Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Topik sebelumnya (Bagaimana Sistem Manajemen Sumber Daya cocok dan memilih sumber daya) melihat pencocokan kualifikasi secara umum. Topik ini berfokus pada pencocokan tag bahasa secara lebih rinci.
Pendahuluan
Sumber daya dengan kualifikasi tag bahasa dibandingkan dan dinilai berdasarkan daftar bahasa runtime aplikasi. Untuk definisi daftar bahasa yang berbeda, lihat Memahami bahasa profil pengguna dan bahasa manifes aplikasi. Pencocokan untuk bahasa pertama dalam daftar terjadi sebelum pencocokan bahasa kedua dalam daftar, bahkan untuk varian regional lainnya. Misalnya, sumber daya untuk en-GB dipilih melalui sumber daya fr-CA jika bahasa runtime aplikasi adalah en-US. Hanya jika tidak ada sumber daya untuk bentuk en adalah sumber daya untuk fr-CA yang dipilih (perhatikan bahwa bahasa default aplikasi tidak dapat diatur ke bentuk en apa pun dalam hal ini).
Mekanisme penilaian menggunakan data yang disertakan dalam registri subtag BCP-47 , dan sumber data lainnya. Ini memungkinkan gradien penilaian dengan kualitas kecocokan yang berbeda dan, ketika beberapa kandidat tersedia, ia memilih kandidat dengan skor yang paling cocok.
Jadi, Anda dapat menandai konten bahasa dalam istilah generik, tetapi Anda masih dapat menentukan konten tertentu saat diperlukan. Misalnya, aplikasi Anda mungkin memiliki banyak string bahasa Inggris yang umum untuk Amerika Serikat, Inggris, dan wilayah lainnya. Menandai string ini sebagai "en" (Bahasa Inggris) menghemat ruang dan overhead pelokalan. Ketika perbedaan perlu dibuat, seperti dalam string yang berisi kata "warna/warna", versi Amerika Serikat dan Inggris dapat ditandai secara terpisah menggunakan subtag bahasa dan wilayah, masing-masing sebagai "en-US" dan "en-GB".
Tag bahasa
Bahasa diidentifikasi menggunakan tag bahasa BCP-47 yang dinormalisasi dan terbentuk dengan baik. Komponen subtag didefinisikan dalam registri subtag BCP-47. Struktur normal untuk tag bahasa BCP-47 terdiri dari satu atau beberapa elemen subtag berikut.
- Subtag bahasa (diperlukan).
- Subtag skrip (yang dapat disimpulkan menggunakan default yang ditentukan dalam registri subtag).
- Subtag wilayah (opsional).
- Subtag varian (opsional).
Elemen subtag tambahan mungkin ada, tetapi akan memiliki efek yang dapat diabaikan pada pencocokan bahasa. Tidak ada rentang bahasa yang ditentukan menggunakan wild card (""), misalnya, "en-".
Mencocokkan dua bahasa
Setiap kali Windows membandingkan dua bahasa, biasanya dilakukan dalam konteks proses yang lebih besar. Ini mungkin dalam konteks menilai beberapa bahasa, seperti ketika Windows menghasilkan daftar bahasa aplikasi (lihat Memahami bahasa profil pengguna dan bahasa manifes aplikasi). Windows melakukan ini dengan mencocokkan beberapa bahasa dari preferensi pengguna ke bahasa yang ditentukan dalam manifes aplikasi. Perbandingan mungkin juga dalam konteks menilai bahasa bersama dengan kualifikasi lain untuk sumber daya tertentu. Salah satu contohnya adalah ketika Windows menyelesaikan sumber daya file tertentu ke konteks sumber daya tertentu; dengan lokasi rumah pengguna atau skala perangkat saat ini atau dpi sebagai faktor lain (selain bahasa) yang diperhitungkan dalam pemilihan sumber daya.
Ketika dua tag bahasa dibandingkan, perbandingan diberi skor berdasarkan ke dekatnya.
| Cocokkan | Skor | Contoh |
|---|---|---|
| Sama persis | Tertinggi | en-AU : en-AU |
| Kecocokan varian (bahasa, skrip, wilayah, varian) | en-AU-variant1 : en-AU-variant1-t-ja | |
| Kecocokan wilayah (bahasa, skrip, wilayah) | en-AU : en-AU-variant1 | |
| Kecocokan parsial (bahasa, skrip) | ||
| - Kecocokan wilayah makro | en-AU : en-053 | |
| - Kecocokan netral wilayah | en-AU : en | |
| - Kecocokan afinitas ortografis (dukungan terbatas) | en-AU : en-GB | |
| - Kecocokan wilayah pilihan | en-AU : en-US | |
| - Kecocokan wilayah apa pun | en-AU : en-CA | |
| Bahasa yang tidak ditentukan (kecocokan bahasa apa pun) | en-AU : und | |
| Tidak ada kecocokan (ketidakcocokan skrip atau ketidakcocokan tag bahasa utama) | Terendah | en-AU : fr-FR |
Sama persis
Tag sama persis (semua elemen subtag cocok). Perbandingan dapat dipromosikan ke jenis kecocokan ini dari varian atau kecocokan wilayah. Misalnya, en-US cocok dengan en-US.
Kecocokan varian
Tag cocok pada subtag bahasa, skrip, wilayah, dan varian, tetapi berbeda dalam beberapa hal lainnya.
Kecocokan wilayah
Tag cocok pada subtag bahasa, skrip, dan wilayah, tetapi berbeda dalam beberapa hal lainnya. Misalnya, de-DE-1996 cocok dengan de-DE, dan en-US-x-Pirate cocok dengan en-US.
Kecocokan parsial
Tag cocok pada subtag bahasa dan skrip, tetapi berbeda di wilayah atau beberapa subtag lainnya. Misalnya, en-US cocok dengan en, atau en-US cocok dengan en-*.
Kecocokan wilayah makro
Tag cocok pada subtag bahasa dan skrip; kedua tag memiliki subtag wilayah, salah satunya menunjukkan wilayah makro yang mencakup wilayah lain. Subtag wilayah makro selalu numerik dan berasal dari Divisi Statistik Perserikatan Bangsa-Bangsa M.49 negara dan kode area. Untuk detail tentang hubungan yang mencakup, lihat Komposisi wilayah geografis makro (kontinental), sub-wilayah geografis, dan pengelompokan ekonomi dan lainnya yang dipilih.
Perhatikan kode PBB untuk "pengelompokan ekonomi" atau "pengelompokan lain" tidak didukung di BCP-47.
Catatan Tag dengan subtag wilayah makro "001" dianggap setara dengan tag netral wilayah. Misalnya, "es-001" dan "es" diperlakukan sebagai sinonim.
Kecocokan netral wilayah
Tag cocok pada subtag bahasa dan skrip, dan hanya satu tag yang memiliki tag wilayah. Kecocokan induk lebih disukai daripada kecocokan parsial lainnya.
Kecocokan afinitas orthografis
Tag cocok pada subtag bahasa dan skrip, dan subtag wilayah memiliki afinitas orthographic. Afinitas bergantung pada data yang dikelola di Windows yang menentukan wilayah terdefinisi khusus bahasa, misalnya, "en-IE" dan "en-GB".
Kecocokan wilayah pilihan
Tag cocok pada subtag bahasa dan skrip, dan salah satu subtag wilayah adalah subtag wilayah default untuk bahasa tersebut. Misalnya, "fr-FR" adalah wilayah default untuk subtag "fr". Jadi, fr-FR adalah pertandingan yang lebih baik untuk fr-BE daripada fr-CA. Ini bergantung pada data yang dikelola di Windows yang menentukan wilayah default untuk setiap bahasa tempat Windows dilokalkan.
Kecocokan saudara
Tag cocok pada subtag bahasa dan skrip, dan keduanya memiliki subtag wilayah, tetapi tidak ada hubungan lain yang ditentukan di antara mereka. Jika terjadi beberapa pertandingan saudara kandung, saudara kandung terakhir yang dijumlahkan akan menjadi pemenang, dengan tidak adanya pertandingan yang lebih tinggi.
Bahasa yang tidak ditentukan
Sumber daya dapat ditandai sebagai "und" untuk menunjukkan bahwa sumber daya cocok dengan bahasa apa pun. Tag ini juga dapat digunakan dengan tag skrip untuk memfilter kecocokan berdasarkan skrip. Misalnya, "und-Latn" akan cocok dengan tag bahasa apa pun yang menggunakan skrip Latin. Baca di bawah ini untuk detail selengkapnya.
Ketidakcocokan skrip
Ketika tag hanya cocok pada tag bahasa utama tetapi bukan skrip, pasangan dianggap tidak cocok dan diberi skor di bawah tingkat kecocokan yang valid.
Tidak ada kecocokan
Subtag bahasa utama yang tidak cocok dinilai di bawah tingkat kecocokan yang valid. Misalnya, zh-Hant tidak cocok dengan zh-Hans.
Contoh
Bahasa pengguna "zh-Hans-CN" (Chinese Simplified (Tiongkok)) cocok dengan sumber daya berikut dalam urutan prioritas yang ditampilkan. X menunjukkan tidak ada kecocokan.
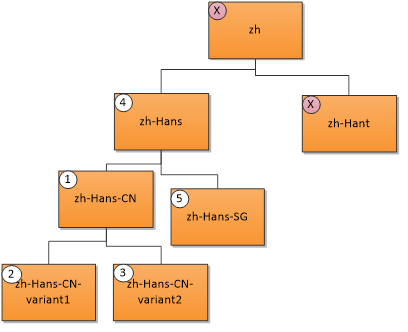
- Kecocokan persis; 2. - 3. Kecocokan wilayah; 4. Kecocokan induk; 5. Kecocokan saudara kandung.
Ketika subtag bahasa memiliki nilai Suppress-Script yang ditentukan dalam registri subtag BCP-47, pencocokan yang sesuai terjadi, mengambil nilai kode skrip yang ditekan. Misalnya, en-Latn-US cocok dengan en-US. Dalam contoh berikutnya, bahasa pengguna adalah "en-AU" (Inggris (Australia)).
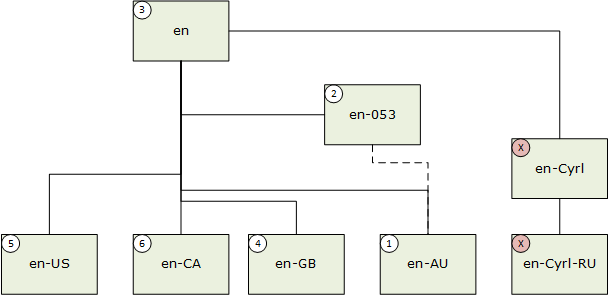
- Kecocokan persis; 2. Kecocokan wilayah makro; 3. Kecocokan netral wilayah; 4. Kecocokan afinitas ortografis; 5. Kecocokan wilayah pilihan; 6. Kecocokan saudara kandung.
Mencocokkan bahasa dengan daftar bahasa
Terkadang, pencocokan terjadi sebagai bagian dari proses yang lebih besar untuk mencocokkan satu bahasa dengan daftar bahasa. Misalnya, mungkin ada kecocokan sumber daya berbasis bahasa tunggal dengan daftar bahasa aplikasi. Skor kecocokan ditimbang oleh posisi bahasa pencocokan pertama dalam daftar. Semakin rendah bahasa dalam daftar, semakin rendah skornya.
Ketika daftar bahasa berisi dua varian regional atau lebih yang memiliki subtag bahasa dan skrip yang sama, perbandingan untuk tag bahasa pertama hanya diberi skor untuk kecocokan tepat, varian, dan wilayah. Penskoran kecocokan parsial ditunda ke varian regional terakhir. Ini memungkinkan pengguna untuk mengontrol perilaku pencocokan dengan baik untuk daftar bahasa mereka. Perilaku pencocokan mungkin termasuk mengizinkan kecocokan yang tepat untuk item sekunder dalam daftar yang lebih disukai daripada kecocokan parsial untuk item pertama dalam daftar, jika ada item ketiga yang cocok dengan bahasa dan skrip yang pertama. Berikut adalah contoh.
- Daftar bahasa (berurutan): "pt-PT" (Portugis (Portugal)), "en-US" (Inggris (Amerika Serikat)), "pt-BR" (Portugis (Brasil)).
- Sumber daya: "en-US", "pt-BR".
- Sumber daya dengan skor yang lebih tinggi: "en-US".
- Deskripsi: Perbandingan dimulai dengan "pt-PT" tetapi tidak menemukan kecocokan yang tepat. Karena adanya "pt-BR" dalam daftar bahasa pengguna, pencocokan parsial ditunda dengan perbandingan dengan "pt-BR". Perbandingan bahasa berikutnya adalah "en-US", yang memiliki kecocokan yang tepat. Jadi, sumber daya yang menang adalah "en-US".
ATAU
- Daftar bahasa (berurutan): "es-MX" (Spanyol (Meksiko)), "es-HO" (Spanyol (Honduras)).
- Sumber daya: "en-ES", "es-HO".
- Sumber daya dengan skor lebih tinggi: "es-HO".
Bahasa yang tidak ditentukan ("und")
Tag bahasa "und" dapat digunakan untuk menentukan sumber daya yang akan cocok dengan bahasa apa pun tanpa adanya kecocokan yang lebih baik. Ini dapat dianggap mirip dengan rentang bahasa BCP-47 "" atau "-<script>". Berikut adalah contoh.
- Daftar bahasa: "en-US", "zh-Hans-CN".
- Sumber daya: "zh-Hans-CN", "und".
- Sumber daya dengan skor yang lebih tinggi: "und".
- Deskripsi: Perbandingan dimulai dengan "en-US" tetapi tidak menemukan kecocokan berdasarkan "en" (parsial atau lebih baik). Karena ada sumber daya yang ditandai dengan "und", algoritma yang cocok menggunakannya.
Tag "und" memungkinkan beberapa bahasa untuk berbagi satu sumber daya dan mengizinkan bahasa individual diperlakukan sebagai pengecualian. Contohnya.
- Daftar bahasa: "zh-Hans-CN", "en-US".
- Sumber daya: "zh-Hans-CN", "und".
- Sumber daya dengan skor yang lebih tinggi: "zh-Hans-CN".
- Deskripsi: Perbandingan menemukan kecocokan yang tepat untuk item pertama sehingga tidak memeriksa sumber daya berlabel "und".
Anda dapat menggunakan "und" dengan tag skrip untuk memfilter sumber daya menurut skrip. Contohnya.
- Daftar bahasa: "ru".
- Sumber daya: "und-Latn", "und-Cyrl", "und-Arab".
- Sumber daya dengan skor yang lebih tinggi: "und-Cyrl".
- Deskripsi: Perbandingan tidak menemukan kecocokan untuk "ru" (parsial atau lebih baik), sehingga cocok dengan tag bahasa "und". Nilai suppress-script "Cyrl" yang terkait dengan tag bahasa "ru" cocok dengan sumber daya "und-Cyrl".
Afinitas regional orthografis
Ketika dua tag bahasa dengan perbedaan subtag wilayah cocok, pasangan wilayah tertentu mungkin memiliki afinitas yang lebih tinggi satu sama lain daripada yang lain. Satu-satunya grup yang didukung adalah untuk bahasa Inggris ("en"). Subtag wilayah "PH" (Filipina) dan "LR" (Liberia) memiliki afinitas ortografis dengan subtag wilayah "AS". Semua subtag wilayah lainnya diafinisis dengan subtag wilayah "GB" (Inggris Raya). Oleh karena itu, ketika sumber daya "en-US" dan "en-GB" tersedia, daftar bahasa "en-HK" (Inggris (Hong Kong SAR)) akan mendapatkan skor yang lebih tinggi dengan sumber daya "en-GB" daripada dengan sumber daya "en-US".
Menangani bahasa dengan banyak varian regional
Bahasa tertentu memiliki komunitas pembicara besar di berbagai wilayah yang menggunakan berbagai jenis bahasa tersebut—bahasa seperti Bahasa Inggris, Prancis, dan Spanyol, yang merupakan salah satu yang paling sering didukung dalam aplikasi multibahasa. Perbedaan regional dapat mencakup perbedaan ortografi (misalnya, "warna" versus "warna"), atau perbedaan dialek seperti kosakata (misalnya, "truk" versus "lorry").
Bahasa-bahasa dengan varian regional yang signifikan ini menghadirkan tantangan tertentu saat membuat aplikasi yang siap di dunia: "Berapa banyak varian regional yang berbeda yang harus didukung?" "Yang mana?" "Apa cara paling hemat biaya untuk mengelola aset varian regional ini untuk aplikasi saya?" Ini di luar cakupan topik ini untuk menjawab semua pertanyaan ini. Namun, mekanisme pencocokan bahasa di Windows memang menyediakan kemampuan yang dapat membantu Anda dalam menangani varian regional.
Aplikasi akan sering mendukung hanya satu variasi bahasa tertentu. Misalkan aplikasi memiliki sumber daya hanya untuk satu variasi bahasa Inggris yang diharapkan untuk digunakan oleh penutur bahasa Inggris terlepas dari wilayah mana mereka berasal. Dalam hal ini, tag "en" tanpa subtag wilayah apa pun akan mencerminkan harapan tersebut. Tetapi aplikasi mungkin secara historis menggunakan tag seperti "en-US" yang menyertakan subtag wilayah. Dalam hal ini, itu juga akan berfungsi: aplikasi hanya menggunakan satu varian bahasa Inggris, dan Windows menangani pencocokan sumber daya yang ditandai untuk satu varian regional dengan preferensi bahasa pengguna untuk varian regional yang berbeda dengan cara yang sesuai.
Namun, jika dua atau beberapa varietas regional akan didukung, perbedaan seperti "en" versus "en-US" dapat berdampak signifikan pada pengalaman pengguna, dan menjadi penting untuk mempertimbangkan subtag wilayah apa yang akan digunakan.
Misalkan Anda ingin menyediakan pelokalan Prancis terpisah untuk bahasa Prancis seperti yang digunakan di Kanada versus Prancis Eropa. Untuk Bahasa Prancis Kanada, "fr-CA" dapat digunakan. Untuk pembicara dari Eropa, pelokalan akan menggunakan Bahasa Prancis (Prancis), sehingga "fr-FR" dapat digunakan untuk itu. Tetapi bagaimana jika pengguna tertentu berasal dari Belgia, dengan preferensi bahasa "fr-BE"; yang akan mereka dapatkan? Wilayah "BE" berbeda dari "FR" dan "CA", menyarankan kecocokan "wilayah apa pun" untuk keduanya. Namun, Prancis kebetulan menjadi wilayah pilihan untuk bahasa Prancis, sehingga "fr-FR" akan dianggap sebagai kecocokan terbaik dalam kasus ini.
Misalkan Anda pertama kali melokalisasi aplikasi Anda hanya untuk satu variasi bahasa Prancis, menggunakan string Prancis (Prancis) tetapi memenuhi syaratnya secara generik sebagai "fr", dan kemudian Anda ingin menambahkan dukungan untuk Prancis Kanada. Mungkin hanya sumber daya tertentu yang perlu diterjemahkan ulang untuk Bahasa Prancis Kanada. Anda dapat terus menggunakan semua aset asli yang membuatnya memenuhi syarat sebagai "fr", dan hanya menambahkan set kecil aset baru menggunakan "fr-CA". Jika preferensi bahasa pengguna adalah "fr-CA", maka aset "fr-CA" akan memiliki skor pencocokan yang lebih tinggi daripada aset "fr". Tetapi jika preferensi bahasa pengguna adalah untuk berbagai bahasa Prancis lainnya, maka aset netral wilayah "fr" akan menjadi kecocokan yang lebih baik daripada aset "fr-CA".
Sebagai contoh lain, misalkan Anda ingin menyediakan pelokalan Spanyol terpisah untuk pembicara dari Spanyol versus pembicara dari Amerika Latin. Misalkan lebih lanjut bahwa terjemahan untuk Amerika Latin disediakan dari vendor di Meksiko. Haruskah Anda menggunakan "es-ES" (Spanyol) dan "es-MX" (Meksiko) untuk dua set sumber daya? Jika Anda melakukannya, itu dapat menciptakan masalah untuk pembicara dari wilayah Amerika Latin lainnya seperti Argentina atau Kolombia, karena mereka akan mendapatkan sumber daya "es-ES". Dalam hal ini, ada alternatif yang lebih baik: Anda dapat menggunakan subtag wilayah makro, "es-419" untuk mencerminkan bahwa Anda berniat untuk digunakan untuk pembicara dari bagian mana pun di Amerika Latin atau Karibia.
Tag bahasa netral wilayah dan subtag wilayah makro bisa sangat efektif jika Anda ingin mendukung beberapa varietas regional. Untuk meminimalkan jumlah aset terpisah yang Anda butuhkan, Anda dapat memenuhi syarat aset tertentu dengan cara yang mencerminkan cakupan terluas yang berlaku. Kemudian melengkapi aset yang berlaku secara luas dengan varian yang lebih spesifik sesuai kebutuhan. Aset dengan kualifikasi bahasa netral wilayah akan digunakan untuk pengguna variasi regional apa pun kecuali ada aset lain dengan kualifikasi yang lebih spesifik secara regional yang berlaku untuk pengguna tersebut. Misalnya, aset "en" akan cocok dengan pengguna Bahasa Inggris Australia, tetapi aset dengan "en-053" (Bahasa Inggris seperti yang digunakan di Australia atau Selandia Baru) akan lebih cocok untuk pengguna tersebut, sementara aset dengan "en-AU" akan menjadi pertandingan terbaik.
Bahasa Inggris membutuhkan pertimbangan khusus. Jika aplikasi menambahkan pelokalan untuk dua varietas bahasa Inggris, kemungkinan akan untuk bahasa Inggris AS dan untuk Inggris, atau "internasional", Inggris. Seperti disebutkan di atas, wilayah tertentu di luar AS mengikuti konvensi ejaan Amerika Serikat, dan pencocokan bahasa Windows mempertimbangkannya. Dalam skenario ini, tidak disarankan untuk menggunakan tag netral wilayah "en" untuk salah satu varian; sebagai gantinya, gunakan "en-GB" dan "en-US". (Jika sumber daya tertentu tidak memerlukan varian terpisah, namun, "en" dapat digunakan.) Jika "en-GB" atau "en-US" digantikan oleh "en", maka itu akan mengganggu afinitas regional orthografis yang disediakan oleh Windows. Jika pelokalan bahasa Inggris ketiga ditambahkan, gunakan subtag wilayah tertentu atau makro untuk varian tambahan sesuai kebutuhan (misalnya, "en-CA", "en-AU" atau "en-053"), tetapi terus gunakan "en-GB" dan "en-US".