 10 md, atau .010 detik, per blok data.
Ketika setiap akses disk memerlukan pemindahan kepala ke lokasi baru pada disk, perilaku baca atau tulis disebut acak. Ketika semua I/O acak, HD 10.000 RPM dapat menangani sekitar 100 I/O per detik (IOPS).
Ketika semua I/O terjadi dari sektor yang berdekatan pada hard drive, kami menyebutnya I/O berurutan. I/O berurutan tidak memiliki waktu pencarian karena, setelah I/O pertama selesai, kepala baca atau tulis berada di awal tempat hard drive menyimpan blok data berikutnya. Misalnya, HD 10.000 RPM mampu menangani sekitar 333 I/O per detik, berdasarkan persamaan berikut:
1000 md per detik ÷ 3 mdtk per I/O
Sejauh ini, tingkat transfer hard drive belum relevan dengan contoh kami. Tidak peduli ukuran hard drive, jumlah Aktual IOPS yang dapat ditangani HD 10.000-RPM selalu sekitar 100 acak atau 300 I/Os berurutan. Ketika ukuran blok berubah berdasarkan aplikasi mana yang menulis ke drive, jumlah data yang ditarik per I/O juga berubah. Misalnya, jika ukuran blok adalah 8 KB, 100 operasi I/O akan membaca dari atau menulis ke hard drive total 800 KB. Namun, jika ukuran blok adalah 32 KB, 100 I/O akan membaca atau menulis 3.200 KB (3,2 MB) ke hard drive. Jika tingkat transfer SCSI melebihi jumlah total data yang ditransfer, maka mendapatkan tingkat transfer yang lebih cepat tidak mengubah apa pun. Untuk informasi selengkapnya, lihat tabel berikut ini:
| Deskripsi | 7200 RPM 9 ms pencarian, 4 ms akses | Pencarian 10.000 RPM 7 ms, akses 3 mdtk | Pencarian 15.000 RPM 4 ms, akses 2 ms |
|---|---|---|---|
| I/O acak | 80 | 100 | 150 |
| IO berurutan | 250 | 300 | 500 |
| 10.000 drive RPM | Ukuran blok 8 KB (Active Directory Jet) |
|---|---|
| I/O acak | 800 KB/dtk |
| IO berurutan | 2400 KB/dtk |
Backplane SCSI
Bagaimana backplane SCSI, yang dalam skenario contoh ini adalah kabel pita, memengaruhi throughput subsistem penyimpanan tergantung pada ukuran blok. Berapa banyak I/O yang dapat ditangani bus jika I/O berada di blok 8 KB? Dalam skenario ini, bus SCSI adalah 20 MBps, atau 20480 KB/dtk. 20480 KB/dtk dibagi 8 KB blok menghasilkan maksimum sekitar 2500 IOPS yang didukung oleh bus SCSI.
Catatan
Gambar dalam tabel berikut mewakili contoh skenario. Sebagian besar perangkat penyimpanan terpasang saat ini menggunakan PCI Express, yang menyediakan throughput yang jauh lebih tinggi.
| I/O yang didukung oleh bus SCSI per ukuran blok | Ukuran blok 2 KB | Ukuran blok 8 KB (AD Jet) (SQL Server 7.0/SQL Server 2000) |
|---|---|---|
| 20 MBps | 10.000 | 2.500 |
| 40 MBps | 20.000 | 5\.000 |
| 128 MBps | 65,536 | 16,384 |
| 320 MBps | 160.000 | 40.000 |
Seperti yang ditunjukkan tabel sebelumnya, dalam skenario contoh kami, bus tidak pernah menjadi hambatan karena maksimum spindle adalah 100 I/O, jauh di bawah salah satu ambang yang tercantum.
Catatan
Dalam skenario ini, kami berasumsi bahwa bus SCSI 100% efisien.
Adaptor SCSI
Untuk menentukan berapa banyak I/O yang dapat ditangani sistem, Anda harus memeriksa spesifikasi produsen. Mengarahkan permintaan I/O ke perangkat yang sesuai memerlukan daya pemrosesan, jadi berapa banyak I/O yang dapat ditangani sistem tergantung pada adaptor SCSI atau prosesor pengontrol array.
Dalam skenario contoh ini, kami berasumsi bahwa sistem dapat menangani 1.000 I/O.
Bus PCI
Bus PCI adalah komponen yang tidak terpakai. Dalam skenario contoh ini, bus PCI bukan penyempitan. Namun, ketika sistem meningkat, itu berpotensi menjadi hambatan di masa depan.
Kita dapat melihat berapa banyak bus PCI yang dapat mentransfer data dalam skenario contoh kita dengan menggunakan persamaan ini:
32 bit ÷ 8 bit per byte × 33 MHz = 133 MBps
Oleh karena itu, kita dapat mengasumsikan bus PCI 32 bit yang beroperasi pada 33 Mhz dapat mentransfer 133 MBps data.
Catatan
Hasil persamaan ini mewakili batas teoritis data yang ditransfer. Pada kenyataannya, sebagian besar sistem hanya mencapai sekitar 50% dari batas maksimum. Dalam skenario ledakan tertentu, sistem dapat mencapai 75% dari batas untuk jangka pendek.
Bus PCI 66 MHz 64-bit dapat mendukung maksimum teoritis 528 MBps berdasarkan persamaan ini:
64 bit ÷ 8 bit per byte × 66 Mhz = 528 MBps
Ketika Anda menambahkan perangkat lain, seperti adaptor jaringan atau pengontrol SCSI kedua, itu mengurangi bandwidth yang tersedia untuk sistem, karena semua perangkat berbagi bandwidth dan dapat bersaing satu sama lain untuk sumber daya pemrosesan terbatas.
Menganalisis subsistem penyimpanan untuk menemukan hambatan
Dalam skenario ini, spindle adalah faktor pembatasan berapa banyak I/O yang dapat Anda minta. Akibatnya, hambatan ini juga membatasi berapa banyak data yang dapat ditransmisikan sistem. Karena contoh kami adalah skenario AD DS, jumlah data yang dapat ditransmisikan adalah 100 I/O acak per detik dalam kenaikan 8 KB, dengan total 800 KB per detik saat Anda mengakses database Jet. Sebaliknya, throughput maksimum untuk spindle yang Anda konfigurasikan untuk secara eksklusif mengalokasikan ke file log akan dibatasi hingga 300 I/O berurutan per detik dalam angsuran 8 KB, berjumlah 2.400 KB atau 2,4 MB per detik.
Sekarang setelah kita menganalisis komponen konfigurasi contoh kita, mari kita lihat tabel yang menunjukkan di mana hambatan dapat terjadi saat kita menambahkan dan mengubah komponen di subsistem penyimpanan.
| Catatan | Analisis penyempitan | Diska | Bis | Adaptor | Bus PCI |
|---|---|---|---|---|---|
| Ini adalah konfigurasi pengendali domain setelah menambahkan disk kedua. Konfigurasi disk mewakili hambatan pada 800 KB/dtk. | Tambahkan 1 disk (Total=2) I/O acak Ukuran blok 4 KB 10.000 RPM HD |
Total I/Os 200 Total 800 KB/dtk. |
|||
| Setelah menambahkan 7 disk, konfigurasi disk masih mewakili hambatan pada 3200 KB/dtk. | Menambahkan 7 disk (Total=8) I/O acak Ukuran blok 4 KB 10.000 RPM HD |
Total 800 I/Os. Total 3200 KB/dtk |
|||
| Setelah mengubah I/O ke berurutan, adaptor jaringan menjadi hambatan karena terbatas pada 1000 IOPS. | Menambahkan 7 disk (Total=8) I/O berurutan Ukuran blok 4 KB 10.000 RPM HD |
2400 I/O detik dapat dibaca/ditulis ke disk, pengontrol dibatasi hingga 1000 IOPS | |||
| Setelah mengganti adaptor jaringan dengan adaptor SCSI yang mendukung 10.000 IOPS, hambatan kembali ke konfigurasi disk. | Menambahkan 7 disk (Total=8) I/O acak Ukuran blok 4 KB 10.000 RPM HD Meningkatkan adaptor SCSI (sekarang mendukung 10.000 I/O) |
Total 800 I/Os. Total 3.200 KB/dtk |
|||
| Setelah meningkatkan ukuran blok menjadi 32 KB, bus menjadi hambatan karena hanya mendukung 20 MBps. | Menambahkan 7 disk (Total=8) I/O acak Ukuran blok 32 KB 10.000 RPM HD |
Total 800 I/Os. 25.600 KB/dtk (25 MBps) dapat dibaca/ditulis ke disk. Bus hanya mendukung 20 MBps |
|||
| Setelah meningkatkan bus dan menambahkan lebih banyak disk, disk tetap menjadi hambatan. | Menambahkan 13 disk (Total=14) Menambahkan adaptor SCSI kedua dengan 14 disk I/O acak Ukuran blok 4 KB 10.000 RPM HD Tingkatkan ke bus SCSI 320 MBps |
2800 I/O 11.200 KB/dtk (10,9 MBps) |
|||
| Setelah mengubah I/O ke berurutan, disk tetap menjadi hambatan. | Menambahkan 13 disk (Total=14) Menambahkan Adaptor SCSI kedua dengan 14 disk I/O berurutan Ukuran blok 4 KB 10.000 RPM HD Tingkatkan ke bus SCSI 320 MBps |
8.400 I/Os 33.600 KB\s (32,8 MB\s) |
|||
| Setelah menambahkan hard drive yang lebih cepat, disk tetap menjadi hambatan. | Menambahkan 13 disk (Total=14) Menambahkan adaptor SCSI kedua dengan 14 disk I/O berurutan Ukuran blok 4 KB 15.000 RPM HD Tingkatkan ke bus SCSI 320 MBps |
14.000 I/Os 56.000 KB/dtk (54,7 MBps) |
|||
| Setelah meningkatkan ukuran blok menjadi 32 KB, bus PCI menjadi hambatan. | Menambahkan 13 disk (Total=14) Menambahkan adaptor SCSI kedua dengan 14 disk I/O berurutan Ukuran blok 32 KB 15.000 RPM HD Tingkatkan ke bus SCSI 320 MBps |
14.000 I/Os 448.000 KB/dtk (437 MBps) adalah batas baca/tulis pada spindle. Bus PCI mendukung maksimum teoritis 133 MBps (paling baik 75% efisien). |
Memperkenalkan RAID
Ketika Anda memperkenalkan pengontrol array ke subsistem penyimpanan Anda, itu tidak mengubah sifatnya secara dramatis. Pengontrol array hanya menggantikan adaptor SCSI dalam perhitungan. Namun, biaya membaca dan menulis data ke disk saat Anda menggunakan berbagai tingkat array memang berubah.
Di RAID 0, penulisan data menghapusnya di semua disk dalam kumpulan RAID. Selama operasi baca atau tulis, sistem menarik data dari atau mendorongnya ke setiap disk, meningkatkan jumlah data yang dapat ditransmisikan sistem selama periode waktu tertentu ini. Oleh karena itu, dalam contoh ini di mana kita menggunakan 10.000 drive RPM, menggunakan RAID 0 akan memungkinkan Anda melakukan 100 operasi I/O. Jumlah total I/O yang didukung sistem adalah spindel N kali 100 1/O per detik per spindle, atau spindel N × 100 I/O per detik per spindle.

Di RAID 1, sistem mencerminkan, atau menduplikasi, data di sepasang spindle untuk redundansi. Ketika sistem melakukan operasi I/O baca, sistem dapat membaca data dari kedua spindel dalam set. Pencerminan ini membuat kapasitas I/O untuk kedua disk tersedia selama operasi baca. Namun, RAID 1 tidak memberikan operasi tulis keuntungan performa apa pun, karena sistem juga perlu mencerminkan data tertulis pada pasangan spindle. Meskipun pencerminan tidak membuat operasi tulis membutuhkan waktu lebih lama, itu mencegah sistem membuat lebih dari satu operasi baca pada saat yang sama. Oleh karena itu, setiap operasi I/O tulis dikenakan biaya dua operasi baca I/O.
Persamaan berikut menghitung berapa banyak operasi I/O yang terjadi dalam skenario ini:
Baca I/O + 2 × Tulis I/O = Total I/O disk tersedia yang digunakan
Ketika Anda mengetahui rasio bacaan untuk menulis dan jumlah spindel dalam penyebaran Anda, Anda dapat menggunakan persamaan ini untuk menghitung berapa banyak I/O yang dapat didukung array Anda:
IOPS maksimum per spindle × 2 spindel × [(% Reads + % Writes) ÷ (% Reads + 2 × % Writes)] = Total IOPS
Skenario yang menggunakan RAID 1 dan RAID 0 berperilaku persis seperti RAID 1 dalam biaya operasi membaca dan menulis. Namun, I/O sekarang bergaris di setiap set cermin. Ini berarti persamaan akan berubah menjadi ini:
IOPS maksimum per spindel × 2 spindel × [(% Reads + % Writes) ÷ (% Reads + 2 × % Writes)] = Total I/O
Dalam set RAID 1, ketika Anda membagi jumlah N set RAID 1, total I/O yang dapat diproses oleh array menjadi N × I/O per set RAID 1.
N × {IOPS maksimum per spindel × 2 spindel × [(% Baca + % Menulis) ÷ (% Baca + 2 × % Menulis)]} = Total IOPS
Kami terkadang memanggil RAID 5 N + 1 RAID karena sistem melucuti data di seluruh spindel N dan menulis informasi paritas ke spindle + 1 . Namun, RAID 5 menggunakan lebih banyak sumber daya saat melakukan I/O tulis daripada RAID 1 atau RAID 1 + 0. RAID 5 melakukan proses berikut setiap kali sistem operasi mengirimkan I/O tulis ke array:
- Baca data lama.
- Baca paritas lama.
- Tulis data baru.
- Tulis paritas baru.
Setiap permintaan I/O tulis yang dikirim OS ke pengontrol array memerlukan empat operasi I/O untuk diselesaikan. Oleh karena itu, permintaan penulisan RAID N + 1 memerlukan waktu empat kali lebih lama dari penyelesaian I/O baca. Dengan kata lain, untuk menentukan berapa banyak permintaan I/O dari OS yang diterjemahkan ke berapa banyak permintaan yang didapatkan spindle, Anda menggunakan persamaan ini:
Baca I/O + 4 × Tulis I/O = Total I/O
Demikian pula, dalam set RAID 1 di mana Anda tahu rasio bacaan untuk menulis dan berapa banyak spindel yang ada, Anda dapat menggunakan persamaan ini untuk mengidentifikasi berapa banyak I/O yang dapat didukung array Anda:
IOPS per spindel × (Spindel – 1) × [(% Membaca + % Menulis) ÷ (% Membaca + 4 × % Tulis)] = Total IOPS
Catatan
Hasil persamaan sebelumnya tidak termasuk drive yang hilang ke paritas.
Memperkenalkan ASI
Saat Anda memperkenalkan jaringan area penyimpanan (SAN) ke lingkungan Anda, itu tidak memengaruhi prinsip perencanaan yang telah kami jelaskan di bagian sebelumnya. Namun, Anda harus memperhitungkan bahwa SAN dapat mengubah perilaku I/O untuk semua sistem yang terhubung ke dalamnya. Salah satu keuntungan utama menggunakan SAN adalah memberi Anda lebih banyak redundansi daripada penyimpanan yang terpasang secara internal atau eksternal, tetapi itu juga berarti rencana kapasitas Anda perlu memperhitungkan kebutuhan toleransi kesalahan. Selain itu, saat Anda memperkenalkan lebih banyak komponen ke sistem Anda, Anda juga perlu memperhitungkan bagian-bagian baru ini ke dalam perhitungan Anda.
Sekarang, mari kita bagi SAN ke dalam komponennya:
- Hard drive SCSI atau Fibre Channel
- Backplane saluran unit penyimpanan
- Unit penyimpanan itu sendiri
- Modul pengontrol penyimpanan
- Satu atau beberapa sakelar SAN
- Satu atau beberapa adaptor bus host (HBA)
- Bus interkoneksi komponen periferal (PCI)
Ketika Anda merancang sistem untuk redundansi, Anda harus menyertakan komponen tambahan untuk memastikan sistem Anda terus bekerja selama skenario krisis di mana satu atau beberapa komponen asli berhenti berfungsi. Namun, ketika Anda merencanakan kapasitas, Anda perlu mengecualikan komponen redundan dari sumber daya yang tersedia untuk mendapatkan perkiraan akurat dari kapasitas garis besar sistem Anda, karena komponen-komponen tersebut biasanya tidak online kecuali ada keadaan darurat. Misalnya, jika SAN Anda memiliki dua modul pengontrol, Anda hanya perlu menggunakannya saat menghitung total throughput I/O yang tersedia, karena yang lain tidak akan menyala kecuali modul asli berhenti berfungsi. Anda juga tidak boleh membawa sakelar SAN yang berlebihan, unit penyimpanan, atau spindle ke dalam perhitungan I/O.
Selain itu, karena perencanaan kapasitas Anda hanya mempertimbangkan periode penggunaan puncak, Anda tidak boleh memperhitungkan komponen redundan ke dalam sumber daya yang tersedia. Pemanfaatan puncak tidak boleh melebihi 80% saturasi sistem untuk mengakomodasi ledakan atau perilaku sistem lain yang tidak biasa.
Ketika Anda menganalisis perilaku hard drive SCSI atau Fibre Channel, Anda harus menganalisisnya sesuai dengan prinsip yang kami uraikan di bagian sebelumnya. Meskipun setiap protokol memiliki kelebihan dan kekurangannya sendiri, hal utama yang membatasi performa berdasarkan per disk adalah keterbatasan mekanis hard drive.
Ketika Menganalisis saluran pada unit penyimpanan, Anda harus mengambil pendekatan yang sama dengan yang Anda lakukan saat menghitung berapa banyak sumber daya yang tersedia di bus SCSI: bagi bandwidth dengan ukuran blok. Misalnya, jika unit penyimpanan Anda memiliki enam saluran yang masing-masing mendukung tingkat transfer maksimum 20 MBps, jumlah total I/O dan transfer data yang tersedia adalah 100 MBps. Alasan totalnya adalah 100 MBps alih-alih 120 MBps adalah karena throughput total saluran penyimpanan tidak boleh melebihi jumlah throughput yang akan digunakan jika salah satu saluran tiba-tiba dimatikan, meninggalkannya hanya dengan lima saluran yang berfungsi. Tentu saja, contoh ini juga mengasumsikan bahwa sistem mendistribusikan beban dan toleransi kesalahan secara merata di semua saluran.
Apakah Anda dapat mengubah contoh sebelumnya menjadi profil I/O tergantung pada perilaku aplikasi. Untuk Active Directory Jet I/O, nilai maksimumnya adalah sekitar 12.500 I/O per detik, atau 100 MBps ÷ 8 KB per I/O.
Untuk memahami berapa banyak throughput yang didukung modul pengontrol Anda, Anda juga perlu mendapatkan spesifikasi produsennya. Dalam contoh ini, SAN memiliki dua modul pengontrol yang mendukung masing-masing 7.500 I/O. Jika Anda tidak menggunakan redundansi, maka total throughput sistem adalah 15.000 IOPS. Namun, dalam skenario di mana redundansi diperlukan, Anda akan menghitung throughput maksimum berdasarkan batas hanya salah satu pengontrol, yaitu 7.500 IOPS. Dengan asumsi bahwa ukuran blok adalah 4 KB, ambang batas ini jauh di bawah maksimum 12.500 IOPS yang dapat didukung saluran penyimpanan, dan oleh karena itu merupakan hambatan dalam analisis Anda. Namun, untuk tujuan perencanaan, I/O maksimum yang diinginkan yang harus Anda rencanakan adalah 10.400 I/O.
Ketika data meninggalkan modul pengontrol, data mengirimkan koneksi Fibre Channel yang dinilai pada 1 GBps, atau 128 MBps. Karena jumlah ini melebihi total bandwidth 100 MBps di semua saluran unit penyimpanan, itu tidak akan menyempitan sistem. Selain itu, karena transmisi ini hanya ada di salah satu dari dua Saluran Fiber karena redundansi, jika satu koneksi Fibre Channel berhenti berfungsi, koneksi yang tersisa masih memiliki kapasitas yang cukup untuk menangani permintaan transfer data.
Data kemudian transit sakelar SAN dalam perjalanan ke server. Sakelar membatasi jumlah I/O yang dapat ditangani karena perlu memproses permintaan masuk dan kemudian meneruskannya ke port yang sesuai. Namun, Anda hanya dapat mengetahui apa batas sakelar jika Anda melihat spesifikasi produsen. Misalnya, jika sistem Anda memiliki dua sakelar dan setiap sakelar dapat menangani 10.000 IOPS, total throughput akan menjadi 20.000 IOPS. Berdasarkan aturan toleransi kesalahan, jika satu sakelar berhenti berfungsi, total throughput sistem akan menjadi 10.000 IOPS. Oleh karena itu, selama keadaan normal, Anda tidak boleh menggunakan lebih dari 80% pemanfaatan, atau 8.000 I/O.
Akhirnya, HBA yang Anda instal di server juga membatasi berapa banyak I/O yang dapat ditanganinya. Biasanya, Anda menginstal HBA kedua untuk redundansi, tetapi seperti dengan sakelar SAN, ketika Anda menghitung berapa banyak I/O yang dapat ditangani sistem, total throughput akan menjadi N - 1 HBA.
Pertimbangan penembolokan
Cache adalah salah satu komponen yang dapat secara signifikan memengaruhi performa keseluruhan di mana saja dalam sistem penyimpanan. Namun, analisis terperinci tentang algoritma penembolokan berada di luar cakupan artikel ini. Sebagai gantinya, kami akan memberi Anda daftar cepat hal-hal yang harus Anda ketahui tentang penembolokan pada subsistem disk.
- Penembolokan meningkatkan I/O tulis berurutan berkelanjutan karena buffer banyak operasi tulis yang lebih kecil menjadi blok I/O yang lebih besar. Ini juga membatalkan operasi ke penyimpanan di beberapa blok besar alih-alih banyak yang kecil. Pengoptimalan ini mengurangi total operasi I/O acak dan berurutan, membuat lebih banyak sumber daya tersedia untuk operasi I/O lainnya.
- Penembolokan tidak meningkatkan throughput I/O tulis berkelanjutan pada subsistem penyimpanan karena hanya buffer yang menulis sampai spindle tersedia untuk menerapkan data. Ketika semua I/O yang tersedia dari spindle jenuh oleh data untuk jangka waktu yang lama, maka cache akhirnya terisi. Untuk mengosongkan cache, Anda harus menyediakan cukup I/O agar cache membersihkan dirinya sendiri dengan menyediakan spindel tambahan atau memberikan cukup waktu di antara semburan agar sistem mengejar ketinggalan.
- Cache yang lebih besar memungkinkan lebih banyak data untuk di-buffer, yang berarti cache dapat menangani periode saturasi yang lebih lama.
- Dalam subsistem penyimpanan umum, OS mengalami peningkatan performa tulis dengan cache, karena sistem hanya perlu menulis data ke cache. Namun, setelah media yang mendasarinya jenuh dengan operasi I/O, cache mengisi dan menulis performa kembali ke kecepatan disk reguler.
- Ketika Anda cache membaca I/O, cache paling berguna ketika Anda menyimpan data secara berurutan di meja dan memungkinkan cache untuk dibaca di depan. Membaca di depan adalah ketika cache dapat segera berpindah ke sektor berikutnya seolah-olah sektor berikutnya berisi data yang akan diminta sistem berikutnya.
- Ketika membaca I/O acak, penembolokan di pengontrol drive tidak meningkatkan berapa banyak data yang dapat dibaca disk. Jika os atau ukuran cache berbasis aplikasi lebih besar dari ukuran cache berbasis perangkat keras, maka setiap upaya untuk meningkatkan kecepatan baca disk tidak mengubah apa pun.
- Di Direktori Aktif, cache hanya dibatasi oleh jumlah RAM yang disimpan sistem.
Pertimbangan SSD
Solid state drive (SSD) pada dasarnya berbeda dari hard disk berbasis spindle. SSD dapat menangani volume I/O yang lebih tinggi dengan latensi yang lebih rendah. Meskipun SSD bisa mahal berdasarkan biaya per Gigabyte, SSD ini sangat murah dalam hal biaya per I/O. Namun, perencanaan kapasitas dengan SSD melibatkan pertanyaan yang sama dengan yang akan Anda tanyakan tentang spindle: berapa banyak IOPS yang dapat mereka tangani dan dan apa latensi IOPS tersebut?
Berikut adalah beberapa hal yang harus Anda pertimbangkan saat merencanakan SSD:
- IOPS dan latensi tunduk pada desain produsen. Dalam beberapa kasus, desain SSD tertentu dapat berkinerja lebih buruk daripada teknologi berbasis spindle. Ketika mencoba memutuskan apakah Anda harus menggunakan SSD atau spindle, Anda harus meninjau dan memvalidasi drive spesifikasi produsen dengan drive alih-alih mengasumsikan semua teknologi bekerja dengan cara tertentu.
- Jenis IOPS dapat memiliki nilai yang berbeda tergantung pada apakah mereka membaca atau menulis. Layanan AD DS sebagian besar berbasis baca, dan oleh karena itu kurang terpengaruh oleh teknologi tulis yang Anda gunakan membandingkan dto skenario aplikasi lainnya.
- Ketahanan tulis adalah asumsi bahwa sel SSD memiliki umur terbatas dan akhirnya akan aus setelah Anda menggunakannya banyak. Untuk drive database, profil I/O yang sebagian besar membaca memperluas daya tahan tulis sel ke titik di mana Anda tidak perlu khawatir tentang daya tahan tulis sebanyak itu.
Ringkasan
Bayangkan penyimpanan seperti pipa dalam ruangan rumah. IOPS media tempat Anda menyimpan data seperti pengurasan utama rumah. Ketika saluran utama tersumbat atau dibatasi oleh ukuran atau pipa runtuh, maka saluran air kembali ke atas dan tidak berfungsi dengan baik ketika rumah tangga menggunakan banyak air. Skenario ini seperti ketika lingkungan bersama memiliki satu atau beberapa sistem menggunakan penyimpanan bersama pada SAN, NAS, atau iSCSI yang sama dengan media yang mendasari yang sama. Karena permintaan pengguna melebihi kemampuan sistem untuk mengikuti, performa menderita.
Demikian juga, dalam skenario pipa imajiner kami, Anda dapat mengambil pendekatan yang berbeda untuk menyelesaikan penyumbatan dan masalah performa lainnya:
- Untuk mengatasi pipa pengosongan yang diciutkan atau pengosongan yang terlalu kecil, Anda perlu mengganti pipa dengan pipa yang berfungsi dan berukuran benar. Dalam istilah penyimpanan bersama, ini seperti menambahkan perangkat keras baru atau mendistribusikan ulang penggunaan pada sistem bersama di seluruh infrastruktur.
- Membatalkan pengelompokan pengurasan memerlukan identifikasi masalah yang mendasar dan lokasinya, lalu menghapusnya dengan alat yang sesuai. Misalnya, penyumbatan yang relatif sederhana di saluran air wastafel dapur hanya membutuhkan plunger atau pembersih pembuangan untuk dihilangkan, sementara bakiak yang lebih kompleks yang melibatkan objek yang terperangkap mungkin memerlukan ular pengosongan. Demikian juga, dalam sistem penyimpanan bersama, mengidentifikasi penyebab masalah performa membantu Anda mengetahui apakah Anda perlu membuat cadangan tingkat sistem, menyinkronkan pemindaian antivirus di semua server, atau menyinkronkan perangkat lunak defragmentasi yang Anda jalankan selama periode puncak.
Dalam sebagian besar desain pipa, beberapa saluran menguras masuk ke saluran utama. Ketika saluran air tersumbat, air hanya terperangkap di belakang titik di mana semanggi berada. Jika persimpangan tersumbat, maka semua pengurasan di belakang titik persimpangan itu berhenti menguras. Dalam skenario penyimpanan, persimpangan yang tersumbat seperti sakelar yang kelebihan beban, masalah kompatibilitas driver, atau tugas perangkat lunak yang tidak disinkronkan. Anda harus mengukur ukuran IOPS dan I/O untuk menentukan apakah sistem penyimpanan Anda dapat menangani beban, lalu menyesuaikan sistem sesuai kebutuhan.
Lampiran D: pemecahan masalah penyimpanan di lingkungan di mana lebih banyak RAM bukan opsi
Banyak rekomendasi penyimpanan sebelum penyimpanan virtual melayani dua tujuan:
- Mengisolasi I/O untuk mencegah masalah performa pada spindle OS memengaruhi performa untuk database dan profil I/O.
- Memanfaatkan peningkatan performa yang dapat diberikan oleh hard drive dan cache berbasis spindle pada sistem Anda saat digunakan dengan I/O berurutan file log AD DS. Mengisolasi I/O berurutan ke drive fisik terpisah juga dapat meningkatkan throughput.
Dengan opsi penyimpanan baru, banyak asumsi mendasar di balik rekomendasi penyimpanan sebelumnya tidak lagi benar. Skenario penyimpanan virtual, seperti file gambar iSCSI, SAN, NAS, dan Virtual Disk, sering berbagi media penyimpanan yang mendasarinya di beberapa host. Perbedaan ini meniadakan asumsi bahwa Anda harus mengisolasi I/O dan mengoptimalkan I/O berurutan. Sekarang host lain yang mengakses media bersama dapat mengurangi responsivitas terhadap pengendali domain.
Saat Anda merencanakan kapasitas untuk performa penyimpanan, Anda harus mempertimbangkan tiga hal:
- Status cache dingin
- Status cache hangat
- Pencadangan dan pemulihan
Status cache dingin adalah ketika Anda awalnya me-reboot pengontrol domain atau memulai ulang layanan Direktori Aktif, sehingga tidak ada data Direktori Aktif dalam RAM. Status cache hangat adalah ketika pengontrol domain beroperasi dalam keadaan stabil dan telah menyimpan cache database. Dalam hal desain performa, menghangatkan cache dingin seperti sprint, sementara menjalankan server dengan cache yang sepenuhnya dihangatkan seperti maraton. Mendefinisikan status ini dan profil performa yang berbeda yang mereka dorong penting, karena Anda perlu mempertimbangkannya baik saat memperkirakan kapasitas. Misalnya, hanya karena Anda memiliki CUKUP RAM untuk menyimpan seluruh database selama status cache hangat tidak membantu Anda mengoptimalkan performa selama status cache dingin.
Untuk kedua skenario cache, yang paling penting adalah seberapa cepat penyimpanan dapat memindahkan data dari disk ke memori. Saat Anda menghangatkan cache, performa dari waktu ke waktu meningkat saat kueri menggunakan kembali data, laju hit cache meningkat, dan frekuensi masuk ke disk untuk mengambil data berkurang. Akibatnya, dampak performa yang merugikan karena harus pergi ke disk juga berkurang. Setiap penurunan performa bersifat sementara dan biasanya hilang ketika cache mencapai keadaan hangat dan ukuran maksimum yang diizinkan sistem.
Anda dapat mengukur seberapa cepat sistem bisa mendapatkan data dari disk dengan mengukur IOPS yang tersedia di Direktori Aktif. Berapa banyak IOPS yang tersedia juga tunduk pada berapa banyak IOPS yang tersedia di penyimpanan yang mendasar. Dari perspektif perencanaan, karena menghangatkan status cache dan pencadangan atau pemulihan adalah peristiwa luar biasa yang biasanya terjadi di luar jam sibuk dan tunduk pada beban DC, kami tidak dapat memberikan rekomendasi umum selain hanya memasuki status ini selama jam sibuk.
Dalam sebagian besar skenario, AD DS sebagian besar membaca I/O dengan rasio baca 90% hingga 10% tulis. Baca I/O adalah hambatan khas untuk pengalaman pengguna, sementara tulis I/O adalah hambatan yang menurunkan performa tulis. Cache cenderung memberikan manfaat minimal untuk membaca I/O karena operasi I/O untuk file NTDS.dit sebagian besar acak. Oleh karena itu, prioritas utama Anda adalah memastikan Anda mengonfigurasi penyimpanan profil I/O baca dengan benar.
Dalam kondisi operasi normal, tujuan perencanaan penyimpanan Anda adalah untuk meminimalkan waktu tunggu bagi sistem untuk mengembalikan permintaan dari AD DS ke disk. Jumlah operasi I/O yang terutang dan tertunda harus kurang dari atau sama dengan jumlah jalur dalam disk. Untuk skenario pemantauan performa, kami umumnya menyarankan agar LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/Read penghitung harus kurang dari 20 mdtk. Anda harus mengatur ambang batas operasi jauh lebih rendah, sedekat mungkin dengan kecepatan penyimpanan, dalam kisaran dua hingga enam milidetik tergantung pada jenis penyimpanan.
Grafik baris berikut menunjukkan pengukuran latensi disk dalam sistem penyimpanan.
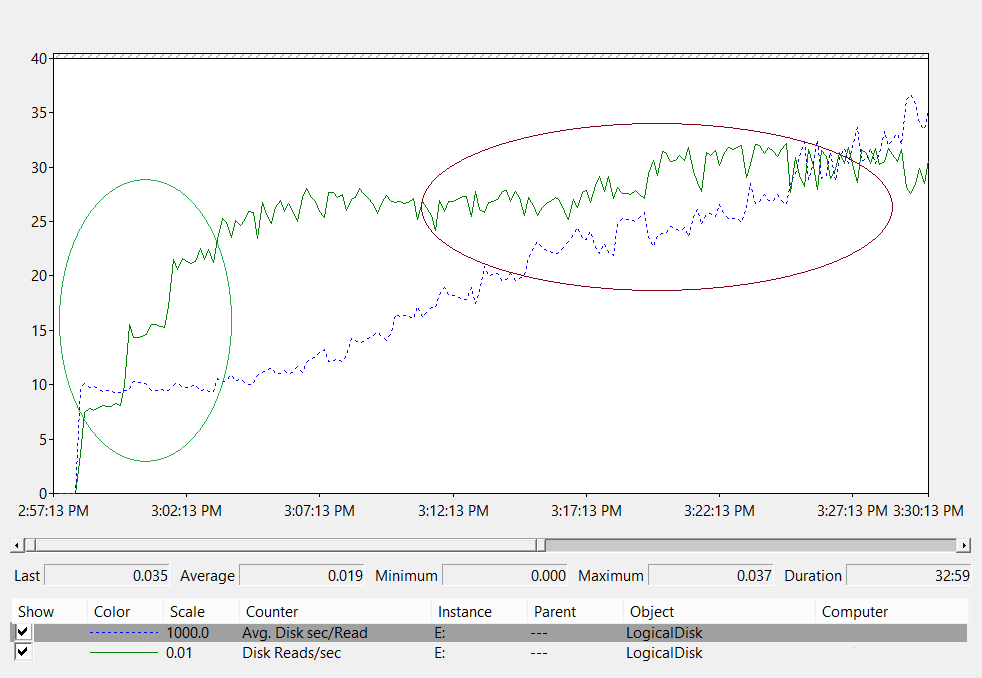
Mari kita analisis grafik baris ini:
- Area di sebelah kiri bagan yang dilingkari berwarna hijau menunjukkan latensi konsisten pada 10 ms saat beban meningkat dari 800 IOPS menjadi 2.400 IOPS. Area ini adalah garis besar seberapa cepat penyimpanan yang mendasar dapat memproses permintaan I/O. Namun, garis besar ini dipengaruhi oleh jenis solusi penyimpanan apa yang Anda gunakan.
- Area di sisi kanan bagan yang dilingkari secara maroon menunjukkan throughput sistem antara garis besar dan akhir pengumpulan data. Throughput itu sendiri tidak berubah, tetapi latensi meningkat. Area ini menunjukkan bagaimana permintaan menghabiskan waktu yang lebih lama untuk menunggu dalam antrean untuk dikirim ke subsistem penyimpanan setiap kali volume permintaan melebihi batas fisik penyimpanan yang mendasar.
Sekarang, mari kita pikirkan tentang apa yang dikatakan data ini kepada kita.
Pertama, mari kita asumsikan pengguna yang mengkueri keanggotaan grup besar memerlukan sistem membaca 1 MB data dari disk. Anda dapat mengevaluasi jumlah I/O yang diperlukan dan berapa lama operasi akan berlangsung dengan nilai-nilai ini:
- Ukuran setiap halaman database Direktori Aktif adalah 8 KB.
- Jumlah minimum halaman yang perlu dibaca sistem adalah 128.
- Oleh karena itu, pada area garis besar dalam diagram, sistem harus membutuhkan waktu setidaknya 1,28 detik untuk memuat data dari disk dan mengembalikannya ke klien. Pada tanda 20 ms, di mana throughput berjalan dengan baik di atas maksimum yang direkomendasikan, proses membutuhkan waktu 2,5 detik.
Berdasarkan angka-angka tersebut, Anda dapat menghitung seberapa cepat cache akan hangat dengan menggunakan persamaan ini:
2.400 IOPS × 8 KB per I/O
Setelah menjalankan perhitungan ini, kita dapat mengatakan bahwa tingkat hangat cache dalam skenario ini adalah 20 MBps. Dengan kata lain, sistem memuat sekitar 1 GB database ke dalam RAM setiap 53 detik.
Catatan
Biasanya melihat latensi naik untuk waktu singkat sementara komponen secara agresif membaca atau menulis ke disk. Misalnya, latensi meningkat ketika sistem mencadangkan atau AD DS menjalankan pengumpulan sampah. Anda harus menyediakan ruang tambahan untuk peristiwa berkala ini di atas perkiraan penggunaan asli Anda. Tujuan Anda adalah memberikan throughput yang cukup untuk mengakomodasi lonjakan ini tanpa memengaruhi fungsi keseluruhan.
Ada batas fisik untuk seberapa cepat cache menghangat berdasarkan cara Anda merancang sistem penyimpanan. Satu-satunya hal yang dapat menghangatkan cache hingga tingkat yang dapat diakomodasi penyimpanan yang mendasar adalah permintaan klien yang masuk. Menjalankan skrip untuk mencoba melakukan pra-pemanasan cache selama jam sibuk bersaing dengan permintaan klien nyata, meningkatkan beban keseluruhan, memuat data yang tidak relevan dengan permintaan klien, dan menurunkan performa. Sebaiknya hindari menggunakan tindakan buatan untuk menghangatkan cache.