WebNN API Tutorial
Untuk pengantroan ke WebNN, termasuk informasi tentang dukungan sistem operasi, dukungan model, dan lainnya, kunjungi Gambaran Umum WebNN.
Tutorial ini akan menunjukkan kepada Anda cara menggunakan WebNN API untuk membangun sistem klasifikasi gambar di web yang dipercepat perangkat keras menggunakan GPU pada perangkat. Kami akan memanfaatkan model MobileNetv2, yang merupakan model sumber terbuka pada Hugging Face yang digunakan untuk mengklasifikasikan gambar.
Jika Anda ingin melihat dan menjalankan kode akhir tutorial ini, Anda dapat menemukannya di GitHub Pratinjau Pengembang WebNN kami.
Catatan
API WebNN adalah Rekomendasi Kandidat W3C dan berada di tahap awal pratinjau pengembang. Beberapa fungsionalitas terbatas. Kami memiliki daftar dukungan dan status implementasi saat ini.
Persyaratan dan pengaturan:
Menyiapkan Windows
Pastikan Anda memiliki versi Edge, Windows, dan driver perangkat keras yang benar seperti yang dirinci di bagian Persyaratan WebNN.
Menyiapkan Edge
Unduh dan instal Microsoft Edge Dev.
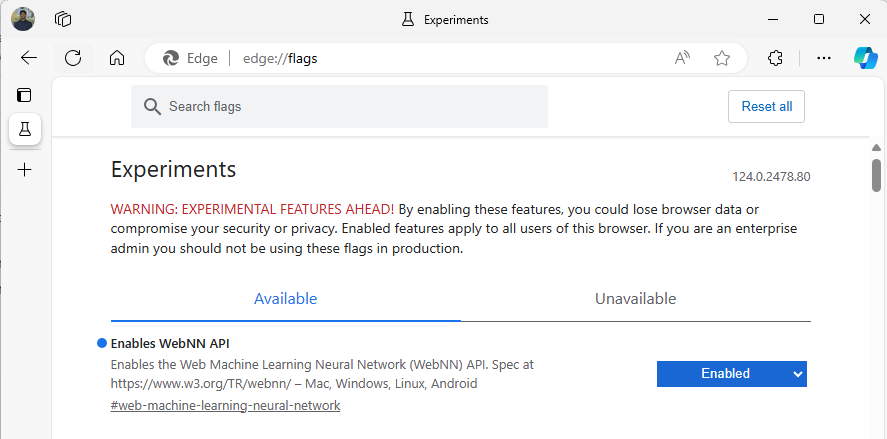
Luncurkan Edge Beta, dan navigasikan ke
about:flagsdi bilah alamat.Cari "WebNN API", klik menu dropdown, dan atur ke 'Diaktifkan'.
Mulai ulang Edge, seperti yang diminta.
Menyiapkan Lingkungan Pengembang
Unduh dan instal Visual Studio Code (VSCode).
Luncurkan VSCode.
Unduh dan instal ekstensi Server Langsung untuk VSCode dalam VSCode.
Pilih
File --> Open Folder, dan buat folder kosong di lokasi yang Anda inginkan.
Langkah 1: Menginisialisasi aplikasi web
- Untuk memulai, buat halaman baru
index.html. Tambahkan kode boilerplate berikut ke halaman baru Anda:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My Website</title>
</head>
<body>
<main>
<h1>Welcome to My Website</h1>
</main>
</body>
</html>
- Verifikasi kode boilerplate dan penyiapan pengembang yang berfungsi dengan memilih tombol Go Live di sisi kanan bawah VSCode. Ini harus meluncurkan server lokal di Edge Beta yang menjalankan kode boilerplate.
- Sekarang, buat file baru yang disebut
main.js. Ini akan berisi kode javascript untuk aplikasi Anda. - Selanjutnya, buat subfolder dari direktori akar bernama
images. Unduh dan simpan gambar apa pun di dalam folder. Untuk demo ini, kita akan menggunakan nama default .image.jpg - Unduh model mobilenet dari ONNX Model Zoo. Untuk tutorial ini, Anda akan menggunakan file mobilenet2-10.onnx . Simpan model ini ke folder akar aplikasi web Anda.
- Terakhir, unduh dan simpan file kelas gambar ini,
imagenetClasses.js. Ini menyediakan 1000 klasifikasi umum gambar untuk digunakan model Anda.
Langkah 2: Tambahkan elemen UI dan fungsi induk
- Dalam isi tag html yang
<main>Anda tambahkan di langkah sebelumnya, ganti kode yang ada dengan elemen berikut. Ini akan membuat tombol dan menampilkan gambar default.
<h1>Image Classification Demo!</h1>
<div><img src="./images/image.jpg"></div>
<button onclick="classifyImage('./images/image.jpg')" type="button">Click Me to Classify Image!</button>
<h1 id="outputText"> This image displayed is ... </h1>
- Sekarang, Anda akan menambahkan ONNX Runtime Web ke halaman Anda, yang merupakan pustaka JavaScript yang akan Anda gunakan untuk mengakses API WebNN. Dalam isi
<head>tag html, tambahkan tautan sumber javascript berikut.
<script src="./main.js"></script>
<script src="imagenetClasses.js"></script>
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.18.0-dev.20240311-5479124834/dist/ort.webgpu.min.js"></script>
- Buka file Anda
main.js, dan tambahkan cuplikan kode berikut.
async function classifyImage(pathToImage){
var imageTensor = await getImageTensorFromPath(pathToImage); // Convert image to a tensor
var predictions = await runModel(imageTensor); // Run inference on the tensor
console.log(predictions); // Print predictions to console
document.getElementById("outputText").innerHTML += predictions[0].name; // Display prediction in HTML
}
Langkah 3: Pra-proses data
- Fungsi yang baru saja Anda tambahkan panggilan
getImageTensorFromPath, fungsi lain yang harus Anda terapkan. Anda akan menambahkannya di bawah ini, serta fungsi asinkron lain yang disebutnya untuk mengambil gambar itu sendiri.
async function getImageTensorFromPath(path, width = 224, height = 224) {
var image = await loadImagefromPath(path, width, height); // 1. load the image
var imageTensor = imageDataToTensor(image); // 2. convert to tensor
return imageTensor; // 3. return the tensor
}
async function loadImagefromPath(path, resizedWidth, resizedHeight) {
var imageData = await Jimp.read(path).then(imageBuffer => { // Use Jimp to load the image and resize it.
return imageBuffer.resize(resizedWidth, resizedHeight);
});
return imageData.bitmap;
}
- Anda juga perlu menambahkan
imageDataToTensorfungsi yang direferensikan di atas, yang akan merender gambar yang dimuat ke dalam format tensor yang akan berfungsi dengan model ONNX kami. Ini adalah fungsi yang lebih terlibat, meskipun mungkin tampak akrab jika Anda telah bekerja dengan aplikasi klasifikasi gambar serupa sebelumnya. Untuk penjelasan yang diperluas, Anda dapat melihat tutorial ONNX ini.
function imageDataToTensor(image) {
var imageBufferData = image.data;
let pixelCount = image.width * image.height;
const float32Data = new Float32Array(3 * pixelCount); // Allocate enough space for red/green/blue channels.
// Loop through the image buffer, extracting the (R, G, B) channels, rearranging from
// packed channels to planar channels, and converting to floating point.
for (let i = 0; i < pixelCount; i++) {
float32Data[pixelCount * 0 + i] = imageBufferData[i * 4 + 0] / 255.0; // Red
float32Data[pixelCount * 1 + i] = imageBufferData[i * 4 + 1] / 255.0; // Green
float32Data[pixelCount * 2 + i] = imageBufferData[i * 4 + 2] / 255.0; // Blue
// Skip the unused alpha channel: imageBufferData[i * 4 + 3].
}
let dimensions = [1, 3, image.height, image.width];
const inputTensor = new ort.Tensor("float32", float32Data, dimensions);
return inputTensor;
}
Langkah 4: Panggil WebNN
- Anda sekarang telah menambahkan semua fungsi yang diperlukan untuk mengambil gambar Anda dan merendernya sebagai tensor. Sekarang, menggunakan pustaka Web Runtime ONNX yang Anda muat di atas, Anda akan menjalankan model Anda. Perhatikan bahwa untuk menggunakan WebNN di sini, Anda cukup menentukan
executionProvider = "webnn"- Dukungan Runtime ONNX membuatnya sangat mudah untuk mengaktifkan WebNN.
async function runModel(preprocessedData) {
// Set up environment.
ort.env.wasm.numThreads = 1;
ort.env.wasm.simd = true;
ort.env.wasm.proxy = true;
ort.env.logLevel = "verbose";
ort.env.debug = true;
// Configure WebNN.
const executionProvider = "webnn"; // Other options: webgpu
const modelPath = "./mobilenetv2-7.onnx"
const options = {
executionProviders: [{ name: executionProvider, deviceType: "gpu", powerPreference: "default" }],
freeDimensionOverrides: {"batch": 1, "channels": 3, "height": 224, "width": 224}
};
modelSession = await ort.InferenceSession.create(modelPath, options);
// Create feeds with the input name from model export and the preprocessed data.
const feeds = {};
feeds[modelSession.inputNames[0]] = preprocessedData;
// Run the session inference.
const outputData = await modelSession.run(feeds);
// Get output results with the output name from the model export.
const output = outputData[modelSession.outputNames[0]];
// Get the softmax of the output data. The softmax transforms values to be between 0 and 1.
var outputSoftmax = softmax(Array.prototype.slice.call(output.data));
// Get the top 5 results.
var results = imagenetClassesTopK(outputSoftmax, 5);
return results;
}
Langkah 5: Data pasca-proses
- Terakhir, Anda akan menambahkan
softmaxfungsi, lalu menambahkan fungsi akhir untuk mengembalikan klasifikasi gambar yang paling mungkin. Mengubahsoftmaxnilai Anda menjadi antara 0 dan 1, yang merupakan bentuk probabilitas yang diperlukan untuk klasifikasi akhir ini.
Pertama, tambahkan file sumber berikut untuk pustaka pembantu main.jsJimp dan Lodash di tag kepala .
<script src="https://cdnjs.cloudflare.com/ajax/libs/jimp/0.22.12/jimp.min.js" integrity="sha512-8xrUum7qKj8xbiUrOzDEJL5uLjpSIMxVevAM5pvBroaxJnxJGFsKaohQPmlzQP8rEoAxrAujWttTnx3AMgGIww==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>
<script src="https://cdn.jsdelivr.net/npm/lodash@4.17.21/lodash.min.js"></script>
Sekarang, tambahkan fungsi berikut ini ke main.js.
// The softmax transforms values to be between 0 and 1.
function softmax(resultArray) {
// Get the largest value in the array.
const largestNumber = Math.max(...resultArray);
// Apply the exponential function to each result item subtracted by the largest number, using reduction to get the
// previous result number and the current number to sum all the exponentials results.
const sumOfExp = resultArray
.map(resultItem => Math.exp(resultItem - largestNumber))
.reduce((prevNumber, currentNumber) => prevNumber + currentNumber);
// Normalize the resultArray by dividing by the sum of all exponentials.
// This normalization ensures that the sum of the components of the output vector is 1.
return resultArray.map((resultValue, index) => {
return Math.exp(resultValue - largestNumber) / sumOfExp
});
}
function imagenetClassesTopK(classProbabilities, k = 5) {
const probs = _.isTypedArray(classProbabilities)
? Array.prototype.slice.call(classProbabilities)
: classProbabilities;
const sorted = _.reverse(
_.sortBy(
probs.map((prob, index) => [prob, index]),
probIndex => probIndex[0]
)
);
const topK = _.take(sorted, k).map(probIndex => {
const iClass = imagenetClasses[probIndex[1]]
return {
id: iClass[0],
index: parseInt(probIndex[1].toString(), 10),
name: iClass[1].replace(/_/g, " "),
probability: probIndex[0]
}
});
return topK;
}
- Anda sekarang telah menambahkan semua pembuatan skrip yang diperlukan untuk menjalankan klasifikasi gambar dengan WebNN di aplikasi web dasar Anda. Dengan menggunakan ekstensi Server Langsung untuk Visual Studio Code, Anda sekarang dapat meluncurkan halaman web dasar dalam aplikasi untuk melihat hasil klasifikasi untuk diri Anda sendiri.