Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pada tahap sebelumnya dari tutorial ini, kami memperoleh himpunan data yang akan kami gunakan untuk melatih model analisis data kami dengan PyTorch. Sekarang, saatnya untuk menggunakan data itu.
Untuk melatih model analisis data dengan PyTorch, Anda perlu menyelesaikan langkah-langkah berikut:
- Muatlah datanya. Jika Anda telah melakukan langkah sebelumnya dari tutorial ini, Anda telah menanganinya.
- Tentukan jaringan neural.
- Tentukan fungsi kerugian.
- Latih model pada data pelatihan.
- Uji jaringan pada data pengujian.
Menentukan jaringan neural
Dalam tutorial ini, Anda akan membangun model jaringan saraf dasar dengan tiga lapisan linier. Struktur model adalah sebagai berikut:
Linear -> ReLU -> Linear -> ReLU -> Linear
Lapisan Linier menerapkan transformasi linier ke data masuk. Anda harus menentukan jumlah fitur input dan jumlah fitur output yang harus sesuai dengan jumlah kelas.
Lapisan fungsi ReLU adalah fungsi aktivasi untuk menentukan semua fitur yang masuk bernilai 0 atau lebih. Dengan demikian, ketika lapisan ReLU diterapkan, angka apa pun yang kurang dari 0 diubah menjadi nol, sementara yang lain disimpan sama. Kami akan menerapkan lapisan aktivasi pada dua lapisan tersembunyi, dan tidak ada aktivasi pada lapisan linear terakhir.
Parameter dari model
Parameter model bergantung pada tujuan dan data pelatihan kami. Ukuran input tergantung pada jumlah fitur yang kami berikan model - empat dalam kasus kami. Ukuran output adalah tiga karena ada tiga kemungkinan jenis Iris.
Memiliki tiga lapisan linier, (4,24) -> (24,24) -> (24,3), jaringan akan memiliki bobot 744 (96+576+72).
Tingkat pembelajaran (lr) menentukan seberapa banyak Anda menyesuaikan bobot jaringan dengan memperhatikan gradien kerugian. Semakin rendah, semakin lambat pelatihannya. Anda akan mengatur lr ke 0.01 dalam tutorial ini.
Bagaimana cara kerja Jaringan?
Di sini, kami sedang membangun jaringan feed-forward. Selama proses pelatihan, jaringan akan memproses input melalui semua lapisan, menghitung kerugian untuk memahami seberapa jauh label gambar yang diprediksi jatuh dari yang benar, dan menyebarluaskan gradien kembali ke jaringan untuk memperbarui bobot lapisan. Dengan melakukan iterasi pada himpunan data input yang besar, jaringan akan "belajar" untuk mengatur bobotnya untuk mencapai hasil terbaik.
Fungsi penerusan menghitung nilai fungsi kerugian, dan fungsi mundur menghitung gradien parameter yang dapat dipelajari. Ketika Anda membuat jaringan neural kami dengan PyTorch, Anda hanya perlu menentukan fungsi penerusan. Fungsi kebelakang akan ditentukan secara otomatis.
- Salin kode berikut ke
DataClassifier.pydalam file di Visual Studio untuk menentukan parameter model dan jaringan neural.
# Define model parameters
input_size = list(input.shape)[1] # = 4. The input depends on how many features we initially feed the model. In our case, there are 4 features for every predict value
learning_rate = 0.01
output_size = len(labels) # The output is prediction results for three types of Irises.
# Define neural network
class Network(nn.Module):
def __init__(self, input_size, output_size):
super(Network, self).__init__()
self.layer1 = nn.Linear(input_size, 24)
self.layer2 = nn.Linear(24, 24)
self.layer3 = nn.Linear(24, output_size)
def forward(self, x):
x1 = F.relu(self.layer1(x))
x2 = F.relu(self.layer2(x1))
x3 = self.layer3(x2)
return x3
# Instantiate the model
model = Network(input_size, output_size)
Anda juga harus menentukan perangkat eksekusi berdasarkan yang tersedia di PC Anda. PyTorch tidak memiliki pustaka khusus untuk GPU, tetapi Anda dapat menentukan perangkat eksekusi secara manual. Perangkat akan menjadi GPU Nvidia jika ada di komputer Anda, atau CPU Anda jika tidak.
- Salin kode berikut untuk menentukan perangkat eksekusi:
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device\n")
model.to(device) # Convert model parameters and buffers to CPU or Cuda
- Sebagai langkah terakhir, tentukan fungsi untuk menyimpan model:
# Function to save the model
def saveModel():
path = "./NetModel.pth"
torch.save(model.state_dict(), path)
Nota
Tertarik untuk mempelajari lebih lanjut tentang jaringan neural dengan PyTorch? Lihat dokumentasi PyTorch.
Menentukan fungsi rugi
Fungsi kerugian menghitung nilai yang memperkirakan seberapa jauh output dari target. Tujuan utama adalah untuk mengurangi nilai fungsi kerugian dengan mengubah nilai-nilai vektor bobot melalui backpropagation pada jaringan neural.
Nilai kerugian berbeda dari akurasi model. Fungsi kerugian mewakili seberapa baik model kita berperilaku setelah setiap iterasi pengoptimalan pada set pelatihan. Akurasi model dihitung pada data pengujian, dan menunjukkan persentase prediksi yang benar.
Di PyTorch, paket jaringan neural berisi berbagai fungsi kehilangan yang membentuk blok penyusun jaringan neural dalam. Jika Anda ingin mempelajari lebih lanjut spesifikasi ini, mulailah dengan catatan di atas. Di sini, kita akan menggunakan fungsi yang sudah ada yang dioptimalkan untuk klasifikasi seperti ini, dan menggunakan fungsi kerugian Entropi Silang Klasifikasi dan pengoptimal Adam. Dalam pengoptimal, laju pembelajaran (lr) mengatur berapa banyak kita menyesuaikan bobot jaringan kita dengan hormat kepada gradien kehilangan. Anda akan mengaturnya sebagai 0,001 di sini - semakin rendah, semakin lambat pelatihannya.
- Salin kode berikut ke dalam
DataClassifier.pyfile di Visual Studio untuk menentukan fungsi kerugian dan pengoptimalan.
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Latih model pada data pelatihan.
Untuk melatih model, Anda harus mengulangi iterator data kita, memberikan input ke jaringan, dan mengoptimalkan. Untuk memvalidasi hasilnya, Anda cukup membandingkan label yang diprediksi dengan label aktual dalam himpunan data validasi setelah setiap masa pelatihan.
Program ini akan menampilkan kehilangan pelatihan, kehilangan validasi, dan akurasi model untuk setiap epoch atau untuk setiap iterasi lengkap selama set pelatihan. Ini akan menyimpan model dengan akurasi tertinggi, dan setelah 10 epoch, program akan menampilkan akurasi akhir.
- Tambahkan kode berikut ke
DataClassifier.pyfile
# Training Function
def train(num_epochs):
best_accuracy = 0.0
print("Begin training...")
for epoch in range(1, num_epochs+1):
running_train_loss = 0.0
running_accuracy = 0.0
running_vall_loss = 0.0
total = 0
# Training Loop
for data in train_loader:
#for data in enumerate(train_loader, 0):
inputs, outputs = data # get the input and real species as outputs; data is a list of [inputs, outputs]
optimizer.zero_grad() # zero the parameter gradients
predicted_outputs = model(inputs) # predict output from the model
train_loss = loss_fn(predicted_outputs, outputs) # calculate loss for the predicted output
train_loss.backward() # backpropagate the loss
optimizer.step() # adjust parameters based on the calculated gradients
running_train_loss +=train_loss.item() # track the loss value
# Calculate training loss value
train_loss_value = running_train_loss/len(train_loader)
# Validation Loop
with torch.no_grad():
model.eval()
for data in validate_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
val_loss = loss_fn(predicted_outputs, outputs)
# The label with the highest value will be our prediction
_, predicted = torch.max(predicted_outputs, 1)
running_vall_loss += val_loss.item()
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
# Calculate validation loss value
val_loss_value = running_vall_loss/len(validate_loader)
# Calculate accuracy as the number of correct predictions in the validation batch divided by the total number of predictions done.
accuracy = (100 * running_accuracy / total)
# Save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
# Print the statistics of the epoch
print('Completed training batch', epoch, 'Training Loss is: %.4f' %train_loss_value, 'Validation Loss is: %.4f' %val_loss_value, 'Accuracy is %d %%' % (accuracy))
Uji model pada data pengujian.
Sekarang setelah kita melatih model, kita dapat menguji model dengan himpunan data pengujian.
Kita akan menambahkan dua fungsi pengujian. Yang pertama menguji model yang Anda simpan di bagian sebelumnya. Ini akan menguji model dengan himpunan data pengujian 45 item, dan mencetak akurasi model. Yang kedua adalah fungsi opsional untuk menguji keyakinan model dalam memprediksi masing-masing dari tiga spesies iris, yang diwakili oleh probabilitas klasifikasi yang berhasil dari setiap spesies.
- Tambahkan kode berikut ke file
DataClassifier.py.
# Function to test the model
def test():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
running_accuracy = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
outputs = outputs.to(torch.float32)
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
print('Accuracy of the model based on the test set of', test_split ,'inputs is: %d %%' % (100 * running_accuracy / total))
# Optional: Function to test which species were easier to predict
def test_species():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
labels_length = len(labels) # how many labels of Irises we have. = 3 in our database.
labels_correct = list(0. for i in range(labels_length)) # list to calculate correct labels [how many correct setosa, how many correct versicolor, how many correct virginica]
labels_total = list(0. for i in range(labels_length)) # list to keep the total # of labels per type [total setosa, total versicolor, total virginica]
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
label_correct_running = (predicted == outputs).squeeze()
label = outputs[0]
if label_correct_running.item():
labels_correct[label] += 1
labels_total[label] += 1
label_list = list(labels.keys())
for i in range(output_size):
print('Accuracy to predict %5s : %2d %%' % (label_list[i], 100 * labels_correct[i] / labels_total[i]))
Terakhir, mari kita tambahkan kode utama. Ini akan memulai pelatihan model, menyimpan model, dan menampilkan hasilnya di layar. Kami hanya akan menjalankan dua iterasi [num_epochs = 25] selama set pelatihan, sehingga proses pelatihan tidak akan memakan waktu terlalu lama.
- Tambahkan kode berikut ke file
DataClassifier.py.
if __name__ == "__main__":
num_epochs = 10
train(num_epochs)
print('Finished Training\n')
test()
test_species()
Mari kita jalankan tes! Pastikan menu dropdown di toolbar atas diatur ke Debug.
Solution Platform Ubah ke x64 untuk menjalankan proyek di komputer lokal Anda jika perangkat Anda 64-bit, atau x86 jika 32-bit.
- Untuk menjalankan proyek, klik tombol
Start Debuggingpada toolbar, atau tekanF5.
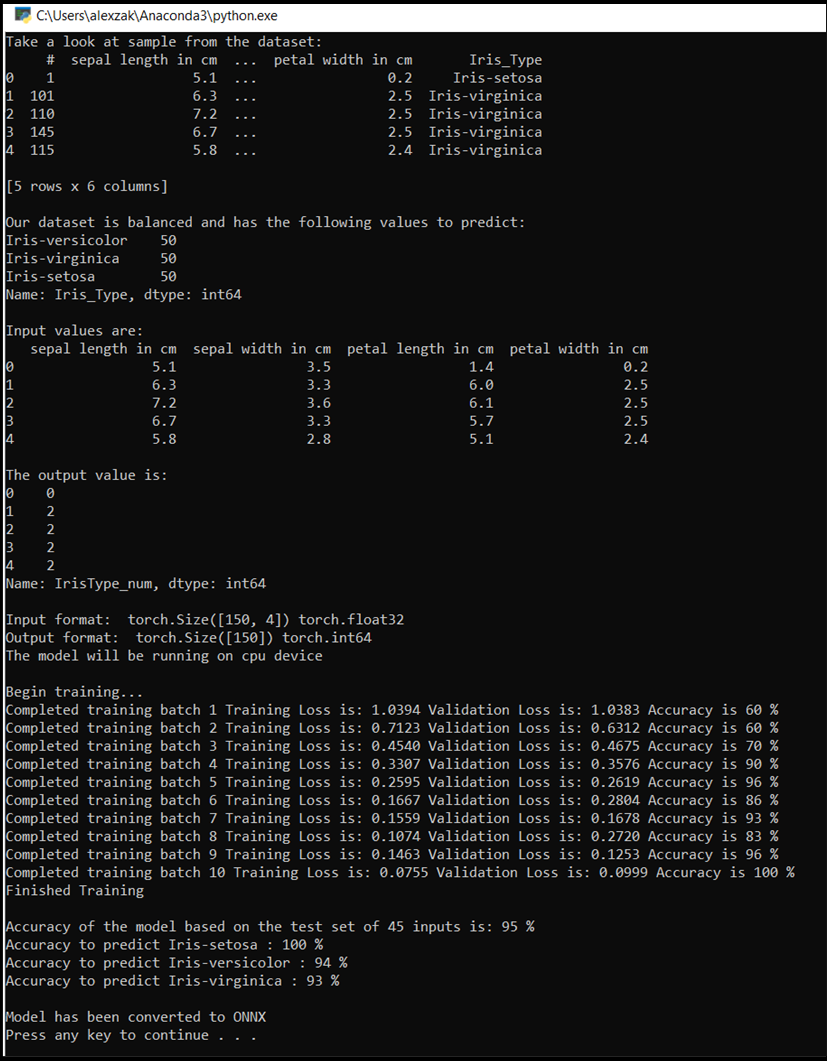
Jendela konsol akan muncul, dan Anda akan melihat proses pelatihan. Seperti yang Anda tentukan, nilai kerugian akan dicetak setiap epoch. Harapannya adalah bahwa nilai kerugian berkurang dengan setiap perulangan.
Setelah pelatihan selesai, Anda akan mengharapkan untuk melihat output yang mirip dengan di bawah ini. Angka Anda tidak akan sama persis - pelatihan tergantung pada banyak faktor, dan tidak akan selalu mengembalikan hasil identifikasi - tetapi akan terlihat mirip.
Langkah Selanjutnya
Sekarang setelah kita memiliki model klasifikasi, langkah selanjutnya adalah mengonversi model ke format ONNX.